文章目录
- 前言
- 一、节点
- 二、决策树
- 2.1 案例分析——优良的水稻
- 2.2 案例分析——家庭财富水平
- 三、随机森林
- 三、Python代码实现
- 3.1 关键问题
- 3.1.1 节点的表示
- 3.1.2 决策树的表示
- ** 根节点划分左右子树的依据 **
- 3.1.3 随机森林的构造与重要性的表示
- 3.2 节点类
- 3.2 决策树类
- 3.2.1 初始化
- 3.2.2 计算方差
- 3.2.3 选择最佳划分特征和阈值
- 3.2.4 构建决策树
- 3.2.5 训练与预测
- 3.2.6 计算指标重要性
- 3.2.6 绘制决策树(调试方法)
- 3.4 随机森林类
- 3.4.1 初始化
- 3.4.2 训练(构造)随机森林
- 3.4.3 获取特征重要性
- 四、程序测试
- 4.1 测试代码
- 4.2 测试结果
- 五、完整代码
前言
善始者繁多,克终者盖寡。
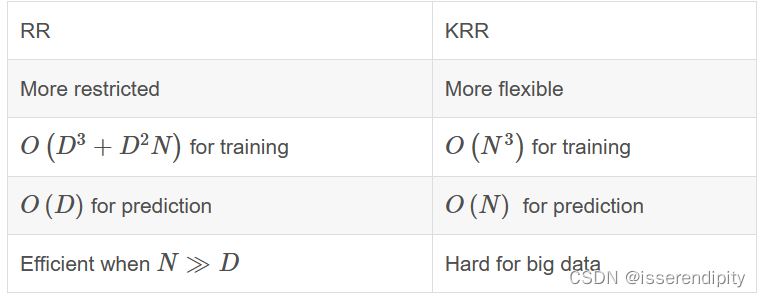
在某个评价体系中,计算指标重要性(或者称之为“权重”)的方法有基于经验的方法,例如层次分析法、德尔菲法,有基于统计学的方法,例如熵权法、离差最大化法,机器学习的发展为指标重要性的计算提供了新的思路。
已有大量的研究将神经网络算法应用于指标权重的计算上,最简单的就是三层结构的BP神经网络,但是使用神经网络算法时通常需要输入数据具备相同的量纲,也就是输入数据需要进行归一化处理,当然数据归一化益处多多,但此过程对异常数据极其敏感,可能导致数据分布改变,从而导致原始数据信息损失。而使用决策树则可以很好的避免数据归一化引起的系列问题,除必要的数据清洗外,通常情况下不需要对原始数据进行任何处理就可以应用决策树算法。从数据结构角度看,决策树算法就是构建一棵二叉树的过程,为了提高系统的准确率和泛化能力,通常在数据集中随机选择数据构建决策树,若干决策树组成了森林,于是就有了随机森林。
注意:并不是说神经网络和决策树谁好谁差,只不过是两种算法的应用场景有所差异,不知如何选择时可以在相同数据集上使用这两种方法,选择效果最佳的一种。
一、节点
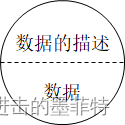
为了交流方便,我们将存放数据的最小单位为“节点”,它至少包含两个信息:数据本身和数据的描述,一个节点可以描述为:
二、决策树
多个节点共同组成了一颗树,下图所示的都可以称之为“树”:
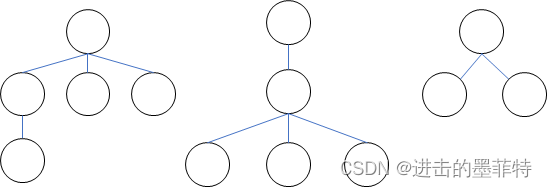
根据节点中最大分支个数我们给这些树取名字,例如图1和图2中的树我们称之为“三叉树”,图3中的树我们称之为“二叉树”,这个“二叉树”像极了帮我们做选择的助手,从第一个节点出发后要么走左边的节点,要么走右边的节点,于是我们称这样的结构为“决策树”。
2.1 案例分析——优良的水稻
