文章目录
- 大数据深度学习:基于Tensorflow深度学习卷积神经网络CNN算法垃圾分类识别系统
- 一、项目概述
- 二、深度学习卷积神经网络(Convolutional Neural Networks,简称CNN)
- 三、部分数据库架构
- 四、系统实现
- 系统模型部分核心代码
- 模型训练效果图
- 训练模型效果展示
- 模型训练过程中训练集和验证集的准确率(accuracy)曲线。
- 模型训练过程中训练集和验证集的损失值(loss)曲线
- 项目启动
- 系统首页
- 上传测试垃圾种类(金属、塑料瓶、玻璃等),用训练好的模型进行识别分类
- 后台数据管理
- 历史识别检测
- 五、项目结语
大数据深度学习:基于Tensorflow深度学习卷积神经网络CNN算法垃圾分类识别系统
一、项目概述
随着社会的发展和城市化进程的加速,垃圾分类已经成为了环境保护和可持续发展的重要课题。然而,传统的垃圾分类方法通常依赖于人工识别,效率低下且易出错。因此,本项目旨在利用大数据和深度学习技术,构建一个基于 TensorFlow 深度学习的神经网络 CNN(Convolutional Neural Network)算法垃圾分类识别系统,以实现自动化高效的垃圾分类。该系统将利用大数据集进行训练,通过深度学习模型提取垃圾图像的特征,从而实现对垃圾进行分类。具体而言,本项目将分为以下几个阶段:
-
数据收集与预处理:收集包括各种类型垃圾的图像数据,并对数据进行预处理,包括图像尺寸统一化、去除噪声等操作,以便于后续模型训练。
-
模型设计与训练:基于 TensorFlow 框架,设计并训练适用于垃圾分类的 CNN 模型。通过大规模数据集的训练,使模型能够准确地识别不同类型的垃圾,并实现高效分类。
