知识点:
散列函数
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位:
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a*key + b,其中a和b为常数(这种散列函数叫做自身函数)
2. 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3. 平方取中法:取关键字平方后的中间几位作为散列地址。
4. 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。通常针对较长的关键字。
5. 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
6. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
查找效率
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1. 散列函数是否均匀;
2. 处理冲突的方法;
3. 散列表的装填因子。
散列表的装填因子定义为:α= 填入表中的元素个数 / 散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。
实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。
加法哈希:
常用于字符串,将字符串中的每个字符转换为其对应的 ASCII 值,然后进行加法运算来生成哈希值。
int hash(char* str) {
int hashValue = 0;
for (int i = 0; str[i] != '\0'; i++) {
hashValue += str[i];
}
return hashValue;
}
这里使用了一个简单的散列函数,它是一个基于质数的乘法散列函数。具体来说,散列函数的实现如下:
//对字符串进行哈希
int hash(char* str) {
int hashValue = 0;
for (int i = 0; str[i] != '\0'; i++) {
hashValue = (hashValue * PRIME + str[i]) % 1000007;
}
return hashValue;
}在这里,PRIME 是一个选择的质数,它有助于减少碰撞。我们遍历字符串的每个字符,并用它们更新 hashValue。由于我们对 hashValue 取模 1000007,所以返回的散列值会在 0 到 1000006 之间。
位运算哈希:
先移位,然后再进行各种位运算是这种类型Hash函数的主要特点。
int bitHash(char* str) {
int hashValue = 0;
for (int i = 0; str[i] != '\0'; i++) {
hashValue = (hashValue << 5) + str[i] ^ hashValue;
}
return hashValue;