假设我们可以通过“稻穗大小、稻杆长短、颜色程度”三个指标判断水稻是否为优良品种,优良品种的特征有“稻穗大、稻杆短、颜色金黄”三个特征,主要满足两个就属于优良品种,现已有三份水稻样品:
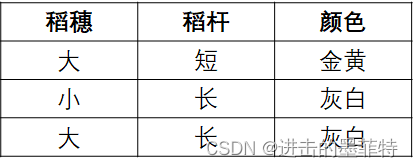
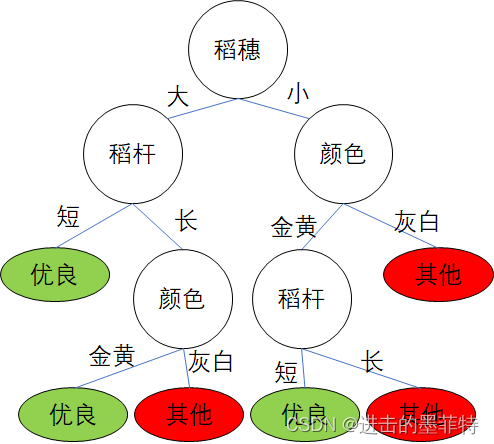
按照人的思维和习惯我们可以逐步划分,即得到如下的决策树,我们很容易判断上述表格中三份水稻样品的品质分别为“优良、其他、其他”。
本例中包含3个属性,所以决策树的深度为3(只看圆的,椭圆是判断结果),如果我们先判断“稻杆”或者“颜色”,我们便会得到一棵不同的决策树,但是不论如何选择决策树的最大深度都是3。值得注意的是本例中所有属性的取值都只有两个,但现实世界中的情况往往复杂的多。
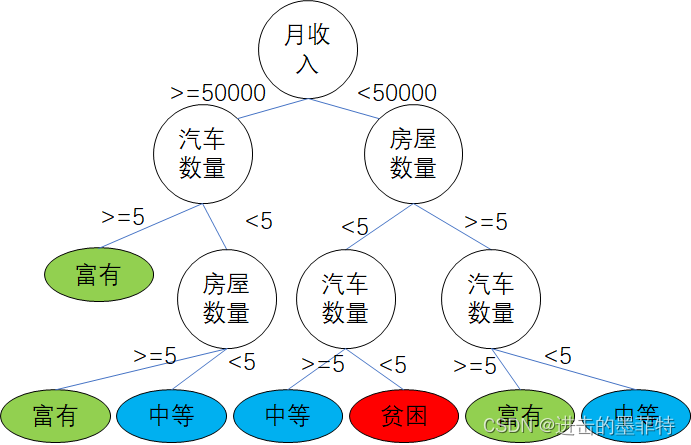
2.2 案例分析——家庭财富水平
假设我们可以通过“月收入、汽车数量、房屋数量”三项指标评估某个家庭的财富水平,已知“月收入>=50000、汽车数量>=5、房屋数量>=5”三项条件中,满足两项及以上的家庭为“富有”,满足一项的家庭为“中等”,一项不满足的家庭为“贫困”,现已收集到三个家庭的数据:
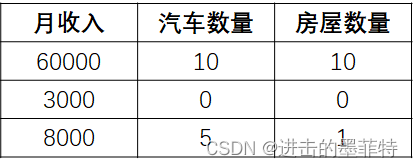
我们同样可以构造一棵决策树,我们不难判断出上表三个家庭的财富水平分别为“富有、贫困、中等”。
本例中我们使用了连续型数据,发现虽然决策树的深度相同,但产生的结果比2.1复杂了许多,随着属性的增多、数据的增多,人工构造决策树的难度会大大提高。
三、随机森林
使用相同的数据可以生成不同的决策树,当数据集足够庞大时我们需要限制每一棵决策树的深度,以增强模型的泛化能力,这就使得每棵决策树产生了差异,随机森林就是考虑每一棵决策树的差异,以期提供最佳决策方案。
确定每棵决策树的深度、森林中决策树的数量是随机森林算法的关键。
三、Python代码实现
3.1 关键问题
3.1.1 节点的表示
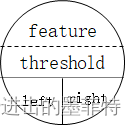
一棵树中的节点应当包含如下信息:节点的描述、节点的数据、左子树、右子树。具体到一颗决策树中,这四项信息可以具体描述为:属性(何处对树分支)、阈值(划分左右子树的标准)、左子树(左子树的根节点)、右子树(右子树的根节点)。
3.1.2 决策树的表示
在一棵树中,只有我们知道了一个树的根节点,我们就可以遍历整棵树;为了防止过拟合以及节省系统资源,我们必须指定树的最大深度。
根据实际情况,我们需要解决的问题是:计算指标重要性。所有我们还需要知道属性的总个数。
那决策树的根节点在选择属性A和阈值x1划分后得到属性A取值全大于等于x1和属性A取值全小于x1的两部分数据,即left和right,那left根节点划分时会不会再次选择A属性进行划分呢????
