性能分析方法
自底向上:通过监控硬件及操作系统性能指标(cpu、内存、磁盘、网络等硬件资源的性能指标)来分析性能问题(配置、程序问题)
- 先检查,再下药
自顶向下:通过生成负载来观察被测试的系统性能,比如响应时间、吞吐量;然后从请求点由外及里一层层分析,从而找到性能问题所在
- 根据症状来诊断,再下药
单机性能分析与调优
传统的架构如下:
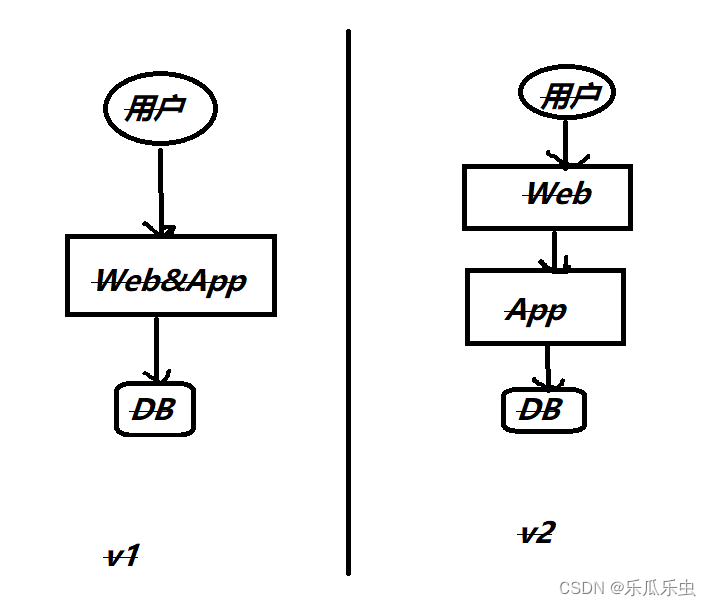
问题出处答题分3部分:web服务、app(应用)服务、或者db;我们web服务、app服务一般运用在中间件上,操作系统来管理计算机硬件设备(cpu、内存、磁盘、网卡等设备)以上就是我们的分析对象
性能分析流程
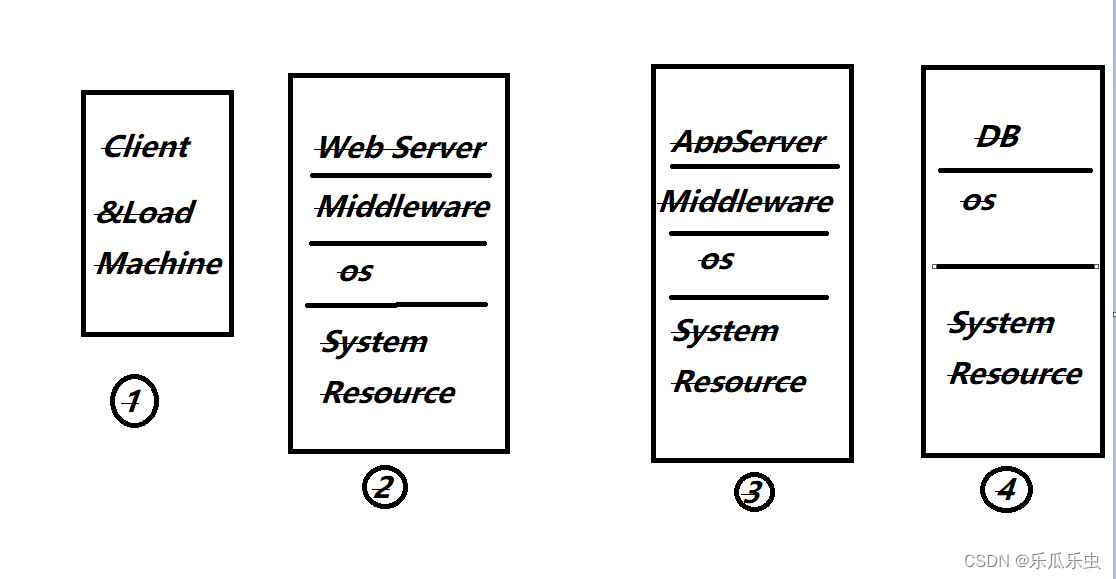
Client:客户浏览器,比如E、Chrome等访问Web页面。
Load Machine:是生成负载的机器,即我们的压测机器用来模拟用户负载。
Web Server:提供 Web 服务的服务器,即我们访问的 Web 页面由此服务器提供服务:般部署在 Nginx、Apache 等中间件上。
Middleware:中间件,比如Tomcat、Jboss、WebLogic等OS:操作系统,Windows或者 Linux。
System Resource:系统资源,比如CPU、内存、磁盘、网络等
AppServer:应用服务,实现业务逻辑,比如生成订单,生成统计报表
DB:数据库服务器,比如 Oracle、Mysql、SqiServer 等。
1号关注的地方
RT:响应时间,一笔业务的完成时间。
TPS:每秒完成的事务数。
CPU:CPU 性能指标,比如 CPU 利用率、CPU 负载。
Mem:内存性能指标,比如可用物理内存、虚拟内存使用率。
Diks:Disk 性能指标,比如 Disk Time、I0 等待。
Network:网络指标,如带宽使用率,任务队列长度。
2号关注的地方
TCP Connections:指TCP 连接数,可以用netstat 命令统计得到
Thread Pool:中间件建立的线程池,监控线程状态。
JVM:JVM 性能指标,比如GC情况,Heap 使用情况。
Load Average:CPU负载队列长度:
3号关注的地方
DB Connections:中间件与数据库之间建立的连接数及连接状态
4号关注的地方
DBTime:消耗在数据库操作上的CPU 时间。
TOP SQL:按内存占用由多到少排序 SQL,按CPU 占用由多到少排序 SQL。
PGA、SGA:PGA\SGA 内存使用情况。
| 序号 | 步骤名称 | 说明 |
| 1 | 检查RT | 模拟用户发起负载后,采用自项向下的方式首先分析RT(响应时间) |
| 2 | 检查TPS | TPS 大时 RT 小,说明性能良好 |
| 3 | 检查负载机资源消耗 | 检查CPU使用率,CPU负载(LoadAverage)确认是用户CPU占用高还是系统CPU占用高? 前提:确认测试脚本没有性能问题,不会造成结果统计的不准确检查内存使用情况,确认并发内存泄露风险,不会造成结果统计的不准确 |
