原文:
www.backtrader.com/
数据 - 多个时间框架
原文:
www.backtrader.com/blog/posts/2015-08-24-data-multitimeframe/data-multitimeframe/
有时,使用不同的时间框架进行投资决策:
-
周线用于评估趋势
-
每日执行进入
或者 5 分钟对比 60 分钟。
这意味着在 backtrader 中需要组合多个时间框架的数据以支持这样的组合。
本地支持已经内置。最终用户只需遵循以下规则:
-
具有最小时间框架的数据(因此是较大数量的条)必须是添加到 Cerebro 实例的第一个数据
-
数据必须正确地对齐日期时间,以便平台能够理解它们的任何含义
此外,最终用户可以自由地在较短/较大的时间框架上应用指标。当然:
- 应用于较大时间框架的指标将产生较少的条
平台也将考虑以下内容
- 较大时间框架的最小周期
最小周期可能会导致在策略添加到 Cerebro 之前需要消耗几个数量级的较小时间框架的数据。
内置的DataResampler将用于创建较大的时间框架。
一些示例如下,但首先是测试脚本的来源。
# Load the Data
datapath = args.dataname or '../datas/sample/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(
dataname=datapath)
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Handy dictionary for the argument timeframe conversion
# Resample the data
if args.noresample:
datapath = args.dataname2 or '../datas/sample/2006-week-001.txt'
data2 = btfeeds.BacktraderCSVData(
dataname=datapath)
else:
data2 = bt.DataResampler(
dataname=data,
timeframe=tframes[args.timeframe],
compression=args.compression)
步骤:
-
加载数据
-
根据用户指定的参数重新采样它
脚本还允许加载第二个数据
-
将数据添加到 cerebro
-
将重新采样的数据(较大的时间框架)添加到 cerebro
-
运行
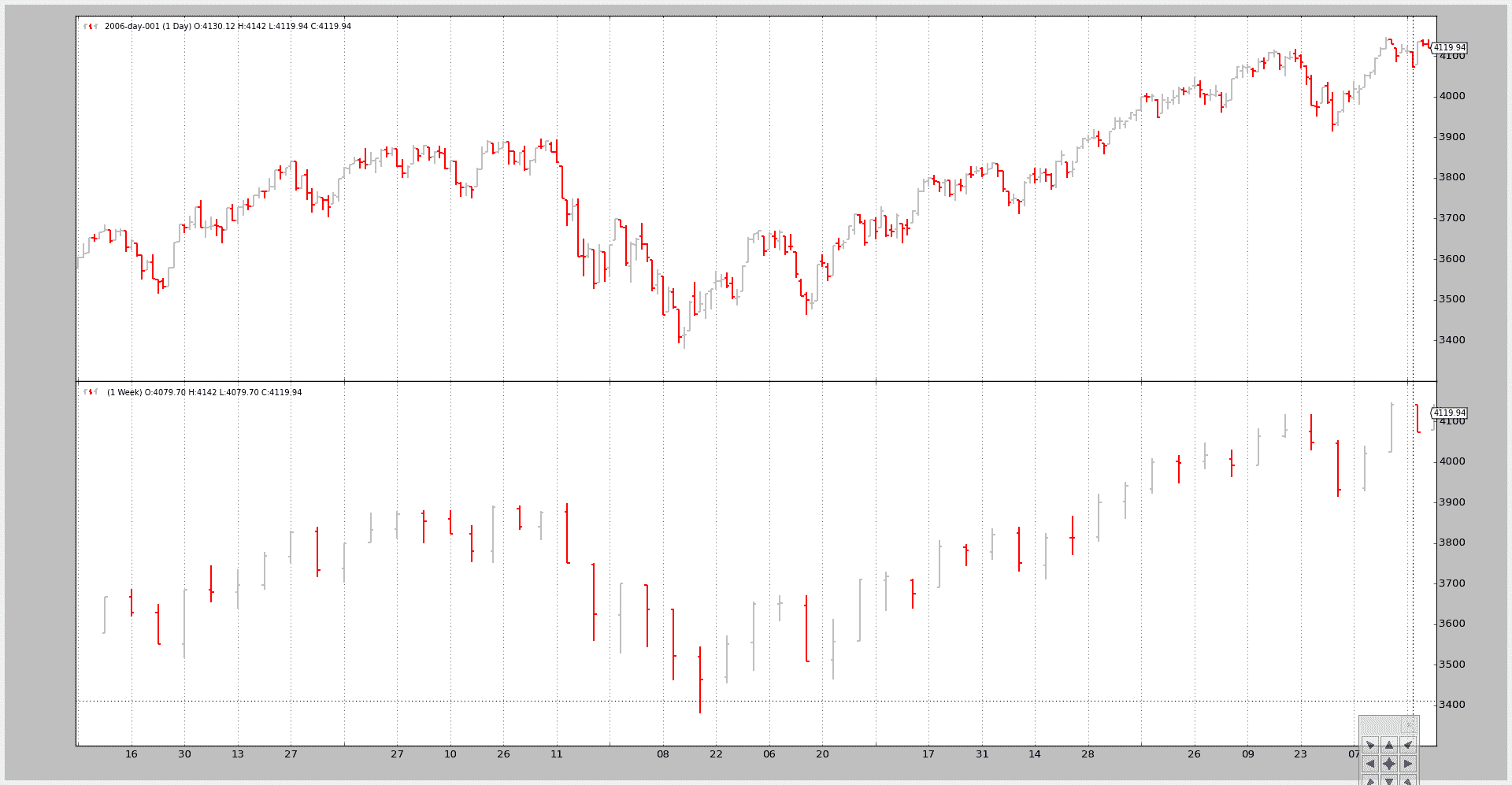
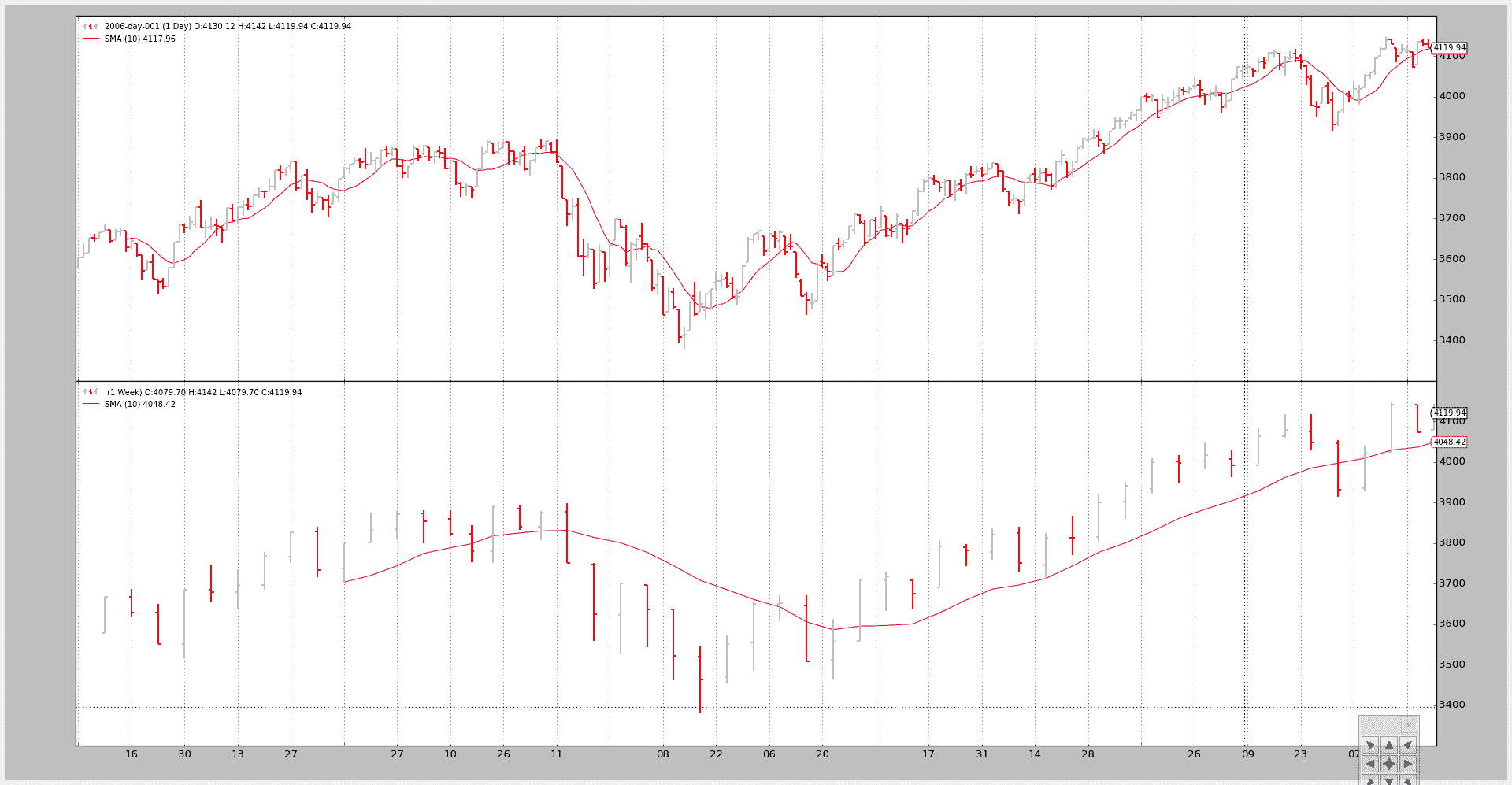
示例 1 - 每日和每周
脚本的调用:
$ ./data-multitimeframe.py --timeframe weekly --compression 1
和输出图表:
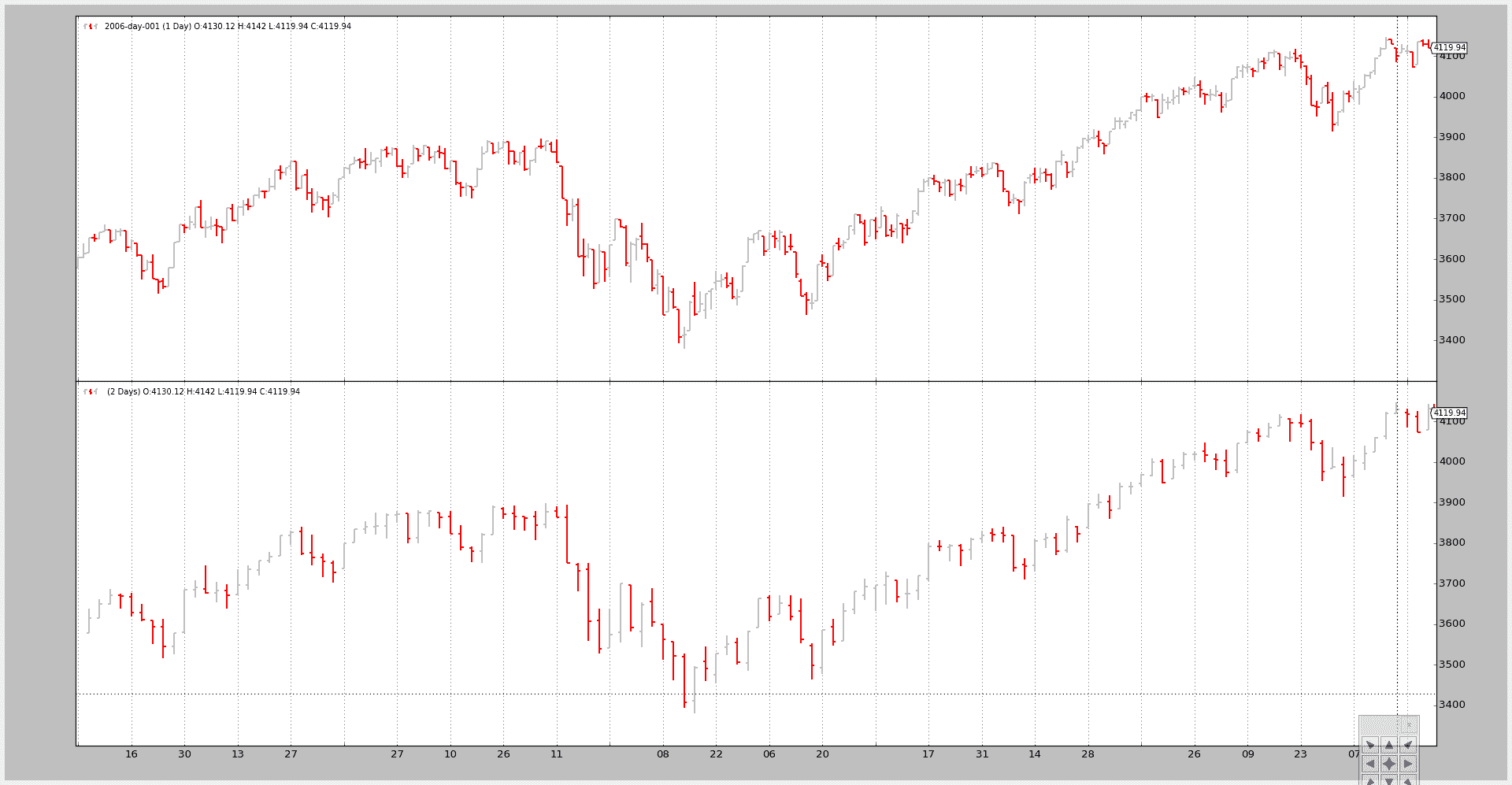
示例 2 - 日间和日间压缩(2 根变成 1 根)
脚本的调用:
$ ./data-multitimeframe.py --timeframe daily --compression 2
和输出图表:
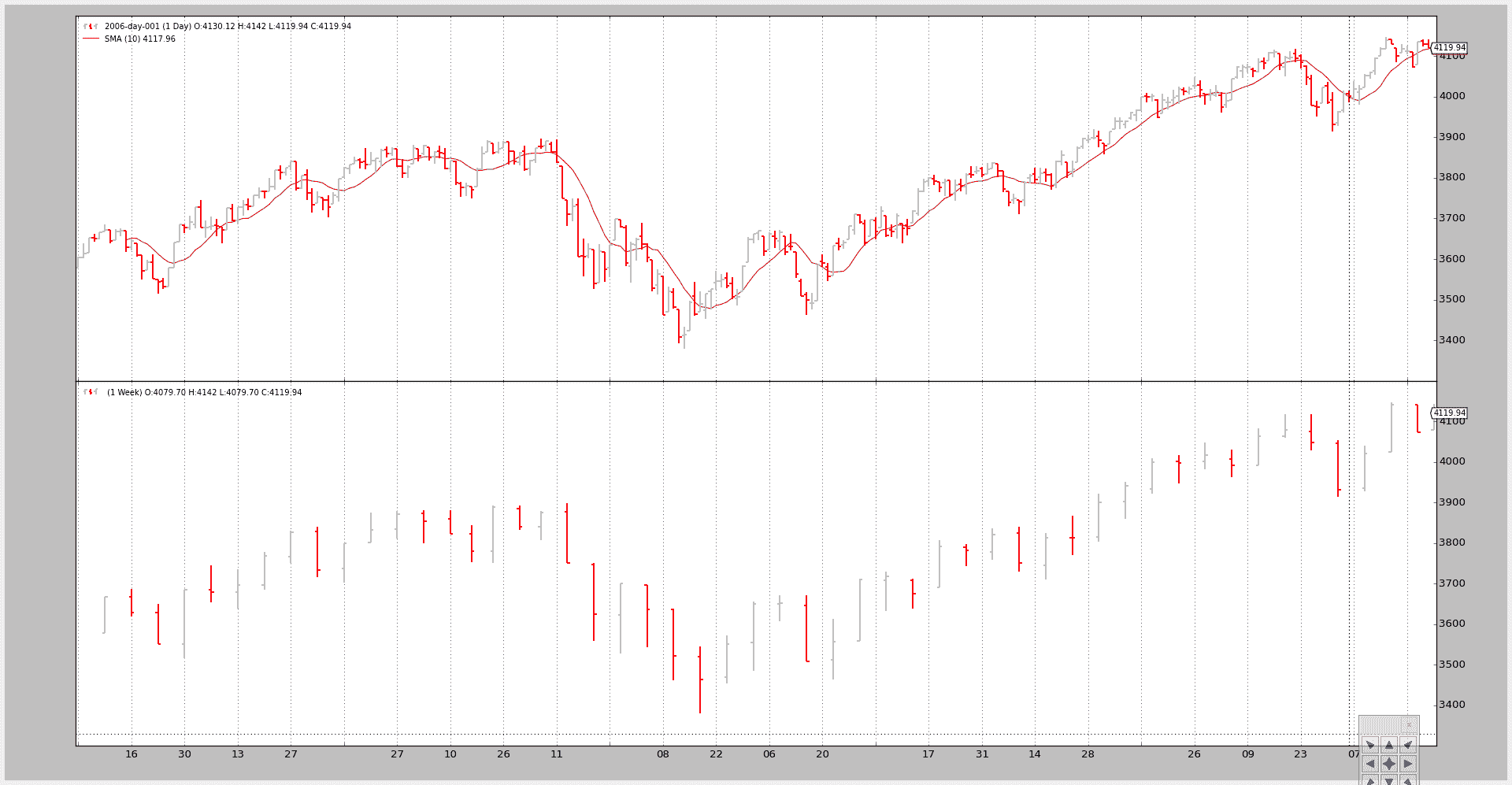
示例 3 - 带有 SMA 的策略
虽然绘图很好,但这里的关键问题是显示较大的时间框架如何影响系统,特别是当涉及到起始点时
脚本可以采用--indicators来添加一个策略,该策略在较小时间框架和较大时间框架的数据上创建10 周期的简单移动平均线。
如果只考虑较小的时间框架:
-
next将在 10 个条之后首先被调用,这是简单移动平均需要产生值的时间注意
请记住,策略监视创建的指标,并且只有在所有指标都产生值时才调用
next。理由是最终用户已经添加了指标以在逻辑中使用它们,因此如果指标尚未产生值,则不应进行任何逻辑
但在这种情况下,较大的时间框架(每周)会延迟调用next,直到每周数据的简单移动平均产生值为止,这需要… 10 周。
脚本覆盖了nextstart,它只被调用一次,默认调用next以显示首次调用的时间。
调用 1:
只有较小的时间框架,即每日,才有一个简单移动平均值。
命令行和输出
$ ./data-multitimeframe.py --timeframe weekly --compression 1 --indicators --onlydaily
--------------------------------------------------
nextstart called with len 10
--------------------------------------------------
以及图表。
调用 2:
两个时间框架都有一个简单移动平均。
命令行:
$ ./data-multitimeframe.py --timeframe weekly --compression 1 --indicators
--------------------------------------------------
nextstart called with len 50
--------------------------------------------------
--------------------------------------------------
nextstart called with len 51
--------------------------------------------------
--------------------------------------------------
nextstart called with len 52
--------------------------------------------------
--------------------------------------------------
nextstart called with len 53
--------------------------------------------------
--------------------------------------------------
nextstart called with len 54
--------------------------------------------------
注意这里的两件事:
-
不是在10个周期之后被调用,而是在 50 个周期之后第一次被调用。
这是因为在较大(周)时间框架上应用简单移动平均值后产生了一个值,… 这是 10 周* 5 天/周… 50 天。
-
nextstart被调用了 5 次,而不是仅 1 次。这是将时间框架混合并(在这种情况下仅有一个)指标应用于较大时间框架的自然副作用。
较大时间框架的简单移动平均值在消耗 5 个日间条时产生 5 倍相同的值。
由于周期的开始由较大的时间框架控制,
nextstart被调用了 5 次。
以及图表。
结论
多时间框架数据可以在backtrader中使用,无需特殊对象或调整:只需先添加较小的时间框架。
测试脚本。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class SMAStrategy(bt.Strategy):
params = (
('period', 10),
('onlydaily', False),
)
def __init__(self):
self.sma_small_tf = btind.SMA(self.data, period=self.p.period)
if not self.p.onlydaily:
self.sma_large_tf = btind.SMA(self.data1, period=self.p.period)
def nextstart(self):
print('--------------------------------------------------')
print('nextstart called with len', len(self))
print('--------------------------------------------------')
super(SMAStrategy, self).nextstart()
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
if not args.indicators:
cerebro.addstrategy(bt.Strategy)
else:
cerebro.addstrategy(
SMAStrategy,
# args for the strategy
period=args.period,
onlydaily=args.onlydaily,
)
# Load the Data
datapath = args.dataname or '../datas/sample/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(
dataname=datapath)
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Handy dictionary for the argument timeframe conversion
# Resample the data
if args.noresample:
datapath = args.dataname2 or '../datas/sample/2006-week-001.txt'
data2 = btfeeds.BacktraderCSVData(
dataname=datapath)
else:
data2 = bt.DataResampler(
dataname=data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# First add the original data - smaller timeframe
cerebro.adddata(data)
# And then the large timeframe
cerebro.adddata(data2)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--dataname2', default='', required=False,
