入门介绍
需求:提取文本中某类字符
传统方法:遍历每个字符,判断其是否在ASCII码中某种类型得编码范围内,代码量大,效率不高
正则表达式(RegExp, regular expression):处理文本的利器,是对字符串执行模式匹配的技术。java\javascript\php等语言都支持。
//假设爬虫获取内容
String content = "...";
//1 先创建一个Pattern模式对象,即一个正则表达式对象
//提取所有英文单词
Pattern pattern = Pattern.compile("[a-zA-Z]+");
//提取所有数字
Pattern pattern = Pattern.compile("[0-9]+");
//提取所有数字和英文单词
Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");
//提取百度热搜的标题
Pattern pattern = Pattern.compile("<a target=\"_blank\" title=\"(\\S*)\"");
//提取文本中的ip地址
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+")
//2 创建一个匹配器对象,按照模式到content中匹配,找到返回true,否则false
Matcher matcher = pattern.matcher(content);
//3 开始循环匹配
while (matcher.find()) {
//匹配内容,文本,放到m.group(0)
System.out.println("找到:" + matcher.group(0)); //热搜标题使用group(1)
}
正则底层实现
matcher.find():定位满足指定规则的字符串,将找到的子字符串的开始缩影记录到matcher的属性int[] groups中groups[0];把结束索引+1的值记录到groups[1],同时记录为oldLast的值,作为下次find开始的位置。
group(int group):根据groups[2 * group]和groups[2 * group + 1]从content截取字符串(前闭后开)并返回。
String regStr = "\\d\\d\\d\\d"; //4个任意数字
group(0) //返回content中[group[0], group(1))的子字符串
String regStr = "(\\d\\d)(\\d\\d)"; //表示分组1和2
//另外还会把第1组匹配到的子字符串的开始索引和结束索引+1的值记录到group[2]和group[3];第2组对应值记录到group[4]和group[5]...
group(0) //返回匹配到的子字符串,content中[group[0], group(1))的子字符串
group(1) //返回匹配到的子字符串中的第1组,content中[group[2], group[3])的子字符串
group(2) //返回匹配到的子字符串中的第2组,content中[group[4], group[5])的子字符串
基本语法
元字符
转义符\\
使用正则表达式去检索某些特殊字符的时候,需要用到转义符号,将下一字符标记为特殊字符,如:. * + ( ) $ / \ ? [ ] ^ { }。Java正则表达式中\\代表其它语言中的一个\。
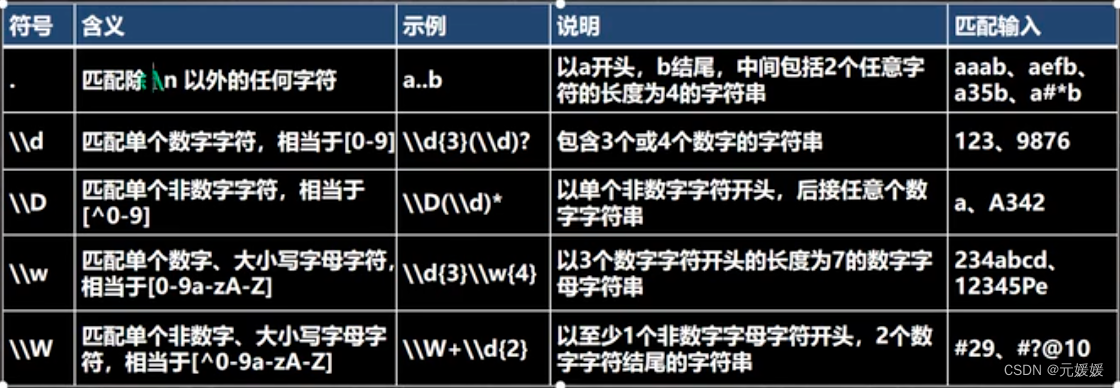
字符匹配符

