详解Pod的配置管理与调度特性等剖析
- Kubernetes 中 Pod 的配置管理(ConfigMap)、调度策略、回滚与扩缩容详解
- 一、Pod 配置管理:ConfigMap
- 创建 ConfigMap 示例
- 使用 ConfigMap 的 Pod 示例
- 二、玩转 Pod 调度:Kubernetes 高级调度策略大揭秘(带示例)
- 三、Pod 回滚
- 回滚 Deployment 示例
- 四、Pod 扩缩容
- 扩容 Pod 示例
- 缩容 Pod 示例
- 大总结
- 一、ConfigMap 概述与创建/使用示例及应用场景
- 二、Kubernetes 调度策略及示例
- 三、Pod 回滚
- 四、Pod 扩缩容
Kubernetes 中 Pod 的配置管理(ConfigMap)、调度策略、回滚与扩缩容详解
一、Pod 配置管理:ConfigMap
ConfigMap 是 Kubernetes 中一种用于存储应用配置数据的资源对象,旨在将应用的配置细节从容器镜像中解耦出来,
以便在不修改镜像的前提下,能够灵活地管理和更新应用配置。
ConfigMap 主要包含两种数据类型:键值对(key-value pairs)和配置文件内容。
具备以下主要特性:
-
数据隔离:ConfigMap 将应用配置与镜像分离,使配置更改无需重新构建镜像,提升了灵活性和可维护性。
-
类型多样:支持键值对形式的数据存储,也可以存储完整的配置文件内容,满足不同应用场景的需求。
-
数据注入:ConfigMap 数据可以通过环境变量、命令行参数或卷挂载等方式注入到 Pod 中,供容器内应用读取。
-
更新热加载:当 ConfigMap 更新后,若 Pod 使用了 ConfigMap 卷,Kubernetes 可以触发 Pod 内部的配置自动更新(需应用支持)。
创建 ConfigMap 示例
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
app.properties: |-
key1=value1
key2=value2
database-config.yaml: |-
username: dbuser
password: dbpassword
上述 YAML 描述了一个名为 example-configmap 的 ConfigMap,其中包含两个配置文件内容:app.properties 和 database-config.yaml。
使用 ConfigMap 的 Pod 示例
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: app-container
image: your-app-image
volumeMounts:
- name: config-volume
mountPath: /etc/config
envFrom:
- configMapRef:
name: example-configmap
volumes:
- name: config-volume
configMap:
name: example-configmap
在这个例子中,我们创建了一个 Pod 并挂载了 example-configmap ConfigMap 到容器内的 /etc/config 目录,同时还将 ConfigMap 中的数据注入到容器环境变量,供应用直接读取。
使用ConfigMap的限制条件如下。
◎ ConfigMap必须在Pod之前创建。
◎ ConfigMap受Namespace限制,只有处于相同Namespace中的Pod才可以引用它。
◎ ConfigMap中的配额管理还未能实现。
◎ kubelet只支持可以被API Server管理的Pod使用ConfigMap。kubelet在本Node上通过 --manifest-url或–config自动创建的静态Pod将无法引用ConfigMap。
◎ 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,在目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其他文件,则容器内的该目录将被挂载的ConfigMap覆盖。如果应用程序需要保留原来的其他文件,则需要进行额外的处理。可以将ConfigMap挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接到(cp或link命令)应用所用的实际配置目录下。
二、玩转 Pod 调度:Kubernetes 高级调度策略大揭秘(带示例)
Kubernetes 调度策略丰富多样,主要特性包括:
-
节点亲和性/反亲和性:通过节点标签选择特定节点部署 Pod,或者避免在某些节点上部署,如 nodeAffinity 和 nodeAntiAffinity。
-
区域亲和性/反亲和性:根据区域、可用区等高级地理属性控制 Pod 分布,确保应用高可用或资源优化。
-
资源约束:根据节点的 CPU、内存、磁盘、GPU 等资源条件进行调度,如 resources.requests 和 resources.limits。
-
污点容忍度:允许 Pod 允许或容忍节点上的污点(Taint),实现精细化调度。
-
NodeSelector: 根据节点标签和字段进行选择,将 Pod 限制在具有特定特性的节点上运行。
示例:假设您有一个 Pod 需要访问专用的 GPU 资源。您可以使用 NodeSelector 将 Pod 调度到具有
