1.窗口的概念

时间是为窗口服务的。窗口是什么?为什么会有窗口呢?
(1)Flink要处理的数据,一般是从Kafka过来的流式数据,如果只是单纯地统计流的数据量,是没办法统计的。
(2)所以,要人为的 加上了一个时间区间限制(窗口),才可以进行统计。
2.窗口的分类
2.1滚动窗口(tumble)
2.1.1 sql版
窗口大小 = 滑动距离。
它的窗口是紧密排布的,中间没有任何的数据重复和丢失。

--创建表
CREATE TABLE source_table (
user_id STRING,
price BIGINT,
`timestamp` bigint,
row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),
watermark for row_time as row_time - interval '0' second
) WITH (
'connector' = 'socket',
'hostname' = 'node1',
'port' = '9999',
'format' = 'csv'
);
--语法
tumble(row_time,时间间隔),比如,如下的sql
tumble(row_time,interval '5' second),每隔5秒滚动一次。
--业务查询逻辑(传统方式)
select
user_id,
count(*) as pv,
sum(price) as sum_price,
UNIX_TIMESTAMP(CAST(tumble_start(row_time, interval '5' second) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(tumble_end(row_time, interval '5' second) AS STRING)) * 1000 as window_end
from source_table
group by
user_id,
tumble(row_time, interval '5' second);
--TVF写法
--语法,跟3个参数:
--参数1:表名
--参数2:表中事件时间列
--参数3:窗口大小
from table(tumble(table source,descriptor(row_time),interval '5' second))
--sql为:
SELECT
user_id,
UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end,
sum(price) as sum_price
FROM TABLE(TUMBLE(
TABLE source_table
, DESCRIPTOR(row_time)
, INTERVAL '5' SECOND))
GROUP BY window_start,
window_end,
user_id;
--window_start,window_end是新写法的关键字
