本文为 「茶桁的 AI 秘籍 - BI 篇 第 32 篇」

Hi, 你好。我是茶桁。
今天咱们要来完成一个简单的推荐系统的建立。
之前的课程里给大家讲了两种模型,也希望大家对模型的概念以及使用场景会有些了解。不光是推荐系统,在生物、心理学、社交网络等等里面都会有一些使用。
曾经有过这么一句话:Embedding is all you need,这曾经是一篇论文的标题,也有很多 AI 相关的文章都会引用这句话作为标题,大家可以去 Google 一下,一搜一大片。这句话意思是 Embedding 就是你所想要的一切,这可以说明特征工程的一个重要性。
Embedding 之所以这么重要,原因就是因为它后续可以接入神经网络。神经网络是一个无限的拟合器,它需要有一个固定维度的向量。如果你不给它做 Embedding 放到神经网路里去就会产生维度爆炸。所以先做 Embedding,特征学完以后再放到神经网络里是一个最好的方法。
接下来,咱们来看一个项目,这个项目是移动推荐系统项目,我们看一看用户的购买预测,如何来进行推荐。
移动推荐系统是来自于阿里云天池上的一场比赛,这个比赛目前也是开放的,感兴趣的可以自己进行提交,看一看你自己的排名。
https://tianchi.aliyun.com/competition/entrance/231522/information
如果之前没有做过这场比赛可以先把数据下载下来。数据压缩包 100 多兆,解压以后大概一个 G,数据量级非常庞大。所以这个数据大家就自己去比赛页面去自己下载一下。
这个数据是一个真实业务场景的数据,当然也做了一些脱敏的处理。在官网上对题目和数据的定义是这样的:
在真实的业务场景下,我们往往需要对所有商品的一个子集构建个性化推荐模型。在完成这件任务的过程中,我们不仅需要利用用户在这个商品子集上的行为数据,往往还需要利用更丰富的用户行为数据。定义如下的符号:
U ——用户集合
I ——商品全集
P ——商品子集,P ⊆ I
D ——用户对商品全集的行为数据集合
那么我们的目标是利用 D 来构造 U 中用户对 P 中商品的推荐模型。
我们需要对所有商品的子集构造一个个性化的推荐。完成这个任务不仅需要在用户的商品子集上的行为,还需要更丰富的其它用户行为。
首先用户的集合 U 是全量的用户,你可以把它想象成是淘宝上的用户。淘宝上面还有非常多的商品,I 是商品全集。我们要去关注的不是全量商品,而是一部分商品是 P。为什么是一个子集,想象有一个广告投放业务,他不需要对所有商品都做推荐,要找谁付了费,放到阿里巴巴上面要去做推广,这是有收益的。所以 P 是他的广告候选集。
D 是用户的行为集合,这是一个全量商品 I 的行为,是用户在 i 上面的所有的全量行为,这本身是构造了一个用户行为的一个数据集。而我们要去预测的并不是全部的数据,而是 P,看一看用户会不会对 P 感兴趣。
这样定义完之后大家应该能明白了把?
整个的比赛的数据是给我们提供了 2 万个用户的行为数据以及百万个商品信息,数据啊我们也可以看到比赛页面上也有比较详细的一个描述:
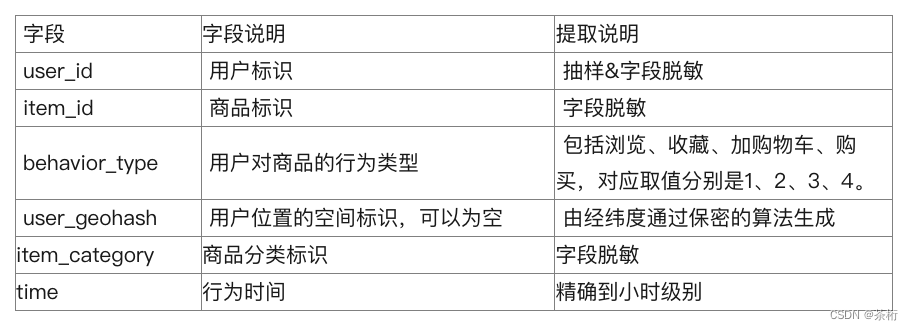
第一部分是用户在商品全集上的移动端行为数据(D),表名为
tianchi_fresh_comp_train_user_2w,包含如下字段:
时间上,是来自于 11.18 到 12.18,一个月的左右的移动端的行为,对应的数据表就是 tianchi_fresh_comp_train_user, 一个多 G 的 CSV,所以原始数据还是非常大的。
我们来看一下 behavior_type 这个字段的说明,包含了浏览、收藏、加购物车、购买、对应取值分别是 1、2、3、4,我们平时用淘宝大概也就这些行为。看一看商品,放到购物车里,产生购买,你可以把这个商品收藏起来,这个行为字段叫 behavior_type。
数据集里还包含了用户位置的空间。用户有的时候把位置开放了,就可以知道用户的一些位置空间,这里是做了一个加密算法的处理,因为用户的隐私,并不能直接告诉你,这些数据都是做了一些脱敏的处理。
脱敏虽然看不出来原始数据,但是它的特征是有保留的。可以把它理解成为就是经过算法的一个映射关系,看成是个加密。Embedding 和 PAC 都是一些比较常见的脱敏技术,因为 Embedding 和 PAC 本身是对特征做了一些提取。
还有一些行为,精确到小时的级别。
这个数据表就把用户和商品的行为、时间以及地理位置都做了一些特征的描述。还有包括商品特征,商品子集是来自于 tianchi_fresh_comp_train_item 这张表,这张表比较简单,只有三个字段。商品标识,商品分类标识以及商品位置的空间标识。
第二个部分是商品子集(P),表名为
