目录
- 0 写在前面
- 1 文本嵌入:LLM落地的根基
- 2 C-MTEB:acge荣夺榜一
- 2.1 max tokens
- 2.2 文本分类
- 2.3 文本聚类
- 3 acge demo演示与体验
- 总结
0 写在前面
随着信息技术的发展和应用场景的不断扩大,人们需要处理和利用大量的文档信息。而传统的手动处理方法效率低下,无法满足现代生活和工作的需求。文档图像智能分析与处理就是一个重要且极具挑战性的研究问题。

如今,大型语言模型(LLMs)在自然语言处理领域的各项任务中表现出了显著的多功能性和能力,相对于传统方法,大语言模型具备更强大的上下文理解和推理性能。文本嵌入是支撑大语言模型应用的关键技术之一,近期,合合信息发布了文本向量化模型acge_text_embedding(简称acge模型),获得被公认为是目前业界最全面、最权威的中文语义向量评测基准C-MTEB榜单第一的成绩,打通了文本嵌入模型领域的底层原理。
接下来让我们一起深入看看acge模型的核心逻辑吧~
1 文本嵌入:LLM落地的根基
在解决自然语言处理领域相关问题时,首先需要解决的便是如何对单词和文本进行表征,由此研究者们开始研究文本表示技术,即将文本中的单词转换为机器学习或深度学习技术方便处理和使用的向量,又称文本嵌入技术(Embedding),由于能否用向量准确表达出单词和文本的语义信息能够直接决定其他自然语言处理领域的任务效果是否理想,因此词嵌入技术自提出以来便一直处于不断地发展当中。

当前词嵌入技术主要包含两类:
- 离散式表示:即将单词转化为高维向量形式,各个维度之间相互独立,互不联系;
- 分布式表示:即将单词转化成一个固定维度的向量,单词的语义信息分布在向量的各个维度中。
在早期的机器学习算法中,通常采用One-Hot向量进行文本的离散表示,该方法中的词向量维度为所用词典的大小,词向量中只有和单词在词典中位置相同的维度的值为1,其他维度皆为0。
一个浅显的例子如下所示:
将连续的年龄离散化为不同年龄段,并对这些年龄段进行编码,例如少年是 [ 1 , 0 , 0 , 0 ] [1,0,0,0] [1,0,0,0],青年是 [ 0 , 1 , 0 , 0 ] [0,1,0,0] [0,1,0,0],依次类推,通过这种方式将不同的文本区别开
