1、Kafka 介绍
在使用 Kafka 之前,通常需要先安装和配置 ZooKeeper。ZooKeeper 是 Kafka 的依赖项之一,它用于协调和管理 Kafka 集群的状态。
ZooKeeper 是一个开源的分布式协调服务,它提供了可靠的数据存储和协调机制,用于协调分布式系统中的各个节点。Kafka 使用 ZooKeeper 来存储和管理集群的元数据、配置信息和状态。
2、Kafka 环境搭建
环境:
- Windows11
- Java 1.8 及以上
- Anaconda
- Python10
- Kafka 2.0.2 (kafka-python)
2.1、安装 Python 版本 Kafka
pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simple
至此,Windows 环境下还不能运行 Kafka,一般情况下,程序会提示超时(60ms)等报错。原因是,还需要启动 Kafka 服务。
2.2、启动 Kafka 服务
从 Kafka 官网下下载对应的文件:Apache Kafka 官网下载地址
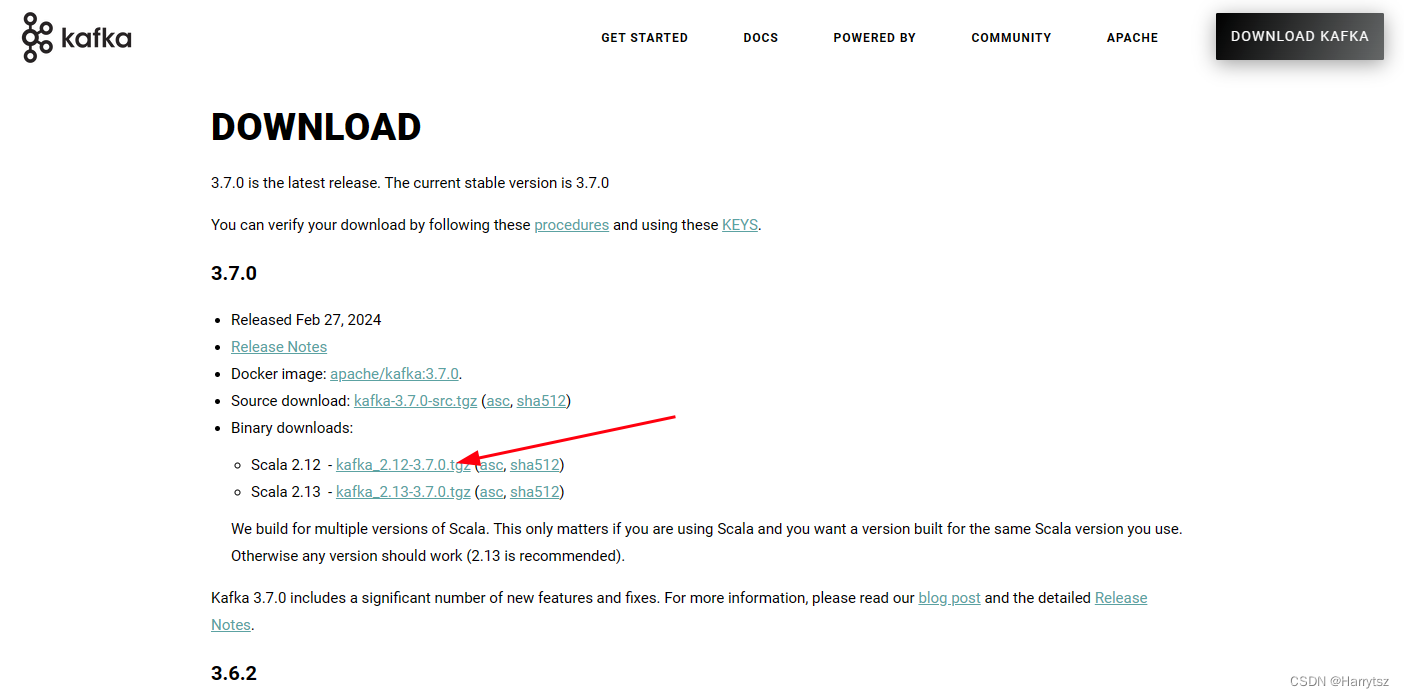
下载红色箭头所指向的文件到本地并解压。
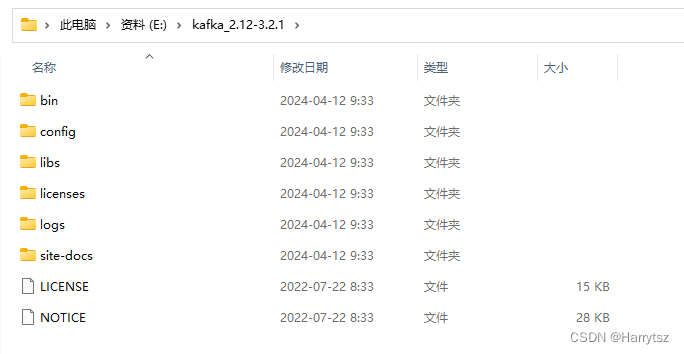
注意:
从 Kafka 官网上下载的 kafka_2.12-3.2.1 文件需要放置在路径较浅文件夹下解压,一旦放置的路径较深,会报错:
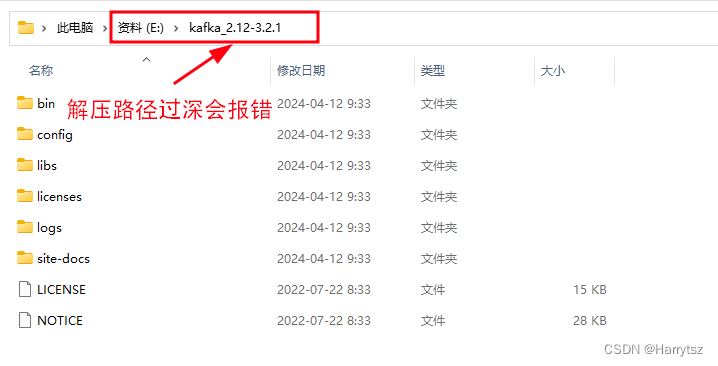
输入行太长。
命令语法不正确。
本案例放在 E 盘下。
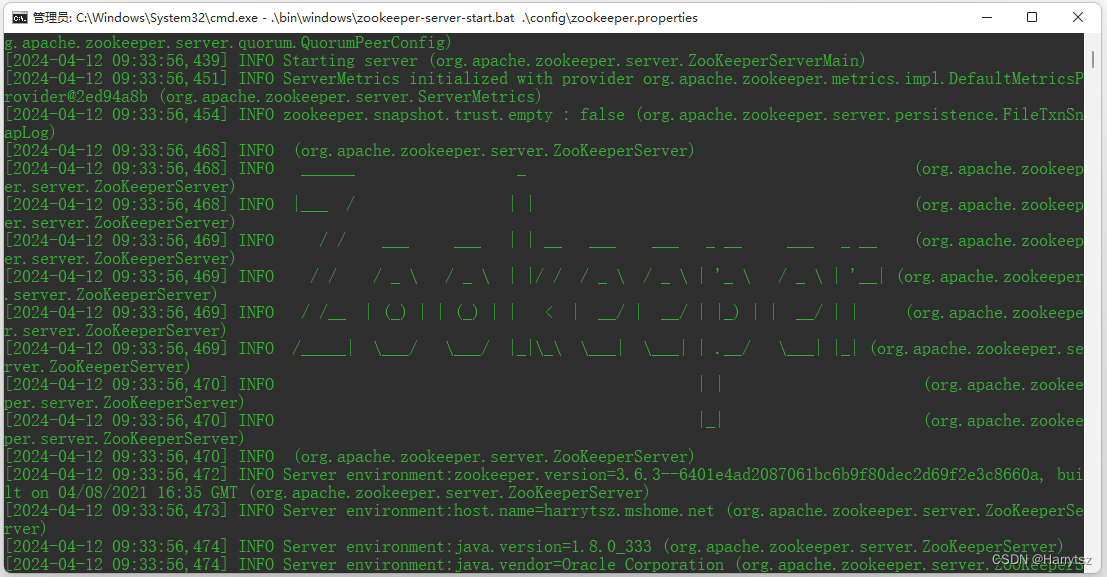
2.2.1、启动 Zookeeper 服务
在上图路径下打开 cmd 命令窗口,执行如下命令:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties

出现如下信息,表示 Zookeeper 服务启动成功:
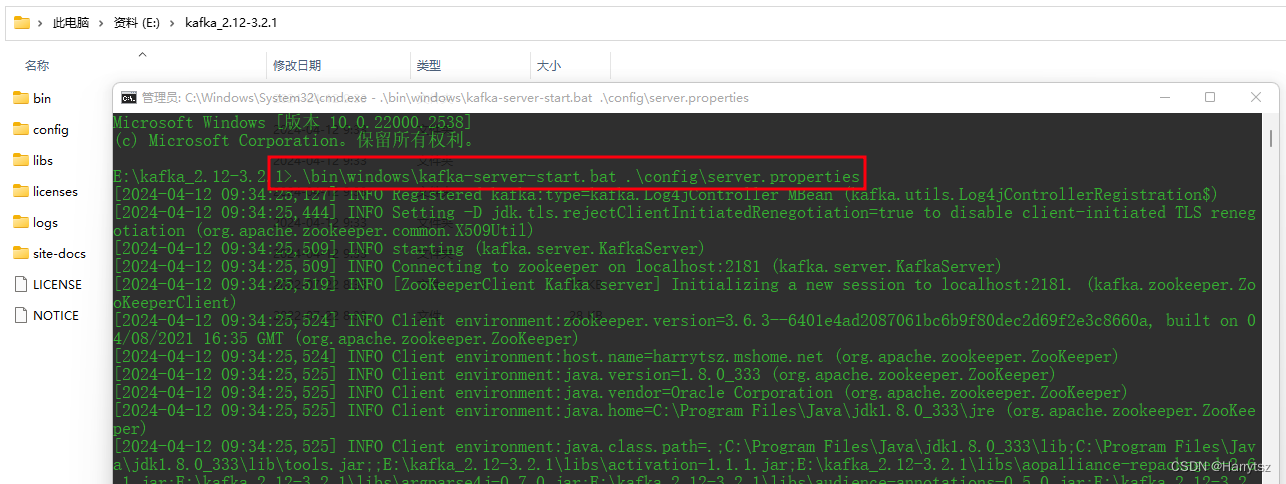
2.2.2、启动 Kafka 服务
在上图路径下打开 cmd 命令窗口,执行如下命令:
.\bin\windows\kafka-server-start.bat .\config\server.properties
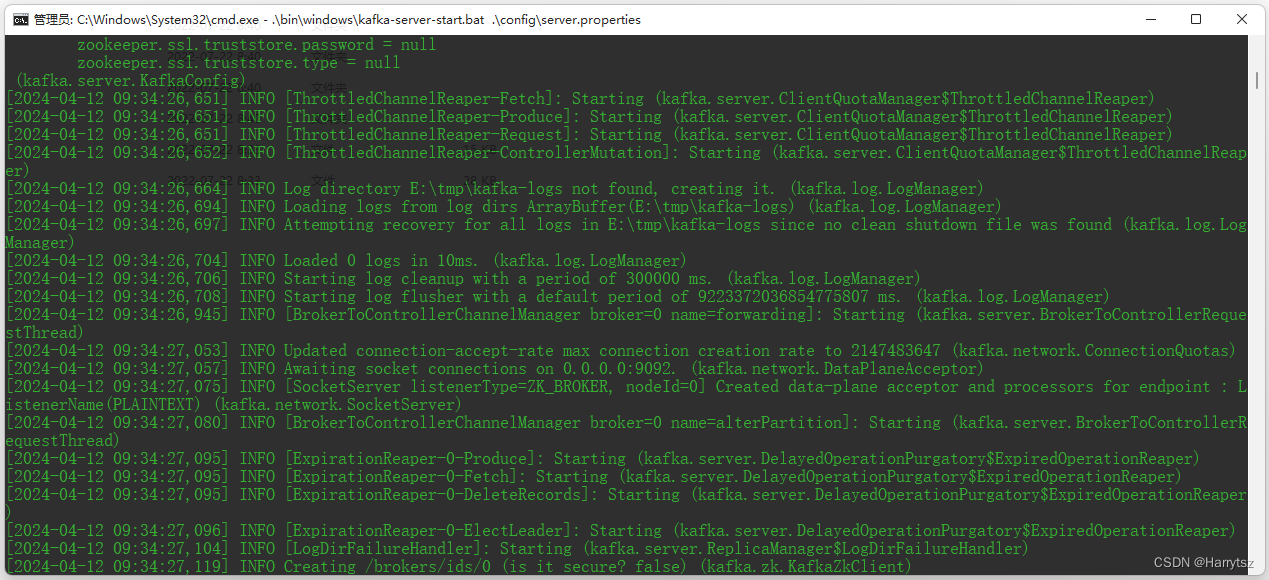
出现如下信息,表示 Kafka 服务启动成功:
3、构建图片传输队列
3.1、配置文件
Properties/config.yaml:
kafka:
host: "127.0.0.1"
port: 9092
parameter:
bootstrap_servers: '127.0.0.1:9092'
api_version: "2.5.0"
log_path: "KafkaLog/log.txt"
workspace:
path: "E:/harrytsz-workspace/harrytsz-python/DistributedSystemDemo00"
input:
images_path: "DataSource/Images"
output:
output_path: "DataSource/Output"
3.2、Kafka 创建分区
KafkaModule/ProducerConsumer/KafkaClient.py:
from kafka.admin import KafkaAdminClient, NewPartitions
client = KafkaAdminClient(bootstrap_servers="127.0.0.1:9092")
# 在已有的 topic 中创建分区
new_partitions = NewPartitions(3)
client.create_partitions({"kafka_demo": new_partitions})
3.3、生产者、消费者(单线程版)
生产者:
KafkaModule/ProducerConsumer/KafkaDemoProducer.py:
# -*- coding: utf-8 -*-
import json
import yaml
import base64
import os.path
import logging
import random
import traceback
from kafka.errors import kafka_errors
from kafka import KafkaProducer
def producer_demo(cfg):
"""
:param cfg:
:return:
"""
# 假设生产的消息为键值对(不是一定要键值对),且序列化方式为json
producer = KafkaProducer(bootstrap_servers=cfg['kafka']['parameter']['bootstrap_servers'],
key_serializer=lambda k: json.dumps(k).encode(),
