文章目录
- 图谱问答
- NER
- ac自动机
- 实体链接
- 实体消歧
- 多跳问答
- neo4j_graph执行流程
- 结构图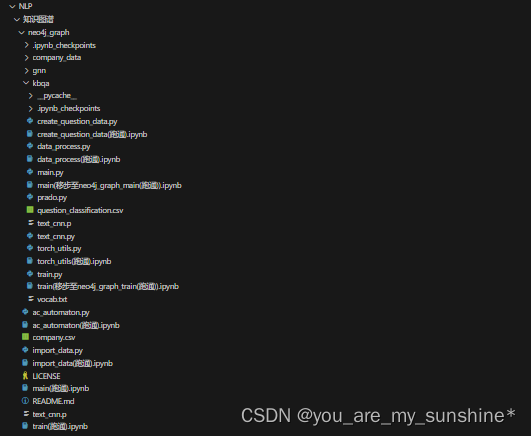
- company_data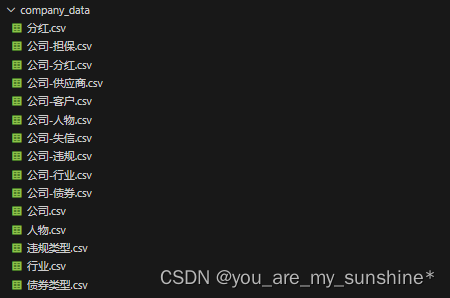
- 代码与数据
- 先启动neo4j图数据库
- import_data
- create_question_data
- data_process
- ac_automaton
- torch_utils
- text_cnn
- train
- main
- 图谱问答实战小结
图谱问答
图谱问答有很多种情况,例如根据实体和关系查询尾实体,或者根据实体查询关系,甚至还会出现多跳的情况,不同的情况采用的方法略有不同,我们先来看最简单的情况,根据头实体和关系查询尾实体。
1、找到实体与关系,可以采用BIO的形式做NER,也可以直接使用分类的方法
2、实体链接,如果遇到相同名字的实体,需要做一个消歧
NER
目前的NER的方式很多,基本的结构都是encoder+crf层
ac自动机
1、构建前缀树
2、给前缀树加上fail指针
节点i的fail指针,如果在第一层,则指向root节点,其它情况指向其父节点的fail指针指向的节点的相同节点
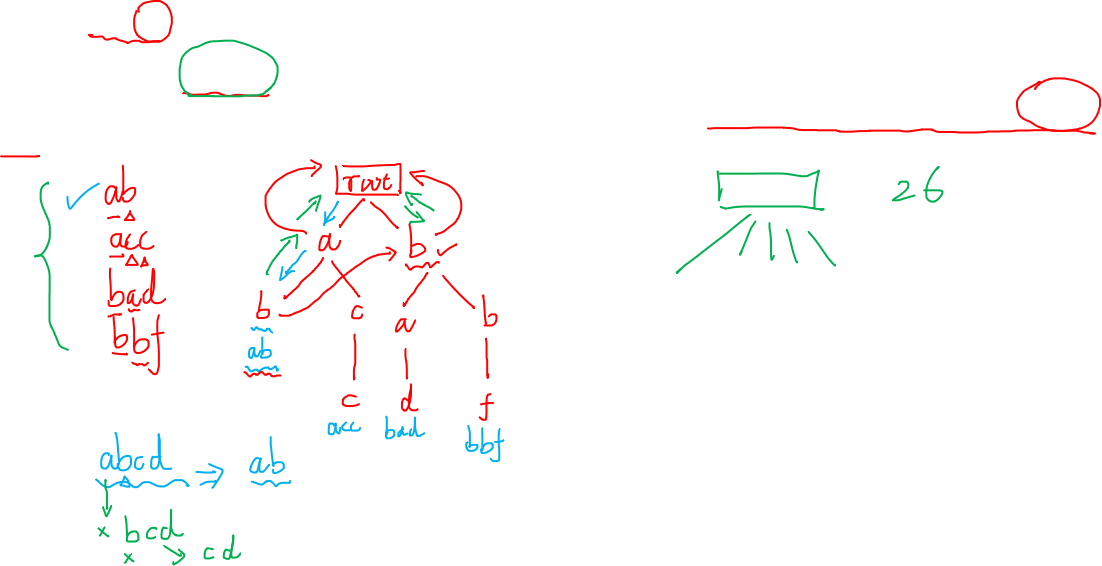
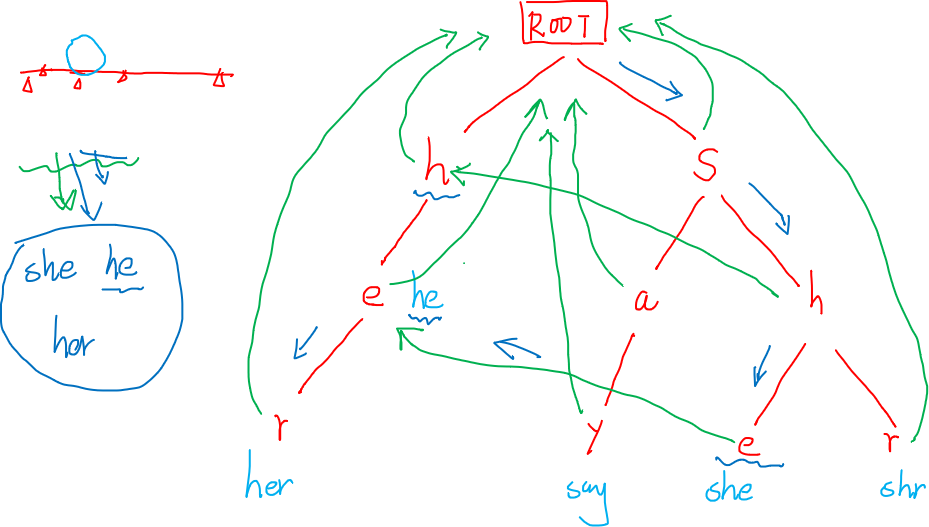
有如下的几个模式串:she he say shr her
匹配串:yasherhs
实体链接
实体链接包括两个步骤:
Candidate Entity Generation、Entity Disambiguation
找到候选实体后,下一步就是实体消歧
实体消歧
实体消歧,这里我们使用的是匹配的方法:
1、使用孪生网络,计算相似度
2、对问题和候选集做embedding,计算余弦相似度
多跳问答
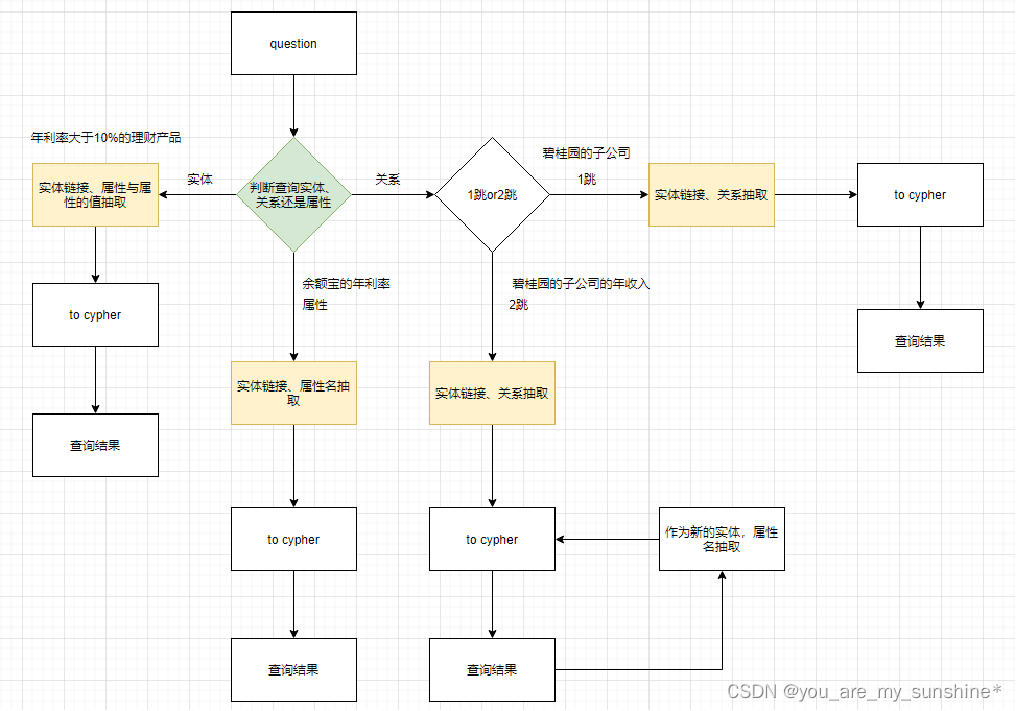
neo4j_graph执行流程
1、先执行import_data.py脚本,把company_data下面的数据导入到neo4j
2、执行gnn/saint.py脚本进行节点分类
3、company.csv文件是每个节点的属性
结构图
company_data
截图举几个例子(ps:数据为虚假,作为学习使用):

代码与数据
先启动neo4j图数据库
操作流程:WIN+R,cmd,neo4j.bat concole
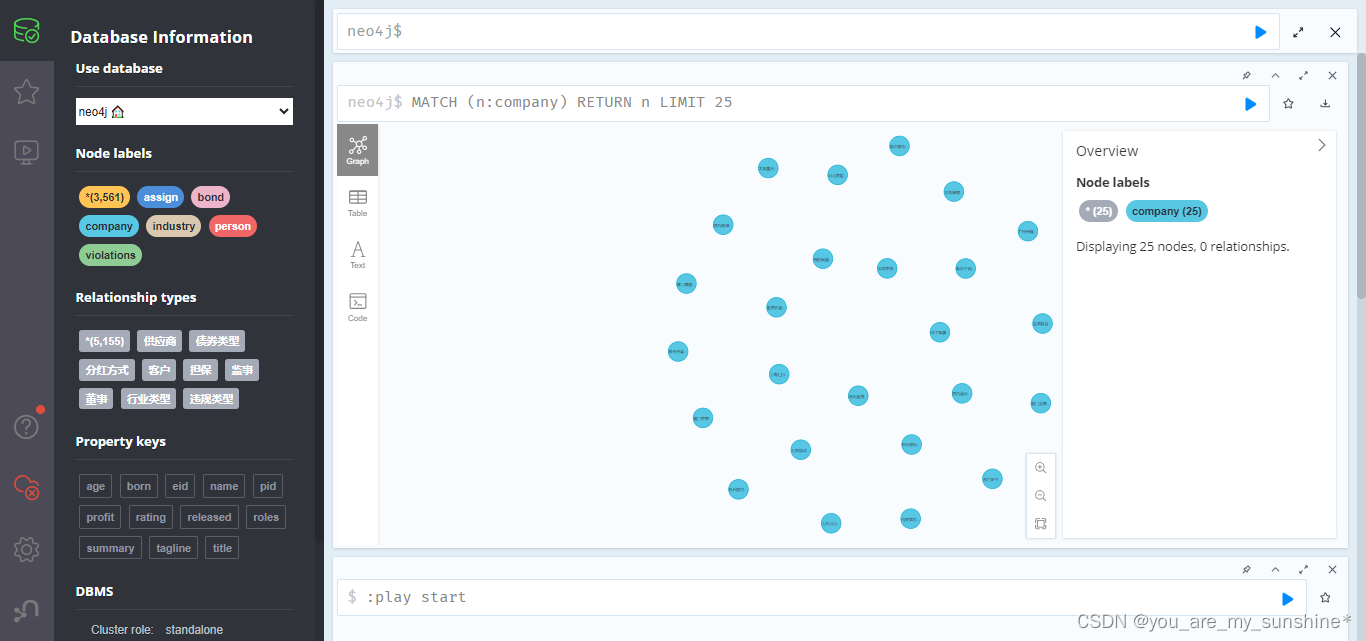
import_data
import os
from py2neo import Node, Subgraph, Graph, Relationship, NodeMatcher
from tqdm import tqdm
import pandas as pd
import numpy as np
#graph = Graph("http://127.0.0.1:7474", auth=("neo4j", "qwer"))
#graph = Graph("http://127.0.0.1:7474", auth=("neo4j", "qwer"))
#uri = 'bolt://localhost:7687'
#graph = Graph(uri, auth=("neo4j", "password"), port= 7687, secure=True)
#uri = uri = 'http://localhost:7687'
#graph = Graph(uri, auth=("neo4j", "qwer"), port= 7687, secure=True, name= "StellarGraph")
import py2neo
default_host = os.environ.get("STELLARGRAPH_NEO4J_HOST")
# Create the Neo4j Graph database object; the arguments can be edited to specify location and authentication
graph = py2neo.Graph(host=default_host, port=7687, user='neo4j', password='qwer')
def import_company():
df = pd.read_csv('company_data/公司.csv')
eid = df['eid'].values
name = df['companyname'].values
nodes = []
data = list(zip(eid, name))
for eid, name in tqdm(data):
profit = np.random.randint(100000, 100000000, 1)[0]
node = Node('company', name=name, profit=int(profit), eid=eid)
nodes.append(node)
graph.create(Subgraph(nodes))
def import_person():
df = pd.read_csv('company_data/人物.csv')
pid = df['personcode'].values
name = df['personname'].values
nodes = []
data = list(zip(pid, name))
for eid, name in tqdm(data):
age = np.random.randint(20, 70, 1)[0]
node = Node('person', name=name, age=int(age), pid=str(eid))
nodes.append(node)
graph.create(Subgraph(nodes))
def import_industry():
df = pd.read_csv('company_data/行业.csv')
names = df['orgtype'].values
nodes = []
for name in tqdm(names):
node = Node('industry', name=name)
nodes.append(node)
graph.create(Subgraph(nodes))
def import_assign():
df = pd.read_csv('company_data/分红.csv')
names = df['schemetype'].values
nodes = []
for name in tqdm(names):
node = Node('assign', name=name)
nodes.append(node)
graph.create(Subgraph(nodes))
def import_violations():
df = pd.read_csv('company_data/违规类型.csv')
names = df['gooltype'].values
nodes = []
for name in tqdm(names):
