ollama帮助我们可以快速在本地运行一个大模型,再整合一个可视化页面就能构建一个chatGPT,可视化页面我选择了chat-ollama(因为它还能支持知识库,可玩性更高),如果只是为了聊天更推荐chatbox
部署步骤
- 下载ollama并启动,参考:https://ollama.com/download
# 启动命令
ollama serve
- 下载chat-ollama,参考:https://github.com/sugarforever/chat-ollama。本人使用docker安装的
docker compose up
# 如果您是第一次启动,需要初始化 SQLite 数据库,在新的控制台运行
docker-compose exec chatollama npx prisma migrate dev
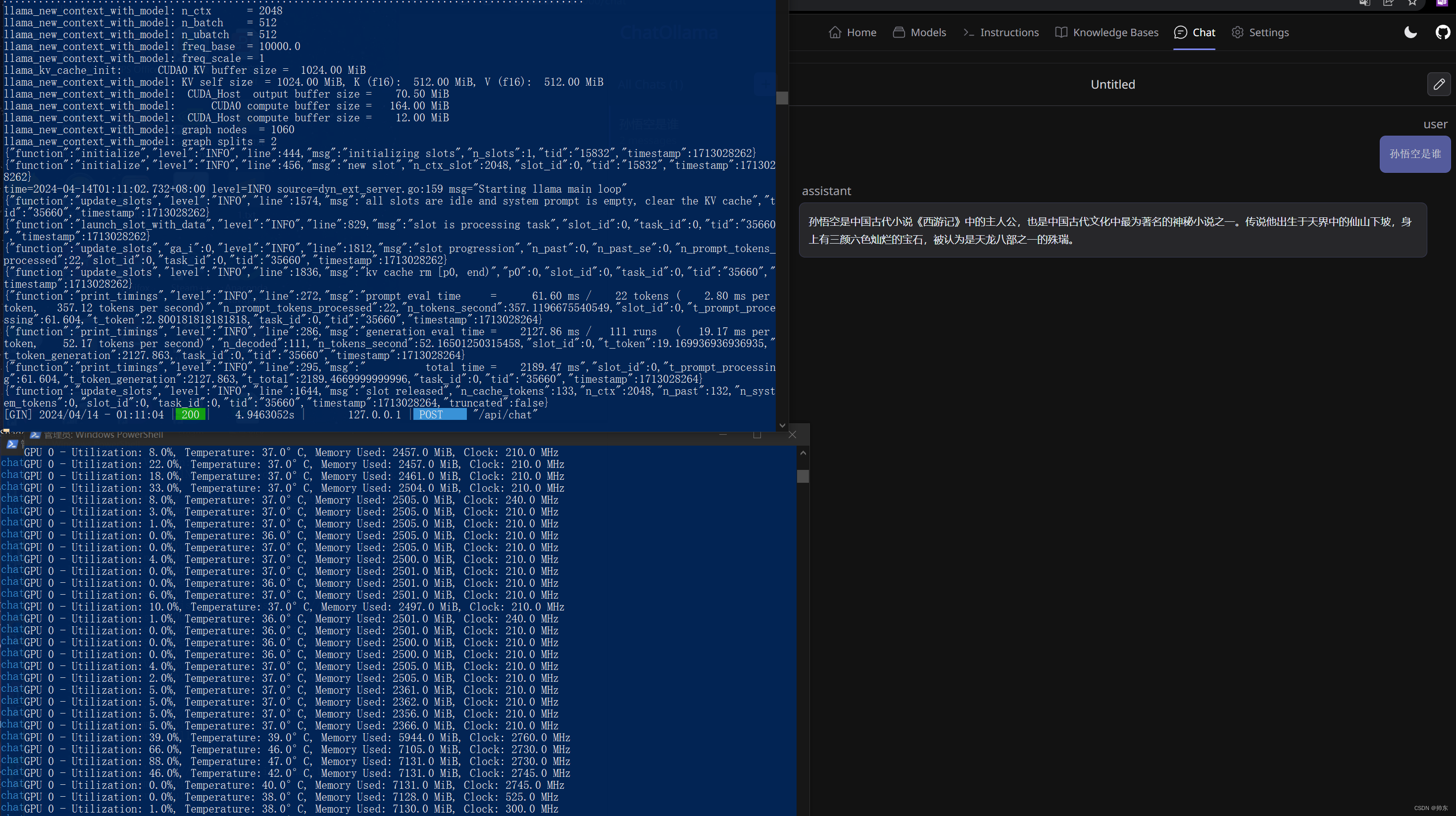
- 访问chat-ollama,网址:http://localhost:3000
- 配置ollama地址

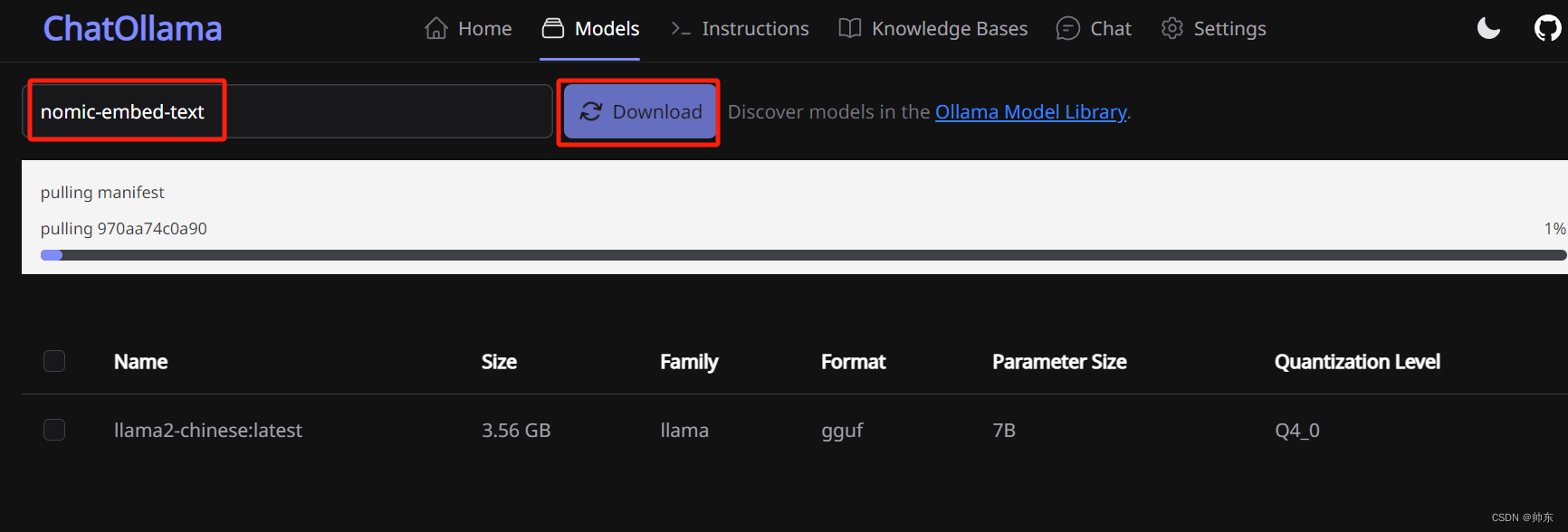
- 点击models,下载模型llama2-chinese。因为Llama 2 本身的中文比较弱。
- 开始聊天

注意
llama2-chinese模型最少要8G内存
- 7b models generally require at least 8GB of RAM
- 13b models generally require at least 16GB of RAM
CPU跑的太慢,用GPU的话也要差不多8G显存