一、transformer的贡献
transformer架构的贡献:该架构只使用自注意力机制,没有使用RNN或卷积网络。且可以实现并行计算,加快模型训练速度。
(将所有的循环层全部换成:multi-headed self-attention)
二、transformer架构
当前序列模型中编码器和解码器架构的效果会更好(encoder-decoder)。
1、编码器定义:
编码器会将一个输入(x1,x2,x3,x4....xn)的一个序列,表示为一个长度为n的序列(z1,z2,z3,z4...zn),其中每一个zt,表示的是xt的一个向量。若该序列为一个句子,则第xt就表示第xt个词。则zt就表示第t个词的向量表示。综上就是编码器的输出。
(通过这样的转换,就可以将用户的输入转换为向量表示,使得模型能够正确的处理)
2、解码器的定义:
解码器会拿到编码器的输出,然后会生成一个长为m(y1,y2,y3,....ym)的一个序列,需要注意的是:n和m可能是不一样长的。如:在将中文句子翻译成英文句子的时候,两种语言的长度可能是不一样的。
3、编码器和解码器的差异:
对于编码器而言:在生成对应的序列的时候,可能是一次性全部生成的。 但在解码器中,解码器生成序列的时候是一个一个元素生成的。这个过程叫做自回归(auto-regressivet)的一个模型。
4、自回归概念的解释
在一个模型中,你的输入又是你的输出。
实际举例:比如在一个实际的序列模型中,你想模型输入了一句话,经过编码器的处理,变成了一个向量序列z(z1,z2,z3....zn),然后将这个向量序列逐个传递给解码器,解码器得到z1后,根据z1就会得到y1;然后根据自回归原理,y1预测得到y2,y2预测y3,依次类推,就可以得到yn。
5、transformer与encoder-decoder之间的联系
transformer是使用了一个编码器和解码器的架构。更具体的解释为:transformer是将一些注意力和point-wise fully connected layers,一个一个堆在一起的。
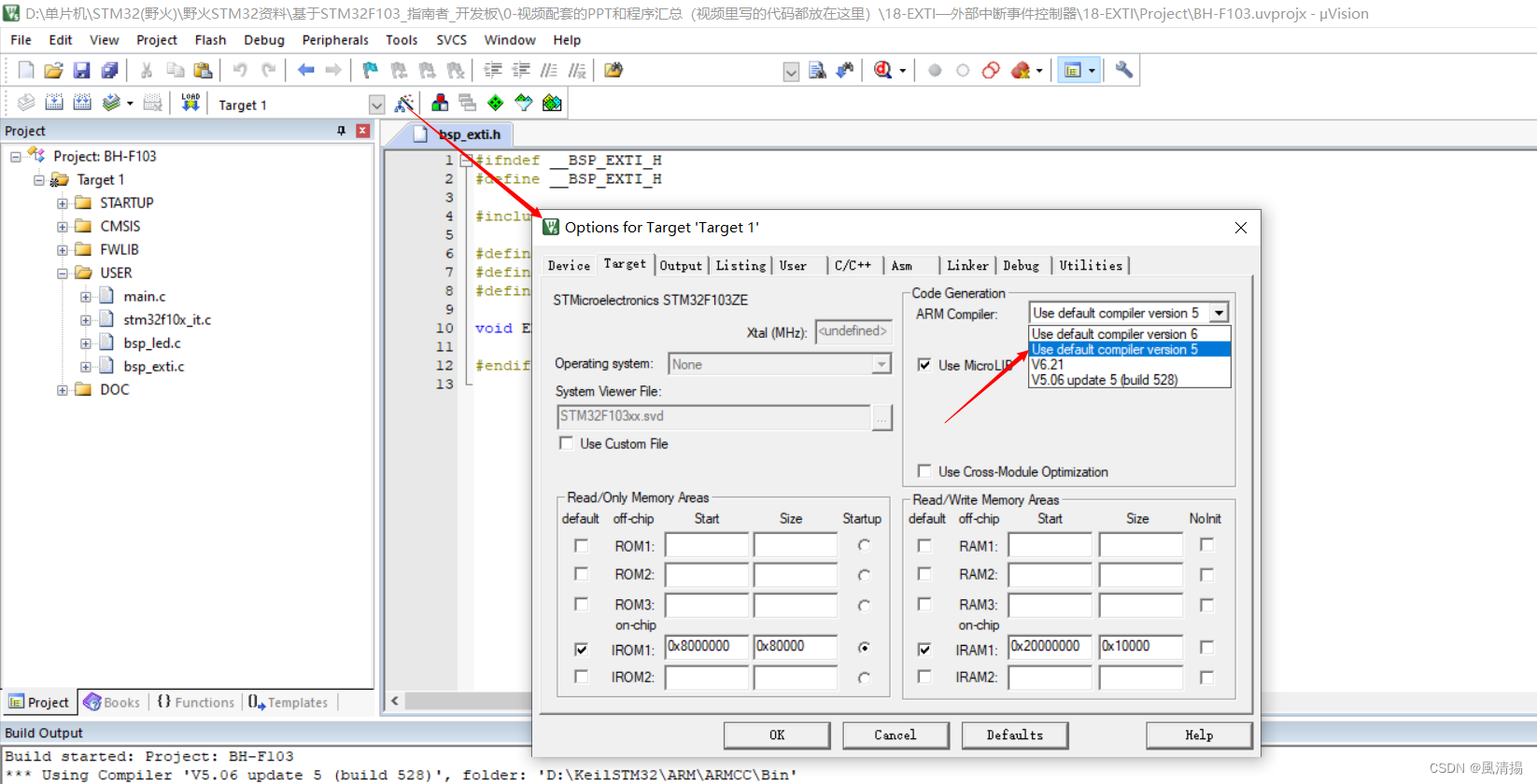
