【README】
本文对 explain打印的执行结果的字段进行解析;
本文总结自:
MySQL :: MySQL 8.3 Reference Manual :: 10.8.2 EXPLAIN Output Format![]() https://dev.mysql.com/doc/refman/8.3/en/explain-output.html
https://dev.mysql.com/doc/refman/8.3/en/explain-output.html
| 列名 | 含义 |
| id | 选择标识 |
| select_type | 选择类型 |
| table | 输出结果的表 |
| parition | 分区 |
| type | 访问方式或连表类型(单表也算连表) |
| possible_keys | 可能使用的索引 |
| key | 实际使用的索引 |
| key_len | 实际使用索引的长度 |
| ref | 与索引比较的查询列 |
| rows | 扫描行数 |
| filtered | 按表条件过滤出的行的百分比(占全表总行数) |
| extra | 其他信息 |
【1】查看执行计划

由上图可以看到,执行计划的列名如下:
- id: 执行顺序(id越大,越先执行;id相等,则按照从上到下顺序执行)
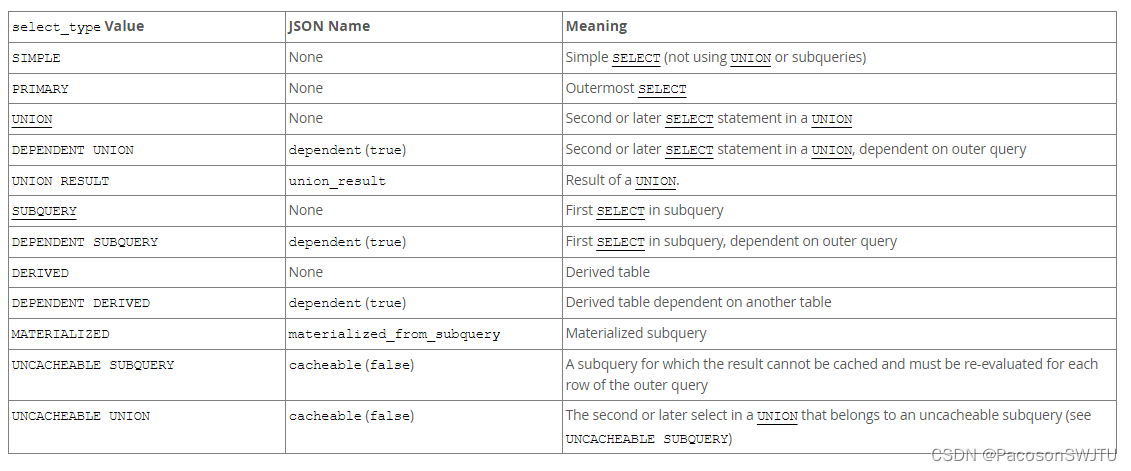
- select_type:查询类型;
- SIMPLE:简单查询;
- PRIMARY:最外层 SELECT;
- UNION:包含union合并子句的合并查询;
- MATERIALIZED:物化子查询;
- SUBQUERY: 子查询中的第1个SELECT;
- ...more;
- table:输出结果的表;
- parttion:分区;
- type:表的访问方式(性能从差到好);
- ALL:全表扫描(磁盘);
- index:full index scan ,全索引树扫描;
- range:基于索引树的范围查询;
- ref:普通索引扫描;
- eq_ref:唯一索引扫描(包括主键索引);
- const:常量;
- system:是const的特例,当表只有一行时,使用system;
- NULL: 空查询,不用扫描表与索引,直接返回结果;如查询索引列的最小值;
- possible_key: 可能使用的索引名;
- key:实际使用的索引名;
- key_len:索引使用的字节数(最大可能长度,非实际);
- ref: 与索引列比较的列名(请求sql中的);
- row:扫描行数;
- filtered: 条件过滤的行百分比;
- extra:其他信息;
- using where :表明mysql将通过 where条件筛选存储引擎返回的记录;
- using index: 扫描索引树;
- using temporary:使用临时表;(当排序所需内存超过排序缓冲时,需要新建临时表);
- using filesort:使用文件排序(无法通过索引完成排序,都会使用文件排序,无论在内存还是在磁盘排序);
【2】补充 select_type列表