原文:
www.backtrader.com/
用户自定义佣金
原文:
www.backtrader.com/docu/user-defined-commissions/commission-schemes-subclassing/
重塑 CommInfo 对象到实际形式的最重要部分涉及:
-
保留原始的
CommissionInfo类和行为 -
为轻松创建用户定义的佣金打开大门
-
将格式 xx% 设为新佣金方案的默认值而不是 0.xx(只是一种品味问题),保持行为可配置
注意
请参阅下面的 CommInfoBase 的文档字符串以获取参数参考
定义佣金方案
这涉及到 1 或 2 个步骤
-
子类化
CommInfoBase简单地更改默认参数可能就足够了。
backtrader已经在模块backtrader.commissions中的一些定义中这样做了。期货的常规行业标准是每个合同和每轮的固定金额。定义如下:class CommInfo_Futures_Fixed(CommInfoBase): params = ( ('stocklike', False), ('commtype', CommInfoBase.COMM_FIXED), )`对于股票和百分比佣金:
class CommInfo_Stocks_Perc(CommInfoBase): params = ( ('stocklike', True), ('commtype', CommInfoBase.COMM_PERC), )`如上所述,这里对百分比的解释的默认是:xx%。如果希望使用旧的/其他行为 0.xx,可以轻松实现:
class CommInfo_Stocks_PercAbs(CommInfoBase): params = ( ('stocklike', True), ('commtype', CommInfoBase.COMM_PERC), ('percabs', True), )` -
覆盖(如果需要的话)
_getcommission方法定义如下:
def _getcommission(self, size, price, pseudoexec): '''Calculates the commission of an operation at a given price pseudoexec: if True the operation has not yet been executed '''`更多详细信息请参见下面的实际示例
如何应用到平台上
一旦 CommInfoBase 的子类就位,关键是使用 broker.addcommissioninfo 而不是通常的 broker.setcommission。后者将在内部使用传统的 CommissionInfoObject。
说起来容易做起来难:
...
comminfo = CommInfo_Stocks_PercAbs(commission=0.005) # 0.5%
cerebro.broker.addcommissioninfo(comminfo)
addcommissioninfo 方法定义如下:
def addcommissioninfo(self, comminfo, name=None):
self.comminfo[name] = comminfo
设置 name 意味着 comminfo 对象仅适用于具有该名称的资产。默认值 None 意味着它适用于系统中的所有资产。
一个实际的例子
票号 #45 询问适用于期货的佣金方案,是百分比方式,并在佣金计算中使用合同的“虚拟”价值的佣金百分比。即:在佣金计算中包括未来合约的倍数。
这应该很容易:
import backtrader as bt
class CommInfo_Fut_Perc_Mult(bt.CommInfoBase):
params = (
('stocklike', False), # Futures
('commtype', bt.CommInfoBase.COMM_PERC), # Apply % Commission
# ('percabs', False), # pass perc as xx% which is the default
)
def _getcommission(self, size, price, pseudoexec):
return size * price * self.p.commission * self.p.mult
将其加入系统:
comminfo = CommInfo_Fut_Perc_Mult(
commission=0.1, # 0.1%
mult=10,
margin=2000 # Margin is needed for futures-like instruments
)
cerebro.addcommissioninfo(comminfo)
如果格式 0.xx 被偏好为默认值,只需将参数 percabs 设置为 True:
class CommInfo_Fut_Perc_Mult(bt.CommInfoBase):
params = (
('stocklike', False), # Futures
('commtype', bt.CommInfoBase.COMM_PERC), # Apply % Commission
('percabs', True), # pass perc as 0.xx
)
comminfo = CommInfo_Fut_Perc_Mult(
commission=0.001, # 0.1%
mult=10,
margin=2000 # Margin is needed for futures-like instruments
)
cerebro.addcommissioninfo(comminfo)
这一切都应该行得通。
解释 pseudoexec
让我们回顾一下 _getcommission 的定义:
def _getcommission(self, size, price, pseudoexec):
'''Calculates the commission of an operation at a given price
pseudoexec: if True the operation has not yet been executed
'''
pseudoexec 参数的目的可能看起来很模糊,但它确实有其作用。
-
平台可能调用此方法来预先计算可用现金和一些其他任务
-
这意味着该方法可能(而且实际上会)使用相同的参数调用多次
pseudoexec 表示调用是否对应于订单的实际执行。虽然乍一看这可能似乎“不相关”,但如果考虑以下情景,它就很重要:
-
一家经纪人在合同数量超过 5000 单位后会给期货来回佣金打 5 折
在这种情况下,如果没有
pseudoexec,对该方法的多次非执行调用将迅速触发折扣已生效的假设。
将情景付诸实践:
import backtrader as bt
class CommInfo_Fut_Discount(bt.CommInfoBase):
params = (
('stocklike', False), # Futures
('commtype', bt.CommInfoBase.COMM_FIXED), # Apply Commission
# Custom params for the discount
('discount_volume', 5000), # minimum contracts to achieve discount
('discount_perc', 50.0), # 50.0% discount
)
negotiated_volume = 0 # attribute to keep track of the actual volume
def _getcommission(self, size, price, pseudoexec):
if self.negotiated_volume > self.p.discount_volume:
actual_discount = self.p.discount_perc / 100.0
else:
actual_discount = 0.0
commission = self.p.commission * (1.0 - actual_discount)
commvalue = size * price * commission
if not pseudoexec:
# keep track of actual real executed size for future discounts
self.negotiated_volume += size
return commvalue
现在,pseudoexec的目的和存在应该清楚了。
CommInfoBase 文档字符串和参数
参见佣金:股票 vs 期货以获取CommInfoBase的参考。
佣金:信用
原文:
www.backtrader.com/docu/commission-credit/
在某些情况下,真实经纪人的现金金额可能会减少,因为资产操作包括利率。例如:
-
股票空头交易
-
ETF 即多头又空头
收费直接影响经纪账户的现金余额。但它仍然可以被视为佣金方案的一部分。因此,它已经在backtrader中建模。
CommInfoBase类(以及与之相关的CommissionInfo主接口对象)已经扩展了:
- 两个新参数,允许设置利率,并确定是否仅应用于空头或同时适用于多头和空头
参数
-
interest(默认:0.0)如果这个值不为零,则这是持有空头头寸的年利息。这主要是针对股票空头交易的
应用的默认公式:
days * price * size * (interest / 365)必须以绝对值指定:0.05 -> 5%
注意
可以通过重写方法
get_credit_interest来改变行为 -
interest_long(默认:False)一些产品(如 ETF)在空头和多头头寸上都会被收取利息。如果这是
True,并且interest不为零,利息将在两个方向上都收取
公式
默认实现将使用以下公式:
days * abs(size) * price * (interest / 365)
其中:
days:自仓位开启或上次计算信用利息以来经过的天数
重写公式
为了改变CommissionInfo的公式子类化是必需的。需要被重写的方法是:
def _get_credit_interest(self, size, price, days, dt0, dt1):
'''
This method returns the cost in terms of credit interest charged by
the broker.