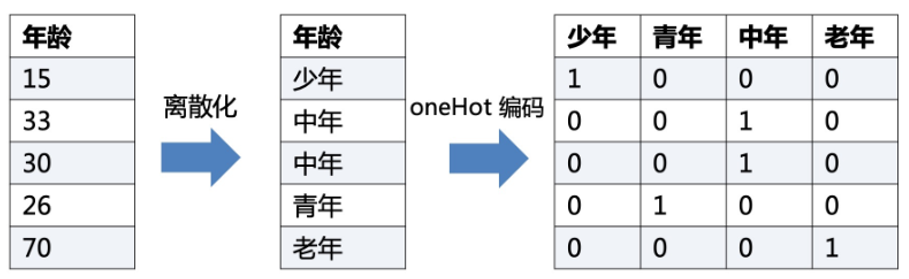
One-Hot编码方式实现简单,但由于维度大小受到所用词典大小的影响且只有一个可使用的维度,因此面临维度灾难和数据稀疏性的问题。在语义表示方面,该编码方式使得词向量之间都是正交的,即词向量之间的语义距离相同,这是不符合实际情况的也无法进行单词语义相似度的计算。此外,该方法也无法解决一词多义的问题,有时候容易出现语义指代不明的情况。
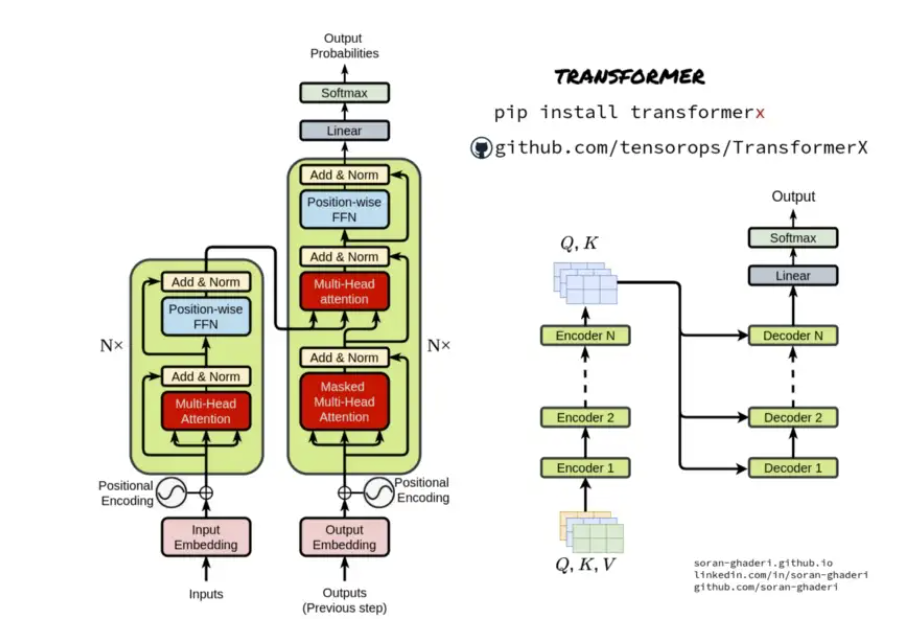
自从Transformer被提出以来, 自然语言处理领域迎来了新的变革, 基于Transformer的大规模预训练语言模型,即动态词嵌入模型,逐渐被提了出来,如GPT,Bert 及其改进模型,它们在自然语言处理领域的诸多任务中都具有优秀的性能表现,使得之后的模型大多都是基于这些大规模预训练语言或对它们进行微调来解决相关任务。
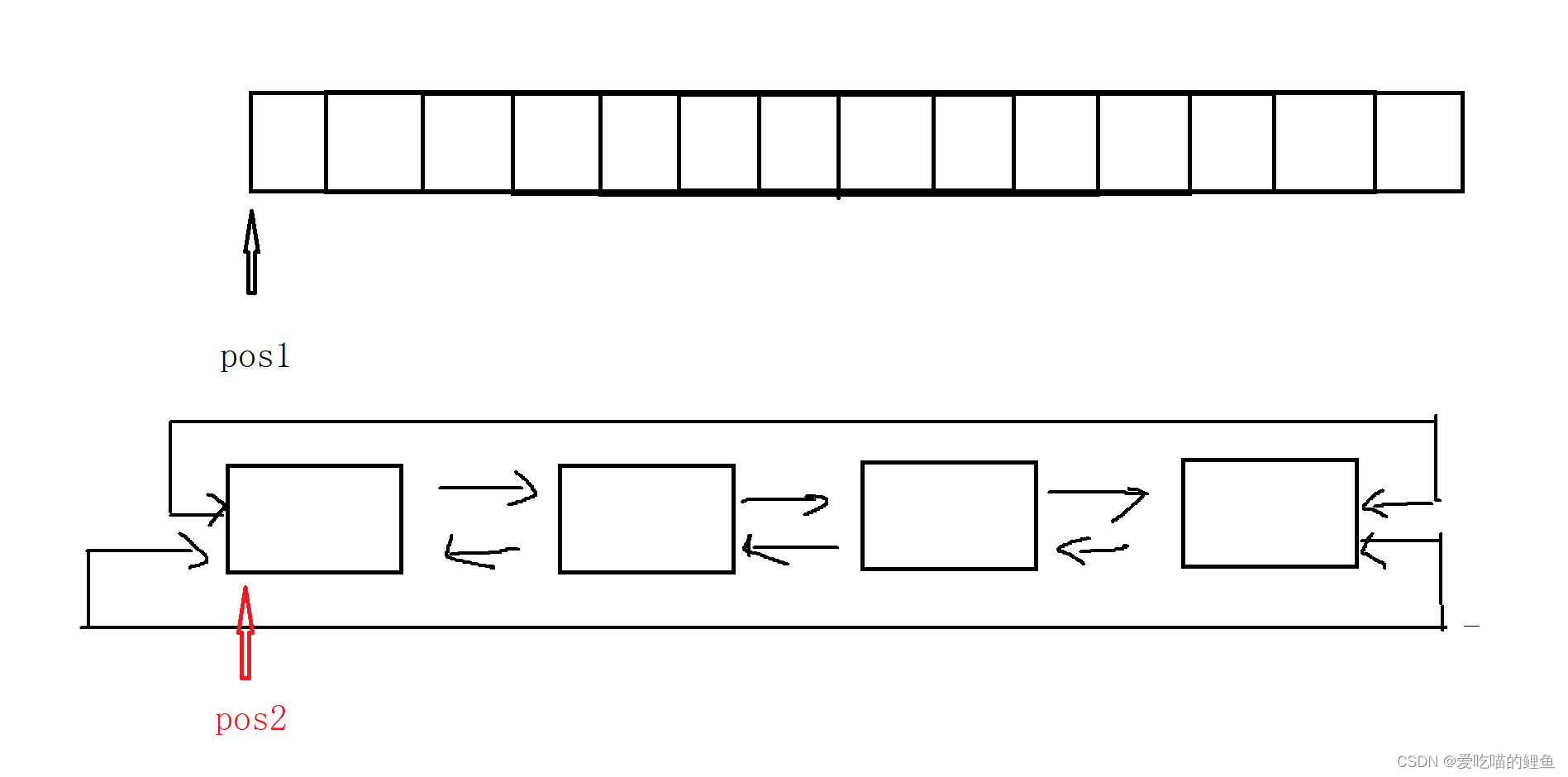
举一个实际的应用案例,合合信息提出的文档排版引擎如下所示

其中从文档抽象出四部分嵌入向量:
- 字符嵌入(Character embedding):将每个字符表示为一个向量的过程,通过将字符映射到一个连续的向量空间中,使得具有相似语义或上下文关系的字符在向量空间中更加接近
- 文本行嵌入(Textline embedding):将整个文本行表示为一个向量的过程。通过将文本行中的所有字符的嵌入向量进行聚合,可以捕捉到整个文本行的语义和上下文信息
- 段落嵌入(Paragraph embedding):将整个段落表示为一个向量的过程。通过将段落中的句子或文本行的嵌入向量进行聚合,可以捕捉到段落的整体语义和上下文信息
- 关系嵌入(Relation embedding):将文本中不同元素之间的关系表示为向量的过程。这些元素可以是词语、句子、文本行或段落等。通过学习元素之间的关系嵌入,可以捕捉到它们之间的语义关联性和相互作用。
