一、简述
本文对 ConcurrentHashMap#put() 源码进行分析。
二、源码概览
public V put(K key, V value) {
return putVal(key, value, false);
}
上面是 ConcurrentHashMap#put() 的源码,我们可以看出其核心逻辑在 putVal() 方法中。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
上面是 ConcurrentHashMap#putVal() 的源码,有兴趣的小伙伴可以先试着读一下。
三、核心流程分析
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 检查 key 和 value 是否为 null,如果是则抛出 NullPointerException 异常
if (key == null || value == null) throw new NullPointerException();
// 调用 spread 方法将 key 的哈希码进行扩散,得到一个散列值 hash
int hash = spread(key.hashCode());
int binCount = 0;
// 开启循环
for (Node<K,V>[] tab = table;;) {
// 定义一些变量
Node<K,V> f; int n, i, fh; K fk; V fv;
// 检查当前的哈希表(tab)是否为空或长度为 0
if (tab == null || (n = tab.length) == 0)
// 调用 initTable() 方法初始化哈希表
tab = initTable();
// 如果当前槽位(f = tabAt(tab, i = (n - 1) & hash))为空
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 使用 CAS 操作尝试在该槽位上添加新的节点
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
// 成功则跳出循环
break; // no lock when adding to empty bin
}
// 如果当前槽位的哈希值为 MOVED
else if ((fh = f.hash) == MOVED)
// 帮助其进行哈希表的转移操作
tab = helpTransfer(tab, f);
// 如果 onlyIfAbsent 为 true,并且当前槽位的键与要添加的键相同
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
// 直接返回当前槽位的值
return fv;
else {
V oldVal = null;
// 对当前槽位的节点进行加锁
synchronized (f) {
// 暂时省略 synchronized 中的内容
}
// 检查 binCount 是否不为 0
