文章目录
- 一、用户文档
- 1.安装Pytorch
- 2.安装TorchEEG
- 3.安装与图算法的插件
- 二、教程
- 1.使用TorchEEG完成深度学习工作流程
- 2datasets模块
- 3.transforms模块
- 4.models模块
- 5.trainer模块
- 6.使用Vanilla PyTorch训练模型
一、用户文档
1.安装Pytorch
TorchEEG依赖于PyTorch,根据系统、CUDA版本等信息完成PyTorch(>=1.8.1)的安装:
# Conda
# please refer to https://pytorch.org/get-started/locally/
# e.g. CPU version
conda install pytorch==1.11.0 torchvision torchaudio cpuonly -c pytorch
# e.g. GPU version
conda install pytorch==1.11.0 torchvision torchaudio cudatoolkit=11.3 -c pytorch
# Pip
# please refer to https://pytorch.org/get-started/previous-versions/
# e.g. CPU version
pip install torch==1.11.0+cpu torchvision==0.12.0+cpu torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cpu
# e.g. GPU version
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
2.安装TorchEEG
conda安装:
conda install -c tczhangzhi -c conda-forge torcheeg
pip安装:
pip install torcheeg
安装尚未完全发布的最新TorchEEG功能
pip install git+https://github.com/tczhangzhi/torcheeg.git
3.安装与图算法的插件
用于将数据集中的脑电图转换为图结构并使用图神经网络对其进行分析。
# Conda
# please refer to https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html
conda install pyg -c pyg
# Pip
# please refer to https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html
# e.g. CPU version
pip install torch-scatter torch-sparse torch-cluster torch-spline-conv torch-geometric -f https://data.pyg.org/whl/torch-1.11.0+cpu.html
# e.g. GPU version
pip install torch-scatter torch-sparse torch-cluster torch-spline-conv torch-geometric -f https://data.pyg.org/whl/torch-1.11.0+cu113.html
二、教程
1.使用TorchEEG完成深度学习工作流程
(1)初始化数据集
使用TorchEEG支持的DEAP数据集。每个EEG样本长度设置为1秒,包含128个数据点。基线信号长3秒,我们将其分为三段,然后进行平均以获得实验的基线信号。
在离线预处理过程中,我们将每个电极的脑电信号分为4个子带,计算每个子带的微分熵作为特征,进行去基线,并映射到网络上。最后将预处理后的脑电信号保存到本地。对于在线处理,我们将所有脑电图信号转换为张量,使它们适合神经网络输入。
from torcheeg.datasets import DEAPDataset #导入DEAP数据集类
from torcheeg import transforms #导入数据预处理的转换模块
from torcheeg.datasets.constants.emotion_recognition.deap import \
DEAP_CHANNEL_LOCATION_DICT #导入DEAP数据集的通道位置字典
dataset = DEAPDataset( #使用DEAPDataset类创建一个数据集对象
io_path=f'./examples_pipeline/deap', #数据集的输入输出路径
root_path='./data_preprocessed_python', #数据集根路径
offline_transform=transforms.Compose([ #离线转换,用于对数据进行预处理
transforms.BandDifferentialEntropy(apply_to_baseline=True),
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True)
]),
online_transform=transforms.Compose( #在线转换,用于实时处理数据
[transforms.BaselineRemoval(),
transforms.ToTensor()]),
label_transform=transforms.Compose([ #标签转换,用于对标签进行处理
transforms.Select('valence'),
transforms.Binary(5.0),
]),
num_worker=8) #工作进程数量
"""
transforms.Compose([...]):使用Compose函数将多个转换组合起来应用到数据集中。
transforms.BandDifferentialEntropy(apply_to_baseline=True):计算带通微分熵,参数apply_to_baseline指定是否将该转换应用于基线信号。
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True):将EEG信号映射到网格上,参数apply_to_baseline指定是否将该转换应用于基线信号。
transforms.BaselineRemoval():基线移除转换,用于移除基线信号。
transforms.ToTensor():将数据转换为张量格式。
transforms.Select('valence'):选择情感标签中的valence字段。
transforms.Binary(5.0):将valence标签转换为二进制形式,大于5.0的为正类,小于等于5.0的为负类。
"""
(2)将数据集拆分为训练集和测试集
使用每个主体的5倍交叉验证来分割数据集。在次过程中,我们将每个受试者的脑电图样本分为训练集和测试集。用4倍进行训练,1倍进行测试。
#从torcheeg库中导入KFoldGroupbyTrial类,该类用于按照试验分组的K折交叉验证。
from torcheeg.model_selection import KFoldGroupbyTrial
#创建一个KFoldGroupbyTrial对象
k_fold = KFoldGroupbyTrial(n_splits=10, #指定将数据集划分为10个子集,即进行10折交叉验证
split_path='./examples_pipeline/split', #指定分割方案的路径,即存储每个子集分割情况的文件夹路径。
shuffle=True, #指定在分割数据集之前是否对数据进行洗牌
random_state=42) #指定随机种子,用于确定数据洗牌的顺序,保证结果的可复现性
(3)定义模型并开始训练
循环遍历每个交叉验证集,对于每个交叉验证集,我们初始化CCNN模型并定义其超参数。例如,每个EEG样本包含来自4个子带的4通道特征,网格大小为9 x 9。
#从PyTorch中导入DataLoader类,用于批量加载数据
from torch.utils.data import DataLoader
#从torcheeg库中导入CCNN模型,这是一个用于情绪识别的卷积神经网络模型
from torcheeg.models import CCNN
#从torcheeg库中导入ClassifierTrainer类,这个类用于训练分类器模型
from torcheeg.trainers import ClassifierTrainer
#导入PyTorch Lightning库,用于训练和评估深度学习模型
import pytorch_lightning as pl
#遍历KFoldGroupbyTrial对象的划分结果,获取每个训练集和验证集的数据集
for i, (train_dataset, val_dataset) in enumerate(k_fold.split(dataset)):
#创建训练集的DataLoader对象,用于批量加载训练数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
#创建验证集的DataLoader对象,用于批量加载验证数据。
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
#创建CCNN模型的实例,指定模型的参数,包括类别数、输入通道数和网格大小
model = CCNN(num_classes=2, in_channels=4, grid_size=(9, 9))
#创建ClassifierTrainer对象,用于训练分类器模型。指定了模型、类别数、学习率、权重衰减和加速器类型
trainer = ClassifierTrainer(model=model,
num_classes=2,
lr=1e-4,
weight_decay=1e-4,
accelerator="gpu")
#使用训练集和验证集对模型进行训练。指定了最大的训练周期数、模型保存路径、回调函数、是否显示进度条、是否打印模型摘要以及验证集批次的限制
trainer.fit(train_loader,
val_loader,
max_epochs=50,
default_root_dir=f'./examples_pipeline/model/{i}',
callbacks=[pl.callbacks.ModelCheckpoint(save_last=True)],
enable_progress_bar=True,
enable_model_summary=True,
limit_val_batches=0.0)
#对验证集进行评估,计算模型在验证集上的性能指标。返回一个性能指标字典,这里取出了测试准确率
score = trainer.test(val_loader,
enable_progress_bar=True,
enable_model_summary=True)[0]
#打印每个折叠(fold)的测试准确率
print(f'Fold {i} test accuracy: {score["test_accuracy"]:.4f}')
2datasets模块
提供了基于脑电图的情感识别的各种基准数据集,例如,DEAP、DREAMER、SEED、MAHNOB、AMIGOS和MPED。这些数据集使用音乐和视频等一系列刺激来触发情绪反应。一旦记录了情感体验,参与者就会使用效价唤醒维度或离散情感类别等方法对其进行标记。
(1)加载DEAP数据集。读取脑电图信号和标签,应用离线转换,并保存它们以便以后轻松访问。
from torcheeg.datasets import DEAPDataset #导入DEAP数据集类
from torcheeg import transforms #导入数据预处理的转换模块
from torcheeg.datasets.constants.emotion_recognition.deap import \
DEAP_CHANNEL_LOCATION_DICT #导入DEAP数据集的通道位置字典
dataset = DEAPDataset( #使用DEAPDataset类创建一个数据集对象
io_path=f'./deap', #数据集的输入输出路径
root_path='./data_preprocessed_python', #数据集根路径
offline_transform=transforms.Compose([ #离线转换,用于对数据进行预处理
transforms.BandDifferentialEntropy(apply_to_baseline=True),
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True)
]),
online_transform=transforms.Compose( #在线转换,用于实时处理数据
[transforms.BaselineRemoval(),
transforms.ToTensor()]),
label_transform=transforms.Compose([ #标签转换,用于对标签进行处理
transforms.Select('valence'),
transforms.Binary(5.0),
]),
num_worker=8) #工作进程数量
"""
transforms.Compose([...]):使用Compose函数将多个转换组合起来应用到数据集中。
transforms.BandDifferentialEntropy(apply_to_baseline=True):计算带通微分熵,参数apply_to_baseline指定是否将该转换应用于基线信号。
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True):将EEG信号映射到网格上,参数apply_to_baseline指定是否将该转换应用于基线信号。
transforms.BaselineRemoval():基线移除转换,用于移除基线信号。
transforms.ToTensor():将数据转换为张量格式。
transforms.Select('valence'):选择情感标签中的valence字段。
transforms.Binary(5.0):将valence标签转换为二进制形式,大于5.0的为正类,小于等于5.0的为负类。
"""
从数据集中获取单个样本:
print(dataset[0]) #输出一个元组,第一个元素是脑电图信号,第二个元素是其标签
可视化脑电图信号:
import torch
from torcheeg.utils import plot_3d_tensor
img = plot_3d_tensor(torch.tensor(dataset[0][0]))
注意:
如果更改数据集的配置,请记住清除缓存或指定新的io_path。否则,只有在线转换(online_transform 和 label_transform )才会生效:
!rm -rf ./deap
如果删除所有转换并声明一个数据集,会发现它返回未经过任何预处理的分段脑电图信号。此外,还有一个字典表示与脑电图信号样本相对应的所有元信息。
from torcheeg.datasets import DEAPDataset
dataset = DEAPDataset(io_path=f'./deap', root_path='./data_preprocessed_python')
print(dataset[0])
(2)高级用法:
大多数情绪分析数据集都可以在TorchEEG中找到。此外,TorchEEG提供对MOABB的支持,允许在MOABB的帮助下访问运动图像的相关数据集。
import torcheeg.datasets.moabb as moabb_dataset
from moabb.datasets import BNCI2014001
from moabb.paradigms import LeftRightImagery
dataset = BNCI2014001() #设置录的运动想象数据集
dataset.subject_list = [1, 2, 3]
paradigm = LeftRightImagery() #涉及左右手运动想象的任务
dataset = moabb_dataset.MOABBDataset( #自定义的数据集类
dataset=dataset,
paradigm=paradigm,
io_path='./moabb',
offline_transform=transforms.Compose([transforms.BandDifferentialEntropy()
]),
online_transform=transforms.ToTensor(),
label_transform=transforms.Compose([transforms.Select('label')]))
(3)自定义数据集:
按照特定规则将记录的EEG信号文件放置在文件夹中:
label01
|- sub01.edf
|- sub02.edf
label02
|- sub01.edf
|- sub02.edf
使用FolderDataset自动获取相应的脑电信号样本:
from torcheeg.datasets import FolderDataset
label_map = {'label01': 0, 'label02': 1}#字典,键是原始标签,值是将其映射到的数字标签
dataset = FolderDataset(io_path='./folder',#数据集的输入/输出路径
root_path='./root_folder',#数据集的根路径
#数据集的组织结构,subject_in_label表示每个标签文件夹中包含一个或多个主体文件夹,每个主体文件夹中包含数据文件
structure='subject_in_label',
num_channel=14,#数据中的通道数
online_transform=transforms.ToTensor(),#在线转换,将应用于数据加载过程中
label_transform=transforms.Compose([#标签转换,用于从数据中提取标签并进行任何必要的转换
transforms.Select('label'),
transforms.Lambda(lambda x: label_map[x])
]),
num_worker=4) #加载数据时使用的工作进程数
或者使用CSV文件来指定更详细的元信息以供阅读:
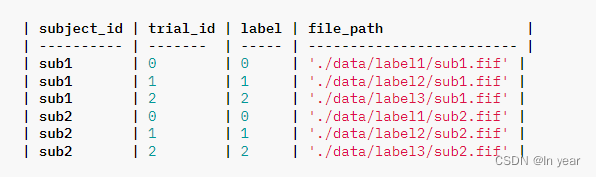
from torcheeg.datasets import CSVFolderDataset
dataset = CSVFolderDataset(csv_path='./data.csv',#指定了CSV文件的路径
# 定义了在线转换操作,将数据转换为张量格式
online_transform=transforms.ToTensor(),
#定义了标签转换操作,从数据中选择标签列
label_transform=transforms.Select('label'),
#指定了数据加载过程中使用的工作进程数,以加快数据加载速度
num_worker=4)
默认情况下,TorchEEG使用mne读取记录的EEG信号,也可以通过read_fn指定自己的文件读取逻辑:
import mne
#从文件路径加载EEG数据,并将其转换为epochs对象,使得数据集的每个样本具有相同的长度
def default_read_fn(file_path, **kwargs):
# 加载原始EEG数据文件
raw = mne.io.read_raw(file_path)
# 将加载的原始数据转为固定长度的epochs对象,每个epoch的持续时间为1秒
epochs = mne.make_fixed_length_epochs(raw, duration=1)
# Return EEG data
return epochs
dataset = CSVFolderDataset(io_path='./csv_folder',#指定包含CSV文件的文件夹路径
csv_path='./data.csv',#指定了CSV文件的路径
read_fn=default_read_fn,#从原始数据中加载EEG数据
online_transform=transforms.ToTensor(),#在线转换操作,将数据转换为张量格式
label_transform=transforms.Select('label'),#定义了标签转换操作,从数据中选择标签列
num_worker=4) #指定了数据加载过程中使用的工作进程数,以加快数据加载速度
3.transforms模块
为脑电图信号和相关元数据的转换和预处理而设计的工具。
脑电图转换专注于深度学习模型的脑电图预处理、特征提取、数据转换和数据增强。它们通常接受各种参数进行实例化,并且实例化的transformer可以用作处理EEG信号的函数。它们接受“eeg”和“baseline”作为关键字参数并返回一个字典,其中“eeg”对应于处理后的脑电图信号,而“baseline”对应于处理后的基线信号。
import numpy as np
from torcheeg import transforms
from torcheeg.datasets.constants.emotion_recognition.deap import \
DEAP_CHANNEL_LOCATION_DICT
"""
创建了一个ToGrid的转换对象,它的作用是将原始的EEG信号转换为网格化的形式,
使用了DEAP数据集的通道位置字典DEAP_CHANNEL_LOCATION_DICT来确定网格的布局。
"""
t = transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT)
#将一个大小为(32, 128)的随机EEG信号输入到转换函数中,
#并获取转换后的网格化EEG信号。打印出了转换后的EEG信号的形状。
eeg = t(eeg=np.random.randn(32, 128))['eeg']
print(eeg.shape)
eeg = t(eeg=np.random.randn(32, 128), baseline=np.random.randn(32, 128))['eeg']
print(eeg.shape)
在预处理方面,脑电图转换有助于消除脑电图信号中的噪声。一个典型的例子是基线去除,它在刺激之前使用基线信号来从处理的信号中去除与刺激无关的波动。
#基线去除
t = transforms.BaselineRemoval()
#将一个大小为(32, 128)的随机EEG信号及相应的基线数据传入基线去除操作中,
#然后获取去除基线后的EEG信号。打印出了去除基线后的EEG信号的形状。
eeg = t(eeg=np.random.randn(32, 128), baseline=np.random.randn(32, 128))['eeg']
print(eeg.shape)
对于特征提取,脑电图变换负责创建情感识别中通常使用的情感区分特征。BandDifferentialEntropy就是这样的一个例子,它测量EEG信号内频率子带的微分熵。
eeg = np.random.randn(32, 128)
#将一个大小为(32, 128)的随机EEG信号传入频带差分熵变换中,然后获取变换后的EEG信号。
#最后,将变换后的EEG信号保存在transformed_eeg变量中。
transformed_eeg = transforms.BandDifferentialEntropy()(eeg=eeg)['eeg']
在数据转换方面,EEG转换在将EEG信号塑造为时间序列,3D网格或图形网络方面发挥着关键作用。其中的实例包括ToGrid、TolnterpolatedGrid、ToG和ToDynamicG。
# DEAP 数据集的邻接矩阵,它描述了 EEG 信号之间的电极连接关系
from torcheeg.datasets.constants import DEAP_ADJACENCY_MATRIX
#创建了一个 ToG 转换对象,它的作用是将 EEG 信号转换为图结构数据
from torcheeg.transforms.pyg import ToG
eeg = np.random.randn(32, 128)
#将一个大小为 (32, 128) 的随机 EEG 信号传入图结构转换中,然后获取转换后的 EEG 图结构数据。
#最后,将转换后的 EEG 图结构数据保存在 transformed_eeg 变量中。
transformed_eeg = ToG(DEAP_ADJACENCY_MATRIX)(eeg=eeg)['eeg']
print(transformed_eeg)
关于数据增强,RandomMask等变换对EEG信号应用随机变换,有效地增强数据量。
import torch
eeg = torch.randn(32, 128)
#创建了一个 RandomMask 转换对象,它的作用是对输入的数据进行随机掩码处理。
#参数 p=1.0 表示每个元素都有概率 100% 被掩码。
transformed_eeg = transforms.RandomMask(p=1.0)(eeg=eeg)['eeg']
print(transformed_eeg.shape)
元数据转换与脑电图信号相关的元数据交互,生成模型所需的辅助信息或标签。一个例子是Binary,它将连续的情绪价或唤醒度转换为二元标签。
info = {'valence': 4.5, 'arousal': 5.5, 'subject_id': 7}
transformed_label = transforms.Select(key='valence')(y=info)['y']
print(transformed_label)
#大于或等于5为1,否则为0
transformed_label = transforms.Binary(threshold=5.0)(y=transformed_label)['y']
print(transformed_label)
流程转换将多个transformer组合在一起,从而制定整个流程。例如,Compose允许一个转换的输出作为下一个转换的输入,从而将多个转换链接在一起。
from torcheeg import transforms
#将多个转换操作一次应用于数据
t = transforms.Compose([
#计算信号的频带差分熵
transforms.BandDifferentialEntropy(),
#将EEG信号转为网格形式,DEAP_CHANNEL_LOCATION_DICT通道位置的字典
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT)
])
#随机生成32个通道,每个通道有128个时间点的EEG数据传递给了定义的转换操作,
#然后从转换后的结果中提取EEG数据。
eeg = t(eeg=np.random.randn(32, 128))['eeg']
print(eeg.shape)
值得注意的是,除非特别需要,BaselineRemoval之前的Transformer应设置apply_to_baseline = True,以确保基线信号和实验信号进行相同的变换。
t = transforms.Compose([
transforms.BandDifferentialEntropy(apply_to_baseline=True),
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True),
transforms.BaselineRemoval()
])
eeg = t(eeg=np.random.randn(32, 128), baseline=np.random.randn(32, 128))['eeg']
print(eeg.shape)
4.models模块
(1)判别模型,包含卷积神经网络的实现,如EEGNet和TSception。这些模型创建脑电图信号的各种空间、时间或频谱张量表示,并通过卷积执行局部模式分析。
#使用torcheeg库中的一个CNN模型‘TSCeption’对EEG数据进行分类。
import torch
from torcheeg.models.cnn import TSCeption
#创建随机张量,包含1个通道、28个电极、每个电极有512个时间点
eeg = torch.randn(1, 1, 28, 512)
#创建TSCeption模型的实例
model = TSCeption(num_classes=2, #2分类
num_electrodes=28,#电极数
sampling_rate=128, #采样率
num_T=15, #时间卷积核
num_S=15, #空间卷积核
hid_channels=32, #隐藏通道数
dropout=0.5)
pred = model(eeg)
要了解如何将数据集预处理为模型所需的格式,请参阅每个模型相应的文档。
#加载和预处理DEAP数据集的流程,
#并将预处理后的数据输入到了TSCeption模型中进行分类
from torcheeg.datasets import DEAPDataset
from torcheeg import transforms
from torcheeg.datasets.constants import DEAP_CHANNEL_LIST
dataset = DEAPDataset(io_path=f'./deap',
root_path='./data_preprocessed_python',
chunk_size=512,#数据块大小
num_baseline=1, #基线数据的数量
baseline_chunk_size=512, # 基线数据的块大小
offline_transform=transforms.Compose([
transforms.PickElectrode(transforms.PickElectrode.to_index_list(
['FP1', 'AF3', 'F3', 'F7',
'FC5', 'FC1', 'C3', 'T7',
'CP5', 'CP1', 'P3', 'P7',
'PO3','O1', 'FP2', 'AF4',
'F4', 'F8', 'FC6', 'FC2',
'C4', 'T8', 'CP6', 'CP2',
'P4', 'P8', 'PO4', 'O2'], DEAP_CHANNEL_LIST)),
transforms.To2d()
]),
online_transform=transforms.ToTensor(),
label_transform=transforms.Compose([
transforms.Select('valence'),
transforms.Binary(5.0),
]))
#创建TSCeption模型
model = TSCeption(num_classes=2,
num_electrodes=28,
sampling_rate=128,
num_T=15,
num_S=15,
hid_channels=32,
dropout=0.5)
x = dataset[0][0]
x = torch.unsqueeze(x,dim=0)
print(model(x))
该模块还包括了GRU和;STM等循环神经网络。这些模型将脑电图信号视为多元时间序列数据,并构建用于情感接码的循环模块。
from torcheeg.models import GRU
model = GRU(num_electrodes=32, hid_channels=64, num_classes=2)
eeg = torch.randn(2, 32, 128)
pred = model(eeg)
在图神经网络(GNN)领域,模型模块融合了 DGCNN、RGNN 和 LGGNet 等著名网络。这些模型旨在通过将电极描述为图网络并设计图卷积核来分析电极之间的功能连接。
from torcheeg.models import DGCNN
eeg = torch.randn(1, 62, 200)
model = DGCNN(in_channels=200, num_electrodes=62, hid_channels=32, num_layers=2,num_classes=2)
pred = model(eeg)
近年来,基于 Transformer 的模型(例如 EEG-ConvTransformer)的日益流行,已在模型模块中得到认可。这些模型主要利用各种自注意力机制来分析电极相关性,提供有价值的见解。
from torcheeg.models import SimpleViT
eeg = torch.randn(1, 128, 9, 9)
model = SimpleViT(chunk_size=128, t_patch_size=32, s_patch_size=(3, 3), num_classes=2)
pred = model(eeg)
一些研究表明,基于注意力的模型在脑电图方面取得了良好的分类性能,例如Altaheri等人的ATCNet,该模型在模型结构中使用了移动窗口,并利用多头注意力来处理窗口内的数据。该模型在以下方面取得了优异的效果: BCI 竞赛 IV 的数据集 2a。
from torcheeg.models import ATCNet
from torcheeg.datasets import BCICIV2aDataset
from torcheeg import transforms
dataset = BCICIV2aDataset(io_path=f'./bciciv_2a',
root_path='./BCICIV_2a_mat',
online_transform=transforms.Compose([
transforms.To2d(),
transforms.ToTensor()
]),
label_transform=transforms.Compose([
transforms.Select('label'),
transforms.Lambda(lambda x: x - 1)
]))
model = ATCNet(num_classes=4,
num_windows=3,
num_electrodes=22,
chunk_size=1750)
x = dataset[0][0]
x = torch.unsqueeze(x,dim=0) #在张量的指定维度上添加一个维度
pred = model(x)
(2)生成模型,提供各种生成模型,这些模型以其在计算机视觉、自然语言处理和其他领域的令人印象深刻的进步而闻名。当应用于脑电图分析时,提供了四类生成模型作为研究人员的可靠基准。生成对抗网络(GAN),例如 WGAN-GP,包括生成器和鉴别器。鉴别器学习区分真实信号和生成信号,并且生成器通过针对鉴别器的对抗性训练来训练以近似准确的信号。
from torcheeg.models import BCGenerator, BCDiscriminator
#创建BCGenerator模型实例
g_model = BCGenerator(in_channels=128, num_classes=3)
#创建BCDiscriminator实例
d_model = BCDiscriminator(in_channels=4, num_classes=3)
#生成一个服从正态分布的随机张量z,大小为(1, 128),作为生成器的输入
z = torch.normal(mean=0, std=1, size=(1, 128))
#生成一个随机整数张量y,范围在0到2之间,大小为(1, ),表示标签信息。
y = torch.randint(low=0, high=3, size=(1, ))
#将随机噪声z和标签y输入到生成器模型中,生成一个假的数据张量fake_X。
fake_X = g_model(z, y)
#将生成的假数据fake_X和相应的标签y输入到判别器模型中,得到判别结果disc_X
disc_X = d_model(fake_X, y)
变分自动编码器(VAE),例如 Beta VAE,配备了编码器和解码器,使用编码器将观察到的 EEG 信号映射到潜在空间,然后使用解码器来再现 EEG 信号。
from torcheeg.models import BCEncoder, BCDecoder
encoder = BCEncoder(in_channels=4, num_classes=3)
decoder = BCDecoder(in_channels=64, out_channels=4, num_classes=3)
y = torch.randint(low=0, high=3, size=(1, ))
#创建一个模拟的脑电图数据张量,1:批次大小、4:通道数、
#9:时间点数,每个通道有9个时间点、9:时间点数,每个通道有9个时间点
mock_eeg = torch.randn(1, 4, 9, 9)
mu, logvar = encoder(mock_eeg, y)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = eps * std + mu
fake_X = decoder(z, y)
归一化流(Normalizing Flow),例如 Glow,提供了一系列可逆变换。它学习可逆变换的序列,将脑电图信号转换为潜在变量,并利用流函数的逆函数返回样本进行生成。
import torch.nn.functional as F
import torch
from torcheeg.models import BCGlow
#创建BCGlow模型的实例,指定类别数为2
model = BCGlow(num_classes=2)
# 生成模拟的EEG数据张量,2个样本,每个样本4个通道,每个通道有32x32的时间点
mock_eeg = torch.randn(2, 4, 32, 32)
#生成随机的标签张量,元素随机取值为0或1,形状为(2,)
y = torch.randint(0, 2, (2, ))
#将标签张量y转为浮点型张量,以便在计算损失函数时能够与模型输出对齐。
y = y.float()
#调用模型的前向传播函数,计算损失函数,
#model(mock_eeg, y) 返回负对数似然损失 (nll_loss) 和模型预测的结果 (y_logits)。
nll_loss, y_logits = model(mock_eeg, y)
#计算总损失,其中包括了负对数似然损失和交叉熵损失
loss = nll_loss.mean() + F.cross_entropy(y_logits, y)
# 转为整数类型
y = y.to(torch.int64)
#调用模型的 sample 方法来生成一个假的结果
fake_X = model.sample(y, temperature=1.0)
扩散模型(例如 DDPM)会随着噪声的增加而引入观察数据的连续损坏,并学会逆转此过程。生成过程反转了这种扩散过程,从白噪声开始,逐渐将其去噪为相应的观察到的脑电图信号。
from torcheeg.models import BCUNet
#实例化模型,创建一个‘BCUNet’模型,两分类任务
unet = BCUNet(num_classes=2)
#生成模拟的EEG数据,批次大小为2,有4个通道,并且每个EEG信号的维度为9x9
mock_eeg = torch.randn(2, 4, 9, 9)
#生成时间t和标签y的随机值,t:时间信息,y:标签信息
t = torch.randint(low=1, high=1000, size=(2, ))
y = torch.randint(low=0, high=2, size=(1, ))
fake_X = unet(mock_eeg, t, y)
EEGtorch提供了其他类型的模型,例如eegfusenet,它结合了脑电编码和生成新样本的功能。同时,eefusenet是一种无监督学习模型,可以从输入脑电信号中提取深度特征编码,最终生成类似的新样本。 Eegfusenet使用类似于传统gan模型的方法来识别样本是否真实:EFDiscriminator,最终通过对抗性训练后的eegfuset提高样本生成的质量。
from torcheeg.models import EEGfuseNet,EFDiscriminator
#实例化EEGfuseNet模型
fusenet = EEGfuseNet(in_channels=1,
num_electrodes=32,
hid_channels_gru=16,
num_layers_gru= 1,
hid_channels_cnn=1,
chunk_size=384)
#模拟EEG数据,批次大小为2,通道数为1,电极数量为32,时间点数为384
eeg = torch.randn(2,1, 32, 384)
# 通过EEGfuseNet模型生成假数据和深度融合编码
fake_X,deep_code = fusenet(eeg)
#实例化 EFDiscriminator 模型
discriminator = EFDiscriminator(in_channels=1,
num_electrodes=32,
hid_channels_cnn=1,
chunk_size=384)
#通过 EFDiscriminator 模型判别真假数据
p_real = discriminator(eeg)
p_fake = discriminator(fake_X)
5.trainer模块
提供了一套基于 Pytorch-lightning 构建的训练器,用于模型训练。这些训练器旨在处理从判别模型到生成模型的各种模型,并配备了对比学习和微调的功能。它们还能够在各种硬件配置上运行,从单 CPU、单 GPU 到多 GPU 。
(1)使用 ClassifierTrainer 的判别模型
from torcheeg.datasets import DEAPDataset
from torcheeg import transforms
from torcheeg.model_selection import KFoldGroupbyTrial
from torcheeg.datasets.constants.emotion_recognition.deap import \
DEAP_CHANNEL_LOCATION_DICT
from torch.utils.data import DataLoader
from torcheeg.models import CCNN
from torcheeg.trainers import ClassifierTrainer
import pytorch_lightning as pl
dataset = DEAPDataset(
io_path=f'./examples_trainers_1/deap',
root_path='./data_preprocessed_python',
offline_transform=transforms.Compose([
transforms.BandDifferentialEntropy(apply_to_baseline=True),
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True)
]),
online_transform=transforms.Compose(
[transforms.BaselineRemoval(),
transforms.ToTensor()]),
label_transform=transforms.Compose([
transforms.Select('valence'),
transforms.Binary(5.0),
]),
num_worker=8)
k_fold = KFoldGroupbyTrial(n_splits=10,
split_path='./examples_trainers_1/split',
shuffle=True,
random_state=42)
for i, (train_dataset, val_dataset) in enumerate(k_fold.split(dataset)):
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
model = CCNN(num_classes=2, in_channels=4, grid_size=(9, 9))
trainer = ClassifierTrainer(model=model,
num_classes=2,
lr=1e-4,
weight_decay=1e-4,
devices=1,
accelerator="gpu")
trainer.fit(train_loader, #训练数据集的数据加载器
val_loader, #验证数据集的数据加载器
max_epochs=50, #最大训练周期数,即模型将在整个训练数据集上迭代的次数
default_root_dir=f'./examples_trainers_1/model/{i}', #模型和日志文件的保存路径
callbacks=[pl.callbacks.ModelCheckpoint(save_last=True)], #在每个周期结束时保存最后一次训练模型
enable_progress_bar=True, #启用训练过程中的进度条显示
enable_model_summary=True, #启用模型摘要显示,在训练开始时会显示模型的结果摘要
limit_val_batches=0.0) #验证数据集的使用比例,设置为0.0表示使用完整的验证数据集进行验证。
score = trainer.test(val_loader, #验证数据集的数据加载器
enable_progress_bar=True, #启用评估过程中的进度条显示
enable_model_summary=True)[0] #获取trainer.test方法返回的结果
print(f'Fold {i} test accuracy: {score["test_accuracy"]:.4f}')
在 ClassifierTrainer 中,您可以指定设备以及要使用的设备数量。在trainer.fit函数中,可以传递pytorch_lightning中Trainer类支持的任何参数。如果您想修改训练程序,可以通过扩展训练器来实现:
class MyClassifierTrainer(ClassifierTrainer):
def training_step(self, batch, batch_idx): #用于定义训练步骤的方法,batch:批次数据,batch_idx:批次索引
x, y = batch #从批次数据中解包得到输入x和目标标签y
y_hat = self(x) #将输入x传递给模型self,得到模型的预测输出
# 使用交叉熵损失函数计算预测值与真实值之间的损失
loss = self.ce_fn(y_hat, y)
# 将损失值和训练过程中的其他指标记录到日志中,以便后续的可视化和分析
self.log("train_loss", #记录训练损失
self.train_loss(loss),
prog_bar=True, #进度条中显示损失值
on_epoch=False,
logger=False,
on_step=True)
for i, metric_value in enumerate(self.train_metrics.values()):
self.log(f"train_{self.metrics[i]}", #记录训练过程中的其他指标
metric_value(y_hat, y),
prog_bar=True,
on_epoch=False,
logger=False,
on_step=True)
return loss
通过参考相关文档,您还可以了解培训师模块支持的评估指标。通过进行一些调整,您可以让培训师报告准确性和 f1 分数等指标 。
trainer = ClassifierTrainer(model=model,
num_classes=2,
lr=1e-4,
weight_decay=1e-4,
metrics=['accuracy', 'recall', 'precision', 'f1score'],
accelerator="gpu")
(2)领域适应方法
基于脑电图的情感识别的一个具有挑战性的方面是跨主题问题。即使由相同的刺激引起,不同个体之间的脑电图信号模式的分布也可能发生分布变化。当应用于未知对象时,这种现象会对训练模型的性能产生负面影响。训练器模块通过提供大量领域适应算法来解决这个问题。这些算法使用来自已知受试者(源域)和未知受试者(目标域)的脑电图样本进行测试。他们使用特定的损失函数和训练策略来优化模型,以提取域不变特征或将知识从源域转移到目标域。 CORALTrainer、ADATrainer、DANNTrainer、DDCTrainer、DANTrainer等一系列跨域训练器可以处理不同的应用场景,帮助用户处理跨不同模型和数据集的跨域问题。
from torcheeg.datasets import DEAPDataset
from torcheeg import transforms
from torcheeg.model_selection import LeaveOneSubjectOut
from torcheeg.datasets.constants.emotion_recognition.deap import \
DEAP_CHANNEL_LOCATION_DICT
from torch.utils.data import DataLoader
from torcheeg.models import CCNN
from torcheeg.trainers import CORALTrainer
import pytorch_lightning as pl
dataset = DEAPDataset(
io_path=f'./examples_trainers_2/deap',
root_path='./data_preprocessed_python',
offline_transform=transforms.Compose([
transforms.BandDifferentialEntropy(apply_to_baseline=True),
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT, apply_to_baseline=True)
]),
online_transform=transforms.Compose(
[transforms.BaselineRemoval(),
transforms.ToTensor()]),
label_transform=transforms.Compose([
transforms.Select('valence'),
transforms.Binary(5.0),
]),
num_worker=8)
k_fold = LeaveOneSubjectOut(split_path='./examples_trainers_2/split')
class Extractor(CCNN):
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.flatten(start_dim=1)
return x
class Classifier(CCNN):
def forward(self, x):
x = self.lin1(x) #将x传递给模型的第一个线性层lin1,并进行线性变换。
x = self.lin2(x)
return x
for i, (train_dataset, val_dataset) in enumerate(k_fold.split(dataset)):
source_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
target_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
extractor = Extractor(in_channels=5, num_classes=2)
classifier = Classifier(in_channels=5, num_classes=2)
trainer = CORALTrainer(extractor=extractor,
classifier=classifier,
num_classes=2,
lr=1e-4,
weight_decay=0.0,
accelerator='gpu')
trainer.fit(source_loader,
target_loader,
target_loader,
max_epochs=50,
default_root_dir=f'./examples_trainers_2/model/{i}',
#指定了训练过程中回调函数列表
callbacks=[pl.callbacks.ModelCheckpoint(save_last=True)],
enable_progress_bar=True,
enable_model_summary=True,
limit_val_batches=0.0)
score = trainer.test(target_loader,
enable_progress_bar=True,
enable_model_summary=True)[0]
print(f'Fold {i} test accuracy: {score["test_accuracy"]:.4f}')
(3)生成模型
对于生成模型,我们提供了 VAE、GAN、Normalizing Flow 和 Diffusion Model 等模型的训练器。这些训练器的目的是训练模型生成紧密模仿真实分布的脑电图信号。我们还提供这些训练器的条件版本,允许使用类别作为类别驱动的脑电图样本生成的条件。
from torcheeg.trainers import CDDPMTrainer
from torcheeg.models import BCUNet
model = BCUNet(in_channels=4)
trainer = CDDPMTrainer(model, accelerator='gpu')
from torcheeg.trainers import CWGANGPTrainer
from torcheeg.models import BCGenerator, BCDiscriminator
g_model = BCGenerator(in_channels=128)
d_model = BCDiscriminator(in_channels=4)
trainer = CWGANGPTrainer(g_model,
d_model,
accelerator='gpu')
from torcheeg.trainers import CGlowTrainer
from torcheeg.models import BCGlow
model = BCGlow(in_channels=4)
TorchEEG 支持生成模型的常见评估指标,例如 FID。要使用这些指标,您需要向 Trainer 提供其他参数,例如 metric_extractor、metric_classifier 和 metric_num_features。详情请参阅相关文档。这是一个例子:
from torcheeg.trainers import CDDPMTrainer
from torcheeg.models import BCUNet
model = BCUNet(in_channels=4)
trainer = CDDPMTrainer(model, accelerator='gpu')
from torcheeg.trainers import CWGANGPTrainer
from torcheeg.models import BCGenerator, BCDiscriminator
g_model = BCGenerator(in_channels=128)
d_model = BCDiscriminator(in_channels=4)
trainer = CWGANGPTrainer(g_model,
d_model,
accelerator='gpu')
from torcheeg.trainers import CGlowTrainer
from torcheeg.models import BCGlow
model = BCGlow(in_channels=4)
trainer = CGlowTrainer(model, accelerator='gpu')
#TorchEEG 支持生成模型的常见评估指标,例如 FID。要使用这些指标,您需要向 Trainer 提供其他参数,
#例如 metric_extractor、metric_classifier 和 metric_num_features。详情请参阅相关文档。这是一个例子:
import torch.nn as nn
class Extractor(nn.Module):
def __init__(self, in_channels=4):
super().__init__()
self.conv1 = nn.Sequential(
nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(in_channels, 64, kernel_size=4, stride=1), nn.ReLU())
self.conv2 = nn.Sequential(nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(64, 128, kernel_size=4, stride=1),
nn.ReLU())
self.conv3 = nn.Sequential(nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(128, 256, kernel_size=4, stride=1),
nn.ReLU())
self.conv4 = nn.Sequential(nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(256, 64, kernel_size=4, stride=1),
nn.ReLU())
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.flatten(start_dim=1)
return x
class Classifier(nn.Module):
def __init__(self, in_channels=4, num_classes=2):
super().__init__()
self.conv1 = nn.Sequential(
nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(in_channels, 64, kernel_size=4, stride=1), nn.ReLU())
self.conv2 = nn.Sequential(nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(64, 128, kernel_size=4, stride=1),
nn.ReLU())
self.conv3 = nn.Sequential(nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(128, 256, kernel_size=4, stride=1),
nn.ReLU())
self.conv4 = nn.Sequential(nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(256, 64, kernel_size=4, stride=1),
nn.ReLU())
self.lin1 = nn.Linear(9 * 9 * 64, 1024)
self.lin2 = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.flatten(start_dim=1)
x = self.lin1(x)
x = self.lin2(x)
return x
g_model = BCGenerator(in_channels=128)
d_model = BCDiscriminator(in_channels=4)
extractor = Extractor()
classifier = Classifier()
# you may need to load state dict from your trained extractor, classifier
trainer = CWGANGPTrainer(g_model,
d_model,
metric_extractor=extractor,
metric_classifier=classifier,
metric_num_features=9 * 9 * 64,
metrics=['fid'],
accelerator='gpu')
6.使用Vanilla PyTorch训练模型
使用日志记录模块将输出记录在日志文件中
import os
import time
import logging
os.makedirs('./examples_vanilla_torch/log', exist_ok=True)
logger = logging.getLogger('Training models with vanilla PyTorch')
logger.setLevel(logging.DEBUG)
#创建一个日志记录器的控制台处理器
console_handler = logging.StreamHandler()
#获取当前时间,并将其格式化成字符串
timeticks = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
file_handler = logging.FileHandler(
os.path.join('./examples_vanilla_torch/log', f'{timeticks}.log'))
#将控制台处理器添加到日志记录器中。意味着日志消息将会输出到控制台,以便在命令行界面中查看。
logger.addHandler(console_handler)
#将文件处理器(file_handler)添加到日志记录器(logger)中。意味着日志消息将会被写入到一个文件中,以便后续查看和分析。
logger.addHandler(file_handler)
在所有模块中设置随机数种子对于确保重复运行时结果一致至关重要。
import random
import numpy as np
import torch
def seed_everything(seed):
random.seed(seed) #设置Python的随机数生成器种子,确保后续的随机数生成是确定的
np.random.seed(seed) #设置numpy库的随机数生成器的种子,确保后续的随机数生成是确定的
os.environ["PYTHONHASHSEED"] = str(seed) #设置Python哈希种子的环境变量,以确保在使用哈希表的场景中,哈希值的生成是确定的
torch.manual_seed(seed) #设置 PyTorch库的随机数生成器的种子,确保后续的随机数生成是确定的。
torch.cuda.manual_seed(seed) #设置 PyTorch库的CUDA 随机数生成器的种子,确保在使用GPU进行计算时,后续的随机数生成是确定的。
torch.backends.cudnn.deterministic = True #设置PyTorch库的cuDNN模块使用确定性算法,以确保在使用cuDNN加速时,结果的一致性
torch.backends.cudnn.benchmark = False #禁用 PyTorch库的cuDNN 模块的自动优化功能,以确保结果的一致性。
seed_everything(42)
(1)初始化数据集
使用 TorchEEG 支持的 DEAP 数据集。我们将 EEG 样本配置为 1 秒长,包含 128 个数据点。将 3 秒长的基线信号分为三部分并进行平均以建立试验的基线信号。在离线预处理过程中,我们将每个电极的脑电信号分为4个子带,并计算每个子带上的微分熵作为特征,然后对其进行去基线和网格映射。然后将预处理后的脑电信号存储在本地 IO 中。在在线处理的情况下,所有脑电图信号都被转换为张量以输入到神经网络中。
from torcheeg.datasets import DEAPDataset
from torcheeg import transforms
from torcheeg.datasets.constants.emotion_recognition.deap import \
DEAP_CHANNEL_LOCATION_DICT
dataset = DEAPDataset(
io_path=f'./examples_vanilla_torch/deap',
root_path='./tmp_in/data_preprocessed_python',
offline_transform=transforms.Compose([
transforms.BandDifferentialEntropy(apply_to_baseline=True),
transforms.BaselineRemoval(),
transforms.ToGrid(DEAP_CHANNEL_LOCATION_DICT)
]),
online_transform=transforms.ToTensor(),
label_transform=transforms.Compose([
transforms.Select('valence'),
transforms.Binary(5.0),
]),
num_worker=8)
(2)将数据集划分为训练样本和测试样本
使用每个受试者 5 倍交叉验证来划分数据集。在划分过程中,我们根据每个受试者的脑电图样本来分离训练集和测试集。我们将 4 倍分配给训练样本,将 1 倍分配给测试样本。
from torcheeg.model_selection import KFoldPerSubject
k_fold = KFoldPerSubject(n_splits=10,
split_path='./examples_vanilla_torch/split',
shuffle=True)
培训过程是可定制的。可以灵活地定义训练函数,以方便模型的训练和测试。这是一个基本示例
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# training process
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
#记录步长 = 数据加载器中的批次数量除以10
record_step = int(len(dataloader) / 10)
model.train()
for batch_idx, batch in enumerate(dataloader):
X = batch[0].to(device)
y = batch[1].to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % record_step == 0:
loss, current = loss.item(), batch_idx * len(X)
logger.info(f"Loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
return loss
# validation process
def valid(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
loss, correct = 0, 0
with torch.no_grad():
for batch in dataloader:
X = batch[0].to(device)
y = batch[1].to(device)
pred = model(X)
loss += loss_fn(pred, y).item()
#预测结果 pred 中正确预测的样本数量,并将其累加到变量 correct 中
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
loss /= num_batches
correct /= size
logger.info(
f"Valid Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {loss:>8f} \n"
)
return correct, loss
(3)定义模型并开始训练
最初,使用循环来访问每个交叉验证中的数据集。在每次交叉验证期间,我们都会初始化 CCNN 模型并建立超参数。例如,每个EEG样本包括来自4个子带的4通道特征,网格大小设置为9x9,等等。
随后,我们使用之前定义的训练函数对模型进行 50 个 epoch 的训练,并使用之前定义的验证函数在每个 epoch 的验证集上监控模型的性能。
import torch.nn as nn
from torcheeg.models import CCNN
from torcheeg.model_selection import train_test_split
from torch.utils.data.dataloader import DataLoader
loss_fn = nn.CrossEntropyLoss()
batch_size = 64
test_accs = []
test_losses = []
for i, (train_dataset, test_dataset) in enumerate(k_fold.split(dataset)):
# initialize model
model = CCNN(num_classes=2, in_channels=4, grid_size=(9, 9)).to(device)
# initialize optimizer
optimizer = torch.optim.Adam(model.parameters(),
lr=1e-4) # official: weight_decay=5e-1
# split train and val
train_dataset, val_dataset = train_test_split(
train_dataset,
test_size=0.2,
split_path=f'./examples_vanilla_torch/split{i}',
shuffle=True)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
epochs = 50
best_val_acc = 0.0
for t in range(epochs):
train_loss = train(train_loader, model, loss_fn, optimizer)
val_acc, val_loss = valid(val_loader, model, loss_fn)
# save the best model based on val_acc
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(),
f'./examples_vanilla_torch/model{i}.pt')
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# load the best model to test on test set
model.load_state_dict(torch.load(f'./examples_vanilla_torch/model{i}.pt'))
test_acc, test_loss = valid(test_loader, model, loss_fn)
# log the test result
logger.info(
f"Test Error {i}: \n Accuracy: {(100*test_acc):>0.1f}%, Avg loss: {test_loss:>8f}"
)
test_accs.append(test_acc)
test_losses.append(test_loss)
# log the average test result on cross-validation datasets
logger.info(
f"Test Error: \n Accuracy: {100*np.mean(test_accs):>0.1f}%, Avg loss: {np.mean(test_losses):>8f}"
)