论文(COMPUT METH PROG BIO):OCT2Former: A retinal OCT-angiography vessel segmentation transformer
源码:https://github.com/coreeey/OCT2Former
一、摘要
背景与目的:视网膜血管分割在视网膜疾病自动筛查与诊断中起着重要作用。如何分割出薄血管并保持血管的连通性是视网膜血管分割任务的关键挑战。光学相干断层血管造影(OCTA)是一种无创成像技术,可以显示高分辨率的视网膜血管。为了充分利用OCTA图像高分辨率的特点,提出了一种新的基于transformer的端到端视网膜血管分割网络OCT-2 transformer (OCT-a transformer)。
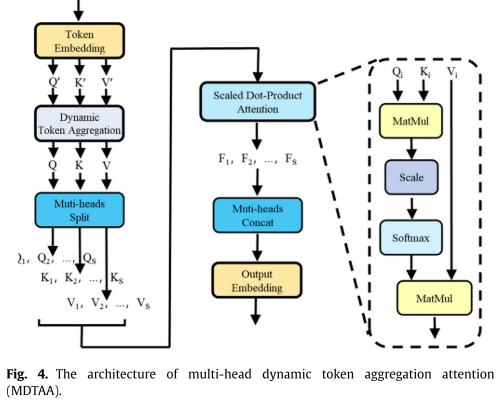
方法:OCT2Former基于编码器-解码器结构,主要包括 动态transformer编码器 和 轻量级解码器。动态transformer编码器 由动态token聚合transformer和辅助卷积分支组成,其中设计了基于多头动态token聚合注意力的 动态token聚合transformer,以在整个网络中捕获来自第一层的全局视网膜血管上下文信息,并提出 辅助卷积分支 来弥补transformer的归纳偏差不足,辅助特征提取。提出一种基于卷积的 轻量级解码器,有效解码特征,降低OCT2解码器的复杂度。
结果:提出的OCT2Former在三个公开的数据集上进行了验证,即OCTA-SS, ROSE-1, OCTA-500(子集OCTA-6M和OCTA-3M)。提出的OCT 2前网络在这些数据集上的Jaccard指标分别为0.8344、0.7855、0.8099和0.8513,分别优于基于卷积的最佳网络1.43、1.32、0.75和1.46%。
结论:实验结果表明,提出的OCT 2 Former可以在视网膜OCTA血管分割任务上取得有竞争力的性能。
Q:什么是多头动态token聚合注意力?
A:
二、引言
结构:OCTA的简介和问题阐述 —> 方向1:在眼底图像中视网膜血管的分割上(前人工作) —> 方向2:OCTA 图像中视网膜血管的分割(前人工作) —> 引出论点:CNN 的接受域低且有限是其缺点之一,而这对语义分割至关重要 —> 引出Transformer —> 总结设计动机 —> 贡献
三、方法

3.1 网络结构
先概括架构结构 —> 编码器组成 —> 解码器组成 —> 框架流程。
OCT2Former的架构:它是基于跳连接的u型编码器-解码器结构。
编码器路径:由 动态transformer编码器 和 组嵌入模块 组成。提出的 动态transformer编码器 由动态token聚合Transformer和辅助卷积分支组成。
解码器路径:两个基于卷积的轻量级解码器和一个1×1卷积构成解码路径。
框架流程:当OCTA图像被馈送到所提出的OCT 2 Former中时,首先将由两个3×3卷积组成的 卷积干模块 应用于原始OCTA图像,以获得 主要特征图 ,并在不改变分辨率的情况下增加通道数量。然后,将这些特征输入到三个连续的 动态变压器编码器 中,逐级获得具有 丰富全局信息的语义token。为了捕获 多尺度信息 并弥补动态Transformer编码器的位置信息损失,将来自前两个动态Transformer编码器的语义token分别送入 组嵌入模块 。在解码器路径中,来自动态Transformer编码器的多尺度语义token被馈送到 轻量级解码器 以 恢复原始分辨率 。在解码器路径的末端,应用1×1卷积以获得最终的分割图。(输入 + 模块(数量,位置) + 处理后得到的特征结果)
Q:多尺度信息和组嵌入模块的关联?
A:
3.2 动态transformer编码器