| 4 | 判下负载机是否有性能问题 | 排除负载机的性能问题,确保测试结果可参考 |
| 5 | 检查 Web 服务器的资源消耗 | (1)检查CPU使用率,确认用户CPU与系统CPU占用情况 (2)检查内存使用情况 |
| 6 | 确认是否 Web 服务器瓶颈 | 判断是否是 Web 服务器硬件性能瓶颈。 |
| 7 | 检查中间件配置 | 确认是否是此配置问题 |
| 8 | 检查APP服务器资源消耗 | 关注 CPU、内存、磁盘、IO,判断是否是APp服务器硬件性能瓶颈 |
| 9 | 数据库服务器资源消耗分析 | (1)CPU消耗,CPU 载 对DB不熟悉的读者可以找DBA帮忙监控分析 |
| 10 | 是否是 DB性能问题 | 由监控结果来判断是否是DB性能问题 |
| 11 | 是否 SQL 问题 | (1)定位最不合理的 SQL 占比 (2)索引是否正常引用 (3)检查共享SQL是否合理范围 (4)检查解析是否合理。 (5)检查数据 ER 结构是否合理 (6)检查数据热点问题 (7)检查数据分布是否合理 (8)检查碎片整理等 |
| 12 | 其他 | 比如网络阻塞、磁盘 IO 瓶颈、热点等 |
上面列举一种典型的分析思路,可以看到性能测试结果分析是考验综合知识的活动,设计了多方面的知识,包括不限于下方7个部分
- 硬件知识(CPU、RAM、Disk、Net)
- 系统知识(OS——Linux、Windows)
- 中间件知识(JVM、Tomcat、Jboss、WebLogic、Websphere等)
- 数据库知识(Mysql、Sql Server、Oracle、DB2、Sysbase等)
- 网络知识,如截包分析
- 程序知识,如Java程序,如何让程序更高效
- 架构知识,如:SSH架构
系统性能关注点
System Resource(系统资源)
系统资源包括CPU、内存、存储介质等这些硬件资源的利用是互相影响的。
- cpu利用率高
- 计算量大,比如运算、连接查询、数据统计。
- 非空闲等待,比如IO等待、资源争用(同一资源被不同线程请求,而此资源又需要一致性,只能前一个释放后一个再访问,这样导致的等待)。
- 过多的系统调用,系统调用即调用操作系统提供的程序接口,比如Java项目中写日会调用系统接口进行日志写操作:这样会导致系统CPU使用率比较高。
- 过多的中断,中断是 CPU用来响应请求的机制,比如键盘的输入、鼠标的点击等会产生中断,中断是通知CPU有任务需要响应,CPU停下正在执行的程序来响应当前的中断
- 内存吃紧
- 内存吃紧的原因就比CPU要简单得多,多数是过多的页交换与内存泄露。
- 我们知道内存是用来缓解磁盘与 CPU之间的同步差,在内存中我们会缓存一些数据,但存的容量是有限的,内存不够用来存储需要的数据时,操作系统会把原内存中的部分内容放掉(移除或者存入磁盘),然后把需要的内容载入,这个过程就是页交换。比如读取一个文件,比如我们常见的大文件下载功能。
- Java程序运行在JVM之上,JVM 的内存设置也是有限制的,有时候JVM 堆内存中有些象无法回收,久而久之就没有空间来容纳新的对象,最后导致IVM 崩溃,这就是内存溢出,收不了的这种现象就是内存泄露,这往往是由于程序原因引起的。
