参考链接:hive sql面试题及答案 - 知乎
1、编写sql实现每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
数据:
userid,month,visits
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,1
预期结果:

create table u_visit(
userid STRING ,month STRING ,visits BIGINT
) LIFECYCLE 1;
INSERT into u_visit values
('A','2015-01',5)
,('A','2015-01',15)
,('B','2015-01',5)
,('A','2015-01',8)
,('B','2015-01',25)
,('A','2015-01',5)
,('A','2015-02',4)
,('A','2015-02',6)
,('B','2015-02',10)
,('B','2015-02',5)
,('A','2015-03',16)
,('A','2015-03',22)
,('B','2015-03',23)
,('B','2015-03',10)
,('B','2015-03',1);
SELECT userid
,MONTH
,visits
,max(visits) OVER(PARTITION BY userid ) AS max_visit
,max(visits) OVER(PARTITION BY userid ORDER BY MONTH ASC ) AS max_visit --截止到当月最大值
,SUM(visits) OVER(PARTITION BY userid ORDER BY MONTH ASC ) AS sum_visit
FROM (
SELECT userid
,MONTH
,sum(visits) visits
FROM u_visit
GROUP BY userid
,MONTH
) A
;
userid month visits max_visit max_visit2 sum_visit
A 2015-01 33 38 33 33
A 2015-02 10 38 33 43
A 2015-03 38 38 38 81
B 2015-01 30 34 30 30
B 2015-02 15 34 30 45
B 2015-03 34 34 34 79
2、求出每个栏目的被观看次数及累计观看时长
数据:
vedio表
Uid channl min
1 1 23
2 1 12
3 1 12
4 1 32
5 1 342
6 2 13
7 2 34
8 2 13
9 2 134
3、编写连续7天登录的总人数
数据:
t1表
Uid dt login_status(1登录成功,0异常)
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 1
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1
4、编写sql语句实现每班前三名,分数一样并列,同时求出前三名按名次排序的一次的分差:
数据:
stu表
Stu_no class score
1 1901 90
2 1901 90
3 1901 83
4 1901 60
5 1902 66
6 1902 23
7 1902 99
8 1902 67
9 1902 87
5、每个店铺的当月销售额和累计到当月的总销售额
数据:
店铺,月份,金额
a,01,150
a,01,200
b,01,1000
b,01,800
c,01,250
c,01,220
b,01,6000
a,02,2000
a,02,3000
b,02,1000
b,02,1500
c,02,350
c,02,280
a,03,350
a,03,250
6、分析用户的行为习惯,找到每个用户的第一次行为
数据:user_action_log
uid time action
1 time1 Read
3 time2 Comment
1 time3 Share
2 time4 Like
1 time5 Write
2 time6 Share
3 time7 Write
2 time8 Read
7、订单及订单类型行列互换
t1表:
order_id order_type order_time
111 N 10:00
111 A 10:05
111 B 10:10
是用hql获取结果如下:
order_id order_type_1 order_type_2 order_time_1 order_time_2
111 N A 10:00 10:05
111 A B 10:05 10:10
8、某APP每天访问数据存放在表access_log里面,包含日期字段 ds,用户类型字段user_type,用户账号user_id,用户访问时间 log_time,请使用hive的hql语句实现如下需求:
(1)、每天整体的访问UV、PV?
(2)、每天每个类型的访问UV、PV?
(3)、每天每个类型中最早访问时间和最晚访问时间?
(4)、每天每个类型中访问次数最高的10个用户?
9、每个用户连续登陆的最大天数?
数据:
login表
uid,date
1,2019-08-01
1,2019-08-02
1,2019-08-03
2,2019-08-01
2,2019-08-02
3,2019-08-01
3,2019-08-03
4,2019-07-28
4,2019-07-29
4,2019-08-01
4,2019-08-02
4,2019-08-03
结果如下:
uid cnt_days
1 3
2 2
3 1
4 3
10、使用hive的hql实现男女各自第一名及其它
id sex chinese_s math_s
0 0 70 50
1 0 90 70
2 1 80 90
1、男女各自语文第一名(0:男,1:女)
2、男生成绩语文大于80,女生数学成绩大于70
11、使用hive的hql实现最大连续访问天数
log_time uid
2018-10-01 18:00:00,123
2018-10-02 18:00:00,123
2018-10-02 19:00:00,456
2018-10-04 18:00:00,123
2018-10-04 18:00:00,456
2018-10-05 18:00:00,123
2018-10-06 18:00:00,123
12、编写sql实现行列互换

行转列:
1、使用case when 查询出多列即可,即可增加列。
列转行:
1、lateral view explode(),使用炸裂函数可以将1列转成多行,被转换列适用于array、map等类型。 lateral view posexplode(数组),如有排序需求,则需要索引。将数组炸开成两行(索引 , 值),需要 as 两个别名。
2、case when 结合concat_ws与collect_set/collect_list实现。内层用case when,外层用 collect_set/list收集,对搜集完后用concat_ws分割连接形成列。
13、编写sql实现如下:
数据:
t1表
uid tags
1 1,2,3
2 2,3
3 1,2
编写sql实现如下结果:
uid tag
1 1
1 2
1 3
2 2
2 3
3 1
3 2
14、用户标签连接查询
数据:
T1表:
Tags
1,2,3
1,2
2,3
T2表:
Id lab
1 A
2 B
3 C
根据T1和T2表的数据,编写sql实现如下结果:
ids tags
1,2,3 A,B,C
1,2 A,B
2,3 B,C
预期结果:

