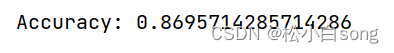目录
一、决策树概述
1.1决策树的组成
1.2构建决策树
1.3决策树的剪枝
1.4决策树的优点和缺点
二、决策树在计算机视觉中的应用
三、基于决策树的图像分类实例
一、决策树概述
决策树是一种非常流行的机器学习算法,它用树状图的形式来表示决策过程。决策树可以用于分类任务和回归任务,其基本思想是将复杂的决策拆解成一系列更简单的决策。
1.1决策树的组成
决策树主要由节点和边组成:
- 根节点:包含整个数据集。
- 内部节点:表示一个特征或属性。
- 叶节点(或终端节点):表示决策结果。
每一个内部节点代表一个测试(通常是某个特征的阈值),每一条边代表测试的一个结果,而每个叶节点代表一个预测分类或数值。
1.2构建决策树
决策树的构建通常基于递归分裂的方式:
- 选择最优特征:从当前数据集中选择最佳分裂特征。常用的方法包括信息增益(基于熵)、增益率和基尼不纯度。
- 分裂过程:基于选择的特征进行数据分裂,生成子节点。
- 递归构建:对分裂后的每个子数据集重复上述过程,直到满足停止条件,如节点数据量小于某个阈值、达到最大深度或节点的纯度已足够高。
1.3决策树的剪枝
为了防止过拟合,决策树在构建完成后常常需要进行剪枝。剪枝有两种基本类型:
- 预剪枝:在决策树完全生成之前就停止其生长。
- 后剪枝:先让树完全生长,然后去掉对最终预测准确度贡献不大的部分。
1.4决策树的优点和缺点
优点:
- 易于理解和解释,可以直观地展示决策过程。
- 对于数据的准备要求不高,不需要进行数据规范化。
- 能够同时处理数据型和类别型变量。
缺点:
- 容易过拟合,特别是当树的深度很大时。
- 对于有些类型的问题,如异或问题,决策树的效果不是很好。
- 对于连续性的字段切分不够理想,容易产生偏差。
二、决策树在计算机视觉中的应用
决策树在计算机视觉领域的应用广泛且多样,主要是因为其能够处理复杂的数据结构,同时提供易于解释的决策过程。以下是一些具体的应用场景:
图像分类:
- 决策树(及其集成版本,如随机森林和梯度提升树)经常被用于图像分类任务。通过训练模型识别和利用图像中的特征(如颜色、纹理、形状等),决策树可以有效地将图像分为不同的类别,例如区分不同类型的动物、植物或车辆。
物体检测与识别:
- 在物体检测任务中,决策树可以帮助确定图像中物体的位置和类别。例如,通过分析图像的特定区域和特征,决策树可以预测该区域是否包含某个特定的物体,并确定其边界框(bounding box)。
面部识别与分析:
- 决策树被用于面部识别系统中,帮助识别和验证个体身份。此外,它们也可以用于分析面部表情,判断个体的情绪状态。在这些应用中,决策树通过评估面部的各种特征(如眼睛、嘴巴的位置和大小)来进行分类。
图像分割:
- 决策树可以应用于图像分割,即将图像划分为多个区域或对象。例如,在医学成像中,决策树可以帮助识别和隔离不同的组织类型,对疾病的诊断提供支持。
动作识别:
- 在视频或实时监控中,决策树可以用于识别和分类不同的人体动作。通过分析连续帧之间的变化,决策树可以帮助系统理解人体动作的模式。
图像恢复和超分辨率:
- 在图像恢复应用中,决策树有助于从损坏或低分辨率的图像中恢复出更清晰的图像。这通常涉及到对缺失或损坏的像素进行预测和填充。
在实际应用中,决策树通常与其他算法相结合,如深度学习网络,以充分利用各自的优点,提高整体的准确性和鲁棒性。例如,可以先用深度学习模型从图像中提取高级特征,然后使用决策树进行高效的分类决策。这种方法结合了深度学习的特征学习能力和决策树的快速决策能力。
三、基于决策树的图像分类实例
这里我们将使用Python的scikit-learn库来实现决策树分类器,同时使用skimage库来处理图像数据。我们将使用非常流行的MNIST手写数字数据集来进行分类。
首先,需要确保已经安装了以下Python库:
numpymatplotlib(用于图像显示)sklearn(提供决策树算法和数据预处理工具)skimage(图像处理)
现在,我们将编写一个程序来加载数据集,预处理图像,并使用决策树进行分类。程序的步骤如下:
- 加载MNIST数据集。
- 预处理图像数据(例如,归一化)。
- 划分数据为训练集和测试集。
- 使用决策树模型进行训练。
- 评估模型性能。
代码:
这段代码将完成基本的图像分类任务。可以根据需要调整决策树的参数,比如max_depth来控制树的深度,或者min_samples_split来控制节点分裂所需的最小样本数。这些调整可以帮助优化模型的表现,减少过拟合的风险。
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import numpy as np
def load_data():
# 加载MNIST数据集
mnist = fetch_openml('mnist_784', version=1)
# 数据集包含70000张28x28的图像
data = mnist['data']
target = mnist['target']
return data, target
def preprocess_data(data):