node = Node('violations', name=name)
nodes.append(node)
graph.create(Subgraph(nodes))
def import_bond():
df = pd.read_csv('company_data/债券类型.csv')
names = df['securitytype'].values
nodes = []
for name in tqdm(names):
node = Node('bond', name=name)
nodes.append(node)
graph.create(Subgraph(nodes))
# def import_dishonesty():
# node = Node('dishonesty', name='失信')
# graph.create(node)
def import_relation():
df = pd.read_csv('company_data/公司-人物.csv')
matcher = NodeMatcher(graph)
eid = df['eid'].values
pid = df['pid'].values
post = df['post'].values
relations = []
data = list(zip(eid, pid, post))
for e, p, po in tqdm(data):
company = matcher.match('company', eid=e).first()
person = matcher.match('person', pid=str(p)).first()
if company is not None and person is not None:
relations.append(Relationship(company, po, person))
graph.create(Subgraph(relationships=relations))
print('import company-person relation succeeded')
df = pd.read_csv('company_data/公司-行业.csv')
matcher = NodeMatcher(graph)
eid = df['eid'].values
name = df['industry'].values
relations = []
data = list(zip(eid, name))
for e, n in tqdm(data):
company = matcher.match('company', eid=e).first()
industry = matcher.match('industry', name=str(n)).first()
if company is not None and industry is not None:
relations.append(Relationship(company, '行业类型', industry))
graph.create(Subgraph(relationships=relations))
print('import company-industry relation succeeded')
df = pd.read_csv('company_data/公司-分红.csv')
matcher = NodeMatcher(graph)
eid = df['eid'].values
name = df['assign'].values
relations = []
data = list(zip(eid, name))
for e, n in tqdm(data):
company = matcher.match('company', eid=e).first()
assign = matcher.match('assign', name=str(n)).first()
if company is not None and assign is not None:
relations.append(Relationship(company, '分红方式', assign))
graph.create(Subgraph(relationships=relations))
print('import company-assign relation succeeded')
df = pd.read_csv('company_data/公司-违规.csv')
matcher = NodeMatcher(graph)
eid = df['eid'].values
name = df['violations'].values
relations = []
data = list(zip(eid, name))
for e, n in tqdm(data):
company = matcher.match('company', eid=e).first()
violations = matcher.match('violations', name=str(n)).first()
if company is not None and violations is not None:
relations.append(Relationship(company, '违规类型', violations))
graph.create(Subgraph(relationships=relations))
print('import company-violations relation succeeded')
df = pd.read_csv('company_data/公司-债券.csv')
matcher = NodeMatcher(graph)
eid = df['eid'].values
name = df['bond'].values
relations = []
data = list(zip(eid, name))
for e, n in tqdm(data):
company = matcher.match('company', eid=e).first()
bond = matcher.match('bond', name=str(n)).first()
if company is not None and bond is not None:
relations.append(Relationship(company, '债券类型', bond))
graph.create(Subgraph(relationships=relations))
print('import company-bond relation succeeded')