3.2.1 Vision transformer(自注意力和多头注意力)
给出ViT的定义 —> 自注意力的定义 —> 多头注意力的定义
ViT:vision transformer(ViT)由一叠自注意力层(self-attention, SA)和一个前馈网络组成,其主要思想是以 sequence-to-sequence 的方式处理图像,并在每个序列之间采取自注意机制。
自注意力:本质上由查询和所有键的 点积 以及通过softmax算子获得的 规范化注意力分数 组成。通过SA层,entity(元素)成为序列中所有entity的加权和,其中权重由归一化的注意力得分确定。不同输入嵌入之间的SA层函数可计算如下:

其中,K、Q、V分别是key、query和value的投影。 是key投影K的维度,并且
提供归一化以使梯度更稳定。
多头注意力:为了封装序列中不同位置之间的多重复杂关系,在变压器中采用由多个自注意块组成的多头自注意(MHSA)。与单头自注意不同,MHSA旨在学习不同表征子空间中序列到序列的信息。MHSA将输入分成M个头(头1,…头i,…,头M),并行计算每个头像的自关注,并将它们连接起来得到最终的输出。MHSA的公式为:

其中,,
,
(i = 1,2,...,M)和
是可独立学习的权重矩阵。
3.2.2 动态token聚合Transformer
问题1:虽然变压器具有全局接受场捕获能力的优势,但昂贵的计算限制了其在语义分割任务中的应用。
问题2:以前的一些工作采用4倍甚至8倍的降采样操作来减少变压器的计算,这在视网膜血管分割任务中很难采用,因为高比例的降采样操作会使薄血管消失。如何设计一种变压器来克服巨大的计算复杂度和分辨率变化问题是视网膜血管分割的关键。
问题3:在vision transformer中,标记通常包含大量冗余信息,只有最具信息量的标记子集有助于最终预测。
解决方法(工作):受基于深度学习的超像素采样的启发,我们提出了一种新的方法,称为多头动态token聚合注意力(MDTAA),该方法试图动态聚合嵌入中的相关token并去除冗余信息。
思想:创建一个新的、浓缩的令牌嵌入,命名为聚合嵌入 (k << N,k设为128),它可以有效地聚合原始嵌入中的重要信息,减少冗余信息。
MDTAA组成:
1)动态token聚合:
- 初始聚合:首先将嵌入T的输入token输入到初始化单元中,生成初始聚合嵌入
,该嵌入通过自适应平均池化层初始聚合像素位置相邻的token(使用自适应平均池用于聚合特征)。
![]()
- 采用余弦距离进一步聚合:在高维语义空间中,符号在像素位置上的接近性不一定能反映出来。因此,
来度量
与
在高维向量空间中的相似度,其值越高表示相似度越低,反之亦然。对于嵌入维数D中的每个(i, j)候选表示对
 和
和 ,它们之间的余弦距离可表示为:
,它们之间的余弦距离可表示为:

余弦距离矩阵:
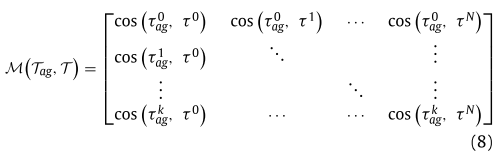
在 上使用一个softargmax(argmax的光滑版本)函数(softmax + argmax),得到一个软分配映射
,它是可微的,能更好地反映
和
之间的相关性。
![]()
因此,每个聚合令牌可以被视为原始token嵌入的加权总和或聚合,其中信息令牌具有较大的权重,反之亦然。利用优化的 ,最终聚合嵌入
可以表示为:
![]()
由于聚合嵌入与原始嵌入之间的初始距离是随机的,因此单次聚合获得的令牌相对粗糙。为了更好地进行优化 ,设计了一种迭代优化算法动态token聚合(dynamic token aggregation, DTA)(轮询优化,因此称之为动态)

2) 多头动态token聚合注意(MDTAA):
综上所诉,动态token聚合注意力公式(套用自注意力公式)如下:

多头动态token聚合注意(MDTAA) (套用多头注意力公式) 如下:

DTA代码如下:
class DTA(nn.Module):
def __init__(self, k=130, stage_num=3):
super(DTA, self).__init__()
self.pool = nn.AdaptiveMaxPool1d(k)
self.stage_num = stage_num
def forward(self, x1, x2):
k = self.pool(x1)
k = self._l2norm(k, dim=1)
q = self.pool(x2)
q = self._l2norm(q, dim=1)
x1 = rearrange(x1, 'b n c -> b c n')
x2 = rearrange(x2, 'b n c -> b c n')
# with torch.no_grad():
for i in range(self.stage_num):
z1 = torch.bmm(x1, k)
z1 = F.softmax(z1, dim=2)
z1_ = self._l2norm(z1, dim=1)
x1_ = x1.permute(0, 2, 1)
k = torch.bmm(x1_, z1_)
k = self._l2norm(k, dim=1)
z2 = torch.bmm(x2, q)
z2 = F.softmax(z2, dim=2)
z2_ = self._l2norm(z2, dim=1)
x2_ = x2.permute(0, 2, 1)
q = torch.bmm(x2_, z2_)
q = self._l2norm(q, dim=1)
return k, q
def _l2norm(self, inp, dim):
return inp / (1e-6 + inp.norm(dim=dim, keepdim=True))3.2.3 辅助卷积分支


动机:由于transformer中缺少感应偏置,所提出的基于动态token聚合transformer的模型存在收敛速度慢的问题,这是transformer中典型的挑战。为了克服这个问题,设计了一个辅助卷积分支(ACB)来补充transformer的感应偏置。(增加一个感应偏置,使损失波动更小,收敛更快)
结构: ACB由两个级联的群卷积块(GCB)组成,每个GCB由一个3×3群卷积、一个批归一化和一个ReLU激活组成。
3.3 组嵌入模块
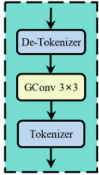
动机:为了获得多尺度特征,并补偿特征token化后的位置信息丢失。
结构:该模块由一个解token转换器、一个3 × 3组卷积和一个token转换器组成。
3.4 轻量级的解码器
结构:由一个轻量级卷积单元(一个 3 ×3 卷积、 一个批处理归一化和一个ReLU激活)和一个双线性上采样单元组成。
3.5 损失函数
二进制交叉熵损失(BCE):
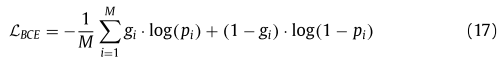
其中, ∈ {0,1}指示地面实况,
∈ [0,1]是对应的预测值,并且 M 是像素的数量。
四、实验
4.1 实验配置
数据集 —> 实现细节
数据集:OCTA-SS、ROSE-1 和 OCTA-500(子集OCTA-6M和OCTA-3M)。
实现细节:在pytorch平台上,使用24GB内存的NVIDIA RTX3090 GPU实现了OCT2Former。为了公平起见,OCT2former和其他网络都以100个epoch和2的批处理大小进行训练。Adaptive moment estimation (Adam)优化,动量为0.9,权重衰减为0.001,ploy学习率![]() 功率为0.9。随机左右翻转、自顶向下翻转和- 10°~ 10°旋转用于数据增强。
功率为0.9。随机左右翻转、自顶向下翻转和- 10°~ 10°旋转用于数据增强。
4.2 评估指标

五、实验


5.1 对比试验
定量分析:表1-4分别展示了不同分割网络在三个公开OCTA数据集上的分割结果,其中混合transformer网络包括提出的OCT2Former和UTNet,在Jaccard指数上优于大多数基于卷积的网络和纯transformer的网络,表明transformer可以应用于OCTA图像中的视网膜血管分割。所提出的网络在几乎所有评估指标上都优于其他竞争方法,特别是在Jaccard, Dice, CAL和LCC指标上。
定性分析:U-Net 作为医学图像分割中功能强大的基于卷 积的网络,在粗血管分割上表现良好,而在大多数细血管分割 上表现不佳。与 U-Net 相比,CS-Net 的分割效果更好,但分割血管的连通性较差。配备规模感知特征聚合(SFA)模块、自适应 特征融合(AFF)模块和多层次语义监督(MSS)模块的 SCS-Net 在 这三个数据集上都表现良好。但其对边界模糊的细血管的分割 性能有待提高,这可能是由于解码过程中接收野的减少所致。(分割效果 + 造成原因分析)
5.2 消融实验(损失曲线 + 评估指标对比分析)


六、总结
1. 本文提出了一种基于端到端混合变压器的视网膜血管分割网络,OCT2Former。
2. 提出了一种动态令牌聚合变压器来降低原始变压器的巨大计算成本,并设计了一个辅助卷积分支来加快原始变压器的收敛速度。
3.在 OCTASS、ROSE-1、OCTA-500(子集 OCTA-6M 和子集 OCTA-3M)数据集上对所提出的 OCT2Former 进行了评估,结果表明所提出的 OCT2Former 优于其他最先进的网络。