tianchi_fresh_comp_train_item_2w,包含如下字段:

现在要去预测一个月之后的某一天,12 月 19 号 他商品子集的购买情况。如果预测更准确分数就会更高一点,最终的输入结果有 user_id 和 item_id 这两个字段。
用户对哪一个商品会产生购买,最终评价指标它用的是 F1 值,F1 是由两个维度来进行构成的。
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n × R e c a l l F1 = \frac{2 \times Precision \times Recall}{Precision \times Recall} F1=Precision×Recall2×Precision×Recall
其中 Precision 是精确度,Recall 是召回率,这两个指标咱们在之前讲解机器学习的时候都有详细的讲解过。
P r e c i s i o n = ∣ ⌢ ( P r e d i c t i o n S e t , R e f e r e n c e S e t ) ∣ ∣ P r e d i c t i o n S e t ∣ R e c a l l = ∣ ⌢ ( P r e d i c t i o n S e t , R e f e r e n c e S e t ) ∣ ∣ R e f e r e n c e S e t ∣ Precision = \frac{|\frown(PredictionSet, ReferenceSet)|}{|PredictionSet|} \\ \\ Recall = \frac{|\frown(PredictionSet, ReferenceSet)|}{|ReferenceSet|} Precision=∣PredictionSet∣∣⌢(PredictionSet,ReferenceSet)∣Recall=∣ReferenceSet∣∣⌢(PredictionSet,ReferenceSet)∣
那为什么不单独的用精确度和召回率呢?
先看一下相关定义,给了一个预测的用户购买集: PredictionSet, 本身答案也有一个ReferenceSet,这是一个真实答案,这是给出来的预测结果。两者之间前面的符号是用了一个交集"
⌢
\frown
⌢",就是两个集合中都存在的一个数据的集合。然后又求了一个 lens,就求它的长度。这里用的| |并不是指绝对值,而是长度。求出的这个长度比上预测的长度,就代表精确度。也就是说,在给出来的这些集合过程中,你预测对了多少个,是精确度。
那请问,如果只看精确度作为最终考核指标的话,这样的一个指标有没有可能作弊?有没有一些策略可以让精确度的分数比较高?
我们最终是除上一个分母 |PredictionSet|,这个分母是精确的,预测的集合。所以会不会存在一种情况可以让它的分数达到很高?比如说只给一个预测购买的结果,这个购买结果确实存在过,所以精确度就会很准,只预测一条数据是个极端行为。所以我们还要考量一个维度 “召回率 Recall”。
召回率还是这两个交集,也就是两个集合中都存在的数据,比上真实的答案。那我们在想想,如果只看召回率,有没有一些方法也能让你作弊,达到很好的成绩?这个应该比较容易。
召回率就是在实际的购买过程中找到了多少,最简单的策略是把所有的商品子集都放进去。如果所有商品子集都放进去一定 100% 都涵盖,召回率就拿了满分,这样其实也是不对的。
为了防止作弊就不能用单一的指标,而是要把这两个指标合到一起。F1 值就更加的精确一点,避免了用户作弊的两种可能性。这样就是一个算法真实的考量,用 F1 值会更合理一些,也成为最终的评价指标。
一会儿会给 2 万的用户行为数据来去预测商品子集在接下来一天会不会产生购买,计算的是 F1 值。
现在可以好好思考一下思路,应该怎么去做?这是一个预测是否购买的任务,第一肯定是先要对原来的数据做观察。
用户的购买本身跟时间是有关系的,给出来的数据给了前 30 天的行为,所以可以先去考量一下。我们一起来看一看。
先把数据加载进来
# 数据加载
df = pd.read_csv(path+'/tianchi_fresh_comp_train_user.csv')
df
数据加载可能存在一个问题,现在这个数据量可能会比较大,所以可能需要对这个数据去做一个分块的处理。如果你的内存比较大可以直接来进行读取。
我的笔记本内存还好一点,16 个 g,如果你的笔记本内存是 8 个 g 的话基本上后面运算就比较难了。前期的读取时间相对来说会比较长。

咱们主要看的是用户的时间,数据这个 time 是 2014 年的 12 月份,要预测的是 2014 年的 12 月 19 号。思考一下, 2014 年 12 月 19 号大家会想到什么样的一个特征?