# df = pd.read_csv('company_data/公司-失信.csv')
# matcher = NodeMatcher(graph)
# eid = df['eid'].values
# rel = df['dishonesty'].values
# relations = []
# data = list(zip(eid, rel))
# for e, r in tqdm(data):
# company = matcher.match('company', eid=e).first()
# dishonesty = matcher.match('dishonesty', name='失信').first()
# if company is not None and dishonesty is not None:
# if pd.notna(r):
# if int(r) == 0:
# relations.append(Relationship(company, '无', dishonesty))
# elif int(r) == 1:
# relations.append(Relationship(company, '有', dishonesty))
#
# graph.create(Subgraph(relationships=relations))
# print('import company-dishonesty relation succeeded')
def import_company_relation():
df = pd.read_csv('company_data/公司-供应商.csv')
matcher = NodeMatcher(graph)
eid1 = df['eid1'].values
eid2 = df['eid2'].values
relations = []
data = list(zip(eid1, eid2))
for e1, e2 in tqdm(data):
if pd.notna(e1) and pd.notna(e2) and e1 != e2:
company1 = matcher.match('company', eid=e1).first()
company2 = matcher.match('company', eid=e2).first()
if company1 is not None and company2 is not None:
relations.append(Relationship(company1, '供应商', company2))
graph.create(Subgraph(relationships=relations))
print('import company-supplier relation succeeded')
df = pd.read_csv('company_data/公司-担保.csv')
matcher = NodeMatcher(graph)
eid1 = df['eid1'].values
eid2 = df['eid2'].values
relations = []
data = list(zip(eid1, eid2))
for e1, e2 in tqdm(data):
if pd.notna(e1) and pd.notna(e2) and e1 != e2:
company1 = matcher.match('company', eid=e1).first()
company2 = matcher.match('company', eid=e2).first()
if company1 is not None and company2 is not None:
relations.append(Relationship(company1, '担保', company2))
graph.create(Subgraph(relationships=relations))
print('import company-guarantee relation succeeded')
df = pd.read_csv('company_data/公司-客户.csv')
matcher = NodeMatcher(graph)
eid1 = df['eid1'].values
eid2 = df['eid2'].values
relations = []
data = list(zip(eid1, eid2))
for e1, e2 in tqdm(data):
if pd.notna(e1) and pd.notna(e2):
company1 = matcher.match('company', eid=e1).first()
company2 = matcher.match('company', eid=e2).first()
if company1 is not None and company2 is not None:
relations.append(Relationship(company1, '客户', company2))
graph.create(Subgraph(relationships=relations))
print('import company-customer relation succeeded')
def delete_relation():
cypher = 'match ()-[r]-() delete r'
graph.run(cypher)
def delete_node():
cypher = 'match (n) delete n'
graph.run(cypher)
def import_data():
import_company()
import_company_relation()
import_person()
import_industry()
import_assign()
import_violations()
import_bond()
# import_dishonesty()
import_relation()
def delete_data():
delete_relation()
delete_node()
print('delete data succeeded')
if __name__ == '__main__':
profit = np.random.randint(100000, 100000000, 10).tolist()
delete_data()
import_data()

create_question_data
from py2neo import Graph
import numpy as np
import pandas as pd
graph = Graph("http://localhost:7474", auth=("neo4j", "qwer"))
# import os
# import py2neo
# default_host = os.environ.get("STELLARGRAPH_NEO4J_HOST")
# graph = py2neo.Graph(host=default_host, port=7687, user='neo4j', password='qwer')
def create_attribute_question():
company = graph.run('MATCH (n:company) RETURN n.name as name').to_ndarray()
person = graph.run('MATCH (n:person) RETURN n.name as name').to_ndarray()
questions = []
for c in company:
c = c[0].strip()
question = f"{c}的收益"
questions.append(question)
question = f"{c}的收入"
questions.append(question)
for p in person:
p = p[0].strip()
question = f"{p}的年龄是几岁"
questions.append(question)
question = f"{p}多大"
questions.append(question)
question = f"{p}几岁"
questions.append(question)
return questions
def create_entity_question():
questions = []
for _ in range(250):
for op in ['大于', '等于', '小于', '是', '有']:
profit = np.random.randint(10000, 10000000, 1)[0]
question = f"收益{op}{profit}的公司有哪些"
questions.append(question)
profit = np.random.randint(10000, 10000000, 1)[0]
question = f"哪些公司收益{op}{profit}"
questions.append(question)
for _ in range(250):
for op in ['大于', '等于', '小于', '是', '有']:
profit = np.random.randint(20, 60, 1)[0]
question = f"年龄{op}{profit}的人有哪些"
questions.append(question)
profit = np.random.randint(20, 60, 1)[0]
question = f"哪些人年龄{op}{profit}"
questions.append(question)
return questions
def create_relation_question():
relation = graph.run('MATCH (n)-[r]->(m) RETURN n.name as name, type(r) as r').to_ndarray()
questions = []
for r in relation:
if str(r[1]) in ['董事', '监事']:
question = f"{r[0]}的{r[1]}是谁"
questions.append(question)
else:
question = f"{r[0]}的{r[1]}"
questions.append(question)
question = f"{r[0]}的{r[1]}是啥"
questions.append(question)
question = f"{r[0]}的{r[1]}什么"
questions.append(question)
return questions
q1 = create_entity_question()
q2 = create_attribute_question()
q3 = create_relation_question()
df = pd.DataFrame()
df['question'] = q1 + q2 + q3
df['label'] = [0] * len(q1) + [1] * len(q2) + [2] * len(q3)
df.to_csv('question_classification.csv', encoding='utf_8_sig', index=False)
data_process
import pandas as pd
import jieba
from collections import defaultdict
import numpy as np
import os
__file__ = 'kbqa'
path = os.path.dirname(__file__)
def tokenize(text, use_jieba=True):
if use_jieba:
res = list(jieba.cut(text, cut_all=False))
else:
res = list(text)
return res
# 构建词典
def build_vocab(del_word_frequency=0):
data = pd.read_csv('question_classification.csv')
segment = data['question'].apply(tokenize)
word_frequency = defaultdict(int)
for row in segment:
for i in row:
word_frequency[i] += 1
word_sort = sorted(word_frequency.items(), key=lambda x: x[1], reverse=True) # 根据词频降序排序
f = open('vocab.txt', 'w', encoding='utf-8')
f.write('[PAD]' + "\n" + '[UNK]' + "\n")
for d in word_sort:
if d[1] > del_word_frequency:
f.write(d[0] + "\n")
f.close()
# 划分训练集和测试集
def split_data(df, split=0.7):
df = df.sample(frac=1)
length = len(df)
train_data = df[0:length - 2000]
eval_data = df[length - 2000:]
return train_data, eval_data
vocab = {}
if os.path.exists(path + '/vocab.txt'):
with open(path + '/vocab.txt', encoding='utf-8')as file:
for line in file.readlines():
vocab[line.strip()] = len(vocab)
# 把数据转换成index
def seq2index(seq):
seg = tokenize(seq)
seg_index = []
for s in seg:
seg_index.append(vocab.get(s, 1))
return seg_index
# 统一长度
def padding_seq(X, max_len=10):
return np.array([
np.concatenate([x, [0] * (max_len - len(x))]) if len(x) < max_len else x[:max_len] for x in X
])
if __name__ == '__main__':
build_vocab(5)

ac_automaton
import ahocorasick
from py2neo import Graph
graph = Graph("http://localhost:7474", auth=("neo4j", "qwer"))
company = graph.run('MATCH (n:company) RETURN n.name as name').to_ndarray()
