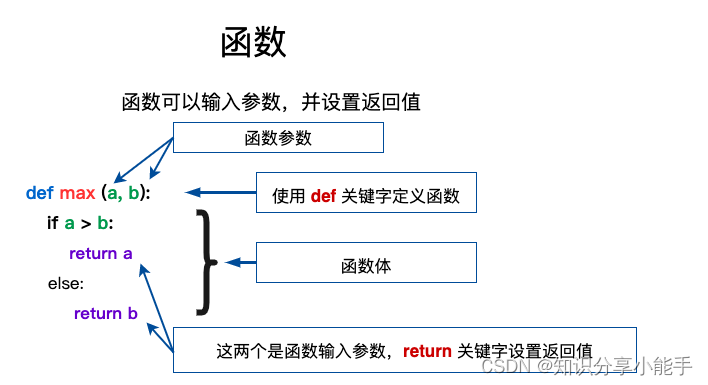
第1关:什么是决策树
任务描述
本关任务:根据本节课所学知识完成本关所设置的选择题。
第2关:信息熵与信息增益
任务描述
本关任务:掌握什么是信息增益,完成计算信息增益的程序设计。
import numpy as np
def calcInfoGain(feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
#*********** Begin ***********#
def total_cal(label):
label_set = set(label)
result = 0
for i in label_set:
p=list(label).count(i)/len(label)
result-=p * np.log2(p)
return result
aba=[]
length=[]
for value in set(feature[:,index]):
# num=feature[:,index].count(value)
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
sub_label.append(label[i])
aba.append(total_cal(sub_label))
length.append(len(sub_label)/len(label))
res=total_cal(label)-length[0]*aba[0]-length[1]*aba[1]
return res
#*********** End *************#
第3关:使用ID3算法构建决策树
任务描述
本关任务:补充python代码,完成DecisionTree类中的fit和predict函数。
import numpy as np
class DecisionTree(object):
def __init__(self):
#决策树模型
self.tree = {}
def calcInfoGain(self, feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
# 计算熵
def calcInfoEntropy(label):
'''
计算信息熵
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
label_set = set(label)
result = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算标签在数据集中出现的概率
p = count / len(label)
# 计算熵
result -= p * np.log2(p)
return result
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
count = 0
# sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_feature.append(feature[i])
sub_label.append(label[i])
pHA = count / len(feature)
e = calcInfoEntropy(sub_label)
return pHA * e
base_e = calcInfoEntropy(label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
return base_e - sum_HDA
# 获得信息增益最高的特征
def getBestFeature(self, feature, label):
max_infogain = 0
best_feature = 0
for i in range(len(feature[0])):
infogain = self.calcInfoGain(feature, label, i)
if infogain > max_infogain:
max_infogain = infogain
best_feature = i
return best_feature
def createTree(self, feature, label):
# 样本里都是同一个label没必要继续分叉了
if len(set(label)) == 1:
return label[0]
# 样本中只有一个特征或者所有样本的特征都一样的话就看哪个label的票数高
if len(feature[0]) == 1 or len(np.unique(feature, axis=0)) == 1:
vote = {}
for l in label:
if l in vote.keys():
vote[l] += 1
else:
vote[l] = 1
max_count = 0
vote_label = None
for k, v in vote.items():
if v > max_count:
max_count = v
vote_label = k
return vote_label
# 根据信息增益拿到特征的索引
best_feature = self.getBestFeature(feature, label)
tree = {best_feature: {}}
f = np.array(feature)
# 拿到bestfeature的所有特征值
f_set = set(f[:, best_feature])
# 构建对应特征值的子样本集sub_feature, sub_label
for v in f_set:
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][best_feature] == v:
sub_feature.append(feature[i])
sub_label.append(label[i])
# 递归构建决策树
tree[best_feature][v] = self.createTree(sub_feature, sub_label)
return tree
def fit(self, feature, label):
'''
:param feature: 训练集数据,类型为ndarray
:param label:训练集标签,类型为ndarray
:return: None
'''
#************* Begin ************#
self.tree = self.createTree(feature, label)
#************* End **************#
def predict(self, feature):
'''
:param feature:测试集数据,类型为ndarray
:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])
'''
#************* Begin ************#
result = []
def classify(tree, feature):
if not isinstance(tree, dict):
return tree
t_index, t_value = list(tree.items())[0]
f_value = feature[t_index]
if isinstance(t_value, dict):
classLabel = classify(tree[t_index][f_value], feature)
return classLabel
else:
return t_value
for f in feature:
result.append(classify(self.tree, f))
return np.array(result)
#************* End **************#
第4关:信息增益率
任务描述
本关任务:根据本关所学知识,完成calcInfoGainRatio函数。
import numpy as np
def calcInfoGain(feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
# 计算熵
def calcInfoEntropy(label):
'''
计算信息熵
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