- Windows 需要保留一定的物理内存供统使用,Windows为了缓解内存不足的情况设计了一个虚拟内存机制,把部分物理磁盘空虚拟成内存使用。如果已经开始使用虚拟内存,多数是物理内存吃紧了。
- Linux则是尽可能地利用上所有的内存,比如开辟内存空间用来缓存数据。但是对于imnux 来说,如果已经开始频繁地使用虚拟内存,也说明物理内存吃紧了。简单粗暴的方式是加内存、加机器。最根本的方法是减少不必要的调用,减少内存资源占用。
- 磁盘繁忙,数据读写频繁
- 磁盘繁忙我们知道,磁介质磁盘的读写是物理动作,所以速度受限。如果频繁地对磁盘进行读写,因为磁盘的瓶颈导致的CPU等待的情况会激增。虽然现在了 SSD,但 SSD 相当昂贵,所以磁盘的瓶颈问题是相对突出的问题。
- 网络流量过大
- 高并发系统由于访问量大,带宽需求会比较大,导致网络拥堵。比-个PV(访问一个页面的单位)100K,同一时刻10万用户在访问,那么此时占用带宽大就是:100K*100000=977MB,换算成bits是7.8Gbits。
OS操作系统
操作系统要关注的是:
- 系统负载:Windows是Processor Queue Length,Linux是load average。意思就是 CPU的任务队列长度。CPU任务队列是由操作系统来控制的,所以是操作系统层面的监控项。现在多数系统都已经是多CPU多核的服务器了,在计算这个1oad average时要考虑CPU的个数与核数,建议 CPU使用率 70%以下。
- 系统连接数的控制,操作系统为了安全会限制外部及内部建立TCP连接的数量,在服务器环境我们需要提供大量的服务,TCP连接数量会很大,此时需要修改这个TCP连接数的限制。
- 缓存:一般操作系统都会有缓存机制,内存不够时还会有虚拟内存机制,这些都是用来提高 IO 效率的手段。
DB(数据库)
当前我们绝大多数应用系统都离不开关系型数据库的支持,系统性能的好坏很大一部分由数据库系统、应用系统数据库设计及如何使用数据库来决定的。简单地把这些应用系统为OLTP(On-Line TransactionProcessing联机事务处理系统)与OLAP(联机分析处理n-Line Analytical Processing,OLAP)两种,不同的系统应用决定了不同的设计方法,不同设计方法将表现出不同的性能。表10-3为OLTP与OLAP的粗略比较:
| OLTP | OLAP | |
| 用户 | 普通用户(员工、客户) | 高级管理人员(决策人员) |
| 功能 | 日常操作 | 统计分析 |
| DB 设计 | 面向应用 | 面向主题 |
| 数据 | 当前数据、面向细节 | 过程数据、多维分析 |
| 存取 | 少量读与写 | 大量读 |
| 工作单位 | 简单事务 | 复杂分析查询统计 |
| 用户数 | 多 | 少 |
| DB 大小 | MB 到 GB | GB 到 TB |
对于OLAP类型常规办法是:
- 预处理,比如物化、多维数据,先把数据放在后台统计,生成一个较小的数据集,然后程序对物化后的数据进行访问来减小系统压力。
- 分而治之,比如并行查询。
- 优化语句提高效率。
当前我们面对的系统大多数都是OLTP类型,经常要关注的是:
- 慢查询