}乘法哈希:
利用了乘法的不相关性(乘法的这种性质,最有名的莫过于平方取头尾的随机数生成算法,虽然这种算法效果并不好)。
FNV(Fowler–Noll–Vo)哈希算法是一个著名的乘法哈希算法,常用于字符串哈希。它是一种非常简单但效果很好的哈希算法。
#include <stdint.h>
uint32_t fnv1a(char* str) {
uint32_t hash = 2166136261u; // FNV偏移基础值
while (*str) {
hash ^= (unsigned char)*str++;
hash *= 16777619u; // FNV素数
}
return hash;
}
字符串操作:
#include<string.h>
字符串复制
strdup 是一个 C 语言函数,用于复制一个字符串。
strdup 函数会分配足够的内存来存储传入的字符串,并将原始字符串复制到新分配的内存中。然后返回指向新分配的字符串的指针。
char* copy = strdup(str);
free(copy);
strdup 可以用于创建字符串的副本,以便稍后使用和修改,而不影响原始字符串。
将malloc和赋值操作合二为一
排序:
void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));
base:指向要排序的数组的指针。nmemb:数组中元素的数量。size:数组中每个元素的大小(以字节为单位)。compar:用于比较两个元素的函数的指针。
int compare(const void* a, const void* b) {
return *(char*)a - *(char*)b;
} char* str1 = strdup(strs[i]);
int len = strlen(str1);
//对 str1 中的字符进行排序,这样,具有相同字符的异位词会有相同的排序后的字符串。
qsort(str1, len, sizeof(char), compare);暴力求解:
超出时间限制。
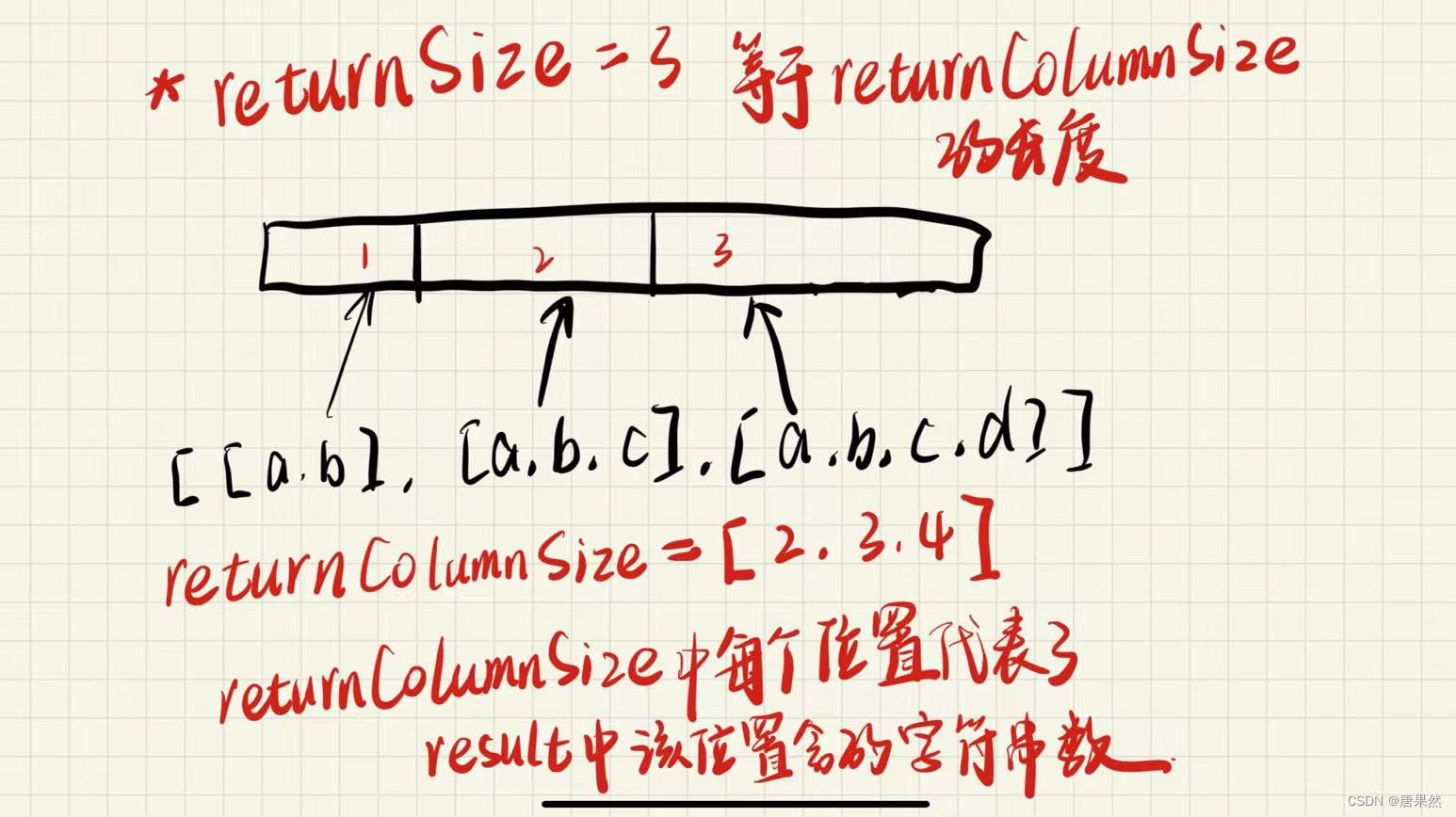
*returnSize记录最终数组有多少个。
returnColumnSize记录最终数组中,每个数组的长度。一维数组。
result[*returnSize] = (char**)malloc(strsSize * sizeof(char*));
(*returnColumnSizes)[*returnSize] = 0;
result[*returnSize][(*returnColumnSizes)[*returnSize]] = strs[i];
(*returnColumnSizes)[*returnSize] += 1;
/**
* Return an array of arrays of size *returnSize.
* The sizes of the arrays are returned as *returnColumnSizes array.
* Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int compare(const void* a, const void* b) {
return *(char*)a - *(char*)b;
}
char*** groupAnagrams(char** strs, int strsSize, int* returnSize, int** returnColumnSizes) {
//记录strs中哪个词被找过了
int* countstrs = (int*)malloc(strsSize * sizeof(int));
//全置为0
memset(countstrs, 0, strsSize * sizeof(int));
*returnSize = 0;
char*** result = (char***)malloc(strsSize * sizeof(char**));
*returnColumnSizes = (int*)malloc(strsSize * sizeof(int));
for (int i = strsSize-1; i >=0; i--) {
if (countstrs[i] == 1) continue;
char* str1 = strdup(strs[i]);
int len = strlen(str1);
//对 str1 中的字符进行排序,这样,具有相同字符的异位词会有相同的排序后的字符串。
qsort(str1, len, sizeof(char), compare);
result[*returnSize] = (char**)malloc(strsSize * sizeof(char*));
(*returnColumnSizes)[*returnSize] = 0;
result[*returnSize][(*returnColumnSizes)[*returnSize]] = strs[i];
(*returnColumnSizes)[*returnSize] += 1;
countstrs[i] = 1;
for (int z = i-1; z >=0; z--) {
if (countstrs[z] == 1) continue;
char* str2 = strdup(strs[z]);
if (len != strlen(str2)) {
free(str2);
continue;
}
qsort(str2, len, sizeof(char), compare);
//现在都顺序排列了
int flag=0;
for (int j = 0; j < len; j++) {
if (str1[j] == str2[j] ) {
flag++;
}
else
break;
}
if (flag==len) {
result[*returnSize][(*returnColumnSizes)[*returnSize]] = strs[z];
(*returnColumnSizes)[*returnSize] += 1;
countstrs[z] = 1;
}
free(str2);
}
*returnSize += 1;
free(str1);
}
free(countstrs);
return result;
}哈希:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define PRIME 31
typedef struct Node {
char* key;
char** values;
int count;
struct Node* next;
} Node;
int compare(const void* a, const void* b) {
return *(char*)a - *(char*)b;
}
//对字符串进行哈希
int hash(char* str) {
int hashValue = 0;
for (int i = 0; str[i] != '\0'; i++) {
hashValue = (hashValue * PRIME + str[i]) % 1000007;
}
return hashValue;
}
Node* createNode(char* key, char* value) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->key = strdup(key);
newNode->values = (char**)malloc(1000 * sizeof(char*));
newNode->values[0] = strdup(value);
newNode->count = 1;
newNode->next = NULL;
return newNode;
}
Node** createHashMap(int size) {
Node** table = (Node**)malloc(size * sizeof(Node*));
for (int i = 0; i < size; i++) {
table[i] = NULL;
}
return table;
}
void insert(Node** table, char* key, char* value, int size) {
int index = hash(key) % size;
if (table[index] == NULL) {
table[index] = createNode(key, value);
return;
}
Node* current = table[index];
while (current->next != NULL) {
if (strcmp(current->key, key) == 0) {
current->values[current->count++] = strdup(value);
return;
}
current = current->next;
}
if (strcmp(current->key, key) == 0) {
current->values[current->count++] = strdup(value);
} else {
current->next = createNode(key, value);
}
}
char*** groupAnagrams(char** strs, int strsSize, int* returnSize, int** returnColumnSizes) {
*returnSize = 0;
Node** hashMap = createHashMap(1000007);
*returnColumnSizes = (int*)malloc(strsSize * sizeof(int));
char*** result = (char***)malloc(strsSize * sizeof(char**));
for (int i = 0; i < strsSize; i++) {
char* sortedStr = strdup(strs[i]);
qsort(sortedStr, strlen(sortedStr), sizeof(char), compare);
insert(hashMap, sortedStr, strs[i], 1000007);
free(sortedStr);
}
for (int i = 0; i < 1000007; i++) {
Node* current = hashMap[i];
while (current != NULL) {
result[*returnSize] = (char**)malloc(current->count * sizeof(char*));
for (int j = 0; j < current->count; j++) {
result[*returnSize][j] = strdup(current->values[j]);
}
(*returnColumnSizes)[*returnSize] = current->count;
(*returnSize)++;
current = current->next;
}
}
for (int i = 0; i < 1000007; i++) {
Node* current = hashMap[i];
while (current != NULL) {
for (int j = 0; j < current->count; j++) {
free(current->values[j]);
}
free(current->values);
Node* temp = current;
current = current->next;
free(temp->key);
free(temp);
}
}
free(hashMap);
return result;
}