对于网购来说,哪一天购买对用户来说是否有关系?比如说周一的时候买商品还是周五的时候买会不会不一样?周一在淘宝上购买行为跟周日会不会有区别?这个肯定还是有区别的。所以咱们第一个想法是需要看一看,2014 年 12 月 19 号是星期几。

周五更容易产生购物,而这一天正好是周五。给了 30 天的数据,要怎么去完成预测呢?是不是可以划一个时间段,给你一个 x,然后再预测一个 y。
x 怎么设置?如果预测的是周五,把它分成几组,可以这样分:
t r a i n 1 : 11.22 11.27 − > 11.28 t r a i n 2 : 11.29 12.04 − > 12.05 t r a i n 3 : 12.06 12.10 − > 12.12 t r a i n 4 : 12.13 12.18 − > 12.19 \begin{align*} train1 : 11.22 ~ 11.27 -> 11.28 \\ train2 : 11.29 ~ 12.04 -> 12.05 \\ train3 : 12.06 ~ 12.10 -> 12.12 \\ train4 : 12.13 ~ 12.18 -> 12.19 \end{align*} train1:11.22 11.27−>11.28train2:11.29 12.04−>12.05train3:12.06 12.10−>12.12train4:12.13 12.18−>12.19
前面 13 到 18 是 6 天的时间,预测它是周五。相当于是从周六开始一直到周四,预测 19 号。从 train1 到 train4 都是一样的,都是从周六开始到周四,预测周五。把每一周七天的时间可以划分出来,这样就会有四个七天的时间,每个七天都形成了 x 和 y 的特点,前面是 x,后面是 y。所以如果要去建一个分类模型就可以这么去构造,前面是原始数据的 x,后面是 y。可以把它称为 test day,就是预测 y。y 的时间点就是 12 月 19 号、12 月 12 号、 12 月 05 号和 11 月 28 号。
当然这种划分方式也不是唯一的标准,也可以按照其他不同的方式。比如预测 31 天,然后再把中间的 30 天预测下一天也完全可以。没有一种统一的方式,采用哪种方法都可以,看哪一种更合理。
咱们现在按照之前的划分方式,四个段落里有没有可能存在异常值?
2014 年的时候,淘宝那阵已经上线一段时间双十一的活动,这应该是淘宝造节的一个非常成功的一个案例。除了双十一以外还有一个重要的节日,也可能会造成购买的异常,你会发现用户购买的情况非常多,这个数据集里面也覆盖到了,就是 12 月 12 号,叫双十二。
这个相信大家应该经历过,就是下一个月双 12 的时候应该也有一些促销的优惠幅度,这对于第三组(train3: 12.06 ~ 12.10 -> 12.12)来说包含了一个异常点。有了这个异常点对于模型来说存在一些反向价值,或者有些噪音点。所以为了更好去预测,可以把异常值去掉。
以上是一个思考维度,大家可以按照这种思维自己去做一个建模。最终我们可以用模型去预测用户是否会完成购买,前期也会有数据的一个统计。
另外我这里也教给大家还有一些方式,咱们可以对数据做分块儿的处理。如果你的数据很大,可以使用 chunksize,chunksize 是 Pandas 里面做分块处理的一个设置。
dateparse = lambda dates: pd.to_datetime(dates, format='%Y-%m-%d %H')
file_name = path+'/tianchi_fresh_comp_train_user.csv'
batch = 0
for df in pd.read_csv(open(file_name, 'r'), parse_dates=['time'],
index_col=['time'],
date_parser = dateparse,
chunksize = 1000000):
打开一个文件,然后设置成 size,这里的 size 大小设置成了 100 万,或者你设成 10 万,这里意思就是每一块现在是 100 万行的数据。
第一行的 dateparse 中,date 代表是日期的含义。我们设置了一个日期的一个解析。解析是 parse_dates=['time'] 这个特征,还可以把它设成 index_col,这样每一次 DF 就有了 100 万行。也可以把这 100 万行的数据每一次都 to 成一个 CSV,把它保存进去。