relation = graph.run('MATCH ()-[r]-() RETURN distinct type(r)').to_ndarray()
ac_company = ahocorasick.Automaton()
ac_relation = ahocorasick.Automaton()
for key in enumerate(company):
ac_company.add_word(key[1][0], key[1][0])
for key in enumerate(relation):
ac_relation.add_word(key[1][0], key[1][0])
ac_company.make_automaton()
ac_relation.make_automaton()
# haystack = '浙江东阳东欣房地产开发有限公司的客户的供应商'
haystack = '衡水中南锦衡房地产有限公司的债券类型'
# haystack = '临沂金丰公社农业服务有限公司的分红方式'
print('question:', haystack)
subject = ''
predicate = []
for end_index, original_value in ac_company.iter(haystack):
start_index = end_index - len(original_value) + 1
print('公司实体:', (start_index, end_index, original_value))
assert haystack[start_index:start_index + len(original_value)] == original_value
subject = original_value
for end_index, original_value in ac_relation.iter(haystack):
start_index = end_index - len(original_value) + 1
print('关系:', (start_index, end_index, original_value))
assert haystack[start_index:start_index + len(original_value)] == original_value
predicate.append(original_value)
for p in predicate:
cypher = f'''match (s:company)-[p:`{p}`]-(o) where s.name='{subject}' return o.name'''
print(cypher)
res = graph.run(cypher).to_ndarray()
# print(res)
subject = res[0][0]
print('answer:', res[0][0])

torch_utils
import torch
import time
import numpy as np
import six
class TrainHandler:
def __init__(self,
train_loader,
valid_loader,
model,
criterion,
optimizer,
model_path,
batch_size=32,
epochs=5,
scheduler=None,
gpu_num=0):
self.train_loader = train_loader
self.valid_loader = valid_loader
self.criterion = criterion
self.optimizer = optimizer
self.model_path = model_path
self.batch_size = batch_size
self.epochs = epochs
self.scheduler = scheduler
if torch.cuda.is_available():
self.device = torch.device(f'cuda:{gpu_num}')
print('Training device is gpu:{gpu_num}')
else:
self.device = torch.device('cpu')
print('Training device is cpu')
self.model = model.to(self.device)
def _train_func(self):
train_loss = 0
train_correct = 0
for i, (x, y) in enumerate(self.train_loader):
self.optimizer.zero_grad()
x, y = x.to(self.device).long(), y.to(self.device)
output = self.model(x)
loss = self.criterion(output, y)
train_loss += loss.item()
loss.backward()
self.optimizer.step()
train_correct += (output.argmax(1) == y).sum().item()
if self.scheduler is not None:
self.scheduler.step()
return train_loss / len(self.train_loader), train_correct / len(self.train_loader.dataset)
def _test_func(self):
valid_loss = 0
valid_correct = 0
for x, y in self.valid_loader:
x, y = x.to(self.device).long(), y.to(self.device)
with torch.no_grad():
output = self.model(x)
loss = self.criterion(output, y)
valid_loss += loss.item()
valid_correct += (output.argmax(1) == y).sum().item()
return valid_loss / len(self.valid_loader), valid_correct / len(self.valid_loader.dataset)
def train(self):
min_valid_loss = float('inf')
for epoch in range(self.epochs):
start_time = time.time()
train_loss, train_acc = self._train_func()
valid_loss, valid_acc = self._test_func()
if min_valid_loss > valid_loss:
min_valid_loss = valid_loss
torch.save(self.model, self.model_path)
print(f'\tSave model done valid loss: {valid_loss:.4f}')