if (binCount != 0) {
// 如果 binCount 的值大于或等于 TREEIFY_THRESHOLD(默认值为8)
if (binCount >= TREEIFY_THRESHOLD)
// 将当前的链表结构转化为红黑树结构
treeifyBin(tab, i);
// 如果 oldVal 不为 null
if (oldVal != null)
// 直接返回 oldVal
return oldVal;
// 跳出循环
break;
}
}
}
// 调用 addCount 方法增加元素的数量
addCount(1L, binCount);
return null;
}
从上面的源码中可以分析出,ConcurrentHashMap#putVal() 的核心逻辑为:
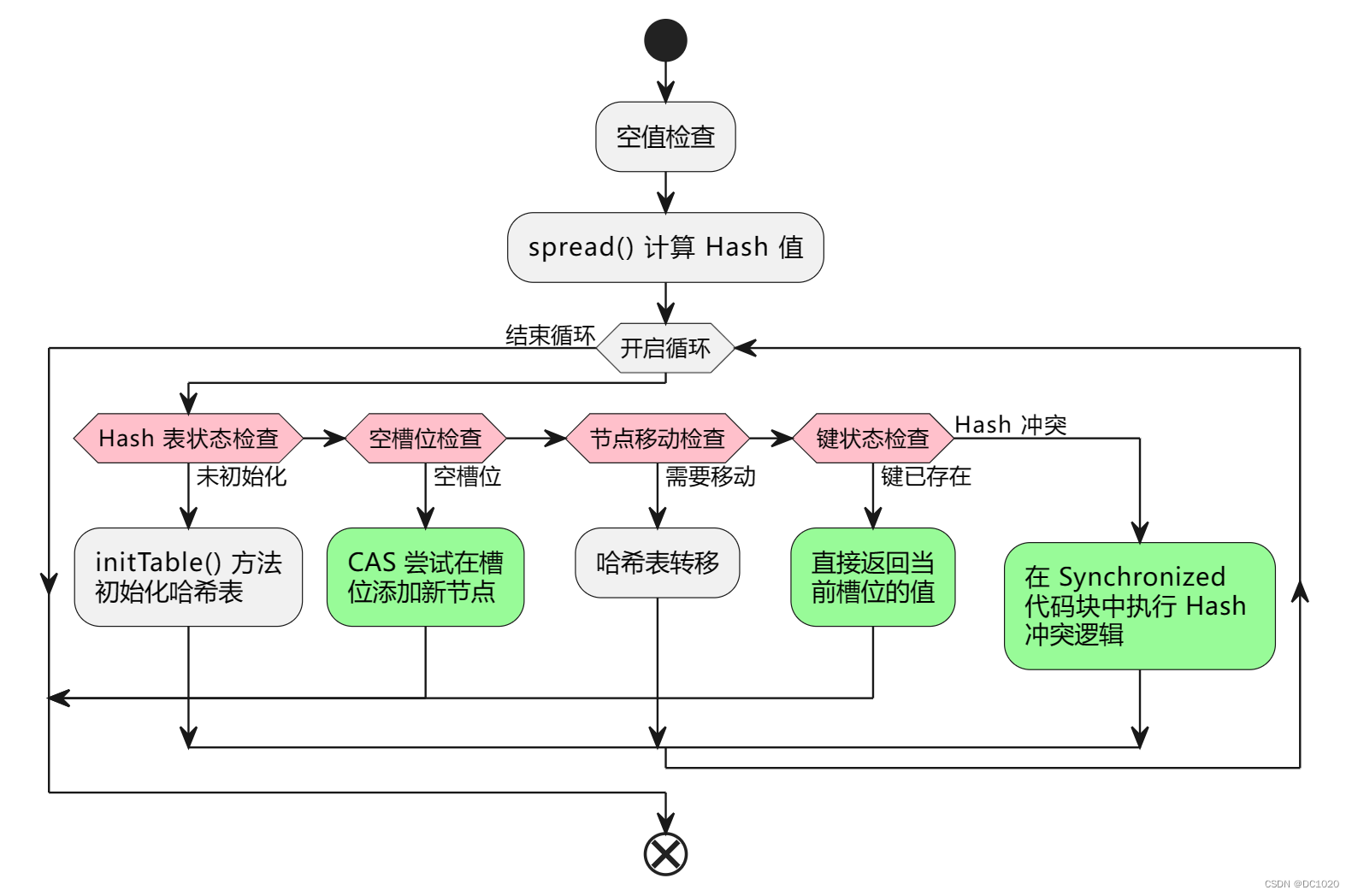
- 首先进行空值检查,如果键或值为 null,那么抛出
NullPointerException - 使用
spread()方法,计算 Hash 值 - 开启循环,首先检测 Hash 表的状态是否已完成初始化
- 未完成初始化,使用
initTable()方法完成初始化 - 若 Hash 表已完成初始化,则检查需要插入的槽位是否为空
- 若槽位为空,则采用 CAS 插入新节点,新节点插入成功退出循环
- 若槽位不为空,判断插入槽位是否需要移动
- 若需要移动,使用
helpTransfer()方法实现槽位转移(扩容) - 若不需要移动,则检查当前槽位的键是否与插入的键相同
- 若键相同,直接返回当前槽位的值,退出循环
- 若键不同,发生 Hash 冲突,进入
synchronized代码块执行解决 Hash 冲突的逻辑
四、Hash 冲突流程分析
// 之前 synchronized 省略的内容
// 对哈希桶的节点加锁
synchronized (f) {
// 检查当前的槽位是否改变
if (tabAt(tab, i) == f) {
// 如果当前节点是链表节点
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果找到了与添加的键相同的节点
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
// 更新该节点的值
e.val = value;
break;
}
Node<K,V> pred = e;
// 如果找到链表末尾依旧没有找到
if ((e = e.next) == null) {
// 添加一个新的节点
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
// 如果当前节点是红黑树节点
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 调用 putTreeVal() 方法
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
// 如果键已存在则更新旧值
p.val = value;