- 大事务
- 死锁
- DB Time 高
- 磁盘 IO等待时间
- 对于一些热点数据,可以置入内存,提高响应速度,常见的缓存如 memcache、redis等,Hibermate 这种ORM模型的框架也提供了二级缓存支持。
Middleware(中间件)
- J2EE架构的程序多数运行在 Tomcat、Jboss、WebLogic、WebSphere、Jetty 等中间件上。作为Java应用程序容器,中间件有其特定的指标项。
- JVM:中间件是运行在JVM之上,我们需要监控JVM 堆内存使用情况。包括GC 频率线程状态等。Full GC操作是对堆空间进行全面回收,此时是停止响应用户请求的,所以频繁地Fu GC会影响响应时间。监控线程运行状态可以帮助我们了解到线程的繁忙程度,一般我们要关注状态是Blocked状态的线程,此状态说明当前线程运行相对较慢,长时间的Blocked 可能是因为线程阻塞(任务繁重或者响应慢),甚至造成死锁。
- Thread pool:中间件在接收用户请求时为了节省建立连接、销毁连接的资源消耗,设计建立线程池,需要监控其使用情况,一般当超过一定的使用率时可以考虑加大连接池数量。
- DB Connections pool(数据库连接数):为了节省程序与DB建立连接、释放连接的资源消耗,设计了数据库连接池,在测试执行过程中也需要监控其使用情况,当超过一定的使用率时可以考虑加大连接数数量。
不管是 ThreadPool 还是 DB Connections Pool,我们都可以通过 netstat 命令统计到其连接数。
AppServer(应用程序)
- 当前的系统都采用分层开发的方式,各层分别完成不同工作;分层不但用来简化工作的复杂度,还用工程思想来组织系统开发运作,方便协作,不同的人员各司其职完成自己善长的部分,层次清晰,方便维护及管理。
- 不同的架构当然也存在着不同的性能短板,抽象层次越高(底层封装程度越高),开发效率越高,对开发人员要求越低(基础功能底层已经实现,开发人员专注业务实现),性能风险越大。往往性能风险都会集中在这一层次。我们常见的SSH(Spring Struts Hibemate)架构是MVC 模型
- 展现层 View(V)负责展现内容,Controller(C)负责请求接收,前台逻辑跳转;ModeM)层实现业务逻辑,返回数据;数据层负责与数据库打交道。这里我们把业务逻辑与数据访问归类到应用程序部分,展现层归到Web服务层(WebServer)。
Web Server(web服务)
按照分层开发的理论来讲,这一层仅仅是页面跳转控制与结果的道染。当前前端技术的多样化,展现的内容也更加丰富,内容多也导致了一些前端性能问题关注的问题如下。
- 页面Size:动态数据、CSS、JS、图片等的大小
- 隐藏的,无用的数据传输:开发过程中为了方便,我们会继承一些基类,我们需要考虑成本,最好不要有大对象生成。还有我们在做SQL查询时,只查询需要的字段,对于无用字段排除掉,避免不必要的数据传输。
对于 Web 服务性能优化的方向一般是:
- 页面静态化,比如新浪的新闻,先进行静态化然后提供访问,减小DB负担。
- 减小页面 Size;
- 图片变得更小;
- CSS 合并;
