目录
ResNet网络架构
ResNet部分实现代码
ResNet网络架构
论文原址:https://arxiv.org/pdf/1512.03385.pdf
残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的,通过引入残差学习解决了深度网络训练中的退化问题,同时该网络结构特点主要表现为3点,超深的网络结构(超过1000层)、提出residual(残差结构)模块和使用Batch Normalization 加速训练(丢弃dropout)。ResNet网络的模型结构如下:
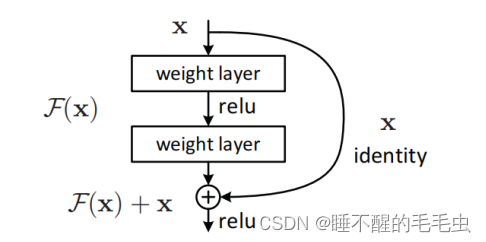
ResNet网络通过“跳跃连接”,将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。即神经网络学习到该层的参数是冗余的时候,它可以选择直接走这条“跳接”曲线(shortcut connection),跳过这个冗余层,而不需要再去拟合参数使得H(x)=F(x)=x。同时通过这种连接方式不仅保护了信息的完整性(避免卷积层堆叠存在的信息丢失),整个网络也只需要学习输入、输出差别的部分,这克服了由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题(梯度消失或梯度爆炸)。
残差模块如下图示:
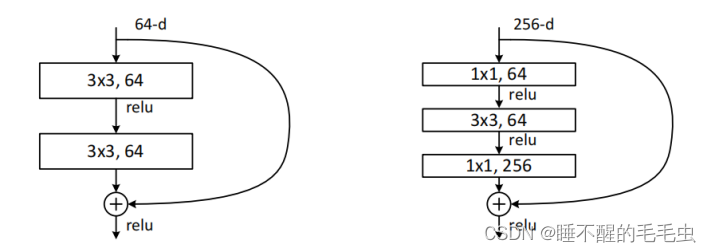
残差结构有两种,常规残差和瓶颈残差。常规残差:由2个3x3卷积层堆叠而成,当输入和输出维度一致时,可以直接将输入加到输出上,这相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度(随着网络深度的加深,这种残差模块在实践中并不十分有效);瓶颈残差:依次由1x1 、3x3 、1x1个卷积层构成,这里1x1卷积,能够对通道数channel起到升维或降维的作用,从而令3x3 的卷积,以相对较低维度的输入进行卷积运算,提高计算效率。
ResNet网络的具体配置信息如下:
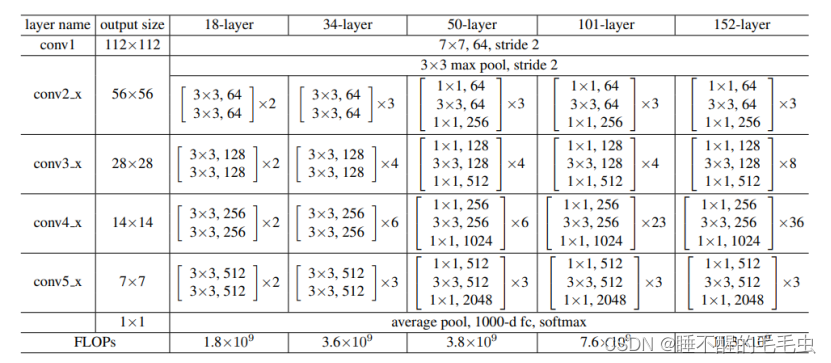
在构建神经网络时,首先采用了步长为2的卷积层进行图像尺寸缩减,即下采样操作,紧接着是多个残差结构,在网络架构的末端,引入了一个全局平均池化层,用于整合特征信息,最后是一个包含1000个类别的全连接层,并在该层后应用了softmax激活函数以进行多分类任务。值得注意的是,通过引入残差连接模块,其最深的网络结构达到了152层,同时在50层后均使用的是瓶颈残差结构。
ResNet部分实现代码
老样子,直接上代码,建议大家阅读代码时结合网络结构理解
import torch
import torch.nn as nn
__all__ = ['resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
class ConvBNReLU(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2d(num_features=out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class ConvBN(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super(ConvBN, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2d(num_features=out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
def conv3x3(in_channels, out_channels, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding:捕捉局部特征和空间相关性,学习更复杂的特征和抽象表示"""
return nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_channels, out_channels, stride=1):
"""1x1 convolution:实现降维或升维,调整通道数和执行通道间的线性变换"""
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.convbnrelu1 = ConvBNReLU(in_channels, out_channels, kernel_size=3, stride=stride)
self.convbn1 = ConvBN(out_channels, out_channels, kernel_size=3)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.conv_down = nn.Sequential(
conv1x1(in_channels, out_channels * self.expansion, self.stride),
nn.BatchNorm2d(out_channels * self.expansion),
)
def forward(self, x):
residual = x
out = self.convbnrelu1(x)
out = self.convbn1(out)
if self.downsample:
residual = self.conv_down(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(Bottleneck, self).__init__()
groups = 1
base_width = 64
dilation = 1
width = int(out_channels * (base_width / 64.)) * groups # wide = out_channels
self.conv1 = conv1x1(in_channels, width) # 降维通道数
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = conv1x1(width, out_channels * self.expansion) # 升维通道数
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.conv_down = nn.Sequential(
conv1x1(in_channels, out_channels * self.expansion, self.stride),
nn.BatchNorm2d(out_channels * self.expansion),
)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample:
residual = self.conv_down(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64):
super(ResNet, self).__init__()
self.inplanes = 64
self.dilation = 1
replace_stride_with_dilation = [False, False, False]
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
downsample = False
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = True
layers = nn.ModuleList()
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return layers
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
for layer in self.layer1:
x = layer(x)
for layer in self.layer2:
x = layer(x)
for layer in self.layer3:
x = layer(x)
for layer in self.layer4:
x = layer(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet18(num_classes, **kwargs):
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes, **kwargs)
def resnet34(num_classes, **kwargs):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, **kwargs)
def resnet50(num_classes, **kwargs):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, **kwargs)
def resnet101(num_classes, **kwargs):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, **kwargs)
def resnet152(num_classes, **kwargs):
return ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes, **kwargs)
if __name__=="__main__":
import torchsummary
device = 'cuda' if torch.cuda.is_available() else 'cpu'
input = torch.ones(2, 3, 224, 224).to(device)
net = resnet50(num_classes=4)
net = net.to(device)
out = net(input)
print(out)
print(out.shape)
torchsummary.summary(net, input_size=(3, 224, 224))
# Total params: 134,285,380希望对大家能够有所帮助呀!
![[Spring Cloud] (4)搭建Vue2与网关、微服务通信并配置跨域](https://img-blog.csdnimg.cn/img_convert/0089662f313198fb47a2fa99884e6678.png)



![【Hadoop】- MapReduce YARN的部署[8]](https://img-blog.csdnimg.cn/direct/2db7663582ac4a1fa825037da60fc7d6.png)

![【Hadoop】- MapReduce YARN 初体验[9]](https://img-blog.csdnimg.cn/direct/f09935e8bade4d16a28d0d5ce9f9e616.png)