Weakly Supervised Audio-Visual Violence Detection 论文阅读
- 摘要
- III. METHODOLOGY
- A. Multimodal Fusion
- B. Relation Modeling Module
- C. Training and Inference
- IV. EXPERIMENTS
- V. CONCLUSION
- 阅读总结
文章信息:

发表于:IEEE TRANSACTIONS ON MULTIMEDIA 2022
摘要
由于近年来大量视频的涌现,视频中的暴力检测在实际应用中非常有前景。大多数以前的工作将暴力检测定义为简单的视频分类任务,并使用小规模数据集的单模态,例如,视觉信号。然而,这样的解决方案供给不足。为了缓解这个问题,我们研究了大规模音视频暴力数据上的弱监督暴力检测,并首次引入了两个互补的任务,即粗粒度暴力帧检测和细粒度暴力事件检测,将简单的暴力视频分类推进到帧级别的暴力事件定位,旨在准确地定位未经修剪的视频中的暴力事件。然后,我们提出了一种新颖的网络,将音视频数据作为输入,并包含三个并行分支来捕获视频片段之间的不同关系,并进一步集成特征,其中相似性分支和接近性分支分别使用相似性先验和接近性先验捕获长程依赖关系,评分分支动态捕获预测分数的接近程度。在粗粒度和细粒度任务中,我们的方法在两个公开数据集上均优于其他最先进的方法。此外,实验结果还显示了音视频输入和关系建模的积极效果。
III. METHODOLOGY
在本节中,我们首先介绍多模态融合以生成音视频融合特征(第III-A节),然后将融合特征输入到以下模型中以捕捉三种不同的关系(第III-B节)。接下来,我们介绍了用于训练和推断过程的客观函数(第III-C节)。最后,我们展示了我们模型的时间空间复杂性(第III-D节)。我们提出的方法总结在图1中。