label_set = set(label)
result = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算标签在数据集中出现的概率
p = count / len(label)
# 计算熵
result -= p * np.log2(p)
return result
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
count = 0
# sub_label表示根据特征列和特征值分割出的子数据集中的标签
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_label.append(label[i])
pHA = count / len(feature)
e = calcInfoEntropy(sub_label)
return pHA * e
base_e = calcInfoEntropy(label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
return base_e - sum_HDA
def calcInfoGainRatio(feature, label, index):
'''
计算信息增益率
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益率,类型float
'''
#********* Begin *********#
info_gain = calcInfoGain(feature, label, index)
unique_value = list(set(feature[:, index]))
IV = 0
for value in unique_value:
len_v = np.sum(feature[:, index] == value)
IV -= (len_v/len(feature))*np.log2((len_v/len(feature)))
return info_gain/IV
#********* End *********#
第5关:基尼系数
任务描述
本关任务:根据本关所学知识,完成calcGini函数。
import numpy as np
def calcGini(feature, label, index):
'''
计算基尼系数
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:基尼系数,类型float
'''
#********* Begin *********#
def _gini(label):
unique_label = list(set(label))
gini = 1
for l in unique_label:
p = np.sum(label == l)/len(label)
gini -= p**2
return gini
unique_value = list(set(feature[:, index]))
gini = 0
for value in unique_value:
len_v = np.sum(feature[:, index] == value)
gini += (len_v/len(feature))*_gini(label[feature[:, index] == value])
return gini
#********* End *********#
第6关:预剪枝与后剪枝
任务描述
本关任务:补充python代码,完成DecisionTree类中的fit和predict函数。
import numpy as np
from copy import deepcopy
class DecisionTree(object):
def __init__(self):
#决策树模型
self.tree = {}
def calcInfoGain(self, feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature,类型为ndarray
:param label:测试用例中字典里的label,类型为ndarray
:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
:return:信息增益,类型float
'''
# 计算熵
def calcInfoEntropy(feature, label):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
label_set = set(label)
result = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算标签在数据集中出现的概率
p = count / len(label)
# 计算熵
result -= p * np.log2(p)
return result
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
count = 0
# sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_feature.append(feature[i])
sub_label.append(label[i])
pHA = count / len(feature)
e = calcInfoEntropy(sub_feature, sub_label)
return pHA * e
base_e = calcInfoEntropy(feature, label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
return base_e - sum_HDA
# 获得信息增益最高的特征
def getBestFeature(self, feature, label):
max_infogain = 0
best_feature = 0
for i in range(len(feature[0])):
infogain = self.calcInfoGain(feature, label, i)
if infogain > max_infogain:
max_infogain = infogain
best_feature = i
return best_feature
# 计算验证集准确率
def calc_acc_val(self, the_tree, val_feature, val_label):
result = []
def classify(tree, feature):
if not isinstance(tree, dict):
return tree
t_index, t_value = list(tree.items())[0]
f_value = feature[t_index]
if isinstance(t_value, dict):
classLabel = classify(tree[t_index][f_value], feature)
return classLabel
else:
return t_value
for f in val_feature:
result.append(classify(the_tree, f))
result = np.array(result)
return np.mean(result == val_label)
def createTree(self, train_feature, train_label):
# 样本里都是同一个label没必要继续分叉了
if len(set(train_label)) == 1:
return train_label[0]
# 样本中只有一个特征或者所有样本的特征都一样的话就看哪个label的票数高
if len(train_feature[0]) == 1 or len(np.unique(train_feature, axis=0)) == 1:
vote = {}
for l in train_label:
if l in vote.keys():
vote[l] += 1
else:
vote[l] = 1
max_count = 0
vote_label = None
for k, v in vote.items():
if v > max_count:
max_count = v
vote_label = k
return vote_label
