以pytorch pipeline并行为例,分析各kernel的耗时占比及性能瓶颈
- 1.生成pipeline并行的测试代码
- 2.pipeline profing
- 3.生成nsys2json.py代码
- 4.将nsys sqlite格式转chrome json格式
- 5.生成耗时成分统计代码
- 6.统计耗时成分
- 7.耗时成分如下:
- 8.查看GPU PCIE链路状态
- 9.链路状态如下
- 10.Nsight Compute查看Timeline
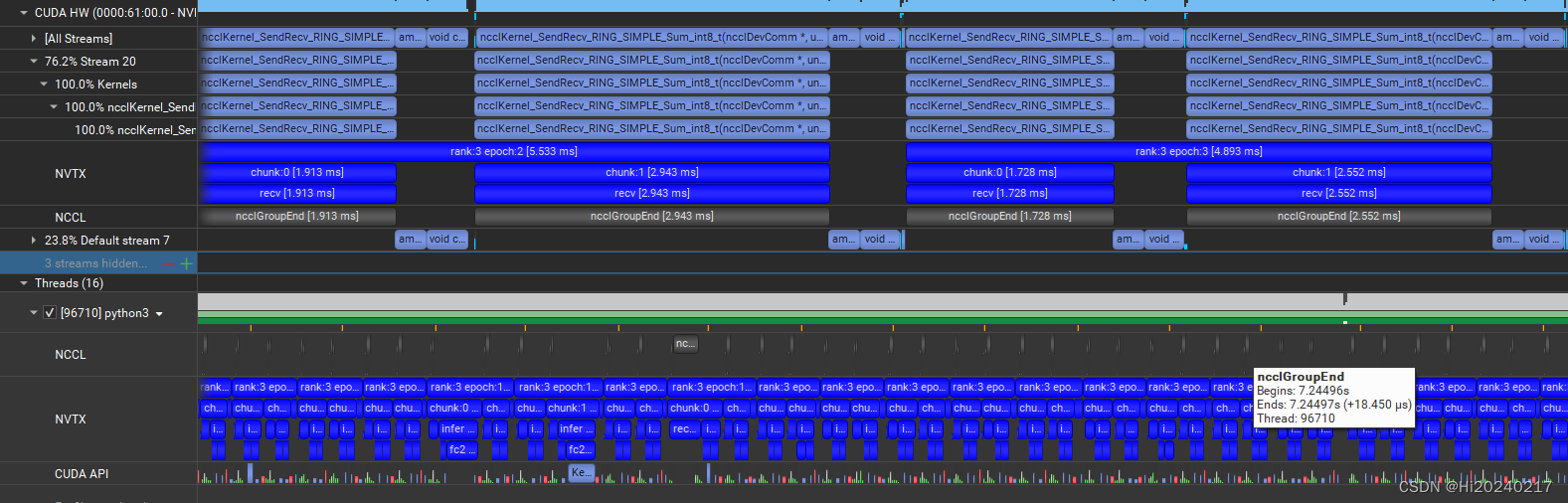
以下DEMO演示了,pipeline多卡并行时,如何分析各kernel的耗时占比
如果nccl kernel占比过大,说明GPU有效利用率不高
主要步骤如下:
- 1.nsys profile 运行4卡pipeline并行demo
- 2.用开源的nsys2json.py将nsys的sqlite-schema转成chrome event格式
- 3.分析chrome event格式,按设备统计各kernel的耗时占比
1.生成pipeline并行的测试代码
tee pp_demo_fps.py <<-'EOF'
import os
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
import torch.distributed as dist
from torch.distributed import ReduceOp
import threading
import queue
import time
import argparse
import nvtx
class FeedForward(nn.Module):
def __init__(self,hidden_size,ffn_size):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(hidden_size, ffn_size,bias=False)
self.fc2 = nn.Linear(ffn_size, hidden_size,bias=False)
def forward(self, input):
with nvtx.annotate(f"fc1"):
out=self.fc1(input)
with nvtx.annotate(f"fc2"):
out=self.fc2(out)
return out
parser = argparse.ArgumentParser(description="")
parser.add_argument('--hidden_size', default=512, type=int, help='')
parser.add_argument('--ffn_size', default=1024, type=int, help='')
parser.add_argument('--seq_len', default=512, type=int, help='')
parser.add_argument('--batch_size', default=8, type=int, help='')
parser.add_argument('--world_size', default=4, type=int, help='')
parser.add_argument('--device', default="cuda", type=str, help='')
parser.add_argument('--chunk_size', default=1, type=int, help='')
args = parser.parse_args()
hidden_size = args.hidden_size
ffn_size = args.ffn_size
seq_len = args.seq_len
batch_size = args.batch_size
world_size = args.world_size
device = args.device
chunk_size = args.chunk_size
def tp_mode():
torch.random.manual_seed(1)
dist.init_process_group(backend='nccl')
world_size = torch.distributed.get_world_size()
rank=rank = torch.distributed.get_rank()
local_rank=int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(local_rank)
device = torch.device("cuda",local_rank)
model = FeedForward(hidden_size,ffn_size)
model.eval()
input = torch.rand((batch_size, seq_len, hidden_size),dtype=torch.float32).half().to(device)
model=model.half().to(device)
chunks=torch.split(input,chunk_size,dim=0)
