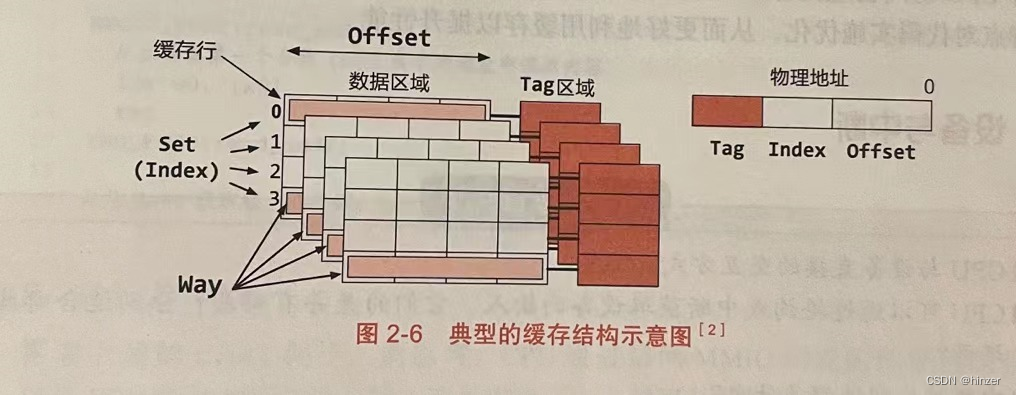
1.什么是Kano模型
Kano模型就是一个可以帮助我们有效识别“真伪需求”、划分需求优先级的有效工具。Kano模型是东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
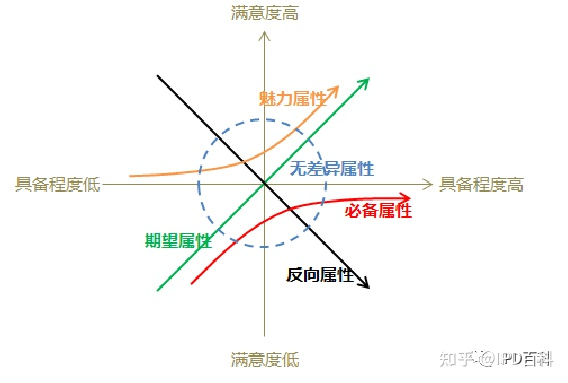
KANO模型是一个典型的定性分析模型,一般不直接用来测量用户的满意度,常用于识别用户对新功能的接受度。有助于产品经理了解不同层次的用户需求,主要是通过标准化问卷进行调研,根据调研结果对各因素属性归类,解决需求属性的定位问题,以提高用户满意度。根据不同的需求内容与用户的满意度关系,可以将Kano模型的内容具体分为五类:
1.基本型需求——痛点
客户存在什么问题,Ta睡不着觉,ta苦恼,这些痛就是客户急需要解决的问题。也称必备型、理所当然的需求,是给用户对服务方提供的基本要求。基本型需求没有达到时用户会表现的很不满意,但是即便做的再好,用户也不会因此有更多的好感。
2. 期望型需求——痒点
期望型需求与用户的满意度成比例关系,即期望型需求满足的越多,用户的满意度越高。对应⽤户愉悦和满⾜的情绪。当不爽的事情被及时解决时,容易得到满⾜。此需求不会像基本型需求那么苛刻,但此需求得不到满足时用户的不满感也不会像基本型需求那样显著增加。
3. 魅力型需求——兴奋点
兴奋点即能给客户带来“wow”效应的那种刺激,立即产生快感又称兴奋型需求,不会被用户过分期望的需求。随着不断满足用户的兴奋型需求,用户的满意度也会不断的增加,即便表现的不完善,用户的满意程度也是非常高的。反之用户的期望不满足时,顾客也不会表现出明显的不满意。
4. 无差异型需求——无关紧要点
不论提供与否,对用户体验无影响的需求。
5.反向型需求——膈应点
又称逆向型需求,指引起强烈不满的质量特性和导致低水平满意的质量特性,因为并非所有的消费者都有相似的喜好。许多用户根本都没有此需求,提供后用户满意度反而会下降,而且提供的程度与用户满意程度成反比。
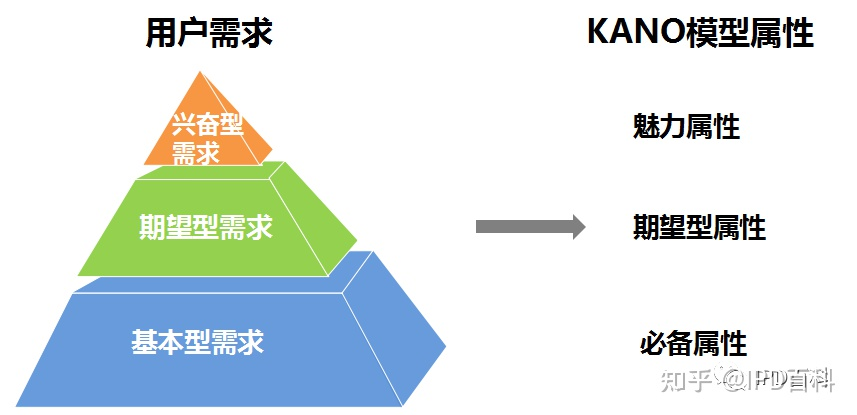
根据Kano模型,将其属性分类与用户需求优先级进行对应,便于实际应用,主要定义了三种:基本型需求(必备属性)、期望型需求(期望属性)、兴奋型需求(魅力属性),这三种需求根据绩效指标分类就是基本因素、绩效因素和激励因素。
2.Kano模型的实操
(1).设计调查问卷