train1.to_csv(train1_file, columns = ['user_id', 'item_id', 'behavior_type', 'item_category'], header = False, mode = 'a')
如果你的文件特别特别大,要保存的话可以使用一种叫做 append 的模式。mode = 'a' 代表是 append, 追加模式。追加模式的话,header 就不能有了。每次如果都有表实际上就多了一些表头,要把表头去掉。所以在追加模式过程中,header 一般设为 False,这样你生成出来的 CSV 是没有表头的。
除了对数据做了这样一个处理以外,我们再来做一个简单的策略,先做个简单规则。
我们想想,在购买要预测的是哪一个特征?是 behavior_type 这个字段。再来看看字段说明:
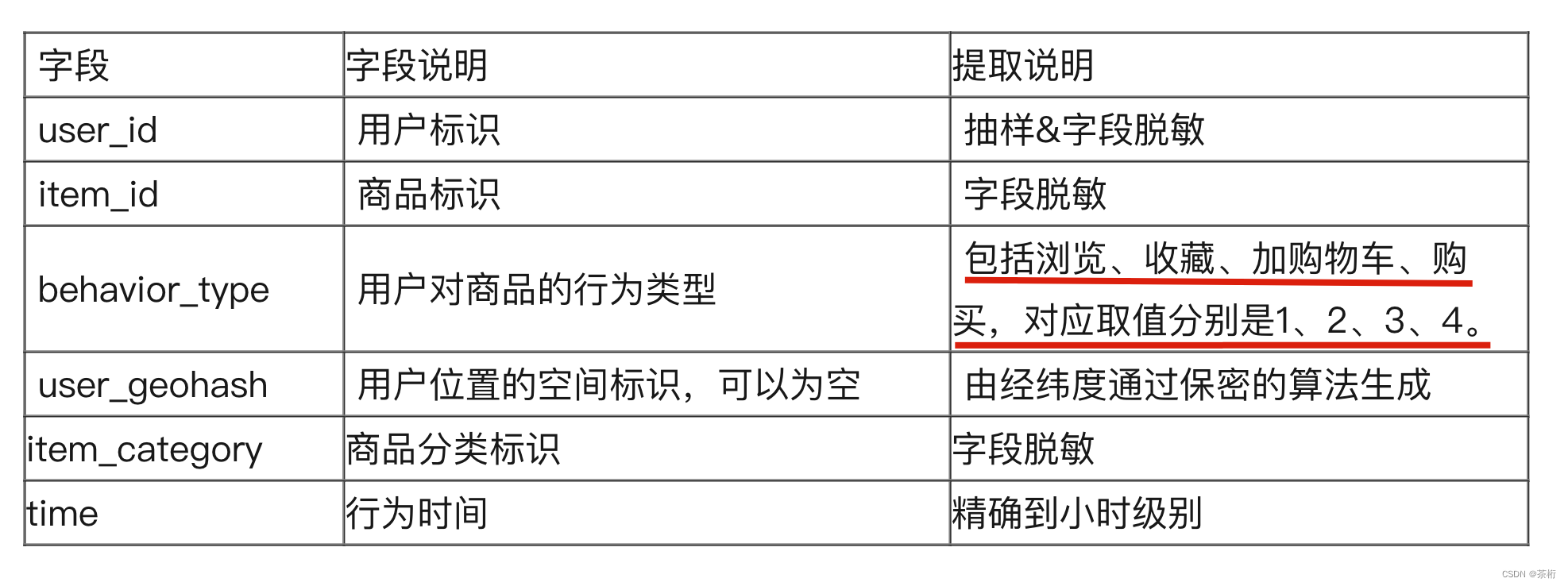
要是产生购买应该是 behavior_type 的第 4 个, behavior_type 等于 4。一般购买的逻辑是什么?在购买之前还要做一个操作,哪一个逻辑跟购买之间是最直接相关的?
一个用户可能不只有一种类型,对同一个商品 ID 可能会有 1、2、3、4,也就是浏览、收藏、加购物车和购买。那 1 肯定是必备的,其他的 3 可能最近。知道转化漏斗吧?点击进去以后放到购物车产生购买,所以 3 和 4 之间的关系,到底转化率是多少这可能是一个问号,我们可能想要去看一看。
原始数据已经给到了,完全可以通过一些数据探索的形式做一些可视化的分析。这里可以先设一个简单规则,假设用户都是先放到购物车再进行购买的,也就是对应的从 behavior_type = 3 再到 behavior_type = 4。先去观察一下,因为每一个 behavior_type 都有时间的记录,可以看到原始的数据里面有个 time,可能就比较好奇 3 ~ 4 之间一般会间隔多久。
一般放到购物车里然后产生购买,不同的人时间不一样。这里咱们做个小调查,有没有一些同学把购物车当成收藏夹,大家可以在我的留言区内回复。
有时候我们发现产品设计很有意思,虽然有收藏的功能,但总有些人先放到购物车里不买,先等着,可能过一段时间又买了。很神奇,我身边有很多人也都是类似的一些行为。我们可以观察一下这两者之间的时间差。你放到购物车到最终完成购买,这里设置一个 delta_hour,这是一个新的特征段,把这个 delta_hour 可视化。
购物车到购买的时间间隔越短,可能很快就买了,越长就越是起到收藏的功能,总体来说这个规律非常的明显,特征很突出。
我们设置它每个长度是 24,就是 24 小时,基本上是在一天左右用户就产生一个购买。用户有一个很强的特征,一般要放在购物车的话一天的时间之内可能就买了,那我们能不能写一个简单的策略,去预测用户购买哪些商品?
既然要预测的是 12 月 29 号的购买情况,如果上一步是要放到购物车,最大的数据是 12 月 18 号的数据,所以会利用哪一天的购物车来进行预测呢?有没有可能,在 12 月 18 号之前把商品放到购物车里去,而那一天没有购买,我们就可以把它认为未来可能会购买,可以以 12 月 18 号那一天的购物车数据来进行预测。这就是一个简单的一个策略。
如果把它放到了购物车里还没有完成购物,假设它可能会在 12 月 19 号完成购物,这样一个策略我们看一看它的结果会是怎样的。
接着上面的代码继续写下去,就像前面分析的,咱们最关注的特征应该是 behavior_type, 在它等于 3 或 4的时候,因为你现在假设是 3-4 之间的一个转换,所以可以写一个数组,把它做一个抽取,原来的数据直接读进来。
df_act_34 = df[df['behavior_type'].isin([3,4])]
因为我的内存还可以,而追加读取的方式太耗时间,所以我干脆就直接读取完整的数据了。然后未了方便,我将其保存为 pickle:
df_act_34.to_pickle(path+'/df_act_34.pkl')
这样的话,下次只要计算一次,以后其实就可以直接通过 pickle 文件来进行读取了,速度会比较快一点。得到的文件为 49.2 M.

