目录
一、Kafka 工作流程及文件存储机制
二、数据可靠性保证
三 、数据一致性问题
3.1follower 故障
3.2leader 故障
四、ack 应答机制
五、部署Filebeat+Kafka+ELK
5.1环境准备
5.2部署ELK
5.2.1部署 Elasticsearch 软件
5.2.1.1修改elasticsearch主配置文件
5.2.1.2启动elasticsearch是否成功开启
5.2.1.3安装 Elasticsearch-head 插件
5.2.1.3.1编译安装 node
5.2.1.3.2安装 phantomjs(前端的框架)
5.2.1.3.3安装 Elasticsearch-head 数据可视化工具
5.2.1.3.4启动 elasticsearch-head 服务
5.2.2ELK-Logstash部署(在Apache节点上操作)
5.2.1.1安装Apahce服务(httpd)
5.2.1.2安装Java环境
5.2.1.3安装logstash
5.2.1.4测试 Logstash
5.2.3ELK Kiabana 部署(在 Node1 节点上操作)
安装Kibana
设置 Kibana 的主配置文件
启动 Kibana 服务
验证 Kibana
5.3ELFK(Filebeat+ELK)
5.3.1设置 filebeat 的主配置文件
5.3.2在logstash组件所在节点(apache节点)上新建一个logstash配置文件
5.4zookeeper集群部署
5.5部署 Zookeeper+Kafka 集群
5.6部署 Filebeat
5.7 修改Logstash节点配置并启动
一、Kafka 工作流程及文件存储机制
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。
Producer 生产的数据会被不断追加到该 log 文件末端,且每条数据都有自己的 offset。
消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,
Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment
每个 segment 对应两个文件:“.index” 文件和 “.log” 文件。
这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如,test 这个 topic 有三个分区, 则其对应的文件夹为 test-0、test-1、test-2。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。
“.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
二、数据可靠性保证
- 为保证 producer 发送的数据,能可靠的发送到指定的 topic,
- topic 的每个 partition 收到 producer 发送的数据后, 都需要向 producer 发送 ack(acknowledgement 确认收到)
- 如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
三 、数据一致性问题
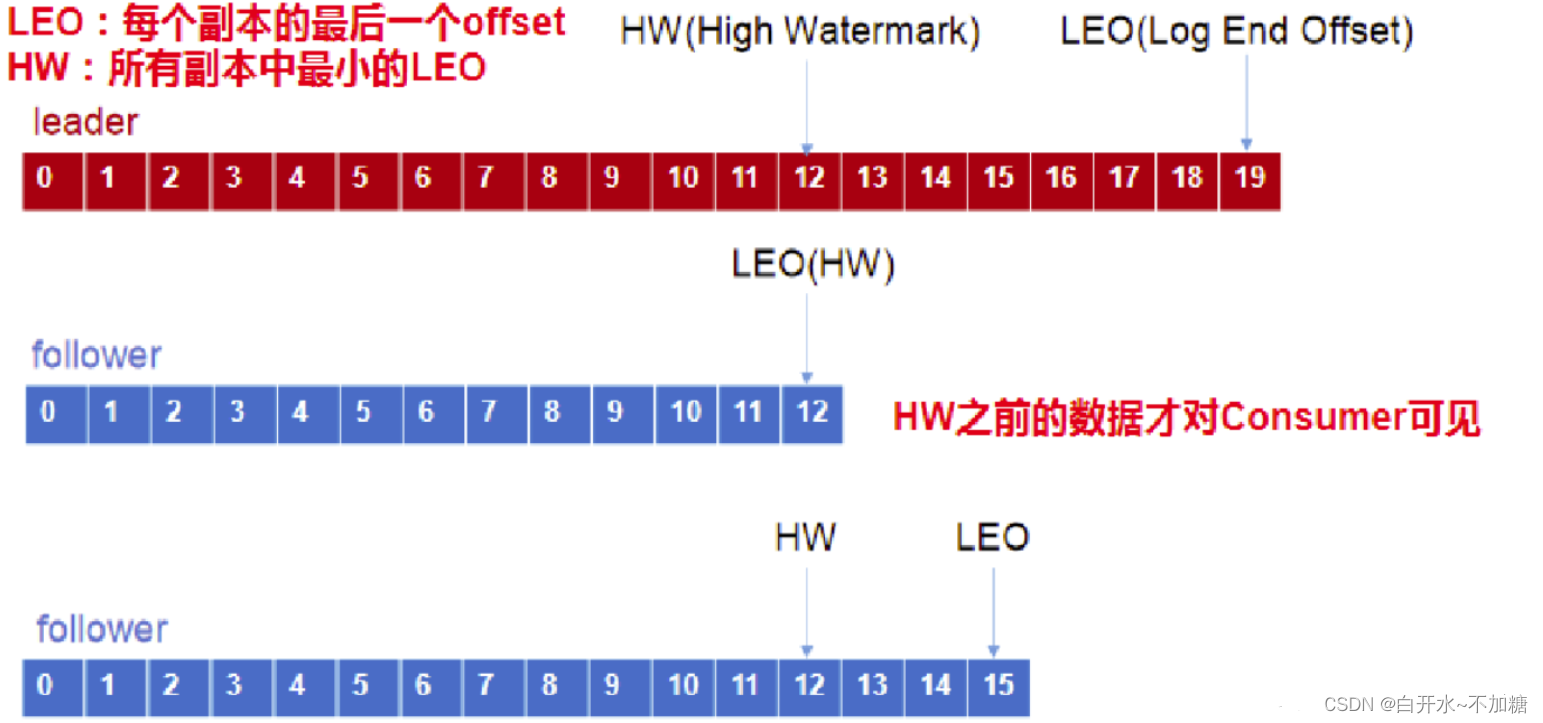
LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,所有副本中最小的 LEO。
3.1follower 故障
follower 发生故障后会被临时踢出 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合),待该 follower 恢复后,follower 会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
3.2leader 故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader, 之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。
注:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
四、ack 应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。
所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡选择。
当 producer 向 leader 发送数据时,可以通过 request.required.acks 参数来设置数据可靠性的级别:
- 0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。
这种情况下数据传输效率最高,但是数据可靠性确是最低的。当broker故障时有可能丢失数据。
- 1(默认配置):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。
如果在follower同步成功之前leader故障,那么将会丢失数据。
- -1(或者是all):producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高
但是如果在 follower 同步完成后,broker 发送ack 之前,leader 发生故障,那么会造成数据重复。
三种机制性能依次递减,数据可靠性依次递增。
注:在 0.11 版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。在 0.11 及以后版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据, Server 端都只会持久化一条
五、部署Filebeat+Kafka+ELK
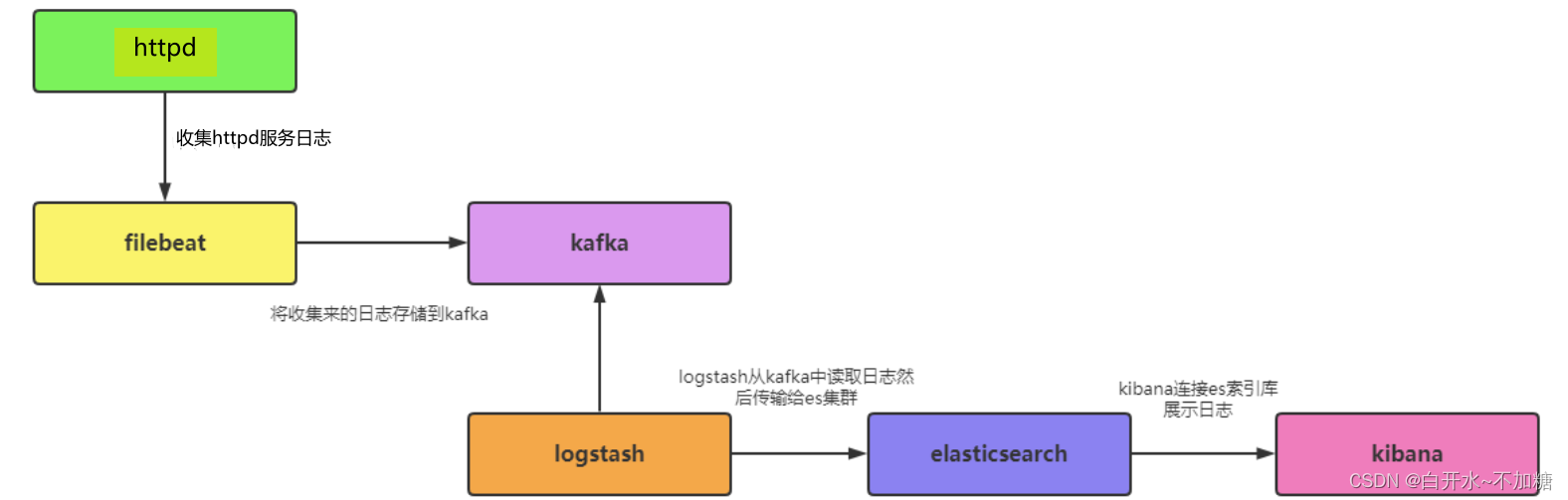
数据流向