for epoch in range(32):
with nvtx.annotate(f"rank:{rank} epoch:{epoch}"):
all_output=[]
snd_reqs=None
for idx,chunk in enumerate(chunks):
with nvtx.annotate(f"chunk:{idx}"):
with nvtx.annotate(f"wait_snd"):
if snd_reqs:
snd_reqs.wait()
snd_reqs=None
if rank==0:
with nvtx.annotate(f"infer"):
out=model(chunk)
else:
with nvtx.annotate(f"recv"):
torch.distributed.recv(chunk,rank-1)
with nvtx.annotate(f"infer"):
out=model(chunk)
if rank==world_size-1:
all_output.append(out.clone())
else:
with nvtx.annotate(f"isend"):
snd_reqs = torch.distributed.isend(out,rank+1)
if rank==world_size-1:
with nvtx.annotate(f"concat"):
out=torch.cat(all_output,dim=0)
if __name__ == "__main__":
num_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1
is_distributed = num_gpus > 1
if is_distributed:
tp_mode()
EOF
2.pipeline profing
export NCCL_DEBUG=info
export NCCL_SOCKET_IFNAME=ens8
export NCCL_IB_DISABLE=1
rm cuda_profing_report.* -f
nsys profile --stats=true -o cuda_profing_report.nsys-rep -f true -t cuda,nvtx --gpu-metrics-device=0,1,2,3 \
torchrun -m --nnodes=1 --nproc_per_node=4 pp_demo_fps --hidden_size 512 \
--ffn_size 4096 --seq_len 512 --batch_size 16 --world_size 4 --chunk_size 8
3.生成nsys2json.py代码
tee nsys2json.py <<-'EOF'
import sqlite3
import argparse
import json
from pathlib import Path
import re
from collections import defaultdict
_PID_TO_DEVICE = None
# Code adapted from https://raw.githubusercontent.com/chenyu-jiang/nsys2json/main/nsys2json.py
def parse_args():
parser = argparse.ArgumentParser(description='Convert nsight systems sqlite output to Google Event Trace compatible JSON.')
parser.add_argument("-f", '--filename', help="Path to the input sqlite file.", required=True)
parser.add_argument("-o", "--output", help="Output file name, default to same as input with .json extension.")
parser.add_argument("-t", "--activity-type", help="Type of activities shown. Default to all.", default=["kernel", "nvtx-kernel"], choices=['kernel', 'nvtx', "nvtx-kernel", "cuda-api"], nargs="+")
parser.add_argument("--nvtx-event-prefix", help="Filter NVTX events by their names' prefix.", type=str, nargs="*")
parser.add_argument("--nvtx-color-scheme", help="""Color scheme for NVTX events.
Accepts a dict mapping a string to one of chrome tracing colors.
Events with names containing the string will be colored.