pickle 文件在读取的时候需要用 open 来进行,
with open(path+'/df_act_34.pkl', 'rb') as file:
df_act_34 = pickle.load(file)
df_act_34.head()

这个写完以后,下面要去提取所有 behavior_type = 3的数据,不过数据还需要再做个处理。
咱们需要将 dublicate 的数据 drop 一下。对他的一个粒度筛选是用户和商品之间的行为,最终要提交的也是用户和商品之间的行为。
把一些重复的 drop 掉之后还有一个小问题,就是应该有一些时间的概念,要把时间从小到大排序,按照它的这个维度可以先 sort 一下:
df_act_34.sort_values(by=['time'], ascending=True, inplace=True)
df_act_34.drop_duplicates(['user_id', 'item_id', 'behavior_type'], keep='last', inplace=True)
df_act_34.info()
---
...
Index: 742625 entries, 5 to 23290546
Data columns (total 6 columns):
...
保存它最后一次 keep = 'last' 就可以了,原来是 89 万的数据,现在变成了 74 万的数据。
那现在这个数据其实还是[3, 4]的数据,要提取几个关键特征,第一个要提取的是 behavior_type = 3 的数据。
# 所有 behavior_type = 3 的数据
df_time_3 = df_act_34[df_act_34['behavior_type'] == 3][['user_id', 'item_id', 'time']]
df_time_3
我们求几个维度,['user_id', 'item_id', 'time'], 把这个数据作为 df_time_3 打印出来。
同理还可以求一下所有 behavior_type = 4 的数据,目的就是要看这两者之间有没有一些关联。