gpu=true标签的节点上。apiVersion: v1 kind: Pod metadata: name: gpu-pod spec: nodeSelector: gpu: "true" containers: - name: my-app image: my-app-image # ...其他容器配置 -
Pod Affinity & Anti-Affinity: 基于 Pod 的亲和性和反亲和性进行选择,控制 Pod 之间的距离,提升应用程序性能。
示例:假设您有一个 Web 应用程序和一个数据库 Pod。您可以使用 Pod Affinity 将它们调度到同一节点上,降低网络延迟,提升性能。
apiVersion: v1 kind: Pod metadata: name: web-pod spec: affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web containers: - name: my-web-app image: my-web-app-image # ...其他容器配置您可以使用 Pod Anti-Affinity 将对资源有竞争的 Pod 隔离在不同的节点上,避免争抢资源导致性能下降。
-
Tolerations & Taints: 利用容忍度和污点机制,控制 Pod 对节点瑕疵的敏感程度,灵活安排 Pod 运行位置。
示例:假设您有一个节点,其上存在
node.unreachable: NoRouteFound污点。您可以为 Pod 添加 Tolerations 允许它运行在该节点上。apiVersion: v1 kind: Pod metadata: name: my-pod spec: tolerations: - key: node.unreachable operator: Exists containers: - name: my-app image: my-app-image # ...其他容器配置 -
DaemonSet: 确保每个节点上都运行一个 Pod 副本,常用于部署集群范围的服务。
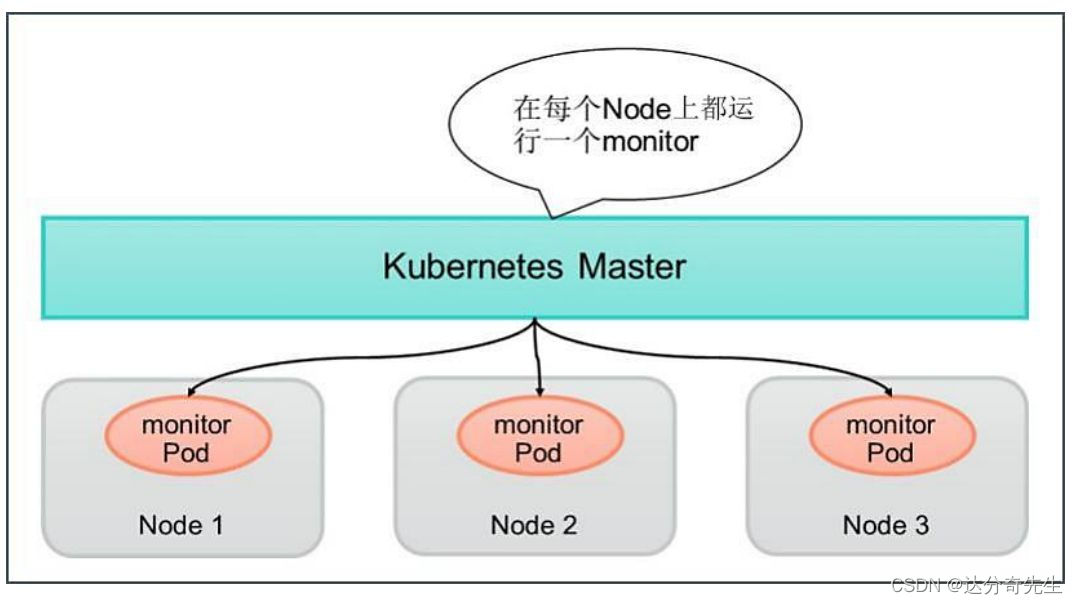
示例:假设您想在每个节点上部署一个日志收集代理。您可以使用 DaemonSet 来完成。
apiVersion: apps/v1 kind: DaemonSet metadata: name: logging-daemon spec: template: metadata: labels: app: logging spec: containers: - name: fluentd image: fluentd:latest # ...其他容器配置 -
Job: 用于运行一次性批处理作业,例如数据迁移或备份。
示例:假设您想执行一次性数据迁移任务。您可以使用 Job 来完成。
apiVersion: batch/v1 kind: Job metadata: name: data-migration spec: template: metadata: labels: app: data-migration spec: containers: - name: data-mover image: data-mover-image # ...其他容器配置 restartPolicy: OnFailure -
Cronjob: 定期运行作业,例如每日报告或每周备份。
示例:假设您想每天生成一份系统运行状况报告。您可以使用 Cronjob 来完成。
apiVersion: batch/v1beta1 kind: CronJob metadata: name: report-generator spec: schedule: "0 0 * * *" # 每天凌晨执行 jobTemplate: spec: template: metadata: labels: app: report-generator spec: containers: - name: report-generator-container image: your-report-generator-image:latest # 使用包含报告生成逻辑的镜像 command: ["/bin/sh", "-c"] # 假设容器内使用shell执行脚本 args: ["./generate_report.sh"] # 执行生成报告的脚本文件 volumeMounts: - name: report-storage mountPath: /var/reports # 将存储卷挂载至容器内的路径,以便持久化保存生成的报告 volumes: - name: report-storage persistentVolumeClaim: claimName: report-pvc # PVC名称,需要提前创建并关联PV用于持久化存储 restartPolicy: OnFailure # 如果任务失败,则尝试重启容器
上述 YAML 配置片段展示了一个完整的 CronJob 示例,它将在每天凌晨执行一个名为 report-generator 的任务来生成系统运行状况报告。
其中,spec.jobTemplate.spec.template.spec.containers 包含一个容器的具体配置,包括:
name: 容器的名字,这里填写为 report-generator-container。
image: 指定运行报告生成逻辑的应用镜像及其版本。
command 和 args:指定了容器启动后执行的命令及参数,这里假设运行一个 shell 脚本来生成报告。