In the case of ``size > 0`` this method will only be called if the
parameter to the class ``interest_long`` is ``True``
The formulat for the calculation of the credit interest rate is:
The formula: ``days * price * abs(size) * (interest / 365)``
Params:
- ``data``: data feed for which interest is charged
- ``size``: current position size. > 0 for long positions and < 0 for
short positions (this parameter will not be ``0``)
- ``price``: current position price
- ``days``: number of days elapsed since last credit calculation
(this is (dt0 - dt1).days)
- ``dt0``: (datetime.datetime) current datetime
- ``dt1``: (datetime.datetime) datetime of previous calculation
``dt0`` and ``dt1`` are not used in the default implementation and are
provided as extra input for overridden methods
'''
可能是经纪人在计算利率时不考虑周末或银行假日。在这种情况下,这个子类会奏效
import backtrader as bt
class MyCommissionInfo(bt.CommInfo):
def _get_credit_interest(self, size, price, days, dt0, dt1):
return 1.0 * abs(size) * price * (self.p.interest / 365.0)
在这种情况下,在公式中:
days已被1.0替代
因为如果周末/银行假日不计入,下一次计算将始终在上次计算后的1个交易日后发生
分析器
分析器
原文:
www.backtrader.com/docu/analyzers/analyzers/
无论是回测还是交易,能够分析交易系统的性能对于了解是否仅仅获得了利润以及是否存在过多风险或者与参考资产(或无风险资产)相比是否真的值得努力至关重要。
这就是 Analyzer 对象族的作用:提供已发生情况或实际正在发生情况的分析。
分析器的性质
接口模仿了 Lines 对象的接口,例如包含一个 next 方法,但有一个主要区别:
-
Analyzers不保存线条。这意味着它们在内存方面并不昂贵,因为即使在分析了成千上万个价格条之后,它们仍然可能只保存单个结果在内存中。
生态系统中的位置
Analyzer 对象(像 strategies、observers 和 datas 一样)通过 cerebro 实例添加到系统中:
addanalyzer(ancls, *args, **kwargs)
但是当在 cerebro.run 过程中进行操作时,对于系统中每个 策略,将会发生以下情况
-
ancls将在cerebro.run过程中以*args和**kwargs实例化。 -
ancls实例将被附加到策略上。
这意味着:
- 如果回测运行包含例如 3 个策略,那么将会创建 3 个
ancls实例,并且每个实例都将附加到不同的策略上。
底线是:分析器分析单个策略的性能,而不是整个系统的性能
额外的位置
一些 Analyzer 对象实际上可能使用其他分析器来完成其工作。例如:SharpeRatio 使用 TimeReturn 的输出进行计算。
这些 子分析器 或 从属分析器 也将被插入到创建它们的同一策略中。但对用户来说完全看不见。
属性
为了执行预期的工作,Analyzer 对象提供了一些默认属性,这些属性被自动传递和设置在实例中以便使用:
-
self.strategy:策略子类的引用,分析器对象正在操作其中。任何 strategy 可访问的内容也可以被 analyzer 访问。 -
self.datas[x]:策略中存在的数据源数组。尽管这可以通过 strategy 引用访问,但这个快捷方式使工作更加方便。 -
self.data:为了额外的便利而设置的快捷方式。 -
self.dataX:快捷方式到不同的self.datas[x]
还提供了一些其他别名,尽管它们可能是多余的:
* `self.dataX_Y` where X is a reference to `self.datas[X]` and `Y`
refers to the line, finally pointing to: `self.datas[X].lines[Y]
如果线条有名称,还可以获得以下内容:
* `self.dataX_Name` which resolves to `self.datas[X].Name` returning
the line by name rather than by index
对于第一个数据,最后两个快捷方式也可用,无需初始的 X 数字引用。例如:
* `self.data_2` refers to `self.datas[0].lines[2]
和
* `self.data_close` refers to `self.datas[0].close
返回分析结果
Analyzer 基类创建一个 self.rets(类型为 collections.OrderedDict)成员属性来返回分析结果。 这是在方法 create_analysis 中完成的,如果创建自定义分析器,子类可以覆盖此方法。
操作模式
虽然 Analyzer 对象不是 Lines 对象,因此不会迭代线条,但它们被设计为遵循相同的操作模式。
-
在系统启动之前实例化(因此调用
__init__) -
使用
start标志操作的开始 -
将调用
prenext/nextstart/next,遵循 策略 正在运行的最短周期的计算结果。prenext和nextstart的默认行为是调用 next,因为分析器可能从系统启动的第一刻就开始分析。在 Lines 对象中调用
len(self)来检查实际的条数可能是习惯的。 这在Analyzers中也适用,通过为self.strategy返回值。 -
订单和交易将像对策略一样通过
notify_order和notify_trade进行通知 -
现金和价值也将像对策略一样通过
notify_cashvalue方法进行通知 -
现金、价值、基金价值和基金份额也将像对策略一样通过
notify_fund方法进行通知 -
stop将被调用以信号操作结束
一旦常规操作周期完成,分析器 就会提供用于提取/输出信息的附加方法
-
get_analysis:理想情况下(不强制要求)返回一个类似于dict的对象,其中包含分析结果。 -
print使用标准的backtrader.WriterFile(除非被覆盖)来从get_analysis写入分析结果。 -
pprint(漂亮打印)使用 Pythonpprint模块打印get_analysis的结果。
最后:
-
get_analysis创建一个成员属性self.ret(类型为collections.OrderedDict),分析器将分析结果写入其中。Analyzer 的子类可以重写此方法以更改此行为
分析器模式
在 backtrader 平台上开发 Analyzer 对象揭示了两种不同的用法模式用于生成分析:
-
通过在
notify_xxx和next方法中收集信息并在next中生成分析的当前信息进行执行例如,
TradeAnalyzer只使用notify_trade方法生成统计信息。 -
在
stop方法期间一次性生成分析结果,收集(或不收集)如上信息SQN(系统质量数)在notify_trade期间收集交易信息,但在stop方法中生成统计信息
一个快速的示例
尽可能简单:
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import backtrader as bt
import backtrader.analyzers as btanalyzers
import backtrader.feeds as btfeeds
import backtrader.strategies as btstrats
cerebro = bt.Cerebro()
# data
dataname = '../datas/sample/2005-2006-day-001.txt'
data = btfeeds.BacktraderCSVData(dataname=dataname)
cerebro.adddata(data)
# strategy
cerebro.addstrategy(btstrats.SMA_CrossOver)
# Analyzer
cerebro.addanalyzer(btanalyzers.SharpeRatio, _name='mysharpe')
thestrats = cerebro.run()
thestrat = thestrats[0]
print('Sharpe Ratio:', thestrat.analyzers.mysharpe.get_analysis())
执行它(已将其存储在 analyzer-test.py 中:
$ ./analyzer-test.py
Sharpe Ratio: {'sharperatio': 11.647332609673256}
没有绘图,因为 SharpeRatio 是在计算结束时的单个值。
分析器的法证分析
让我们重申一下,分析器不是线对象,但为了无缝地将它们整合到backtrader生态系统中,遵循了几个线对象的内部 API 约定(实际上是一个混合)
注意
SharpeRatio的代码已经发展到例如考虑年度化,这里的版本应该仅作为参考。
请查看分析器参考资料
此外还有一个SharpeRatio_A,无论所需的时间范围如何,都会直接提供年化形式的值
SharpeRatio的代码作为基础(简化版)
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import operator
from backtrader.utils.py3 import map
from backtrader import Analyzer, TimeFrame
from backtrader.mathsupport import average, standarddev
from backtrader.analyzers import AnnualReturn
class SharpeRatio(Analyzer):
params = (('timeframe', TimeFrame.Years), ('riskfreerate', 0.01),)
def __init__(self):
super(SharpeRatio, self).__init__()
self.anret = AnnualReturn()
def start(self):
# Not needed ... but could be used
pass
def next(self):
# Not needed ... but could be used
pass
def stop(self):
retfree = [self.p.riskfreerate] * len(self.anret.rets)
retavg = average(list(map(operator.sub, self.anret.rets, retfree)))
retdev = standarddev(self.anret.rets)
self.ratio = retavg / retdev
def get_analysis(self):
return dict(sharperatio=self.ratio)
代码可以分解为:
-
params声明尽管声明的变量没有被使用(仅作为示例),像大多数
backtrader中的其他对象一样,分析器也支持参数 -
__init__方法就像策略在
__init__中声明指标一样,分析器也是使用支持对象的。在这种情况下:使用年度收益计算
夏普比率。计算将自动进行,并且将对夏普比率进行自己的计算。注意
夏普比率的实际实现使用了更通用和后来开发的TimeReturn分析器 -
next方法夏普比率不需要它,但是此方法将在每次调用父策略的next后调用 -
start方法在回测开始之前调用。可用于额外的初始化任务。
夏普比率不需要它 -
stop方法在回测结束后立即调用。像
SharpeRatio一样,它可用于完成/进行计算 -
get_analysis方法(返回一个字典)外部调用者对生成的分析的访问
返回:带有分析结果的字典。
参考资料
类 backtrader.Analyzer()
分析器基类。所有分析器都是此类的子类
分析器实例在策略的框架内运行,并为该策略提供分析。
自动设置成员属性:
-
self.strategy(提供对策略及其可访问的任何内容的访问) -
self.datas[x]提供对系统中存在的数据源数组的访问,也可以通过策略引用访问 -
self.data,提供对self.datas[0]的访问 -
self.dataX->self.datas[X] -
self.dataX_Y->self.datas[X].lines[Y] -
self.dataX_name->self.datas[X].name -
self.data_name->self.datas[0].name -
self.data_Y->self.datas[0].lines[Y]
这不是一个线对象,但是方法和操作遵循相同的设计
-
在实例化和初始设置期间的
__init__ -
start/stop用于信号开始和结束操作 -
遵循与策略中相同方法调用后的
prenext/nextstart/next方法系列 -
notify_trade/notify_order/notify_cashvalue/notify_fund,它们接收与策略的等效方法相同的通知
操作模式是开放的,没有首选模式。因此,分析可以通过next调用,在stop期间的操作结束时甚至通过单个方法notify_trade生成。
重要的是要重写get_analysis以返回包含分析结果的类似于字典的对象(实际格式取决于实现)。
start()
表示开始操作,使分析器有时间设置所需的东西。
stop()
表示结束操作,使分析器有时间关闭所需的东西。
prenext()
对策略的每次 prenext 调用都会调用,直到策略的最小周期已达到。
分析器的默认行为是调用next。
nextstart()
为下一次策略的 nextstart 调用精确调用一次,当首次达到最小周期时。
next()
对策略的每次 next 调用进行调用,一旦策略的最小周期已达到。
notify_cashvalue(cash, value)
在每次下一周期之前接收现金/价值通知。
notify_fund(cash, value, fundvalue, shares)
在每次下一周期之前接收当前现金、价值、基金价值和基金份额。
notify_order(order)
在每次下一周期之前接收订单通知。
notify_trade(trade)
在每次下一周期之前接收交易通知。
get_analysis()
返回一个类似于字典的对象,其中包含分析结果。
字典中分析结果的键和格式取决于具体实现。
甚至不强制结果是类似于字典对象,只是约定。
默认实现返回由默认的create_analysis方法创建的默认OrderedDict``rets。
create_analysis()
应由子类重写。给予创建保存分析的结构的机会。
默认行为是创建一个名为rets的OrderedDict。
print(*args, **kwargs)
通过标准的Writerfile对象打印get_analysis返回的结果,默认情况下将其写入标准输出。
pprint(*args, **kwargs)
使用 Python 的漂亮打印模块(pprint)打印get_analysis返回的结果。
len()
通过实际返回分析器所操作的策略的当前长度来支持对分析器进行len调用。
PyFolio 概述
原文:
www.backtrader.com/docu/analyzers/pyfolio/
注意
截至至少 2017-07-25,pyfolio的 API 已更改,create_full_tear_sheet不再具有gross_lev作为命名参数。
因此,集成的示例无法运行
引用主要pyfolio页面上的内容quantopian.github.io/pyfolio/:
pyfolio is a Python library for performance and risk analysis of financial
portfolios developed by Quantopian Inc. It works well with the Zipline open
source backtesting library
现在它也与backtrader很好地配合。需要什么:
-
显然是
pyfolio -
以及它的依赖项(例如
pandas,seaborn…)注意
在与版本
0.5.1集成期间,需要更新依赖项的最新软件包,例如从先前安装的0.7.0-dev到0.7.1的seaborn,显然是由于缺少swarmplot方法
用法
-
将
PyFolio分析器添加到cerebro混合中:cerebro.addanalyzer(bt.analyzers.PyFolio)` -
运行并检索第 1 个策略:
strats = cerebro.run() strat0 = strats[0]` -
使用您指定的名称或默认名称
pyfolio检索分析器。例如:pyfolio = strats.analyzers.getbyname('pyfolio')` -
使用分析器方法
get_pf_items检索后续需要用于pyfolio的 4 个组件:returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()`!!! 注意
The integration was done looking at test samples available with `pyfolio` and the same headers (or absence of) has been replicated` -
使用
pyfolio(这已经超出了backtrader生态系统)
一些与backtrader无直接关系的使用说明
-
pyfolio自动绘图功能在Jupyter Notebook之外也可以工作,但在内部效果最佳。 -
pyfolio数据表的输出似乎在Jupyter Notebook之外几乎无法工作。它在Notebook内部工作
如果希望使用pyfolio,结论很简单:在 Jupyter Notebook 内部工作
示例代码
代码如下所示:
...