图1. 我们提出方法的流程图。给定一个视频和相应的音频,首先使用特征提取器提取视觉和音频特征。然后将这些不同模态的特征融合以生成片段特征。RM 模块用于建模片段之间的三种不同关系,可用于离线检测,而在线检测器则用于在线检测,可以在没有未来内容的情况下检测暴力行为。我们的方法很灵活,因为它可以同时应用于粗粒度和细粒度的暴力检测任务。
A. Multimodal Fusion
考虑到我们有一个未修剪的视频 v v v 和相应的标签 y B y^B yB 和 y y y,其中 y B ∈ { 0 , 1 } , y B = 1 y^B{\in}\{0,1\},y^B=1 yB∈{0,1},yB=1 表示 v v v 包含了暴力事件,而 y = { 0 , 1 } i = 1 M + 1 , M y=\{0,1\}_{i=1}^{M+1},M y={0,1}i=1M+1,M 是暴力类别的数量。我们使用现成的预训练网络作为特征提取器 F V F^V FV 和 F A F^A FA,并通过滑动窗口机制提取视觉和音频特征矩阵 X V X^V XV 和 X A X^A XA,其中 X V ∈ R T × d V X^V\in\mathbb{R}^{T\times d^V} XV∈RT×dV, X A ∈ R T × d A X^A\in\mathbb{R}^{T\times d^A} XA∈RT×dA, x i V ∈ R d V x_i^V\in\mathbb{R}^{d^V} xiV∈RdV 和 x i A ∈ R d A x_i^A\in\mathbb{R}^{d^A} xiA∈RdA 分别表示第 i i i 个片段的视觉和音频特征。 T T T 是视频 v v v 的长度, d V d^V dV 和 d A d^A dA 分别是视觉和音频特征的维度。
然后我们将视觉和音频特征连接起来生成融合特征。更具体地说,我们首先将 X V X^V XV 和 X A X^A XA 在通道上堆叠,然后将堆叠的特征送入两个堆叠的全连接(FC)层,每个层都有512和128个神经元。每个FC层后跟ReLU激活函数和dropout。我们得到融合特征,表示为 X F X^F XF,它是两个堆叠FC层的最终输出。
B. Relation Modeling Module
我们首先回顾神经网络中的长程依赖建模[28],它可以用公式表示如下:
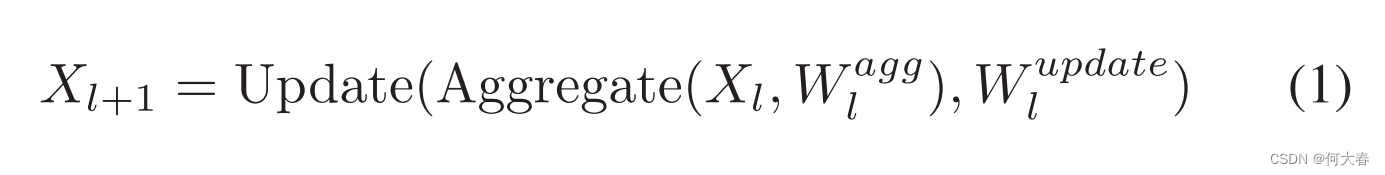
与常规的卷积层的主要区别在于聚合操作,它汇总来自全局范围(长程依赖)而不是局部区域的信息。
相似度分支的实现:我们通过特征相似性先验设计了相似性关系矩阵,从视频理解的GCN中获得启发。相似性关系如下所示:
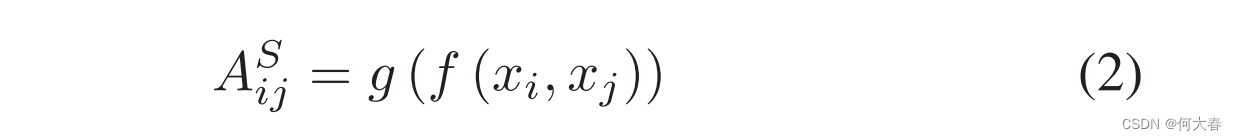
其中,
A
s
∈
R
T
×
T
A^s\in\mathbb{R}^{T\times T}
As∈RT×T,
A
i
j
S
A_{ij}^S
AijS衡量第
i
i
i个和第
j
j
j个特征之间的特征相似度。 值得注意的是,在公式(2)中,大小为
T
×
(
d
V
+
d
A
)
T{\times}(d^V{+}d^A)
T×(dV+dA)的
X
X
X表示原始特征的串联,以利用原始的先验知识。
g
g
g是归一化函数,函数
f
f
f用于计算一对特征的余弦相似度,其定义如下:
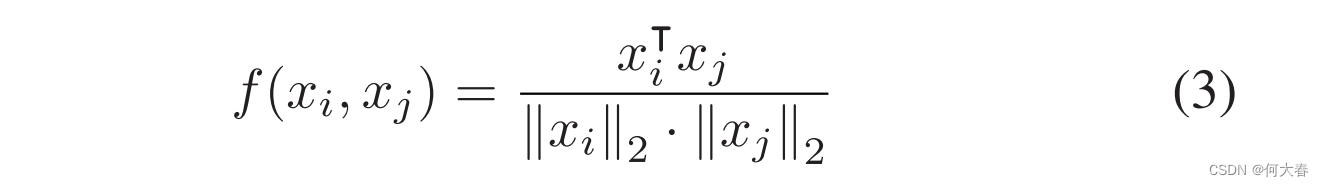
在公式(3)中的相似性被限制在(0, 1]的范围内,然后使用阈值机制来过滤掉更不相似的成对弱关系,并加强更相似成对的关系。阈值机制如下所示:
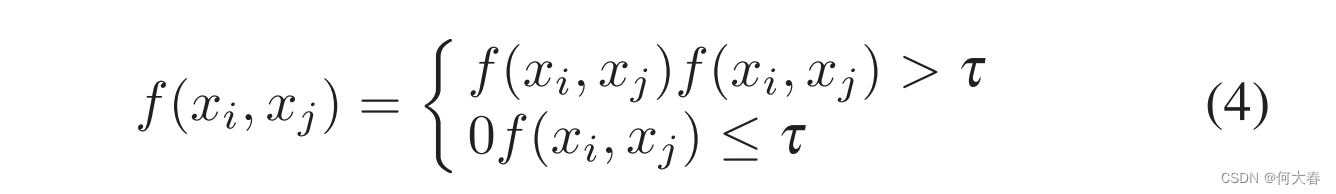
其中τ是阈值,其位于0和1之间。
之后,使用归一化函数
g
g
g来确保A的每行之和为1,这里我们采用softmax作为
g
g
g,如图所示:
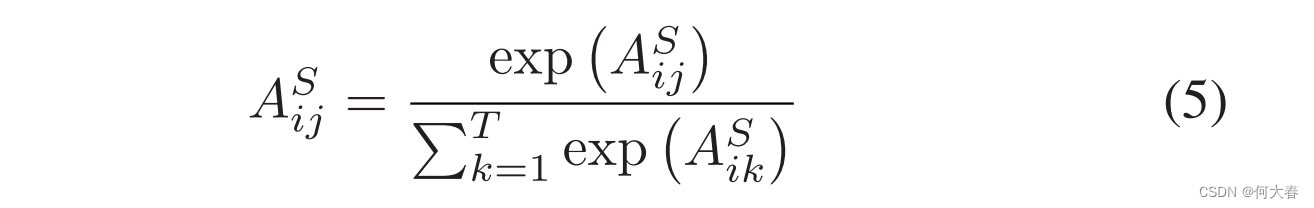
遵循GCN范例,我们如下引入相似性层,
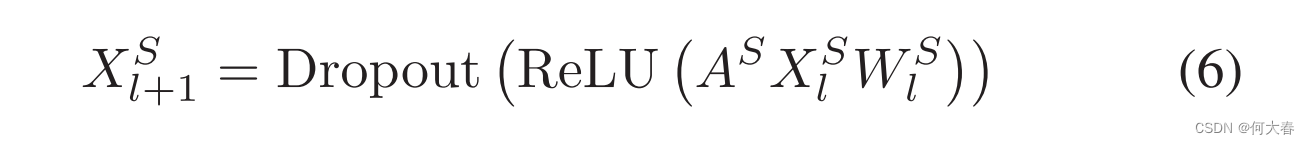
这样的操作旨在基于全局范围内特征的加权和来计算位置响应,而不是基于局部邻居。W是用于转换特征空间的可学习权重。
接近性分支的实现:虽然相似性分支可以捕捉长程依赖性,但它直接计算任意两个位置之间的相似性,并忽视了位置距离。位置信息在视频中也起着至关重要的作用,例如,时间事件检测。在这项工作中,我们在接近性先验之上设计了另一个关系矩阵,如下所示:
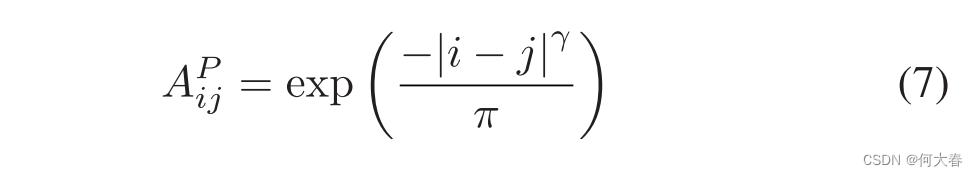
这里第
i
i
i个和第
j
j
j个特征之间的接近性关系仅与它们相对时间位置有关,其中
γ
\gamma
γ和
π
\pi
π是超参数,用于控制距离关系的影响范围。这样的设置确保了位置越接近,关系越高;否则,关系越小。
类似地,邻近层如下所示,
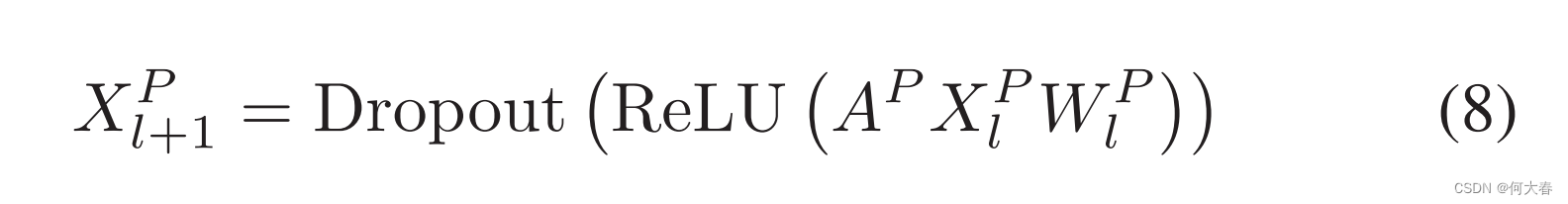
评分分支的实现:如上所述,用于暴力检测的前瞻性算法旨在进行离线检测,例如,互联网录像机,以及在线检测,例如,监控系统。然而,以上 RM 模块的在线检测受到一个主要障碍的阻碍:RM 模块通过整个视频获取长程依赖性。为了解决这一困境,我们提出了一个在线检测器,它将先前的视频片段作为输入,而不是整个视频,以在 RM 模块的指导下生成粗粒度和细粒度的预测。具体来说,两个堆叠的全连接(FC)层后跟 ReLU 和两个并行分类器构成了在线检测器。一个分类器是在线粗粒度分类器,即,一个具有时间上大小为5的卷积核,步长为1,填充为4的因果卷积层,在时间上滑动卷积滤波器。该分类器的输出是形状为
T
T
T 的粗粒度暴力激活,表示为
C
O
C
C^{OC}
COC。另一个分类器是在线细粒度分类器,它包括两个 1D 卷积层。第一层是一个因果层,卷积核大小为5,然后是 ReLU,第二层将特征投影到
M
+
1
M+1
M+1 维空间,以获得细粒度暴力激活,表示为
C
O
F
C^{OF}
COF。
这个操作引入了一个额外的分支,称为评分分支,它依赖于