-
系统开发与集成:利用 Django 框架开发垃圾分类识别系统的前端和后端功能,包括用户界面设计、垃圾图像上传与识别、分类结果展示等功能,并与深度学习模型进行集成。
-
系统测试与模型超参数优化:对系统进行全面的测试,包括功能测试、性能测试和用户体验测试,及时发现并修复存在的问题。通过不断优化算法和模型,提升系统的准确性和稳定性。
-
部署与推广:将完成的垃圾分类识别系统部署到实际环境中,并进行推广和宣传,引导社会公众积极参与垃圾分类工作,促进城市环境的改善和可持续发展。
通过本项目的实施,将有效提高垃圾分类的准确性和效率,减少人力成本和资源浪费,为城市环境治理和可持续发展做出积极贡献。同时,该项目还将为深度学习在环境保护领域的应用提供有益经验和参考。
二、深度学习卷积神经网络(Convolutional Neural Networks,简称CNN)
卷积神经网络(Convolutional Neural Networks,简称CNN)是近年发展起来,并引起广泛重视的一种高效的识别方法。
1962年,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的局部互连网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络[1](Convolutional Neural Networks-简称CNN)7863。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。
Fukushima在1980年基于神经元间的局部连通性和图像的层次组织转换,为解决模式识别问题,提出的新识别机(Neocognitron)是卷积神经网络的第一个实现网络[2]。他指出,当在不同位置应用具有相同参数的神经元作为前一层的patches时,能够实现平移不变性1296。随着1986年BP算法以及T-C问题[3](即权值共享和池化)9508的提出, LeCun和其合作者遵循这一想法,使用误差梯度(the error gradient)设计和训练卷积神经网络,在一些模式识别任务中获得了最先进的性能4。在1998年,他们建立了一个多层人工神经网络,被称为LeNet-5[5],用于手写数字分类, 这是第一个正式的卷积神经网络模型3579。类似于一般的神经网络,LeNet-5有多层,利用BP算法来训练参数。它可以获得原始图像的有效表示,使得直接从原始像素(几乎不经过预处理)中识别视觉模式成为可能。然而,由于当时大型训练数据和计算能力的缺乏,使得LeNet-5在面对更复杂的问题时,如大规模图像和视频分类,不能表现出良好的性能。
因此,在接下来近十年的时间里,卷积神经网络的相关研究趋于停滞,原因有两个:一是研究人员意识到多层神经网络在进行BP训练时的计算量极其之大,当时的硬件计算能力完全不可能实现;二是包括SVM在的浅层机器学习算法也渐渐开始暂露头脚。直到2006年,Hinton终于一鸣惊人,在《科学》上发表文章,使得CNN再度觉醒,并取得长足发展。随后,更多的科研工作者对该网络进行了改进。其中,值得注意的是Krizhevsky等人提出的一个经典的CNN架构,相对于图像分类任务之前的方法,在性能方面表现出了显著的改善2674。他们方法的整体架构,即AlexNet[9](也叫ImageNet),与LeNet-5相似,但具有更深的结构。