总结而言,文本嵌入技术能够将文本数据映射到低维度的向量空间中,从而将文本的语义信息编码为连续的向量表示。这种表示能够捕捉单词、短语甚至整个句子的语义信息,为语言模型理解和表示文本提供了基础。
2 C-MTEB:acge荣夺榜一
文本嵌入技术除了语义编码,在自然语言处理的其他方面也有显著应用。例如文本相似度计算,即将文本映射到向量空间中,从而可以计算文本之间的相似度。这对于信息检索、推荐系统等任务非常重要,可以帮助模型准确地衡量文本之间的语义相似性,从而提高系统的效果;再如文本分类和聚类,由于文本数据在向量空间中具有结构化的表示,从而可以应用传统的机器学习算法进行文本分类和聚类。这些任务包括情感分析、主题识别、文档归类等,嵌入技术的应用可以提高模型的分类和聚类性能。
那么如何客观地综合评价文本嵌入模型的好坏呢?MTEB(Massive Text Embedding Benchmark)就是一个旨在评估文本嵌入模型性能的基准测试,用于帮助研究人员和从业者了解不同文本嵌入模型在多个任务上的表现,并促进对文本嵌入技术的研究和发展。C-MTEB则是最权威的中文语义向量评测基准之一,覆盖了多个自然语言处理任务,包括分类、聚类、检索、排序、文本相似度、STS等6个经典任务,涵盖了不同层次和领域的文本理解和处理;采用共计35个数据集,包含数百万到数十亿的文本样本,提供统一的评估标准和指标,以便研究人员可以直观地比较不同模型在各个任务上的表现

与目前C-MTEB榜单上排名前五的开源模型相比,合合信息本次发布的acge模型具有以下优势
2.1 max tokens
token是一个比较抽象的概念。在自然语言处理中,token通常指对文本进行分割和标记后得到的最小单元。这个最小单元可以是单词、子词、字符或者其他更小的单元。
例1:单词级token
一个token通常对应一个单词。例如,在句子I love natural language processing.中,每个单词都是一个token:["I", "love", "natural", "language", "processing", "."]