value_serializer=lambda v: json.dumps(v).encode())
logging.info("Kafka Producer Starting")
images_path = cfg['input']['images_path']
workspace_path = cfg['workspace']['path']
for i, img in enumerate(os.listdir(os.path.join(workspace_path, images_path))):
print(f"img: {img}")
workspace_path = cfg['workspace']['path']
image_path = os.path.join(workspace_path, images_path, img)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
encode_image = base64.b64encode(image_data)
json_data = encode_image.decode("utf-8")
json_string = json.dumps(json_data)
future = producer.send('kafka_demo',
key=str(i), # 同一个key值,会被送至同一个分区
value=json_string,
partition=random.randint(0, 2)) # 向分区1发送消息
producer.flush()
logging.info("Send {}".format(str(i)))
try:
future.get(timeout=10) # 监控是否发送成功
except kafka_errors: # 发送失败抛出 kafka_errors
traceback.format_exc()
def process():
with open(os.path.expanduser("E:/harrytsz-workspace/harrytsz-python/DistributedSystemDemo00/"
"Properties/config.yaml"), "r") as config:
cfg = yaml.safe_load(config)
logging.basicConfig(filename=cfg['kafka']['parameter']['log_path'],
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s - %(funcName)s',
level=logging.INFO)
producer_demo(cfg)
if __name__ == '__main__':
process()
消费者:
KafkaModule/ProducerConsumer/KafkaDemoConsumer.py:
import json
import yaml
import base64
import logging
import os.path
from kafka import KafkaConsumer
def consumer_demo0(cfg):
"""
:param cfg:
:return:
"""
consumer = KafkaConsumer('kafka_demo',
bootstrap_servers=cfg['kafka']['parameter']['bootstrap_servers'],
api_version=cfg['kafka']['parameter']['api_version'],
group_id='test')
logging.info("consumer_demo0 starting")
for message in consumer:
key_json_string = json.loads(message.key.decode())
value_json_string = json.loads(message.value.decode())
name_data = "test0" + key_json_string + ".jpg"
image_data = base64.b64decode(value_json_string)
logging.info(f"Receiving {name_data} data.")
workspace_path = cfg['workspace']['path']
output_path = cfg['output']['output_path']
image_path = os.path.join(workspace_path, output_path, name_data)
with open(image_path, 'wb') as jpg_file:
jpg_file.write(image_data)
logging.info(f"Save {name_data} data finished.")
def process():
"""
:return:
"""
with open(os.path.expanduser("E:/harrytsz-workspace/harrytsz-python/DistributedSystemDemo00/"
"Properties/config.yaml"), "r") as config:
cfg = yaml.safe_load(config)
logging.basicConfig(filename=cfg['kafka']['parameter']['log_path'],
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s - %(funcName)s',
level=logging.INFO)
consumer_demo0(cfg)
if __name__ == '__main__':
process()
3.4、生产者、消费者(线程池版)
生产者:
KafkaModule/ProducerConsumer/KafkaDemoProducerMultiThread.py:
# -*- coding: utf-8 -*-
import json
import yaml
import base64
import os.path
import logging
import random
import traceback
from kafka.errors import kafka_errors
from kafka import KafkaProducer
def producer_demo(cfg):
"""
:param cfg:
:return:
"""
# 假设生产的消息为键值对(不是一定要键值对),且序列化方式为json
producer = KafkaProducer(bootstrap_servers=cfg['kafka']['parameter']['bootstrap_servers'],
key_serializer=lambda k: json.dumps(k).encode(),
value_serializer=lambda v: json.dumps(v).encode())
logging.info("Kafka Producer Starting")
images_path = cfg['input']['images_path']
workspace_path = cfg['workspace']['path']
for i, img in enumerate(os.listdir(os.path.join(workspace_path, images_path))):
print(f"img: {img}")
workspace_path = cfg['workspace']['path']
image_path = os.path.join(workspace_path, images_path, img)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
encode_image = base64.b64encode(image_data)
json_data = encode_image.decode("utf-8")
json_string = json.dumps(json_data)
future = producer.send('kafka_demo',
key=str(i), # 同一个key值,会被送至同一个分区
value=json_string,
partition=random.randint(0, 2)) # 向分区1发送消息
producer.flush()
logging.info("Send {}".format(str(i)))
try:
future.get(timeout=10) # 监控是否发送成功
except kafka_errors: # 发送失败抛出 kafka_errors
traceback.format_exc()
def process():
with open(os.path.expanduser("E:/harrytsz-workspace/harrytsz-python/DistributedSystemDemo00/"
"Properties/config.yaml"), "r") as config:
cfg = yaml.safe_load(config)
logging.basicConfig(filename=cfg['kafka']['parameter']['log_path'],
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s - %(funcName)s',
level=logging.INFO)
producer_demo(cfg)
if __name__ == '__main__':
process()
消费者:
KafkaModule/ProducerConsumer/KafkaDemoConsumerMultiThread.py:
import json
import yaml
import base64
import logging
import os.path
from kafka import KafkaConsumer
from concurrent.futures import ThreadPoolExecutor, as_completed
def consumer_demo0(cfg, thread_id):
""" 线程池版的消费者
:param cfg: 配置文件
:param thread_id: 线程序号
:return:
"""
consumer = KafkaConsumer('kafka_demo',
bootstrap_servers=cfg['kafka']['parameter']['bootstrap_servers'],
api_version=cfg['kafka']['parameter']['api_version'],
group_id='test')
logging.info("consumer_demo0 starting")
for message in consumer:
key_json_string = json.loads(message.key.decode())
value_json_string = json.loads(message.value.decode())
name_data = f"test_{thread_id}_" + key_json_string + ".jpg"
image_data = base64.b64decode(value_json_string)
logging.info(f"Receiving {name_data} data.")
workspace_path = cfg['workspace']['path']
output_path = cfg['output']['output_path']
image_path = os.path.join(workspace_path, output_path, name_data)
with open(image_path, 'wb') as jpg_file:
jpg_file.write(image_data)
logging.info(f"Save {name_data} data finished.")
def process():
"""
:return:
"""
with open(os.path.expanduser("E:/harrytsz-workspace/harrytsz-python/DistributedSystemDemo00/"
"Properties/config.yaml"), "r") as config:
cfg = yaml.safe_load(config)
logging.basicConfig(filename=cfg['kafka']['parameter']['log_path'],
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s - %(funcName)s',
level=logging.INFO)
# 线程池
thread_pool_executor = ThreadPoolExecutor(max_workers=5, thread_name_prefix="thread_test_")
all_task = [thread_pool_executor.submit(consumer_demo0, cfg, i) for i in range(10)]
for future in as_completed(all_task):
res = future.result()
print("res", str(res))
thread_pool_executor.shutdown(wait=True)
if __name__ == '__main__':
process()
运行顺序:
- 首先运行
KafkaDemoConsumer.py或者KafkaDemoConsumerMultiThread.py - 然后运行
KafkaDemoProducer.py或者KafkaDemoProducerMultiThread.py DataSource/Output中会接受生产者发送的图片数据,ProducerConsumer/KafkaLog路径也会产生运行日志。