5.1环境准备
| 服务器 | 配置 | 主机名 | ip地址 | 主要软件部署 |
|---|---|---|---|---|
| node1节点 | 2C/4G | node1 | 192.168.246.8 | ElasticSearch、Kibana、Zookeeper、Kafka |
| node2节点 | 2C/4G | node2 | 192.168.246.12 | ElasticSearch、Zookeeper、Kafka |
| logstash节点 | 2C/4G | apache | 192.168.246.10 | Logstash、Apache、Zookeeper、Kafka |
| filebeat节点 | - | filebeat | 192.168.246.11 | Filebeat、Zookeeper、Kafka |
5.2部署ELK
systemctl stop firewalld
setenforce 0
hostnamectl set-hostname node2
hostnamectl set-hostname node1由于原来的7-3虚拟机损坏,换一台7-6虚拟机做node2
5.2.1部署 Elasticsearch 软件
192.168.246.8和192.168.246.12机器安装 elasticsearch-5.5.0.rpm
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm 

5.2.1.1修改elasticsearch主配置文件
systemctl daemon-reload
systemctl enable elasticsearch.service
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml vim /etc/elasticsearch/elasticsearch.yml
---------------------------------------
##17行,取消注释,指定群集名称cluster.name: my-elk-cluster
##23行,取消注释,指定节点名称(node1节点为node1,node2节点为node2)node.name: node1
##33行,取消注释,指定数据存放路径path.data: /data/elk_data
##37行,取消注释,指定日志存放路径path.logs: /var/log/elasticsearch/
##43行,取消注释,改为在启动的时候不锁定内存,开启为truebootstrap.memory_lock: false
##55行,取消注释,设置监听地址,0.0.0.0代表所有地址network.host: 0.0.0.0
##59行,取消注释,ES服务的默认监听端口为9200http.port: 9200
##68行,取消注释,集群发现通过单播实现,指定要发现的节点node1、node2discovery.zen.ping.unicast.hosts: ["node1", "node2"]

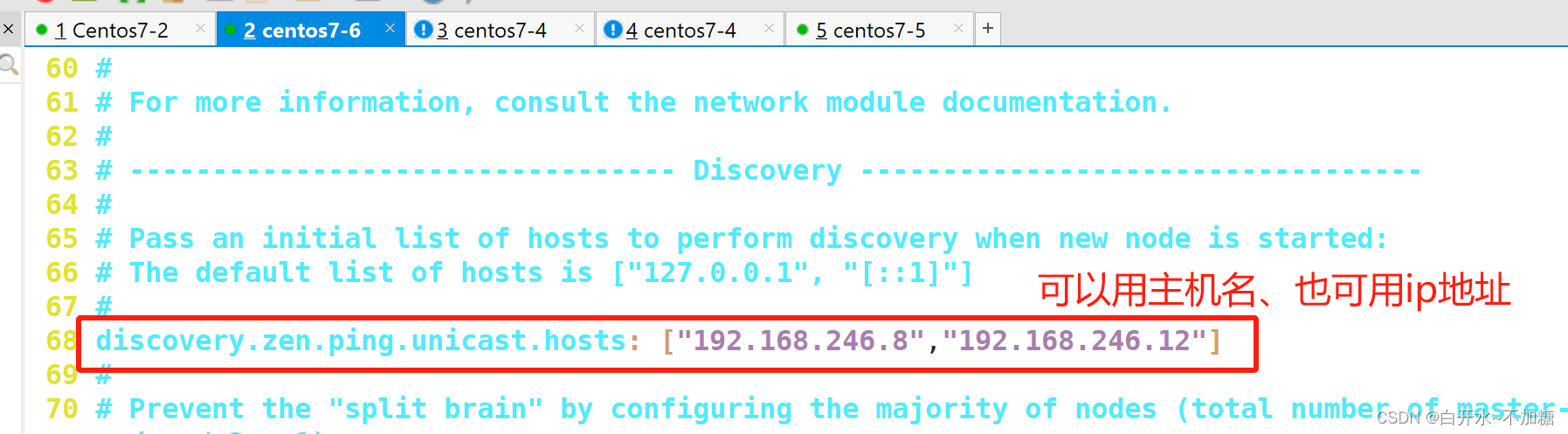
5.2.1.2启动elasticsearch是否成功开启
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
systemctl start elasticsearch.service
netstat -natp| grep 9200
浏览器访问
浏览器访问
http://192.168.246.8:9200 和http://192.168.246.9:9200 查看节点 Node1、Node2 的信息。
----------------------------------------
浏览器访问
http://192.168.246.8:9200/_cluster/health?pretty http://192.168.246.9:9200/_cluster/health?pretty
#查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。由于原来的7-3虚拟机损坏,换一台7-6虚拟机做node2
5.2.1.3安装 Elasticsearch-head 插件
方便好看的清晰
只需要安装一台,此处在node1上安装
5.2.1.3.1编译安装 node
#上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make -j 4 && make install5.2.1.3.2安装 phantomjs(前端的框架)
以node1为例

cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin/
cp phantomjs /usr/local/bin/5.2.1.3.3安装 Elasticsearch-head 数据可视化工具
cd /opt
tar xf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head
npm installvim /etc/elasticsearch/elasticsearch.yml
---------------------------------
G到配置文件末尾,添加以下内容
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有
--------------------------------
systemctl restart elasticsearch.service
systemctl restart elasticsearch.service
ss -natp|grep 9200
5.2.1.3.4启动 elasticsearch-head 服务
cd /usr/local/src/elasticsearch-head/
npm run start &
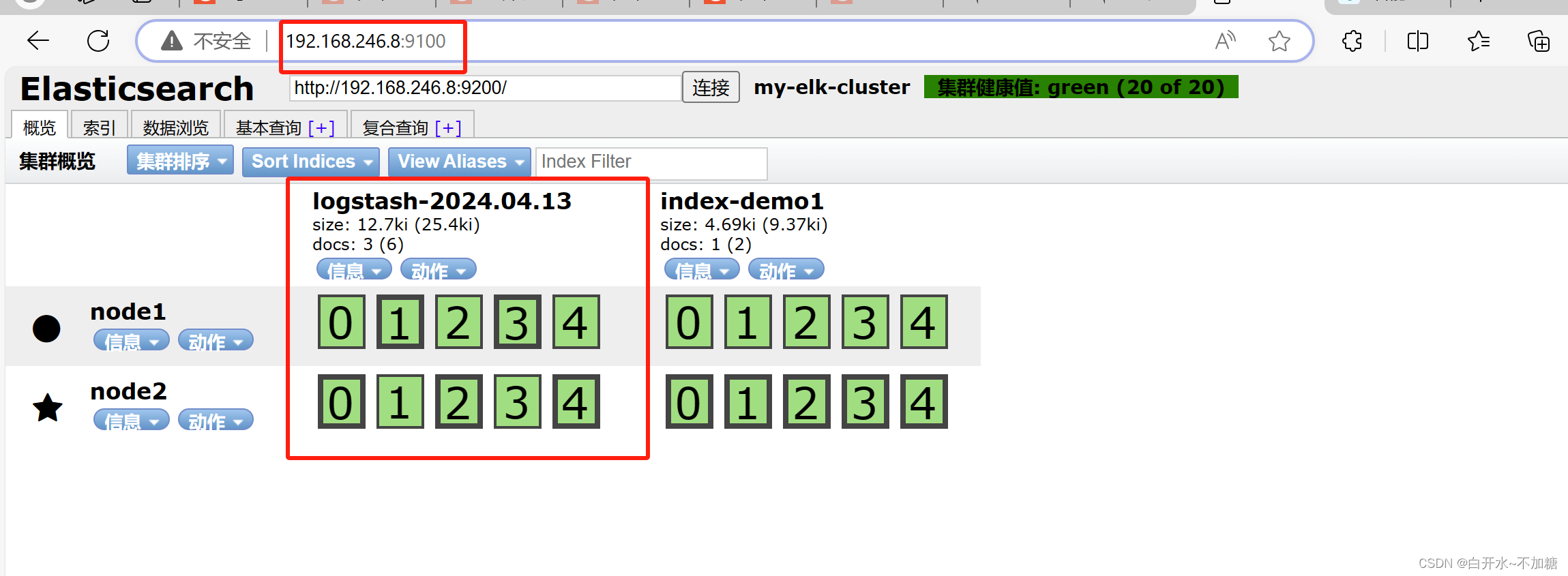
netstat -natp |grep 9100通过浏览器输入http://192.168.246.8:9100/ 去访问,然后Elasticsearch 输入下面网址访问http://192.168.246.8:9200/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康

curl -X PUT 'localhost:9200/index-demo1/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
5.2.2ELK-Logstash部署(在Apache节点上操作)

hostnamectl set-hostname apache5.2.1.1安装Apahce服务(httpd)
yum install httpd -y
systemctl start httpd5.2.1.2安装Java环境
java -version
如果没有jdk就yum -y install java 安装5.2.1.3安装logstash
#上传软件包 logstash-5.5.1.rpm 到/opt目录下
cd /opt
---------------------------
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/5.2.1.4测试 Logstash
参考之前文章
5.2.3ELK Kiabana 部署(在 Node1 节点上操作)
安装Kibana
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm
cp /etc/kibana/kibana.yml /etc/kibana/kibana.yml.bak
vim /etc/kibana/kibana.yml设置 Kibana 的主配置文件
##2行,取消注释,kibana服务的默认监听端口为5601
server.port: 5601
##7行,取消注释,设置kibana的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
##21行,取消注释,设置和ES建立连接的地址和端口
elasticsearch.url: "http://192.168.246.8:9200"
##30行,取消注释,设置在ES中添加.kibana索引
kibana.index: ".kibana"启动 Kibana 服务
systemctl start kibana.service
systemctl enable kibana.service验证 Kibana
浏览器访问 http://192.168.246.8:5601

5.3ELFK(Filebeat+ELK)
在ELK的基础上,增加一台filebeat服务器,因此只需再前述ELK部署的前提下进一步操作
hostnamectl set-hostname filebeat
su
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
5.3.1设置 filebeat 的主配置文件
cp /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml.bak
vim /etc/filebeat/filebeat.ymlfilebeat节点
cd /usr/local/filebeat/
cp filebeat.yml filebeat.yml.bak
vim filebeat.yml
-----------------
filebeat.prospectors:
##21行,指定log类型,从日志文件中读取消息- type: log
##24行,开启日志收集功能,默认为false enabled: true
##28行,指定监控的日志文件 - /var/log/*.log
##29行,添加收集/var/log/messages - /var/log/messages
##31行,添加以下内容,注意格式
fields:
service_name: filebeat
log_type: log
service_id: 192.168.246.11
#-------------------------- Elasticsearch output ------------------------------
该区域内容全部注释
#----------------------------- Logstash output --------------------------------
##157行,取消注释output.logstash:
##159行,取消注释,指定logstash的IP和端口号 hosts: ["192.168.246.10:5044"]
./filebeat -e -c filebeat.yml
#启动filebeat,-e记录到stderr并禁用syslog /文件输出,-c指定配置文件
其它修改参见如上
5.3.2在logstash组件所在节点(apache节点)上新建一个logstash配置文件
(apache节点)
cd /etc/logstash/conf.d/
vim logstash.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.246.8:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
systemctl restart logstash.service
/usr/share/logstash/bin/logstash -f logstash.conf