既然是讲解transformer架构,那怎么能少了论文中的transformer架构图: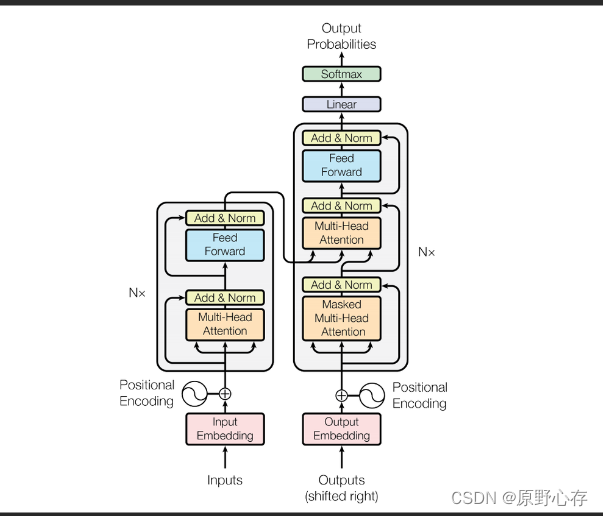
简单解释一下:
我们可以发现这个架构是有两个部分构成,分别是左边的编码器和右边的解码器。然后在编码器的下方,接收一个用户输入。 在解码器的下方,也有一个解码器输入,但是这个输入是比较特殊的,我们细看这个架构图,可以发现解码器的输入并不是input,而是output。其实这是因为在做预测的时候,解码器的输入其实就是编码器的输入。所以这是output,表示是的编码器的输出。然后解码器的输入是一个一个往后或往右移动的。
图中的左边N表示编码器这个整体有N个叠加在一起,右边的N作用雷同。
然后左边编码器的输出作为右边解码器的输入。
6、transformer中编码器的深入讲解
编码器是用n等于六个一样的层(layer),即transformer架构图中的编码器。每个layer中有两个子层(sub-layers)。第一个sub-layer叫做multi-head self-attention。第二sub-layer叫做position-wise fully connected feed-forwad network。对于每个子层,采用了残差连接。最后再使用一个layer notmalization。因为在编码器中使用了残差连接,且残差网络的需求是:输入和输出是一样的大小,如果输入和输出大小不一样,则需要进行投影。所以为了简单起见,论文中奖每一个层的输出的维度变为512,也就是说对一个词,不管是在那一层,就将该词对应的向量表示为512维。
正式基于上述的简单网络设计:
使得该架构可以通过调整n和每一层输出的长度维数这两个参数。
7、transformer中解码器的深入 理解
解码器的构成和编码器很像,也是n为6的同样的层构成。每个层中都有两个子层。但是不同的是:编码器中使用了第三个子层,该层同样是一个多头注意力机制,layer notmalization。在解码器中进行的是自回归预测。所以在训练解码器进行预测时候,不应该让解码器看到预测后的结果。