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='pyfolio')
...
results = cerebro.run()
strat = results[0]
pyfoliozer = strat.analyzers.getbyname('pyfolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
...
...
# pyfolio showtime
import pyfolio as pf
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
gross_lev=gross_lev,
live_start_date='2005-05-01', # This date is sample specific
round_trips=True)
# At this point tables and chart will show up
参考
查看PyFolio分析器的参考资料以及它内部使用的分析器
Pyfolio 集成
原文:
www.backtrader.com/docu/analyzers/pyfolio-integration/pyfolio-integration/
portfolio 工具的集成,即 pyfolio,是在 Ticket #108 中提出的。
对教程的第一次尝试被认为很难,考虑到 zipline 和 pyfolio 之间的紧密集成,但是 pyfolio 提供的用于其他用途的样本测试数据实际上非常有用,可以解码背后发生的事情,从而实现了集成的奇迹。
大部分组件已经在 backtrader 中就位:
-
分析器基础设施
-
子分析器
-
一个 TimeReturn 分析器
只需要一个主PyFolio分析器和 3 个简单的子分析器。再加上一个依赖于pyfolio的依赖项中的方法,即pandas。
最具挑战性的部分…“确保所有依赖项正确”
-
pandas的更新 -
numpy的更新 -
scikit-learn的更新 -
seaborn的更新
在类 Unix 环境下使用 C 编译器,一切都取决于时间。在 Windows 下,即使安装了特定的 Microsoft 编译器(在这种情况下是用于 Python 2.7 的链),事情也会失败。但是一个众所周知的拥有最新包的 Windows 站点却有所帮助。如果你需要的话,请访问它:
www.lfd.uci.edu/~gohlke/pythonlibs/
如果没有经过测试,集成就不完整,这就是为什么通常的样本总是存在。
没有 PyFolio
样本使用random.randint来决定何时买入/卖出,所以这只是一个检查是否工作的简单检查:
$ ./pyfoliotest.py --printout --no-pyfolio --plot
输出:
Len,Datetime,Open,High,Low,Close,Volume,OpenInterest
0001,2005-01-03T23:59:59,38.36,38.90,37.65,38.18,25482800.00,0.00
BUY 1000 @%23.58
0002,2005-01-04T23:59:59,38.45,38.54,36.46,36.58,26625300.00,0.00
BUY 1000 @%36.58
SELL 500 @%22.47
0003,2005-01-05T23:59:59,36.69,36.98,36.06,36.13,18469100.00,0.00
...
SELL 500 @%37.51
0502,2006-12-28T23:59:59,25.62,25.72,25.30,25.36,11908400.00,0.00
0503,2006-12-29T23:59:59,25.42,25.82,25.33,25.54,16297800.00,0.00
SELL 250 @%17.14
SELL 250 @%37.01
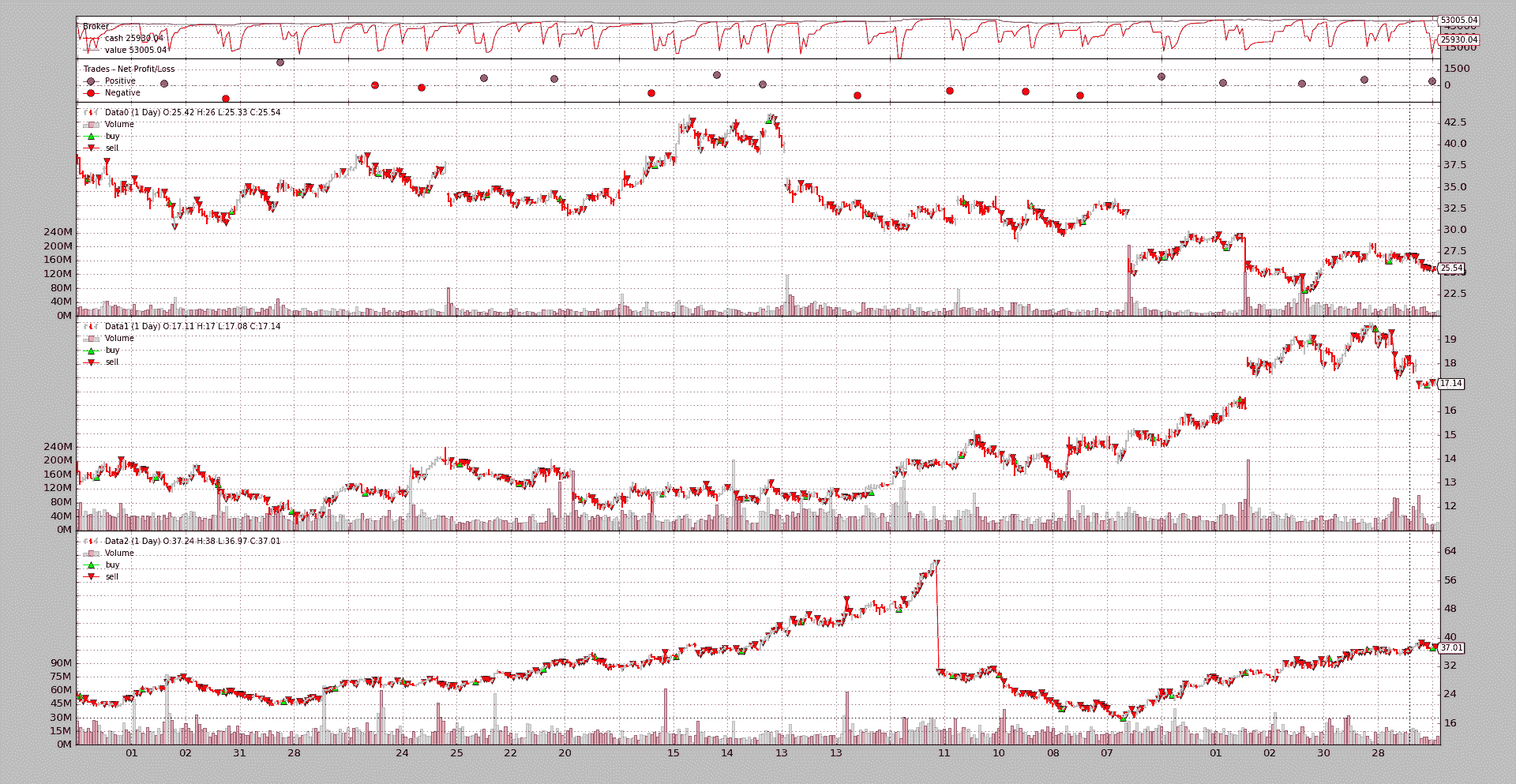
有 3 个数据,几个买入和卖出操作被随机选择并散布在测试运行的默认 2 年生命周期内
一个 PyFolio 运行
运行在 Jupyter Notebook 中时,pyfolio 的工作非常顺利,包括内联绘图。这就是笔记本
注意
runstrat 在此处使用[]作为参数运行,默认参数并跳过笔记本本身传递的参数
%matplotlib inline
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import random
import backtrader as bt
class St(bt.Strategy):
params = (
('printout', False),
('stake', 1000),
)
def __init__(self):
pass
def start(self):
if self.p.printout:
txtfields = list()
txtfields.append('Len')
txtfields.append('Datetime')
txtfields.append('Open')
txtfields.append('High')
txtfields.append('Low')
txtfields.append('Close')
txtfields.append('Volume')
txtfields.append('OpenInterest')
print(','.join(txtfields))
def next(self):
if self.p.printout:
# Print only 1st data ... is just a check that things are running
txtfields = list()
txtfields.append('%04d' % len(self))
txtfields.append(self.data.datetime.datetime(0).isoformat())
txtfields.append('%.2f' % self.data0.open[0])
txtfields.append('%.2f' % self.data0.high[0])
txtfields.append('%.2f' % self.data0.low[0])
txtfields.append('%.2f' % self.data0.close[0])
txtfields.append('%.2f' % self.data0.volume[0])
txtfields.append('%.2f' % self.data0.openinterest[0])
print(','.join(txtfields))
# Data 0
for data in self.datas:
toss = random.randint(1, 10)
curpos = self.getposition(data)
if curpos.size:
if toss > 5:
size = curpos.size // 2
self.sell(data=data, size=size)
if self.p.printout:
print('SELL {} @%{}'.format(size, data.close[0]))
elif toss < 5:
self.buy(data=data, size=self.p.stake)
if self.p.printout:
print('BUY {} @%{}'.format(self.p.stake, data.close[0]))
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
cerebro.broker.set_cash(args.cash)
dkwargs = dict()
if args.fromdate:
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
dkwargs['fromdate'] = fromdate
if args.todate:
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
dkwargs['todate'] = todate
data0 = bt.feeds.BacktraderCSVData(dataname=args.data0, **dkwargs)
cerebro.adddata(data0, name='Data0')
data1 = bt.feeds.BacktraderCSVData(dataname=args.data1, **dkwargs)
cerebro.adddata(data1, name='Data1')
data2 = bt.feeds.BacktraderCSVData(dataname=args.data2, **dkwargs)
cerebro.adddata(data2, name='Data2')
cerebro.addstrategy(St, printout=args.printout)
if not args.no_pyfolio:
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='pyfolio')
results = cerebro.run()
if not args.no_pyfolio:
strat = results[0]
pyfoliozer = strat.analyzers.getbyname('pyfolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
if args.printout:
print('-- RETURNS')
print(returns)
print('-- POSITIONS')
print(positions)
print('-- TRANSACTIONS')
print(transactions)
print('-- GROSS LEVERAGE')
print(gross_lev)
import pyfolio as pf
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
gross_lev=gross_lev,
live_start_date='2005-05-01',
round_trips=True)
if args.plot:
cerebro.plot(style=args.plot_style)
