文章目录
- 设计动机与目标
- 数据模型
- 行
- 列
- 时间戳
- 系统架构
- 主服务器
- Chubby作用
- 子表服务器
- SSTable结构
- 子表实际组成
- 子表地址组成
- 子表数据存储及读/写操作
- 数据压缩
- 性能优化
- 局部性群组(Locality groups)
- 压缩
- 布隆过滤器
- Bigtable是Google开发的基于GFS和Chubby的分布式存储系统。Google的很多数据,包括Web索引、卫星图像数据等在内的海量结构化和半结构化数据,都存储在Bigtable中。
设计动机与目标
Google设计Bigtable的动机:
- 需要存储的数据种类繁多
- 海量的服务请求
- 商用数据库无法满足Google的需求
Bigtable应达到的基本目标
- 广泛的适用性:Bigtable是为了满足一系列Google产品而并非特定产品的存储要求。
- 很强的可扩展性:根据需要随时可以加入或撤销服务器
- 高可用性:确保几乎所有的情况下系统都可用
- 简单性:底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来便利
数据模型
- Bigtable是一个分布式多维映射表,表中的数据通过一个行关键字、一个列关键字以及一个时间戳进行索引
- Bigtable的存储逻辑可以表示为: ( r o w : s t r i n g , c o l u m n : s t r i n g , t i m e : i n t 64 ) → s t r i n g (row:string, column:string, time:int64)→string (row:string,column:string,time:int64)→string