- JS 精减等;
- 压缩页面,从图10-4中可以看到Accept-Encoding:gzip,这就是对页面内容进行了压缩。
- 客户端缓存图片、样式及 JS。
- 砍掉无用请求,无用数据传输。
- 对数据做异步处理,事情分为多步,先完成优先级高的事情。这就是异步的好处,体验提高,用户停留时间更长,刺激更多消费。大家可以试用下去哪儿网站,我们查询机票都是一部分一部分加载,采用动态加载方式,尽量值传输动态数据,尽量异步处理请求(多个请求分开传输)
- 智能DNS及CDN加速,让响应数据离用户更近,回避缓解网络瓶颈
程序优化
低效代码优化,这里说的低效代码排除架构问题,纯粹是程序逻辑及算法低比如逻辑混乱、调用继承不合理、内存泄漏等。常用的解决方法如下:
- 表单压缩
- 压缩表单,减少网络的传输量达到提高响应速度的效果
- 局部刷新
- 页面中采取局部内容获取的方式,减少向服务器的请求,服务器由于负载小当然就能更快地响应,或者说客户的体验会更好。
- 仅取所需
- 只向服务器请求必要的内容,只向客户端发送必要的表单内容,减少网络传输,减轻服务器负担。
- 逻辑清淅
- 程序逻辑清晰方便维护,方便分析问题;不做错误及多余调用,资源请求后能够释放。
- 谨慎继承
- 开发过程中要对系统架构了解,特别是一些基类、公共组件,合理利用,减少大对数像产生的可能。
- 程序算法优化
- 试着分析程序,是否需要用算法来提高程序效率,比如我们可以用二分法来做物料计划(不用扫描整个库存数据与物料需求做对比,我们只需要找到满足需要的库存数据即可以停止遍历,一般来说这样效率至少可以提高一个数量级,当然这也取决于库存数量与需求的物料种类及数量)。
- 批处理
- 对于大批量的数据处理,最好能够做成批处理,不会因为单次操作而影响系统的正常使用
- 延迟加载
- 对于大对象的展示可以采用延迟加载的方式,层层递进的显示明细。比如我们分页显示列表内容,往往我们只显示主表的内容,附表的内容在查看明细时才去请求。
- 防止内存泄露
- 内存泄露是由于对象无法回收造成的,特别是一些长生命周期的对象风险较大。比如用户登录成功后,系统往往会把用户的状态保存在Session中,如果同一用户再次登录时(前一次并没登出)我们会在Session中检查一下此用户是否已经在线,如果是就更新Session 状态,不是就记录 Session 信息。另外我们还会做一个过滤器,对于长时间不活动的用户进行&ession 过期处理。笔者以前就碰到系统不做这样的处理,最后导致内存溢出。
- 减少大对象引用
- 防止在程序中声明及实例化大对象,不能为了方便而设计出大对象。比如有些工程师为了图方便,会把用户的功能权限、数据权限、用户信息统统都放在一个对象中,而实际上系统中多数用户并不一定都要用这些信息,所以这个对象中存放这么多信息就是浪费,自然占用的堆空间就大;我们可以拆分成多个更小的类。
- 防止争用死锁
- 一般出现在线程同步的场景,不同线程对同一资源的争用通常会导致等待,处理不当会导致死锁。可以适当采用监听器、观察者模式来处理这类场景,核心思想就是同步向异步转化。如果是OLTP系统,在程序优化的背后还有数据库的优化,涉及表结构、索引、存储过程及内存分配等。
- 索引:编写合理的SQL,尽量利用索引;
- 索引是大家通常都会注意的性能点,但往往是有心注意,无心使用。
- 存储过程:为了减少数据传输到应用程序层面,一般会在数据库层面利用存储过程来完成数据的逻辑运算,只需要回传少量结果给应用层。当然现在分布式数据库并不主张用储过程,数据库仅仅用来做存储,从物理设计、并发处理方面来提升性能。
- 内存分配:合理地分配数据库内存,比如PGA与SGA的设置;当然我们在操作数据库的同时也要避免冲击内存的底限,比如我们对于大数据不提供 Order by 的操作,避免 PGA区域被占满,即使允许排序,也要限定查询条件来减小数据集的范围。
- 并行:使用多个进程或者线程来处理任务,比如Oracle中的并行查询,Tomcat的线程池。当然也要避免并行时的数据争用而导致的死锁;OLTP类型系统并行及数据争用的机率比较大,尤其要注意提高程序效率,减少争用对象的等待;程序要防止互锁(甲需要资源 A、B,乙需要 B、A;此时甲占有A等待 B,正好乙占有B等待A,此时就容
易互锁)。 - 异步:比如用 MQ(消息中间件)来解藕系统之间的依赖关系,减少阻塞。
- 使用好的设计模式来优化程序,比如用回调来减少阻塞,使用监听器来阻塞依赖。
- 选择合适的 I0 模式,比如 NIO、AIO 等。
配置优化
提起配置优化,大家应该在脑子里立即闪现JVM、连接池、线程池、缓存机制、CDN等优化手段,这些优化提高了资源利用率,最大限度地压榨出服务器性能。
- JVM 配置优化:合理地分配堆与非堆的内存,配置适合的内存回收算法,提高系统服务
能力。 - 连接池:数据库连接池可以节省建立连接与关闭连接的资源消耗。
- 线程池:通过缓存线程的状态来减少新建线程与关闭线程的开销,一般是在中间件中进行配置,比如在 Tomcat 的 server.xml 文件中进行配置。
- 缓存机制:通过数据的缓存来减少磁盘的读写压力,缩小存储与CPU的效率差。
数据库连接池优化
数据库连接池存在的意义是让连接复用,通过建立一个数据库连接池(缓冲区)以及套连接使用、分配、管理策略,使得该连接池中的连接可以得到高效、安全的复用,避免数据库连接频繁建立、关闭的开销。
关心的数据库连接问题:
- 连接池的配置参数。
- 连接池配置多少连接合适。
- 监控连接池。
具体可以参考下这里
线程优化
线程优化也属于配置优化
线程池优化
为什么要有线程池?
线程池是为了减少创建新线程和销毁线程的系统资源消耗
系统性能差一般有以下两种明显的表现:
- 第一种是CPU使用率不高,用户感觉交易响应时间很长
- 可能是由于系统的某一小部分造成了瓶颈,导致了所有的请求都在等待,线程池的数量开的太小,导致所有的请求都在排队等待进入线程池,因为没有可线程使用,所以这个交易请求一直在排队,导致交易响应时间很长。
- 第二种是CPU使用率很高,用户感觉交易响应时间很长
- 可能是硬件资源不够,也可能是应用系统中产生了较多的大对象,还可能是程序算法等问题
cpu处理能力
线程池配置多少与CPU处理能力相关,比如CPU一核心每秒能处理10个任务(请求),那么一颗4核心的CPU每秒理论上能处理40个任务。在同一时刻CPU最多只能处理4个任务(只有4个核心),所以理论上线程池配置4个连接。