def parse_args(args=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Sample for pivot point and cross plotting')
parser.add_argument('--data0', required=False,
default='../../datas/yhoo-1996-2015.txt',
help='Data to be read in')
parser.add_argument('--data1', required=False,
default='../../datas/orcl-1995-2014.txt',
help='Data to be read in')
parser.add_argument('--data2', required=False,
default='../../datas/nvda-1999-2014.txt',
help='Data to be read in')
parser.add_argument('--fromdate', required=False,
default='2005-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', required=False,
default='2006-12-31',
help='Ending date in YYYY-MM-DD format')
parser.add_argument('--printout', required=False, action='store_true',
help=('Print data lines'))
parser.add_argument('--cash', required=False, action='store',
type=float, default=50000,
help=('Cash to start with'))
parser.add_argument('--plot', required=False, action='store_true',
help=('Plot the result'))
parser.add_argument('--plot-style', required=False, action='store',
default='bar', choices=['bar', 'candle', 'line'],
help=('Plot style'))
parser.add_argument('--no-pyfolio', required=False, action='store_true',
help=('Do not do pyfolio things'))
import sys
aargs = args if args is not None else sys.argv[1:]
return parser.parse_args(aargs)
runstrat([])
Entire data start date: 2005-01-03
Entire data end date: 2006-12-29
Out-of-Sample Months: 20
Backtest Months: 3
[-0.012 -0.025]
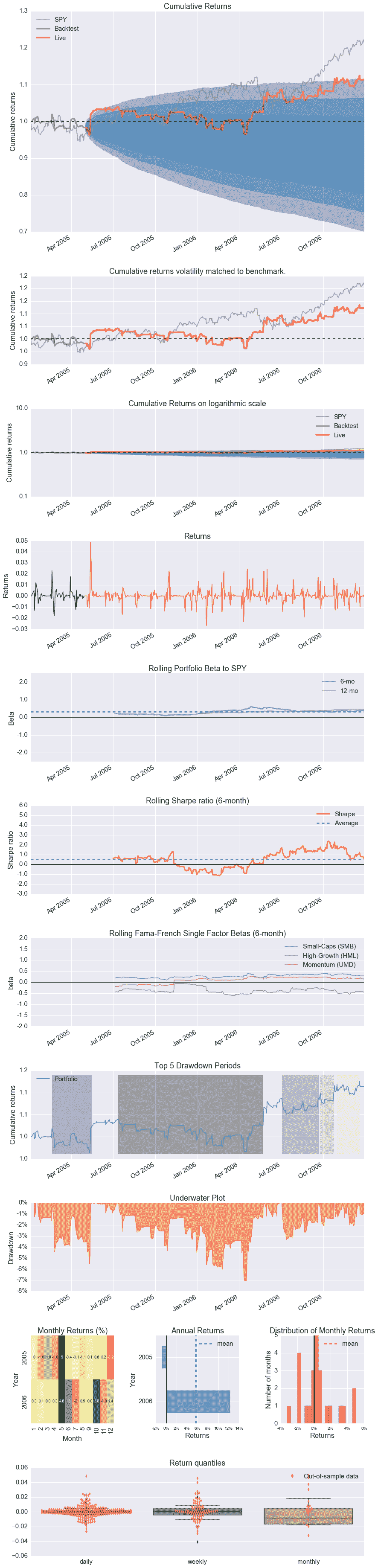
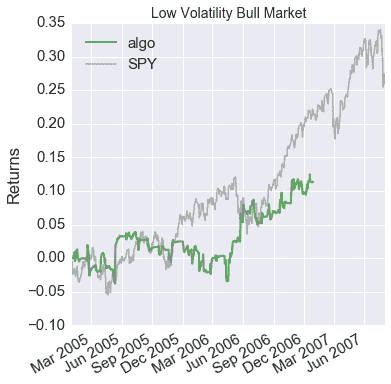
pyfolioplotting.py:1210: FutureWarning: .resample() is now a deferred operation
use .resample(...).mean() instead of .resample(...)
**kwargs)
<matplotlib.figure.Figure at 0x23982b70>
样本的使用:
$ ./pyfoliotest.py --help
usage: pyfoliotest.py [-h] [--data0 DATA0] [--data1 DATA1] [--data2 DATA2]
[--fromdate FROMDATE] [--todate TODATE] [--printout]
[--cash CASH] [--plot] [--plot-style {bar,candle,line}]
[--no-pyfolio]
Sample for pivot point and cross plotting
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to be read in (default:
../../datas/yhoo-1996-2015.txt)
--data1 DATA1 Data to be read in (default:
../../datas/orcl-1995-2014.txt)
--data2 DATA2 Data to be read in (default:
../../datas/nvda-1999-2014.txt)
--fromdate FROMDATE Starting date in YYYY-MM-DD format (default:
2005-01-01)
--todate TODATE Ending date in YYYY-MM-DD format (default: 2006-12-31)
--printout Print data lines (default: False)
--cash CASH Cash to start with (default: 50000)
--plot Plot the result (default: False)
--plot-style {bar,candle,line}
Plot style (default: bar)
--no-pyfolio Do not do pyfolio things (default: False)
分析员参考
原文:
www.backtrader.com/docu/analyzers-reference/
AnnualReturn
class backtrader.analyzers.AnnualReturn()
此分析器通过查看年初和年末来计算年度回报
参数:
- (无)
成员属性:
-
rets:计算的年度回报列表 -
ret:年度回报的字典(键:年份)
get_analysis:
- 返回年度回报的字典(键:年份)
Calmar
class backtrader.analyzers.Calmar()
此分析器计算 CalmarRatio 时间范围,该范围可能与基础数据中使用的范围不同 参数:
-
timeframe(默认:None)如果为None,则系统中第 1 个数据的timeframe将被使用传递
TimeFrame.NoTimeFrame以考虑没有时间约束的整个数据集 -
compression(默认:None)仅用于次日时间范围,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来在小时时间范围上工作
如果为
None,则将使用系统的第 1 个数据的压缩 -
None
-
fund(默认:None)如果为
None,则经纪人的实际模式(fundmode - True/False)将被自动检测,以决定收益是否基于总净资产价值或基金价值。参见经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
- get_analysis()
返回具有时间段键和相应滚动 Calmar 比率的 OrderedDict
- calmar最新计算的 calmar 比率()
回撤
class backtrader.analyzers.DrawDown()
此分析器计算交易系统的回撤统计数据,例如以%为单位和以美元为单位的回撤值,以%为单位和以美元为单位的最大回撤,回撤长度和最大回撤长度
参数:
-
fund(默认:None)如果为
None,则经纪人的实际模式(fundmode - True/False)将被自动检测,以决定收益是否基于总净资产价值或基金价值。参见经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
- get_analysis()
返回一个字典(支持点表示法和子字典)作为值的回撤统计,可用以下键/属性:
-
drawdown- 0.xx%的回撤值 -
moneydown- 货币单位中的回撤值 -
len- 回撤长度 -
max.drawdown- 0.xx%的最大回撤值 -
max.moneydown- 最大资金单位中的最大回撤值 -
max.len- 最大回撤长度
TimeDrawDown
class backtrader.analyzers.TimeDrawDown()
此分析器计算所选时间范围内的交易系统回撤,该时间范围可能与基础数据中使用的范围不同 参数:
-
timeframe(默认:None)如果为None,则系统中第 1 个数据的timeframe将被使用传递
TimeFrame.NoTimeFrame以考虑没有时间约束的整个数据集 -
compression(默认:None)仅用于亚日时间框架,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来在小时时间框架上工作
如果为
None,则将使用系统第一条数据的压缩 -
None
-
fund(默认:None)如果为
None,则将自动检测经纪人的实际模式(fundmode - True/False),以决定收益是基于总净资产价值还是基金价值。请参阅经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
- get_analysis()
返回一个字典(支持.表示法和子字典)作为值的回撤统计信息,可用的键/属性如下:
-
drawdown- 回撤值为 0.xx % -
maxdrawdown- 回撤值为货币单位 -
maxdrawdownperiod- 回撤长度
- 这些在运行时作为属性可用()
-
dd -
maxdd -
maxddlen
总杠杆
类backtrader.analyzers.GrossLeverage()
此分析器按时间框架计算当前策略的总杠杆
参数:
-
fund(默认:None)如果为
None,则将自动检测经纪人的实际模式(fundmode - True/False),以决定收益是基于总净资产价值还是基金价值。请参阅经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