# 所有 behavior_type = 4 的数据
df_time_4 = df_act_34[df_act_34['behavior_type'] == 4][['user_id', 'item_id', 'time']]
df_time_4
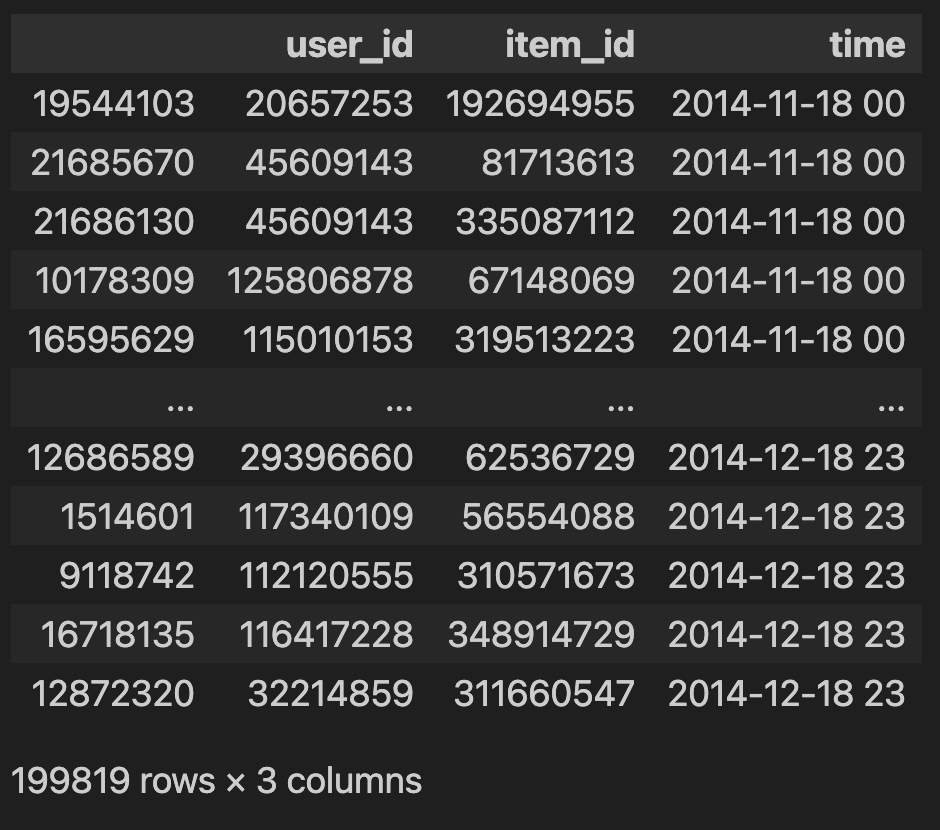
现在 3 和 4 都求完了,统一去看 3-4 之间的一个差值。以用户的粒度为例,或者以 item 粒度为例。咱们最后要提交的文件里面是 user_id 和 item_id。
现在提取出来了 user_id 和 item_id 两种特征,一个是 behavior_type = 3 的特征,一个是 behavior_type = 4 的特征,可以把这两个特征合并起来。
合并的过程中也存在一个问题,它都等于 time,所以对它的 time 也需要做一个变换。
df_time_3.rename(columns={'time':'time3'}, inplace=True)
df_time_4.rename(columns={'time':'time4'}, inplace=True)
这些都求解出来以后,如果之前有些数据不想要了也可以给他 drop 掉,可以直接帮他把内存清掉。
这两个数据还可以合并到一起,将time3和time4的数据进行连接,用 user_id 和 item_id 来做链接:
df_time = pd.merge(df_time_3, df_time_4, on = ['user_id', 'item_id'], how='left')
df_time

这样就可以把它链接到一起。可以看到有些是有 3 但是没有 4,4 的位置是空值。那我们需要在对数据进行一下处理,将空值去掉。
df_time_34 = df_time.dropna()
df_time_34
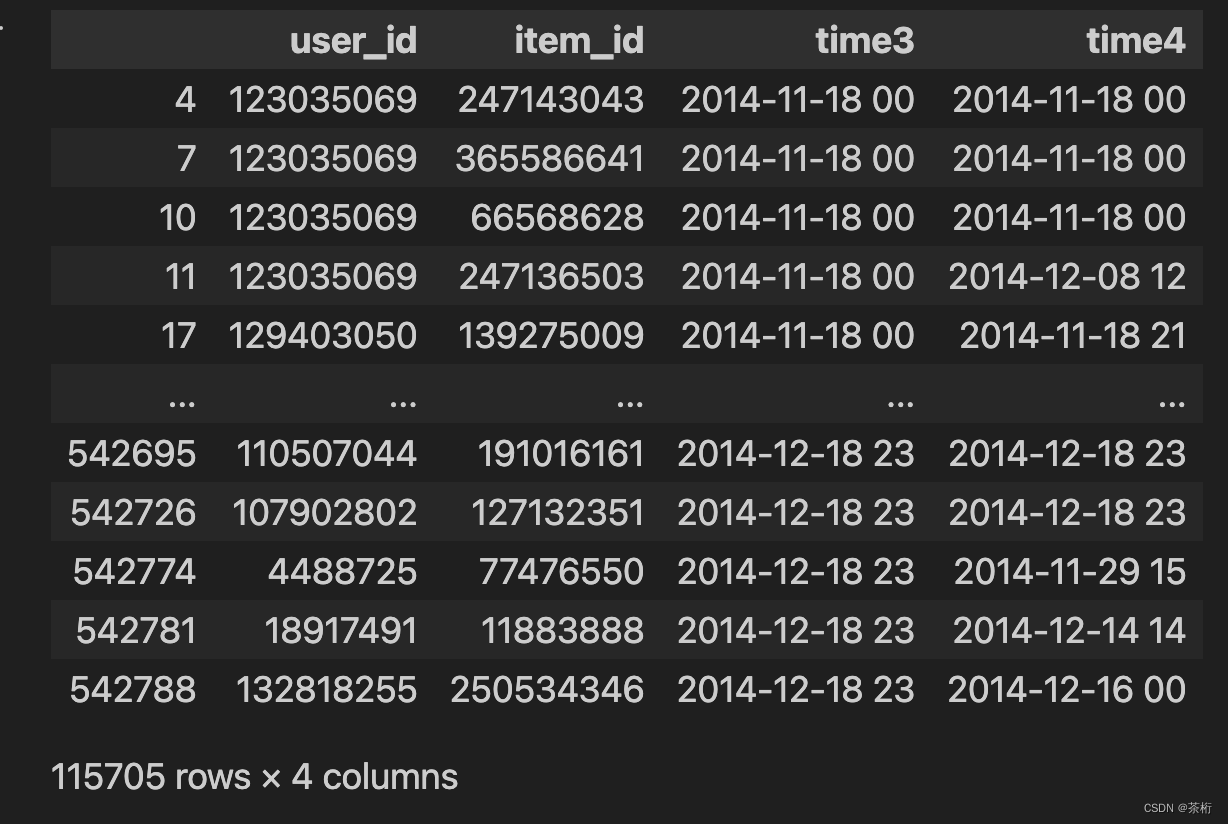
接着咱们来计算从加购物车到购买的时间差:
delta_time = pd.to_datetime(df_time_34['time4']) - pd.to_datetime(df_time_34['time3'])
delta_time
---
4 0 days 00:00:00
...
