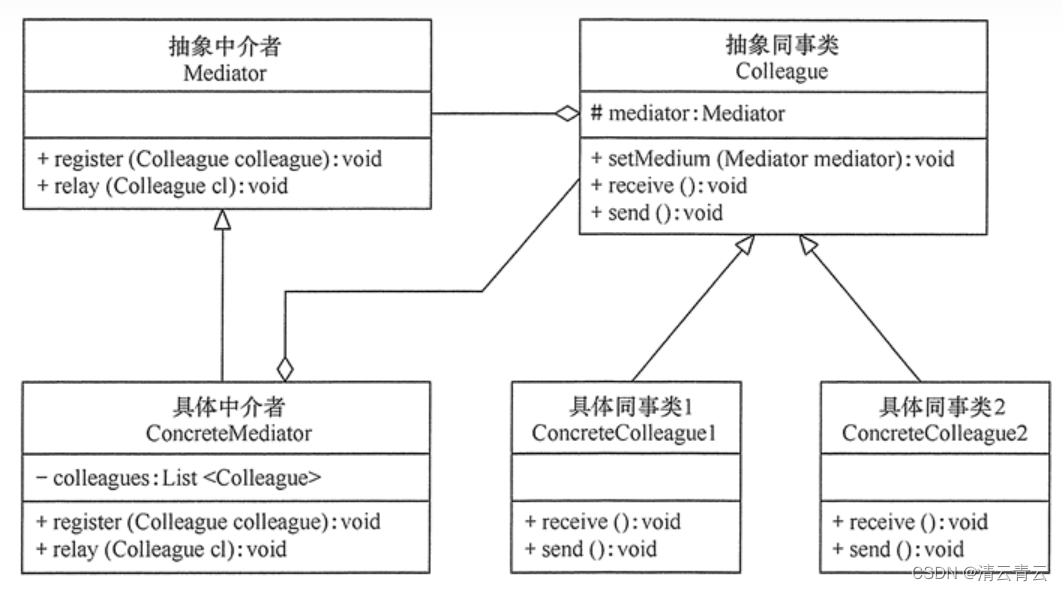
数据结构
单值二叉树
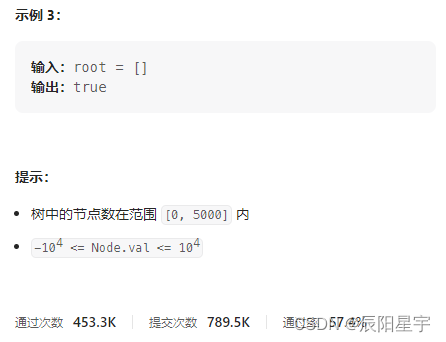
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。只有给定的树是单值二叉树时,才返回 true;否则返回 false。
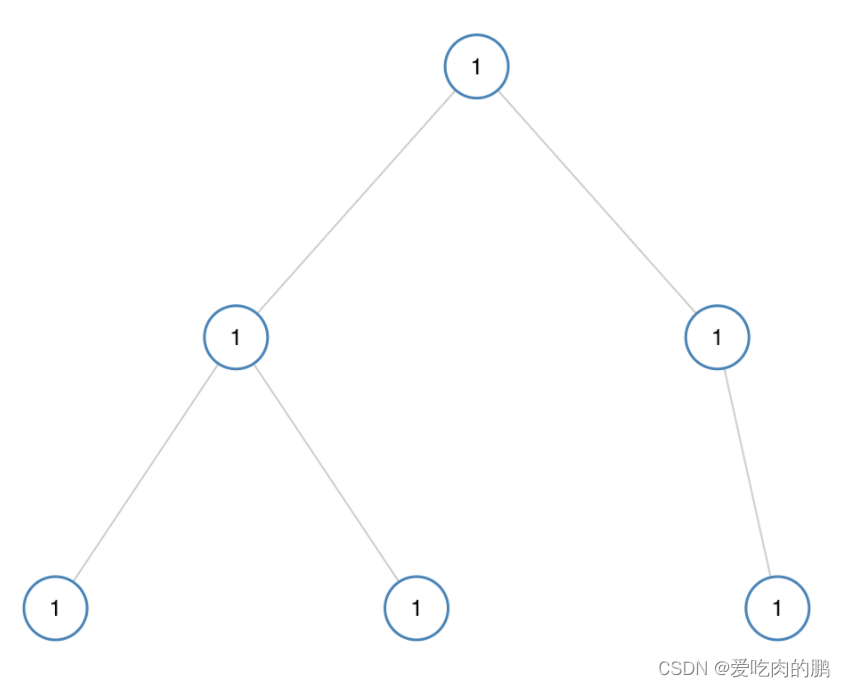
类似上述图中,所有结点都为1,那么返回true,只要有一个结点不一样就返回false。
思路:深度优先搜索
思路与算法
一棵树的所有节点都有相同的值,对于树上的每一条边的两个端点,它们都有相同的值(这样根据传递性,所有节点都有相同的值)。
因此,我们可以对树进行一次深度优先搜索。当搜索到节点 xx 时,我们检查 xx 与 xx 的每一个子节点之间的边是否满足要求。例如对于左子节点而言,如果其存在并且值与 xx 相同,那么我们继续向下搜索该左子节点;如果值与 xx 不同,那么我们直接返回 False。
C++
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
class Solution
{
public:
bool isUnivalTree(TreeNode* root)
{
if(!root)
{
return true;
}
if(root->left)
{
if(root->val != root->left->val || !isUnivalTree(root->left))
{
return false;
}
}
if(root->right)
{
if(root->val != root->right->val || !isUnivalTree(root->right))
{
return false;
}
}
return true;
}
}python
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def isUnivalTree(self, root: TreeNode) -> bool:
if not root:
return True
if root.left:
if root.val != root.left.val or not self.isUnivalTree(root.left):
return False
if root.right:
if root.val != root.right.val or not self.isUnivalTree(root.right):
return False
return True
算法
无重复字符的最长字串
给定一个字符串 s ,请找出其中不含有重复字符的 最长子串 的长度。
输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是"abc",所以其长度为 3。
滑动窗口法
思路和算法
以字符串 abcabcbb 为例,找出从每一个字符开始的,不包含重复字符的最长子串,那么其中最长的那个字符串即为答案。对于示例字符串,列举出这些结果,其中括号中表示选中的字符以及最长的字符串:
以 (a)bcabcbb 开始的最长字符串为 (abc)abcbb;
以 a(b)cabcbb 开始的最长字符串为 a(bca)bcbb;
以 ab(c)abcbb 开始的最长字符串为 ab(cab)cbb;
以 abc(a)bcbb 开始的最长字符串为 abc(abc)bb;
以 abca(b)cbb 开始的最长字符串为 abca(bc)bb;
以 abcab(c)bb 开始的最长字符串为 abcab(cb)b;
以 abcabc(b)b 开始的最长字符串为 abcabc(b)b;
以 abcabcb(b) 开始的最长字符串为 abcabcb(b)。
发现了什么?如果我们依次递增地枚举子串的起始位置,那么子串的结束位置也是递增的!这里的原因在于,假设我们选择字符串中的第 k 个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 r_kr 。那么当我们选择第 k+1 个字符作为起始位置时,首先从k+1 到 r k的字符显然是不重复的,并且由于少了原本的第 k 个字符,我们可以尝试继续增大 r_k,直到右侧出现了重复字符为止。这样一来,我们就可以使用「滑动窗口」来解决这个问题了:我们使用两个指针表示字符串中的某个子串(或窗口)的左右边界,其中左指针代表着上文中「枚举子串的起始位置」,而右指针即为上文中的 r_k