但是在注意力机制里面,可以看到完整的输入,这样就不能达到预测的效果。因此transformer的解决方法是:通过一个带掩码的注意力机制,这样做的目的是:当我们要让模型预测t时刻对应的结果时,模型不能知道t时刻以后的内容。这样就可以达到一个预测的效果。
三.transformer注意力相关知识介绍
1、transformer中注意力定义
注意力函数:是将query和一些关键值(key value)对,映射成一个输出(output)的一个函数。函数涉及到的query、key value 和output都是一些向量。
具体来说注意力机制的输出output是:value的一个加权和。所以这也说明了输出的维度是和value的维度是一样的。
既然output是value的加权和,那么权重是怎么计算得到?
权重是根据key和query的相似度进行计算的。
2、transformer中单个注意力的计算过程(scaled dot-product attention)
transformer中将注意力的计算过程叫做:缩放的点积注意力(scaled dot-product attention)。
这种计算注意力的方法query和key它的长度是等长的,都等于dk。value是dv。
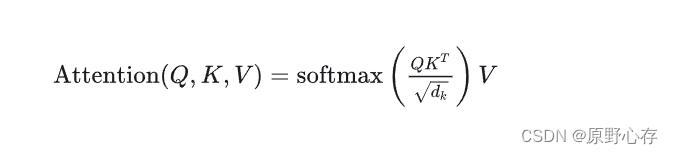
具体的理论计算过程是:将每一个query和key做累积,可以简单的认为是两个向量做“点积”运算。然后再将累积的结果除以根号dk,然后再用一个softmax函数对处理后的结果进行运算得到该query的权重。然后将得到的权重作用到v中就得到输出。
实例的注意力计算过程:刚刚解释了注意力的计算过程,我们发现一个问题,如果我们仅仅是一个query,一个query的计算。则计算的速度是比较慢的。所以在实际计算注意力机制的时候:我们是将query写成一个矩阵(包含n个query),将key写成一个矩阵(包含m个key),这里需要注意的是:query的个数不一定等于key的个数。
①query矩阵的解释:
这时query矩阵是由n个长度为dk的向量构成的二维矩阵。
②key矩阵的解释:
这时key矩阵是由m个长度为dk的向量构成的二维矩阵。