答案是完全有可能! 所以,我们还需要一个变量用于存储 决策树中使用到的属性的个数。
** 根节点划分左右子树的依据 **
方差。本例中使用“方差”考量原系统的聚合程度、划分后系统的聚合程度 。理想状态下,随着决策树的划分,系统的聚合程度越来越高,即系统的方差越来越小,相似的样本被划分到一起,所有决策树最早是被用来解决分类问题。
3.1.3 随机森林的构造与重要性的表示
使用“出现频次”表示属性的重要性。
通过循环构建若干决策树,决策树的集合就构成了随机森林,随机森林中包含若干决策树,统计每棵决策树中各属性出现的频次,出现频次高的属性其重要性强,反之则弱。
3.2 节点类
节点的left、right属性存储的是左右子树的根节点。
在实际操作中我们使用“ 属性的索引 ”代替具体的属性名称,以方便程序操作。
# 决策树节点
class TreeNode:
def __init__(self, feature_index=None, threshold=None, left=None, right=None):
# 特征索引(在决策树按哪个特征进行分支)
self.feature_index = feature_index
# 阈值(在决策树中按某个特征的某个值划分左右子树)
self.threshold = threshold
# 左子树
self.left:TreeNode = left
# 右子树
self.right:TreeNode = right
3.2 决策树类
3.2.1 初始化
class DecisionTreeRegressor:
def __init__(self, max_depth=None,feature_numbers=None):
# 指定决策树的最大深度
self.max_depth = max_depth
# 返回整棵决策树(也就是根节点,可通过根节点遍历整棵树)
self.bootnode:TreeNode = None
# 属性的总个数
self.feature_numbers = np.zeros(feature_numbers)
# 树中出现属性的个数
self.available_feature_numbers = 0
3.2.2 计算方差
# 计算数据集的方差(使用方差作为目标函数)
def _calculate_variance(self, y):
return np.var(y)
# 计算划分后的两个数据集的加权方差(用来寻找最合适划分子树的方法,让方差最小)
def _calculate_weighted_variance(self, left_y, right_y):
n = len(left_y) + len(right_y)
left_var = self._calculate_variance(left_y)
right_var = self._calculate_variance(right_y)
weighted_var = (len(left_y) / n) * left_var + (len(right_y) / n) * right_var
return weighted_var
3.2.3 选择最佳划分特征和阈值
# 选择最佳划分特征和阈值
def _find_best_split(self, X, y):
m, n = X.shape
# 计算当前划分方法系统方差变化值(减少量),方差减少的越多越好
best_var_reduction = 0
best_feature_index = None
best_threshold = None
# 计算当前节点的方差
current_var = self._calculate_variance(y)
# 有n个特征值,要进行n次判断
for feature_index in range(n):
'''
找到每一个特征值中的唯一值(返回值是一个列表)
依次取出列表中的值作为阈值计算系统方差变化情况
'''
thresholds = np.unique(X[:, feature_index])
for threshold in thresholds:
'''
np.where方法返回的是元组对象
元组中包含了在feature_index特征上取值小于等于阈值的行索引,使用[0]取出
'''
left_indices = np.where(X[:, feature_index] <= threshold)[0]
right_indices = np.where(X[:, feature_index] > threshold)[0]
# 如果划分到最后,该节点无法划分出左子树或者右子树,说明该节点已经是叶子节点了,跳过
if len(left_indices) == 0 or len(right_indices) == 0:
continue
# 取出左右子树记录,为计算系统方差做准备
left_y = y[left_indices]
right_y = y[right_indices]
# 计算加权方差的减少量
var_reduction = current_var - self._calculate_weighted_variance(left_y, right_y)
# 更新最佳划分(减少量越大越好,说明系统方差小)
if var_reduction > best_var_reduction:
best_var_reduction = var_reduction
best_feature_index = feature_index
best_threshold = threshold
return best_feature_index, best_threshold
3.2.4 构建决策树
# 递归构建决策树
def _build_tree(self, X, y, depth):
if depth == self.max_depth or len(np.unique(y)) == 1:
return TreeNode(None, None, None, None)
# 找到划分的属性和阈值
feature_index, threshold = self._find_best_split(X, y)
if feature_index is None or threshold is None:
return TreeNode(None, None, None, None)
left_indices = np.where(X[:, feature_index] <= threshold)[0]
right_indices = np.where(X[:, feature_index] > threshold)[0]
left_child = self._build_tree(X[left_indices], y[left_indices], depth + 1)
right_child = self._build_tree(X[right_indices], y[right_indices], depth + 1)
return TreeNode(feature_index, threshold, left_child, right_child)
3.2.5 训练与预测
决策树的训练就是构建决策树的过程。
在决策树中通常采用均值表示某条记录的预测值。(计算指标重要性不需要使用预测方法)
# 计算数据集的均值
def _calculate_mean(self, y):
return np.mean(y)
# 训练决策树模型
def fit(self, X, y):
self.bootnode = self._build_tree(X, y, 0)
# 预测单个样本
def _predict_one(self, x, node):
if node.feature_index is None or node.threshold is None:
return self._calculate_mean(x)
if x[node.feature_index] <= node.threshold:
return self._predict_one(x, node.left)
else:
return self._predict_one(x, node.right)
# 批量预测
def predict(self, X):
return np.array([self._predict_one(x, self.bootnode) for x in X])
3.2.6 计算指标重要性
# 计算树中各特征值出现频次
def _calculate_features(self,node:TreeNode):
if node.feature_index is not None:
self.feature_numbers[node.feature_index] += 1
self.available_feature_numbers += 1
self._calculate_features(node.left)
self._calculate_features(node.right)
# 将树中特征出现频次转换为特征重要性
def calculate_importance(self):
self._calculate_features(self.bootnode)
return self.feature_numbers/self.available_feature_numbers
3.2.6 绘制决策树(调试方法)
像神经网络这样的模型,其结构是在创建之前就设定好了的,但决策树不同,在调试时可以打印出决策树中各节点信息,绘制决策树,以判断程序运行效果是否满足研究的需要。
def show(self,node:TreeNode):
list = ["根","左","右"]
if node.feature_index is not None:
print(list[0],node.feature_index)
# print("->",end="")
# print(node.threshold)
if node.left is not None:
print(list[1],"--", end="")
self.show(node.left)
else:
print(list[1],"--None")
if node.right is not None:
print(list[2],"--", end="")
self.show(node.right)
else:
print(list[2],"--None")
else:
print(list[0], "--None")
3.4 随机森林类
3.4.1 初始化
class RandomForestRegressor:
def __init__(self, n_estimators=None, max_depth=None, max_features=None):
# 若干棵决策树组成森林,树的数量
self.n_estimators = n_estimators
# 每一棵决策树具有相同的深度
self.max_depth = max_depth
# 每一棵决策树的特征综素相同
self.max_features = max_features
# 若干棵决策树组成的列表,就是我们需要的随机森林了
self.trees = []
3.4.2 训练(构造)随机森林
# 训练随机森林,也就是向列表中依次添加决策树
def fit(self, X, y):
for _ in range(self.n_estimators):
# 随机选择数据子集和特征子集
n_samples = X.shape[0]
# 从样本中随机选择n_samples条记录,记录可重复
bootstrap_indices = np.random.choice(n_samples, size=n_samples, replace=True)
bootstrap_X = X[bootstrap_indices]
bootstrap_y = y[bootstrap_indices]
tree = DecisionTreeRegressor(max_depth=self.max_depth,feature_numbers=self.max_features)
