Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!"
数据可视化(四):Pandas技术的高级操作案例,豆瓣电影数据也能轻松分析!
目录
- 数据可视化(四):Pandas技术的高级操作案例,豆瓣电影数据也能轻松分析!
- 1. 创建一个Series
- 2. 采用以下值和索引创建Series
- 3. 显示DataFrame列
- 4. 采用loc对DataFrame行进行切片
- 5. 采用iloc对DataFrame行进行切片
- 6. 采用loc对DataFrame进行行和列切片
- 7. 采用iloc对DataFrame进行行和列切片
- 8. iloc 和 loc 的区别
- 9. 使用时间索引创建空 DataFrame,包含'A'、'B'、'C'三列,用0值填充
- 10. 改变 DataFrame 行、列的排序
- 11. 更改 DataFrame 指定列的数据类型
- 12. 两个 DataFrame 相加
- 13. 删除数据
- 14. 获取行、列的平均值
- 15. 计算行、列的和
- 16. 对索引值进行排序
- 17. 对列名进行排序
- 18. 对数据进行排序
- 19. map()、applymap()使用
- 20. 采用“豆瓣电影数据”进行分析
- 附录:
import numpy as np
import pandas as pd
1. 创建一个Series
名字为Countries
内容由以下列表组成
[“India”, “Canada”, “Germany”]
# 编程
import pandas as pd
import numpy as np
# 创建一个列表
country_list = ["India", "Canada", "Germany"]
# 使用列表创建一个Series对象,并设置名字为"Countries"
countries_series = pd.Series(country_list, name="Countries")
# 打印Series
print(countries_series)

2. 采用以下值和索引创建Series
values = [“India”, “Canada”, “Australia”, “Japan”, “Germany”, “France”]
inds = [“IND”, “CAN”, “AUS”, “JAP”, “GER”, “FRA”]
# 编程
import pandas as pd
# 定义值和索引
values = ["India", "Canada", "Australia", "Japan", "Germany", "France"]
inds = ["IND", "CAN", "AUS", "JAP", "GER", "FRA"]
# 使用指定的值和索引创建Series对象
countries_series = pd.Series(values, index=inds)
# 打印Series
print(countries_series)

3. 显示DataFrame列
数据如下创建:
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
# 1、显示Score列
df[["Score"]]

# 2、显示Color、Score两列
df[["Color","Score"]]
# 3、显示为整数值的列
int_columns = df.select_dtypes(include=['int64']).columns
# 打印整数类型的列
int_columns
# 4、显示非字符串的列
non_string_columns = df.select_dtypes(exclude=[object]).columns
print("非字符串的列:")
print(non_string_columns)

4. 采用loc对DataFrame行进行切片
数据如下创建:
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
采用loc切片
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
# 1、显示Penelope行
df.loc[["Penelope"],:]
# 2、显示Cornelia, Jane, Dean三行
df.loc[["Cornelia","Jane","Dean"],:]

# 3、显示Aaron到Dean行(包括Dean行)
df.loc["Aaron":"Dean",:]

5. 采用iloc对DataFrame行进行切片
数据如下创建:
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
采用iloc切片
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
# 1、显示Penelope行
df.iloc[[3],:]
# 2、显示Cornelia, Jane, Dean三行
df.iloc[[3,0,4],:]
# 3、显示Aaron到Dean行(包括Dean行)
df.iloc[2:5,:]

6. 采用loc对DataFrame进行行和列切片
采用loc切片
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
# 1、选取Penelope行,Color、Height两列
df.loc[["Penelope"],["Color","Height"]]
# 2、选取Penelope到Christina三行,Color到Height三列
df.loc[["Penelope"],["Color","Height"]]
# 3、选取Jane、Penelope、Cornelia三行,Age、State两列
df.loc[["Jane","Penelope","Cornelia"],["Age","State"]]

7. 采用iloc对DataFrame进行行和列切片
采用iloc切片
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
# 1、选取Penelope行,Color、Height两列
df.iloc[[3],[1,3]]
# 2、选取Penelope到Christina三行,Color到Height三列
df.iloc[3:6,1:4]
# 3、选取Jane、Penelope、Cornelia三行,Age、State两列
df.iloc[[0,3,6],[0,5]]
注意loc左闭右闭,iloc左闭右开