当我们得到query的矩阵和key的矩阵,只需要用query的矩阵点积key矩阵的转置,就会得到一个新的n×m的矩阵(此时这个矩阵的每一行就代表着一个query和key的内积值)。然后再将得到的内积值,除以根号下dk,在将除以dk的结果经过softmax函数进行处理。然后将经过softmax处理后的结果乘以v(其中v是一个m行dv列的矩阵),最后的输出结果就是一个n行dv列的矩阵。
注意力机制一般有两种:加型注意力机制(用于处理query和key不等长的情况)和点积注意力机制(transformer架构中的注意力机制就是基于这种注意力机制,但是除了一个根号dk),正是因为transformer架构中除以了一个数,所以transformer中的注意力机制叫做缩放点积注意力机制
3、transformer计算注意力的时候除以根号dk的解释
在论文中给出了详细的解释:当dk不是很大的时候(dk是指query和key向量对应的长度),可以不除根号dk。 但是当dk的值比较大时,就表明向量的长度比较大,所以将这两个向量做点积的时候,这些值比较大也可能比较小,这样就会造成计算得到的结果相对差距会变大。从而大致越大的值经过softmax函数处理后,会更加的接近1;越小的值经过softmax函数处理后,就会更加接近0;最终的结果就会使得计算得到的值是在聚集在“0端” 和“1端”这样就是的结果两级分化。这样的效果就会造成梯度消失或梯度爆炸。
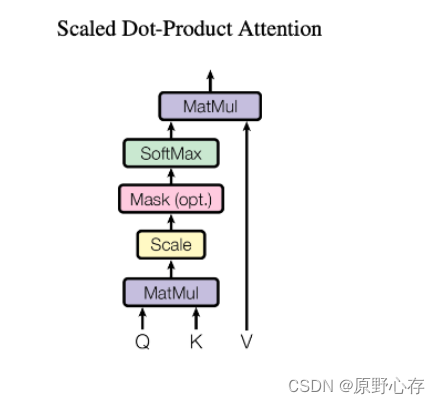
transformer中注意力机制的计算图:
4.transformer中多头注意力机制(Multi-Head Attention)的计算过程

在论文中解释多头注意力机制的由来,是将query、key、value投影到一个低维h次,然后做h次的注意力函数。然后将每一个函数的输出并在一起,然后再投影来得到最终的输出。
论文中举出的公式:

通过以上公式我们可以看出:在计算多头注意力的时候,输入还是以前的q、k、v。但是输出是不同的头进行合并起来(concat),投影到wo里面。然后对每个头,通过一个不同的可以学习的wq,wk,wv投影到低维上面。
在论文中使用8个头,因为在计算注意力的时候,有残差连接,所以输出和出入维度至少是一样的。