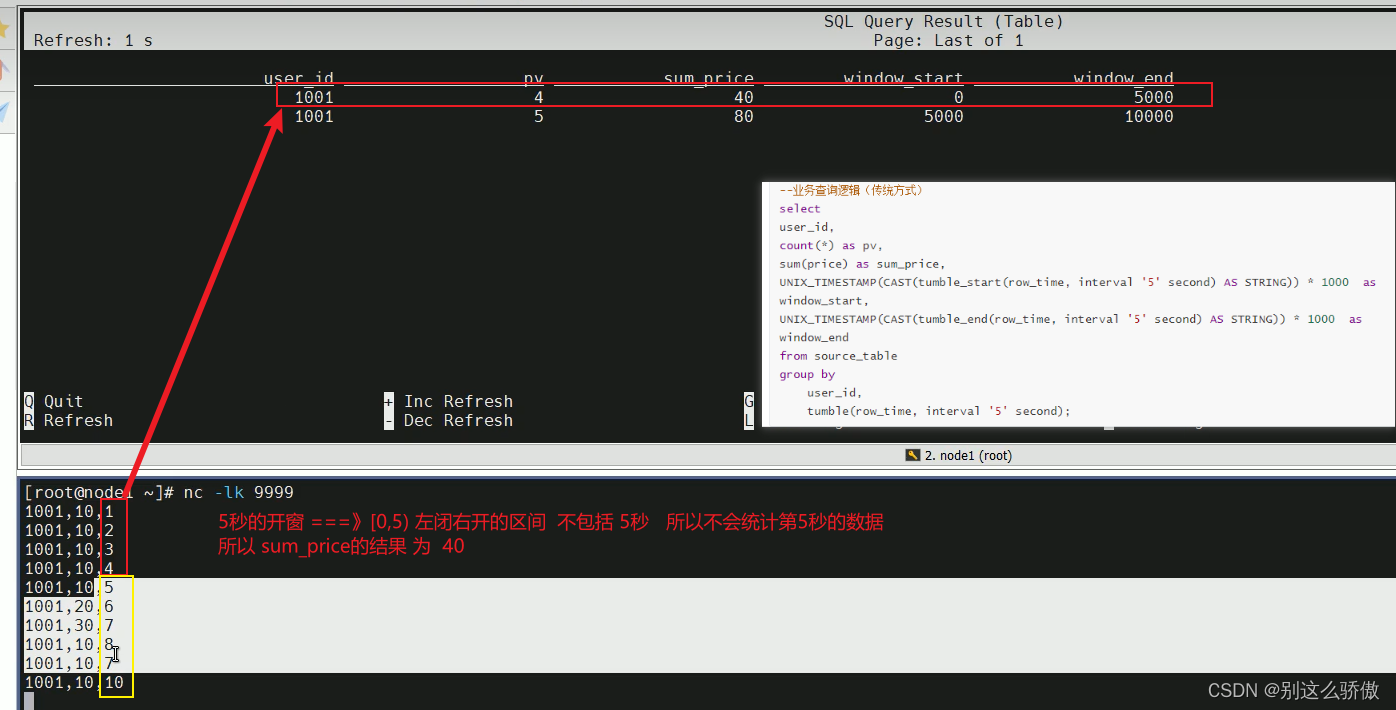
在事件时间下,窗口的划分是根据第一条事件时间来划分的,只有等数据来了才会创建窗口。
计算公式 = 事件时间 - (事件时间 % 窗口大小)
刚刚的案例中,第一条数据的事件时间为1,窗口大小为5
1 - (1 % 5) = 0,所以,窗口的起始是从0开始。
由于窗口的大小是5秒,因此,后面的窗口排布就是:
[0,5)
[5,10)
[10,15)
什么时候触发计算呢?
在事件时间下,窗口的触发计算就是窗口结束 - 1(毫秒)。
比如上面的窗口是[0,5),结束的点就是5 * 1000 - 1 = 4999。
所以,我们输入5秒的时候,会触发窗口内的数据计算。
2.1.2 DataStream API版
开发步骤:
//1.创建流式执行环境
//2.数据源
//3.数据处理
//3.1数据map转换操作,转成Tuple3
//3.2把Tuple3的数据添加Watermark(monotonousTimestamps)
前两个目的是为了指定时间列(才能根据这一列进行窗口的划分)
//3.3把数据根据id进行分组
//3.4分组之后,设置滚动事件时间窗口,并且制定窗口大小为5秒钟
//3.5对窗口内的数据进行sum操作
//3.6把Tuple3转成了Tuple2(取id和sum的值)
//4.数据输出
//5.启动流式任务
package flink.test;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class tests {
public static void main(String[] args) throws Exception {
// TODO: 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// TODO: 2.数据源
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
// TODO: 3.处理数据
//分配窗口,创建窗口就有水位线,不需要就设置为0,类似于sql版
/**
* WatermarkStrategy的策略有四种:
* forMonotonousTimestamps,单调递增水印
* forBoundedOutOfOrderness,允许乱序数据(数据迟到)的水印
* forGenerator,自定义水印
* noWatermarks,没有水印
*
* ---
* (1)map转换得到 每一行对应的列
* (2)通过 .assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps() 来创建窗口
* (3) .withTimestampAssigner() 来指定哪一列来表示时间列(才能根据这一列进行窗口的划分)
*/
