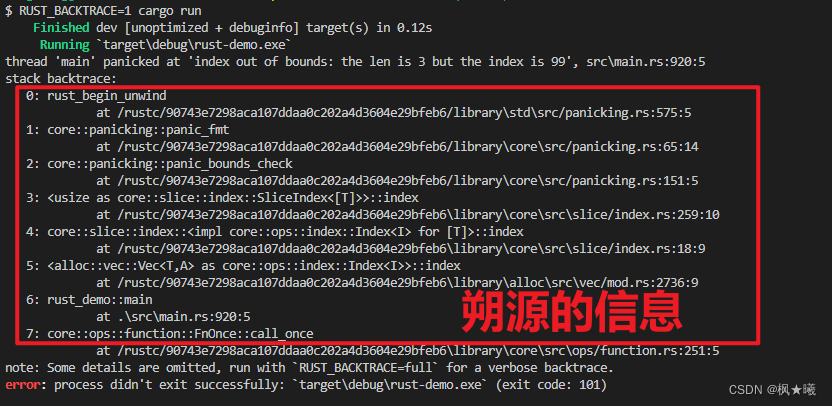
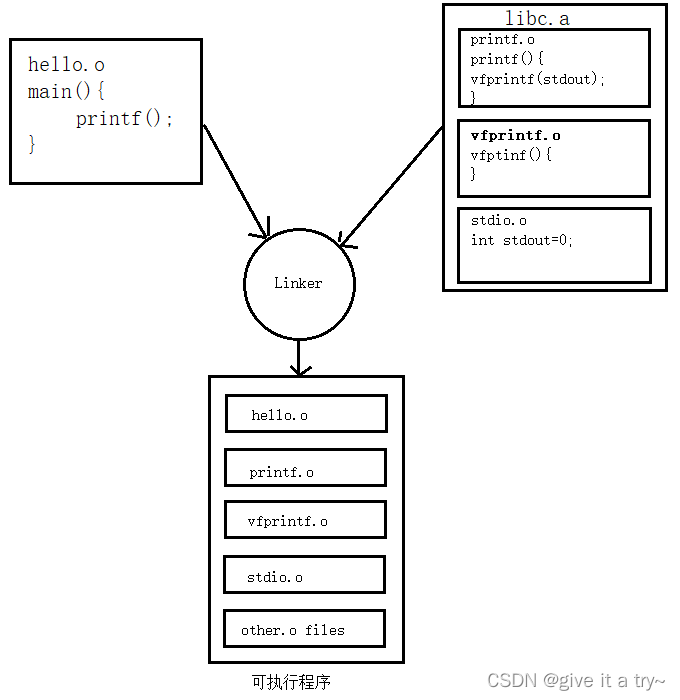
骑电动车不戴头盔识别抓拍系统通过Python基于YOLOv7网络深度学习技术,对现场画面中骑电动车不戴头盔识别抓拍包括骑乘人员和带乘人员。YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器,并在V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。
相对于其他类型的工具,YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于 transformer 的检测器 SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)速度上高出 509%,精度高出 2%,比基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度高出 551%,精度高出 0.7%。
YOLOv7 的发展方向与当前主流的实时目标检测器不同,研究团队希望它能够同时支持移动 GPU 和从边缘到云端的 GPU 设备。除了架构优化之外,该研究提出的方法还专注于训练过程的优化,将重点放在了一些优化模块和优化方法上。这可能会增加训练成本以提高目标检测的准确性,但不会增加推理成本。研究者将提出的模块和优化方法称为可训练的「bag-of-freebies」。
对于模型重参数化,该研究使用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。此外,研究者发现使用动态标签分配技术时,具有多个输出层的模型在训练时会产生新的问题:「如何为不同分支的输出分配动态目标?」针对这个问题,研究者提出了一种新的标签分配方法,称为从粗粒度到细粒度(coarse-to-fine)的引导式标签分配。
Adapter接口定义了如下方法:
public abstract void registerDataSetObserver (DataSetObserver observer)
Adapter表示一个数据源,这个数据源是有可能发生变化的,比如增加了数据、删除了数据、修改了数据,当数据发生变化的时候,它要通知相应的AdapterView做出相应的改变。为了实现这个功能,Adapter使用了观察者模式,Adapter本身相当于被观察的对象,AdapterView相当于观察者,通过调用registerDataSetObserver方法,给Adapter注册观察者。
public abstract void unregisterDataSetObserver (DataSetObserver observer)
通过调用unregisterDataSetObserver方法,反注册观察者。
public abstract int getCount () 返回Adapter中数据的数量。
public abstract Object getItem (int position)
Adapter中的数据类似于数组,里面每一项就是对应一条数据,每条数据都有一个索引位置,即position,根据position可以获取Adapter中对应的数据项。
public abstract long getItemId (int position)
获取指定position数据项的id,通常情况下会将position作为id。在Adapter中,相对来说,position使用比id使用频率更高。
public abstract boolean hasStableIds ()
hasStableIds表示当数据源发生了变化的时候,原有数据项的id会不会发生变化,如果返回true表示Id不变,返回false表示可能会变化。Android所提供的Adapter的子类(包括直接子类和间接子类)的hasStableIds方法都返回false。
public abstract View getView (int position, View convertView, ViewGroup parent)
getView是Adapter中一个很重要的方法,该方法会根据数据项的索引为AdapterView创建对应的UI项。