help='Larger timeframe file to load')
parser.add_argument('--noresample', action='store_true',
help='Do not resample, rather load larger timeframe')
parser.add_argument('--timeframe', default='weekly', required=False,
choices=['daily', 'weekly', 'monhtly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help='Compress n bars into 1')
parser.add_argument('--indicators', action='store_true',
help='Wether to apply Strategy with indicators')
parser.add_argument('--onlydaily', action='store_true',
help='Indicator only to be applied to daily timeframe')
parser.add_argument('--period', default=10, required=False, type=int,
help='Period to apply to indicator')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
数据重新取样
原文:
www.backtrader.com/blog/posts/2015-08-23-data-resampling/data-resampling/
当数据仅在一个时间段可用,而分析必须针对不同的时间段进行时,就是时候进行一些重新取样了。
“重新取样”实际上应该称为“向上取样”,因为要从一个源时间段转换到一个较大的时间段(例如:从天到周)
“向下采样”目前还不可能。
backtrader 通过将原始数据传递给一个智能命名为 DataResampler 的过滤器对象来支持重新取样。
该类具有两个功能:
-
更改时间框架
-
压缩条柱
为此,DataResampler 在构造过程中使用标准的 feed.DataBase 参数:
-
timeframe(默认:bt.TimeFrame.Days)目标时间段必须与源时间段相等或更大才能有用
-
compression(默认:1)将所选值 “n” 压缩到 1 条柱
让我们看一个从每日到每周的手工脚本示例:
$ ./data-resampling.py --timeframe weekly --compression 1
输出结果:
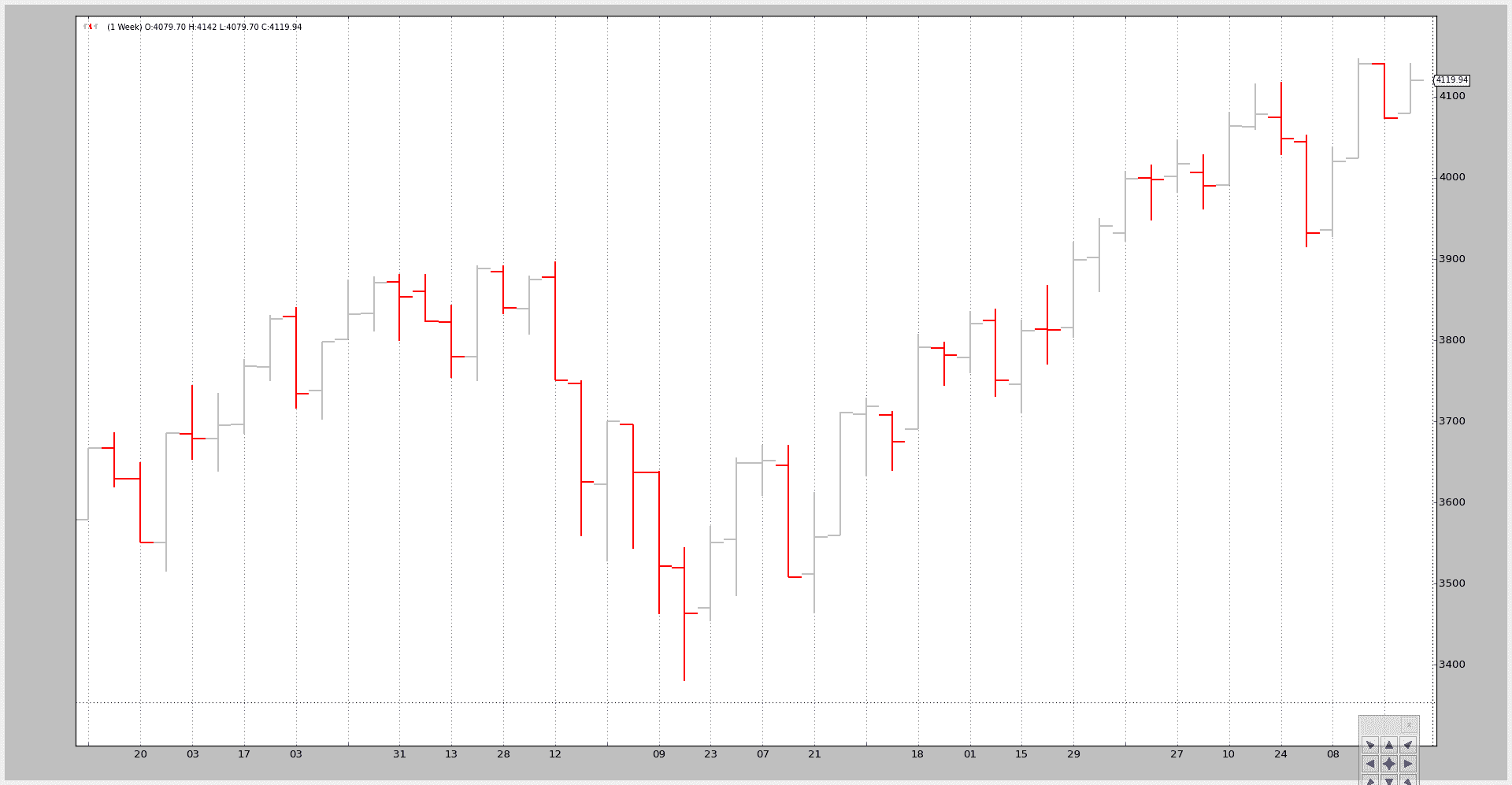
我们可以将其与原始每日数据进行比较:
$ ./data-resampling.py --timeframe daily --compression 1
输出结果:
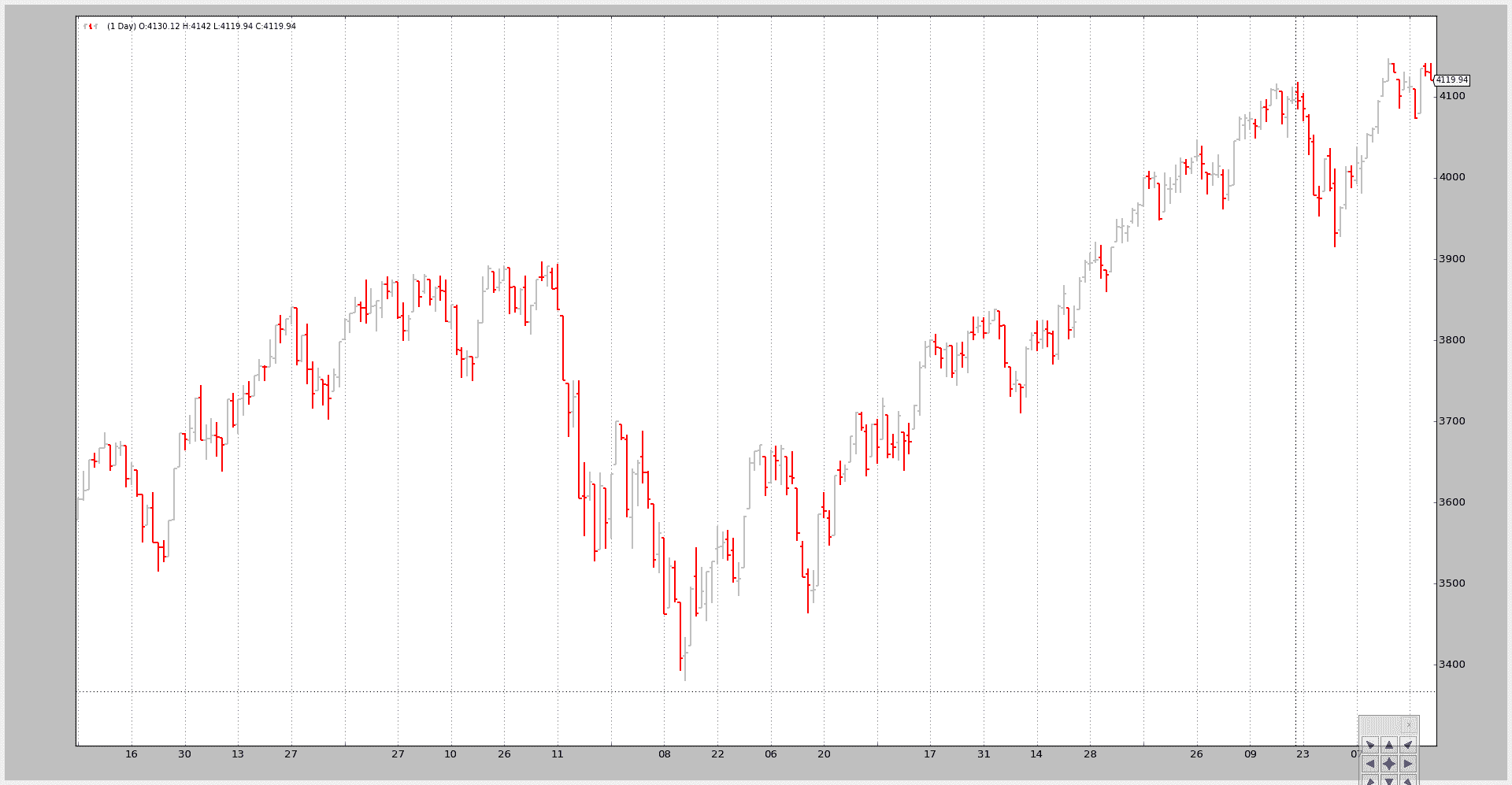
这是通过执行以下步骤来完成的魔术:
-
像往常一样加载数据
-
将数据馈送到具有所需的
DataResampler中-
时间框架
-
压缩
-
示例代码(底部的整个脚本)。
# Load the Data
datapath = args.dataname or '../datas/sample/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(
dataname=datapath)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Resample the data
data_resampled = bt.DataResampler(
dataname=data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# Add the resample data instead of the original
cerebro.adddata(data_resampled)
最后一个例子中,我们首先将时间框架从每日更改为每周,然后应用 3 到 1 的压缩:
$ ./data-resampling.py --timeframe weekly --compression 3
输出结果:
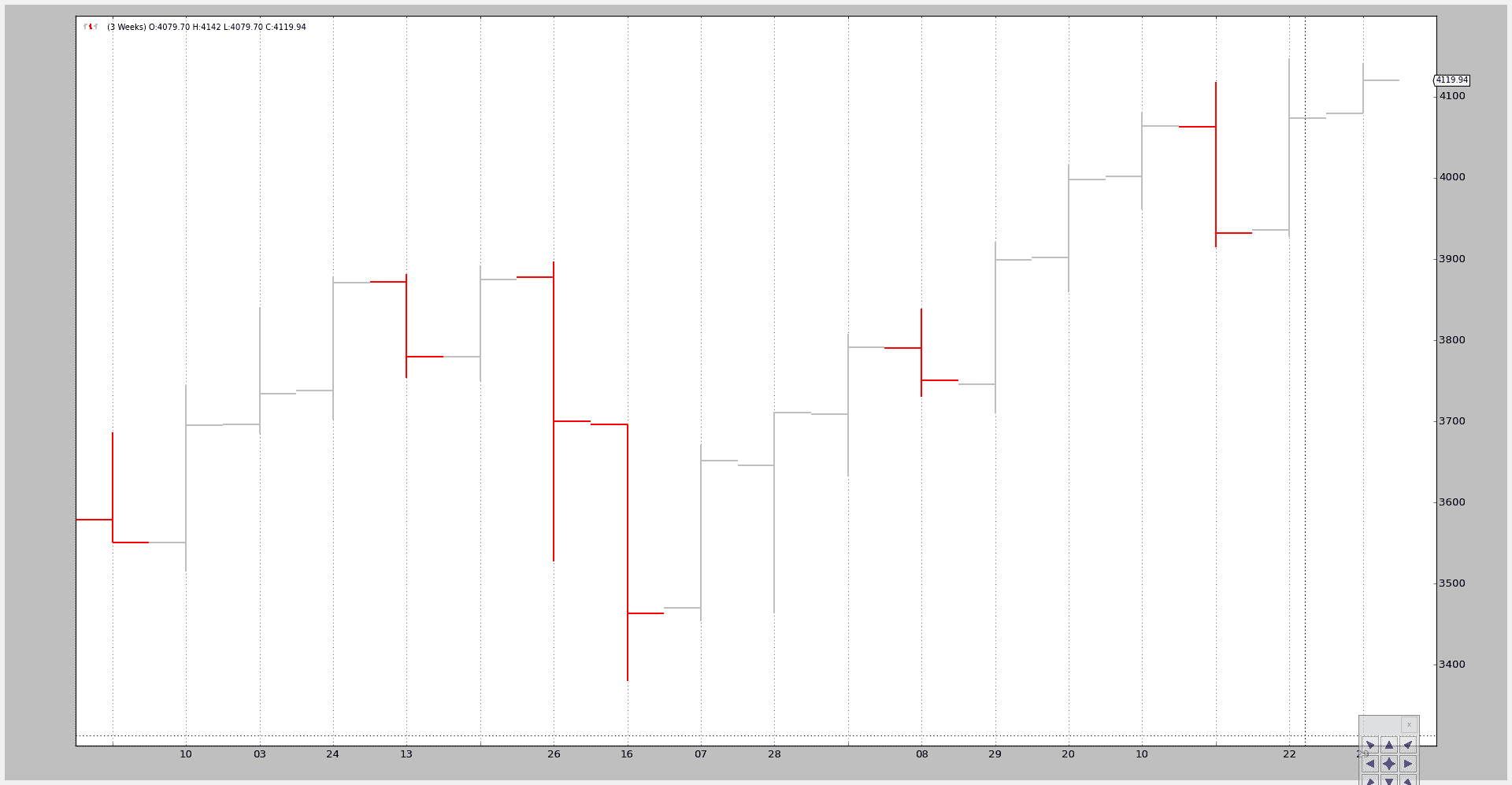
从原始的 256 个每日条柱变为 18 个 3 周条柱。具体情况如下:
-
52 周
-
52 / 3 = 17.33 因此为 18 条柱
这不需要太多。当然,分钟数据也可以进行重新取样。
重新取样测试脚本的示例代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
# Load the Data
datapath = args.dataname or '../datas/sample/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(
dataname=datapath)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Resample the data
data_resampled = bt.DataResampler(
dataname=data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# Add the resample data instead of the original
cerebro.adddata(data_resampled)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--timeframe', default='weekly', required=False,
choices=['daily', 'weekly', 'monhtly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help='Compress n bars into 1')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
Pandas DataFeed 支持
原文:
www.backtrader.com/blog/posts/2015-08-21-pandas-datafeed/pandas-datafeed/
在一些小的增强和一些有序字典调整以更好地支持 Python 2.6 的情况下,backtrader 的最新版本增加了对从 Pandas Dataframe 或时间序列分析数据的支持。
注意
显然必须安装 pandas 及其依赖项。
这似乎引起了很多人的关注,他们依赖于已经可用的用于不同数据源(包括 CSV)的解析代码。
class PandasData(feed.DataBase):
'''
The ``dataname`` parameter inherited from ``feed.DataBase`` is the pandas
Time Series
'''
params = (
# Possible values for datetime (must always be present)
# None : datetime is the "index" in the Pandas Dataframe
# -1 : autodetect position or case-wise equal name
# >= 0 : numeric index to the colum in the pandas dataframe
# string : column name (as index) in the pandas dataframe
('datetime', None),
# Possible values below:
# None : column not present
# -1 : autodetect position or case-wise equal name
# >= 0 : numeric index to the colum in the pandas dataframe
# string : column name (as index) in the pandas dataframe
('open', -1),
('high', -1),
('low', -1),
('close', -1),
('volume', -1),
('openinterest', -1),
)
上述从 PandasData 类中摘录的片段显示了键:
-
实例化期间
dataname参数对应 Pandas Dataframe此参数继承自基类
feed.DataBase -
新参数使用了
DataSeries中常规字段的名称,并遵循这些约定-
datetime(默认:无) -
无:datetime 是 Pandas Dataframe 中的“index”
-
-1:自动检测位置或大小写相等的名称
-
= 0:Pandas 数据框中列的数值索引
-
string:Pandas 数据框中的列名(作为索引)
-
open,high,low,high,close,volume,openinterest(默认:全部为 -1) -
无:列不存在
-
-1:自动检测位置或大小写相等的名称
-
= 0:Pandas 数据框中列的数值索引
-
string:Pandas 数据框中的列名(作为索引)
-
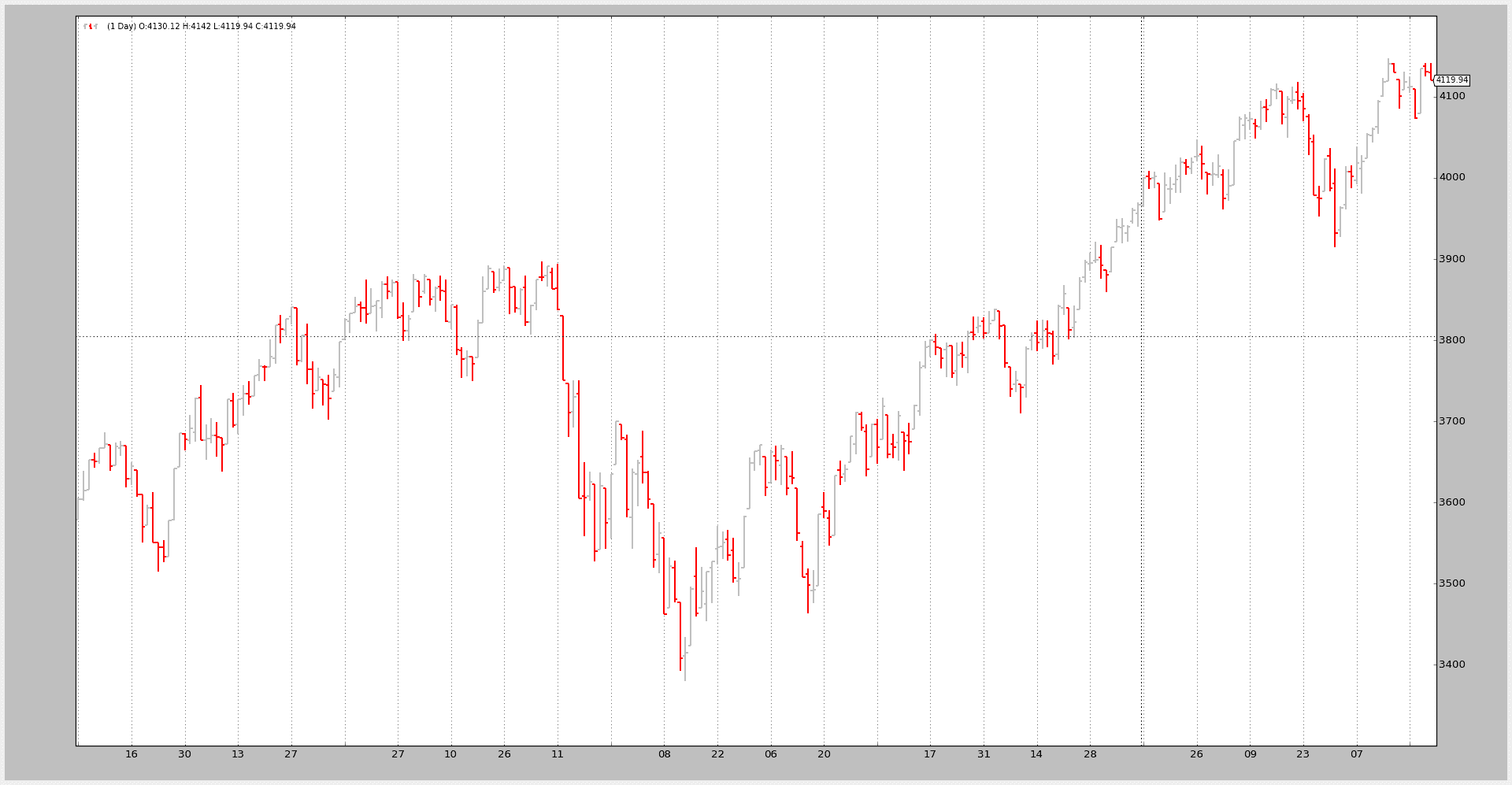
一个小的样本应该能够加载标准 2006 样本,已被 Pandas 解析,而不是直接由 backtrader 解析。
运行示例以使用 CSV 数据中的现有“headers”:
$ ./panda-test.py
--------------------------------------------------
Open High Low Close Volume OpenInterest
Date
2006-01-02 3578.73 3605.95 3578.73 3604.33 0 0
2006-01-03 3604.08 3638.42 3601.84 3614.34 0 0
2006-01-04 3615.23 3652.46 3615.23 3652.46 0 0
相同,但告诉脚本跳过标题:
$ ./panda-test.py --noheaders
--------------------------------------------------
1 2 3 4 5 6
0
2006-01-02 3578.73 3605.95 3578.73 3604.33 0 0
2006-01-03 3604.08 3638.42 3601.84 3614.34 0 0
2006-01-04 3615.23 3652.46 3615.23 3652.46 0 0
第二次运行是使用 tells pandas.read_csv:
-
跳过第一个输入行(
skiprows关键字参数设置为 1) -
不要寻找标题行(
header关键字参数设置为 None)
backtrader 对 Pandas 的支持尝试自动检测是否已使用列名,否则使用数值索引,并相应地采取行动,尝试提供最佳匹配。
以下图表是成功的致敬。Pandas Dataframe 已被正确加载(在两种情况下)。
测试的示例代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import pandas
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
# Get a pandas dataframe
datapath = ('../datas/sample/2006-day-001.txt')
# Simulate the header row isn't there if noheaders requested
skiprows = 1 if args.noheaders else 0
header = None if args.noheaders else 0
dataframe = pandas.read_csv(datapath,
skiprows=skiprows,
header=header,
parse_dates=True,
index_col=0)
if not args.noprint:
print('--------------------------------------------------')
print(dataframe)
print('--------------------------------------------------')
# Pass it to the backtrader datafeed and add it to the cerebro
data = bt.feeds.PandasData(dataname=dataframe)
cerebro.adddata(data)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--noheaders', action='store_true', default=False,
required=False,
help='Do not use header rows')
parser.add_argument('--noprint', action='store_true', default=False,
help='Print the dataframe')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
自动化 backtrader 回测。
原文:
www.backtrader.com/blog/posts/2015-08-16-backtesting-with-almost-no-programming/backtesting-with-almost-no-programming/
到目前为止,所有 backtrader 的示例和工作样本都是从头开始创建一个主要的 Python 模块,加载数据、策略、观察者,并准备现金和佣金方案。
算法交易的一个目标是交易的自动化,鉴于 bactrader 是一个用于检查交易算法的回测平台(因此是一个算法交易平台),自动化使用 backtrader 是一个显而易见的目标。
注意
2015 年 8 月 22 日
bt-run.py 中包含了对 Analyzer 的支持。
backtrader 的开发版本现在包含了 bt-run.py 脚本,它自动化了大多数任务,并将作为常规软件包的一部分与 backtrader 一起安装。
bt-run.py 允许最终用户:
-
指明必须加载的数据。
-
设置加载数据的格式。
-
指定数据的日期范围
-
禁用标准观察者。
-
从内置的或 Python 模块中加载一个或多个观察者(例如:回撤)
-
为经纪人设置现金和佣金方案参数(佣金、保证金、倍数)
-
启用绘图,控制图表数量和数据呈现风格。
最后:
-
加载策略(内置的或来自 Python 模块)
-
向加载的策略传递参数。
请参阅下面关于脚本的用法*。
应用用户定义的策略。
让我们考虑以下策略:
-
简单地加载一个 SimpleMovingAverage(默认周期 15)
-
打印输出。
-
文件名为 mymod.py。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import backtrader as bt
import backtrader.indicators as btind
class MyTest(bt.Strategy):
params = (('period', 15),)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.data.datetime[0]
if isinstance(dt, float):
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
sma = btind.SMA(period=self.p.period)
def next(self):
ltxt = '%d, %.2f, %.2f, %.2f, %.2f, %.2f, %.2f'
self.log(ltxt %
(len(self),
self.data.open[0], self.data.high[0],
self.data.low[0], self.data.close[0],
self.data.volume[0], self.data.openinterest[0]))
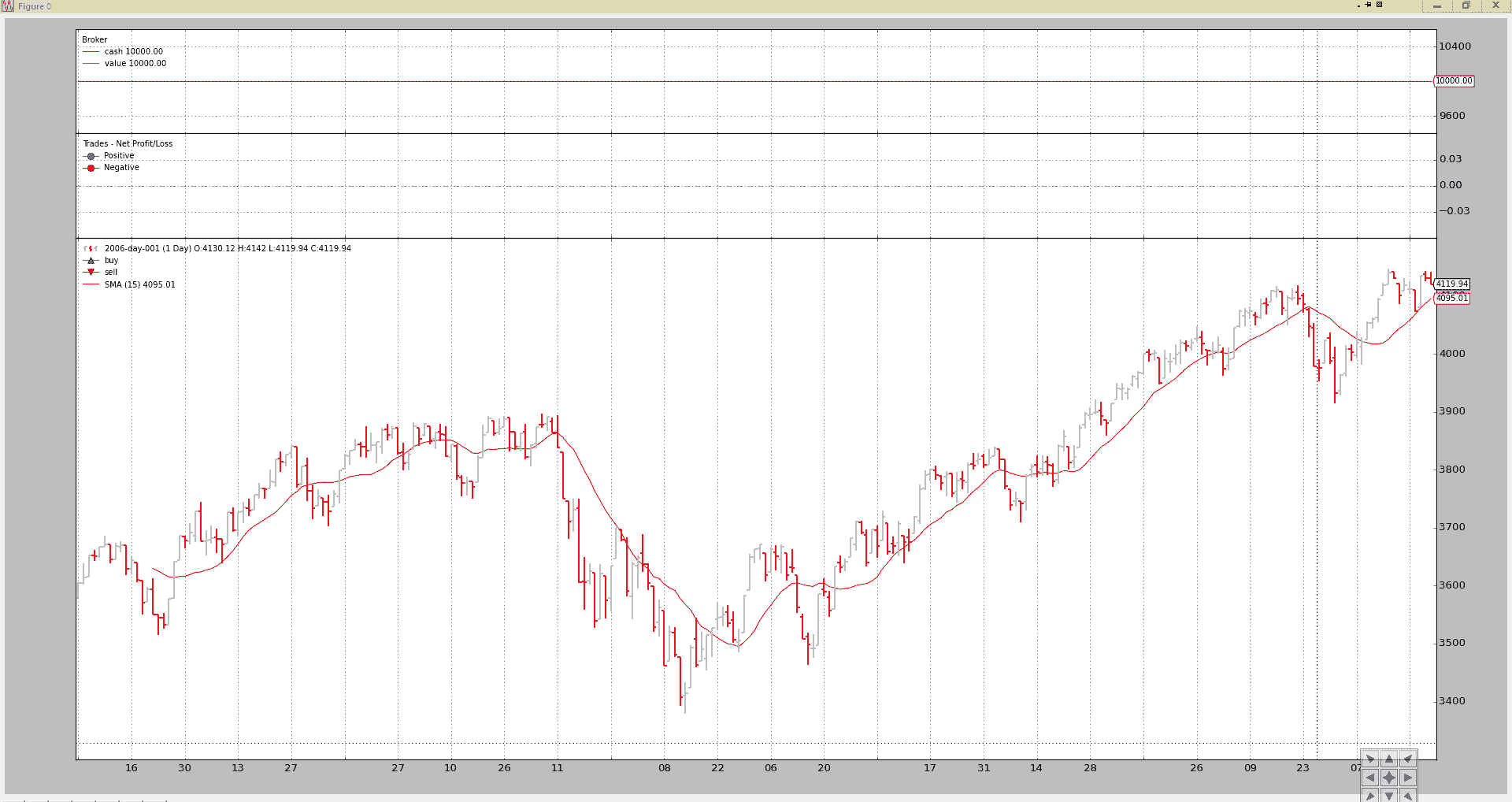
用通常的测试样本执行策略很容易:简单:
./bt-run.py --csvformat btcsv \
--data ../samples/data/sample/2006-day-001.txt \
--strategy ./mymod.py
图表输出。
控制台输出:
2006-01-20T23:59:59+00:00, 15, 3593.16, 3612.37, 3550.80, 3550.80, 0.00, 0.00
2006-01-23T23:59:59+00:00, 16, 3550.24, 3550.24, 3515.07, 3544.31, 0.00, 0.00
2006-01-24T23:59:59+00:00, 17, 3544.78, 3553.16, 3526.37, 3532.68, 0.00, 0.00
2006-01-25T23:59:59+00:00, 18, 3532.72, 3578.00, 3532.72, 3578.00, 0.00, 0.00
...
...
2006-12-22T23:59:59+00:00, 252, 4109.86, 4109.86, 4072.62, 4073.50, 0.00, 0.00
2006-12-27T23:59:59+00:00, 253, 4079.70, 4134.86, 4079.70, 4134.86, 0.00, 0.00
2006-12-28T23:59:59+00:00, 254, 4137.44, 4142.06, 4125.14, 4130.66, 0.00, 0.00
2006-12-29T23:59:59+00:00, 255, 4130.12, 4142.01, 4119.94, 4119.94, 0.00, 0.00
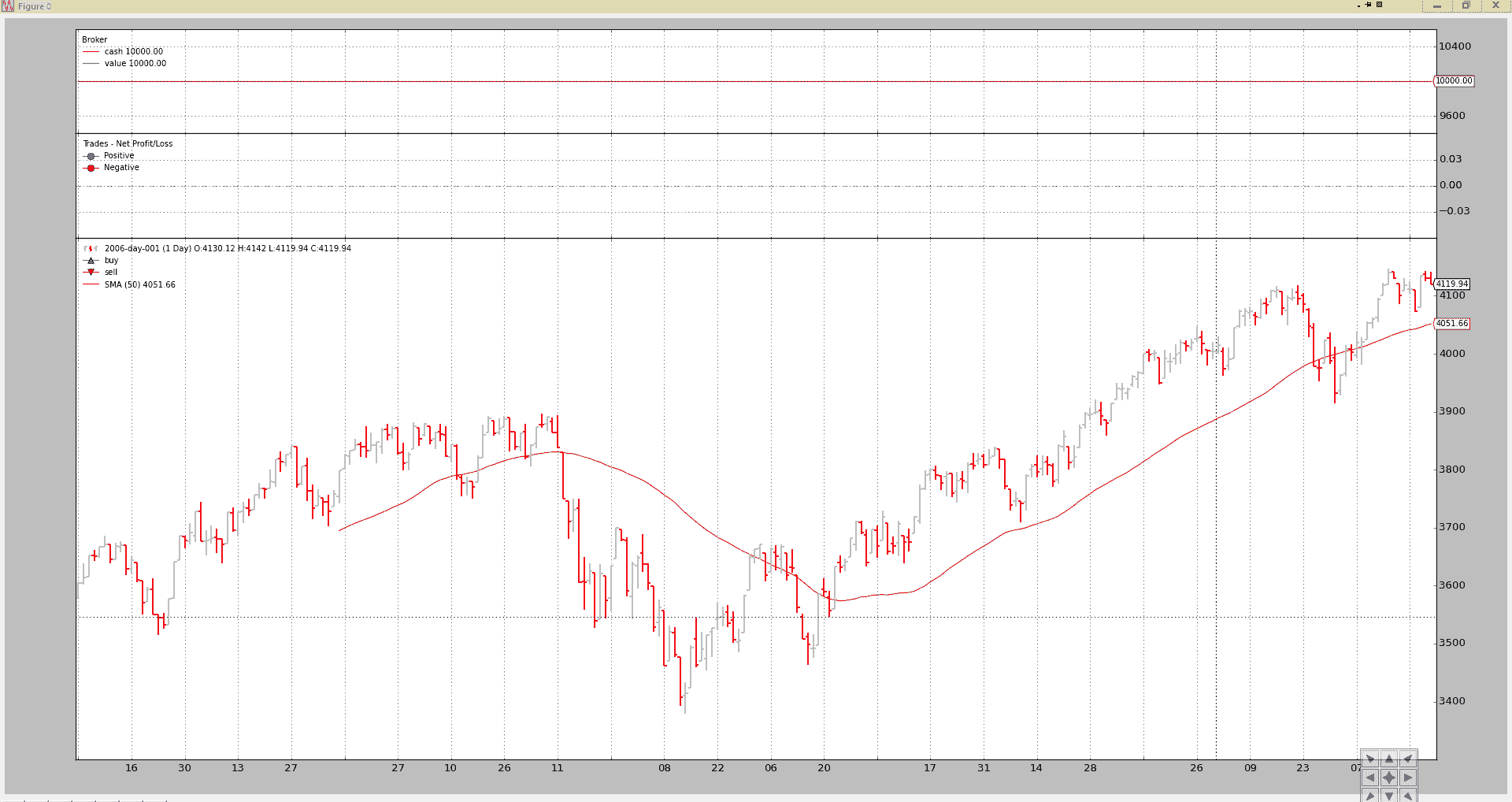
同样的策略但是:
- 将参数
period设置为 50。
命令行:
./bt-run.py --csvformat btcsv \
--data ../samples/data/sample/2006-day-001.txt \
--strategy ./mymod.py \
period 50
图表输出。
使用内置策略。
backtrader 将逐渐包含示例(教科书)策略。随着 bt-run.py 脚本一起,一个标准的简单移动平均线交叉策略已包含在内。名称:
-
SMA_CrossOver -
参数。
-
快速(默认 10)快速移动平均的周期
-
慢(默认 30)慢速移动平均的周期
-
如果快速移动平均线向上穿过快速移动平均线并且在慢速移动平均线向下穿过快速移动平均线后卖出(仅在之前已购买的情况下)。
代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import backtrader as bt
import backtrader.indicators as btind
class SMA_CrossOver(bt.Strategy):
params = (('fast', 10), ('slow', 30))
def __init__(self):
sma_fast = btind.SMA(period=self.p.fast)
sma_slow = btind.SMA(period=self.p.slow)
self.buysig = btind.CrossOver(sma_fast, sma_slow)
def next(self):
if self.position.size:
if self.buysig < 0:
self.sell()
elif self.buysig > 0:
self.buy()
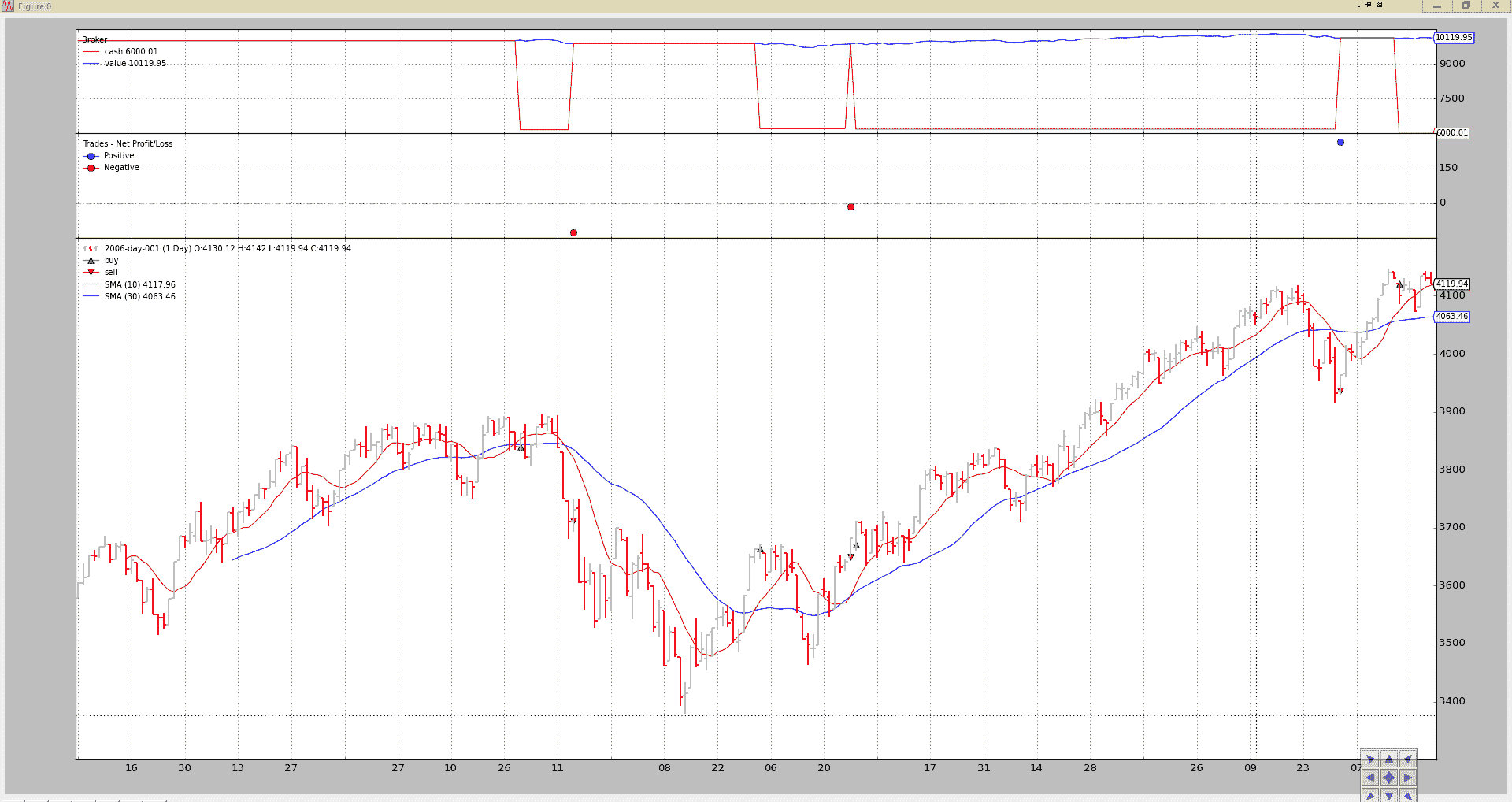
标准执行:
./bt-run.py --csvformat btcsv \
--data ../samples/data/sample/2006-day-001.txt \
--strategy :SMA_CrossOver
注意‘:’。加载策略的标准表示法(见下文)是:
- 模块:策略。
遵循以下规则:
-
如果模块存在且指定了策略,则将使用该策略。
-
如果模块存在但未指定策略,则将返回模块中找到的第一个策略。
-
如果未指定模块,则假定“strategy”是指
backtrader包中的策略
后者是我们的情况。
输出。
最后一个示例添加佣金方案、现金并更改参数:
./bt-run.py --csvformat btcsv \
--data ../samples/data/sample/2006-day-001.txt \
--cash 20000 \
--commission 2.0 \
--mult 10 \
--margin 2000 \
--strategy :SMA_CrossOver \
fast 5 slow 20
输出。
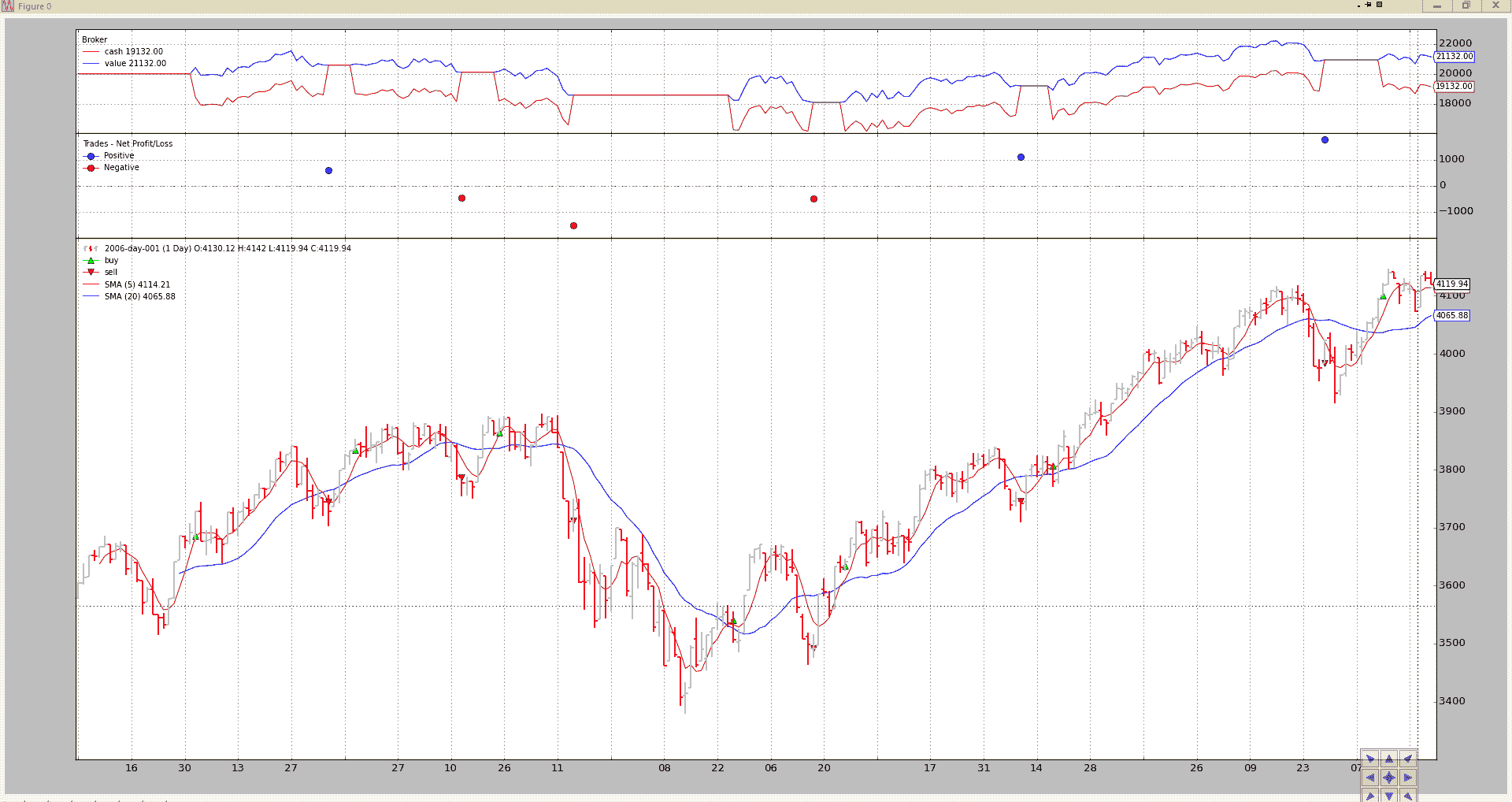
我们已经对策略进行了回测:
-
更改移动平均周期
-
设置新的起始资金
-
为期货类工具设置佣金方案
查看每根柱子中现金的连续变化,因为现金会根据期货类工具的每日变动进行调整。
添加分析器
注意
添加了分析器示例
bt-run.py还支持使用与策略相同的语法添加Analyzers来选择内部/外部分析器。
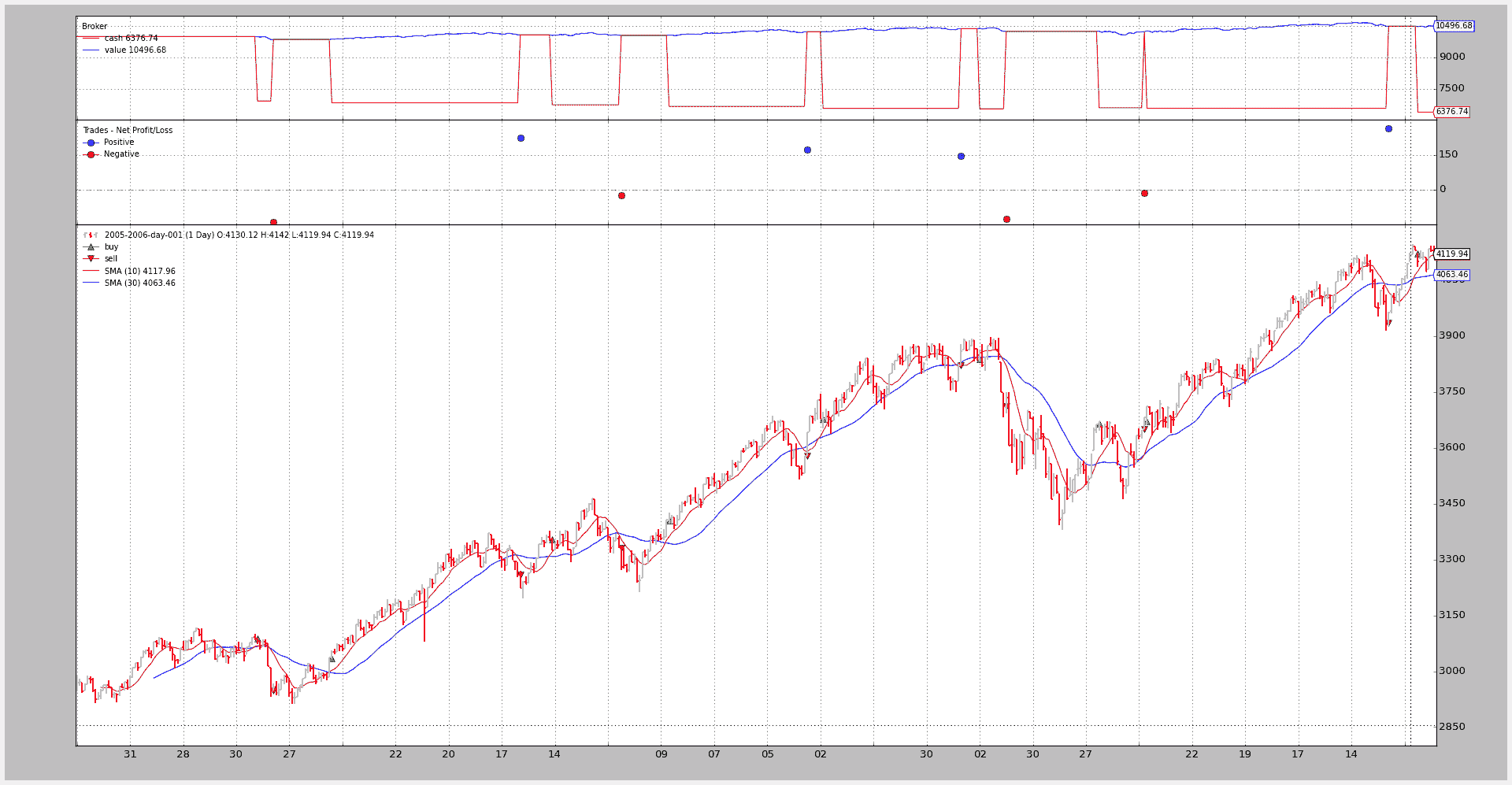
以SharpeRatio分析 2005-2006 年为例:
./bt-run.py --csvformat btcsv \
--data ../samples/data/sample/2005-2006-day-001.txt \
--strategy :SMA_CrossOver \
--analyzer :SharpeRatio
输出:
====================
== Analyzers
====================
## sharperatio
-- sharperatio : 11.6473326097
良好的策略!!!(实际示例中纯粹是运气,而且也没有佣金)
图表(仅显示分析器不在图表中,因为分析器无法绘制,它们不是线对象)
脚本的用法
直接从脚本中:
$ ./bt-run.py --help
usage: bt-run.py [-h] --data DATA
[--csvformat {yahoocsv_unreversed,vchart,sierracsv,yahoocsv,vchartcsv,btcsv}]
[--fromdate FROMDATE] [--todate TODATE] --strategy STRATEGY
[--nostdstats] [--observer OBSERVERS] [--analyzer ANALYZERS]
[--cash CASH] [--commission COMMISSION] [--margin MARGIN]
[--mult MULT] [--noplot] [--plotstyle {bar,line,candle}]
[--plotfigs PLOTFIGS]
...
Backtrader Run Script
positional arguments:
args args to pass to the loaded strategy
optional arguments:
-h, --help show this help message and exit
Data options:
--data DATA, -d DATA Data files to be added to the system
--csvformat {yahoocsv_unreversed,vchart,sierracsv,yahoocsv,vchartcsv,btcsv}, -c {yahoocsv_unreversed,vchart,sierracsv,yahoocsv,vchartcsv,btcsv}
CSV Format
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD[THH:MM:SS] format
--todate TODATE, -t TODATE
Ending date in YYYY-MM-DD[THH:MM:SS] format
Strategy options:
--strategy STRATEGY, -st STRATEGY
Module and strategy to load with format
module_path:strategy_name. module_path:strategy_name
will load strategy_name from the given module_path
module_path will load the module and return the first
available strategy in the module :strategy_name will
load the given strategy from the set of built-in
strategies
Observers and statistics:
--nostdstats Disable the standard statistics observers
--observer OBSERVERS, -ob OBSERVERS
This option can be specified multiple times Module and
observer to load with format
module_path:observer_name. module_path:observer_name
will load observer_name from the given module_path
module_path will load the module and return all
available observers in the module :observer_name will
load the given strategy from the set of built-in
strategies
Analyzers:
--analyzer ANALYZERS, -an ANALYZERS
This option can be specified multiple times Module and
analyzer to load with format
module_path:analzyer_name. module_path:analyzer_name
will load observer_name from the given module_path
module_path will load the module and return all
available analyzers in the module :anaylzer_name will
load the given strategy from the set of built-in
strategies
Cash and Commission Scheme Args:
--cash CASH, -cash CASH
Cash to set to the broker
--commission COMMISSION, -comm COMMISSION
Commission value to set
--margin MARGIN, -marg MARGIN
Margin type to set
--mult MULT, -mul MULT
Multiplier to use
Plotting options:
--noplot, -np Do not plot the read data
--plotstyle {bar,line,candle}, -ps {bar,line,candle}
Plot style for the input data
--plotfigs PLOTFIGS, -pn PLOTFIGS
Plot using n figures
以及代码:
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import inspect
import itertools
import random
import string
import sys
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btinds
import backtrader.observers as btobs
import backtrader.strategies as btstrats
import backtrader.analyzers as btanalyzers
DATAFORMATS = dict(
btcsv=btfeeds.BacktraderCSVData,
vchartcsv=btfeeds.VChartCSVData,
vchart=btfeeds.VChartData,
sierracsv=btfeeds.SierraChartCSVData,
yahoocsv=btfeeds.YahooFinanceCSVData,
yahoocsv_unreversed=btfeeds.YahooFinanceCSVData
)
def runstrat():
args = parse_args()
stdstats = not args.nostdstats
cerebro = bt.Cerebro(stdstats=stdstats)
for data in getdatas(args):
cerebro.adddata(data)
# Prepare a dictionary of extra args passed to push them to the strategy
# pack them in pairs
packedargs = itertools.izip_longest(*[iter(args.args)] * 2, fillvalue='')
# prepare a string for evaluation, eval and store the result
evalargs = 'dict('
for key, value in packedargs:
evalargs += key + '=' + value + ','
evalargs += ')'
stratkwargs = eval(evalargs)
# Get the strategy and add it with any arguments
strat = getstrategy(args)
cerebro.addstrategy(strat, **stratkwargs)
obs = getobservers(args)
for ob in obs:
cerebro.addobserver(ob)
ans = getanalyzers(args)
for an in ans:
cerebro.addanalyzer(an)
setbroker(args, cerebro)
runsts = cerebro.run()
runst = runsts[0] # single strategy and no optimization
if runst.analyzers:
print('====================')
print('== Analyzers')
print('====================')
for name, analyzer in runst.analyzers.getitems():
print('## ', name)
analysis = analyzer.get_analysis()
for key, val in analysis.items():
print('-- ', key, ':', val)
if not args.noplot:
cerebro.plot(numfigs=args.plotfigs, style=args.plotstyle)
def setbroker(args, cerebro):
broker = cerebro.getbroker()
if args.cash is not None:
broker.setcash(args.cash)
commkwargs = dict()
if args.commission is not None:
commkwargs['commission'] = args.commission
if args.margin is not None:
commkwargs['margin'] = args.margin
if args.mult is not None:
commkwargs['mult'] = args.mult
if commkwargs:
broker.setcommission(**commkwargs)
def getdatas(args):
# Get the data feed class from the global dictionary
dfcls = DATAFORMATS[args.csvformat]
# Prepare some args
dfkwargs = dict()
if args.csvformat == 'yahoo_unreversed':
dfkwargs['reverse'] = True
fmtstr = '%Y-%m-%d'
if args.fromdate:
dtsplit = args.fromdate.split('T')
if len(dtsplit) > 1:
fmtstr += 'T%H:%M:%S'
fromdate = datetime.datetime.strptime(args.fromdate, fmtstr)
dfkwargs['fromdate'] = fromdate
fmtstr = '%Y-%m-%d'
if args.todate:
dtsplit = args.todate.split('T')
if len(dtsplit) > 1:
fmtstr += 'T%H:%M:%S'
todate = datetime.datetime.strptime(args.todate, fmtstr)
dfkwargs['todate'] = todate
datas = list()
for dname in args.data:
dfkwargs['dataname'] = dname
data = dfcls(**dfkwargs)
datas.append(data)
return datas
def getmodclasses(mod, clstype, clsname=None):
clsmembers = inspect.getmembers(mod, inspect.isclass)
clslist = list()
for name, cls in clsmembers:
if not issubclass(cls, clstype):
continue
if clsname:
if clsname == name:
clslist.append(cls)
break
else:
clslist.append(cls)
return clslist
def loadmodule(modpath, modname=''):
# generate a random name for the module
if not modname:
chars = string.ascii_uppercase + string.digits
modname = ''.join(random.choice(chars) for _ in range(10))
version = (sys.version_info[0], sys.version_info[1])
if version < (3, 3):
mod, e = loadmodule2(modpath, modname)
else:
mod, e = loadmodule3(modpath, modname)
return mod, e
def loadmodule2(modpath, modname):
import imp
try:
mod = imp.load_source(modname, modpath)
except Exception, e:
return (None, e)
return (mod, None)
def loadmodule3(modpath, modname):
import importlib.machinery
try:
loader = importlib.machinery.SourceFileLoader(modname, modpath)
mod = loader.load_module()
except Exception, e:
return (None, e)
return (mod, None)
def getstrategy(args):
sttokens = args.strategy.split(':')
if len(sttokens) == 1:
modpath = sttokens[0]
stname = None
else:
modpath, stname = sttokens
if modpath:
mod, e = loadmodule(modpath)
if not mod:
print('')
print('Failed to load module %s:' % modpath, e)
sys.exit(1)
else:
mod = btstrats
strats = getmodclasses(mod=mod, clstype=bt.Strategy, clsname=stname)
if not strats:
print('No strategy %s / module %s' % (str(stname), modpath))
sys.exit(1)
return strats[0]
def getanalyzers(args):
analyzers = list()
for anspec in args.analyzers or []:
tokens = anspec.split(':')
if len(tokens) == 1:
modpath = tokens[0]
name = None
else:
modpath, name = tokens
if modpath:
mod, e = loadmodule(modpath)
if not mod:
print('')
print('Failed to load module %s:' % modpath, e)
sys.exit(1)
else:
mod = btanalyzers
loaded = getmodclasses(mod=mod, clstype=bt.Analyzer, clsname=name)
if not loaded:
print('No analyzer %s / module %s' % ((str(name), modpath)))
sys.exit(1)
analyzers.extend(loaded)
return analyzers
def getobservers(args):
observers = list()
for obspec in args.observers or []:
tokens = obspec.split(':')
if len(tokens) == 1:
modpath = tokens[0]
name = None
else:
modpath, name = tokens
if modpath:
mod, e = loadmodule(modpath)
if not mod:
print('')
print('Failed to load module %s:' % modpath, e)
sys.exit(1)
else:
mod = btobs
loaded = getmodclasses(mod=mod, clstype=bt.Observer, clsname=name)
if not loaded:
print('No observer %s / module %s' % ((str(name), modpath)))
sys.exit(1)
observers.extend(loaded)
return observers
def parse_args():
parser = argparse.ArgumentParser(
description='Backtrader Run Script')
group = parser.add_argument_group(title='Data options')
# Data options
group.add_argument('--data', '-d', action='append', required=True,
help='Data files to be added to the system')
datakeys = list(DATAFORMATS.keys())
group.add_argument('--csvformat', '-c', required=False,
default='btcsv', choices=datakeys,
help='CSV Format')
group.add_argument('--fromdate', '-f', required=False, default=None,
help='Starting date in YYYY-MM-DD[THH:MM:SS] format')
group.add_argument('--todate', '-t', required=False, default=None,
help='Ending date in YYYY-MM-DD[THH:MM:SS] format')
# Module where to read the strategy from
group = parser.add_argument_group(title='Strategy options')
group.add_argument('--strategy', '-st', required=True,
help=('Module and strategy to load with format '
'module_path:strategy_name.\n'
'\n'
'module_path:strategy_name will load '
'strategy_name from the given module_path\n'
'\n'
'module_path will load the module and return '
'the first available strategy in the module\n'
'\n'
':strategy_name will load the given strategy '
'from the set of built-in strategies'))
# Observers
group = parser.add_argument_group(title='Observers and statistics')
group.add_argument('--nostdstats', action='store_true',
help='Disable the standard statistics observers')
group.add_argument('--observer', '-ob', dest='observers',
action='append', required=False,
help=('This option can be specified multiple times\n'
'\n'
'Module and observer to load with format '
'module_path:observer_name.\n'
'\n'
'module_path:observer_name will load '
'observer_name from the given module_path\n'
'\n'
'module_path will load the module and return '
'all available observers in the module\n'
'\n'
':observer_name will load the given strategy '
'from the set of built-in strategies'))
# Anaylzers
group = parser.add_argument_group(title='Analyzers')
group.add_argument('--analyzer', '-an', dest='analyzers',
action='append', required=False,
help=('This option can be specified multiple times\n'
'\n'
'Module and analyzer to load with format '
'module_path:analzyer_name.\n'
'\n'
'module_path:analyzer_name will load '
'observer_name from the given module_path\n'
'\n'
'module_path will load the module and return '
'all available analyzers in the module\n'
'\n'
':anaylzer_name will load the given strategy '
'from the set of built-in strategies'))
# Broker/Commissions
group = parser.add_argument_group(title='Cash and Commission Scheme Args')
group.add_argument('--cash', '-cash', required=False, type=float,
help='Cash to set to the broker')
group.add_argument('--commission', '-comm', required=False, type=float,
help='Commission value to set')
group.add_argument('--margin', '-marg', required=False, type=float,
help='Margin type to set')
group.add_argument('--mult', '-mul', required=False, type=float,
help='Multiplier to use')
# Plot options
group = parser.add_argument_group(title='Plotting options')
group.add_argument('--noplot', '-np', action='store_true', required=False,
help='Do not plot the read data')
group.add_argument('--plotstyle', '-ps', required=False, default='bar',
choices=['bar', 'line', 'candle'],
help='Plot style for the input data')
group.add_argument('--plotfigs', '-pn', required=False, default=1,
type=int, help='Plot using n figures')
# Extra arguments
parser.add_argument('args', nargs=argparse.REMAINDER,
help='args to pass to the loaded strategy')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
观察者和统计
原文:
www.backtrader.com/blog/posts/2015-08-12-observers-and-statistics/observers-and-statistics/
运行在 backtrader 内部的策略主要处理数据和指标。
数据被添加到Cerebro实例中,并最终成为策略的输入的一部分(被解析并作为实例的属性提供),而指标是由策略本身声明和管理的。
到目前为止,backtrader 的所有示例图表都有 3 个似乎被视为理所当然的东西,因为它们没有在任何地方声明:
-
现金和价值(经纪人的资金情况)
-
交易(也称为操作)
-
买入/卖出订单
它们是观察者,存在于子模块backtrader.observers中。它们在那里是因为Cerebro支持一个参数,可以自动将它们添加(或不添加)到策略中:
stdstats(默认值:True)
如果默认值被遵守,Cerebro执行以下等效用户代码:
import backtrader as bt
...
cerebro = bt.Cerebro() # default kwarg: stdstats=True
cerebro.addobserver(backtrader.observers.Broker)
cerebro.addobserver(backtrader.observers.Trades)
cerebro.addobserver(backtrader.observers.BuySell)
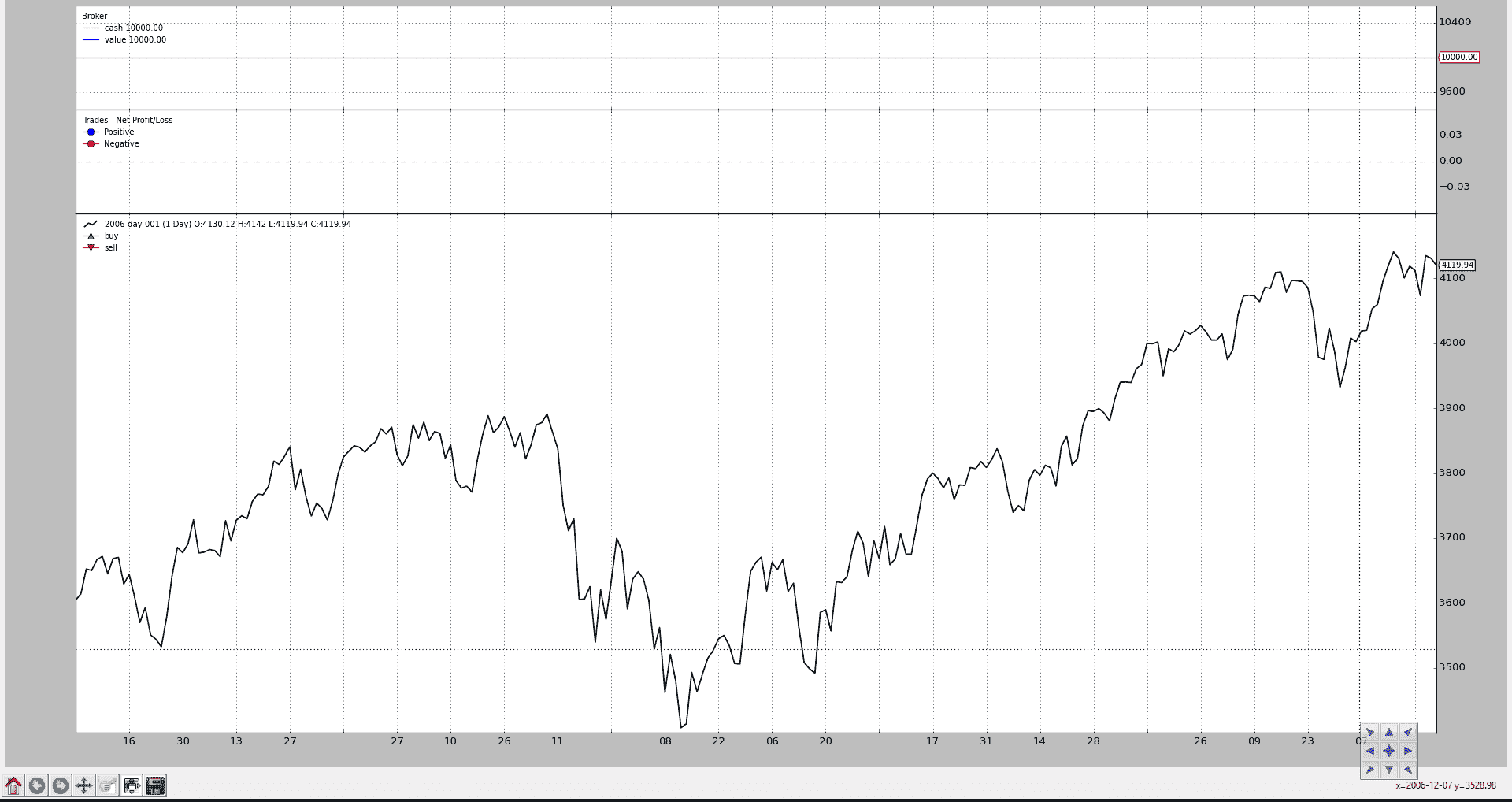
让我们看看具有这 3 个默认观察者的通常图表(即使没有发出订单,因此没有交易发生,也没有现金和投资组合价值的变化)
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import backtrader as bt
import backtrader.feeds as btfeeds
if __name__ == '__main__':
cerebro = bt.Cerebro(stdstats=False)
cerebro.addstrategy(bt.Strategy)
data = bt.feeds.BacktraderCSVData(dataname='../datas/2006-day-001.txt')
cerebro.adddata(data)
cerebro.run()
cerebro.plot()
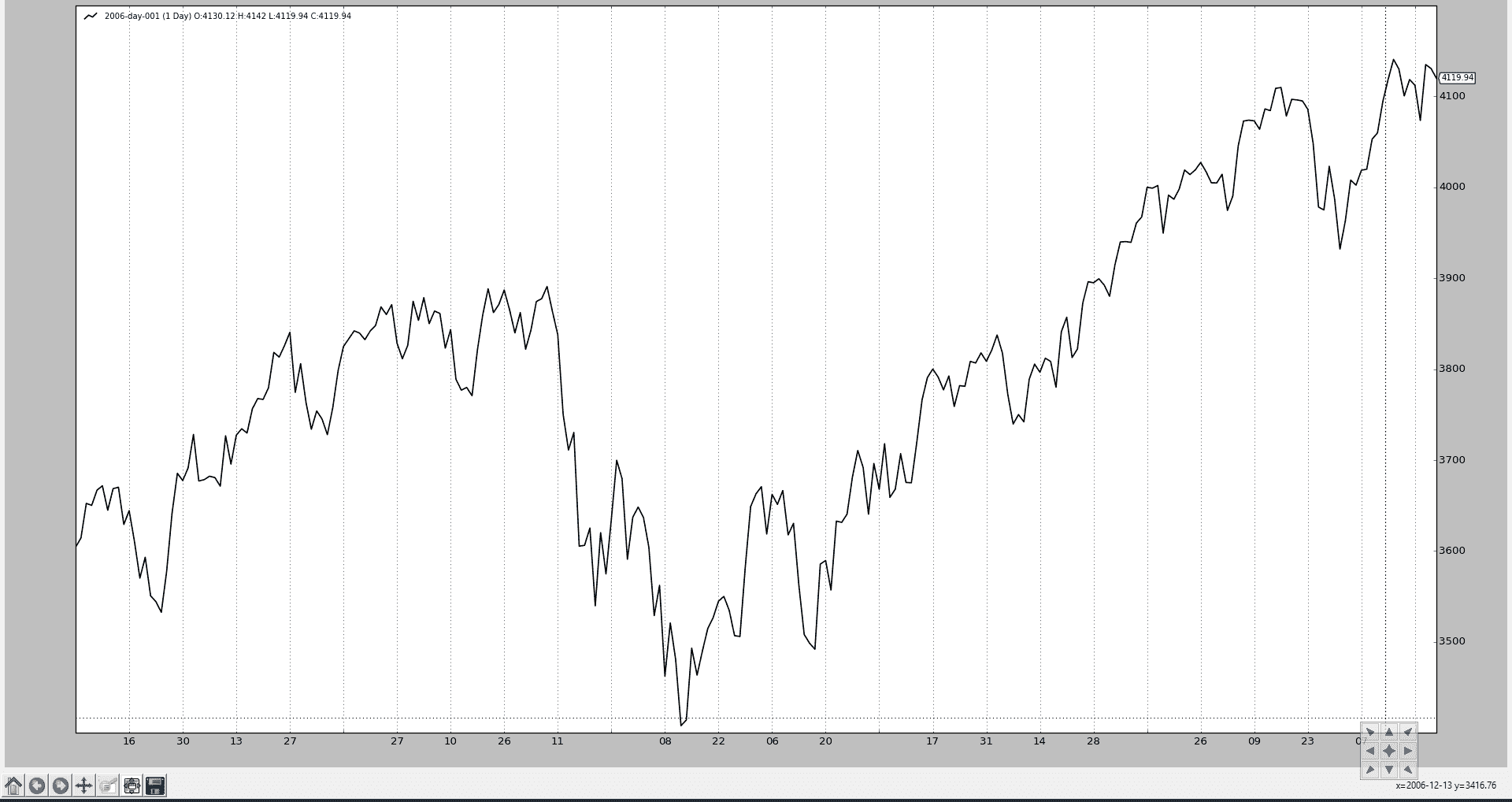
现在让我们在创建Cerebro实例时将stdstats的值更改为False(也可以在调用run时完成):
cerebro = bt.Cerebro(stdstats=False)
现在图表不同了。
访问观察者
如上所述,观察者已经存在于默认情况下,并收集可用于统计目的的信息,这就是为什么可以通过策略的一个属性来访问观察者的原因:
stats
它只是一个占位符。如果我们回想一下如何添加默认观察者之一,就像上面描述的那样:
...
cerebro.addobserver(backtrader.observers.Broker)
...