volumeMounts:配置了容器内的文件目录挂载,将持久卷 report-storage 挂载到 /var/reports 目录下,便于存储生成的报告。
volumes:定义了使用的持久卷,这里引用了一个名为 report-pvc 的 PersistentVolumeClaim,确保生成的报告数据能够持久化存储。
restartPolicy: 设置当 Job 中的容器遇到故障时的重启策略,此处设置为 OnFailure,即当容器执行失败时,会尝试重新启动容器以生成报告。
要使此 CronJob 正常工作,你需要确保已有一个合适的 Docker 镜像用于报告生成,并且已经创建了相应的 PersistentVolumeClaim(PVC),使其能够绑定到合适的 PersistentVolume(PV)。
三、Pod 回滚
-
回滚功能 对于 Deployment 或 StatefulSet 等控制器管理的 Pod,具有以下特性:
-
版本历史记录:Kubernetes 会自动保留每次 Deployment 更新的历史记录,用于后续回滚操作。
-
无缝切换:回滚操作可以快速将 Pod 滚回到前一个已知的良好版本,无需人工干预,业务连续性得到保障。
-
可视化管理:通过 kubectl rollout history 命令查看 Deployment 的滚动更新历史,以便决定回滚到哪个版本。
回滚 Deployment 示例
kubectl rollout undo deployment/my-deployment
这条命令将会把 my-deployment 的当前版本回滚到前一个已知的稳定版本。
四、Pod 扩缩容
扩缩容功能 支持自动或手动调整 Pod 数量,主要特性如下:
-
弹性伸缩:根据 CPU 或内存使用率、自定义指标或外部指标自动调整 Pod 副本数,以应对负载变化。
-
一键操作:通过 kubectl scale 命令快速调整 Deployment 或 ReplicaSet 控制器管理的 Pod 副本数。
-
滚动更新策略:在扩缩容过程中,Kubernetes 采用滚动更新策略,逐步替换旧 Pod,保证服务不间断。
扩容 Pod 示例
kubectl scale deployment/my-deployment --replicas=5
这将把 my-deployment 的副本数调整为 5。
缩容 Pod 示例
kubectl scale deployment/my-deployment --replicas=3
以上命令将减少 my-deployment 的副本数至 3。
ConfigMap 为 Pod 提供了灵活的配置管理,而 Kubernetes 强大的调度策略和伸缩机制,则帮助我们轻松应对复杂的应用部署与运维挑战。
在实际操作中,合理运用这些功能,能够有效提升云原生环境下的应用部署与管理效率。
大总结
一、ConfigMap 概述与创建/使用示例及应用场景
| 特性 | 描述 | 示例 | 应用场景 |
|---|---|---|---|
| 数据隔离 | 应用配置与镜像分离,方便独立更新 | 如上所示的 example-configmap 创建与挂载示例 | 配置频繁变动的应用,如数据库连接信息、API 密钥 |
| 数据类型 | 支持键值对和完整配置文件内容 | app.properties 和 database-config.yaml | Spring Boot 应用的属性文件、数据库连接配置 |
| 数据注入 | 通过环境变量、命令行参数、卷挂载注入 Pod | envFrom 使用 ConfigMap 注入环境变量 | 无需修改应用代码即可传递配置信息 |
| 热加载 | 更新ConfigMap后,符合条件的Pod可自动刷新配置 | 当 config-volume 卷挂载 ConfigMap | 实现实时配置更新,比如调整应用阈值 |
创建 ConfigMap 示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
app.properties: |-
key1=value1
key2=value2
database-config.yaml: |-
username: dbuser
password: dbpassword
使用 ConfigMap 的 Pod 示例:
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: app-container
image: your-app-image
volumeMounts:
- name: config-volume
mountPath: /etc/config
envFrom:
- configMapRef:
name: example-configmap
volumes:
- name: config-volume
configMap:
name: example-configmap
应用场景举例:
- 数据隔离:在一个电商网站中,数据库密码需要定期更换,通过 ConfigMap 存储并更新密码,避免每次修改都需重建应用镜像。
- 数据类型:Web 服务器配置文件(如 Nginx 的
nginx.conf),可通过 ConfigMap 存储并挂载到容器内,实现配置统一管理与更新。 - 数据注入:微服务应用中,通过环境变量传递API密钥,保持密钥安全且易于管理。
- 热加载:在线游戏服务器,根据流量调整限流阈值,更新 ConfigMap 后,游戏服务器能实时感知并应用新配置。
二、Kubernetes 调度策略及示例
| 调度策略 | 描述 | 示例 | 应用场景 |