E.g. {"send": "thread_state_iowait", "recv": "thread_state_iowait", "compute": "thread_state_running"}
For details of the color scheme, see links in https://github.com/google/perfetto/issues/208
""", type=json.loads, default={})
args = parser.parse_args()
if args.output is None:
args.output = Path(args.filename).with_suffix(".json")
return args
class ActivityType:
KERNEL = "kernel"
NVTX_CPU = "nvtx"
NVTX_KERNEL = "nvtx-kernel"
CUDA_API = "cuda-api"
def munge_time(t):
"""Take a timestamp from nsys (ns) and convert it into us (the default for chrome://tracing)."""
# For strict correctness, divide by 1000, but this reduces accuracy.
return t / 1000.
# For reference of the schema, see
# https://docs.nvidia.com/nsight-systems/UserGuide/index.html#exporter-sqlite-schema
def parse_cupti_kernel_events(conn: sqlite3.Connection, strings: dict):
per_device_kernel_rows = defaultdict(list)
per_device_kernel_events = defaultdict(list)
for row in conn.execute("SELECT * FROM CUPTI_ACTIVITY_KIND_KERNEL"):
per_device_kernel_rows[row["deviceId"]].append(row)
event = {
"name": strings[row["shortName"]],
"ph": "X", # Complete Event (Begin + End event)
"cat": "cuda",
"ts": munge_time(row["start"]),
"dur": munge_time(row["end"] - row["start"]),
"tid": "Stream {}".format(row["streamId"]),
"pid": "Device {}".format(row["deviceId"]),
"args": {
# TODO: More
},
}
per_device_kernel_events[row["deviceId"]].append(event)
return per_device_kernel_rows, per_device_kernel_events
def link_pid_with_devices(conn: sqlite3.Connection):
# map each pid to a device. assumes each pid is associated with a single device
global _PID_TO_DEVICE
if _PID_TO_DEVICE is None:
pid_to_device = {}
for row in conn.execute("SELECT DISTINCT deviceId, globalPid / 0x1000000 % 0x1000000 AS PID FROM CUPTI_ACTIVITY_KIND_KERNEL"):
assert row["PID"] not in pid_to_device, \
f"A single PID ({row['PID']}) is associated with multiple devices ({pid_to_device[row['PID']]} and {row['deviceId']})."
pid_to_device[row["PID"]] = row["deviceId"]
_PID_TO_DEVICE = pid_to_device
return _PID_TO_DEVICE
def parse_nvtx_events(conn: sqlite3.Connection, event_prefix=None, color_scheme={}):
if event_prefix is None:
match_text = ''
else:
match_text = " AND "
if len(event_prefix) == 1:
match_text += f"NVTX_EVENTS.text LIKE '{event_prefix[0]}%'"
else:
match_text += "("
for idx, prefix in enumerate(event_prefix):
match_text += f"NVTX_EVENTS.text LIKE '{prefix}%'"
if idx == len(event_prefix) - 1:
match_text += ")"
else:
match_text += " OR "
per_device_nvtx_rows = defaultdict(list)
per_device_nvtx_events = defaultdict(list)
pid_to_device = link_pid_with_devices(conn)
# eventType 59 is NvtxPushPopRange, which corresponds to torch.cuda.nvtx.range apis
for row in conn.execute(f"SELECT start, end, text, globalTid / 0x1000000 % 0x1000000 AS PID, globalTid % 0x1000000 AS TID FROM NVTX_EVENTS WHERE NVTX_EVENTS.eventType == 59{match_text};"):
text = row['text']
pid = row['PID']
tid = row['TID']
per_device_nvtx_rows[pid_to_device[pid]].append(row)
assert pid in pid_to_device, f"PID {pid} not found in the pid to device map."