C
O
C
C^{OC}
COC。评分分支旨在计算一个位置响应,作为所有位置特征的加权和,其中权重依赖于预测分数
C
O
C
C^{OC}
COC 的接近程度。与相似性和接近性分支的关系矩阵不同,评分分支的关系矩阵在每次迭代中动态更新。具体来说,评分分支的关系矩阵设计如下:
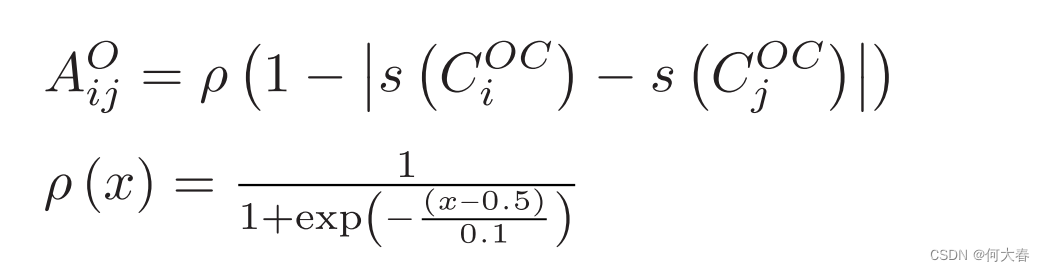
其中,
s
s
s 是 Sigmoid 函数,
ρ
\rho
ρ 是 Sigmoid 的一种变体,其作用是基于预测分数的接近程度来转换成对关系。如果一对之间的分数接近(在本文中,0.5 是预定义的阈值),则增加这对之间的关系;否则,减少。Softmax 也用于归一化。
类似地,评分层如下所示:
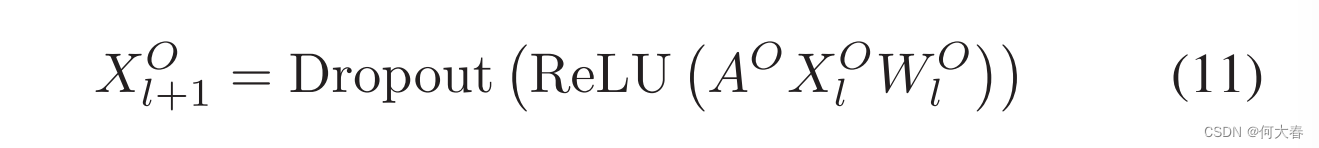
其中
X
0
O
(
=
X
0
S
=
X
0
P
)
=
X
F
\begin{aligned}X_0^O(=X_0^S=X_0^P)=X^F\end{aligned}
X0O(=X0S=X0P)=XF
C. Training and Inference
我们设计了两个类似于在线检测器的并行分类器,将特征映射到两个不同的空间。具体来说,我们简单地使用一个 FC 层作为粗粒度分类器,将串联表示投影到类别空间,其中这个 FC 层的输出大小为 1。粗粒度的暴力激活
C
C
∈
R
T
C^C{\in}\mathbb{R}^T
CC∈RT 可以表示如下:
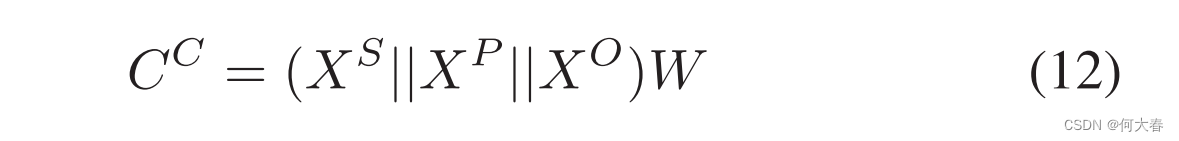
其中
∥
\|
∥ 表示连接操作。类似地,我们引入了细粒度分类器,它将串联表示投影到
M
+
1
M+1
M+1 维空间。细粒度的暴力激活可以表示如下:
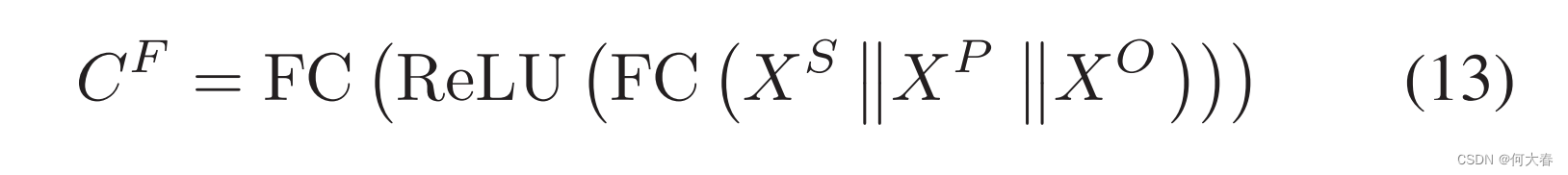