- get_analysis()
返回一个字典,其中值为收益,键为每个收益的日期时间点
PositionsValue
类backtrader.analyzers.PositionsValue()
此分析器报告当前数据集的持仓价值
参数:
-
时间框架(默认:
None)如果为None,则将使用系统第一条数据的时间框架 -
压缩(默认:
None)仅用于亚日时间框架,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来在小时时间框架上工作
如果为
None,则将使用系统第一条数据的压缩 -
headers(默认:
False)向字典添加一个初始键,其中包含结果的名称(“Datetime”作为键
-
现金(默认:
False)将实际现金作为额外头寸包含(对于标题,将使用“cash”作为名称)
- get_analysis()
返回一个字典,其中值为收益,键为每个收益的日期时间点
PyFolio
类backtrader.analyzers.PyFolio()
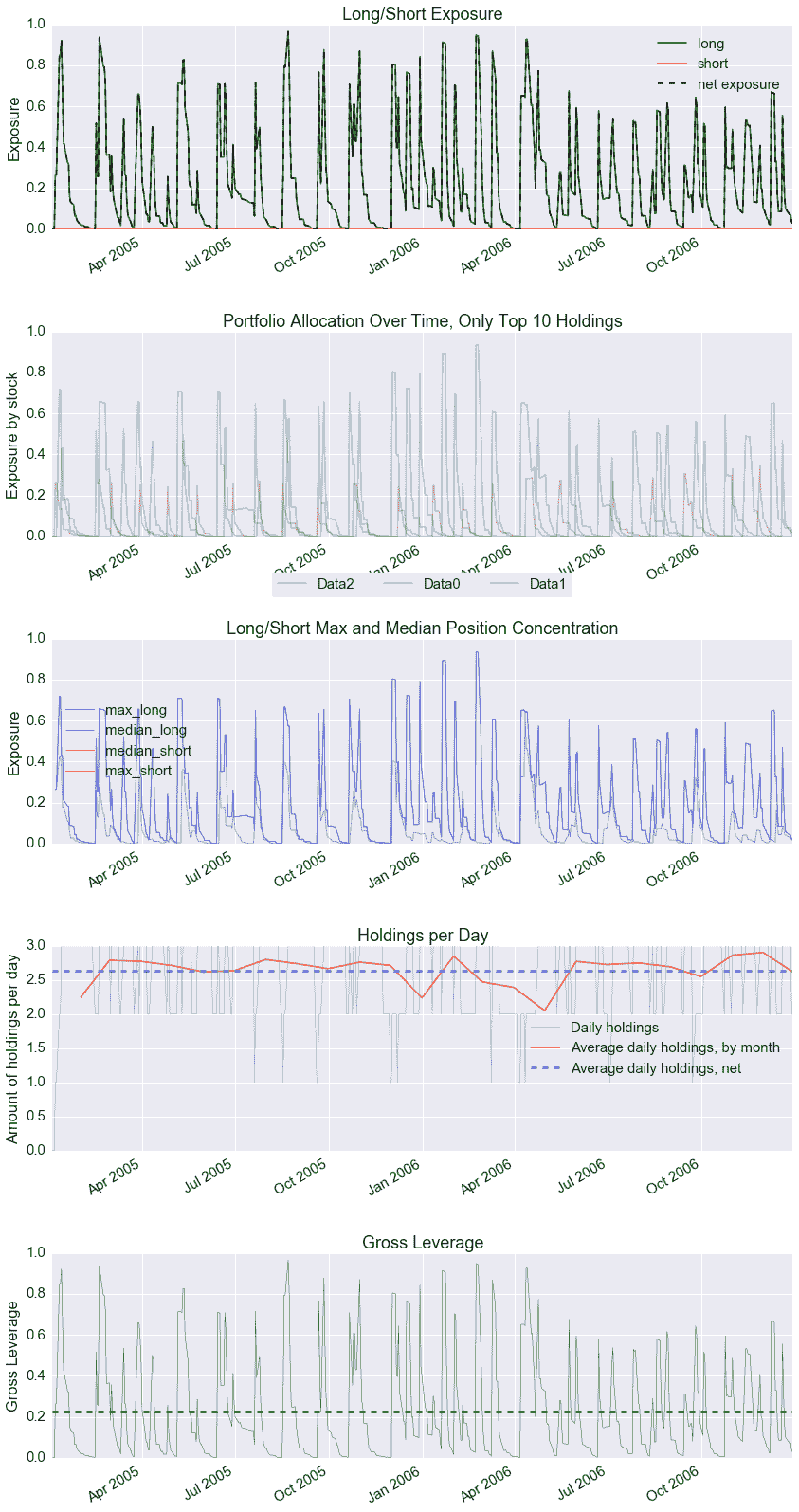
此分析器使用 4 个子分析器收集数据并将其转换为与pyfolio兼容的数据集
子分析器
-
TimeReturn用于计算全局投资组合价值的收益
-
PositionsValue用于计算每个数据的持仓价值。它将
headers和cash参数设置为True -
Transactions用于记录每笔交易的数据(大小,价格,价值)。将
headers参数设置为True -
GrossLeverage跟踪总杠杆(策略投资了多少)
参数:
These are passed transparently to the children
* timeframe (default: `bt.TimeFrame.Days`)
If `None` then the timeframe of the 1st data of the system will be
used
* compression (default: 1\`)
If `None` then the compression of the 1st data of the system will be
used
timeframe 和 compression 都遵循 pyfolio 的默认行为,即使用 daily 数据并将其上采样以获得年度收益等值。
- 获取分析()
返回一个以值为收益和以键为每个收益的日期时间点的字典
获取 pf_items()
返回一个包含收益为值和每个收益为键的字典
pyfolio`
returns, positions, transactions, gross_leverage
因为对象旨在直接输入到 pyfolio,此方法通过本地导入 pandas 将内部 backtrader 结果转换为 pandas DataFrames,这是例如 pyfolio.create_full_tear_sheet 期望的输入
如果未安装 pandas,则该方法将中断
LogReturnsRolling
类 backtrader.analyzers.LogReturnsRolling()
此分析器计算给定时间框架和压缩的滚动收益
参数:
-
timeframe(默认:None)如果None系统中的第一个数据的timeframe将被使用传递
TimeFrame.NoTimeFrame来考虑没有时间约束的整个数据集 -
compression(默认:None)仅用于子日时间框架,例如通过指定“TimeFrame.Minutes”和压缩为 60 来工作在小时时间框架上
如果为
None,则将使用系统的第一个数据的压缩 -
data(默认:None)跟踪的参考资产,而不是组合价值。
注意:此数据必须已经通过
addata、resampledata或replaydata添加到cerebro实例中 -
firstopen(默认:True)当跟踪
data的收益时,当穿越时间框架边界时,例如Years时,将执行以下操作:- 上一年的最后一个
close用作参考价格,以查看当前年份的收益
问题在于第一个计算,因为数据没有上一个收盘价。因此,当此参数为
True时,将使用 开盘 价格进行第一个计算。这要求数据源具有
open价格(对于close,将使用标准的[0]符号,不涉及字段价格)否则将使用初始收盘价。
- 上一年的最后一个
-
fund(默认:None)如果为
None,则将自动检测经纪人的实际模式(fundmode - True/False),以决定收益是基于总净资产价值还是基金价值。请参阅经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
- 获取分析()
返回一个以值为收益和以键为每个收益的日期时间点的字典
期间统计
类 backtrader.analyzers.PeriodStats()
计算给定时间框架的基本统计信息
参数:
-
timeframe(默认:Years)如果为None,则将使用系统中第一个数据的timeframe传递
TimeFrame.NoTimeFrame来考虑没有时间约束的整个数据集 -
compression(默认:1)仅用于子日时间框架,例如通过指定“TimeFrame.Minutes”和压缩为 60 来工作在小时时间框架上
如果是
None,则将使用系统的第一个数据进行压缩 -
fund(默认值:None)如果是
None,则会自动检测经纪人的实际模式(fundmode - True/False),以决定收益是否基于总净资产价值或基金价值。参见经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
get_analysis返回一个包含键的字典:
-
average -
stddev -
positive -
negative -
nochange -
best -
worst
如果参数zeroispos设置为True,则没有变化的期间将被视为正值
返回
类 backtrader.analyzers.Returns()
使用对数方法计算的总、平均、复合和年化收益
参见:
www.crystalbull.com/sharpe-ratio-better-with-log-returns/
参数:
-
timeframe(默认值:None)如果是
None,则将使用系统的第一个数据的timeframe将
TimeFrame.NoTimeFrame传递以考虑整个数据集,不受时间限制 -
compression(默认值:None)仅用于亚日时间框架,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来处理小时时间框架
如果是
None,则将使用系统的第一个数据进行压缩 -
tann(默认值:None)年度化(normalization)所使用的周期数
即:
-
days: 252 -
weeks: 52 -
months: 12 -
years: 1
-
-
fund(默认值:None)如果是
None,则会自动检测经纪人的实际模式(fundmode - True/False),以决定收益是否基于总净资产价值或基金价值。参见经纪人文档中的set_fundmode将其设置为
True或False以获得特定行为
- get_analysis()
返回一个以返回值为值和每个返回值的日期时间点为键的字典
返回的字典有以下键:
-
rtot:总复合回报 -
ravg:整个周期的平均回报(特定于时间框架) -
rnorm:年化/标准化回报 -
rnorm100:以 100%表示的年化/标准化回报
SharpeRatio
类 backtrader.analyzers.SharpeRatio()
此分析器使用一个风险免费资产(简单地是利率)计算策略的 SharpeRatio
参数:
-
timeframe:(默认值:TimeFrame.Years) -
compression(默认值:1)仅用于亚日时间框架,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来处理小时时间框架
-
riskfreerate(默认值:0.01 -> 1%)以年为单位表达(见下文的
convertrate) -
convertrate(默认值:True)将
riskfreerate从年度转换为月度、周度或日度利率。不支持亚日转换 -
factor(默认值:None)如果是
None,则将从预定义表中选择将风险无风险利率的转换因子从年度转换为所选择的时间框架天数:252,周数:52,月数:12,年数:1
否则将使用指定的值
-
annualize(默认值:False)如果
convertrate为True,则SharpeRatio将以所选的timeframe传递。在大多数情况下,SharpeRatio 以年化形式呈现。将
riskfreerate从年化转换为月度、周度或日度利率。不支持亚日转换 -
stddev_sample(默认值:False)如果设置为
True,则将计算标准差,并将平均值中的分母减1。当计算标准差时使用此项,如果考虑到并非所有样本都用于计算,则会使用此项。这称为Bessels’校正 -
daysfactor(默认值:None)旧名称为
factor。如果设置为除None之外的任何值,并且timeframe为TimeFrame.Days,则会假定这是旧代码,并将使用该值 -
legacyannual(默认值:False)使用
AnnualReturn返回分析器,正如其名称所示,仅适用于年份 -
fund(默认值:None)如果为
None,则将自动检测经纪人的实际模式(fundmode - True/False),以决定回报是基于总净资产值还是基金值。请参阅经纪人文档中的set_fundmode将其设置为
True或False以获取特定行为
- 获取分析()
返回一个带有键“sharperatio”的字典,其中包含比率
SharpeRatio_A
class backtrader.analyzers.SharpeRatio_A()
SharpeRatio 的扩展,直接以年化形式返回 Sharpe 比率
以下参数已从SharpeRatio更改
annualize(默认值:True)
SQN
class backtrader.analyzers.SQN()
SQN 或系统质量数。由 Van K. Tharp 定义以对交易系统进行分类。
-
1.6 - 1.9 低于平均水平
-
2.0 - 2.4 平均
-
2.5 - 2.9 良好
-
3.0 - 5.0 优秀
-
5.1 - 6.9 极好
-
7.0 - 圣杯?