tree.fit(bootstrap_X, bootstrap_y)
self.trees.append(tree)
3.4.3 获取特征重要性
特征重要性是在决策树类中计算的,在随机森林中只需要统计各决策树中特征重要性并求均值即可。
# 获取特征重要性
def feature_importances(self, X, y):
n_features = X.shape[1]
total_importances = np.zeros(n_features)
# 计数,统计每一棵树中各特征值出现的频次,出现频次越多说明该特征越重要
for one_tree in self.trees:
importance = one_tree.calculate_importance()
total_importances += importance
# 计算n_estimators棵树中,各特征值的平均重要程度(还是通过出现频次表示)
return total_importances / self.n_estimators
四、程序测试
4.1 测试代码
load_data_primal方法用于读取数据文件,文件中前3列为基本信息,最后以来为期望输出,其余10列为原始数据。
测试程序中构建了一个包含100棵树、每棵树最大深度为10、输入样本特征为10的随机森林。
def load_data_primal():
df = pd.read_excel("data.xlsx")
data_temp = df.iloc[:,3:-1]
label_temp = df["综合评分"]
data = []
label = []
for i in range(df.shape[0]):
data.append(data_temp.iloc[i].to_list())
temp = []
temp.append(label_temp[i])
label.append(temp)
data = np.array(data)
label = np.array(label)
return data,label
if __name__ == '__main__':
# 生成示例数据集
X, y = load_data_primal()
# print(X)
# print(y)
# 构建随机森林模型
rf = RandomForestRegressor(n_estimators=100, max_depth=10, max_features=10)
rf.fit(X, y)
#for one_tree in rf.trees:
# one_tree.show(one_tree.bootnode)
# 获取特征重要性
importances = rf.feature_importances(X, y)
# 先使用argsort进行降序排序,再进行反转
indices = np.argsort(importances)[::-1]
# 打印特征重要性
print("Feature ranking:")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# 可视化特征重要性
plt.figure()
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices], color="r", align="center")
plt.xticks(range(X.shape[1]), indices)
plt.xlim([-1, X.shape[1]])
plt.show()
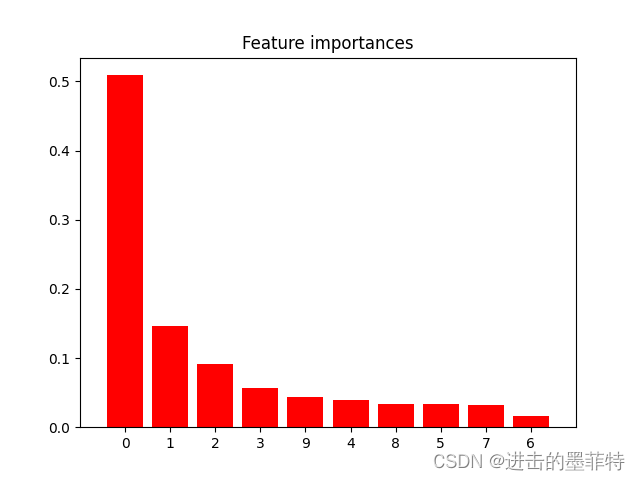
4.2 测试结果
本例中以“出现频次”作为判断特征重要性的依据,显示的是对频次处理后的结果。
五、完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 决策树节点
class TreeNode:
def __init__(self, feature_index=None, threshold=None, left=None, right=None):
# 特征索引(在决策树按哪个特征进行分支)
self.feature_index = feature_index
# 阈值(在决策树中按某个特征的某个值划分左右子树)
self.threshold = threshold
# 左子树
self.left:TreeNode = left
# 右子树
self.right:TreeNode = right
# 决策树模型(通过递归创建)
class DecisionTreeRegressor:
def __init__(self, max_depth=None,feature_numbers=None):
# 指定决策树的最大深度
self.max_depth = max_depth
# 返回整棵决策树(也就是根节点,可通过根节点遍历整棵树)
self.bootnode:TreeNode = None
# 属性的总个数
self.feature_numbers = np.zeros(feature_numbers)
# 树中出现属性的个数
self.available_feature_numbers = 0
# 计算数据集的方差(使用方差作为目标函数)
def _calculate_variance(self, y):
return np.var(y)
# 计算数据集的均值
def _calculate_mean(self, y):
return np.mean(y)
# 计算树中各特征值出现频次
def _calculate_features(self,node:TreeNode):
if node.feature_index is not None:
self.feature_numbers[node.feature_index] += 1
self.available_feature_numbers += 1