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> mapAndWatermarkStream = source.map(new MapFunction<String, Tuple3<String, Integer, Long>>() {
@Override
public Tuple3<String, Integer, Long> map(String s) throws Exception {
String[] lines = s.split(",");
/**
* lines分为3个字段:String id,Integer price,Long ts 所有要类型转换一下
*/
return Tuple3.of(lines[0], Integer.valueOf(lines[1]), Long.valueOf(lines[2]));
}
}).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element, long l) {
//这个方法用于标记 哪一列是表示时间戳
return element.f2 * 1000L;
}
}));
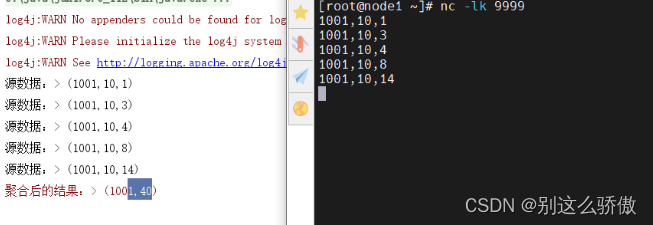
mapAndWatermarkStream.print("原数据:");
//数据分组 sql group by
KeyedStream<Tuple3<String, Integer, Long>, String> keybyStream = mapAndWatermarkStream.keyBy(value -> value.f0);
//划分窗口和统计 指定窗口的大小,再sum ---》类似与离线 sql where条件限制范围 time between 20240101 and 20240107(比如说求一周内的某个指标) 和 select中的 sum
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> result = keybyStream.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1)
.returns(Types.TUPLE(Types.STRING, Types.INT));
// TODO: 4.数据输出
result.printToErr("聚合后的数据:");
// TODO: 5.启动流式任务
env.execute();
}
}
数据输出和结果输出:
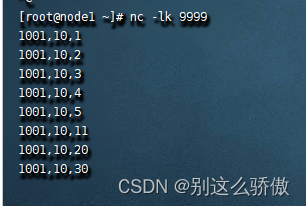

2.2滑动窗口(hop)
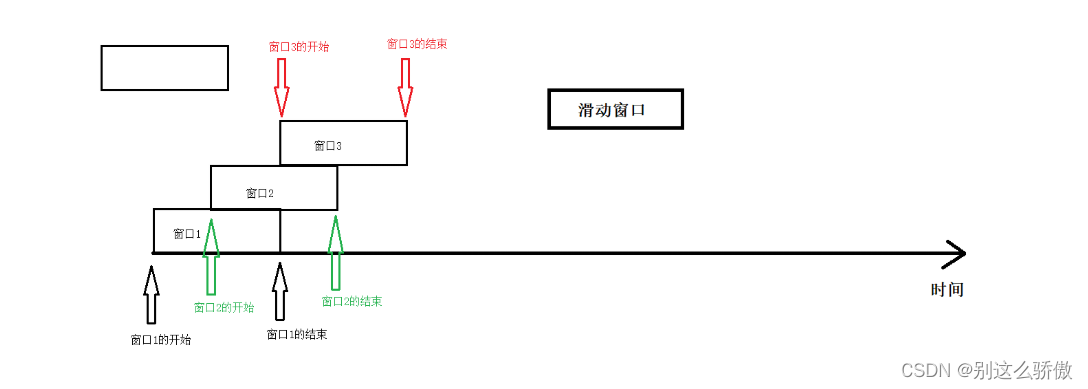
滑动窗口 :滑动距离 不等于 窗口大小。
(1)如果滑动距离<窗口大小===>数据重复;
(2)如果滑动距离=窗口大小===>滚动窗口(没有任何的数据重复和丢失);
(3)如果滑动距离>窗口大小===>数据丢失(不考虑)!!!
