Collection:单列集合:每个元素只包含一个值
Collection集合存储的是地址
Collection的三种遍历方法如下
//迭代器是用来遍历集合的专用方式(数组没有迭代器),在java中迭代器的代表是Iterator
//boolean hasNext():询问当前位置是否有元素存在
//E next():获取当前位置的元素,并同时将迭代器指向下一个元素处
public class CollectionTest3 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("java1");
c.add("java2");
c.add("java3");
//从集合对象获取迭代器对象
Iterator<String> iterator = c.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//增强For循环:可以遍历数组或集合,本质就是迭代器遍历集合的简便写法
/*
for(元素的数据类型 变量名:数组或者集合)
*/
for(String s:c){
System.out.println(s);
}
//使用Lambda表达式遍历
c.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
c.forEach((String s) -> {
System.out.println(s);
});
c.forEach( s -> {
System.out.println(s);
});
c.forEach( s -> System.out.println(s));
c.forEach(System.out::println);
}
}

1. List系列集合:添加的元素是有序,可重复,有索引。
List集合存储的是内容
四种遍历方式如下
public class ListTest1 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("java1");
list.add("java2");
list.add("java2");
// System.out.println(list);
//for循环遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//迭代器遍历
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//增强for循环
for (String s : list) {
System.out.println(s);
}
//Lambda表达式遍历
list.forEach( System.out::println);
}
}
a. ArrayList:有序,可重复,有索引( 基于数组实现 )
查询快,增删慢
- 查询速度快(是根据索引查询数据快)
- 删除效率低:可能需要把后边很多数据进行前移
- 添加数据效率极低:可能需要把后边很多数据后移,再添加元素;或者也可能进行数组的扩容
底层原理:(1)利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
(2)添加第一个元素时,底层会创建一个新的长度为10的数组
(3)存满时,会扩容1.5倍
(4)如果一次添加多个元素,1.5倍还放不下,则创建数组的长度以实际为准
b. LinkedList:有序,可重复,有索引(基于双向链表实现)
适合用作 队列,栈
- 查询慢,增删相对较快,但对首尾进行增删改查的速度是极快的
(API中有 在头部增加删除元素,在尾部增加删除元素 方法)
2. Set系列集合:添加的元素是无序,不重复,无索引.
a. HashSet : 无序,不重复,无索引(基于哈希表实现,底层基于Map实现的,只是只要键数据,不要值数据)
增删改查性能都较好
哈希值:java中每个对象都有一个哈希值,是一个int类型的数据
哈希表:数组+链表+红黑树
底层原理:(1)创建一个默认长度16的数组,默认加载因子为0.75,数组名为table
(2)使用元素的哈希值对数组长度求余计算出应存入的位置
(3)判断当前位置是否为null,如果是null直接存入
(4)如果不为null,表示有元素,则调用equals方法比较
相等,则不存;不相等,则存入数组
(数组占满后,扩容16*0.75=12个)
JDK8之前,新元素存入数组,占老元素位置,老元素挂在下面(链表)
JDK8之后,新元素挂在老元素下面(链表),当链表长度超过8,且数组长度
>=64时,自动将链表转成红黑树
如果Set集合认为两个内容一样的对象是重复的,必须重写对象的HashCode()方法和equals()方法
b. LinkedHashSet : 有序,不重复,无索引(基于哈希表实现,底层基于LinkedHashMap实现)
每个元素都额外多了一个双链表的机制记录它前后元素的位置
c. TreeSet : 按照大小默认升序排序,不重复,无索引(基于红黑树实现)
存储自定义的对象时,必须制定规则排序,支持如下两种方法(见 对象排序的两种方法)
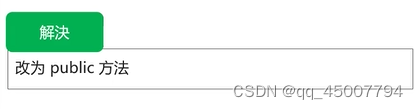
Map:双列集合,每个元素包含两个值(键值对)
键不可以重复,值可以重复
在做购物车时,商品与购买数量是一对数据等等
把Map集合变成Set集合(把一个键值对看成一个元素)
Set<Map.Entry<String, Integer>> entries = map.entrySet();map集合三种遍历方式如下
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
public class MapTest1 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("张三",20);
map.put("张三",21);
map.put("李四",19);
map.put("王五",20);
System.out.println(map);
//键找值
//获取map集合的全部键
Set<String> keys = map.keySet();
System.out.println(keys);
//遍历全部的键,获得值
for (String key : keys) {
Integer i = map.get(key);
System.out.println(key+"==>"+i);
}
//把键值对看成一个整体进行遍历
//1.调用map集合提供的entrySet方法,把map集合转换成键值对类型的set集合
Set<Map.Entry<String, Integer>> entries = map.entrySet();
//entires = {(张三=21),(李四=19),(王五=20)}
for (Map.Entry<String, Integer> entry:entries) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key+"==>"+value);
}
//lambda表达式遍历
map.forEach((k,v) -> {
System.out.println(k+"==>"+v);
});
//即
map.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String k, Integer i) {
System.out.println(k+"==>"+i);
}
});
}
}
1.HashMap(由键决定特点):无序,不重复,无索引(基于哈希表实现)
键相同时,后边的内容会覆盖前边的
public class MapTest1 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("手表",2);
map.put("手表",15);
map.put("手机",5);
map.put(null,null);
System.out.println(map);
//{null=null, 手表=15, 手机=5}
}
}
- HashMap集合是一种增删改查数据,性能都较好的集合
- 但是他是无序的,不能重复,没有索引支持的(由键决定的特点)
- HashMap的键依赖HashCode方法和equals方法保证键的唯一
- 如果存储的是自定义类型的对象,可以通过重写通过 HashCode方法和equals方法,这样可以保证多
个对象内容一样时,HashMap集合就能认为是重复的
a.LinkedHashMap:有序,不重复,无索引
底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)
2.TreeMap:按照大小默认升序排序,不重复,无索引
集合的并发修改异常
- 使用迭代器遍历时,又同时在删除集合中的数据,程序就会出现并发修改异常
- 使用 增强for循环,lambda表达式 遍历集合并删除数据,没有办法解决bug
解决办法
List<String> list = new ArrayList<>();
list.add("java1");
list.add("java2");
list.add("java2");
list.add("java21");
list.add("java3");
list.add("java11");
//迭代器遍历
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String name = iterator.next();
if (name.contains("1")){
// list.remove(name);//会出现并发错误,会漏删
iterator.remove();//删除迭代器当前遍历到的数据,每删除一个数据后,相当于在底层做了i--
}
}
//for循环遍历
for (int i = 0; i < list.size(); i++) {
String name = list.get(i);
if (name.contains("1")){
list.remove(name);
i--;
}
}
可变参数
- 就是一种特殊形参,定义在方法,构造器的形参列表里,格式是:数据类型,参数名称
特点和好处
- 好处:可以不传数据给他;可以同时传一个或者同时传多个数据给他;也可以传一个数组给她
- 好处:常常用来灵活的接收数据
注意:
- 一个形参列表中,只能有一个可变参数
- 可变参数必须放到形参列表的最后边
public class ParamTest {
public static void main(String[] args) {
test();
test(1);
test(1,2);
test(new int[]{1,2,3});
}
//一个形参列表中,只能有一个可变参数
//可变参数必须放到形参列表的最后边
public static void test(int...nums){
//可变参数在方法内部,本质就是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("----------------");
}
}


![[Linux][基础IO][一][系统文件IO][文件描述符fd]详细解读](https://img-blog.csdnimg.cn/direct/5f37d4c6f20b4cef8ea3c88401b178ee.png)