由于我们只有视频级别的真实标签,我们需要获得视频级别的预测。在此之后,计算视频级别预测和真实标签之间的差异。遵循 MIL [6],[38] 的原则,我们使用时间维度上的 Top-K 激活的平均值而不是整个激活来计算粗粒度置信度
p
O
C
,
p
C
p^{OC},p^C
pOC,pC 和细粒度置信度
p
O
F
,
p
F
p^{OF},p^F
pOF,pF。具体地,预测的置信度可以计算如下:
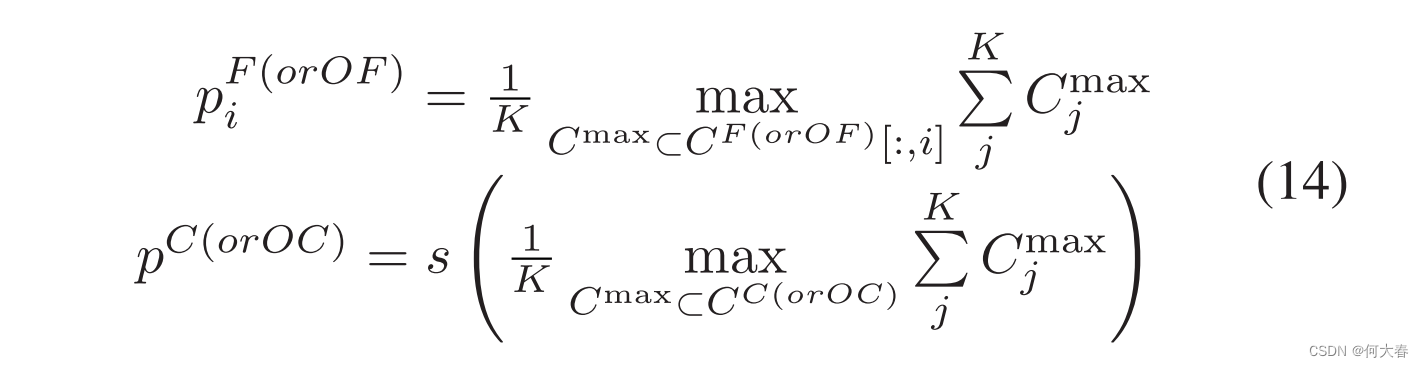
其中
C
m
a
x
C^{max}
Cmax 是前
K
K
K 大的激活值,而
K
K
K 的定义如下:
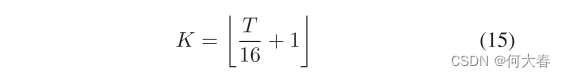
粗粒度分类损失是预测的粗粒度置信度
p
C
(
o
r
O
C
)
p^{C(orOC)}
pC(orOC) 和真实标签
y
B
y^{B}
yB 之间的二元交叉熵,如下所示:
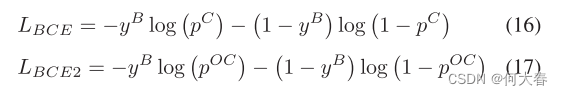
细粒度分类损失是基于交叉熵的,我们首先使用softmax得到概率质量函数,定义如下:
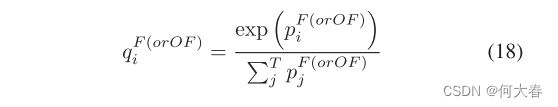
那么,细粒度分类定义为:
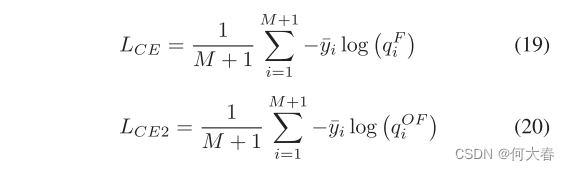
由于一个视频可能包含多个暴力事件,因此我们在这里对 y 进行 L1 归一化得到
y
ˉ
\bar{y}
yˉ。此外,还利用知识蒸馏损失来鼓励在线检测器的输出逼近 RM 模块的输出,具体如下所示:
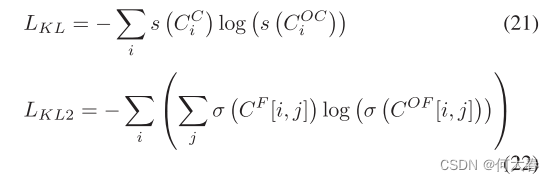
其中函数σ为softmax。最后,将上述损失加起来计算总损失,如下所示:
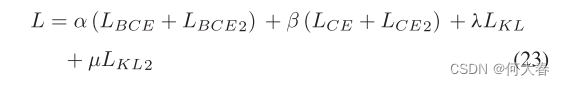
推断:对于粗粒度暴力帧检测,我们使用 Sigmoid 函数对粗粒度暴力激活
C
C
C^C
CC 和
C
O
C
C^{OC}