secs = int(time.time() - start_time)
mins = secs / 60
secs = secs % 60
print('Epoch: %d' % (epoch + 1), " | time in %d minutes, %d seconds" % (mins, secs))
print(f'\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)')
print(f'\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)')
def torch_text_process():
from torchtext import data
def tokenizer(text):
import jieba
return list(jieba.cut(text))
TEXT = data.Field(sequential=True, tokenize=tokenizer, lower=True, fix_length=20)
LABEL = data.Field(sequential=False, use_vocab=False)
all_dataset = data.TabularDataset.splits(path='',
train='LCQMC.csv',
format='csv',
fields=[('sentence1', TEXT), ('sentence2', TEXT), ('label', LABEL)])[0]
TEXT.build_vocab(all_dataset)
train, valid = all_dataset.split(0.1)
(train_iter, valid_iter) = data.BucketIterator.splits(datasets=(train, valid),
batch_sizes=(64, 128),
sort_key=lambda x: len(x.sentence1))
return train_iter, valid_iter
def pad_sequences(sequences, maxlen=None, dtype='int32',
padding='post', truncating='pre', value=0.):
"""Pads sequences to the same length.
This function transforms a list of
`num_samples` sequences (lists of integers)
into a 2D Numpy array of shape `(num_samples, num_timesteps)`.
`num_timesteps` is either the `maxlen` argument if provided,
or the length of the longest sequence otherwise.
Sequences that are shorter than `num_timesteps`
are padded with `value` at the end.
Sequences longer than `num_timesteps` are truncated
so that they fit the desired length.
The position where padding or truncation happens is determined by
the arguments `padding` and `truncating`, respectively.
Pre-padding is the default.
# Arguments
sequences: List of lists, where each element is a sequence.
maxlen: Int, maximum length of all sequences.
dtype: Type of the output sequences.
To pad sequences with variable length strings, you can use `object`.
padding: String, 'pre' or 'post':
pad either before or after each sequence.
truncating: String, 'pre' or 'post':
remove values from sequences larger than
`maxlen`, either at the beginning or at the end of the sequences.
value: Float or String, padding value.
# Returns
x: Numpy array with shape `(len(sequences), maxlen)`
# Raises
ValueError: In case of invalid values for `truncating` or `padding`,
or in case of invalid shape for a `sequences` entry.
"""
if not hasattr(sequences, '__len__'):
raise ValueError('`sequences` must be iterable.')
num_samples = len(sequences)
lengths = []
for x in sequences:
try:
lengths.append(len(x))
except TypeError:
raise ValueError('`sequences` must be a list of iterables. '
'Found non-iterable: ' + str(x))
if maxlen is None:
maxlen = np.max(lengths)
# take the sample shape from the first non empty sequence
# checking for consistency in the main loop below.
sample_shape = tuple()
for s in sequences:
if len(s) > 0:
sample_shape = np.asarray(s).shape[1:]
break
is_dtype_str = np.issubdtype(dtype, np.str_) or np.issubdtype(dtype, np.unicode_)
if isinstance(value, six.string_types) and dtype != object and not is_dtype_str:
raise ValueError("`dtype` {} is not compatible with `value`'s type: {}\n"
"You should set `dtype=object` for variable length strings."