# 根据信息增益拿到特征的索引
best_feature = self.getBestFeature(train_feature, train_label)
tree = {best_feature: {}}
f = np.array(train_feature)
# 拿到bestfeature的所有特征值
f_set = set(f[:, best_feature])
# 构建对应特征值的子样本集sub_feature, sub_label
for v in f_set:
sub_feature = []
sub_label = []
for i in range(len(train_feature)):
if train_feature[i][best_feature] == v:
sub_feature.append(train_feature[i])
sub_label.append(train_label[i])
# 递归构建决策树
tree[best_feature][v] = self.createTree(sub_feature, sub_label)
return tree
# 后剪枝
def post_cut(self, val_feature, val_label):
# 拿到非叶子节点的数量
def get_non_leaf_node_count(tree):
non_leaf_node_path = []
def dfs(tree, path, all_path):
for k in tree.keys():
if isinstance(tree[k], dict):
path.append(k)
dfs(tree[k], path, all_path)
if len(path) > 0:
path.pop()
else:
all_path.append(path[:])
dfs(tree, [], non_leaf_node_path)
unique_non_leaf_node = []
for path in non_leaf_node_path:
isFind = False
for p in unique_non_leaf_node:
if path == p:
isFind = True
break
if not isFind:
unique_non_leaf_node.append(path)
return len(unique_non_leaf_node)
# 拿到树中深度最深的从根节点到非叶子节点的路径
def get_the_most_deep_path(tree):
non_leaf_node_path = []
def dfs(tree, path, all_path):
for k in tree.keys():
if isinstance(tree[k], dict):
path.append(k)
dfs(tree[k], path, all_path)
if len(path) > 0:
path.pop()
else:
all_path.append(path[:])
dfs(tree, [], non_leaf_node_path)
max_depth = 0
result = None
for path in non_leaf_node_path:
if len(path) > max_depth:
max_depth = len(path)
result = path
return result
# 剪枝
def set_vote_label(tree, path, label):
for i in range(len(path)-1):
tree = tree[path[i]]
tree[path[len(path)-1]] = vote_label
acc_before_cut = self.calc_acc_val(self.tree, val_feature, val_label)
# 遍历所有非叶子节点
for _ in range(get_non_leaf_node_count(self.tree)):
path = get_the_most_deep_path(self.tree)
# 备份树
tree = deepcopy(self.tree)
step = deepcopy(tree)
# 跟着路径走
for k in path:
step = step[k]
# 叶子节点中票数最多的标签
vote_label = sorted(step.items(), key=lambda item: item[1], reverse=True)[0][0]
# 在备份的树上剪枝
set_vote_label(tree, path, vote_label)
acc_after_cut = self.calc_acc_val(tree, val_feature, val_label)
# 验证集准确率高于0.9才剪枝
if acc_after_cut > acc_before_cut:
set_vote_label(self.tree, path, vote_label)
acc_before_cut = acc_after_cut
def fit(self, train_feature, train_label, val_feature, val_label):
'''
:param train_feature:训练集数据,类型为ndarray
:param train_label:训练集标签,类型为ndarray
:param val_feature:验证集数据,类型为ndarray
:param val_label:验证集标签,类型为ndarray
:return: None
'''
#************* Begin ************#
self.tree = self.createTree(train_feature, train_label)
# 后剪枝
self.post_cut(val_feature, val_label)
#************* End **************#
def predict(self, feature):
'''
:param feature:测试集数据,类型为ndarray
:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])
'''
#************* Begin ************#
result = []
# 单个样本分类
def classify(tree, feature):
if not isinstance(tree, dict):
return tree
t_index, t_value = list(tree.items())[0]
f_value = feature[t_index]
if isinstance(t_value, dict):
classLabel = classify(tree[t_index][f_value], feature)
return classLabel
else:
return t_value
for f in feature:
result.append(classify(self.tree, f))
return np.array(result)
#************* End **************#
# 第7关:鸢尾花识别
## 任务描述
本关任务:使用sklearn完成鸢尾花分类任务。
```python
#********* Begin *********#
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
train_df = pd.read_csv('./step7/train_data.csv').as_matrix()
train_label = pd.read_csv('./step7/train_label.csv').as_matrix()
test_df = pd.read_csv('./step7/test_data.csv').as_matrix()
dt = DecisionTreeClassifier()
dt.fit(train_df, train_label)
result = dt.predict(test_df)
result = pd.DataFrame({'target':result})
result.to_csv('./step7/predict.csv', index=False)
#********* End *********#