所以在投影的时候,它投影的就是你的输出的维度除以h
在论文中因为设置的维度为512维,多头数为8,所以投影维度为512/8=64。
5、transformer中使用多头注意力机制的情况
①在编码器中使用,外部输入的信息经过添加位置编码后,转换为向量。然后将向量一分为三:query,value、key。通过多头注意力机制,将n组q,k,v作为输入,就会得到n个输出。在使用多头注意力机制的时候,会学习到n个不一样的距离空间出来,使得输出输出的东西是不一样的。
②在解码器中底部使用:在解码器中的利用和编码器中利用原理是相似的,但是解码器中多出一个掩码机制,这是因为解码器在预测第t个词的时候,是不能看到第t个词后面的信息。所以要将第t个词后的全部词对应的权重为0。
③在解码器的中间使用:需要注意的是:这时的注意力机制不在是自注意力机制(即q,k,v的来源是不一样的)。此时注意力机制输入的key和value是来自编码器的输出。然后query是来自解码器下一个(与transformer中解码器的结构图对应)attention的输入。这个注意力机制的应用,目的是根据在解码器输入的不一样向量,则会根据当前需要计算的向量,在编码器的输出里面去挑出与该变量最相关的东西,进行计算。
四、transformer中位置前馈网络(position-wise feed-forward networks)讲解
1、位置前馈网络的简单介绍
位置前馈网络(position-wise feed-forward networks )其实就是MLP(多层感知机)。但是不一样的是把一个MLP对每一个词作用一次,且对每个词作用的是同一个MLP(这就是论文中point wise的意思)。
2、计算公式
![]()
公式解释:这个公式中xw1+b1表示一个线性层,然后使用max函数,将线性层的结果与0进行比较,选择较大的数,即表示的一个relu激活函数。然后将relu的结果与w2相乘,加上一个常数b2。从而构成一个新的线性层。