15、用户标签组合
数据:
t1表:
id tag flag
a b 2
a b 1
a b 3
c d 6
c d 8
c d 8
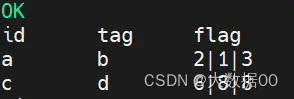
编写sql实现如下结果:
id tag flag
a b 1|2|3
c d 6|8
预期结果:
16、户标签行列互换
数据:
t1表
uid name tags
1 goudan chihuo,huaci
2 mazi sleep
3 laotie paly
编写sql实现如下结果:
uid name tag
1 goudan chihuo
1 goudan huaci
2 mazi sleep
3 laotie paly
17、hive实现词频统计
数据:
t1表:
uid contents
1 i|love|china
2 china|is|good|i|i|like
统计结果如下,如果出现次数一样,则按照content名称排序:
content cnt
i 3
china 2
good 1
like 1
love 1
is 1
18、课程行转列
数据:
t1表
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e
根据编写sql,得到结果如下(表中的1表示选修,表中的0表示未选修):
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
19、兴趣行转列
t1表
name sex hobby
janson 男 打乒乓球、游泳、看电影
tom 男 打乒乓球、看电影
hobby最多3个值,使用hql实现结果如下:
name sex hobby1 hobby2 hobby3
janson 男 打乒乓球 游泳 看电影
tom 男 打乒乓球 看电影
20、用户商品行列互换
t1表:
用户 商品
A P1
B P1
A P2
B P3
请你使用hql变成如下结果:1代表购买过的商品0代表未购买
用户 P1 P2 P3
A 1 1 0
B 1 0 1
21、求top3英雄及其pick率
id names
1 亚索,挖掘机,艾瑞莉娅,洛,卡莎
2 亚索,盖伦,奥巴马,牛头,皇子
3 亚索,盖伦,艾瑞莉娅,宝石,琴女
4 亚素,盖伦,赵信,老鼠,锤石
请用 HiveSQL 计算出出场次数最多的 top3 英雄及其 pick 率(=出现场数/总场数)
21、使用hive求出两个数据集的差集
数据
t1表:
id name
1 zs
2 ls
t2表:
id name
1 zs
3 ww
结果如下:
id name
2 ls
3 ww
22、两个表A 和B ,均有key 和value 两个字段,写一个SQL语句, 将B表中的value值置成A表中相同key值对应的value值
A:
key vlaue
k1 123
k2 234
k3 235
B:
key value
k1 111
k2 222
k5 246
使用hive的hql实现,结果是B表数据如下:
k1 123
k2 234
k5 246
23、有用户表user(uid,name)以及黑名单表Banuser(uid)
1、用left join方式写sql查出所有不在黑名单的用户信息
2、用not exists方式写sql查出所有不在黑名单的用户信息
24、使用什么来做的cube
使用with cube 、 with rollup 或者grouping sets来实现cube。
详细解释如下:
0、hive一般分为基本聚合和高级聚合
基本聚合就是常见的group by,高级聚合就是grouping set、cube、rollup等。
一般group by与hive内置的聚合函数max、min、count、sum、avg等搭配使用。
1、grouping sets可以实现对同一个数据集的多重group by操作。
事实上grouping sets是多个group by进行union all操作的结合,它仅使用一个stage完成这些操作。
grouping sets的子句中如果包换() 数据集,则表示整体聚合。多用于指定的组合查询。
2、cube俗称是数据立方,它可以时限hive任意维度的组合查询。
即使用with cube语句时,可对group by后的维度做任意组合查询
如:group a,b,c with cube ,则它首先group a,b,c 然后依次group by a,c 、 group by b,c、group by a,b 、group a 、group b、group by c、group by () 等这8种组合查询,所以一般cube个数=2^3个。2是定 值,3是维度的个数。多用于无级联关系的任意组合查询。
3、rollup是卷起的意思,俗称层级聚合,相对于grouping sets能指定多少种聚合,而with rollup则表示从左 往右的逐级递减聚合,如:group by a,b,c with rollup 等价于 group by a, b, c grouping sets( (a, b, c), (a, b), (a), ( )).直到逐级递减为()为止,多适用于有级联关系的组合查询,如国家、省、市级联组合查 询。
4、Grouping__ID在hive2.3.0版本被修复过,修复后的发型版本和之前的不一样。对于每一列,如果这列 被聚合 过则返回0,否则返回1。应用场景暂时很难想到用于哪儿。
5、grouping sets/cube/rollup三者的区别: 注: grouping sets是指定具体的组合来查询。 with cube 是group by后列的所有的维度的任意组合查询。
with rollup 是group by后列的从左往右逐级递减的层级组合查询。 cube/rollup 后不能加()来选择列,hive是要求这样。
25、访问日志正则提取
表t1(注:数据时正常的访问日志数据,分隔符全是空格)
8.35.201.160 - - [16/May/2018:17:38:21 +0800] "GET
/uc_server/data/avatar/000/01/54/22_avatar_middle.jpg HTTP/1.1" 200 5396
使用hive的hql实现结果如下:
ip dt url
8.35.201.160 2018-5-16 17:38:21
/uc_server/data/avatar/000/01/54/22_avatar_middle.jpg