它包括8个学习层(5个卷积与池化层和3个全连接层),前边的几层划分到2个GPU上,(和ImageNet是同一个)并且它在卷积层使用ReLU作为非线性激活函数,在全连接层使用Dropout减少过拟合。该深度网络在ImageNet大赛上夺冠,进一步掀起了CNN学习热潮。
一般地,CNN包括两种基本的计算,其一为特征提取,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。这两种操作形成了CNN的卷积层。此外,卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,即池化层,这种特有的两次特征提取结构减小了特征分辨率。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式地特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
CNN 的一个核心特点是卷积操作,它可以在图像上进行滑动窗口的计算,通过滤波器(又称卷积核)和池化层(Max Pooling)来提取出图像的特征。卷积操作可以有效地减少权重数量,降低计算量,同时也能够保留图像的空间结构信息。池化层则可以在不改变特征图维度的前提下,减少计算量,提高模型的鲁棒性。
CNN 的典型结构包括卷积层、池化层、全连接层等。同时,为了防止过拟合,CNN 还会加入一些正则化的技术,如 Dropout 和 L2 正则等。
CNN 在图像分类、目标检测、语音识别等领域都有着广泛的应用。在图像分类任务中,CNN 的经典模型包括 LeNet-5、AlexNet、VGG 和 GoogleNet/Inception 等,这些模型的设计思想和网络结构都有所不同,但都对卷积神经网络的发展做出了重要贡献。
