⭐简单说两句⭐
✨ 正在努力的小新~
💖 超级爱分享,分享各种有趣干货!
👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板
🌈 感谢关注,关注了你就是我的超级粉丝啦!
🔒 以下内容仅对你可见~作者:后端小知识,CSDN后端领域新星创作者 |阿里云专家博主
CSDN个人主页:后端小知识
🔎GZH:
后端小知识🎉欢迎关注🔎点赞👍收藏⭐️留言📝
Flink入门学习-WordCount

我们今天来编写一个Flink入门学习案例,统计单词出现的次数
这里就先直接上手实践,先不看枯燥的理论
IDEA方式运行
我们首先创建Flink运行环境
//设置Flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
然后模拟一点数据
//从集合中读取模拟数据
DataStream<String> stream = env
.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");
切词做转换
stream
.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {
//value就是每一个元素的数据
System.out.println("读取内容:" + value);
//将每一个元素按照空格切分
String[] split = value.split(" ");
//遍历每一个单词
for (String word : split) {
//将每一个单词发送到下游
out.collect(new Tuple2<>(word, 1));
}
})
返回类型
.returns(Types.TUPLE(Types.STRING, Types.INT))
keyby分组(按照tuple的第一个元素进行分组)
.keyBy(f->f.f0)
聚合统计
.sum(1);
打印结果
sum.print();
最后执行execute
env.execute();
完整代码如下
package cn.wy.chapter02;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author tiancx
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//设置Flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从集合中读取模拟数据
DataStream<String> stream = env
.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream
.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {
//value就是每一个元素的数据
System.out.println("读取内容:" + value);
//将每一个元素按照空格切分
String[] split = value.split(" ");
//遍历每一个单词
for (String word : split) {
//将每一个单词发送到下游
out.collect(new Tuple2<>(word, 1));
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(f->f.f0)
.sum(1);
//打印结果
sum.print();
env.execute();
}
}
运行看结果

提交到集群运行
启动集群后我们使用命令
flink run -c 类全限定路径名 jar文件
flink run -c cn.wy.chapter02.WordCount FlinkDemo-1.0-SNAPSHOT.jar

可以看到任务提交切运行成功了
我们进入web-ui界面
网址
http://localhost:8081/#/job/completed
界面如下图所示
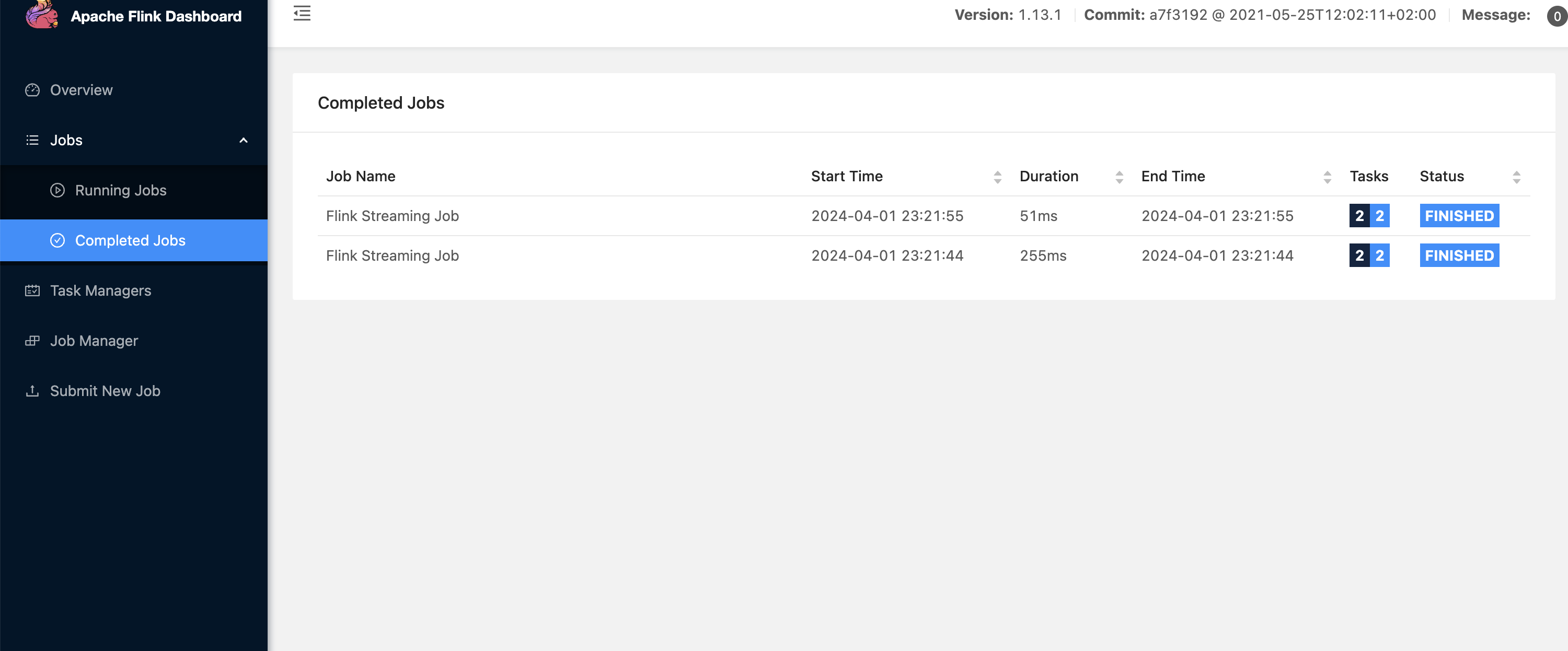
可以清晰的看到任务状态是FINISHED(完成)
任务执行成功了,我们的日志在哪看呢?
我们直接去TaskManager中看
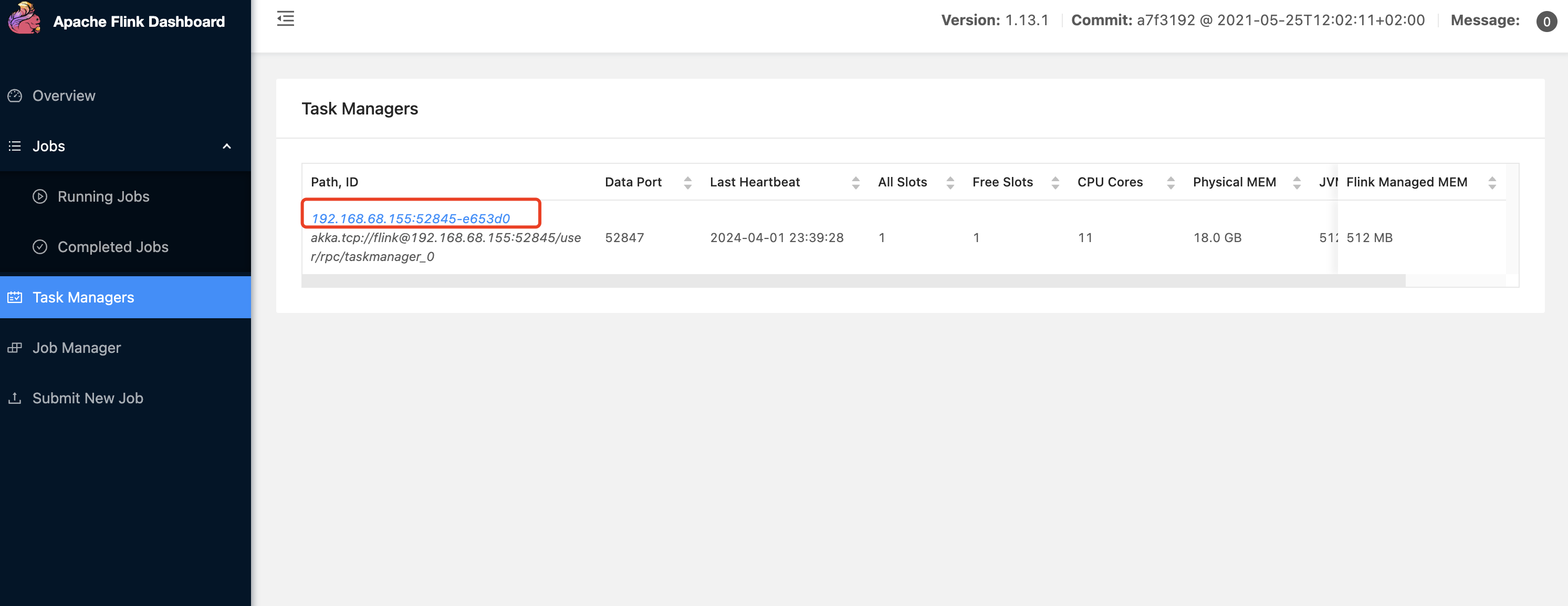
点击地址进去
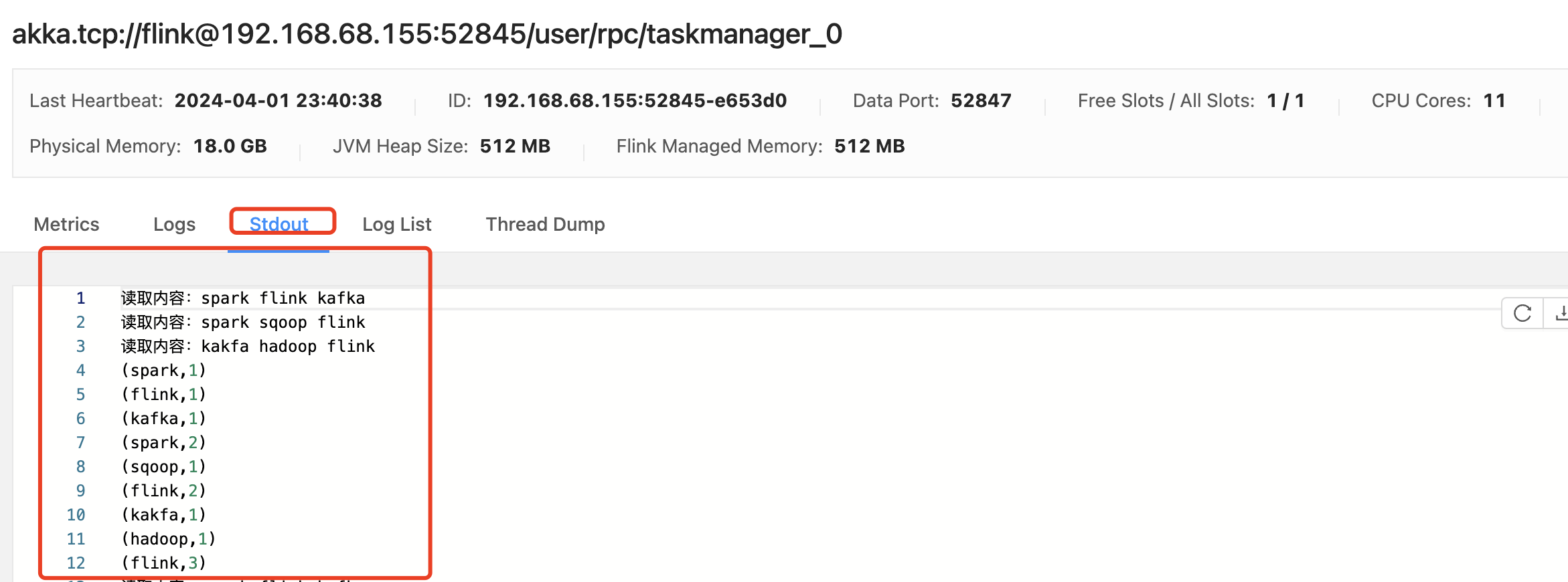 这里就是结果啦
这里就是结果啦
【都看到这了,点点赞点点关注呗,爱你们】😚😚


💬
✨ 正在努力的小新~
💖 超级爱分享,分享各种有趣干货!
👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板
🌈 感谢关注,关注了你就是我的超级粉丝啦!
🔒 以下内容仅对你可见~
作者:后端小知识,CSDN后端领域新星创作者 | 阿里云专家博主
CSDN个人主页:后端小知识
🔎GZH:后端小知识
🎉欢迎关注🔎点赞👍收藏⭐️留言📝