2.2.1 sql版
--创建表
CREATE TABLE source_table (
user_id STRING,
price BIGINT,
`timestamp` bigint,
row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),
watermark for row_time as row_time - interval '0' second
) WITH (
'connector' = 'socket',
'hostname' = 'node1',
'port' = '9999',
'format' = 'csv'
);
--语法
hop(事件时间列,滑动间隔,窗口大小)
hop(row_time,interval '2' second, interval '5' second)
--业务SQL
SELECT user_id,
UNIX_TIMESTAMP(CAST(hop_start(row_time, interval '2' SECOND, interval '5' SECOND) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(hop_end(row_time, interval '2' SECOND, interval '5' SECOND) AS STRING)) * 1000 as window_end,
sum(price) as sum_price
FROM source_table
GROUP BY user_id
, hop(row_time, interval '2' SECOND, interval '5' SECOND);--每隔两秒滑动一次
--TVF写法
--table:表名
--descriptor:事件时间列
--滑动距离:interval 2 second
--窗口大小:interval 5 second
from table(hop(table 表名,descriptor(事件时间列),滑动间隔,窗口大小))
from table(hop(table source,descriptor(row_time),interval '2' second,interval '5' second))
--sql为:
SELECT
user_id,
UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end,
sum(price) as sum_price
FROM TABLE(HOP(
TABLE source_table
, DESCRIPTOR(row_time)
, interval '2' SECOND, interval '6' SECOND))
GROUP BY window_start,
window_end,
user_id;
数据输入和运行结果如下:

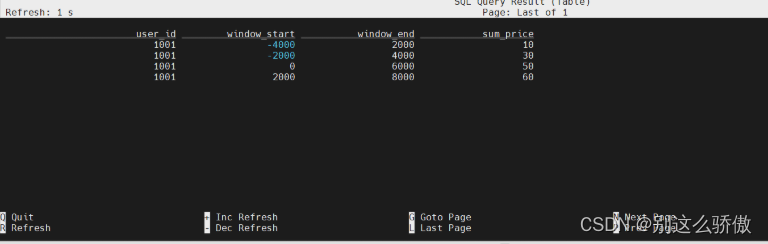
说明:
(1)事件时间1的到来,会让窗口仅限排布(划分),划分的窗口如下:
[-2,3],[0,5],[2,7],[4,9]
(2)窗口每隔两秒滑动一次,所以会有数据重复计算。
2.2.2 DataStream API版
package flink.test;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class Demo02_SlideWindow {
public static void main(String[] args) throws Exception {
//1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.数据源
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
//3.数据处理
//3.1数据map转换操作,转成Tuple3
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> mapStream = source.map(value -> {
/**
* 由一行数据中,用逗号进行切分【id,price,ts】
* String id
* Integer price
* Long ts
*/
String[] lines = value.split(",");
return Tuple3.of(lines[0], Integer.valueOf(lines[1]), Long.parseLong(lines[2]));
}).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG));
//3.2把Tuple3的数据添加Watermark(monotonousTimestamps)
/**
* WatermarkStrategy生成水印的策略有四种:
* forMonotonousTimestamps,单调递增水印(用的次多)
* forBoundedOutOfOrderness,运行数据迟到(乱序)(用的最多)
* forGeneric,自定义水印(不用)
* noWatermark,没有水印(不用)
*/
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> watermarks = mapStream.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element, long recordTimestamp) {
return element.f2 * 1000L;
}
}));
//3.3把数据根据id进行分组
watermarks.print("源数据:");
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> sumStream = watermarks.keyBy(value -> value.f0)
//3.4分组之后,设置滑动事件时间窗口,并且制定窗口大小为5秒钟,滑动间隔为2秒。
/**
* SlidingEventTimeWindows,滑动事件时间窗口,带2个参数:
* 参数1:窗口大小
* 参数2:滑动间隔
*/
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(2)))