COC 进行归一化,并计算离线和在线粗粒度暴力置信度,限制在 [0,1] 的范围内,因为我们的模型可以选择离线或在线方式来检测暴力事件,以满足不同的需求。值得注意的是,在在线推断中,RM 模块被移除,只有在线检测器起作用。对于细粒度暴力事件检测,我们遵循之前的工作[39],使用阈值策略来预测暴力事件。在测试时给定一个暴力视频,我们首先丢弃细粒度置信度低于某个阈值(本文中使用0.0)的暴力类别。然后,对于剩余的每个类别,我们沿着时间轴应用一个阈值来获取暴力片段。预测的暴力片段的得分是其最高帧激活和相应类别激活的加权和。
IV. EXPERIMENTS
V. CONCLUSION
在本文中,我们研究了大规模暴力数据上的弱监督音视频暴力检测。我们引入了两个互补的任务,一个是粗粒度暴力帧检测,重点是在帧级别上区分,另一个是细粒度暴力事件检测,考虑了预测的暴力事件的类别和连续性。然后,我们提出了一种通用方法,明确地建模了视频片段之间的关系,并学习了强大的音视频表示。大量实验证明,
- 多模态显著提高了性能;
- 明确地利用关系非常有效;
- 我们的方法在两个不同的任务上表现良好,而且多任务学习在我们的方法中是有效的。
阅读总结
这篇文章的Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision 拓展工作。
主要是增加了一个细粒度的分支。
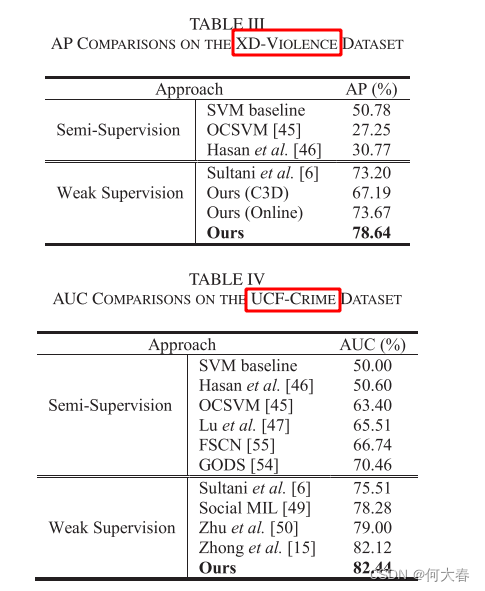
两篇文章在XD-Violence上的结果都是一样的吗?
左边是这篇文章的,右边是之前的那篇文章。
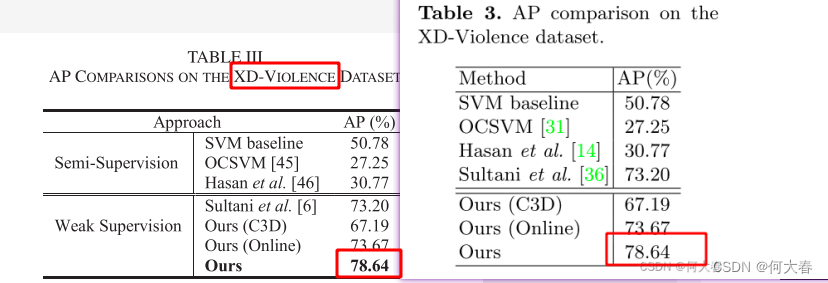
怎么说网络和损失都是变化了一些的。










![[AI]-(第0期):认知深度学习](https://img-blog.csdnimg.cn/direct/ae6a6d303af44505939b2c817b2c08f3.png#pic_center)