选择匹配符

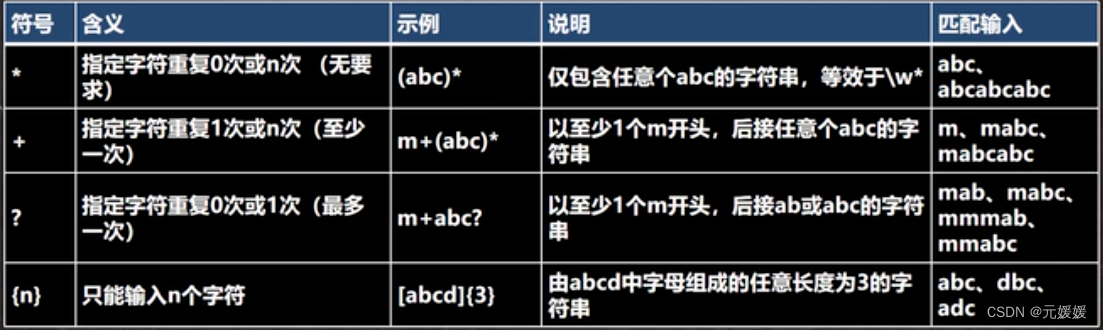
限定符
指定其前面的字符和组合项连续出现多少次

定位符
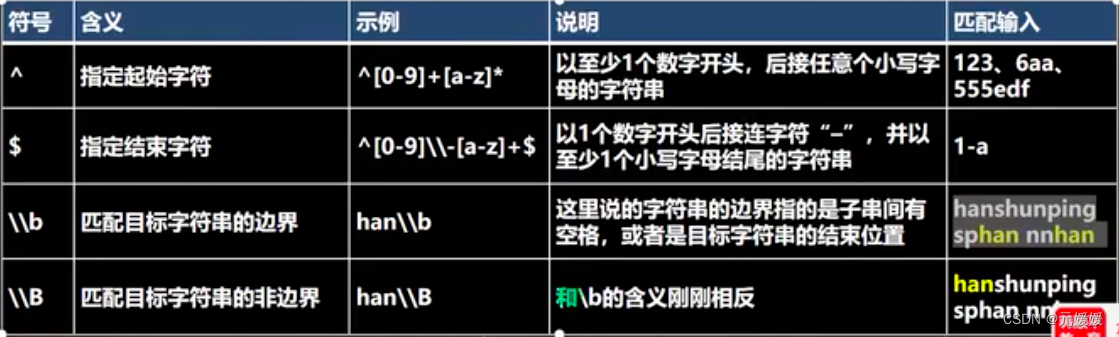
e.g.^[0-9]+[a-z]$ 以至少1个数字作为行开头,后接至少一个小写字母作为行结尾的字符串,如可以匹配"123abc",不可匹配"123abc12"
分组
捕获分组

String regStr = "(?<g1>\\d\\d)(?<g2>\\d)(?<g3>\\d)";
group("g1") //返回匹配到的子字符串中的第1组
group("g2") //返回匹配到的子字符串中的第2组
group("g3") //返回匹配到的子字符串中的第3组
非捕获分组

非贪婪匹配
Java正则表达式默认贪婪匹配
?当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?“只匹配单个"o”,而"o+“匹配所有"o”。
※三个常用类
Pattern
Pattern对象时一个正则表达式对象。Pattern类没有公共构造方法。要创建一个Pattern对象,调用其公共静态方法,接收一个正则表达式作为它的第一个参数,它返回一个Pattern对象。Pattern r = Pattern.compile(pattern);
Pattern类的方法
boolean isMatch = Pattern.matches(String pattern, String content); // 整体匹配,用于验证输入字符串是否满足条件使用
String content = "hello, world!";
String pattern = "hello"; //false
String regStr = "hello.*"; //true .*后跟 *任意个 .任意字符
Matcher
Matcher对象是对输入字符串进行解释和匹配的引擎。Matcher也没有公共构造方法。需要调用Pattern对象的matcher方法来获得一个Matcher对象。

PatternSyntaxException
非强制异常,表示一个正则表达式模式中的语法错误。
※分组、捕获、反向引用
分组:用圆括号组成一个比较复杂的匹配模式,一个个圆括号部分我们可以看作是一个子表达式/一个分组。
捕获:把正则表达式中子表达式/分组匹配的内容,保存到内存中以数字编号或显示命名的组里,0代表整个正则式,从左向右分组号依次是1,2…
反向引用:圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,称为反向引用。这种引用可以在正则表达式内部或外部,内部反向引用\\分组号,外部反向引用$分组号。
(\\d)\\1 //要匹配两个连续的相同数字
(\\d)\\1{4} //匹配连续5个相同数字
(\\d)(\\d)\\2\\1 //匹配个位与千位相同,十位与百位相同的数
String类中的正则表达式
替换
pubilc String replaceAll(String regex, String replacement)
content.replaceAll("JDK1\\.3|JDK1\\.4", "JDK);
判断
pubilc boolean matches(String regex)
phone.matches("13(8|9)\\d{8}"); //验证手机号以138或139开头
分割
pubilc String[] split(String regex)
content = "hello#abc-jack12smith~北京":
String[] split = content.split("#|-|~|\\d+")
for (String s : split) {
System.out.println(s);
}
/**
* hello
* abc
* jack
* smith
* 北京
*/