542781 -5 days +15:00:00
542788 -3 days +01:00:00
Length: 115705, dtype: timedelta64[ns]
这是要去分析的一个重要特征,可以把这个特征画一画。可以提取一些具体的时间,遍历一下:
delta_hour = []
for i in range(len(delta_time)):
d_hour = delta_time.iloc[i].days * 24 + delta_time.iloc[i]._h
delta_hour.append(d_hour)
delta_hour
接着去写可视化的过程
plt.hist(delta_hour, bins=24)
plt.xlabel('Hours')
plt.ylabel('Count')
plt.title('Delta_hour from shopping cart to buy')
plt.grid(True)
plt.show()

可以看到这个数据存在一些异常值,有一些购买和原来的时间不匹配的情况。如果它存在这种不匹配的情况,你可以把它删掉,给它做一个处理。
delta_hour = []
for i in range(len(delta_time)):
d_hour = delta_time.iloc[i].days * 24 + delta_time.iloc[i]._h
if d_hour<0:
continue
else:
delta_hour.append(d_hour)
delta_hour
接着咱们再来展现一下看看:
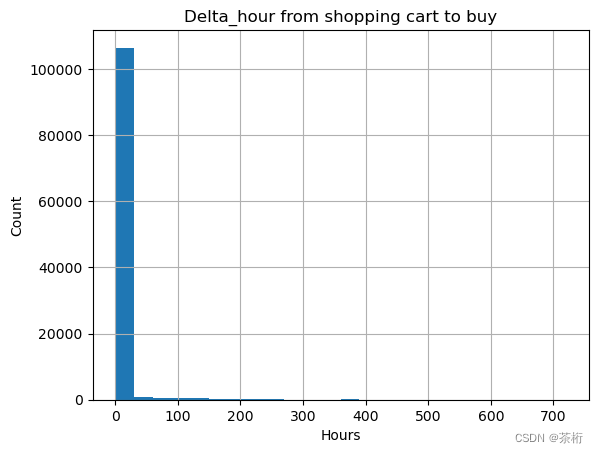
通过这个例子可以看出来比较明显,基本上用户在一天之内都完成了购买,之后陆陆续续也会有一些购买。所以这个特征是一个非常强的特征,特征比较强就可以直接去查看 2014 年 12 月 18 号的购物车,当时放到购物车的用户有哪些。
这个怎么看? 咱们之前在拆解数据的时候,购物车数据应该是 time3, 也就是 df_time_3。咱们来看看这个部分:
# 查看2014-12-18,当时放到购物车中的用户
ui_pred = df_time[df_time['time4'].isnull() & (df_time['time3'] >= '2014-12-18 00')]
ui_pred

求一下 time3 有但是 time4 没有,并且 time3 又大于等于 12 月 18 号,这个数据应该就是咱们想要的数据。
我们想要的就是大于 12 月 18 号在那一天放到购物车,但是没有产生购物的人,求解出来以后再去做一个商品子集的对比。
在原始数据中有个商品子集,咱们可以检索一下,商品子集是 item_id, 把这两个 item_id 做一个求解,做一个 merge。
df_item = pd.read_csv(path+'/tianchi_fresh_comp_train_item.csv')
df_item
ui_pred_in_p = pd.merge(ui_pred, df_item, on='item_id')
ui_pred_in_p
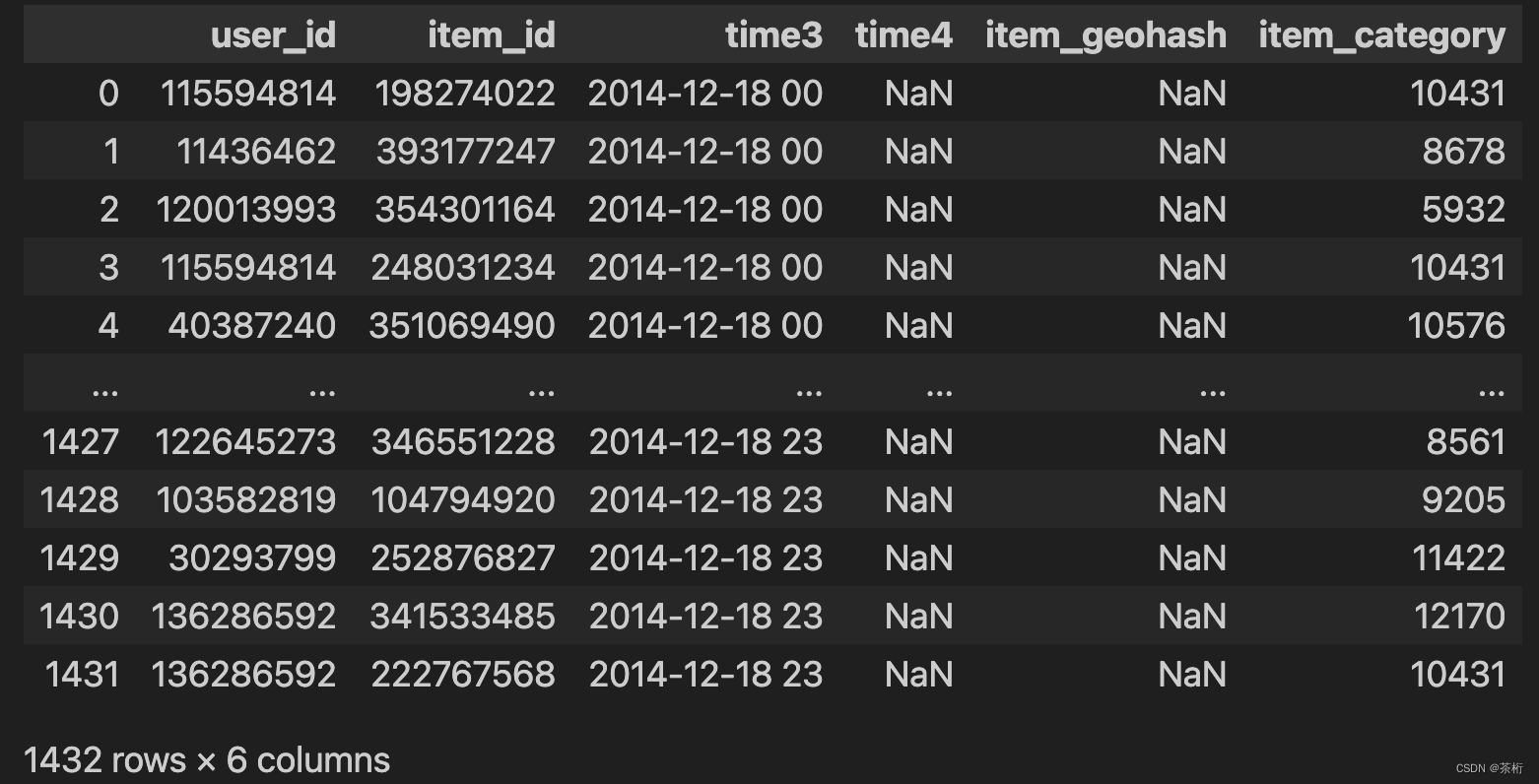
然后把这个结果保存起来
ui_pred_in_p.to_csv(path+'/baseline_rulebased.csv', columns = ['user_id', 'item_id'], index=False)
根据要求应该只有两列,一个是 user_id,一个是 item_id。 所以咱们在保存的时候设置了一下 columns。 index = False 是不要把序号加上去.
保存完毕之后,咱们再来看看保存好的文件,读取一下看看:
pd.read_csv(path+"/baseline_rulebased.csv")
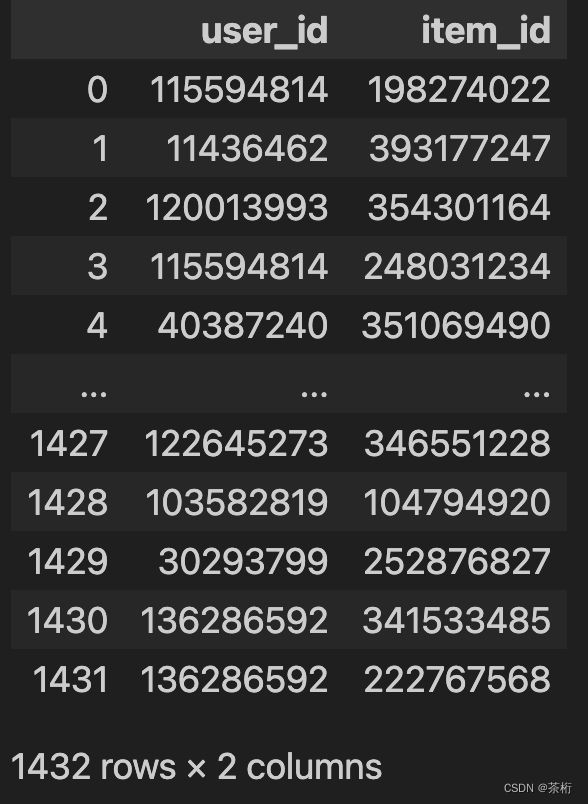
查看一下没有问题,那咱们就可以提交了,看看最终的成绩是怎样的。虽然这次没用机器学习,但是我们找到了一个比较好的特征,这个特征非常明显,可以看看这个特征对最终预测是否会有帮助。

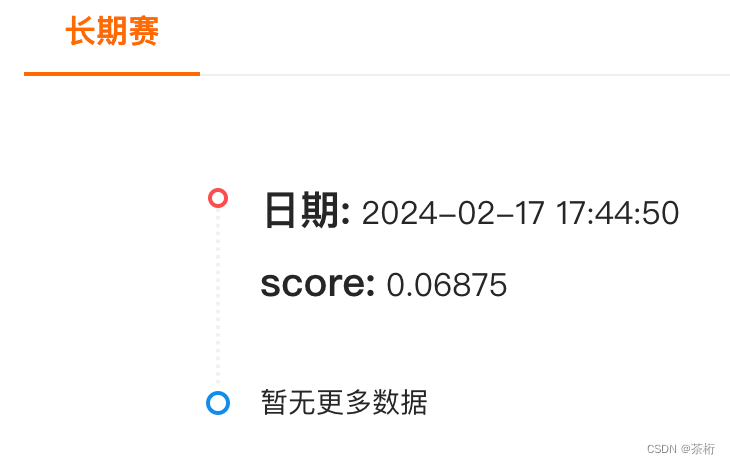
提交之后可以看到自己的分数,那可以看到咱们此次的分数并不高,只有0.06875,也是大概在 400 多名去了。整个参赛队伍大概是有 15000 名左右。
整个数据如果能找到一个比较好的特征,那至少可以把它当成一个权重因子,后续还可以再去引入到一些新的维度,也可以采用多种 rule base 一起来做一个合并,也可以在此基础上再做一些模型训练。
从上面这个例子来去看,推荐系统在这些操作之后还可以再加一个预测的模型,让预测更加精准,而这是一种比较常见的策略。
好,这个就是本节课的一些内容,大家如果想要在比赛中提高自己的分数,或者加强自己的能力,课后可以在尝试融合一些模型训练。勤思考,勤练习,期待大家能有一个更好的成绩和提升,别忘了回来留言告诉我你的成绩。咱们下节课再见。






![基于JavaWeb开发的springboot网约车智能接单规划小程序[附源码]](https://img-blog.csdnimg.cn/direct/32156567858d455f8375fee65a47ed03.png)