欢迎来到白刘的领域 Miracle_86.-CSDN博客
系列专栏 数据结构与算法
先赞后看,已成习惯
创作不易,多多支持!

目录
一、数据结构的概念
二、顺序表(Sequence List)
2.1 线性表的概念以及结构
2.2 顺序表分类
2.2.1 顺序表和数组的区别
2.2.2 顺序表的分类
2.3 顺序表的实现
2.3.1 初始化
2.3.2 销毁
2.3.3 尾插
2.3.4 头插
2.3.5 尾删
2.3.6 头删
2.3.7 在指定位置插入
2.3.8 在指定位置删除
2.3.9 查找
2.4 总代码
2.4.1 SeqList.h
2.4.2 SeqList.c
一、数据结构的概念
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。数据结构反映数据的内部构成,即数据由哪部分构成,以什么方式构成,以及数据之间存在的相互关系。
数据结构可以分为两类:线性数据结构和非线性数据结构。线性数据结构以线性的方式组织数据,例如数组、链表和栈。非线性数据结构是一种通过多个节点之间的关联来组织数据的方式,例如树和图。数据结构的选取和设计对于解决特定问题和提高算法效率非常重要。
我们可以将这个词拆分成“数据”和“结构”两部分。
什么是数据?数据可以是数字、文字、图像等。比如超市购物时的价格、数量,天气预报中的温度、湿度,或是社交媒体上的浏览量、点赞数,都是数据。它们为我们提供信息,帮助我们做出决策,让生活更加便捷。
什么是结构?当我们想要使用大量使用同类型的数据时,通过手动定义大量的独立的变量对于程序来说,可读性非常差,我们可以借助数组这样的数据结构将大量的数据组织在一起,结构也可以理解为组织数据的方式。
比如,想要在世界上找到“喜羊羊”的这只羊很难,但是我告诉你在青青草原找,那就特别好找。青青草原这一块地方就可以看成一个结构,有效地将羊群组织起来。

总结:
1.数据结构可以存储数据。
2.存储的数据能够方便查找。
那为什么我们需要数据结构呢?
在生活中,假如我们开了个餐馆,不借助排队的方式来管理客户,会导致客户就餐感受差、等餐时间长、餐厅营业混乱等情况。同理,程序中如果不对数据进行管理,可能会导致数据丢失、操作数据困难、野指针等情况。
良好的数据结构和算法设计对于确保程序的稳定性和效率至关重要。通过合理地组织和管理数据,我们可以提高程序的性能,减少错误,并为用户提供更好的体验。
我们曾学过最基础的数据结构:数组。
C语言中的百宝箱——数组(1)-CSDN博客
C语言中的百宝箱——数组(2)-CSDN博客
既然我们已经学过数组这种数据结构了,那我们还需要学其它的数据结构嘛?存在即合理,显然数组是有一定的局限性的。
假定数组有10个空间,已经使用了5个,向数组中插入数据的步骤应该是:
1. 求数组的长度(这里是10)。
2. 求数组的有效数据个数(这里是5)。
3. 判断数组是否已满(如果有效数据个数等于数组长度,则数组已满)。
4. 如果数组未满,向下标为有效数据个数的位置插入数据。
注意:在插入数据之前,必须判断数组是否已满。如果数组已满,则不能再继续插入数据,否则可能会导致数据覆盖或程序崩溃等严重问题。
假设数据量非常大,频繁的获取数组有效数据个数确实可能会影响程序执行效率。
所以我们可以得出结论:最基础的数据结构能提供的操作不能满足复杂算法的实现。
二、顺序表(Sequence List)
2.1 线性表的概念以及结构
线性表(linear list)是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表包括顺序表(Sequence List)、链表、栈、队列、字符串等。
线性表在逻辑上是线性结构,也就是说它表现为一条连续的直线。然而,在物理结构上,线性表并不一定是连续的。线性表在物理上存储时,通常以数组和链式结构的形式存在。数组存储方式使得元素在内存中连续排列,便于通过下标快速访问;而链式存储方式则通过指针或引用将元素链接在一起,允许在动态环境中灵活地进行插入和删除操作。
如何来理解逻辑结构和物理结构呢?
简单来说,逻辑结构关注的是数据元素之间的逻辑关系,它描述的是数据应该如何被组织,而不关心数据具体是如何在计算机内存中存放的。例如,我们可以说一个列表是一系列有序的元素,这就是它的逻辑结构。
而物理结构,或者叫存储结构,则关心数据在计算机内存中的具体存放方式。比如,这个列表是用数组的形式连续存储在内存中,还是用链表的形式分散存储在内存中,这就是物理结构所关心的问题。
2.2 顺序表分类
2.2.1 顺序表和数组的区别
其实顺序表的底层逻辑是数组,对数组进行了封装,并且实现了常用的增删查改等接口。
2.2.2 顺序表的分类
顺序表分为静态顺序表和动态顺序表,顾名思义,一个静态动不了,一个动态可调节。
• 静态顺序表:
刚刚我们说了,顺序表是基于数组实现的,那静态顺序表就是基于定长数组实现的。
//静态顺序表
typedef int SLDataType;
#define N 7
typedef struct SeqList{
SLDataType a[N];
int size;
}SL;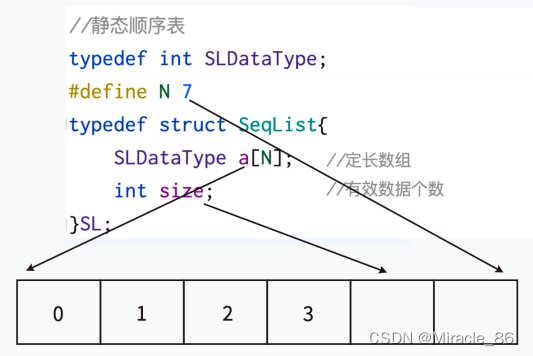
• 动态顺序表:
动态一词,我们不由得想起之前提到的动态内存管理,没错动态顺序表确实是需要动态申请的。
内存地产风云录:malloc、free、calloc、realloc演绎动态内存世界的楼盘开发与交易大戏-CSDN博客
// 动态顺序表 -- 按需申请
typedef struct SeqList
{
SLDataType* a;
int size; // 有效数据个数
int capacity; // 空间容量
}SL; 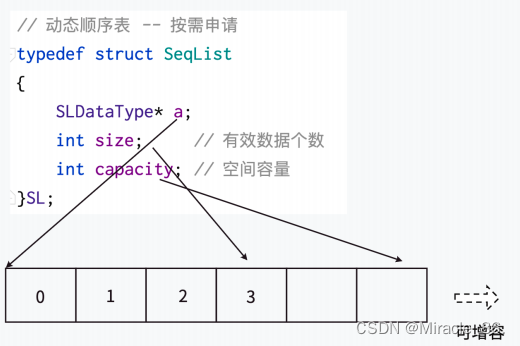
2.3 顺序表的实现
还记得扫雷嘛各位,当时我们创建了三个文件,分别是:game.c,game.h和test.c。game.c用来存放函数的实现,game.h用来存放头文件以及宏,而test.c用来测试。写完函数进行测试,这是一个良好的习惯,今天我们实现顺序表也会这样操作,但这里不介绍test.c文件,着重讲解函数的实现。
首先,我们需要定义一个动态顺序表,我们将定义放在头文件中。
//定义顺序表中的数据类型,可以随时修改int
typedef int SLDataType;
//动态
typedef struct SeqList
{
SLDataType *arr;
int size; //有效数据个数
int capacity; //空间大小
}SL;2.3.1 初始化
接下来我们需要对这个顺序表进行初始化(initialize)。
这个函数没什么好解释的,只需要将顺序表的成员,指针指向NULL,数变成0。唯一一点重要的是:我们传参的时候,需要传顺序表的地址。
要区别传值和传址,我们在这篇文章中解释过:
灵魂指针,教给(一)-CSDN博客
实参传递给形参的时候,形参会单独创建⼀份临时空间来接收实参,对形参的修改不影响实参。如果我们想修改顺序表里的值,那必然得传它的地址。代码如下:
//初始化,注意传址
void SLInit(SL* ps)
{
ps->arr = NULL;
ps->capacity = ps->size = 0;
}2.3.2 销毁
这个函数也很简单,我们既然是动态申请的空间,就需要将其free掉。
函数实现:
//销毁
void SLDestroy(SL* ps)
{
if (ps->arr)
{
free(ps->arr);
}
ps->arr = NULL;
ps->capacity = ps->size = 0;
}
2.3.3 尾插
我们在尾插的时候,试想一下,如果空间不够,是不是就没位置插了,这个时候我们要重新开辟空间,并且,我们在初始化后,空间是0,肯定需要申请。所以这里我们需要一个函数来进行扩容:
//扩容
void SLCheckCapacity(SL* ps)
{
assert(ps);
//先判断空间是否足够,不够需要扩容
if (ps->capacity == ps->size) //不够扩容
{
//申请空间
//三目判断初始空间大小
int NewCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SLDataType* tmp = (SLDataType*)realloc(ps->arr, NewCapacity * sizeof(SLDataType));
if (tmp == NULL)
{
perror("realloc fail");
exit(1);
}
ps->arr = tmp;
ps->capacity = NewCapacity;
}
}首先我们用assert断言防止空指针,之后我们用到了if语句来判断空间是否足够,如果不够则进入if扩容。判断条件我们仔细想想,什么情况是空间不够,是不是当空间大小和有效数据个数相等时,就没法插入了,所以我们将这个作为判断条件。
扩容搞定后,我们就可以进行插入操作了,在尾插中,我们需要传入两个参数:一个是顺序表的地址,另一个是要插入的元素。