- Bigtable数据的存储格式
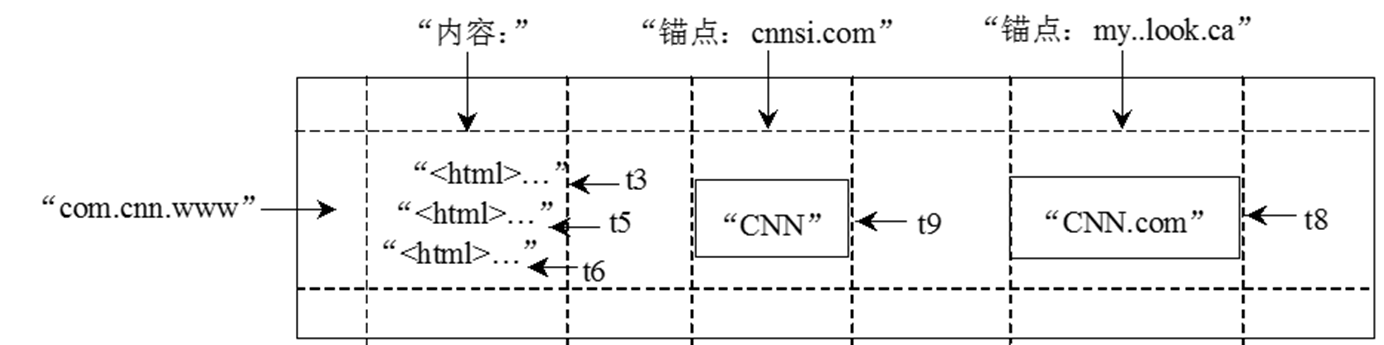
行
- Bigtable的行关键字可以是任意的字符串,但是大小不能够超过64KB
- 表中数据都是根据行关键字进行排序的,排序使用的是词典序
- 同一地址域的网页会被存储在表中的连续位置
- 倒排便于数据压缩,可以大幅提高压缩率
列
- 将其组织成所谓的列族
- 族名必须有意义,限定词则可以任意选定
- 组织的数据结构清晰明了,含义也很清楚
- 族同时也是Bigtable中访问控制的基本单元
时间戳
- Google的很多服务比如网页检索和用户的个性化设置等都需要保存不同时间的数据,不同的数据版本必须通过时间戳来区分。
- Bigtable中的时间戳是64位整型数,具体的赋值方式可以用户自行定义
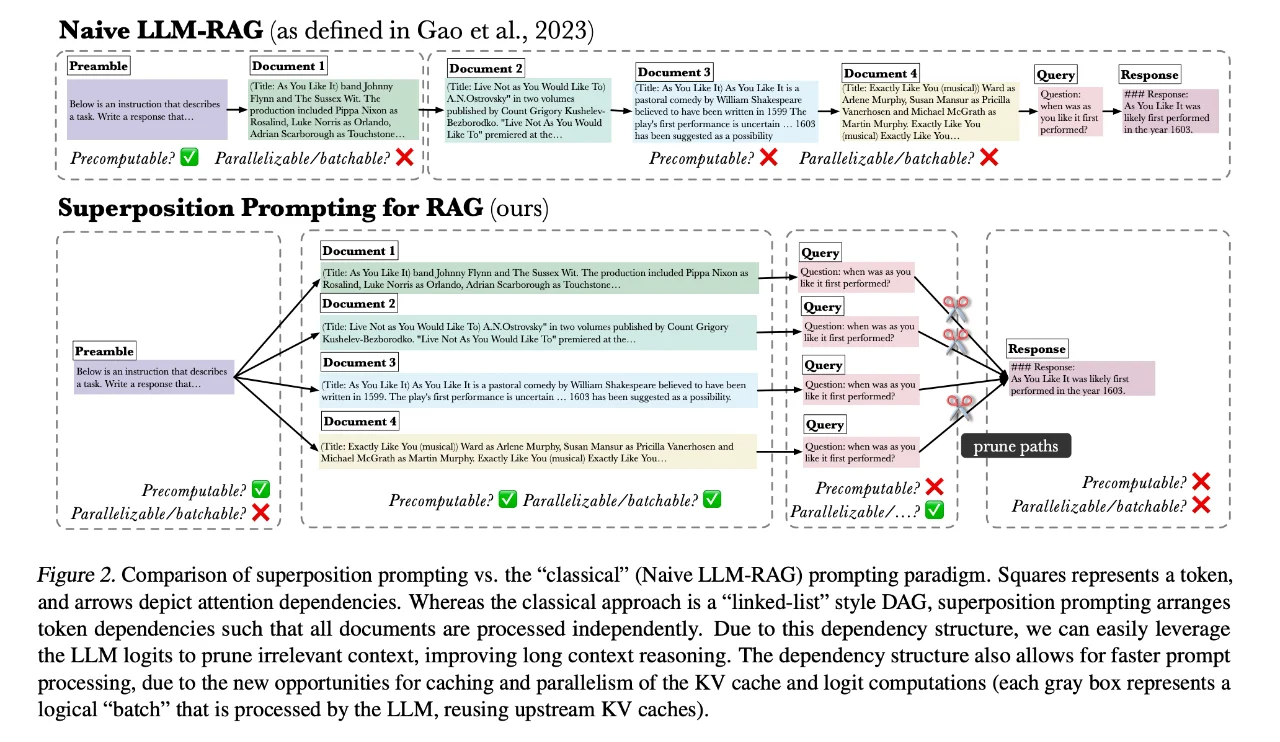
系统架构
- Bigtable是三个云计算组件基础之上构建的
- WorkQueue是一个分布式的任务调度器,用来处理分布式系统队列分组和任务调度
- GFS是Google的分布式文件系统,在Bigtable中GFS主要用来存储子表数据以及一些日志文件
- Chubby提供锁服务。Chubby在Bigtable中的三大主要作用:选取并保证同一时间内只有一个主服务器;获取子表的位置信息;保存Bigtable的模式信息及访问控制列表。