我们知道在论文中,注意力层他的输入:每一个query它对应的哪一个输出,它是长为512,那么就是说公式中的x向量的长度对应就是512,然后论文中的操作根据w1参数,将512投影为2048(即将x向量的维度扩大了四倍)。然后因为position-wise feed-forward networks用到了一个残差连接为了让输出维度和输出维度保持一致,所以会用参数w2将当前长度为2048的向量,投影为长度为512的向量。
五、transformer中Embeddings层 和 Softmax层
①embeddings层:因为我们输出模型的词(token),不能直接被模型识别,所以我们需要将他映射成一个向量(在论文映射成向量后,向量的长度为512)。
②在线性层的前面也需要一个embedding,且权重相同,且将权重乘以根号d(d表示向量对应的长度,论文中d为512)。
六、transformer中位置编码(Positional Encoding)
因为transformer架构中是利用attention提取序列的有效信息。虽然提取到了输入序列的有效信息,但是并不会有时序信息。transformer中解决这个问题方法是将输出序列的内容和时序信息进行结合,作为模型的输入。
论文中给出的计算位置信息的公式: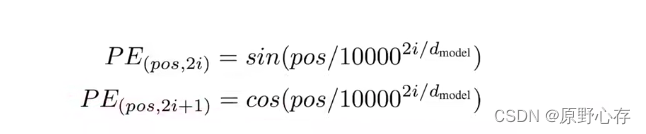
七、transformer的总结
在transformer中attention起到的作用就是把输入序列的有效信息抓取出来,做一次汇聚得到一个输出结果。此时汇聚得到的结果已经包含了序列中我需要的东西,然后聚合结果传入到位置前馈网络中,经过位置前馈网络的处理将得到的序列信息映射到对应的语义空间的时候,做一个语义转换。
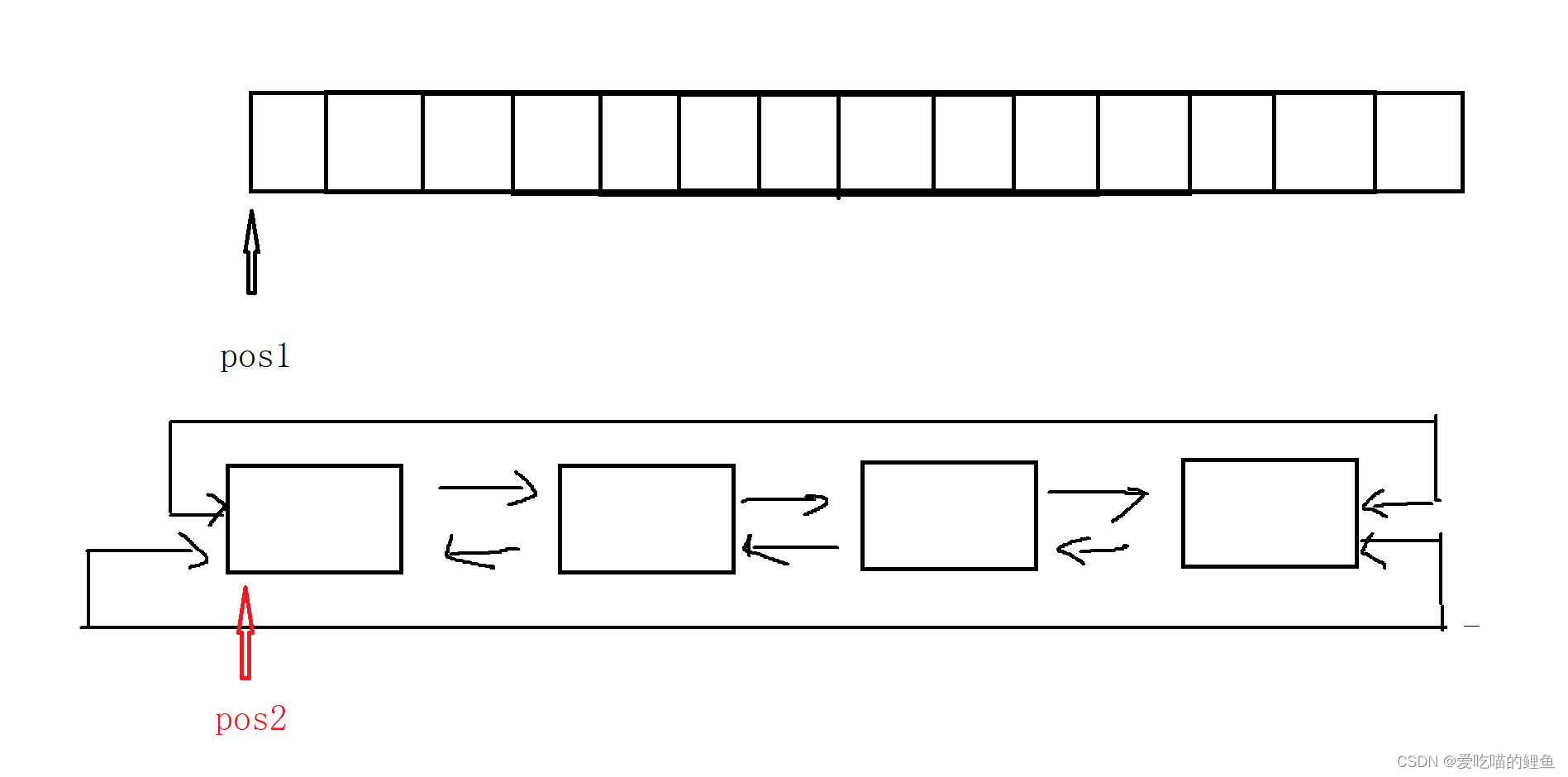
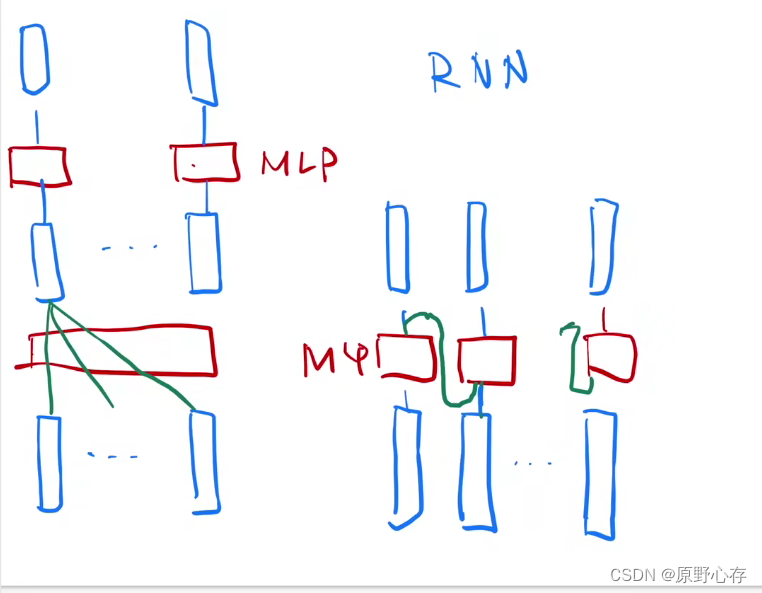
但是在rnn神经网络中,是将输入的序列(x1,x2,..xn),将x1向量经过MLP单独处理后的结果y1,在将y1和下一个序列作为输入计算y2....这样的计算过程就会变慢,而且当输出序列太大时,会出现语义丢失。
下图是沐神画出的transformer和rnn在处理序列上的区别:
课程链接:Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili