C#是一种编译型语言,也称为静态类型语言,这意味着C#代码在运行之前需要经过编译器的编译处理,并生成一个可执行的本地代码文件(通常是.exe或.dll文件)。相反,解释型语言将代码转换为低级代码后直接执行,不需要编译成可执行文件(如Python)。
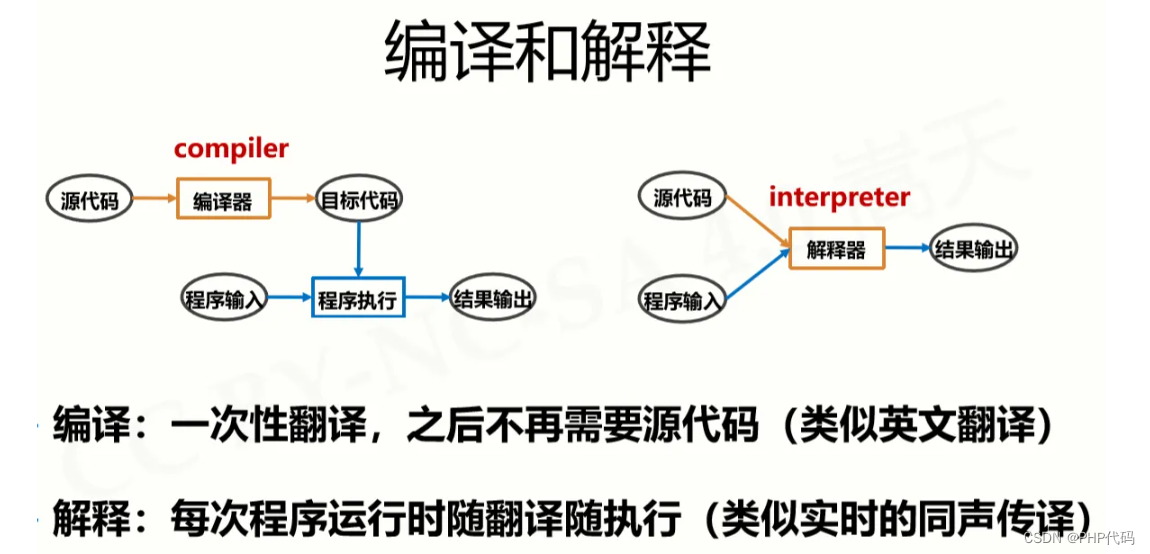
下面是C#编译器的工作流程:
- 预处理: 编译器使用预处理器将C#代码转换为扩展的C#代码。预处理器解析源代码文件中的所有预处理器指令,比如#including和#define语句,并把原始C#代码转换成扩展的C#代码。
- 分析: 编译器则对扩展的C#代码进行词语分析和语法分析。将扩展的C#代码分解为更小的部分,然后构造与代码语法相关的结构,如语法树或中间表示。
- 语义分析: 编译器使用语义分析器检查代码,如变量类型、函数声明是否正确,函数调用是否匹配,变量是否声明并初始化等。
- 代码生成: 编译器将分析和优化后的C#代码转换为本地汇编代码。
- 链接: 在编译之后,链接器将不同的代码模块和库汇集在一起,生成可执行文件。

编译型语言的优点在于代码运行速度较快,因为编译器可以对代码进行优化和检查,可以在编译阶段检测出错误,而不是在运行时发现。此外,也易于代码调试。当开发者编写代码时,编译器会在编辑器中提示代码中的错误。
总之,C#是一种编译语言,它通过与编译器交互来生成本地代码。这种编译方式使代码运行更快,也可以减少开发者在开发和调试过程中的错误。
随着编译技术和虚拟机技术的发展,单纯以“编译型”还是“解释型”来描述一种语言已经不足以给语言分类进了。
一般意义上,编译型和解释型的区别是这种感觉:
最典型的编译型语言,可以将代码最终翻译成汇编/机器语言,直接被CPU识别。
最典型的解释型语言,程序的执行完全由虚拟机接管,甚至可以一边输入代码一边执行。
但是在实践中有两个趋势,“解释型语言”越来越“编译”,“编译型语言”越来越“解释”。
1、即便是纯编译型语言,程序的执行还是离不开操作系统。调用任何系统功能都离不开操作系统提供的基础设施。比如现代C语言离不开 C Runtime (CRT)这种东西。到了就被系统接管。
操作系统不仅要对系统调用负责,而且还要对权限、对内存越界等各种问题负责,并不是你怎么写就怎么执行。
随着语言提供的功能越来越多,运行时(Runtime)越来越厚重,权力也越来越大。编译型可能没有最初那么单纯。
2、解释型语言越来越偏向“编译”。比如原版Python就很“解释”,但也有各种各样的手段能让它显得更“编译”。比如PyPy就是使用了JIT技术,让Python具备了很多编译型语言的特征,性能也实现了翻倍。
静态类型解释型语言,比如C#和Java,由于有充足的类型信息,还支持AOT等更像“编译”的技术。还有C#支持IL2CPP这种直接转化成C++代码的技术,多半截身子都跨到“编译型”的坑里了。
这个问题可以类比“强类型“和“弱类型”。
曾经我们还敢斩钉截铁的说“某某语言是强类型的,某某语言是弱类型的”。但到了今天,仔细来说,所谓的“强弱”并不是非黑即白的。
把变量类型的“强弱”,与变量类型的“静态和动态”画成坐标系,我们会得到一个经典的二维图谱

可以看到,没有哪种语言是绝对位于某哥端点。只是在比较时“类型更强”或者“类型更动态”而已。
“编译型“和“解释型”的区别也像这样,它们互相借鉴,已经到了你中有我,我中有你的程度。