兄弟姐们·,大家好哇!我是喔的嘛呀。今天我们一起来学习requests案列。
一、requests____cookie登录古诗文网
1、首先想要模拟登录,就必须要获取登录表单数据
登录完之后点f12,然后点击network,最上面那个就是登录接口,登录表单数据就在里面

点登录接口,然后在点击payload可以看到有一个form data,里面的数据就是登录表单数据,爬虫模拟登陆就是构造表单数据实现登录。一定要合法合规。(因为涉及自己的账号密码我就不点开了)
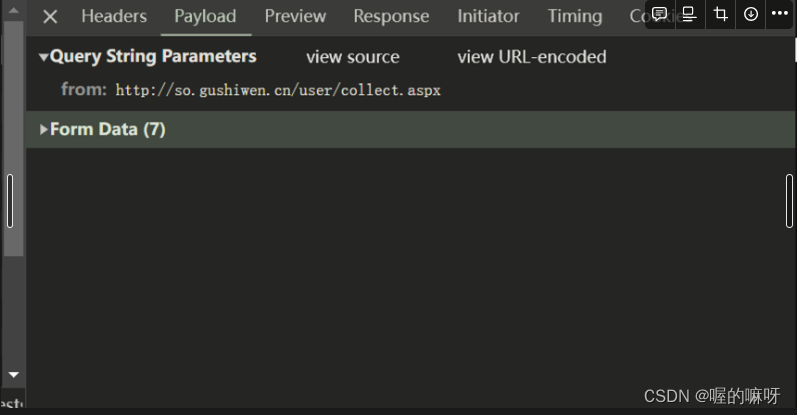
里面的数据就是这些
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': '<http://so.gushiwen.cn/user/collect.aspx>',
'email': 'your_email@example.com',
'pwd': 'your_password',
'code': code_name,
'denglu': '登录',
很多小伙伴不知道'__VIEWSTATE'、'__VIEWSTATEGENERATOR'这两个参数是什么意思,给大家说一哈。
在很多Web页面中,特别是使用ASP.NET开发的页面中,会使用隐藏域(hidden input)来存储一些页面状态或者其他信息,这些信息对于页面的正常操作很重要,但用户是看不到的。
在这个例子中,**__VIEWSTATE和__VIEWSTATEGENERATOR**是两个隐藏域,它们存储了关于页面状态的信息,而且在每次请求页面时都会动态生成和改变。所以,在登录的时候,我们需要获取这两个隐藏域的值,并将它们包含在POST请求的数据中,以确保我们的请求是有效的。
2、第二个主要的地方时我们登录时候需要输入验证码,我们需要拿到正确的验证码地址并把验证码图片爬取下来
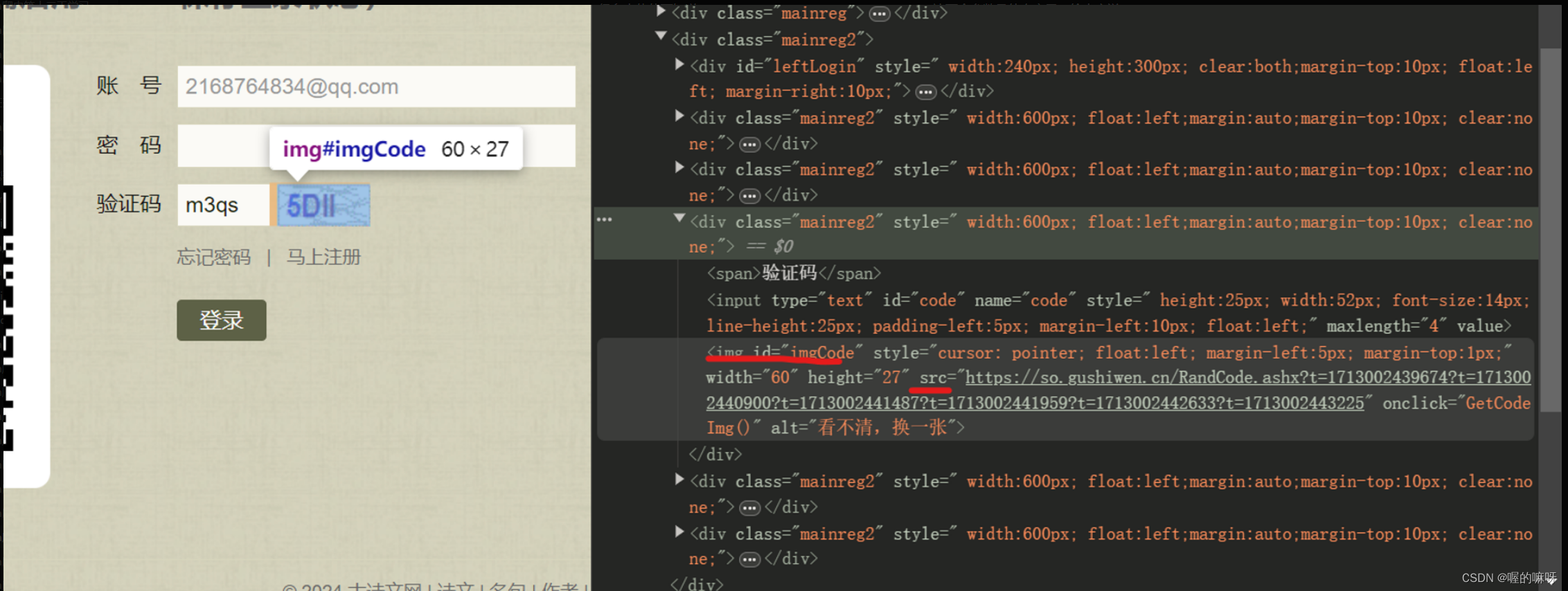
img 的id为imgCode 然后我们就可以使用BeautifulSoup解析
3、根据分析写出代码
(1)导入**requests和BeautifulSoup**库。
import requests
from bs4 import BeautifulSoup
(2)定义登录页面的URL和请求头部信息,模拟浏览器请求。
pythonCopy code
login_url = '<https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx>'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
(3)创建会话对象**session**,用于保持会话状态。
session = requests.session()
(4)发送GET请求获取登录页面的HTML源码,将响应内容保存在**content**变量中。
response = session.get(url=login_url, headers=headers)
content = response.text
(5)使用BeautifulSoup解析HTML源码,获取隐藏域**__VIEWSTATE和__VIEWSTATEGENERATOR**的值,以及验证码图片的URL。
soup = BeautifulSoup(content, 'lxml')
viewstate = soup.select_one('#__VIEWSTATE')['value']
viewstategenerator = soup.select_one('#__VIEWSTATEGENERATOR')['value']
code_url = '<https://so.gushiwen.cn>' + soup.select_one('#imgCode')['src']
(6)拼接验证码图片的完整URL,并发送GET请求获取验证码图片的内容,将内容保存到本地文件**code.jpg**中。
response_code = session.get(code_url)
with open('code.jpg', 'wb') as fp:
fp.write(response_code.content)
(7)用户手动输入验证码。
code_name = input('请输入验证码: ')
(8)构造登录表单数据,包括**__VIEWSTATE、__VIEWSTATEGENERATOR、from、email、pwd、code和denglu**字段。
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': '<http://so.gushiwen.cn/user/collect.aspx>',
'email': 'your_email@example.com',
'pwd': 'your_password',
'code': code_name,
'denglu': '登录',
}
(9)发送POST请求登录,将响应内容保存在**content_post**变量中。
response_post = session.post(url=login_url, headers=headers, data=data_post)
content_post = response_post.text
(10)将登录后的响应内容保存到本地HTML文件**gushiwen.html**中。
with open('gushiwen.html', 'w', encoding='utf-8') as fp:
fp.write(content_post)
(11)完整代码
import requests
from bs4 import BeautifulSoup
# 登录页面的URL
login_url = '<https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx>'
# 请求头部信息,模拟浏览器请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
}
# 创建会话对象,保持会话状态
session = requests.session()
# 发送GET请求获取登录页面的HTML源码
response = session.get(url=login_url, headers=headers)
content = response.text
# 使用BeautifulSoup解析HTML源码,获取隐藏域__VIEWSTATE和__VIEWSTATEGENERATOR的值,以及验证码图片的URL
soup = BeautifulSoup(content, 'lxml')
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = '<https://so.gushiwen.cn>' + code
# 获取验证码图片,并保存到本地
response_code = session.get(code_url)
content_code = response_code.content
with open('code.jpg', 'wb') as fp:
fp.write(content_code)
# 用户输入验证码
code_name = input('请输入验证码')
# 构造登录表单数据
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': '<http://so.gushiwen.cn/user/collect.aspx>',
'email': 'your_email@example.com',
'pwd': 'your_password',
'code': code_name,
'denglu': '登录',
}
# 发送POST请求登录
response_post = session.post(url=login_url, headers=headers, data=data_post)
content_post = response_post.text
# 将登录后的响应内容保存到本地HTML文件中
with open('gushiwen.html', 'w', encoding='utf-8') as fp:
fp.write(content_post)
这段代码实现了模拟登录古诗文网站的功能,并将登录后的响应保存到本地文件中。请注意,其中的邮箱和密码等敏感信息应当替换为真实的信息,并且在实际使用时,需要遵守网站的相关规定和法律法规。
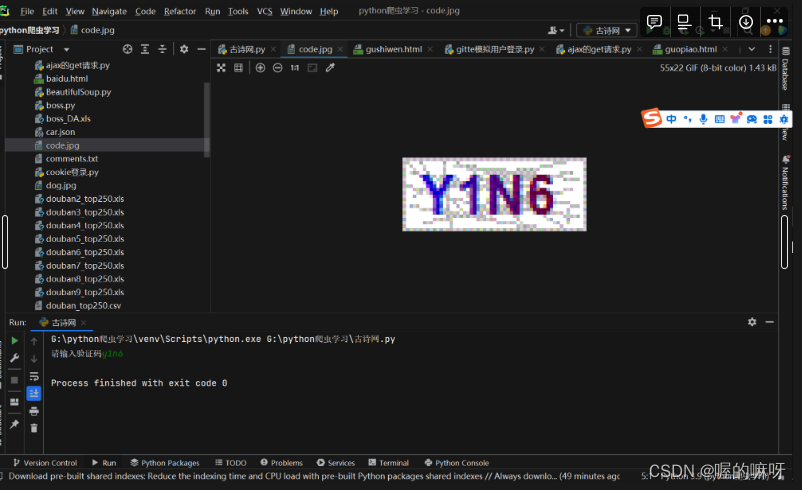
4、结果展示
运行之后找到code.jpg输入验证码
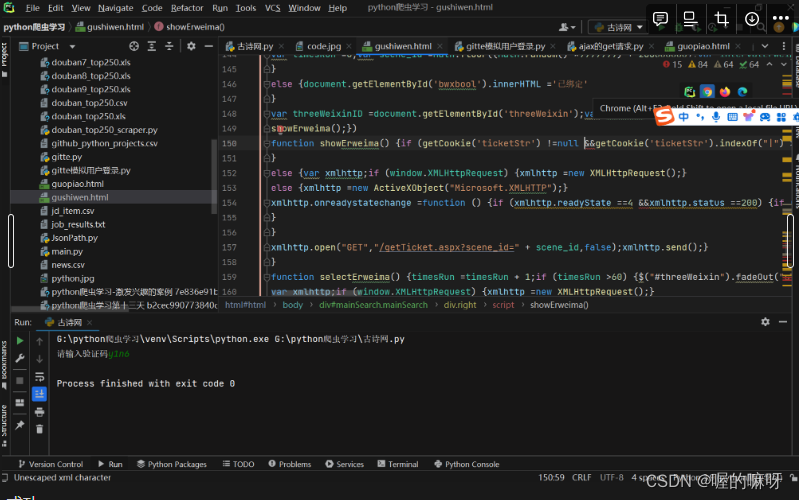
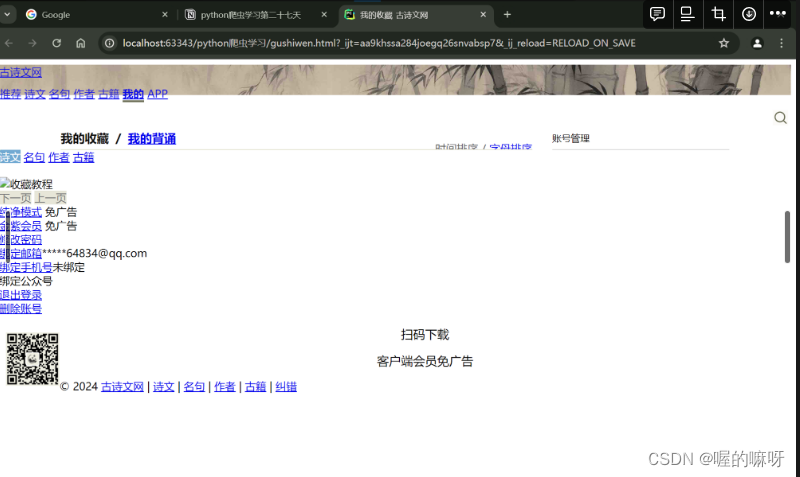
找到爬取下来的gushiwen.html点上面的浏览器标识
成功
失败
好了今天的学习就到这里了,希望兄弟姐妹能够天天开心,拜拜啦!


![[Kubernetes] etcd的集群基石作用](https://img-blog.csdnimg.cn/direct/7b4e2099576e408a81cfffbf8384be77.webp)


![[Spring Cloud] (4)搭建Vue2与网关、微服务通信并配置跨域](https://img-blog.csdnimg.cn/img_convert/0089662f313198fb47a2fa99884e6678.png)