event = {
"name": text,
"ph": "X", # Complete Event (Begin + End event)
"cat": "nvtx",
"ts": munge_time(row["start"]),
"dur": munge_time(row["end"] - row["start"]),
"tid": "NVTX Thread {}".format(tid),
"pid": "Device {}".format(pid_to_device[pid]),
"args": {
# TODO: More
},
}
if color_scheme:
for key, color in color_scheme.items():
if re.search(key, text):
event["cname"] = color
break
per_device_nvtx_events[pid_to_device[pid]].append(event)
return per_device_nvtx_rows, per_device_nvtx_events
def parse_cuda_api_events(conn: sqlite3.Connection, strings: dict):
pid_to_devices = link_pid_with_devices(conn)
per_device_api_rows = defaultdict(list)
per_device_api_events = defaultdict(list)
# event type 0 is TRACE_PROCESS_EVENT_CUDA_RUNTIME
for row in conn.execute(f"SELECT start, end, globalTid / 0x1000000 % 0x1000000 AS PID, globalTid % 0x1000000 AS TID, correlationId, nameId FROM CUPTI_ACTIVITY_KIND_RUNTIME;"):
text = strings[row['nameId']]
pid = row['PID']
tid = row['TID']
correlationId = row['correlationId']
per_device_api_rows[pid_to_devices[pid]].append(row)
event = {
"name": text,
"ph": "X", # Complete Event (Begin + End event)
"cat": "cuda_api",
"ts": munge_time(row["start"]),
"dur": munge_time(row["end"] - row["start"]),
"tid": "CUDA API Thread {}".format(tid),
"pid": "Device {}".format(pid_to_devices[pid]),
"args": {
"correlationId": correlationId,
},
}
per_device_api_events[pid_to_devices[pid]].append(event)
return per_device_api_rows, per_device_api_events
def _find_overlapping_intervals(nvtx_rows, cuda_api_rows):
mixed_rows = []
for nvtx_row in nvtx_rows:
start = nvtx_row["start"]
end = nvtx_row["end"]
mixed_rows.append((start, 1, "nvtx", nvtx_row))
mixed_rows.append((end, -1, "nvtx", nvtx_row))
for cuda_api_row in cuda_api_rows:
start = cuda_api_row["start"]
end = cuda_api_row["end"]
mixed_rows.append((start, 1, "cuda_api", cuda_api_row))
mixed_rows.append((end, -1, "cuda_api", cuda_api_row))
mixed_rows.sort(key=lambda x: (x[0], x[1], x[2]))
active_intervals = []
result = defaultdict(list)
for _, event_type, event_origin, orig_event in mixed_rows:
if event_type == 1:
# start
if event_origin == "nvtx":
active_intervals.append(orig_event)
else:
for event in active_intervals:
result[event].append(orig_event)
else:
# end
if event_origin == "nvtx":
active_intervals.remove(orig_event)
return result
def link_nvtx_events_to_kernel_events(strings: dict,
pid_to_device: dict[int, int],
per_device_nvtx_rows: dict[int, list],
per_device_cuda_api_rows: dict[int, list],
per_device_cuda_kernel_rows: dict[int, list],
per_device_kernel_events: dict[int, list]):
result = {}
for device in pid_to_device.values():
event_map = _find_overlapping_intervals(per_device_nvtx_rows[device], per_device_cuda_api_rows[device])
correlation_id_map = defaultdict(dict)
for cuda_api_row in per_device_cuda_api_rows[device]:
correlation_id_map[cuda_api_row["correlationId"]]["cuda_api"] = cuda_api_row
for kernel_row, kernel_trace_event in zip(per_device_cuda_kernel_rows[device], per_device_kernel_events[device]):
correlation_id_map[kernel_row["correlationId"]]["kernel"] = kernel_row
correlation_id_map[kernel_row["correlationId"]]["kernel_trace_event"] = kernel_trace_event
for nvtx_row, cuda_api_rows in event_map.items():
kernel_start_time = None
kernel_end_time = None
for cuda_api_row in cuda_api_rows:
if "kernel" not in correlation_id_map[cuda_api_row["correlationId"]]:
# other cuda api event, ignore
continue
kernel_row = correlation_id_map[cuda_api_row["correlationId"]]["kernel"]
kernel_trace_event = correlation_id_map[cuda_api_row["correlationId"]]["kernel_trace_event"]
if "NVTXRegions" not in kernel_trace_event["args"]:
kernel_trace_event["args"]["NVTXRegions"] = []
kernel_trace_event["args"]["NVTXRegions"].append(nvtx_row["text"])
if kernel_start_time is None or kernel_start_time > kernel_row["start"]:
kernel_start_time = kernel_row["start"]
if kernel_end_time is None or kernel_end_time < kernel_row["end"]:
kernel_end_time = kernel_row["end"]
if kernel_start_time is not None and kernel_end_time is not None:
result[nvtx_row] = (kernel_start_time, kernel_end_time)
return result
def parse_all_events(conn: sqlite3.Connection, strings: dict, activities=None, event_prefix=None, color_scheme={}):
if activities is None:
activities = [ActivityType.KERNEL, ActivityType.NVTX_CPU, ActivityType.NVTX_KERNEL]
if ActivityType.KERNEL in activities or ActivityType.NVTX_KERNEL in activities:
per_device_kernel_rows, per_device_kernel_events = parse_cupti_kernel_events(conn, strings)
if ActivityType.NVTX_CPU in activities or ActivityType.NVTX_KERNEL in activities:
per_device_nvtx_rows, per_device_nvtx_events = parse_nvtx_events(conn, event_prefix=event_prefix, color_scheme=color_scheme)
if ActivityType.CUDA_API in activities or ActivityType.NVTX_KERNEL in activities:
per_device_cuda_api_rows, per_device_cuda_api_events = parse_cuda_api_events(conn, strings)
if ActivityType.NVTX_KERNEL in activities:
pid_to_device = link_pid_with_devices(conn)
nvtx_kernel_event_map = link_nvtx_events_to_kernel_events(strings, pid_to_device, per_device_nvtx_rows, per_device_cuda_api_rows, per_device_kernel_rows, per_device_kernel_events)
traceEvents = []
if ActivityType.KERNEL in activities:
for k, v in per_device_kernel_events.items():
traceEvents.extend(v)
if ActivityType.NVTX_CPU in activities:
for k, v in per_device_nvtx_events.items():
traceEvents.extend(v)
if ActivityType.CUDA_API in activities:
for k, v in per_device_cuda_api_events.items():
traceEvents.extend(v)
if ActivityType.NVTX_KERNEL in activities:
for nvtx_event, (kernel_start_time, kernel_end_time) in nvtx_kernel_event_map.items():
event = {
"name": nvtx_event["text"],
"ph": "X", # Complete Event (Begin + End event)
"cat": "nvtx-kernel",
"ts": munge_time(kernel_start_time),
"dur": munge_time(kernel_end_time - kernel_start_time),
"tid": "NVTX Kernel Thread {}".format(nvtx_event["tid"]),
"pid": "Device {}".format(pid_to_device[nvtx_event["pid"]]),
"args": {
# TODO: More
},
}
traceEvents.append(event)
return traceEvents
def nsys2json():
args = parse_args()
conn = sqlite3.connect(args.filename)
conn.row_factory = sqlite3.Row
strings = {}
for r in conn.execute("SELECT id, value FROM StringIds"):
strings[r["id"]] = r["value"]
traceEvents = parse_all_events(conn, strings, activities=args.activity_type, event_prefix=args.nvtx_event_prefix, color_scheme=args.nvtx_color_scheme)
# make the timelines appear in pid and tid order
traceEvents.sort(key=lambda x: (x["pid"], x["tid"]))
for i in traceEvents:
if i["name"] is None:
i["name"]="null"
with open(args.output, 'w') as f:
json.dump(traceEvents, f,indent=4)
if __name__ == "__main__":
nsys2json()
EOF
4.将nsys sqlite格式转chrome json格式
python3 nsys2json.py -f cuda_profing_report.sqlite -o prof.json
5.生成耗时成分统计代码
tee paser_prof.py <<-'EOF'
import json
