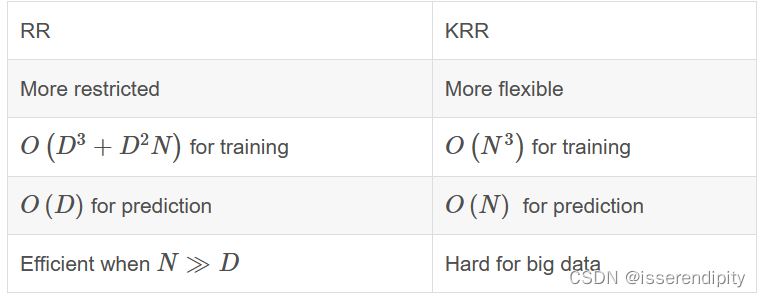
数据结构:线性表、非线性表
线性表: 数组,链表、队列、栈等。
线性表就是数据排成像一条线一样的结构,每个线性表上的数据最多只有前和后两个方向。
非线性表: 二叉树、堆、图等。
在非线性表中,数据之间并不是简单的前后关系。
数组
数组:在内存中分配一段连续的空间,且数据类型相同。
数组为什么能够实现通过下标来访问数据的速度为O(1)?
在这段连续的内存中的下标就是一个内存格子的偏移量,所以下标总是从0开始。(当然原因也不全是这样,但不重要)
为什么要用偏移量,为什么下标从0开始,为什么不从1开始?
因为效率原因
cpu寻址, 首地址–>第一个数据类型所占大小–>第二个数据类型所占大小–>第三个数据类型所占大小
计算公式:cpu寻址应该偏移多少 = 首地址 + (第几个数据 * 单个数据大小)
若下标为1开始时:
寻a[5]时cpu计算公式:首地址 + ( (5-1) * 单个数据大小)
若下标为0开始时:
寻a[5]时cpu计算公式:首地址 + (5 * 单个数据大小)
相比之下,下标从0开始让cpu省去了一个减法运算,虽然对cpu来说,所有运算都只有加法,但要实现减法用补码的方式计算,肯定要比单纯的加法计算要慢。
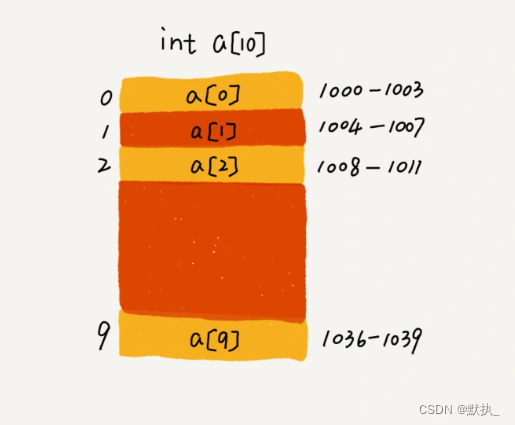
如何优化数组的插入和删除速度?
时间消耗主要原因:
插入数据:在数组中间某个位置插入数据,所有在该数据后面的数据都要向后偏移一位。
删除数据:在数组中间某个位置删除数据,所有在该数据后面的数据都要向前偏移一位。
以上是正常情况下所发生的,如果频繁的插入和删除,按照这种模式,效率肯定会下降。最坏的情况是O(n)。
可利用的优化规律: 如果是在数组的尾部新增(删除)一个数据,就不需要偏移其他数据。
插入: 新数据插入某位置时,将原位置上的数据复制并插入到数组尾部,新数据就可覆盖某处位置了。
删除/插入: 如果出现连续删除几个数据,记录删除的元素,把删除三次合并为删除一次,只需要偏移一次数据,避免偏移3次,提升了删除效率。
容器可以完全替代数组吗?
如果我们申请了大小为 10 的数组,当第 11 个数据需要存储到数组中时,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入,这是容器的好处,动态扩容。
这样确实方便,但如果你知道数组中只需要多少空间的时候,最好使用数组。
数组中指定数据大小可以省掉很多次内存申请和数据搬移操作,更加高效。
这时候要根据情况去权衡,但如果你说,我不差这点效率,那你随意。





![[Linux][多线程][一][线程基础概念][进程VS线程][线程控制]详细讲解](https://img-blog.csdnimg.cn/direct/e672947b349f47d8924596100d777522.png)