8. iloc 和 loc 的区别
- loc可以进行布尔选择
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
display(df)
# 1、返回Age小于30的Age、Color、Height三列,采用loc
df.loc[ df["Age"] < 30,["Age","Color","Height"]]
# 2、返回Age小于30的Age、Color、Height三列,采用iloc
selected_data = df[df["Age"]<30].iloc[:, [0, 1, 3]]
selected_data

# 3、返回Height在120到170之间,Score大于3的所有列,采用loc
df[ (df["Height"]<=170) & (df["Height"] >=120)].loc[ df["Score"]>3, :]
# 4、返回Height在120到170之间,Score大于3的所有列,采用iloc
# 重置索引
df_new = df.reset_index()
df_new
# 创建Height在120到170之间且Score大于3的布尔索引
height_condition = (df_new['Height'] >= 120) & (df_new['Height'] <= 170)
score_condition = df_new['Score'] > 3
combined_condition = height_condition & score_condition
# 使用布尔索引获取满足条件的行的标签(即索引)
indices = df_new[combined_condition].index
# 使用iloc和这些索引来选择满足条件的所有行和所有列
selected_data = df_new.iloc[indices]
# 打印选取的数据
selected_data.set_index("index")

9. 使用时间索引创建空 DataFrame,包含’A’、‘B’、'C’三列,用0值填充
提示:pd.date_range()函数;datatime库;pd.fillna()函数
# 编程
import datetime
# 创建一个日期范围,比如从2024年1月1日到2024年1月5日
date_range = pd.date_range(start='2024-01-01', end='2024-01-05')
# 使用日期范围作为索引,并用0初始化'A', 'B', 'C'列
df = pd.DataFrame(0, index=date_range, columns=['A', 'B', 'C'])
# 打印结果
df

10. 改变 DataFrame 行、列的排序
# 编程
data = {'C':[0,1,2], 'A':[6,8,10], 'B':[3,-1,7]}
df = pd.DataFrame(data,index=['c','b','a'])
display(df)
# 1、改变列顺序从C A B到A B C
df[["A","B","C"]]

# 编程
data = {'C':[0,1,2], 'A':[6,8,10], 'B':[3,-1,7]}
df = pd.DataFrame(data,index=['c','b','a'])
display(df)
# 2、改变行顺序从c b a到a b c
df.loc[["a","b","c"],:]

11. 更改 DataFrame 指定列的数据类型
# 编程
df = pd.DataFrame(data = {'Age': [30, 20, 22, 40, 32, 28, 39],
'Color': ['Blue', 'Green', 'Red', 'White', 'Gray', 'Black', 'Red'],
'Food': ['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'Height': [165, 70, 120, 80, 180, 172, 150],
'Score': [4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index = ['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])
display(df)
display(df.dtypes)
# 1、将Height列数据从int64改为float64
df["Height"] = df["Height"].astype(np.float64)
df.dtypes
# 2、将Score列数据从float64改为str
df["Score"] = df["Score"].astype(str)
df.dtypes

12. 两个 DataFrame 相加
# 编程
df1 = pd.DataFrame({'Age': [30, 20, 22, 40],
'Height': [165, 70, 120, 80],
'Score': [4.6, 8.3, 9.0, 3.3],
'State': ['NY', 'TX', 'FL', 'AL']},
index=['Jane', 'Nick', 'Aaron', 'Penelope'])
df2 = pd.DataFrame({'Age': [32, 28, 39],
'Color': ['Gray', 'Black', 'Red'],
'Food': ['Cheese', 'Melon', 'Beans'],
'Score': [1.8, 9.5, 2.2], 'State': ['AK', 'TX', 'TX']},
index=['Dean', 'Christina', 'Cornelia'])
# df1和df2合,按列排序
# axis=0, df1和df2合,按列排序
df3 = pd.concat([df1,df2],axis=0)
df3

13. 删除数据
# 编程
df = pd.DataFrame({
'Country': ['China', 'China', 'India', 'India', 'America','Japan', 'China', 'India'],
'Income': [10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age': [50, 43, 34, 40, 25, 25, 45, 32]
})
display(df)
# 1、删除第3行
df1 = df.drop(2)
df1