# 将数据归一化到0-1
data_normalized = data / 255.0
return data_normalized
def train_decision_tree(X_train, y_train):
# 创建决策树模型
clf = DecisionTreeClassifier(random_state=42)
# 训练模型
clf.fit(X_train, y_train)
return clf
def evaluate_model(clf, X_test, y_test):
# 使用测试集评估模型
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
def main():
# 加载和预处理数据
data, target = load_data()
data = preprocess_data(data)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=42)
# 训练决策树模型
clf = train_decision_tree(X_train, y_train)
# 评估模型
evaluate_model(clf, X_test, y_test)
if __name__ == "__main__":
main()

为了更直观地理解决策树模型在MNIST数据集上的分类效果,我们可以添加一些可视化的元素,包括显示一些图像样本和它们的预测结果,以及决策树的可视化。以下是完整的Python代码,其中增加了图像样本的显示和决策树结构的可视化功能:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
def load_data():
# 加载MNIST数据集
mnist = fetch_openml('mnist_784', version=1)
# 数据集包含70000张28x28的图像
# 转换为numpy数组确保后续处理的兼容性
data = np.array(mnist['data'], dtype=np.float32) # 确保数据类型为float32
target = np.array(mnist['target'], dtype=np.int64) # 将标签转换为整数
return data, target
def preprocess_data(data):
# 将数据归一化到0-1
data_normalized = data / 255.0
return data_normalized
def train_decision_tree(X_train, y_train):
# 创建决策树模型
clf = DecisionTreeClassifier(random_state=42)
# 训练模型
clf.fit(X_train, y_train)
return clf
def evaluate_model(clf, X_test, y_test):
# 使用测试集评估模型
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
return y_pred
def plot_sample_images(X_test, y_test, y_pred):
# 显示9张图像和它们的预测标签
plt.figure(figsize=(10, 10))
for i in range(9):
plt.subplot(3, 3, i + 1)
image = X_test[i].reshape(28, 28) # 确保数据以正确的形状重塑
plt.imshow(image, cmap='gray')
plt.title(f"True: {y_test[i]}, Pred: {y_pred[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()
def plot_decision_tree(clf):
# 可视化决策树(显示前4层)
plt.figure(figsize=(20,10))
plot_tree(clf, max_depth=4, filled=True, fontsize=10, feature_names=[f"pixel_{i}" for i in range(784)])
plt.show()
def main():
# 加载和预处理数据
data, target = load_data()
data = preprocess_data(data)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=42)
# 训练决策树模型
clf = train_decision_tree(X_train, y_train)
# 评估模型
y_pred = evaluate_model(clf, X_test, y_test)
# 可视化样本图像及预测结果
plot_sample_images(X_test, y_test, y_pred)
# 可视化决策树
plot_decision_tree(clf)
if __name__ == "__main__":
main()