公式:
- 平方根(交易次数)* 平均(交易利润)/ 标准差(交易利润)
当交易次数≥ 30 时,sqn 值应被视为可靠
- 获取分析()
返回一个带有键“sqn”和“trades”(考虑的交易数)的字典
TimeReturn
class backtrader.analyzers.TimeReturn()
此分析器通过查看时间范围的起始点和结束点来计算回报
参数:
-
timeframe(默认值:None)如果为None,则将使用系统中的第一个数据的timeframe通过传递
TimeFrame.NoTimeFrame来考虑没有时间约束的整个数据集 -
compression(默认值:None)仅用于亚日时间框架,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来处理每小时时间框架
如果为
None,则将使用系统的第一个数据的压缩 -
data(默认值:None)跟踪的参考资产而不是投资组合价值。
注意:此数据必须已添加到具有
addata、resampledata或replaydata的cerebro实例中 -
firstopen(默认值:True)当跟踪
data的回报时,当跨越时间范围边界时,例如Years时,会执行以下操作:- 上一年的最后一个
close用作参考价格,以查看当前年度的回报
问题是第一次计算,因为数据没有先前的收盘价。 因此,当此参数为
True时,将使用开盘价进行第一次计算。这需要数据源具有
open价格(对于close,将使用标准[0]表示法,而不参考字段价格)否则将使用初始收盘价。
- 上一年的最后一个
-
fund(默认值:None)如果为
None,则将自动检测经纪人的实际模式(fundmode - True/False),以决定基于总净资产值还是基金价值的回报。请参阅经纪人文档中的set_fundmode将其设置为特定行为的
True或False
- get_analysis()
返回一个带有值作为值的字典,并将每个返回的日期时间点作为键
TradeAnalyzer
类 backtrader.analyzers.TradeAnalyzer()
提供了有关已关闭交易的统计信息(还保留了未平仓交易的计数)
-
总开/闭交易
-
Streak 赢得/失去 当前/最长的
-
利润与损失 总数/平均数
-
赢得/失去 计数/总 PNL/平均 PNL/最大 PNL
-
长/空头 计数/ 总 PNL / 平均 PNL / 最大 PNL
- 赢得/失去 计数/总 PNL/平均 PNL/最大 PNL
-
长度(市场上的条)
-
总数/平均数/最大值/最小值
-
赢得/失去 总数/平均数/最大值/最小值
-
长/短 总数/平均值/最大值/最小值
-
赢得/失去 总数/平均数/最大值/最小值
-
注意:分析器使用“自动”字典进行字段处理,这意味着如果没有执行交易,将不会生成任何统计数据。
在这种情况下,get_analysis返回的字典中将有一个字段/子字段,即:
- dictname[‘total’][‘total’],其值将为 0(该字段还可以使用点表示法 dictname.total.total)。
交易
类 backtrader.analyzers.Transactions()
此分析器报告了系统中发生的每笔交易
它查看订单执行位以从每个next周期开始创建Position,初始值为 0。
结果将在下一个周期记录交易时使用
参数:
-
headers(默认值:
True)向字典添加一个初始键,该键包含具有数据名称的结果
这个分析器的建模是为了方便与
pyfolio集成,头部名称取自用于它的样本:'date', 'amount', 'price', 'sid', 'symbol', 'value'`
- get_analysis()
返回一个带有值作为值的字典,并将每个返回的日期时间点作为键
VWR
类 backtrader.analyzers.VWR()
变异性加权回报:对数收益率的夏普比率更好
别名:
- 变异性加权回报
见:
www.crystalbull.com/sharpe-ratio-better-with-log-returns/
参数:
-
timeframe(默认值:None)如果为None,则将报告整个回测期间的完整收益传递
TimeFrame.NoTimeFrame以考虑没有时间限制的整个数据集 -
compression(默认值:None)仅用于亚日时间框架,例如通过指定“TimeFrame.Minutes”和 60 作为压缩来处理小时时间框架
如果为
None,则将使用系统第一个数据的压缩 -
tann(默认值:None)用于计算平均收益的年化(标准化)周期数。如果为
None,则将使用标准的t值,即:-
days: 252 -
weeks: 52 -
months: 12 -
years: 1
-
-
tau(默认值:2.0)计算的因子(参见文献)
-
sdev_max(默认值:0.20)最大标准偏差(参见文献)
-
fund(默认值:None)如果为
None,则会自动检测经纪人的实际模式(fundmode - True/False),以决定收益是基于总净资产值还是基金价值。请参阅经纪人文档中的set_fundmode将其设置为
True或False以获得特定的行为
- 获取分析()
返回一个字典,其中收益作为值,每个收益对应的日期时间点作为键
返回的字典包含以下键:
vwr: 变异权重收益
观察者
观察者和统计
原文:
www.backtrader.com/docu/observers-and-statistics/observers-and-statistics/
在backtrader中运行的策略大多与数据源和指标有关。
数据源被添加到Cerebro实例中,并最终成为策略的输入之一(以实例的属性形式解析和提供),而指标则由策略本身声明和管理。
所有backtrader示例图表到目前为止都有 3 个似乎被视为理所当然的东西,因为它们没有在任何地方声明:
-
现金和价值(经纪人的资金情况)
-
交易(又名操作)
-
买入/卖出订单
它们是观察者,存在于子模块backtrader.observers中。它们在那里是因为Cerebro支持一个参数,用于自动添加(或不添加)它们到策略中:
stdstats(默认:True)
如果默认值被遵守,Cerebro将执行以下等效的用户代码:
import backtrader as bt
...
cerebro = bt.Cerebro() # default kwarg: stdstats=True
cerebro.addobserver(bt.observers.Broker)
cerebro.addobserver(bt.observers.Trades)
cerebro.addobserver(bt.observers.BuySell)
让我们看看具有这 3 个默认观察者的常规图表(即使没有发出订单,因此没有交易发生,也没有现金和投资组合价值的变化)
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import backtrader as bt
import backtrader.feeds as btfeeds
if __name__ == '__main__':
cerebro = bt.Cerebro(stdstats=False)
cerebro.addstrategy(bt.Strategy)
data = bt.feeds.BacktraderCSVData(dataname='../../datas/2006-day-001.txt')
cerebro.adddata(data)
cerebro.run()
cerebro.plot()
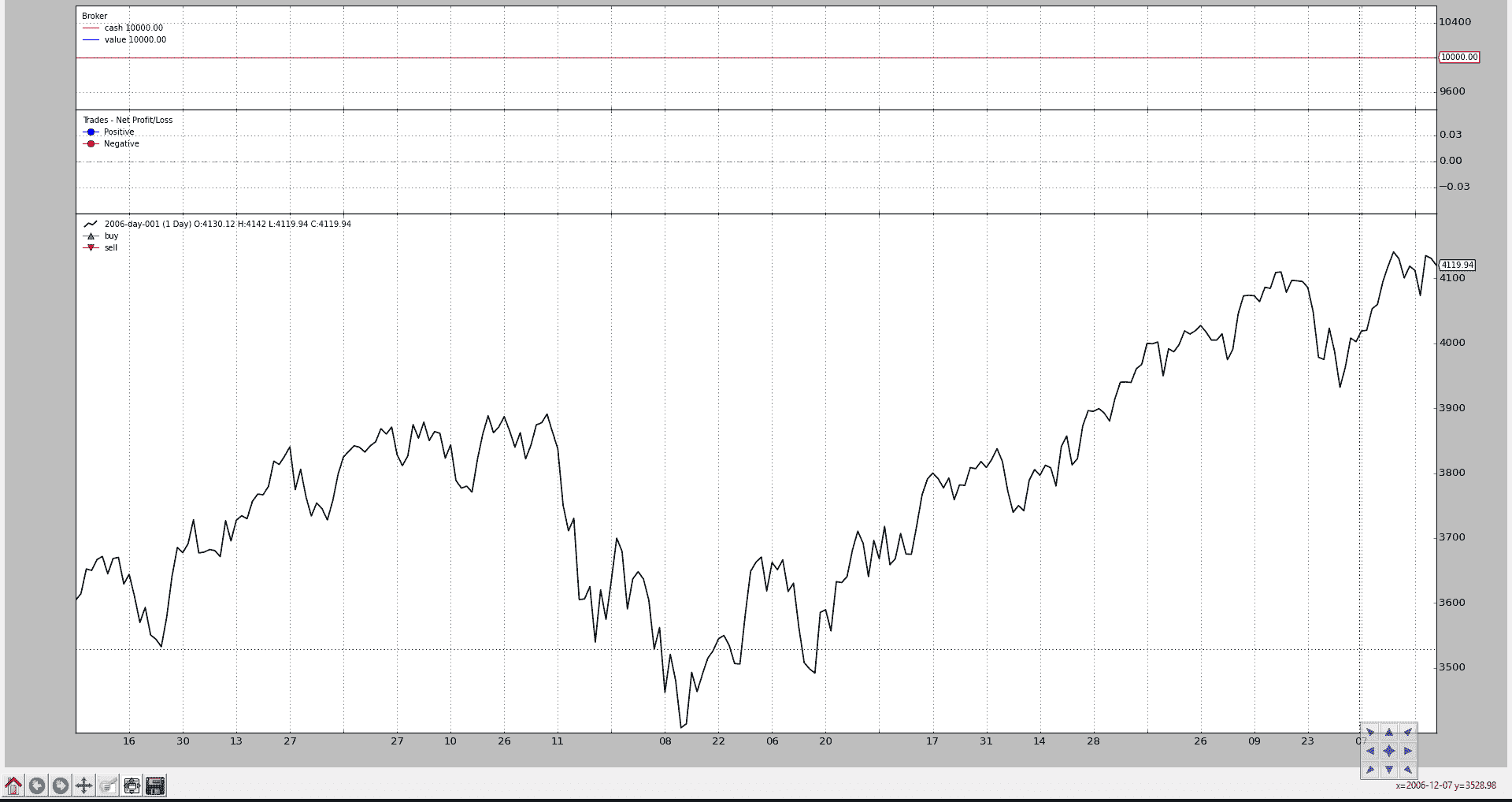
现在让我们在创建Cerebro实例时将stdstats的值更改为False(也可以在调用run时执行):
cerebro = bt.Cerebro(stdstats=False)
现在图表不同了。
访问观察者
如上所述,观察者已经存在于默认情况下,并且收集的信息可以用于统计目的,这就是为什么可以通过策略的属性来访问观察者的原因:
stats
它只是一个占位符。如果我们回忆一下如何添加默认观察者的过程:
...