显而易见的问题是如何访问Broker观察者。以下是一个示例,展示了如何从策略的next方法中完成这个操作:
class MyStrategy(bt.Strategy):
def next(self):
if self.stats.broker.value[0] < 1000.0:
print('WHITE FLAG ... I LOST TOO MUCH')
elif self.stats.broker.value[0] > 10000000.0:
print('TIME FOR THE VIRGIN ISLANDS ....!!!')
Broker观察者就像一个数据、一个指标和策略本身一样,也是一个Lines对象。在这种情况下,Broker有 2 条线:
-
cash -
value
观察者实现
实现非常类似于指标的实现:
class Broker(Observer):
alias = ('CashValue',)
lines = ('cash', 'value')
plotinfo = dict(plot=True, subplot=True)
def next(self):
self.lines.cash[0] = self._owner.broker.getcash()
self.lines.value[0] = value = self._owner.broker.getvalue()
步骤:
-
从
Observer派生(而不是从Indicator派生) -
根据需要声明线和参数(
Broker有 2 条线但没有参数) -
将会有一个自动属性
_owner,它是持有观察者的策略。
观察者开始行动:
-
所有指标计算完成后
-
策略的
next方法执行完成后 -
这意味着:在周期结束时…他们观察发生了什么
在Broker情况下,它只是盲目地记录了每个时间点的经纪人现金和投资组合价值。
将观察者添加到策略中
如上所指出,Cerebro 使用stdstats参数来决定是否添加 3 个默认的观察者,减轻了最终用户的工作量。
将其他观察者添加到混合中是可能的,无论是沿着stdstats还是移除那些。
让我们继续使用通常的策略,当close价格高于SimpleMovingAverage时购买,反之亦然时卖出。
有一个“添加”:
- DrawDown,这是
backtrader生态系统中已经存在的观察者
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import os.path
import time
import sys
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class MyStrategy(bt.Strategy):
params = (('smaperiod', 15),)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.data.datetime[0]
if isinstance(dt, float):
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
视觉输出显示了回撤的演变
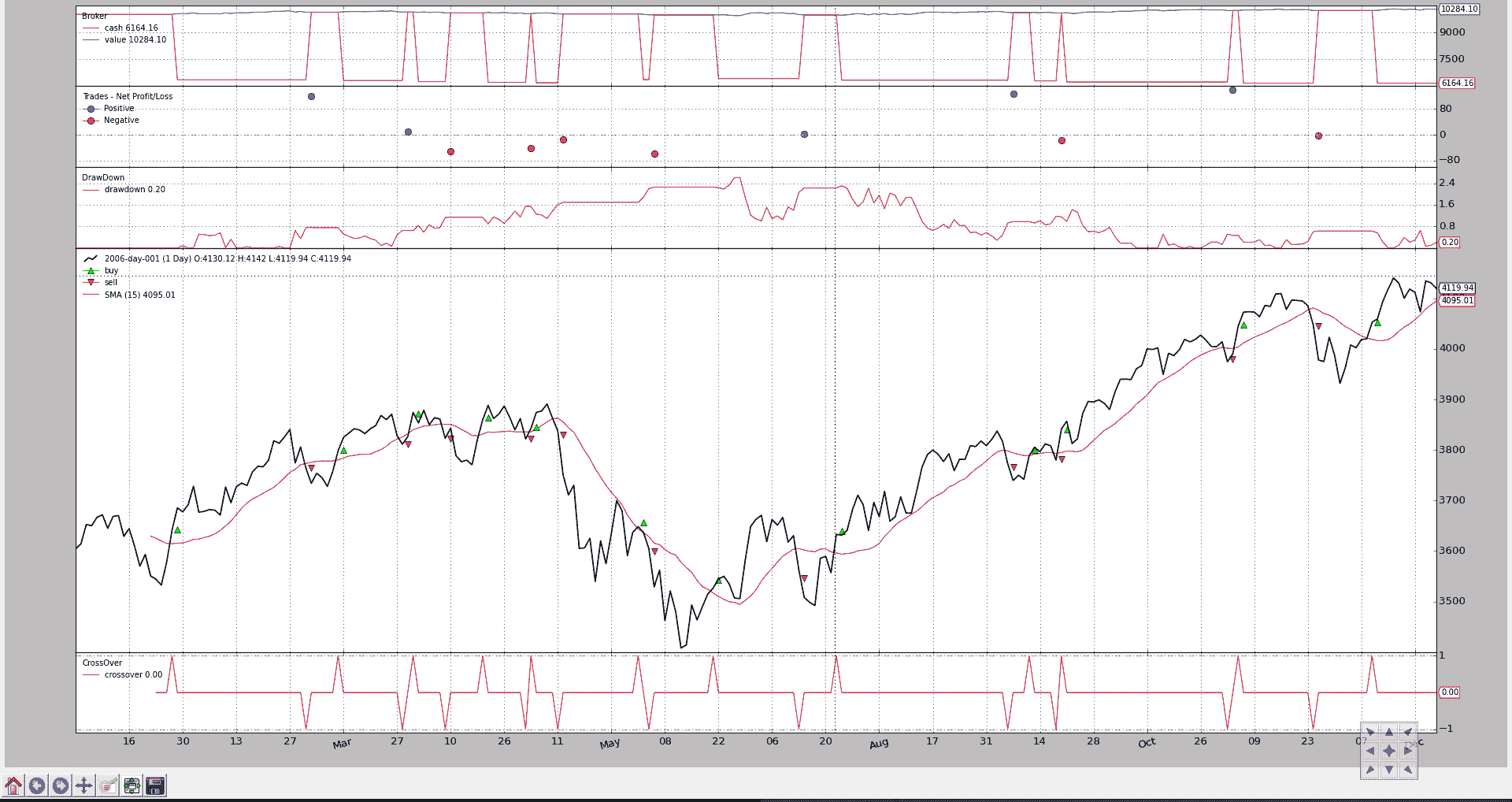
以及部分文本输出:
...
2006-12-14T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-15T23:59:59+00:00, DrawDown: 0.22
2006-12-15T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-18T23:59:59+00:00, DrawDown: 0.00
2006-12-18T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-19T23:59:59+00:00, DrawDown: 0.00
2006-12-19T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-20T23:59:59+00:00, DrawDown: 0.10
2006-12-20T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-21T23:59:59+00:00, DrawDown: 0.39
2006-12-21T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-22T23:59:59+00:00, DrawDown: 0.21
2006-12-22T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-27T23:59:59+00:00, DrawDown: 0.28
2006-12-27T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-28T23:59:59+00:00, DrawDown: 0.65
2006-12-28T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-29T23:59:59+00:00, DrawDown: 0.06
2006-12-29T23:59:59+00:00, MaxDrawDown: 2.62
注意
如文本输出和代码中所见,DrawDown观察者实际上有 2 行:
-
drawdown -
maxdrawdown
选择不绘制maxdrawdown线,但仍然使其对用户可用。
实际上,maxdrawdown的最后一个值也可以通过名为maxdd的直接属性(而不是一行)获得
开发观察者
上面展示了Broker观察者的实现。为了生成有意义的观察者,实现可以使用以下信息:
-
self._owner是当前执行的策略因此,观察者可以访问策略中的任何内容
-
策略中可用的默认内部内容可能会有用:
broker-> 属性,提供对策略创建订单的经纪人实例的访问
如在
Broker中所见,通过调用getcash和getvalue方法收集现金和投资组合价值_orderspending-> 列出由策略创建并经纪人已通知策略的事件的订单。
BuySell观察者遍历列表,寻找已执行(完全或部分)的订单,以创建给定时间点(索引 0)的平均执行价格_tradespending-> 交易列表(一组已完成的买入/卖出或卖出/买入对),从买入/卖出订单编译而成
Observer显然可以通过self._owner.stats路径访问其他观察者。
自定义OrderObserver
标准的BuySell观察者只关心已执行的操作。我们可以创建一个观察者,显示订单何时创建以及是否已过期。
为了可见性,显示将不沿价格绘制,而是在单独的轴上。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import math
import backtrader as bt
class OrderObserver(bt.observer.Observer):
lines = ('created', 'expired',)
plotinfo = dict(plot=True, subplot=True, plotlinelabels=True)
plotlines = dict(
created=dict(marker='*', markersize=8.0, color='lime', fillstyle='full'),
expired=dict(marker='s', markersize=8.0, color='red', fillstyle='full')
)
def next(self):
for order in self._owner._orderspending:
if order.data is not self.data:
continue
if not order.isbuy():
continue
# Only interested in "buy" orders, because the sell orders
# in the strategy are Market orders and will be immediately
# executed
if order.status in [bt.Order.Accepted, bt.Order.Submitted]:
self.lines.created[0] = order.created.price
elif order.status in [bt.Order.Expired]:
self.lines.expired[0] = order.created.price
自定义观察者只关心买入订单,因为这是一个只购买以试图获利的策略。卖出订单是市价订单,将立即执行。
Close-SMA CrossOver 策略已更改为:
-
创建一个限价订单,价格低于信号时的收盘价的 1.0%
-
订单有效期为 7(日历)天
结果图表。
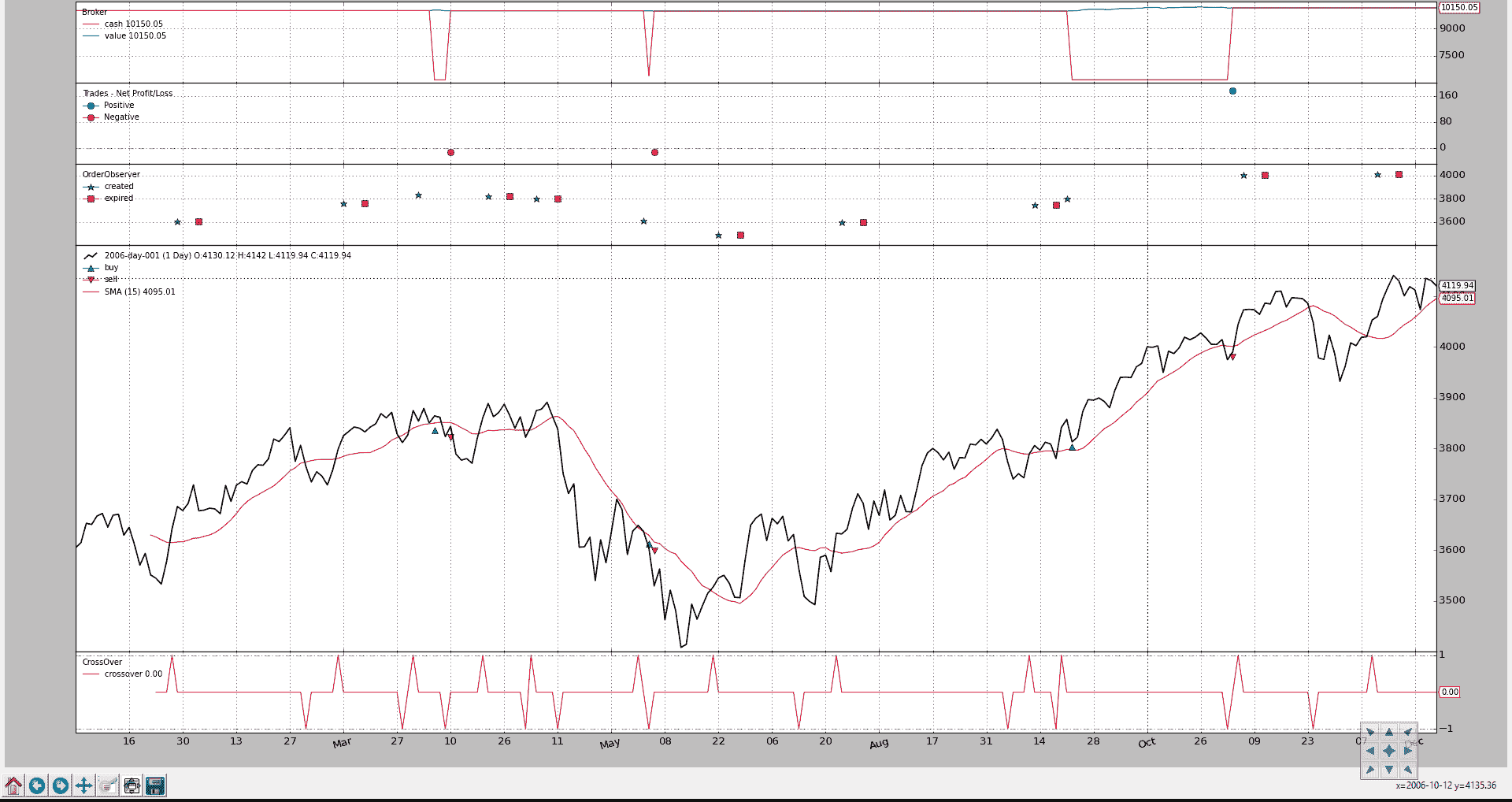
如新子图中所见,有几个订单已过期(红色方块),我们还可以看到在“创建”和“执行”之间有几天的时间。
注意
从提交 1560fa8802 开始,在 development 分支中,如果在订单创建时价格未设置,则会使用收盘价格作为参考价格。
这不会影响市场订单,但始终保持 order.create.price 可用,并简化了 buy 的使用。
最后,应用新的观察者的策略代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
from orderobserver import OrderObserver
class MyStrategy(bt.Strategy):
params = (
('smaperiod', 15),
('limitperc', 1.0),
('valid', 7),
)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.data.datetime[0]
if isinstance(dt, float):
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
# Buy/Sell order submitted/accepted to/by broker - Nothing to do
self.log('ORDER ACCEPTED/SUBMITTED', dt=order.created.dt)
self.order = order
return
if order.status in [order.Expired]:
self.log('BUY EXPIRED')
elif order.status in [order.Completed]:
if order.isbuy():
self.log(
'BUY EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
else: # Sell
self.log('SELL EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
# Sentinel to None: new orders allowed
self.order = None
def __init__(self):
# SimpleMovingAverage on main data
# Equivalent to -> sma = btind.SMA(self.data, period=self.p.smaperiod)
sma = btind.SMA(period=self.p.smaperiod)
# CrossOver (1: up, -1: down) close / sma
self.buysell = btind.CrossOver(self.data.close, sma, plot=True)
# Sentinel to None: new ordersa allowed
self.order = None
def next(self):
if self.order:
# pending order ... do nothing
return
# Check if we are in the market
if self.position:
if self.buysell < 0:
self.log('SELL CREATE, %.2f' % self.data.close[0])
self.sell()
elif self.buysell > 0:
plimit = self.data.close[0] * (1.0 - self.p.limitperc / 100.0)
valid = self.data.datetime.date(0) + \
datetime.timedelta(days=self.p.valid)
self.log('BUY CREATE, %.2f' % plimit)
self.buy(exectype=bt.Order.Limit, price=plimit, valid=valid)
def runstrat():
cerebro = bt.Cerebro()
data = bt.feeds.BacktraderCSVData(dataname='../datas/2006-day-001.txt')
cerebro.adddata(data)
cerebro.addobserver(OrderObserver)
cerebro.addstrategy(MyStrategy)
cerebro.run()
cerebro.plot()
if __name__ == '__main__':
runstrat()
保存/保持统计信息。
目前为止,backtrader 还没有实现任何跟踪观察者值并将它们存储到文件中的机制。最好的方法是:
-
在策略的
start方法中打开一个文件。 -
在策略的
next方法中写入值。
考虑到 DrawDown 观察者,可以这样做:
class MyStrategy(bt.Strategy):
def start(self):
self.mystats = open('mystats.csv', 'wb')
self.mystats.write('datetime,drawdown, maxdrawdown\n')
def next(self):
self.mystats.write(self.data.datetime.date(0).strftime('%Y-%m-%d'))
self.mystats.write(',%.2f' % self.stats.drawdown.drawdown[-1])