尾插其实很简单,我们只需要将最后的位置赋值为要插入的元素就可以了,最后别忘了既然插进去了一个元素,有效数据个数肯定要++。
//尾插
void SLPushBack(SL* ps, SLDataType x)
{
SLCheckCapacity(ps);
//足够尾插
ps->arr[ps->size++] = x;
/*ps->arr[ps->size] = x;
ps->size++;*/
}2.3.4 头插
尾插我们直接在尾巴后面插入元素即可,头插意味着我们要在头部插入一个元素,那么我们就需要在头部为其留出位置,同时原有元素还不可以改变。有了位置再进行插入,思路清晰,直接上代码。
//头插
void SLPushFront(SL* ps, SLDataType x)
{
SLCheckCapacity(ps);
//整体挪动,再插入
for (int i = ps->size; i > 0; i--)
{
ps->arr[i] = ps->arr[i - 1];
}
ps->arr[0] = x;
ps->size++;
}这里注意,for循环遍历时,从后往前遍历,防止覆盖。
2.3.5 尾删
大家想想,怎么删,将最后一个元素置为-1?还是别的什么数字?其实我们根本不需要管最后一个元素,我们直接将size进行 - - 即可。因为不影响其它功能,所以我们不用考虑那么复杂。
//尾删
void SLPopBack(SL* ps)
{
assert(ps);
assert(ps->size);
//删完数据,size--
//ps->arr[ps->size - 1] = -1;要不要这行都可以
ps->size--;
}2.3.6 头删
头删也很简单,直接覆盖即可。
//头删
void SLPopFront(SL* ps)
{
assert(ps);
assert(ps->size);
//直接覆盖即可
for (int i = 1; i < ps->size; i++)
{
ps->arr[i - 1] = ps->arr[i];
}
ps->size--;
}2.3.7 在指定位置插入
我们效仿头插遍历,为元素留位置,在指定位置插入也是如此。
//在指定位置插入
void SLInsert(SL* ps, int pos, SLDataType x)//注意pos是下标
{
assert(ps);
assert(pos >= 0 && pos <= ps->size);
SLCheckCapacity(ps);
for (int i = ps->size; i > pos; i--)
{
ps->arr[i] = ps->arr[i - 1];//arr[pos+1]=arr[pos];
}
ps->arr[pos] = x;
ps->size++;
}2.3.8 在指定位置删除
同样是遍历,同样是覆盖,不多解释,直接上代码。
//在指定位置删除
void SLErase(SL* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
for (int i = pos; i < ps->size - 1; i++)
{
ps->arr[i] = ps->arr[i + 1];//arr[size-2]=arr[size-1]
}
ps->size--;
}2.3.9 查找
其实查找也是遍历,我们可以发现,但凡我们弄清原理之后,顺序表还是蛮简单的。
//查找
int SLFind(SL* ps, SLDataType x)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
if (ps->arr[i] == x)
{
return i;
}
}
return -1;
}2.4 总代码
2.4.1 SeqList.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//定义顺序表的结构
//#define N 100
//静态顺序表
//struct SeqList
//{
// int arr[N];
// int size;//有效数据个数
//};
//定义顺序表中的数据类型,可以随时修改int
typedef int SLDataType;
//动态
typedef struct SeqList
{
SLDataType *arr;
int size; //有效数据个数
int capacity; //空间大小
}SL;
//typedef struct SeqList SL;
//初始化
void SLInit(SL* ps);
//销毁
void SLDestroy(SL* ps);
//打印
void SLPrint(SL* ps);
//扩容
void SLCheckCapacity(SL* ps);
//尾部插入删除 / 头部插入删除
void SLPushBack(SL* ps, SLDataType x);