一般地,CNN包括两种基本的计算,其一为特征提取,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。这两种操作形成了CNN的卷积层。此外,卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,即池化层,这种特有的两次特征提取结构减小了特征分辨率。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式地特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
三、部分数据库架构
四、系统实现
系统模型部分核心代码
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout,BatchNormalization,Activation
base_model = keras.applications.ResNet50(weights='imagenet', include_top=False, input_shape=(img_width,img_height,3))
for layer in base_model.layers:
layer.trainable = True
# Add layers at the end
X = base_model.output
X = Flatten()(X)
X = Dense(512, kernel_initializer='he_uniform')(X)
#X = Dropout(0.5)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Dense(16, kernel_initializer='he_uniform')(X)
#X = Dropout(0.5)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
output = Dense(len(class_names), activation='softmax')(X)
model = Model(inputs=base_model.input, outputs=output)
optimizer = tf.keras.optimizers.Adam(lr=1e-4)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_ds,
validation_data=val_ds,
epochs=15
)
model.save("resnet50_model.h5")
模型训练效果图

训练模型效果展示
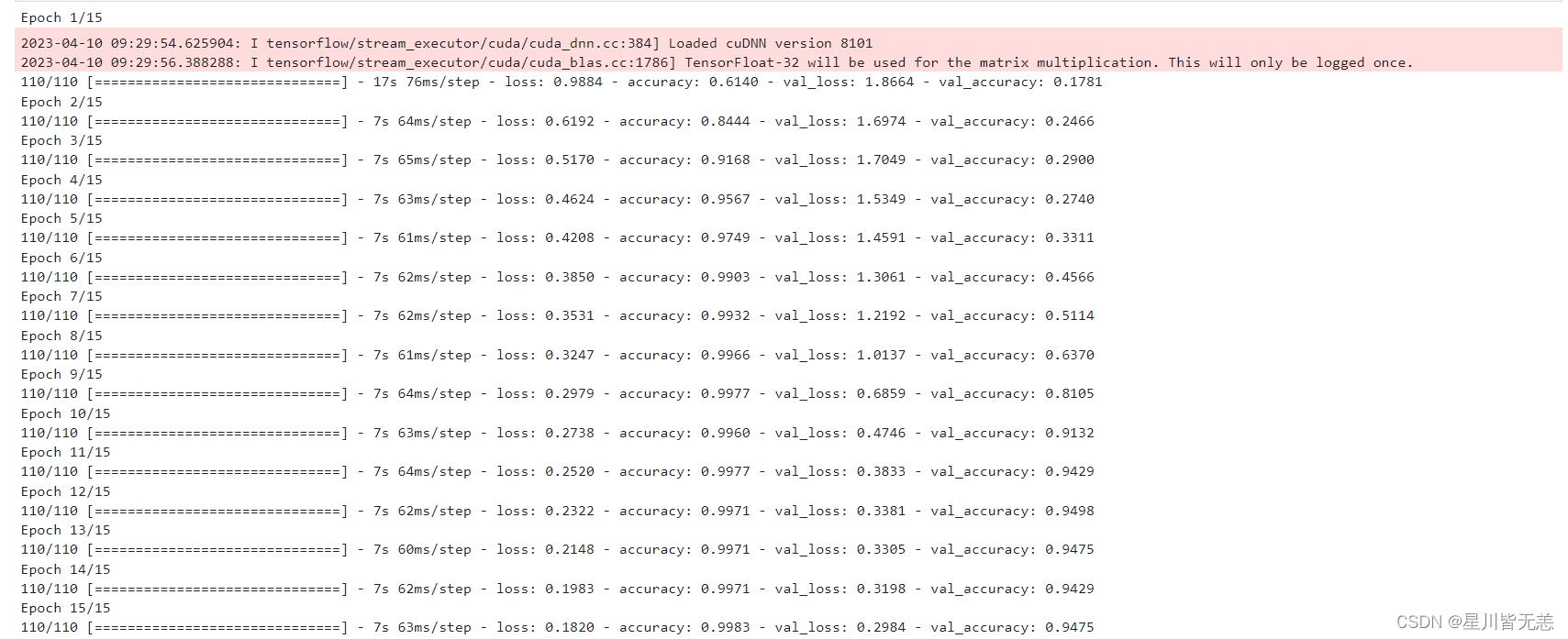
通过训练日志信息,可以看到训练模型效果,我们的这个模型准确率可以达到0.9983,几乎完全拟合,已经很高了,如果进行进一步调参优化,那么模型识别效果会更加理想。
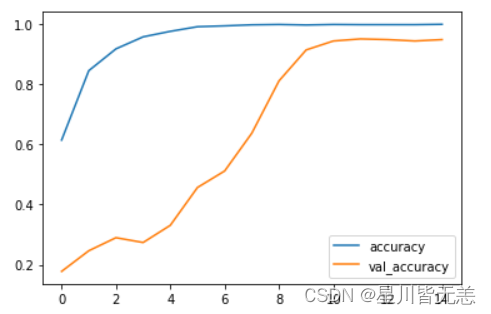
模型训练过程中训练集和验证集的准确率(accuracy)曲线。
history.history.keys()
plt.plot(history.epoch, history.history.get('accuracy'), label='accuracy')
plt.plot(history.epoch, history.history.get('val_accuracy'), label='val_accuracy')
plt.legend()
history.history.keys():获取history对象的history属性的键,history对象通常是在使用 Keras 或 TensorFlow 训练模型时返回的对象,其中包含了训练过程中的各种信息,训练集和验证集的准确率、损失值等。plt.plot(history.epoch, history.history.get('accuracy'), label='accuracy')利用 Matplotlib 库中的plot函数绘制了训练集的准确率曲线。其中,history.epoch表示训练的迭代轮数,history.history.get('accuracy')表示从history对象中获取训练集的准确率,label='accuracy'则是为了在图例中标识出这条曲线的名称为 ‘accuracy’。plt.plot(history.epoch, history.history.get('val_accuracy'), label='val_accuracy'): 绘制验证集的准确率曲线。history.history.get('val_accuracy')表示从history对象中获取验证集的准确率。plt.legend(): 显示图例,将上面绘制的两条曲线的名称 ‘accuracy’ 和 ‘val_accuracy’ 显示在图中的合适位置。
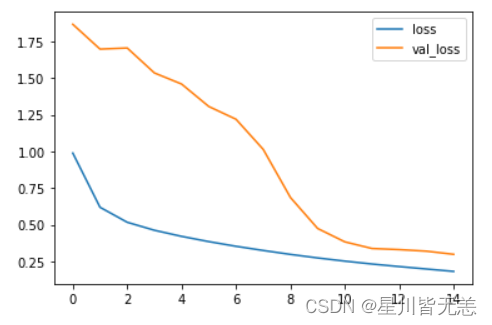