self._calculate_features(node.left)
self._calculate_features(node.right)
# 将树中特征出现频次转换为特征重要性
def calculate_importance(self):
self._calculate_features(self.bootnode)
return self.feature_numbers/self.available_feature_numbers
# 计算划分后的两个数据集的加权方差(用来寻找最合适划分子树的方法,让方差最小)
def _calculate_weighted_variance(self, left_y, right_y):
n = len(left_y) + len(right_y)
left_var = self._calculate_variance(left_y)
right_var = self._calculate_variance(right_y)
weighted_var = (len(left_y) / n) * left_var + (len(right_y) / n) * right_var
return weighted_var
# 选择最佳划分特征和阈值
def _find_best_split(self, X, y):
m, n = X.shape
# 计算当前划分方法系统方差变化值(减少量),方差减少的越多越好
best_var_reduction = 0
best_feature_index = None
best_threshold = None
# 计算当前节点的方差
current_var = self._calculate_variance(y)
# 有n个特征值,要进行n次判断
for feature_index in range(n):
'''
找到每一个特征值中的唯一值(返回值是一个列表)
依次取出列表中的值作为阈值计算系统方差变化情况
'''
thresholds = np.unique(X[:, feature_index])
for threshold in thresholds:
'''
np.where方法返回的是元组对象
元组中包含了在feature_index特征上取值小于等于阈值的行索引,使用[0]取出
'''
left_indices = np.where(X[:, feature_index] <= threshold)[0]
right_indices = np.where(X[:, feature_index] > threshold)[0]
# 如果划分到最后,该节点无法划分出左子树或者右子树,说明该节点已经是叶子节点了,跳过
if len(left_indices) == 0 or len(right_indices) == 0:
continue
# 取出左右子树记录,为计算系统方差做准备
left_y = y[left_indices]
right_y = y[right_indices]
# 计算加权方差的减少量
var_reduction = current_var - self._calculate_weighted_variance(left_y, right_y)
# 更新最佳划分(减少量越大越好,说明系统方差小)
if var_reduction > best_var_reduction:
best_var_reduction = var_reduction
best_feature_index = feature_index
best_threshold = threshold
return best_feature_index, best_threshold
# 递归构建决策树
def _build_tree(self, X, y, depth):
if depth == self.max_depth or len(np.unique(y)) == 1:
return TreeNode(None, None, None, None)
# 找到划分的属性和阈值
feature_index, threshold = self._find_best_split(X, y)
if feature_index is None or threshold is None:
return TreeNode(None, None, None, None)
left_indices = np.where(X[:, feature_index] <= threshold)[0]
right_indices = np.where(X[:, feature_index] > threshold)[0]
left_child = self._build_tree(X[left_indices], y[left_indices], depth + 1)
right_child = self._build_tree(X[right_indices], y[right_indices], depth + 1)
return TreeNode(feature_index, threshold, left_child, right_child)
# 训练决策树模型
def fit(self, X, y):
self.bootnode = self._build_tree(X, y, 0)
# 预测单个样本
def _predict_one(self, x, node):
if node.feature_index is None or node.threshold is None:
return self._calculate_mean(x)
if x[node.feature_index] <= node.threshold:
return self._predict_one(x, node.left)
else:
return self._predict_one(x, node.right)
# 批量预测
def predict(self, X):