在每一步的操作中,我们会将左指针向右移动一格,表示 我们开始枚举下一个字符作为起始位置,然后我们可以不断地向右移动右指针,但需要保证这两个指针对应的子串中没有重复的字符。在移动结束后,这个子串就对应着 以左指针开始的,不包含重复字符的最长子串。我们记录下这个子串的长度;
在枚举结束后,我们找到的最长的子串的长度即为答案。
判断重复字符
在上面的流程中,我们还需要使用一种数据结构来判断 是否有重复的字符,常用的数据结构为哈希集合(即 C++ 中的 std::unordered_set,Java 中的 HashSet,Python 中的 set, JavaScript 中的 Set)。在左指针向右移动的时候,我们从哈希集合中移除一个字符,在右指针向右移动的时候,我们往哈希集合中添加一个字符。
链接:https://leetcode.cn/problems/longest-substring-without-repeating-characters/solution/wu-zhong-fu-zi-fu-de-zui-chang-zi-chuan-by-leetc-2/
C++
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// 哈希集合,记录每个字符是否出现过
unordered_set<char> occ;
int n = s.size();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int rk = -1, ans = 0;
// 枚举左指针的位置,初始值隐性地表示为 -1
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 左指针向右移动一格,移除一个字符
occ.erase(s[i - 1]);
}
while (rk + 1 < n && !occ.count(s[rk + 1])) {
// 不断地移动右指针
occ.insert(s[rk + 1]);
++rk;
}
// 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = max(ans, rk - i + 1);
}
return ans;
}
};
python
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 哈希集合,记录每个字符是否出现过
occ = set()
n = len(s)
# 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
rk, ans = -1, 0
for i in range(n):
if i != 0:
# 左指针向右移动一格,移除一个字符
occ.remove(s[i - 1])
while rk + 1 < n and s[rk + 1] not in occ:
# 不断地移动右指针
occ.add(s[rk + 1])
rk += 1
# 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = max(ans, rk - i + 1)
return ans寻找最长公共前缀:
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
prefix, count = strs[0], len(strs)
for i in range(1, count):
prefix = self.lcp(prefix, strs[i])
if not prefix:
break
return prefix
def lcp(self, str1, str2):
length, index = min(len(str1), len(str2)), 0
while index < length and str1[index] == str2[index]:
index += 1
return str1[:index]
不定期更新。。。。