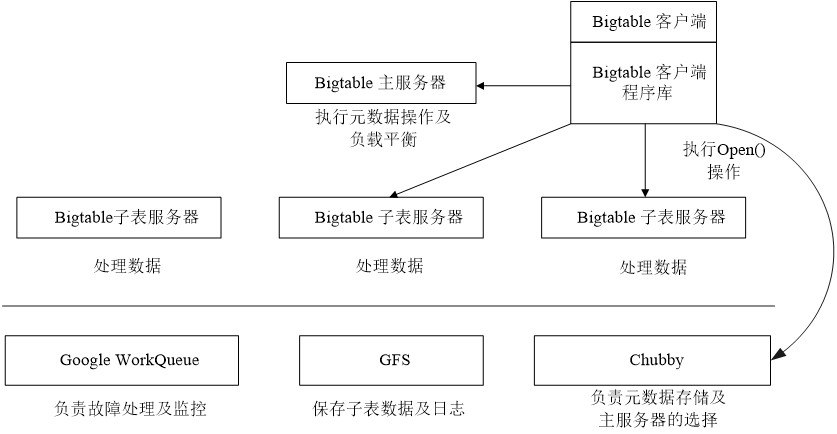
- Bigtable主要由三个部分组成:客户端程序库、一个主服务器和多个子表服务器。
- 客户访问Bigtable服务时,首先要利用其库函数执行 O p e n ( ) Open() Open()操作来打开一个锁(实际上获取文件目录),锁打开以后客户端就可以和子表服务器进行通信。客户端主要与子表服务器通信,几乎不和主服务器进行通信,使得主服务器的负载大大降低。
- 主服务主要进行一些元数据的操作以及子表服务器之间的负载调度问题,实际的数据是存储在子表服务器上的。
主服务器
-
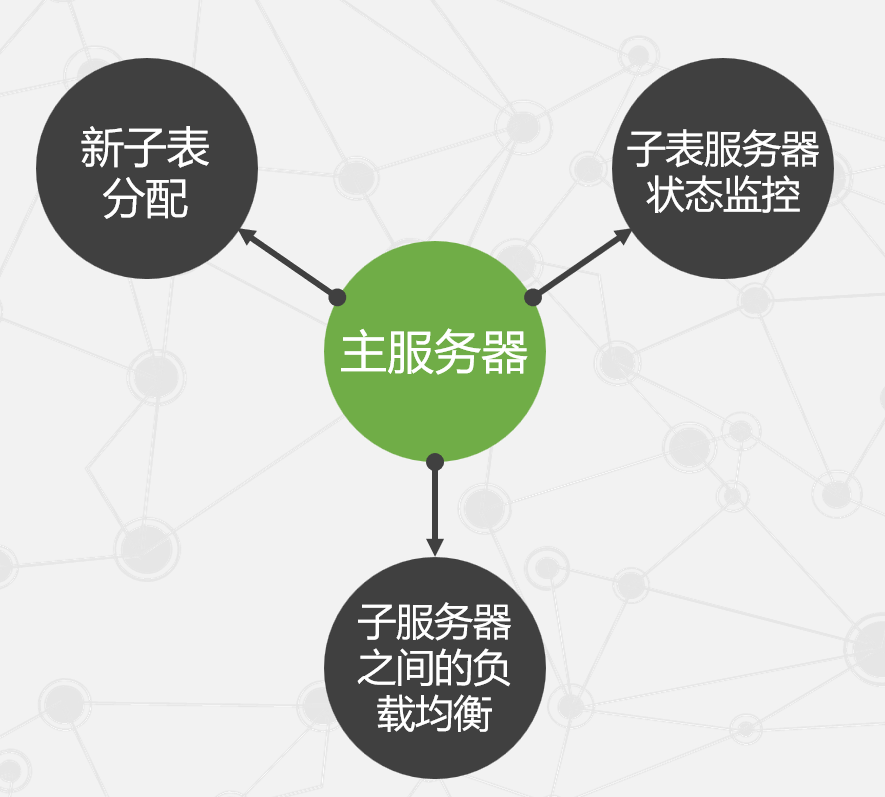
主服务器的主要作用
-
Bigtable的主服务主要负责子表的管理和分配。当新的子表产生,例如通过创建新表、表合并或子表分裂,主服务器会将它们分配给有足够空间的子表服务器。对于由主服务器直接发起的操作(如创建新表和表合并),主服务器能自动检测新子表的产生。而由子表服务器发起的操作(如子表分裂)则需要子服务器在完成后通知主服务器。
-
为了系统的可扩展性,主服务器需监控子表服务器的状态,包括新服务器的加入和现有服务器的撤销。这通过使用Chubby来实现,其中子表服务器在初始化时会从Chubby获取一个独占锁,并将基本信息保存在一个叫做服务器目录的特定位置。主服务器可以通过这个目录获取最新的子表服务器信息和分配情况。
-
主服务器还定期检查每个子表服务器的锁状态,以确定其健康状况。如果检测到锁丢失或无响应,主服务器将尝试获取锁来判断是Chubby服务出现问题还是子表服务器本身有故障。如果是后者,主服务器将停用该子表服务器,并把其上的子表转移给其他服务器。