# 2、删除Income列
column_to_drop = 'Income' # 替换为实际的列名
df2 = df.drop(columns=[column_to_drop],axis=1)
df2
# 3、删除Age列,原DataFrame发生改变,提示inplace参数
df.drop("Age",axis=1,inplace=True)
df

14. 获取行、列的平均值
# 编程
df = pd.DataFrame([[10, 20, 30, 40], [7, 14, 21, 28], [5, 5, 0, 0]],
columns=['Apple', 'Orange', 'Banana', 'Pear'],
index=['Basket1', 'Basket2', 'Basket3'])
display(df)
# 1、按列统计均值
df.mean()
# 2、按行统计均值
df.mean(axis=1)
# 3、增加一列'Basket mean',该列为行均值
df["Basket mean"] = df.mean(axis=1)
df
# 4、增加一行'Fruit mean',该行为列均值
df.loc["Fruit mean",:] = df.mean()
df

15. 计算行、列的和
# 编程
df = pd.DataFrame([[10, 20, 30, 40], [7, 14, 21, 28], [5, 5, 0, 0]],
columns=['Apple', 'Orange', 'Banana', 'Pear'],
index=['Basket1', 'Basket2', 'Basket3'])
display(df)
# 1、按列统计总和
df.sum()
# 2、按行统计总和
df.sum(axis=1)
# 3、增加一列'Basket sum',该列为行总和
df["Basket sum"] = df.sum(axis=1)
df
# 4、增加一行'Fruit sum',该行为列总和
df.loc["Fruit sum",:] = df.sum()
df

16. 对索引值进行排序
# 编程
df = pd.DataFrame({'DateOfBirth': ['1986-11-11', '1999-05-12', '1976-01-01','1986-06-01', '1983-06-04', '1990-03-07', '1999-07-09'],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index=['Jane', 'Pane', 'Aaron', 'Penelope', 'Frane', 'Christina', 'Cornelia'])
# 1、对索引进行排序
df.sort_index(inplace=True)
df
# 2、按降序对索引值进行排序
df.sort_index(ascending=False,inplace=True)
df

17. 对列名进行排序
# 编程
df = pd.DataFrame({'DateOfBirth': ['1986-11-11', '1999-05-12', '1976-01-01','1986-06-01', '1983-06-04', '1990-03-07', '1999-07-09'],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index=['Jane', 'Pane', 'Aaron', 'Penelope', 'Frane', 'Christina', 'Cornelia'])
# 按降序对列名进行排序
# 获取列名,并按降序排序
sorted_columns = df.columns.tolist()
sorted_columns.sort(reverse=True)
# 使用排序后的列名重新索引DataFrame
df_sorted_columns = df.reindex(columns=sorted_columns)
# 显示按降序排序列名的DataFrame
df_sorted_columns

18. 对数据进行排序
# 编程
df = pd.DataFrame({'DateOfBirth': ['1986-11-11', '1999-05-12', '1976-01-01','1986-06-01', '1983-06-04', '1990-03-07', '1999-07-09'],
'State': ['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']},
index=['Jane', 'Pane', 'Aaron', 'Penelope', 'Frane', 'Christina', 'Cornelia'])
# 1、对state列的值进行排序
df.sort_values(by="State")
# 2、对state、DateOfBirth两列的值进行降序排序,并改变原DataFrame
df.sort_values(by=["State","DateOfBirth"],ascending=[False,False])

19. map()、applymap()使用
# 编程
data = {'fruit':['apple','banana','grape'],'price':[5,6,7]}
df = pd.DataFrame(data)
display(df)
# 1、编写函数将price中整数改为字串,例如5改为5元
def convert_price_to_string(df):
df['price'] = df['price'].astype(str) + '元'
return df
# 使用函数转换price列
df_with_string_prices = convert_price_to_string(df)
df1 = display(df_with_string_prices)
df1

# 2、将fruit列中首字母大写
def capitalize_first_letter(df):
df['fruit'] = df['fruit'].str.capitalize()
return df
# 使用函数将fruit列的首字母大写
df_with_capitalized_fruit = capitalize_first_letter(df)
df2 = display(df_with_capitalized_fruit)
df2