Kano问卷中每个属性特性都由正向和负向构成,或者说一个问题需要设置正反2个不同的子问题,分别测量用户在面对具备或不具备某项功能所做出的反应问卷中的问题一般采用五级选项,按照:很好、还行、无所谓、不太好、不喜欢,进行评定
Kano模型的使用-问卷编制与数据处理
编制问卷的时候,对每个项目都要有正反两道题来测。需要注意:
① Kano问卷中与每个功能点相关的题目都有正反两个问题,正反问题之间的区别需注意强调,防止用户看错题意;
② 功能的解释:简单描述该功能点,确保用户理解;
③ 选项说明:由于用户对“很好”“还行”“无所谓”“不太好”不喜欢”的理解不尽相同,因此需要在问卷填写前给出统一解释说明,让用户有一个相对一致的标准,方便填答。
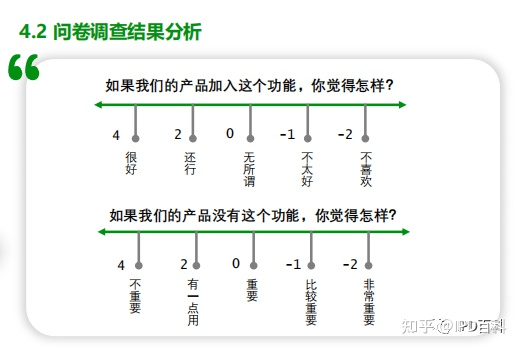
很好:让你感到满意、开心、惊喜。
还行:你觉得是应该的、必备的功能/服务。
无所谓:你不会特别在意,但还可以接受。
不太好:你不喜欢,但是可以接受。
不喜欢:让你感到不满意。
(2).分析统计数据
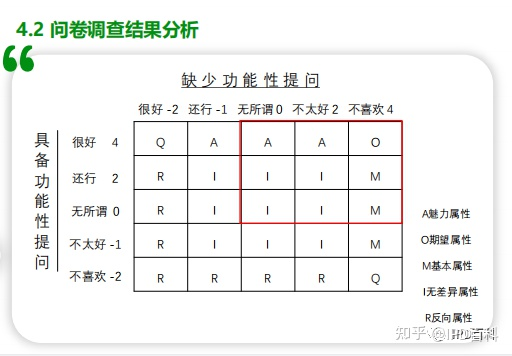
对所有的用户来说,共有5*5即25种可能,统计每种可能下的用户人数占总人数的百分比,来填入下表。之后将下表中标A、O、M、I、R、Q的格子中百分比相加,即可得到五种属性对应的百分比。从需求的角度来说,先满足M百分比最高的去掉R百分比最高的,再满足O百分比最高的,最后满足A百分比最高的。
数据分析过程:数据清洗→Kano⼆维属性归属分析→Better-Worse系数计算
数据清洗:
1.收集所有问卷之后,注意清洗掉个别明显胡乱回答的个例
Kano⼆维属性归属分析:
上述数据整理完成后,将同类型需求进行求和汇总
Better-Worse系数计算:
增加后的满意系数Better/SI=(A+O)/(A+O+M+I)
消除后的不满意系数Worse/DSI=-1*(O+M)/(A+O+M+I)
根据better-worse系数,对系数绝对分值较高的功能/服务需求应当优先实施。
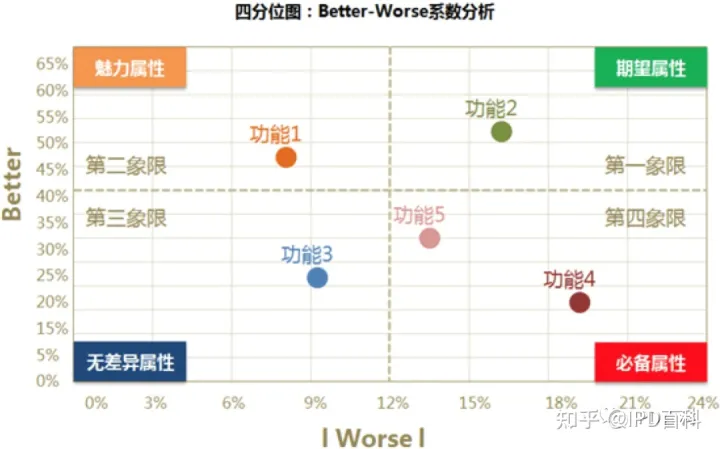
第一象限表示:better系数值高,worse系数绝对值也很高的情况。落入这一象限的属性,称之为是期望属性,即表示产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低,这是质量的竞争性属性,应尽力去满足用户的期望型需求。提供用户喜爱的额外服务或产品功能,使其产品和服务优于竞争对手并有所不同,引导用户加强对本产品的良好印象;