5.4zookeeper集群部署
参考之前文章
192.168.246.8和192.168.246.12和192.168.246.10三台机器都要搭建zookeeper

5.5部署 Zookeeper+Kafka 集群
参考之前文章
192.168.246.8和192.168.246.12和192.168.246.10三台机器都要搭建 Zookeeper+Kafka
(架构在搭好Zookeeper集群之上继续搭建)


当生产者发布数据,和消费者消费数据不是同时开,顺序可能会有出入,例如

5.6部署 Filebeat
要搭建ELK,可见之前的文章,接着写
修改Filebeat节点配置并启动
mv filebeat.yml filebeat.yml.qian
cp filebeat.yml.bak filebeat.yml
vim filebeat.yml

cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/httpd/access_log
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/httpd/error_log
tags: ["error"]#添加输出到 Kafka 的配置
output.kafka:
enabled: true
hosts: ["192.168.246.8:9092","192.168.246.12:9092","192.168.246.10:9092"]
#指定 Kafka 集群配置
topic: "httpd" #指定 Kafka 的 topic添加输出到 Kafka 的配置

output.kafka:
enabled: true
hosts: ["192.168.246.8:9092,192.168.246.12:9092,192.168.246.10:9092"]
topic: "httpd"
启动filebeat
#启动 filebeat
./filebeat -e -c filebeat.yml由于使用rpm安装,直接systemctl 启动就好
5.7 修改Logstash节点配置并启动
部署 ELK在 Logstash 组件所在节点上新建一个 Logstash 配置文件
Logstash节点配置
cd /etc/logstash/conf.d/
vim kafka.conf
--------------------------------------------
input {
kafka {
bootstrap_servers =>"192.168.246.8:9092,192.168.246.12:9092,192.168.246.10:9092"
#kafka集群地址
topics => "httpd" #拉取的kafka的指定topic
type => "httpd_kafka" #指定 type 字段
codec => "json" #解析json格式的日志数据
auto_offset_reset => "latest" #拉取最近数据,earliest为从头开始拉取
decorate_events => true #传递给elasticsearch的数据额外增加kafka的属性数据
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.246.8:9200"]
index => "httpd_access-%{+YYYY.MM.dd}"
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.246.8:9200"]
index => "httpd_error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
-------------------------------------
#启动 logstash
logstash -f kafka.conf

input {
kafka {
bootstrap_servers => "192.168.246.8:9092,192.168.246.12:9092,192.168.246.10:9092"
topics => "httpd"
type => "httpd_kafka"
codec => "json"
auto_offset_reset => "latest"
decorate_events => true
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.246.8:9200"]
index => "httpd_access-%{+YYYY.MM.dd}"
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.246.8:9200"]
index => "httpd_error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
收集日志查看日志
注:生产黑屏操作es时查看所有的索引:curl -X GET "localhost:9200/_cat/indices?v"


直接虚拟机查看有没有索引
生产黑屏操作es时查看所有的索引:curl -X GET "localhost:9200/_cat/indices?v"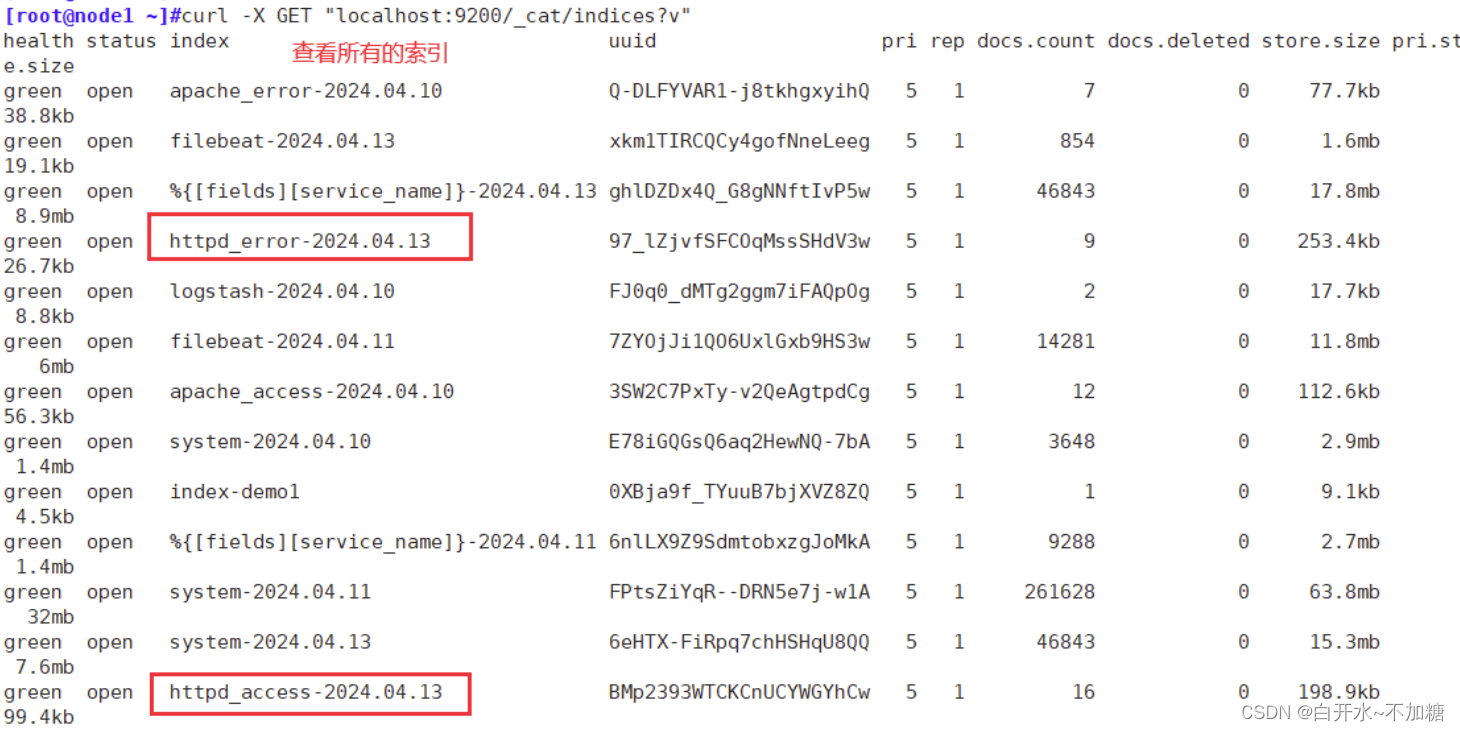
浏览器访问 http://192.168.246.8:9100 登录查看索引

上面两个意思一样,可以文字浏览器查看,也可以直接浏览器查看索引是否有
浏览器访问 http://192.168.246.8:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat_test-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。

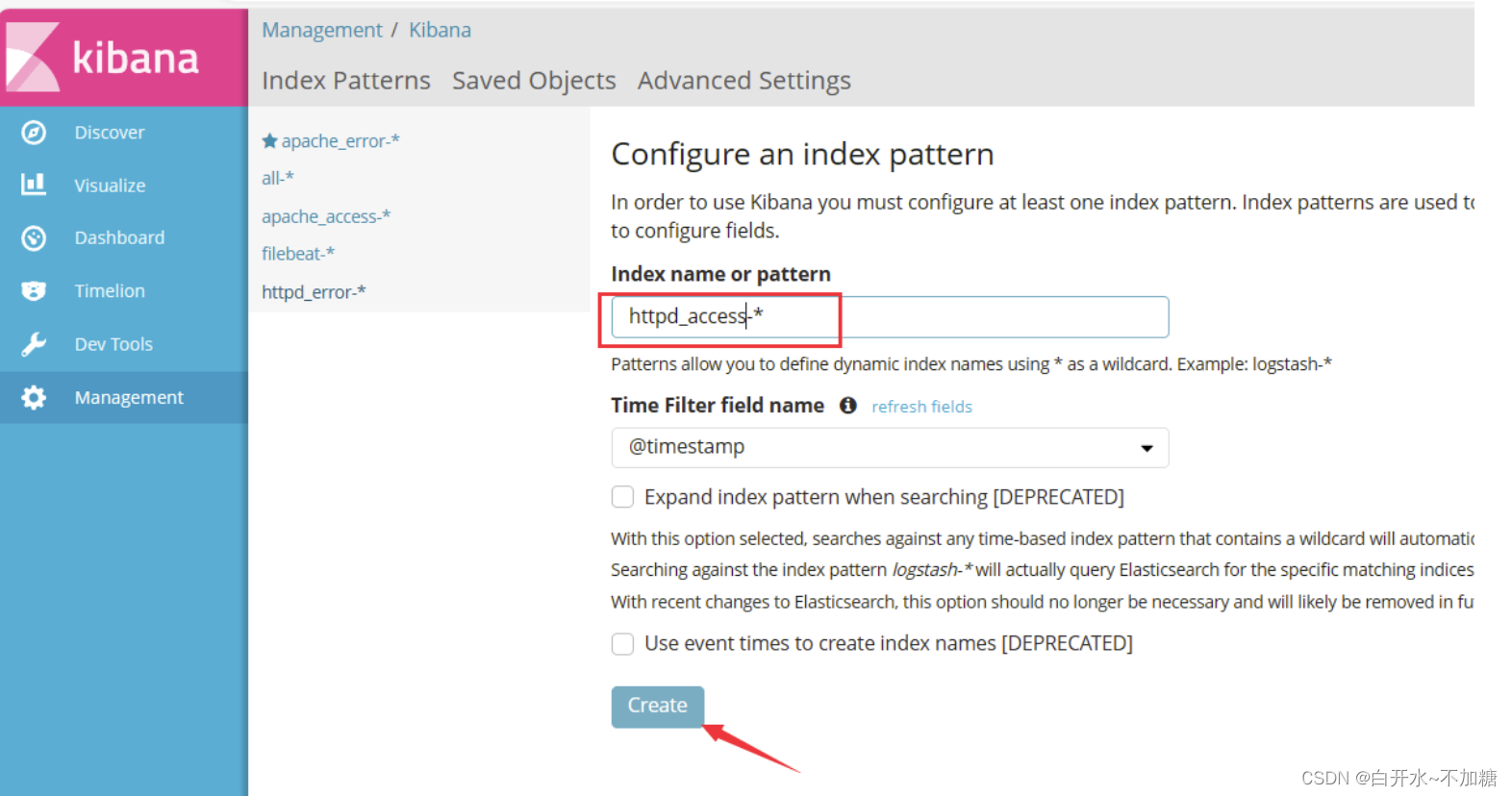
排错思路
1、ES节点是否都正常 使用netstat -natp|grep java 查看9200和9300是否开启
2、filebeat作为生产者将数据推送到kafka,查看kafka中的topic是否有生成
3、在logstash中添加stdout输出,如果屏幕有内容,那么表示kafka与logstash对接成功了
4、filebeat、logstash的配置多次检查
5、环境问题,比如安全机制、防火墙等
6、如果是多次实验使用相同的nginx日志,可以删除/usr/share/logstash/data的.lock隐藏文件