import re
import os
import sys
import numpy as np
with open(sys.argv[1],"r") as f:
traceEvents=json.load(f)
traceEventsPerDevice={}
for event in traceEvents:
pid=event["pid"]
if pid not in traceEventsPerDevice:
traceEventsPerDevice[pid]=[]
if event["cat"]=="cuda":
epoch_str=event["args"]['NVTXRegions'][0]
match = re.match(".*epoch:(\d*)", epoch_str)
epoch=int(match.group(1))
#过滤掉warmup阶段
if epoch>4:
traceEventsPerDevice[pid].append((event["name"]+"_"+event["tid"],event["ts"],event["dur"],epoch))
for k,v in traceEventsPerDevice.items():
v.sort(key=lambda x: x[1], reverse=False)
for device,v in traceEventsPerDevice.items():
print(f"-----------------------------{device}-----------------------------")
totalDurPerKernel={}
durPerKernel={}
marginPerKernel={}
for ev in v:
name,ts,dur,epoch=ev
if name not in totalDurPerKernel:
totalDurPerKernel[name]=0
durPerKernel[name]=[]
marginPerKernel[name]={"beg":ts}
totalDurPerKernel[name]+=dur
durPerKernel[name].append(dur)
marginPerKernel[name]["end"]=ts
total_percent=0
for name,dur in sorted(totalDurPerKernel.items(), key=lambda d:d[1], reverse = True):
total_dur=marginPerKernel[name]["end"]-marginPerKernel[name]["beg"]
total_percent+=(dur/total_dur)
print("{:7.2f} min:{:7.2f} max:{:7.2f} avg:{:7.2f} {}".format(
dur/total_dur,
np.min(durPerKernel[name]),
np.max(durPerKernel[name]),
np.mean(durPerKernel[name]),
name))
print("{:7.2f}".format(total_percent))
EOF
6.统计耗时成分
python3 paser_prof.py prof.json
7.耗时成分如下:
-----------------------------Device 0-----------------------------
0.88 min:1481.39 max:3153.01 avg:2304.01 ncclKernel_SendRecv_RING_SIMPLE_Sum_int8_t_Stream 20
0.16 min: 285.22 max: 661.51 avg: 438.63 Kernel_Stream 7
0.14 min: 238.11 max: 601.51 avg: 372.28 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_tn_Stream 7
1.18
-----------------------------Device 1-----------------------------
0.69 min:1413.80 max:2148.40 avg:1815.43 ncclKernel_SendRecv_RING_SIMPLE_Sum_int8_t_Stream 24
0.43 min: 611.49 max:1828.39 avg:1130.83 ncclKernel_SendRecv_RING_SIMPLE_Sum_int8_t_Stream 20
0.12 min: 233.79 max: 748.87 avg: 319.80 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_tn_Stream 7
0.11 min: 276.61 max: 448.48 avg: 289.69 Kernel_Stream 7
1.35
-----------------------------Device 2-----------------------------
0.64 min:1425.58 max:1902.06 avg:1669.10 ncclKernel_SendRecv_RING_SIMPLE_Sum_int8_t_Stream 24
0.49 min: 625.38 max:2027.44 avg:1294.33 ncclKernel_SendRecv_RING_SIMPLE_Sum_int8_t_Stream 20
0.12 min: 283.36 max: 324.23 avg: 309.24 Kernel_Stream 7
0.10 min: 233.76 max: 273.22 avg: 257.85 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_tn_Stream 7
1.34
-----------------------------Device 3-----------------------------
0.78 min:1437.31 max:2588.53 avg:2040.18 ncclKernel_SendRecv_RING_SIMPLE_Sum_int8_t_Stream 20
0.12 min: 323.55 max: 324.13 avg: 323.83 Kernel_Stream 7
0.10 min: 269.47 max: 274.24 avg: 270.91 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_tn_Stream 7
0.01 min: 28.22 max: 29.12 avg: 28.64 CatArrayBatchedCopy_Stream 7
1.01
8.查看GPU PCIE链路状态
nvidia-smi --query-gpu="gpu_name,pcie.link.gen.current,pcie.link.width.current" --format=csv -i 0,1,2,3
9.链路状态如下
name, pcie.link.gen.current, pcie.link.width.current
NVIDIA GeForce RTX 3090, 1, 16
NVIDIA GeForce RTX 3090, 1, 16
NVIDIA GeForce RTX 3090, 1, 16
NVIDIA GeForce RTX 3090, 1, 16
- 当前为GEN1 X16: 理论带宽4GB/s
10.Nsight Compute查看Timeline