}
}
// 如果当前节点是 ReservationNode
else if (f instanceof ReservationNode)
// 抛出 IllegalStateException 异常
throw new IllegalStateException("Recursive update");
}
}
上面是 ConcurrentHashMap#putVal() 方法中发生 Hash 冲突时的源码。
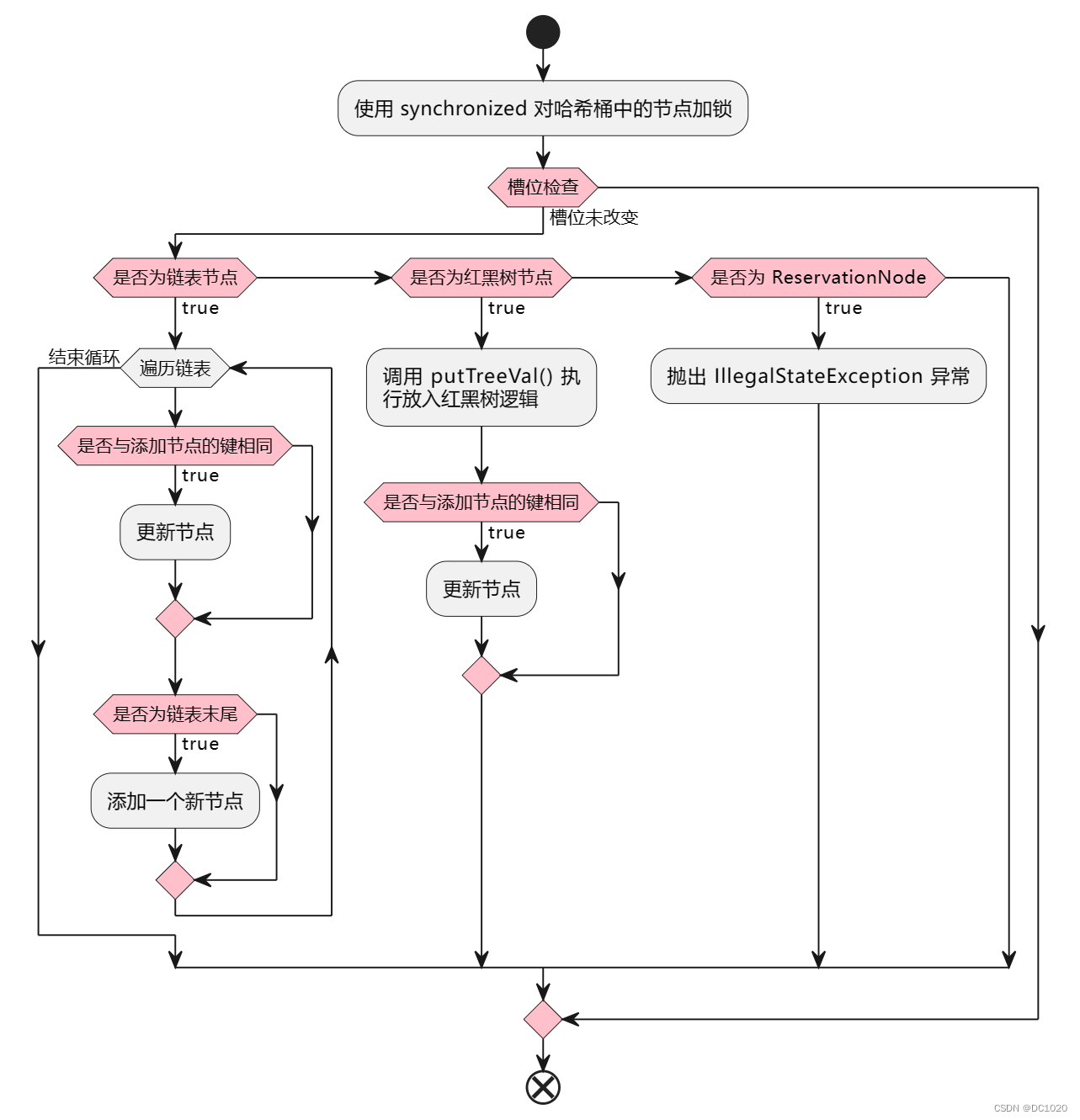
- 首先,将 Hash 桶中的节点加
synchronized锁 - 判断槽位是否改变
- 槽位未改变,检查是否为链表节点
- 若是链表节点,则遍历链表,键已存在则更新值,键不存在则新增节点
- 若是红黑树节点,则调用红黑树的
putTreeVal()方法,键已存在则更新值,键不存在则新增节点 - 若是
ReservationNode则抛出IllegalStateException异常
五、FAQ
5.1 helpTransfer() 方法是什么
helpTransfer() 方法的主要工作是检查是否满足扩容条件,如果满足,则协助进行扩容操作。具体来说,它会检查当前的哈希表是否正在进行扩容操作,如果是,则帮助完成扩容;如果不是,则直接返回当前的哈希表。
5.2 Hash 冲突源码中为什么需要判断槽位是否改变
if (tabAt(tab, i) == f) 的目的是为了检查在进入同步块之后,当前槽位的节点是否发生了变化。
在多线程环境下,当一个线程获取到锁并进入同步块时,其他线程可能已经修改了哈希表的状态。因此,在进行节点操作之前,需要再次检查当前槽位的节点是否与预期的节点相同。
如果当前槽位的节点与预期的节点不同,那么说明在这个线程获取锁的过程中,其他线程已经修改了哈希表的状态。在这种情况下,当前线程应该跳过后续的操作,因为它们可能基于错误的状态。
这是一种常见的并发编程技巧,被称为"双重检查锁"(Double-Checked Locking)。它可以确保在多线程环境下的正确性和效率。
5.3 ReservationNode 是什么
在 ConcurrentHashMap 中,ReservationNode 是一个特殊类型的节点,是一个临时的占位符,不应该出现在正常的操作中。如果出现了,那么可能是发生了递归更新。
往期推荐
- IoC 思想简单而深邃
- ThreadLocal
- 终端的颜值担当-WindTerm
- Spring 三级缓存
- RBAC 权限设计(二)




![[Kubernetes] etcd的集群基石作用](https://img-blog.csdnimg.cn/direct/7b4e2099576e408a81cfffbf8384be77.webp)


![[Spring Cloud] (4)搭建Vue2与网关、微服务通信并配置跨域](https://img-blog.csdnimg.cn/img_convert/0089662f313198fb47a2fa99884e6678.png)