cerebro.addobserver(backtrader.observers.Broker)
...
显而易见的问题是如何访问Broker观察者。以下是一个示例,展示了如何从策略的next方法中执行:
class MyStrategy(bt.Strategy):
def next(self):
if self.stats.broker.value[0] < 1000.0:
print('WHITE FLAG ... I LOST TOO MUCH')
elif self.stats.broker.value[0] > 10000000.0:
print('TIME FOR THE VIRGIN ISLANDS ....!!!')
Broker观察者就像数据、指标和策略本身一样也是Lines对象。在这种情况下,Broker有 2 行:
-
cash -
value
观察者实现
实现与指标的非常相似:
class Broker(Observer):
alias = ('CashValue',)
lines = ('cash', 'value')
plotinfo = dict(plot=True, subplot=True)
def next(self):
self.lines.cash[0] = self._owner.broker.getcash()
self.lines.value[0] = value = self._owner.broker.getvalue()
步骤:
-
派生自
Observer(而不是Indicator) -
根据需要声明行和参数(
Broker有 2 行但没有参数) -
将会有一个自动属性
_owner,它是持有观察者的策略
观察者开始行动:
-
所有指标计算完成后
-
在策略的
next方法执行后 -
这意味着:在周期结束时……它们观察发生了什么
在Broker情况下,它只是盲目地记录经纪人现金和组合价值在每个时间点的情况。
将观察者添加到策略中
正如上面已经指出的,Cerebro使用stdstats参数来决定是否添加 3 个默认观察者,减轻了最终用户的工作。
可以将其他观察者添加到混合中,无论是沿着stdstats还是移除它们。
让我们继续使用通常的策略,当close价格超过SimpleMovingAverage时购买,如果相反则卖出。
有一个“添加”:
- DrawDown是
backtrader生态系统中已经存在的观察者
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import os.path
import time
import sys
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class MyStrategy(bt.Strategy):
params = (('smaperiod', 15),)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.data.datetime[0]
if isinstance(dt, float):
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
# SimpleMovingAverage on main data
# Equivalent to -> sma = btind.SMA(self.data, period=self.p.smaperiod)
sma = btind.SMA(period=self.p.smaperiod)
# CrossOver (1: up, -1: down) close / sma
self.buysell = btind.CrossOver(self.data.close, sma, plot=True)
# Sentinel to None: new ordersa allowed
self.order = None
def next(self):
# Access -1, because drawdown[0] will be calculated after "next"
self.log('DrawDown: %.2f' % self.stats.drawdown.drawdown[-1])
self.log('MaxDrawDown: %.2f' % self.stats.drawdown.maxdrawdown[-1])
# Check if we are in the market
if self.position:
if self.buysell < 0:
self.log('SELL CREATE, %.2f' % self.data.close[0])
self.sell()
elif self.buysell > 0:
self.log('BUY CREATE, %.2f' % self.data.close[0])
self.buy()
def runstrat():
cerebro = bt.Cerebro()
data = bt.feeds.BacktraderCSVData(dataname='../../datas/2006-day-001.txt')
cerebro.adddata(data)
cerebro.addobserver(bt.observers.DrawDown)
cerebro.addstrategy(MyStrategy)
cerebro.run()
cerebro.plot()
if __name__ == '__main__':
runstrat()
视觉输出显示了回撤的演变
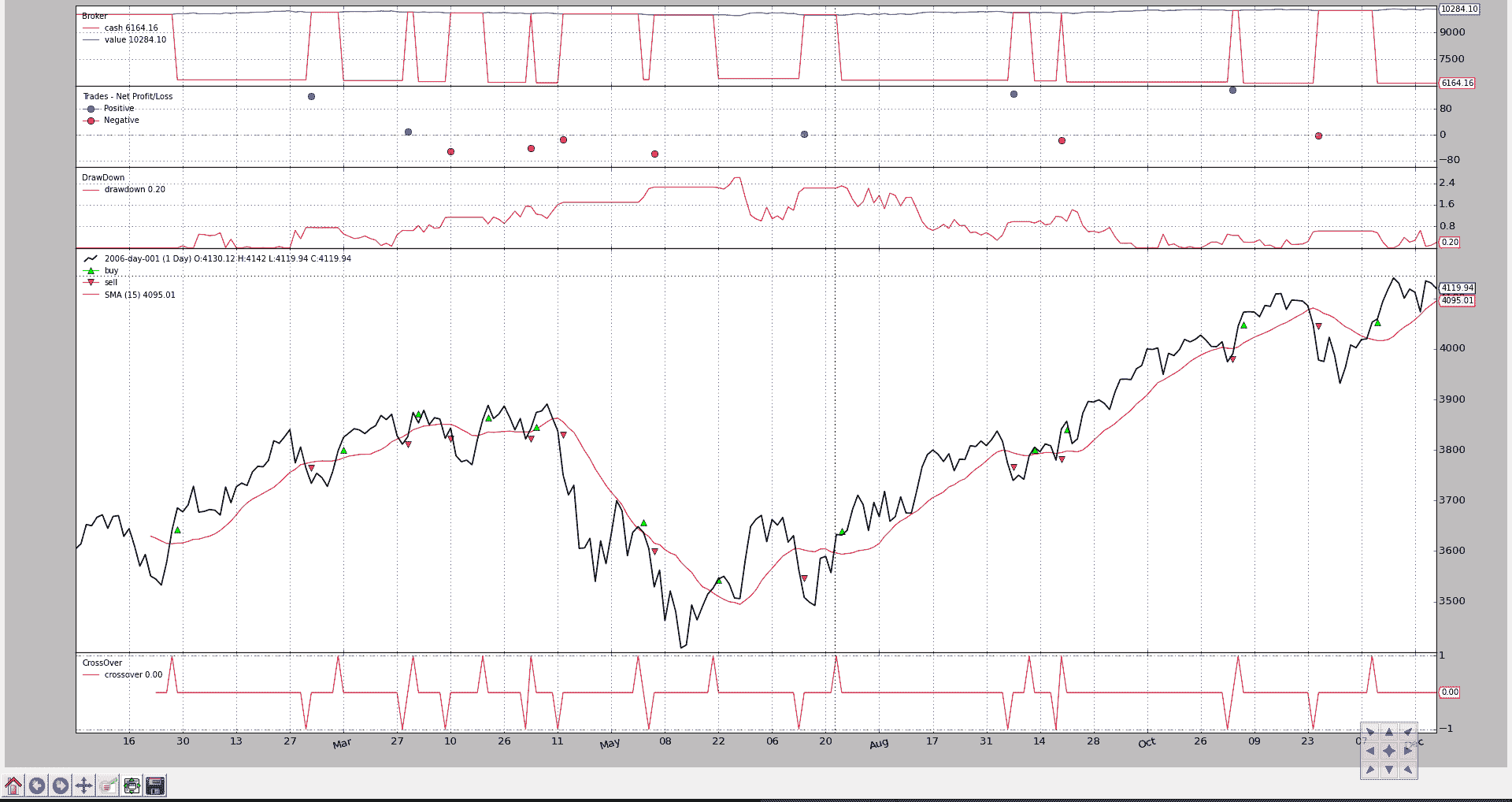
文本输出的一部分:
...