//3.5对窗口内的数据进行sum操作
.sum(1);
//3.6把Tuple3转成了Tuple2(取id和sum的值)
SingleOutputStreamOperator<Tuple2<String, Integer>> result = sumStream.map(value -> Tuple2.of(value.f0, value.f1))
.returns(Types.TUPLE(Types.STRING,Types.INT));
//4.数据输出
result.printToErr("聚合后的数据:");
//5.启动流式任务
env.execute();
}
}
数据输入和结果输出:
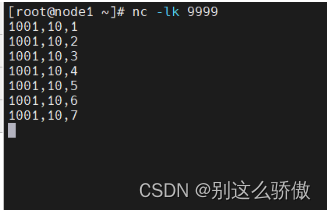

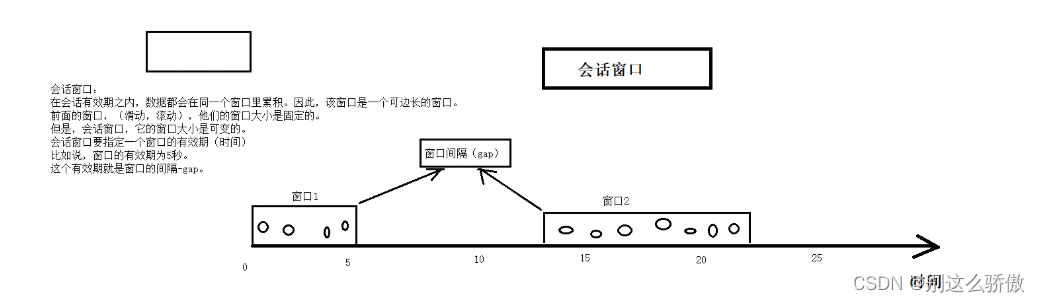
2.3会话窗口(session)
会话窗口:在一个会话周期内,窗口的数据会累积,超过会话周期就会触发窗口的计算,同时开辟下一个新窗口。
注意:
数据本身的事件时间大于窗口间隔,才会触发当前窗口的计算。
2.3.1 sql版
--创建表
CREATE TABLE source_table (
user_id STRING,
price BIGINT,
`timestamp` bigint,
row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),
watermark for row_time as row_time - interval '0' second
) WITH (
'connector' = 'socket',
'hostname' = 'node1',
'port' = '9999',
'format' = 'csv'
);
--语法
session(事件时间列,窗口间隔)
session(row_time,interval '5' second)
--业务SQL
SELECT
user_id,
UNIX_TIMESTAMP(CAST(session_start(row_time, interval '5' SECOND) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(session_end(row_time, interval '5' SECOND) AS STRING)) * 1000 as window_end,
sum(price) as sum_price
FROM source_table
GROUP BY user_id
, session(row_time, interval '5' SECOND);
!!!会话窗口没有TVF写法。
数据输入和结果输出:

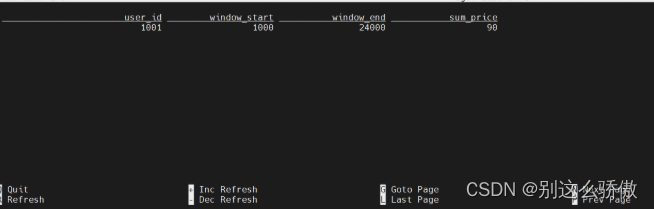
2.3.2 DataStream API版
package flink.test;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class Demo03_SessionWindow {
public static void main(String[] args) throws Exception {
//1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.数据源
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
//3.数据处理
//3.1数据map转换操作,转成Tuple3
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> mapStream = source.map(new MapFunction<String, Tuple3<String, Integer, Long>>() {
@Override
public Tuple3<String, Integer, Long> map(String value) throws Exception {
/**
* String id
* Integer price
* Long ts
*/
String[] lines = value.split(",");
return Tuple3.of(lines[0], Integer.valueOf(lines[1]), Long.parseLong(lines[2]));
}
});
//3.2把Tuple3的数据添加Watermark(monotonousTimestamps)
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> watermarks = mapStream
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element, long recordTimestamp) {
return element.f2 * 1000L;
}
}));
watermarks.print("源数据:");
//3.3把数据根据id进行分组
//3.4分组之后,设置会话事件时间窗口,并且指定窗口间隔为5秒钟。
//3.5对窗口内的数据进行sum操作
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> sumStream = watermarks.keyBy(value -> value.f0)
.window(EventTimeSessionWindows.withGap(Time.seconds(5)))
.sum(1);
//3.6把Tuple3转成了Tuple2(取id和sum的值)
SingleOutputStreamOperator<Tuple2<String, Integer>> result = sumStream.map(value -> Tuple2.of(value.f0, value.f1)).returns(Types.TUPLE(Types.STRING, Types.INT));
//4.数据输出
result.printToErr("聚合后的结果:");
//5.启动流式任务
env.execute();
}
}
数据输入和结果输出: