下载地址:A Geolocation Databases Study | IEEE Journals & Magazine | IEEE Xplore
被引次数:195
Shavitt Y, Zilberman N. A geolocation databases study[J]. IEEE Journal on Selected Areas in Communications, 2011, 29(10): 2044-2056.
5. Discussion
在我们讨论我们的结果之前,重要的是要注意,本文是基于一个PoP提取算法,因此依赖于其准确性。我们在这里和之前的论文中描述的验证使我们相信结果是有效的。此外,每个独立数据库的结果在大多数情况下都很好,主要在比较数据库时出现问题,这加强了算法的正确性。测量误差可能导致同一PoP中不同位置的接口的统一,但由于我们使用保守的方法,更常见的误差是将一个PoP被我们的算法划分为多个组。后者会对地理位置数据库的评估产生一些影响:它不会影响IP级分析(如图8或14),但考虑PoP级分析,数字可能会略有改变,但总体结果将保持不变。
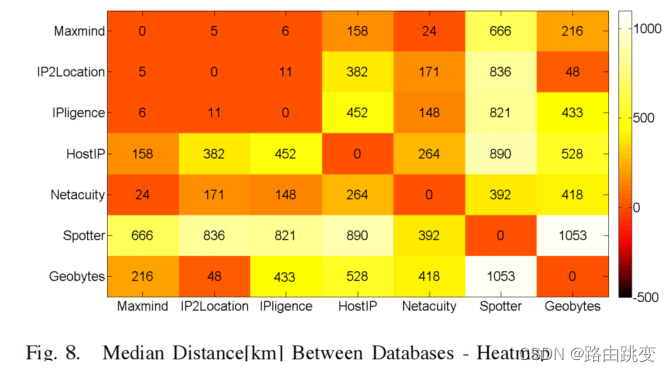
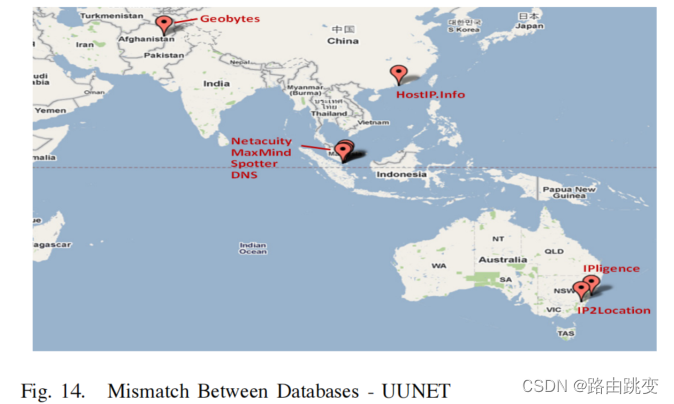
总的来说,我们可以看到,在一个区域级别(500公里)上,数据库大多是自洽的,这意味着它们将所有的PoP IP地址放在同一区域内。这对于许多具有位置感知能力的应用程序来说可能已经足够了。在城市一级,大多数数据库仍然在82%或以上以内保持一致。请注意,一些数据库(IPligence,GeoBytes,HostIP.Info)具有城市级粒度,即某个城市内的所有IP地址都放置在一个位置。其他数据库(如MaxMind)提供了次城市的粒度,因此,在40公里左右的收敛范围内,它们可能会错误地表现得更差。一些数据库(IP2Location和NetAcuity)提供城市粒度的纬度和经度,但也增加了一些国家的邮政编码或邮政编码。这些方法增加了地理位置的粒度,但不能在本工作中加以利用。
不同的独立数据库的区域级一致性与其聚合之间有很大的差异。而对于所有的数据库,除了PoPs,70%到90%有100%的IP在500公里范围内,除了HostIP.Info只有60%,聚合有100%的节点只有4%的情况。如果一个人愿意接受数据库中的总多数投票,那么在500公里的范围内,接近95%的PoPs将被成功定位。这一比例在城市一级下降到70%以下。
一些错误的位置很容易被用户发现。<