2006-12-14T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-15T23:59:59+00:00, DrawDown: 0.22
2006-12-15T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-18T23:59:59+00:00, DrawDown: 0.00
2006-12-18T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-19T23:59:59+00:00, DrawDown: 0.00
2006-12-19T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-20T23:59:59+00:00, DrawDown: 0.10
2006-12-20T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-21T23:59:59+00:00, DrawDown: 0.39
2006-12-21T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-22T23:59:59+00:00, DrawDown: 0.21
2006-12-22T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-27T23:59:59+00:00, DrawDown: 0.28
2006-12-27T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-28T23:59:59+00:00, DrawDown: 0.65
2006-12-28T23:59:59+00:00, MaxDrawDown: 2.62
2006-12-29T23:59:59+00:00, DrawDown: 0.06
2006-12-29T23:59:59+00:00, MaxDrawDown: 2.62
注意
如文本输出和代码中所见,DrawDown观察者实际上有 2 条线:
-
drawdown -
maxdrawdown
选择不绘制maxdrawdown线,但仍然使其对用户可用。
实际上,maxdrawdown的最后一个值也可以通过名为maxdd的直接属性(而不是一条线)获得。
开发观察者
上面展示了Broker观察者的实现。为了生成一个有意义的观察者,实现可以使用以下信息:
-
self._owner是当前正在执行的策略因此,策略内的任何内容都可以供观察者使用
-
策略中可用的默认内部内容可能会有用:
broker-> 属性,提供对策略创建订单的经纪人实例的访问
如在
Broker中所见,现金和投资组合价值是通过调用getcash和getvalue方法收集的_orderspending-> 策略创建的订单列表,经纪人已通知策略的事件。
BuySell观察者遍历列表,查找已执行(完全或部分)的订单,以创建给定时间点(索引 0)的平均执行价格_tradespending-> 交易列表(一组已完成的买入/卖出或卖出/买入对),从买入/卖出订单中编制
一个观察者显然可以通过self._owner.stats路径访问其他观察者。
自定义OrderObserver
标准的BuySell观察者只关心已执行的操作。我们可以创建一个观察者,显示订单何时被创建以及它们是否已过期。
为了可见性,显示将不会沿着价格绘制,而是在单独的轴上。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import math
import backtrader as bt
class OrderObserver(bt.observer.Observer):
lines = ('created', 'expired',)
plotinfo = dict(plot=True, subplot=True, plotlinelabels=True)
plotlines = dict(
created=dict(marker='*', markersize=8.0, color='lime', fillstyle='full'),
expired=dict(marker='s', markersize=8.0, color='red', fillstyle='full')
)
def next(self):
for order in self._owner._orderspending:
if order.data is not self.data:
continue
if not order.isbuy():
continue
# Only interested in "buy" orders, because the sell orders
# in the strategy are Market orders and will be immediately
# executed
if order.status in [bt.Order.Accepted, bt.Order.Submitted]:
self.lines.created[0] = order.created.price
elif order.status in [bt.Order.Expired]:
self.lines.expired[0] = order.created.price
自定义观察者只关心买入订单,因为这是一个只买入以试图获利的策略。卖出订单是市价订单,将立即执行。
Close-SMA CrossOver 策略已更改为:
-
在信号时刻的收盘价以下 1.0%的价格创建一个限价单
-
订单的有效期为 7(日历)天
结果图表。
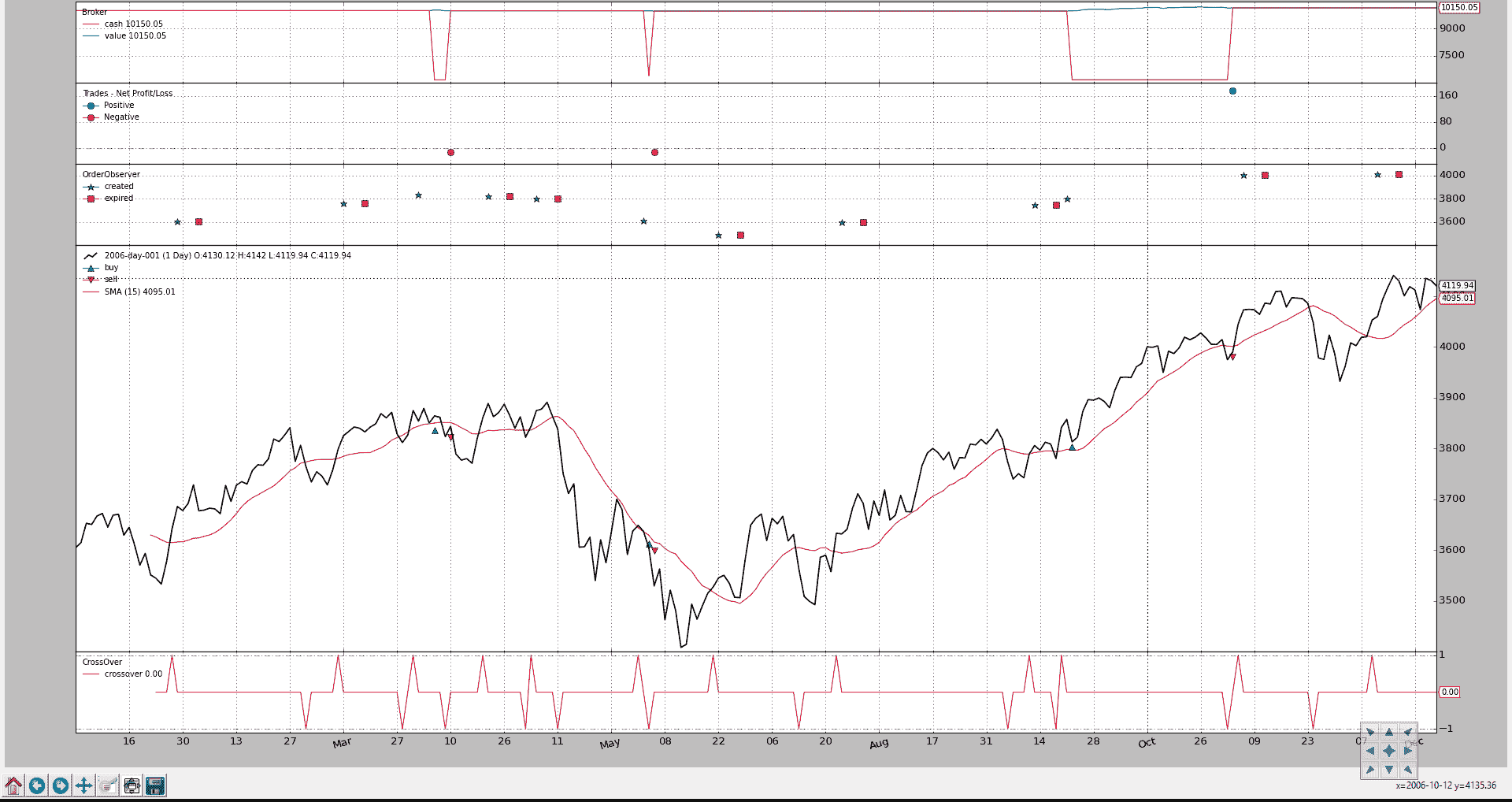
如在新的子图表(红色方块)中所见,几个订单已经过期,我们还可以看到在“创建”和“执行”之间有几天发生。
最终应用新的观察者的策略代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
from orderobserver import OrderObserver
class MyStrategy(bt.Strategy):
params = (
('smaperiod', 15),
('limitperc', 1.0),
('valid', 7),
)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.data.datetime[0]
if isinstance(dt, float):
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
# Buy/Sell order submitted/accepted to/by broker - Nothing to do
self.log('ORDER ACCEPTED/SUBMITTED', dt=order.created.dt)
self.order = order
return
if order.status in [order.Expired]:
self.log('BUY EXPIRED')
elif order.status in [order.Completed]:
if order.isbuy():
self.log(
'BUY EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
else: # Sell
self.log('SELL EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
# Sentinel to None: new orders allowed
self.order = None
def __init__(self):
# SimpleMovingAverage on main data
# Equivalent to -> sma = btind.SMA(self.data, period=self.p.smaperiod)
sma = btind.SMA(period=self.p.smaperiod)
# CrossOver (1: up, -1: down) close / sma
self.buysell = btind.CrossOver(self.data.close, sma, plot=True)
# Sentinel to None: new ordersa allowed
self.order = None
def next(self):
if self.order:
# pending order ... do nothing
return
# Check if we are in the market
if self.position:
if self.buysell < 0:
self.log('SELL CREATE, %.2f' % self.data.close[0])
self.sell()
elif self.buysell > 0:
plimit = self.data.close[0] * (1.0 - self.p.limitperc / 100.0)
valid = self.data.datetime.date(0) + \
datetime.timedelta(days=self.p.valid)
self.log('BUY CREATE, %.2f' % plimit)
self.buy(exectype=bt.Order.Limit, price=plimit, valid=valid)
def runstrat():
cerebro = bt.Cerebro()
data = bt.feeds.BacktraderCSVData(dataname='../../datas/2006-day-001.txt')
cerebro.adddata(data)
cerebro.addobserver(OrderObserver)
cerebro.addstrategy(MyStrategy)
cerebro.run()
cerebro.plot()
if __name__ == '__main__':
runstrat()
保存/保留统计信息
截至目前,backtrader尚未实施任何机制来跟踪观察者的值并将其存储到文件中。最佳方法是:
-
在策略的
start方法中打开文件 -
在策略的
next方法中写下数值
考虑到DrawDown观察者,可以这样做
class MyStrategy(bt.Strategy):
def start(self):
self.mystats = open('mystats.csv', 'wb')
self.mystats.write('datetime,drawdown, maxdrawdown\n')
def next(self):
self.mystats.write(self.data.datetime.date(0).strftime('%Y-%m-%d'))
self.mystats.write(',%.2f' % self.stats.drawdown.drawdown[-1])
self.mystats.write(',%.2f' % self.stats.drawdown.maxdrawdown-1])
self.mystats.write('\n')
要保存索引 0 的值,一旦所有观察者都被处理,可以添加一个自定义观察者作为系统的最后一个观察者,将值保存到 csv 文件中。
注意
Writer 功能可以自动化这个任务。