例2:字符级token
natural language processing可以被分割成["n", "a", "t", "u", "r", "a", "l", " ", "l", "a", "n", "g", "u", "a", "g", "e", " ", "p", "r", "o", "c", "e", "s", "s", "i", "n", "g"]

理解了token的概念之后,不难得到一个推论:越大的可支持输入tokens意味着模型可以容纳更多的文本信息,以更全面地理解文本中的上下文。这对于一些需要长距离依赖的任务,如文本生成或阅读理解,特别有用。同时,对于一些语言结构复杂的任务,如自然语言推理或语言生成,较大的token输入可以提供更多的语言结构信息,帮助模型更好地理解句子的语义和语法。从这个角度看,acge模型的输入文本长度为1024,远超过另外四个开源模型(512),满足绝大部分场景的需求。
2.2 文本分类
文本分类任务是自然语言处理领域中的最基本的一项任务,其研究目标是对输入的文本进行处理、建模、预测,让最终的预测结果符合预定义的类别标签。由于众多自然语言处理领域的任务所使用的模型都需要对输入的文本进行预处理和分析,而在此过程中往往都需要对语义信息进行分类提取出重要部分的语义信息,才能进行进一步的处理,较高的分类准确率代表着模型能够更准确地获取、分析、整合及利用到更具有代表性的那部分语义信息,而较低的分类准确率则意味着模型提取到了不重要的语义信息甚至是关注了较多噪声信息。
概念比较晦涩,举几个生活中常见的案例
例3:电子商务平台了解用户对某产品的反馈
将产品评论分为正面评价、负面评价和中性评价,从而快速了解产品的优劣势,并做出相应的改进或促销策略。
例4:了解民众对某一事件的看法
对新闻报道、社交媒体帖子或论坛评论进行分类,以分析公众对某一话题或事件的看法。政府、企业或组织可以利用这些信息来及时了解公众舆论,以便及时采取应对措施或调整策略。
因此文本分类效果的好坏,会极大地影这些下游任务的最终表现。acge模型在九个数据集上的文本分类得分(72.75)在前五个开源模型中显示出优势。
2.3 文本聚类
聚类(clustering)是无监督学习(unsupervised learning)中研究最多、应用最广的技术之一,其基本思路是**通过对无标记训练样本的学习来揭示数据内在的聚合性质与规律。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇(cluster),每个簇可能对应于一些潜在的概念(类别),但这些概念的语义需由开发者来把握和命名。
形式化地,假定训练集 X = { x 1 , x 2 , ⋯ , x m } X=\left\{ \boldsymbol{x}_1,\boldsymbol{x}_2,\cdots ,\boldsymbol{x}_m \right\} X={x1,x2,⋯,xm}包含 m m m个无标记样本,每个样本 x i = { x i 1 , x i 2 , ⋯ , x i n } \boldsymbol{x}_i=\left\{ x_{i1},x_{i2},\cdots ,x_{in} \right\} xi={xi1,xi2,⋯,xin}是一个 n n n维征向量。
聚类算法的目标是将训练集 X X X划分为 k k k个不相交的簇 C = { C 1 , C 2 , ⋯ , C k } \mathcal{C} =\left\{ C_1,C_2,\cdots ,C_k \right\} C={C1,C2,⋯,Ck},其中 C l ′ ∩ C l = ⊘ C_{l'}\cap C_l=\oslash Cl′∩Cl=⊘且 X = ⋃ l = 1 k C l X=\bigcup\nolimits_{l=1}^k{C_l} X=⋃l=1kCl,每个簇都对应一个未赋语义的簇标记(cluster label),记为 λ j ∈ { 1 , 2 , ⋯ , k } \lambda _j\in \left\{ 1,2,\cdots ,k \right\} λj∈{1,2,⋯,k},聚类的结果可用包含 m m m个元素的簇标记向量表示 λ = [ λ 1 λ 2 ⋯ λ m ] T \boldsymbol{\lambda }=\left[ \begin{matrix} \lambda _1& \lambda _2& \cdots& \lambda _m\\\end{matrix} \right] ^T λ=[λ1λ2⋯λm]T。