void SLPushFront(SL* ps, SLDataType x);
void SLPopBack(SL* ps);
void SLPopFront(SL* ps);
//指定位置之前插入/删除数据
void SLInsert(SL* ps, int pos, SLDataType x);
void SLErase(SL* ps, int pos);
//查找
int SLFind(SL* ps, SLDataType x);2.4.2 SeqList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"SeqList.h"
//初始化,注意传址
void SLInit(SL* ps)
{
ps->arr = NULL;
ps->capacity = ps->size = 0;
}
//销毁
void SLDestroy(SL* ps)
{
if (ps->arr)
{
free(ps->arr);
}
ps->arr = NULL;
ps->capacity = ps->size = 0;
}
//打印
void SLPrint(SL* ps)
{
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->arr[i]);
}
printf("\n");
}
//扩容
void SLCheckCapacity(SL* ps)
{
assert(ps);
//先判断空间是否足够,不够需要扩容
if (ps->capacity == ps->size) //不够扩容
{
//申请空间
//三目判断初始空间大小
int NewCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SLDataType* tmp = (SLDataType*)realloc(ps->arr, NewCapacity * sizeof(SLDataType));
if (tmp == NULL)
{
perror("realloc fail");
exit(1);
}
ps->arr = tmp;
ps->capacity = NewCapacity;
}
}
//尾插
void SLPushBack(SL* ps, SLDataType x)
{
SLCheckCapacity(ps);
//足够尾插
ps->arr[ps->size++] = x;
/*ps->arr[ps->size] = x;
ps->size++;*/
}
//头插
void SLPushFront(SL* ps, SLDataType x)
{
SLCheckCapacity(ps);
//整体挪动,再插入
for (int i = ps->size; i > 0; i--)
{
ps->arr[i] = ps->arr[i - 1];
}
ps->arr[0] = x;
ps->size++;
}
//尾删
void SLPopBack(SL* ps)
{
assert(ps);
assert(ps->size);
//删完数据,size--
//ps->arr[ps->size - 1] = -1;要不要这行都可以
ps->size--;
}
//头删
void SLPopFront(SL* ps)
{
assert(ps);
assert(ps->size);
//直接覆盖即可
for (int i = 1; i < ps->size; i++)
{
ps->arr[i - 1] = ps->arr[i];
}
ps->size--;
}
//在指定位置插入
void SLInsert(SL* ps, int pos, SLDataType x)//注意pos是下标
{
assert(ps);
assert(pos >= 0 && pos <= ps->size);
SLCheckCapacity(ps);
for (int i = ps->size; i > pos; i--)
{
ps->arr[i] = ps->arr[i - 1];//arr[pos+1]=arr[pos];
}
ps->arr[pos] = x;
ps->size++;
}
//在指定位置删除
void SLErase(SL* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
for (int i = pos; i < ps->size - 1; i++)
{
ps->arr[i] = ps->arr[i + 1];//arr[size-2]=arr[size-1]
}
ps->size--;
}
//查找
int SLFind(SL* ps, SLDataType x)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
if (ps->arr[i] == x)
{
return i;
}
}
return -1;
}完