.format(dtype, type(value)))
x = np.full((num_samples, maxlen) + sample_shape, value, dtype=dtype)
for idx, s in enumerate(sequences):
if not len(s):
continue # empty list/array was found
if truncating == 'pre':
trunc = s[-maxlen:]
elif truncating == 'post':
trunc = s[:maxlen]
else:
raise ValueError('Truncating type "%s" '
'not understood' % truncating)
# check `trunc` has expected shape
trunc = np.asarray(trunc, dtype=dtype)
if trunc.shape[1:] != sample_shape:
raise ValueError('Shape of sample %s of sequence at position %s '
'is different from expected shape %s' %
(trunc.shape[1:], idx, sample_shape))
if padding == 'post':
x[idx, :len(trunc)] = trunc
elif padding == 'pre':
x[idx, -len(trunc):] = trunc
else:
raise ValueError('Padding type "%s" not understood' % padding)
return x
if __name__ == '__main__':
torch_text_process()
text_cnn
import torch
from torch import nn
class TextCNN(nn.Module):
def __init__(self, vocab_len, embedding_size, n_class):
super().__init__()
self.embedding = nn.Embedding(vocab_len, embedding_size)
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=100, kernel_size=[3, embedding_size])
self.cnn2 = nn.Conv2d(in_channels=1, out_channels=100, kernel_size=[4, embedding_size])
self.cnn3 = nn.Conv2d(in_channels=1, out_channels=100, kernel_size=[5, embedding_size])
self.max_pool1 = nn.MaxPool1d(kernel_size=8)
self.max_pool2 = nn.MaxPool1d(kernel_size=7)
self.max_pool3 = nn.MaxPool1d(kernel_size=6)
self.drop_out = nn.Dropout(0.2)
self.full_connect = nn.Linear(300, n_class)
def forward(self, x):
embedding = self.embedding(x)
embedding = embedding.unsqueeze(1)
cnn1_out = self.cnn1(embedding).squeeze(-1)
cnn2_out = self.cnn2(embedding).squeeze(-1)
cnn3_out = self.cnn3(embedding).squeeze(-1)
out1 = self.max_pool1(cnn1_out)
out2 = self.max_pool2(cnn2_out)
out3 = self.max_pool3(cnn3_out)
out = torch.cat([out1, out2, out3], dim=1).squeeze(-1)
out = self.drop_out(out)
out = self.full_connect(out)
# out = torch.softmax(out, dim=-1).squeeze(dim=-1)
return out
train
import torch
from torch.utils.data import TensorDataset, DataLoader
from kbqa.torch_utils import TrainHandler
from kbqa.data_process import *
from kbqa.text_cnn import TextCNN
# df = pd.read_csv('question_classification.csv')
# print(df['label'].value_counts())
def load_data(batch_size=32):
df = pd.read_csv('kbqa/question_classification.csv')
train_df, eval_df = split_data(df)
train_x = df['question']
train_y = df['label']
valid_x = eval_df['question']
valid_y = eval_df['label']
train_x = padding_seq(train_x.apply(seq2index))
train_y = np.array(train_y)
valid_x = padding_seq(valid_x.apply(seq2index))
valid_y = np.array(valid_y)
train_data_set = TensorDataset(torch.from_numpy(train_x),
torch.from_numpy(train_y))
valid_data_set = TensorDataset(torch.from_numpy(valid_x),
torch.from_numpy(valid_y))
train_data_loader = DataLoader(dataset=train_data_set, batch_size=batch_size, shuffle=True)
valid_data_loader = DataLoader(dataset=valid_data_set, batch_size=batch_size, shuffle=True)
return train_data_loader, valid_data_loader
train_loader, valid_loader = load_data(batch_size=64)
model = TextCNN(1289, 256, 3)# 原model = TextCNN(1141, 256, 3),1289根据vocat.txt行数
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)
model_path = 'text_cnn.p'
handler = TrainHandler(train_loader,valid_loader,model,
criterion,
optimizer,
model_path,
batch_size=32,
epochs=5,
scheduler=None,
gpu_num=0)
handler.train()
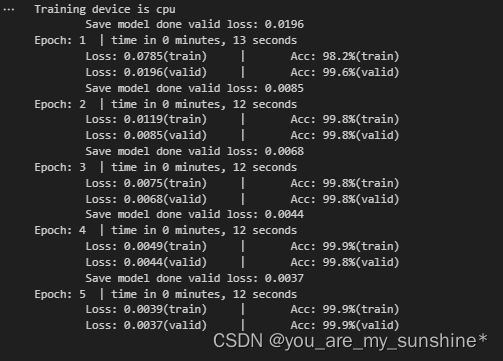
main
import torch
from kbqa.data_process import *
import ahocorasick
from py2neo import Graph
import re
import traceback
model = torch.load('kbqa/text_cnn.p', map_location=torch.device('cpu'))
model.eval()
graph = Graph("http://localhost:7474", auth=("neo4j", "qwer"))
company = graph.run('MATCH (n:company) RETURN n.name as name').to_ndarray()
person = graph.run('MATCH (n:person) RETURN n.name as name').to_ndarray()
relation = graph.run('MATCH ()-[r]-() RETURN distinct type(r)').to_ndarray()
ac_company = ahocorasick.Automaton()
ac_person = ahocorasick.Automaton()
ac_relation = ahocorasick.Automaton()
for key in enumerate(company):
ac_company.add_word(key[1][0], key[1][0])
for key in enumerate(person):
ac_person.add_word(key[1][0], key[1][0])
for key in enumerate(relation):
ac_relation.add_word(key[1][0], key[1][0])
ac_relation.add_word('年龄', '年龄')
ac_relation.add_word('年纪', '年纪')
ac_relation.add_word('收入', '收入')
ac_relation.add_word('收益', '收益')
ac_company.make_automaton()
ac_person.make_automaton()
ac_relation.make_automaton()
def classification_predict(s):
s = seq2index(s)
s = torch.from_numpy(padding_seq([s])).long() #.cuda().long()
out = model(s)
out = out.cpu().data.numpy()
print(out)
return out.argmax(1)[0]
def entity_link(text):
subject = []
subject_type = None
for end_index, original_value in ac_company.iter(text):
start_index = end_index - len(original_value) + 1
print('实体:', (start_index, end_index, original_value))
assert text[start_index:start_index + len(original_value)] == original_value
subject.append(original_value)
subject_type = 'company'
for end_index, original_value in ac_person.iter(text):
start_index = end_index - len(original_value) + 1
print('实体:', (start_index, end_index, original_value))
assert text[start_index:start_index + len(original_value)] == original_value
subject.append(original_value)
subject_type = 'person'
return subject[0], subject_type
def get_op(text):
pattern = re.compile(r'\d+')
num = pattern.findall(text)
op = None
if '大于' in text:
op = '>'
elif '小于' in text:
op = '<'
elif '等于' in text or '是' in text:
op = '='
return op, float(num[0])
def kbqa(text):
print('*' * 100)
cls = classification_predict(text)
print('question type:', cls)
res = ''
if cls == 0:
op, num = get_op(text)
subject_type = ''
attribute = ''
for w in ['年龄', '年纪']:
if w in text:
subject_type = 'person'
attribute = 'age'
break
for w in ['收入', '收益']:
if w in text:
subject_type = 'company'
attribute = 'profit'
break
cypher = f'match (n:{subject_type}) where n.{attribute}{op}{num} return n.name'
print(cypher)
res = graph.run(cypher).to_ndarray()
elif cls == 1:
# 查询属性
subject, subject_type = entity_link(text)
predicate = ''
for w in ['年龄', '年纪']:
if w in text and subject_type == 'person':
predicate = 'age'
break
for w in ['收入', '收益']:
if w in text and subject_type == 'company':
predicate = 'profit'
break
cypher = f'''match (n:{subject_type}) where n.name='{subject}' return n.{predicate}'''
print(cypher)
res = graph.run(cypher).to_ndarray()
elif cls == 2:
subject = ''
for end_index, original_value in ac_company.iter(text):
start_index = end_index - len(original_value) + 1
print('公司实体:', (start_index, end_index, original_value))
assert text[start_index:start_index + len(original_value)] == original_value
subject = original_value
predicate = []
for end_index, original_value in ac_relation.iter(text):
start_index = end_index - len(original_value) + 1
print('关系:', (start_index, end_index, original_value))
assert text[start_index:start_index + len(original_value)] == original_value
predicate.append(original_value)
for i, p in enumerate(predicate):
cypher = f'''match (s:company)-[p:`{p}`]->(o) where s.name='{subject}' return o.name'''
print(cypher)
res = graph.run(cypher).to_ndarray()
subject = res[0][0]
if i == len(predicate) - 1:
break
new_index = text.index(p) + len(p)
new_question = subject + str(text[new_index:])
print('new question:', new_question)
res = kbqa(new_question)
break
return res
if __name__ == '__main__':
while 1:
try:
text = input('text:')
res = kbqa(text)
print(res)
except:
print(traceback.format_exc())
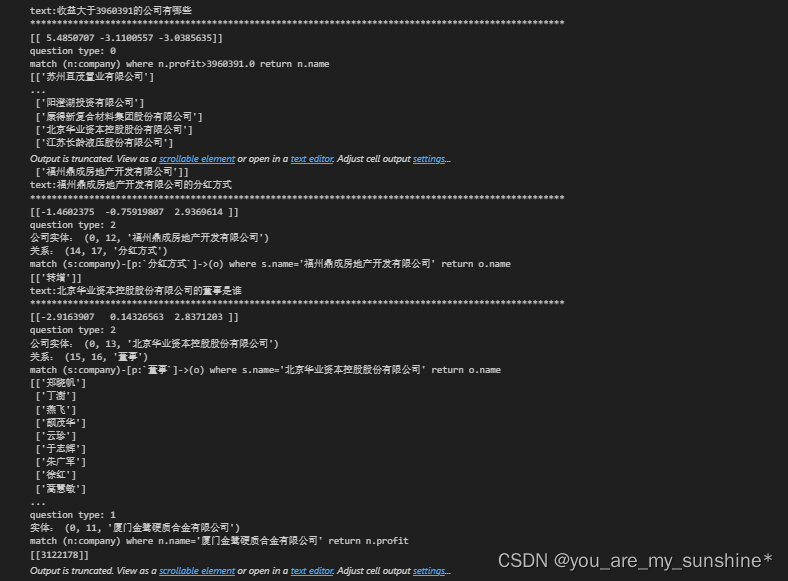
图谱问答实战小结
模型的整体结构:ac自动机+找实体+多跳问答
ps:这里实体没有多个,用不到实体消歧,这里我们使用的是匹配的方法
学习的参考资料:
七月在线NLP高级班
代码参考:
https://github.com/terrifyzhao/neo4j_graph