1. 国际象棋
1.1. 1997年计算机“深蓝”(Deep Blue)击败了顶尖国际象棋手,但机器取代数学研究机构还言之尚早
1.2. 下国际象棋与数学的形式化证明颇有相似之处,但学者认为中国围棋的思维方式更能够体现数学家思考的创造性和直觉力
1.3. 国际象棋与围棋相比,则是随着棋子一个个被吃掉,棋局变得越来越简单
1.4. 计算机科学家克劳德·香农(Claude Shannon)估计的国际象棋走法数量约为120位(称为香农数)
1.5. 国际象棋的行棋步骤以一种可控、有序的方式逐级建立分支,最终形成一个包含各种可能性的树状结构,计算机甚至人类都可以根据逻辑规则逐级分析不同分支的蕴含关系
1.6. 国际象棋更容易进行得分评价
1.6.1. 国际象棋是破坏性的,在行棋过程中,棋子会被一个个吃掉
1.6.2. 棋局会逐步简化
2. 围棋
2.1. 围棋很像数学,可以在相当简单的规则下形成精妙绝伦、错综复杂的推理
2.2. 据美国围棋协会(American Go Association)估计,围棋的可能走法数量是一个大约有300位的数字
2.3. 围棋就不是一种易于推算下一步行棋对策的游戏了,我们很难建立围棋行棋可能性的树状图
2.4. 围棋棋手推演下一步落子策略的过程似乎更依赖于自身的直觉判断
2.5. 围棋最重要的一点,是可以通过客观的方法检验新的行棋思路是否具有价值
2.6. 人类的大脑可以敏锐地捕捉到视觉图像所呈现出的结构和模式,所以围棋棋手可以通过观察棋子布局来推断棋势,然后得出下一步的应对策略
2.6.1. 人类大脑的视觉结构处理能力作为一种基本的生存技能,经过数百万年的进化已经变得高度发达
2.6.2. 任何动物的生存能力在一定程度上都取决于它在形态万千的自然界中对不同结构图像的识别能力
2.6.2.1. 原本平静的丛林之中激起的一丝混乱,极有可能预示着另一种动物的潜入
2.6.2.2. 这类敏感信息备受动物们的关注,因为它关系到自己会成为猎物还是猎食者,这就是大自然的生存法则
2.6.2.3. 人类的大脑非常擅长识别模式并预测它们的发展方向,同时做出适当的反应
2.7. 计算机程序学习下围棋非常困难的主要原因之一,因为到目前为止,还没有一种简单易行的方法可以建立起一套稳妥的系统,去评价对弈双方的领先状况
2.7.1. 围棋则不然,它是建设性的,行棋越多,棋盘上的棋子越多,棋局也越来越复杂
2.8. 对围棋下法的革新一直持续不断、屡见不鲜
2.8.1. 最近一次是围棋界的传奇人物吴清源大师于20世纪30年代开创的新棋法,他的布局之法颠覆了传统围棋布局的常用套路
2.8.2. AlphaGo可能会引发一场更大的围棋“革命”
2.8.2.1. 虽然人类已经发明围棋数千年了,但人工智能技术的出现让我们感觉到人类对围棋的理解仍然还很肤浅
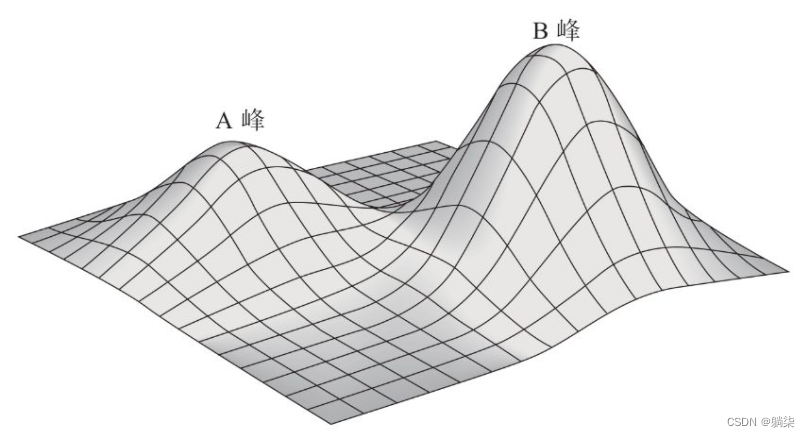
2.9. 局部极大值
2.9.1. 围棋算法是陷入数学家们所说的“局部极大值”的困境当中的
2.9.2. 图