# 编程
data = {'fruit':['apple','banana','grape'],'price':[5,6,7]}
df = pd.DataFrame(data)
display(df)
# 3.将price中数据从整数转为浮点数,采用map()
# 使用向量化操作进行类型转换(对于更复杂的转换可能有用)
df['price'] = [float(p) for p in df['price']]
df.dtypes

# 编程
df = pd.DataFrame(np.random.rand(3,3), index=['a','b','c'], columns=['A','B','C'])
display(df)
# 4. 将所有数据改为小数点后三位,采用applymap()
df['price'] = df['price'].apply(lambda x: '{:.3f}'.format(x))
# 显示格式化后的DataFrame
display(df)

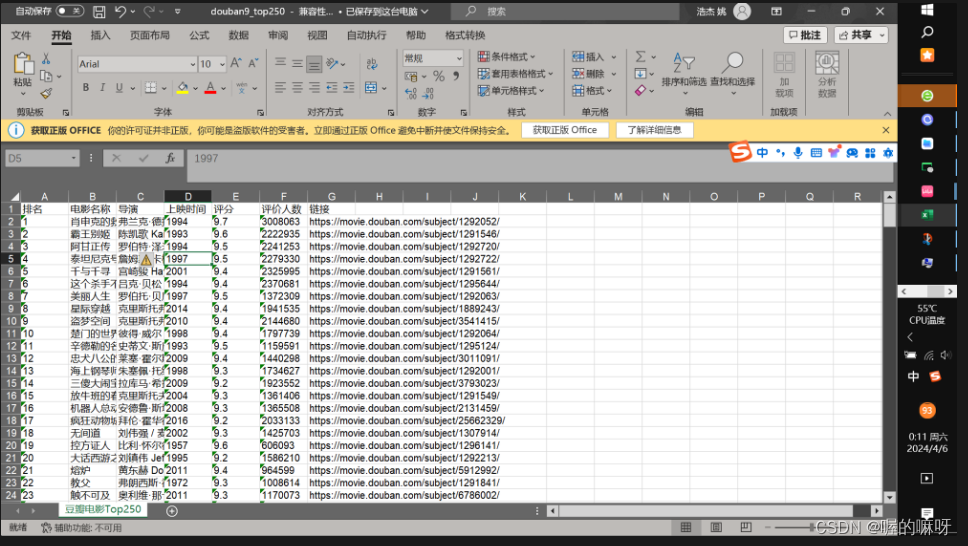
20. 采用“豆瓣电影数据”进行分析
# 编程
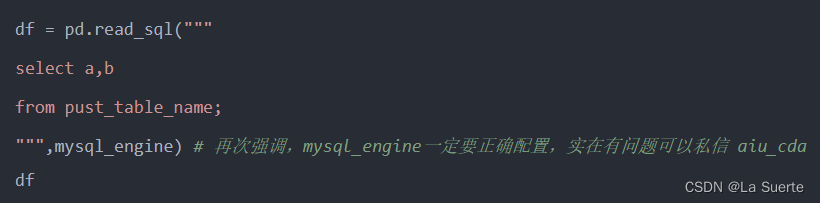
df = pd.read_excel('assets/豆瓣电影数据.xlsx') # read_excel方法进行读取excel文件
# 1、显示前5行
df.head()
# 2、显示后5行
df.tail()
# 3、随机选5行
df.sample(5)

# 编程
# 4、选取产地为泰国,'名字','类型'两列 loc()方法
df.loc[df["产地"]=="泰国",["名字","类型"]]

# 5、选取评分大于9.5,'名字','类型','产地'三列 loc方法
df.loc[df["评分"]>9.5,["名字","类型","产地"]]

# 6、选取评分大于9且投票人数大于1000的数据 query方法
filtered_df = df.query("(`评分`>9) & (`投票人数`>1000)")
filtered_df

# 7、查看整个数据集的统计信息
df.describe()
# 8、查看整个数据基本信息
df.info()

附录:
数据源:豆瓣电影数据.xlsx








![pyqt+opencv+常用图像算法可视化[资源介绍]](https://img-blog.csdnimg.cn/direct/f300e3e87b7b4c079c41a46bedbd1953.png)