-
此外,主服务器还会在检测到子表服务器负载过重时,进行负载均衡操作。
Chubby作用
- 当某个主服务器到时退出后,管理系统就会指定一个新的主服务器,这个主服务器的启动需要经历以下四个步骤:
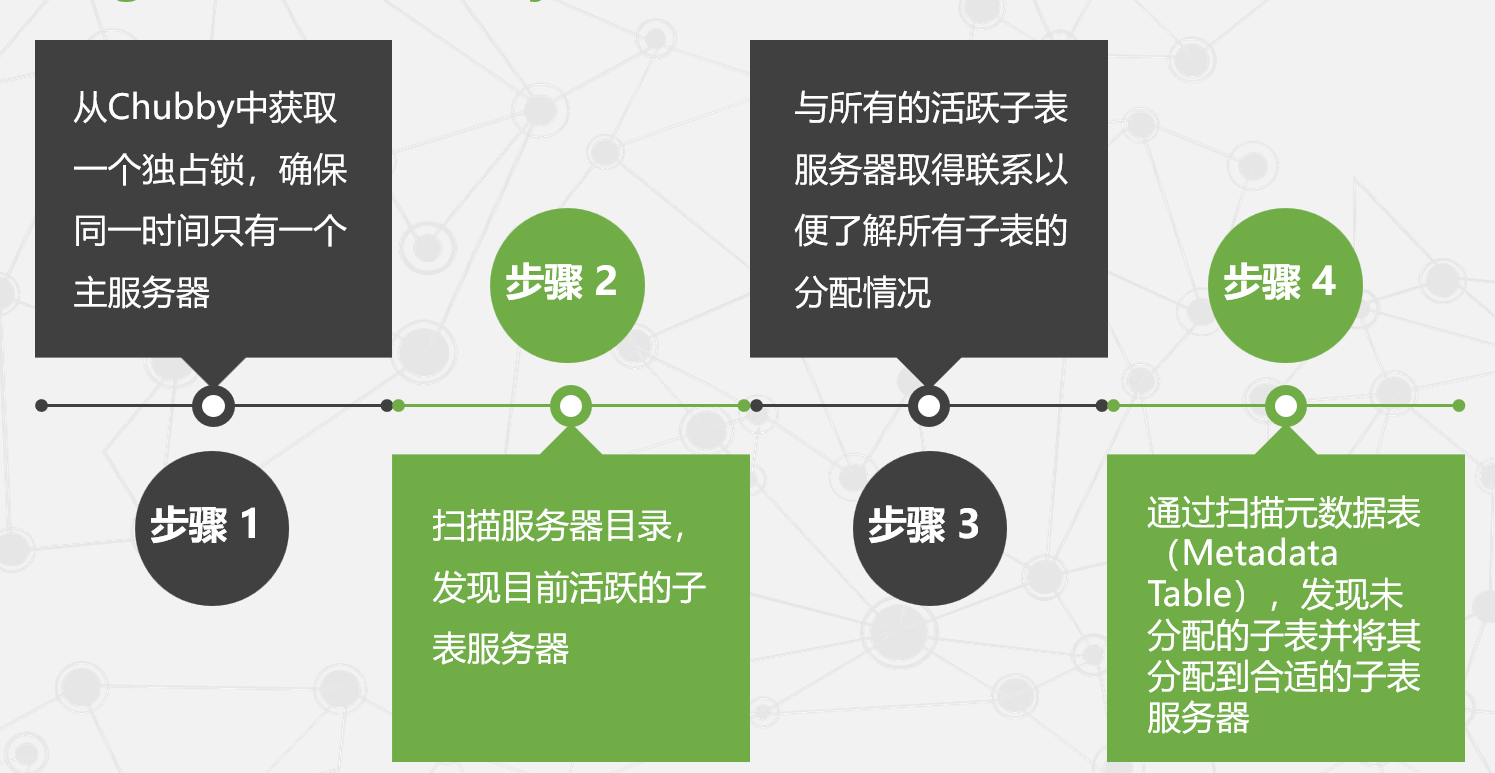
- 从Chubby中获取一个独占锁,确保同一时间只有一个主服务器。
- 扫描服务器目录,发现目前活跃的子表服务器。
- 与所有的活跃子表服务器取得联系,了解所有子表的分配情况。
- 通过扫描元数据表(Metadata Table),发现未分配的子表并将其分配到合适的子表服务器。如果元数据表未分配,则首先需要将根子表(Root Tablet)加入未分配的子表中。
- 子表保存其他所有元数据子表的信息,确保扫描能够发现所有未分配的子表
子表服务器
- Bigtable中实际的数据都是以子表的形式保存在子表服务器上的,客户一般也只和子表服务器进行通信。
SSTable结构
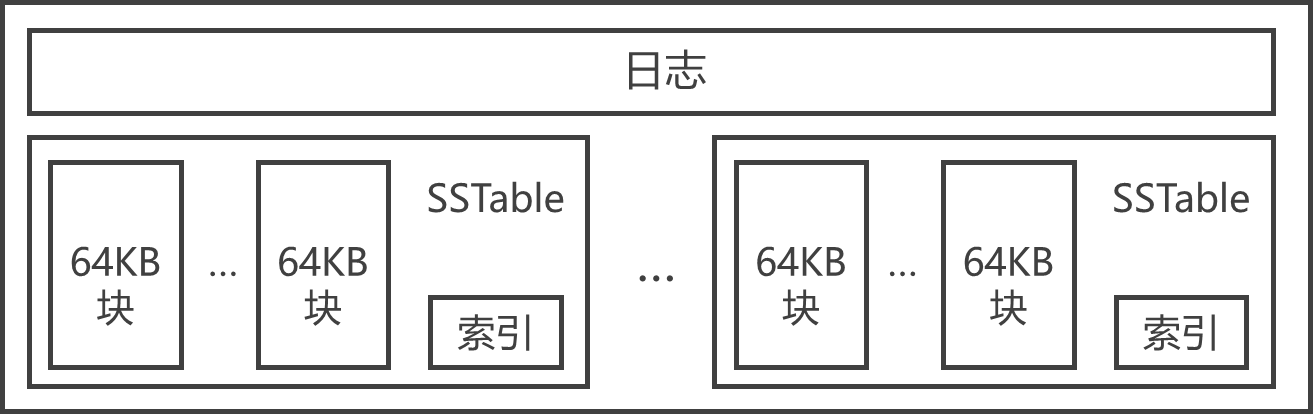
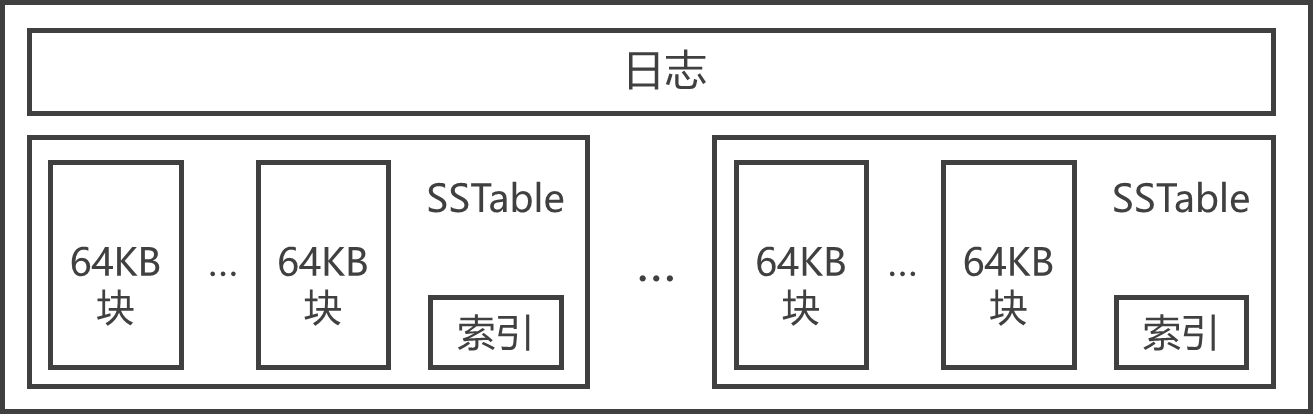
- SSTable是Google为Bigtable设计的内部数据存储格式。所有的SSTable文件都存储在GFS上,用户可以通过键来查询相应的值。

- SSTable中的数据被划分成一个个的块(Block),每个块的大小是可以设置的,一般设置为64KB。
- SSTable结尾的索引(Index),保存SSTable中块的位置信息,在SSTable打开时索引会被加载进内存,用户在查找某个块时首先在内存中查找块的位置信息,然后在硬盘上直接找到这个块,这种查找方法速度非常快。
- 由于每个SSTable一般都不是很大,用户还可以选择将其整体加载进内存,这样查找起来会更快。
子表实际组成
- 不同子表的SSTable可以共享
- 每个子表服务器上仅保存一个日志文件
- Bigtable规定将日志的内容按照键值进行排序
- 每个子表服务器上保存的子表数量可以从几十到上千不等,通常情况下是100个左右
子表地址组成
-
Bigtable系统的内部采用的是一种类似B+树的三层查询体系。
-
所有的子表地址都被记录在元数据表中,元数据表也是由一个个的元数据子表组成

-
Bigtable存储系统利用一个元数据表来记录所有子表的地址信息。这个元数据表由多个元数据子表组成,其中有一个特殊的子表称为根子表,它是元数据表的首条记录,包含了其他所有元数据子表的地址。同时,根子表的信息也被存储在Chubby中的一个文件里。
-
当需要查询特定子表的位置时,系统首先从Chubby获取根子表的地址,通过这个地址读取到所需元数据子表的位置,最后从元数据子表中找到目标子表的具体地址。除了包含子表地址的元数据外,元数据表还储存了用于调试和分析的其他信息,如事件日志等。
-
为提升访问效率和减少开销,Bigtable采用了缓存和预取技术。
- 缓存技术:子表的地址信息被缓存在客户端,使得客户在查询时可以直接利用缓存信息进行地址查找,避免了不必要的网络通信。如果遇到缓存为空或信息过时的情况,客户端会进行相应的网络通信来更新地址信息:缓存为空需进行三次网络通信,而缓存过时则需六次。
- 预取技术则:在每次访问元数据表时,不仅读取当前所需的子表元数据,而是额外读取多个子表的元数据,从而减少未来访问元数据表的次数。
子表数据存储及读/写操作
- 较新的数据存储在内存中一个称为内存表(Memtable)的有序缓冲里,较早的数据则以SSTable格式保存在GFS中。
读和写操作有很大的差异性
- 在进行写操作前,系统会先检查用户是否有权限进行操作(通过查询Chubby中的访问控制列表完成)。一旦用户被认证,写入的数据首先记录到提交日志中,以便在需要时恢复数据。这些记录被称为重做记录,它们记录了最新的数据变更。数据一旦成功记录在提交日志后,会立即写入内存表中。
- 读操作时,首先要通过认证,之后读操作就要结合内存表和SSTable文件来进行,因为内存表和SSTable中都保存了数据。

数据压缩
- 在Bigtable中有三种形式的数据压缩,分别是次压缩(Minor Compaction)、合并压缩(Merging Compaction)和主压缩(Major Compaction)。
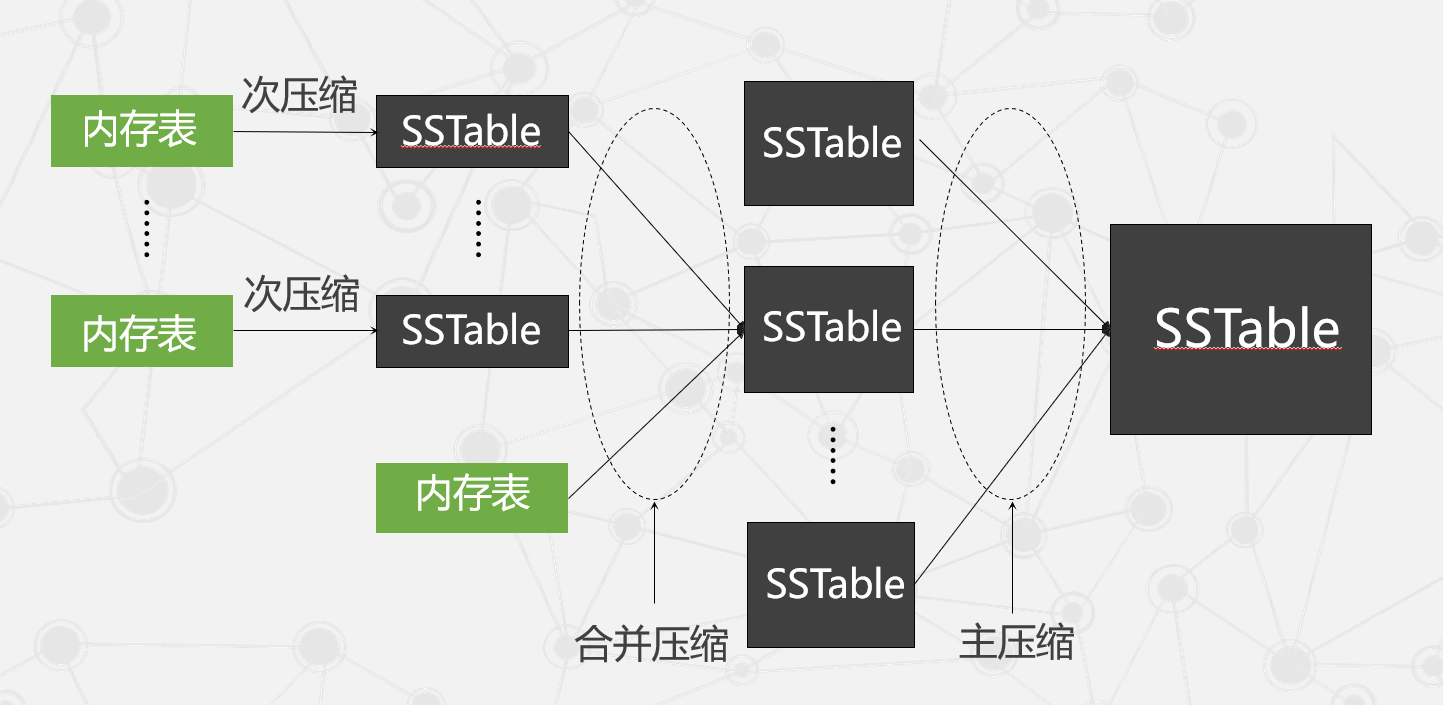
- 每次旧内存表停止使用时都会进行一个次压缩操作,产生SSTable。由于读操作要使用SSTable,数量过多的SSTable显然会影响读的速度。因此Bigtable会定期地执行一次合并压缩操作,将一些已有的SSTable和现有的内存表一并进行一次压缩。
- 主压缩是合并压缩的一种,只不过它将所有的SSTable一次性压缩成一个大的SSTable文件。主压缩也是定期执行的,执行一次主压缩之
后可以保证将所有的被压缩数据彻底删除,既回收空间又能保证敏感数据的安全性(因为这些敏感数据被彻底删除)
性能优化
局部性群组(Locality groups)
- Bigtable还允许用户个人在基本操作基础上对系统进行一些优化
- Bigtable允许用户将原本并不存储在一起的数据以列族为单位,根据需要组织在一个单独的SSTable中,以构成一个局部性群组。(实际上是数据库中垂直分区技术的应用)

- 通过设置局部性群组用户可以只看自己感兴趣的内容,对某个用户来说的大量无用信息无须读取。
- 对于较小的且被经常读取的局部性群组,用户可以将其SSTable文件直接加载进内存,可以明显地改善读取效率。
压缩
- 压缩可以有效地节省空间,Bigtable中的压缩被应用于很多场合。首先压缩可以被用在构成局部性群组的SSTable中,可以选择是否对个人的局部性群组的SSTable进行压缩。
- 利用Bentley & McIlroy方式(BMDiff)在大的扫描窗口将常见的长串进行压缩
- 采取Zippy技术进行快速压缩,它在一个16KB大小的扫描窗口内寻找重复数据,
布隆过滤器
- Bigtable向用户提供一种称为布隆过滤器的数学工具。布隆过滤器是巴顿•布隆在1970年提出的,实际上它是一个很长的二进制向量和一系列随机映射函数,在读操作中确定子表的位置时非常有用。
- 优点:布隆过滤器的速度快,省空间;不会将一个存在的子表判定为不存在
- 缺点:在某些情况下它会将不存在的子表判断为存在