聚类既能作为一个单独过程,用于找寻数据内在的聚合结构,也可作为分类等其他学习任务的前驱过程。在文本聚类任务中,其将文本数据分组成具有相似主题或语义内容的集合。与文本分类不同,文本聚类不需要预先定义的类别,而是通过算法自动发现数据中的模式和结构。
例5:搜索引擎
搜索引擎可以使用文本聚类将大量的文档或文本数据组织成相关主题或类别,从而改善信息检索效率,使用户可以更轻松地浏览相关主题的文档
例6:主题发现
文本聚类可以帮助发现大规模文本数据中的主题和话题,帮助用户快速了解文本数据中的主要内容,这对于新闻报道、社交媒体内容分析以及学术文献研究等领域非常有用。
例7:模式识别
文本聚类可以帮助挖掘大规模文本数据中的隐藏模式和知识。例如在医学领域,可以利用文本聚类技术从医学文献中发现疾病、治疗方法和药物之间的关联和趋势,为医学研究和临床实践提供指导。
合合信息acge模型的文本聚类指标(58.7)远远领先于常规的语言模型。
除此之外acge模型体量较小(326 Million Parameters)且占用资源少(1.21GB);还支持可变输出维度,让企业能够根据具体场景去合理分配资源。
3 acge demo演示与体验
进入acge模型,通过交互界面测试一下模型效果
如图所示,输入源句子和对比句子
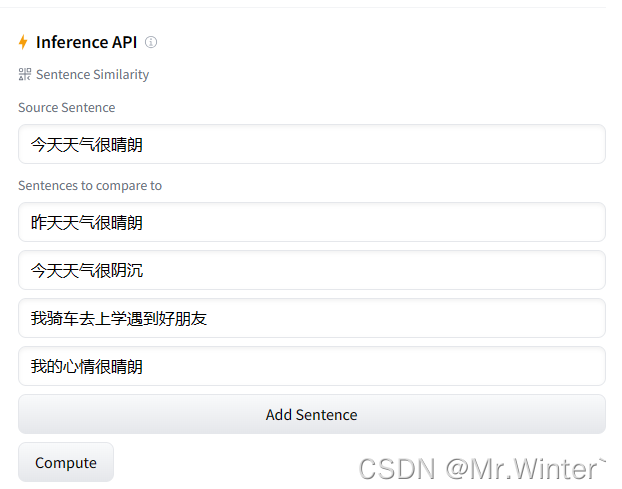
接着系统通过将这些句子输入acge进行文本嵌入,从而在高维嵌入空间计算对比句子和源句子的文本相似性

可以看到其中昨天天气很晴朗和今天天气很晴朗的相似性最高,因为都是形容天气的状态,且都为晴朗;我骑车去上学遇到好朋友和今天天气很晴朗的相似性最低,因为二者几乎不相干。
acge也提供了非常方便的python接口,官网的示范案例如下
from sklearn.preprocessing import normalize
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
model = SentenceTransformer('acge_text_embedding')
embeddings = model.encode(sentences, normalize_embeddings=False)
matryoshka_dim = 1024
embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
embeddings = normalize(embeddings, norm="l2", axis=1)
print(embeddings.shape)
# => (2, 1024)
更多玩法欢迎大家自行探索体验!
总结
在模型升级迭代过程中,合合信息算法团队不断克服行业技术难点:在数据集方面,技术人员收集构造了大量的数据集,保证训练的质量与场景覆盖面;在模型训练方面,引入多种有效的模型调优技术,比如Matryoshka训练方式,能够实现一次训练,获取不同维度的表征提取;为了不同任务针对性学习,使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到最优收敛空间,最终产出了目前业界第一的文本嵌入模型。
除了本次“刷榜”的acge模型,合合信息还在版面分析、图像内容安全、大模型文档处理方面有着积极探索,作为一家人工智能及大数据科技企业,合合信息基于自主研发的领先的智能文字识别及商业大数据核心技术,打造了深受全球用户喜爱的效率工具,例如C端的扫描全能王、名片全能王等。相信合合信息会在模式识别、深度学习、图像处理、自然语言处理等领域的深耕厚积薄发,用技术方案惠及更多的人。