|---|---|---|---|
| NodeSelector | 根据节点标签调度 Pod | 根据 gpu=true 标签调度 Pod 到 GPU 节点 | GPU 高性能计算任务 |
| Pod Affinity/Anti-Affinity | 控制 Pod 间的亲和/反亲和关系 | 同一节点部署 Web 与 DB Pod,保证低延迟 | 微服务架构中关联性强的服务部署 |
| 资源约束 | 根据节点资源进行调度 | 设置 CPU 请求为 1, 限制为 2 | 保证 Pod 不过度消耗节点资源 |
| Tolerations | 控制 Pod 对污点节点的容忍度 | 能够容忍 node.kubernetes.io/unreachable 污点的 Pod | 在问题节点上运行监控诊断工具 |
| DaemonSet | 确保每个节点运行单个 Pod 实例 | 部署日志收集代理到集群所有节点 | 全局日志收集、监控代理 |
| Job | 执行一次性任务 | 执行全量数据迁移作业 | 数据库迁移、定期全量备份 |
| CronJob | 定时执行任务 | 每天凌晨生成系统运行状况报告 | 定期报表生成、清理任务 |
资源约束示例:
apiVersion: v1
kind: Pod
metadata:
name: resource-constraint-pod
spec:
containers:
- name: my-app
image: my-app-image
resources:
requests:
cpu: "1"
limits:
cpu: "2"
DaemonSet 示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-collector-daemonset
spec:
selector:
matchLabels:
app: log-collector
template:
metadata:
labels:
app: log-collector
spec:
tolerations:
- operator: Exists
effect: NoSchedule # 保证 DaemonSet 的 Pod 运行在所有节点上
containers:
- name: log-agent
image: log-collector-image:v1.0
ports:
- containerPort: 5000 # 假设这是日志收集端口
volumeMounts:
- mountPath: /var/log
name: host-logs
volumes:
- name: host-logs
hostPath:
path: /var/log
上述配置创建了一个名为 log-collector-daemonset 的 DaemonSet,它确保集群中的每个节点都运行一个名为 log-agent 的容器,用于从每个节点上的 /var/log 目录收集日志。由于设置了 tolerations,这些 Pod 将会被调度至所有节点,即使节点上有其他污点(如未调度)。
此外,Kubernetes 还提供了其他高级调度策略,例如:
-
Inter-Pod Affinity and Anti-Affinity:除了 Pod 之间的亲和性和反亲和性之外,还可以定义跨命名空间的 Pod 之间的亲和规则。
-
PriorityClass:通过给 Pod 分配优先级等级来影响其调度决策,高优先级 Pod 更有可能被优先调度。
这些策略灵活组合使用,可以帮助管理员实现更加复杂且精准的资源管理和应用部署方案,以适应各种不同的业务需求。
三、Pod 回滚
| 特性 | 描述 | 示例 | 应用场景 |
|---|---|---|---|
| 版本历史记录 | 自动保留更新历史,可用于回滚操作 | N/A | 发现新版本存在问题时,迅速恢复到先前正常运行版本 |
| 无缝切换 | 快速回滚至前一稳定版本,不影响服务 | N/A | 应用出现 bug 或不可预见的问题,需要快速回滚至无问题版本 |
| 可视化管理 | 使用 kubectl rollout history 查看并决定回滚版本 | kubectl rollout history deployment/my-deployment | 开发、测试环境中对比不同版本表现,或生产环境中排查问题时选择合适的回滚版本 |
| 回滚操作示例 | 回滚至上一个修订版 | kubectl rollout undo deployment/my-deployment | 生产环境中因新版本发布引发故障,立即回滚至已知良好状态 |
四、Pod 扩缩容
| 特性 | 描述 | 示例 | 应用场景 |
|---|---|---|---|
| 弹性伸缩 | 根据负载自动调整副本数 | CPU 或内存利用率驱动,由 Horizontal Pod Autoscaler 控制 | 应对流量高峰和低谷,自动增加或减少服务实例,节约资源成本 |
| 一键操作 | 快速调整 Pod 数量 | 扩容至5个副本:kubectl scale deployment/my-deployment --replicas=5缩容至3个副本: kubectl scale deployment/my-deployment --replicas=3 | 针对突发业务需求,手动快速增加服务容量;非高峰期手动减少副本以节省资源 |
| 滚动更新策略 | 保证服务连续性 | 在扩缩容过程中,Kubernetes 逐步替换旧 Pod,维持服务不受中断 | 服务升级、扩缩容时,确保在线用户不受影响,维持 SLA 和用户体验 |
晚安