模型训练过程中训练集和验证集的损失值(loss)曲线
利用 Matplotlib 库中的 plot 函数绘制了训练集的损失值曲线。history.epoch 表示训练的迭代轮数。
项目启动
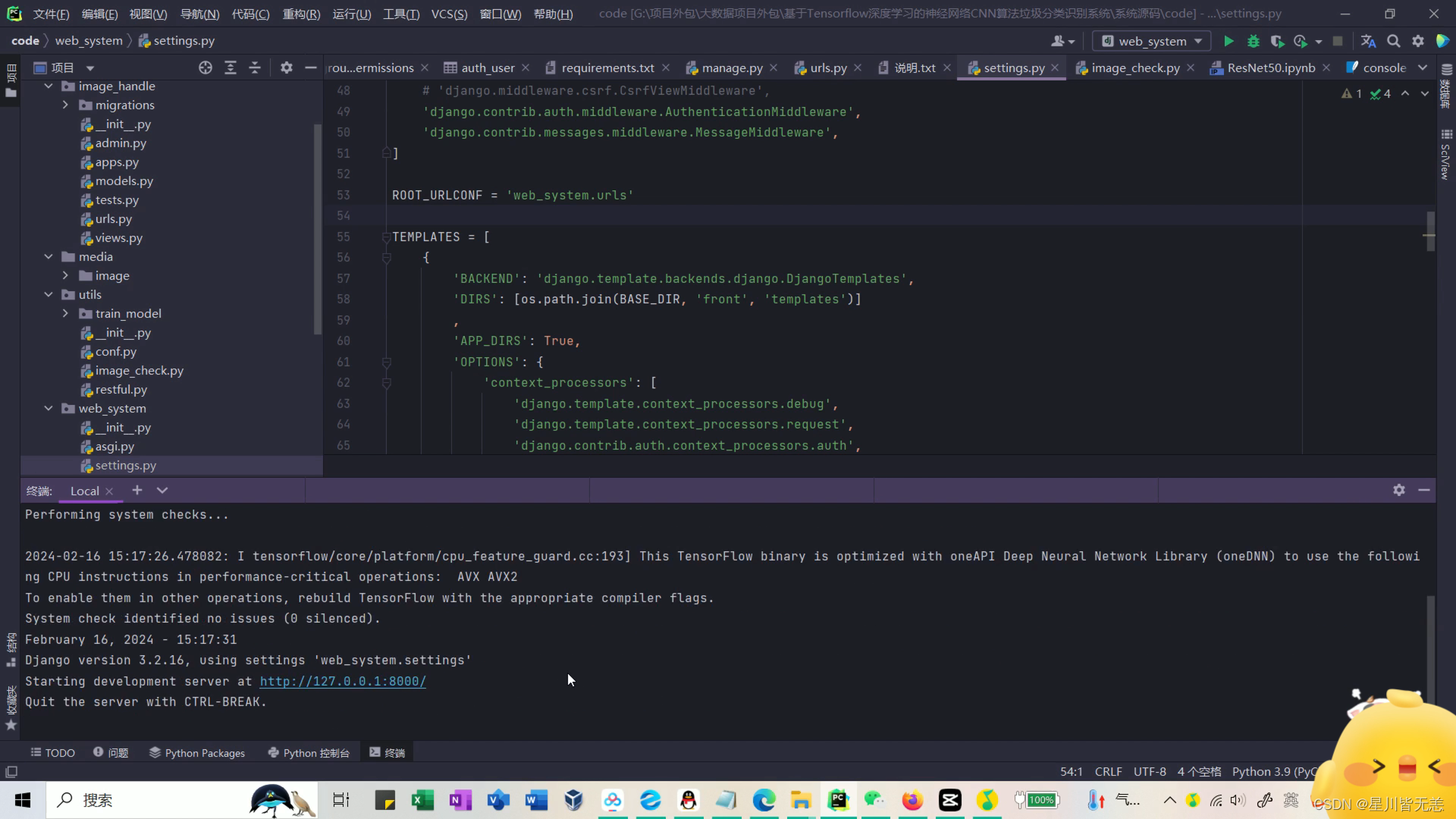
系统首页
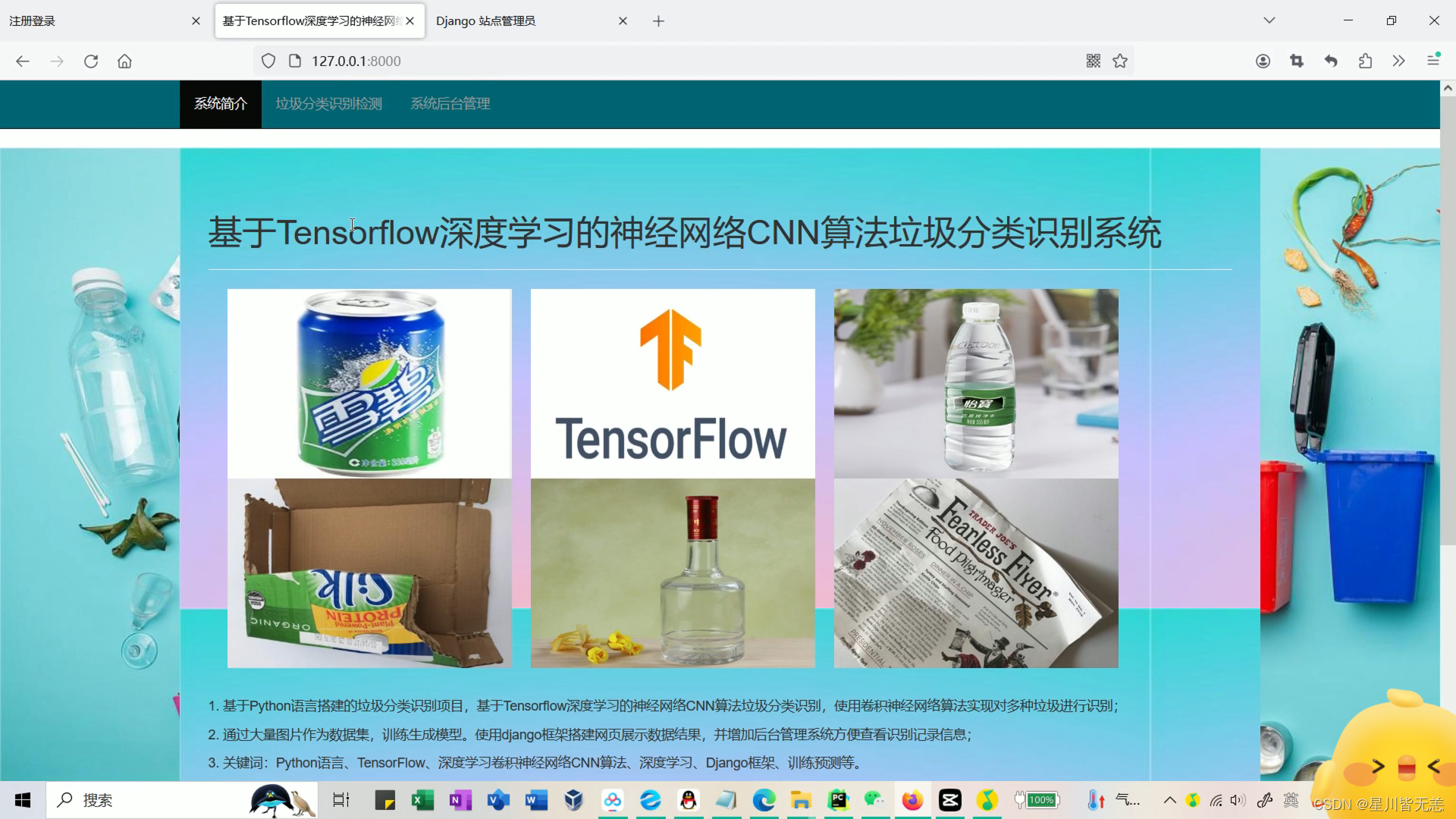
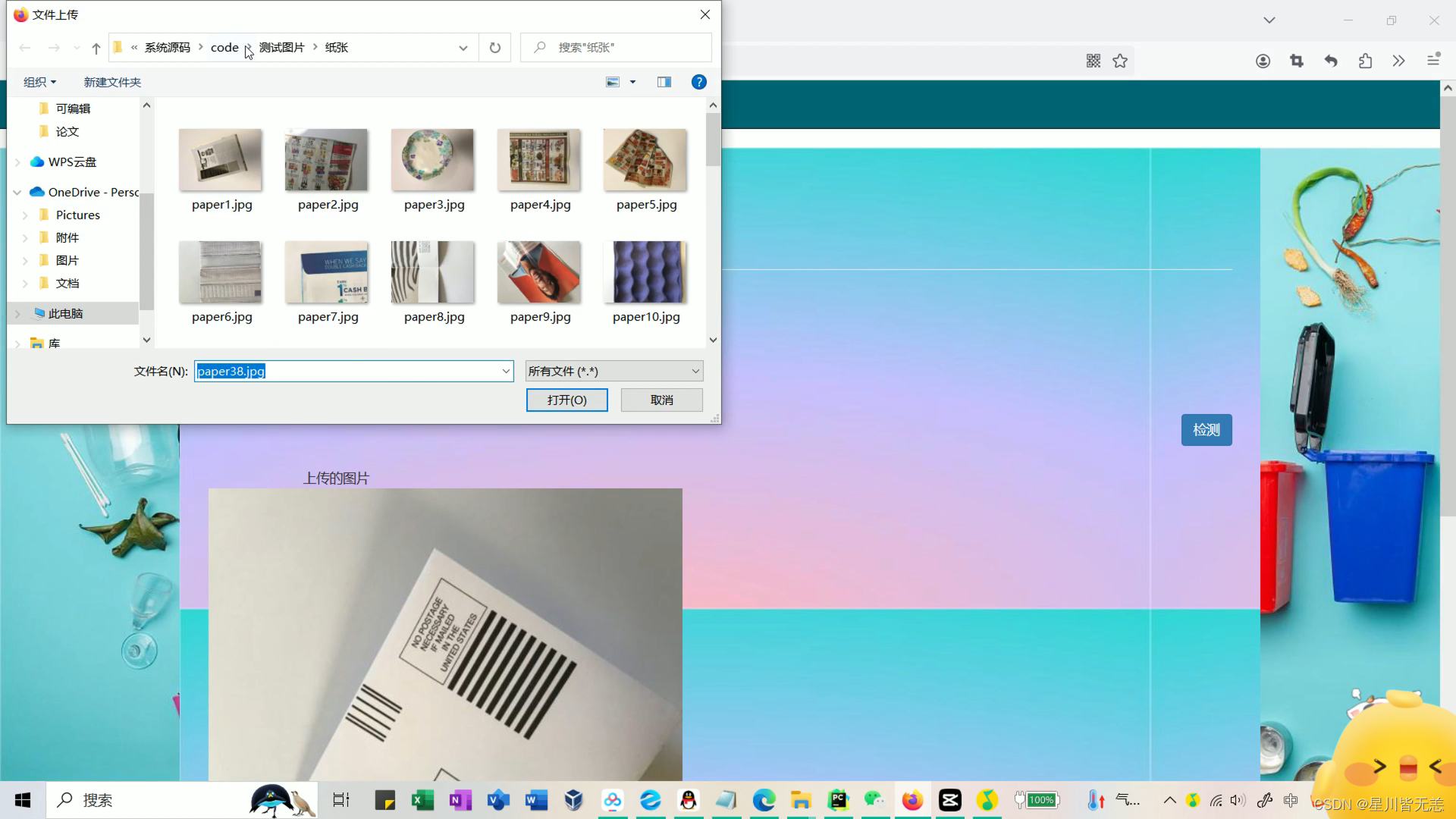
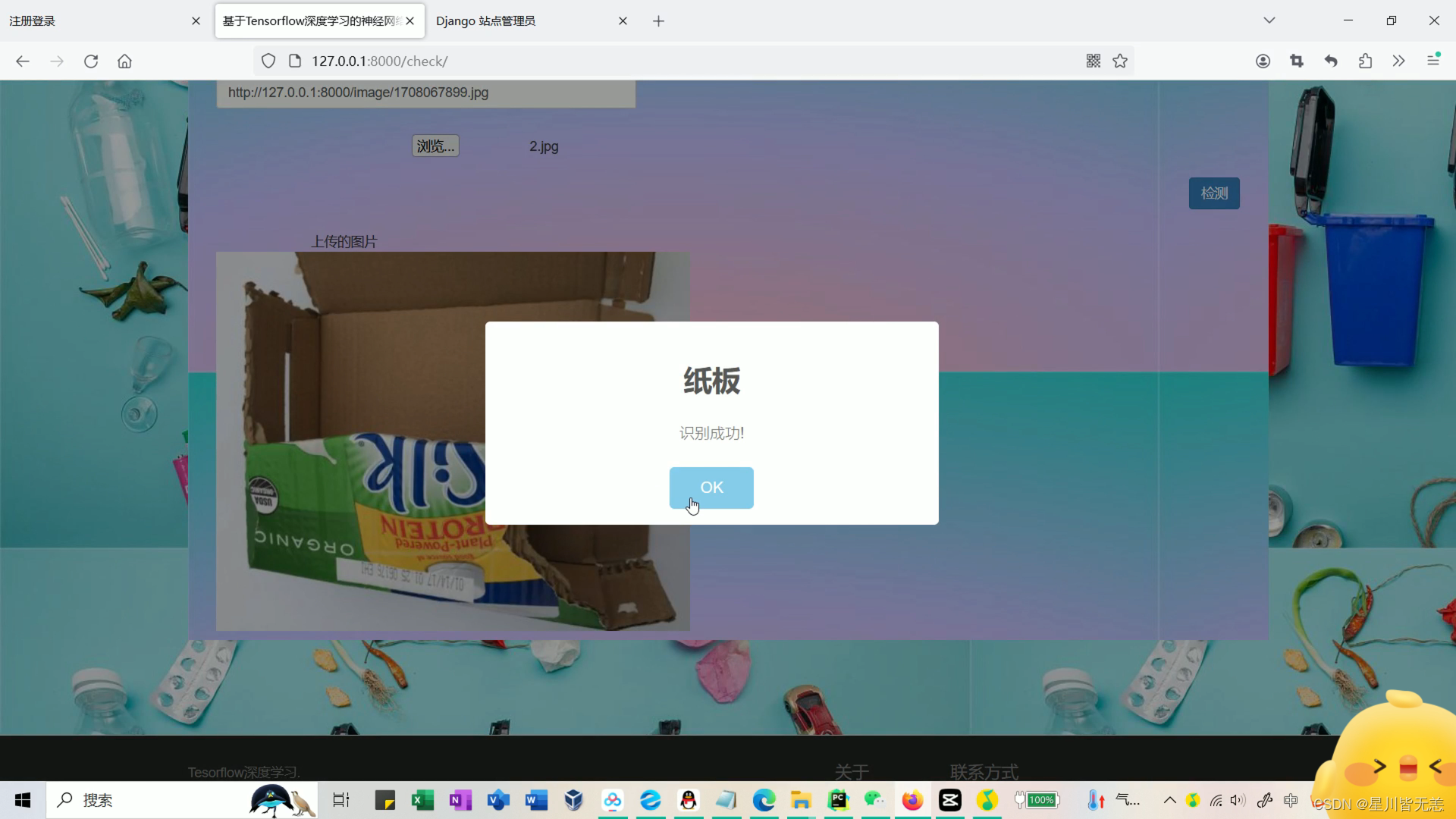
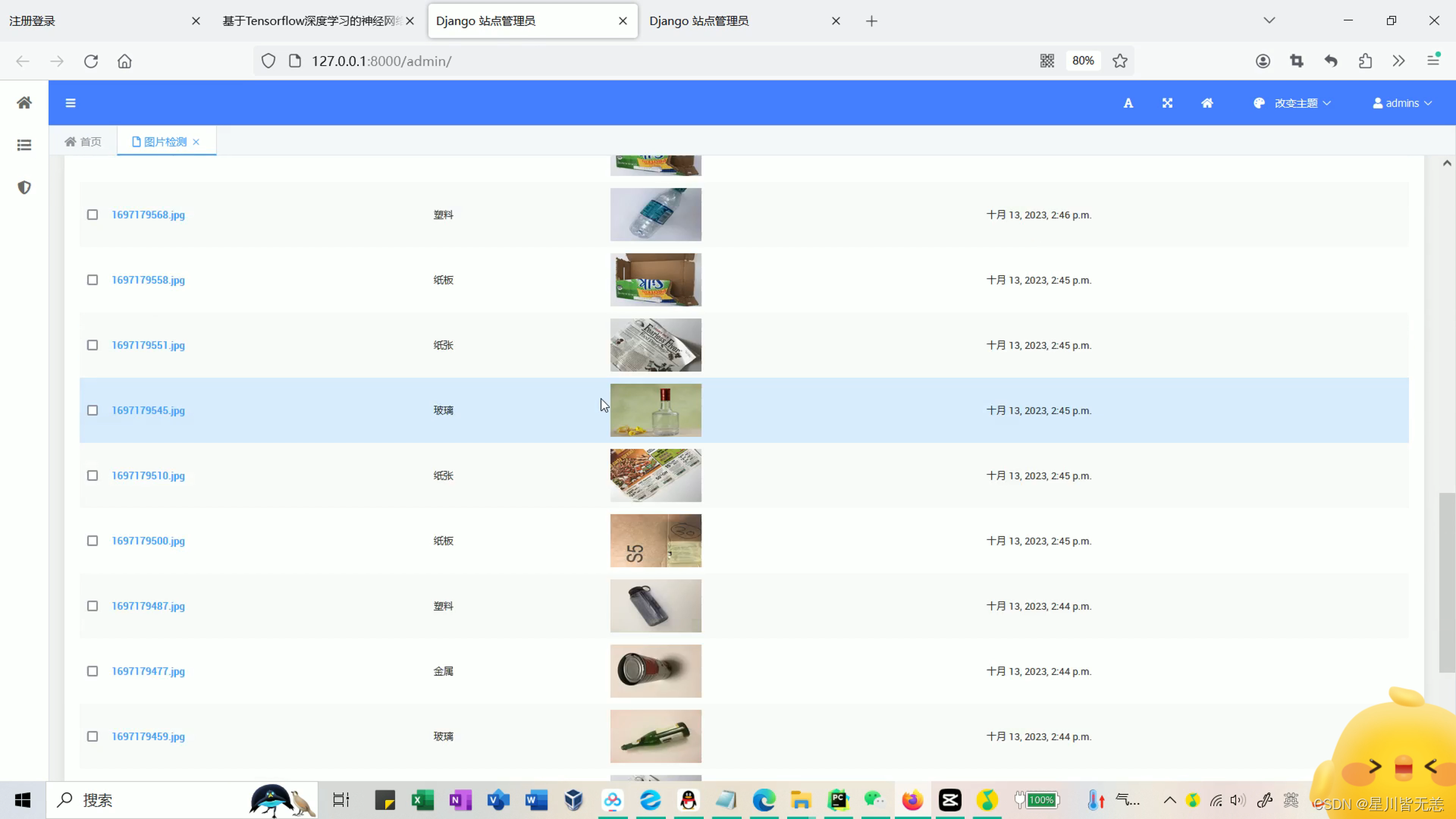
上传测试垃圾种类(金属、塑料瓶、玻璃等),用训练好的模型进行识别分类
后台数据管理
历史识别检测
五、项目结语
本研究展示了一个高度精确的模型,在训练中达到了很好的精确度,为0.9983,几乎完全拟合。这一成果不仅是对机器学习技术在解决实际问题中潜力的有力证明,也为本研究所探索的领域带来了重要的贡献。通过精心设计的实验和深入分析,我们不仅验证了模型的性能,还揭示了其在特定任务上的优势和局限性。我们对于这一研究成果感到满意,并期待着未来进一步探索如何优化和应用这一模型,以解决更广泛的问题,并为学术界和工业界带来更多的创新和价值。
需项目资料/商业合作/交流探讨等可以添加下面个人名片,后续有时间会持续更新更多优质项目内容,感谢各位的喜欢与支持!





![[Linux][基础IO][一][系统文件IO][文件描述符fd]详细解读](https://img-blog.csdnimg.cn/direct/5f37d4c6f20b4cef8ea3c88401b178ee.png)