第二象限表示:better系数值高,worse系数绝对值低的情况。落入这一象限的属性,称之为是魅力属性,即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升;
第三象限表示:better系数值低,worse系数绝对值也低的情况。落入这一象限的属性,称之为是无差异属性,即无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点是用户并不在意的功能。
第四象限表示:better系数值低,worse系数绝对值高的情况。落入这一象限的属性,称之为是必备属性,即表示当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低;说明落入此象限的功能是最基本的功能,这些需求是用户认为我们有义务做到的事情。
3.模型应用的思考
1.Kano属性的优先级排序
辅助业务进⾏优先级排序,是Kano模型的⼀⼤功能特点。业务⽅在排序功能优先级时,可主要参考:必备属性>期望属性>魅⼒属性>⽆差异因素的基本顺序进⾏排序。期望属性的功能点对于⼯具的意义重⼤,建议优先考虑开发或强化;魅⼒属性的功能点,建议优先考虑better值较⾼的功能,会达到事半功倍的效果⽆差异因素可以成为节约成本的机会。
2.正确看待结果中的Kano属性
Kano属性的划分并⾮⼀成不变的,随着时间的变化,卖家对于客户关系管理的概念会⽇益成熟,各功能的属性归属很有可能会发⽣变化。应⽤Kano模型进⾏调研的优势和不⾜:
Kano模型有以下⼏个优势:
- Kano模型可以细致全⾯的挖掘功能的特质;
- Kano模型可以帮助业务⽅在⼯作中排优先级,辅助项⽬排期;
- Kano模型可以帮助⼈们摆脱“误以为没有抱怨就等于⽤户满意”的想法。
Kano模型也有它的不⾜:
- Kano问卷通常较长,⽽且从正反两⾯询问,可能会导致⽤户感觉重复,并引起情绪上的波动,若⽤户受到影响没有认真作答,则会引起数据质量的下降。
- Kano问卷是针对产品属性进⾏测试时,部分属性也许并不是很好理解。
- Kano模型类似于⼀种定性归类的⽅法,以频数来判断每个测试属性的归类,
这种情况下,可能会出属性归类结果表中,同⼀属性出现了不同归类栏频数相等或近似的情况。
由于KANO 模型存在这些不⾜,在运⽤Kano模型分析数据的时候就要注重数据收集前期的准备⼯作,⽐如在问卷设计时,把问卷尽量设计得清晰易懂、语⾔尽量简单具体,避免语意产⽣歧义。同时,可以在在问卷中加⼊简短且明显的提⽰或说明,⽅便⽤户顺利填答。