return np.array([self._predict_one(x, self.bootnode) for x in X])
def show(self,node:TreeNode):
list = ["根","左","右"]
if node.feature_index is not None:
print(list[0],node.feature_index)
# print("->",end="")
# print(node.threshold)
if node.left is not None:
print(list[1],"--", end="")
self.show(node.left)
else:
print(list[1],"--None")
if node.right is not None:
print(list[2],"--", end="")
self.show(node.right)
else:
print(list[2],"--None")
else:
print(list[0], "--None")
# 定义随机森林模型
class RandomForestRegressor:
def __init__(self, n_estimators=None, max_depth=None, max_features=None):
# 若干棵决策树组成森林,树的数量
self.n_estimators = n_estimators
# 每一棵决策树具有相同的深度
self.max_depth = max_depth
# 每一棵决策树的特征综素相同
self.max_features = max_features
# 若干棵决策树组成的列表,就是我们需要的随机森林了
self.trees = []
# 训练随机森林,也就是向列表中依次添加决策树
def fit(self, X, y):
for _ in range(self.n_estimators):
# 随机选择数据子集和特征子集
n_samples = X.shape[0]
# 从样本中随机选择n_samples条记录,记录可重复
bootstrap_indices = np.random.choice(n_samples, size=n_samples, replace=True)
bootstrap_X = X[bootstrap_indices]
bootstrap_y = y[bootstrap_indices]
tree = DecisionTreeRegressor(max_depth=self.max_depth,feature_numbers=self.max_features)
tree.fit(bootstrap_X, bootstrap_y)
self.trees.append(tree)
# 获取特征重要性
def feature_importances(self, X, y):
n_features = X.shape[1]
total_importances = np.zeros(n_features)
# 计数,统计每一棵树中各特征值出现的频次,出现频次越多说明该特征越重要
for one_tree in self.trees:
importance = one_tree.calculate_importance()
total_importances += importance
# 计算n_estimators棵树中,各特征值的平均重要程度(还是通过出现频次表示)
return total_importances / self.n_estimators
def load_data_primal():
df = pd.read_excel("数据汇总3(数据完整)_决策树用.xlsx")
data_temp = df.iloc[:,3:-1]
label_temp = df["综合评分"]
data = []
label = []
for i in range(df.shape[0]):
data.append(data_temp.iloc[i].to_list())
temp = []
temp.append(label_temp[i])
label.append(temp)
data = np.array(data)
label = np.array(label)
return data,label
if __name__ == '__main__':
# 生成示例数据集
X, y = load_data_primal()
# print(X)
# print(y)
# 构建随机森林模型
rf = RandomForestRegressor(n_estimators=100, max_depth=10, max_features=10)
rf.fit(X, y)
# for one_tree in rf.trees:
# one_tree.show(one_tree.bootnode)
# 获取特征重要性
importances = rf.feature_importances(X, y)
# 先使用argsort进行降序排序,再进行反转
indices = np.argsort(importances)[::-1]
# 打印特征重要性
print("Feature ranking:")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# 可视化特征重要性
plt.figure()
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices], color="r", align="center")
plt.xticks(range(X.shape[1]), indices)
plt.xlim([-1, X.shape[1]])
plt.show()


![[Linux][多线程][一][线程基础概念][进程VS线程][线程控制]详细讲解](https://img-blog.csdnimg.cn/direct/e672947b349f47d8924596100d777522.png)