self.mystats.write(',%.2f' % self.stats.drawdown.maxdrawdown-1])
self.mystats.write('\n')
要保存索引 0 的值,在所有观察者都被处理后,可以将一个自定义观察者添加到系统中作为最后一个观察者,将值保存到一个 csv 文件中。
数据源开发
原文:
www.backtrader.com/blog/posts/2015-08-11-datafeed-development/datafeed-development/
添加一个基于 CSV 的新数据源很容易。现有的基类 CSVDataBase 提供了框架,大部分工作都由子类完成,这在大多数情况下可以简单地完成:
def _loadline(self, linetokens):
# parse the linetokens here and put them in self.lines.close,
# self.lines.high, etc
return True # if data was parsed, else ... return False
这在 CSV 数据源开发中已经展示过了。
基类负责参数、初始化、文件打开、读取行、将行拆分为标记以及跳过不符合用户定义的日期范围(fromdate、todate)的行等其他事项。
开发非 CSV 数据源遵循相同的模式,而不需要深入到已拆分的行标记。
要做的事情:
-
源自 backtrader.feed.DataBase
-
添加任何可能需要的参数
-
如果需要初始化,请重写
__init__(self)和/或start(self) -
如果需要任何清理代码,请重写
stop(self) -
工作发生在必须始终被重写的方法内:
_load(self)
让我们使用backtrader.feed.DataBase已经提供的参数:
class DataBase(six.with_metaclass(MetaDataBase, dataseries.OHLCDateTime)):
params = (('dataname', None),
('fromdate', datetime.datetime.min),
('todate', datetime.datetime.max),
('name', ''),
('compression', 1),
('timeframe', TimeFrame.Days),
('sessionend', None))
具有���下含义:
-
dataname是允许数据源识别如何获取数据的内容。在CSVDataBase的情况下,此参数应该是文件的路径或已经是类似文件的对象。 -
fromdate和todate定义了将传递给策略的日期范围。数据源提供的任何超出此范围的值将被忽略 -
name是用于绘图目的的装饰性内容 -
timeframe和compression是装饰性和信息性的。它们在数据重采样和数据重播中真正发挥作用。 -
如果传递了
sessionend(一个 datetime.time 对象),它将被添加到数据源的datetime行中,从而可以识别会话结束的时间
示例二进制数据源
backtrader已经为VisualChart的导出定义了一个 CSV 数据源(VChartCSVData),但也可以直接读取二进制数据文件。
让我们开始吧(完整的数据源代码可以在底部找到)
初始化
二进制 VisualChart 数据文件可以包含每日数据(.fd 扩展名)或分钟数据(.min 扩展名)。这里,信息性参数timeframe将用于区分正在读取的文件类型。
在__init__期间,为每种类型设置不同的常量。
def __init__(self):
super(VChartData, self).__init__()
# Use the informative "timeframe" parameter to understand if the
# code passed as "dataname" refers to an intraday or daily feed
if self.p.timeframe >= TimeFrame.Days:
self.barsize = 28
self.dtsize = 1
self.barfmt = 'IffffII'
else:
self.dtsize = 2
self.barsize = 32
self.barfmt = 'IIffffII'
开始
当开始回测时,数据源将启动(在优化过程中实际上可以启动多次)
在start方法中,除非传递了类似文件的对象,否则将打开二进制文件。
def start(self):
# the feed must start ... get the file open (or see if it was open)
self.f = None
if hasattr(self.p.dataname, 'read'):
# A file has been passed in (ex: from a GUI)
self.f = self.p.dataname
else:
# Let an exception propagate
self.f = open(self.p.dataname, 'rb')
停止
当回测完成时调用。
如果文件已打开,则将关闭
def stop(self):
# Close the file if any
if self.f is not None:
self.f.close()
self.f = None
实际加载
实际工作是在_load中完成的。调用以加载下一组数据,此处为下一个:日期时间、开盘价、最高价、最低价、收盘价、成交量、持仓量。在backtrader中,“实际”时刻对应于索引 0。
一定数量的字节将从打开的文件中读取(由__init__期间设置的常量确定),使用struct模块解析,如果需要进一步处理(例如使用 divmod 操作处理日期和时间),则存储在数据源的lines中:日期时间、开盘价、最高价、最低价、收盘价、成交量、持仓量。
如果无法从文件中读取任何数据,则假定已达到文件结尾(EOF)。
- 返回
False表示无更多数据可用的事实
否则,如果数据已加载并解析:
- 返回
True表示数据集加载成功
def _load(self):
if self.f is None:
# if no file ... no parsing
return False
# Read the needed amount of binary data
bardata = self.f.read(self.barsize)
if not bardata:
# if no data was read ... game over say "False"
return False
# use struct to unpack the data
bdata = struct.unpack(self.barfmt, bardata)
# Years are stored as if they had 500 days
y, md = divmod(bdata[0], 500)
# Months are stored as if they had 32 days
m, d = divmod(md, 32)
# put y, m, d in a datetime
dt = datetime.datetime(y, m, d)
if self.dtsize > 1: # Minute Bars
# Daily Time is stored in seconds
hhmm, ss = divmod(bdata[1], 60)
hh, mm = divmod(hhmm, 60)
# add the time to the existing atetime
dt = dt.replace(hour=hh, minute=mm, second=ss)
self.lines.datetime[0] = date2num(dt)
# Get the rest of the unpacked data
o, h, l, c, v, oi = bdata[self.dtsize:]
self.lines.open[0] = o
self.lines.high[0] = h
self.lines.low[0] = l
self.lines.close[0] = c
self.lines.volume[0] = v
self.lines.openinterest[0] = oi
# Say success
return True
其他二进制格式
相同的模型可以应用于任何其他二进制源:
-
数据库
-
分层数据存储
-
在线数据源
步骤再次说明:
-
__init__-> 实例的任何初始化代码,仅执行一次 -
start-> 回测的开始(如果将进行优化,则可能发生一次或多次)例如,这将打开与数据库的连接或与在线服务的套接字连接。
-
stop-> 清理工作,如关闭数据库连接或打开套接字 -
_load-> 查询数据库或在线数据源以获取下一组数据,并将其加载到对象的lines中。标准字段包括:日期时间、开盘价、最高价、最低价、收盘价、成交量、持仓量
VChartData 测试
VCharData 从本地“.fd”文件加载谷歌 2006 年的数据。
这只涉及加载数据,因此甚至不需要Strategy的子类。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import backtrader as bt
from vchart import VChartData
if __name__ == '__main__':
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
# Create a Data Feed
datapath = '../datas/goog.fd'
data = VChartData(
dataname=datapath,
fromdate=datetime.datetime(2006, 1, 1),
todate=datetime.datetime(2006, 12, 31),
timeframe=bt.TimeFrame.Days
)
# Add the Data Feed to Cerebro
cerebro.adddata(data)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
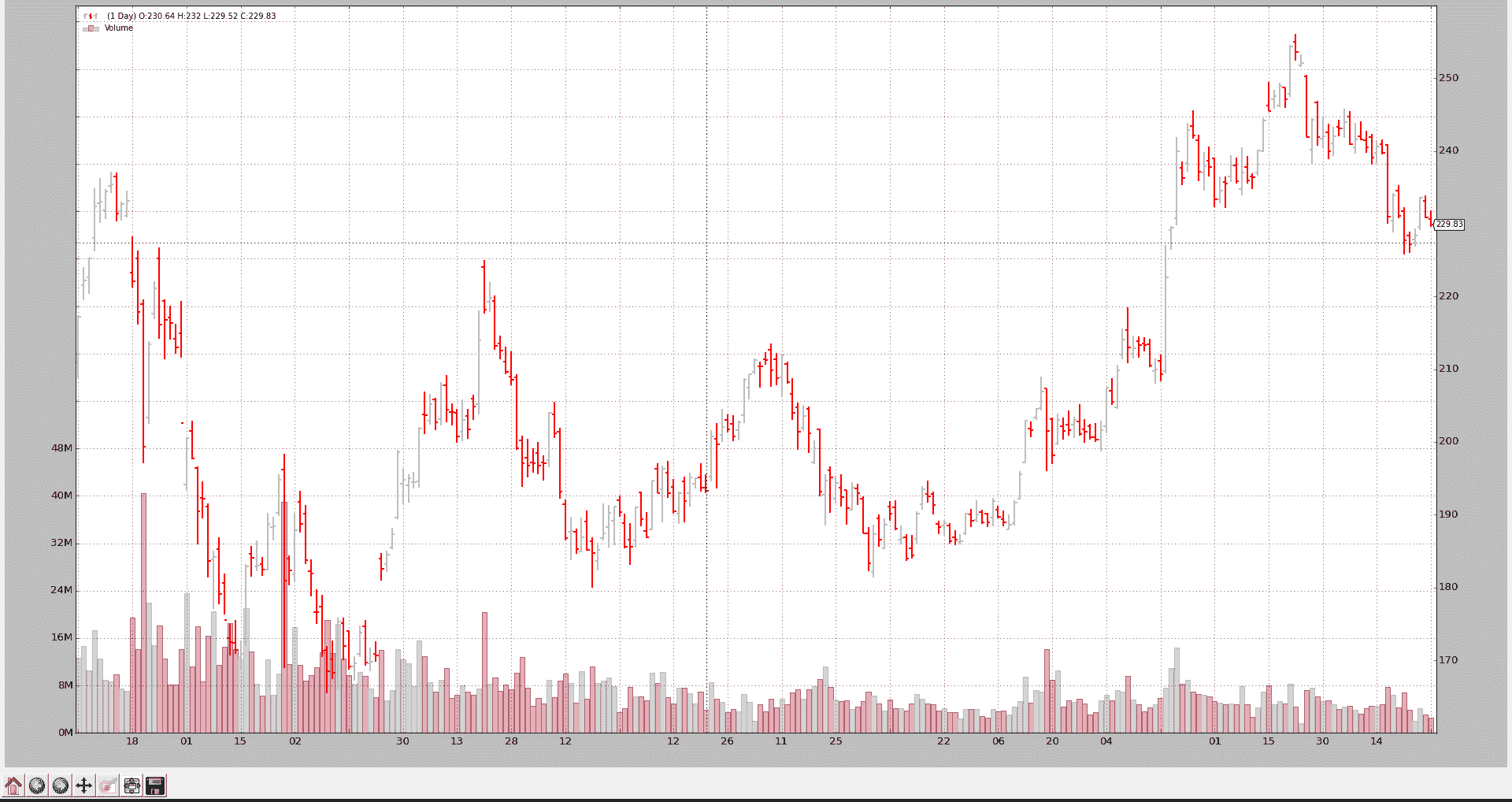
VChartData 完整代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import struct
from backtrader.feed import DataBase
from backtrader import date2num
from backtrader import TimeFrame
class VChartData(DataBase):
def __init__(self):
super(VChartData, self).__init__()
# Use the informative "timeframe" parameter to understand if the
# code passed as "dataname" refers to an intraday or daily feed
if self.p.timeframe >= TimeFrame.Days:
self.barsize = 28
self.dtsize = 1
self.barfmt = 'IffffII'
else:
self.dtsize = 2
self.barsize = 32
self.barfmt = 'IIffffII'
def start(self):
# the feed must start ... get the file open (or see if it was open)
self.f = None
if hasattr(self.p.dataname, 'read'):
# A file has been passed in (ex: from a GUI)
self.f = self.p.dataname
else:
# Let an exception propagate
self.f = open(self.p.dataname, 'rb')
def stop(self):
# Close the file if any
if self.f is not None:
self.f.close()
self.f = None
def _load(self):
if self.f is None:
# if no file ... no parsing
return False
# Read the needed amount of binary data
bardata = self.f.read(self.barsize)
if not bardata:
# if no data was read ... game over say "False"
return False
# use struct to unpack the data
bdata = struct.unpack(self.barfmt, bardata)
# Years are stored as if they had 500 days
y, md = divmod(bdata[0], 500)
# Months are stored as if they had 32 days
m, d = divmod(md, 32)
# put y, m, d in a datetime
dt = datetime.datetime(y, m, d)
if self.dtsize > 1: # Minute Bars
# Daily Time is stored in seconds
hhmm, ss = divmod(bdata[1], 60)
hh, mm = divmod(hhmm, 60)
# add the time to the existing atetime
dt = dt.replace(hour=hh, minute=mm, second=ss)
self.lines.datetime[0] = date2num(dt)
# Get the rest of the unpacked data
o, h, l, c, v, oi = bdata[self.dtsize:]
self.lines.open[0] = o
self.lines.high[0] = h
self.lines.low[0] = l
self.lines.close[0] = c
self.lines.volume[0] = v
self.lines.openinterest[0] = oi
# Say success
return True