发表机构:Apple
本文介绍了一种新的检索增强生成(RAG)提示方法——叠加提示(superposition prompting),该方法可以直接应用于预训练的基于变换器的大模型(LLMs),无需微调。大型语言模型在处理长文本时存在显著缺陷。它们的推理成本与序列长度成二次方关系,使得在一些实际文本处理应用中的部署变得昂贵。
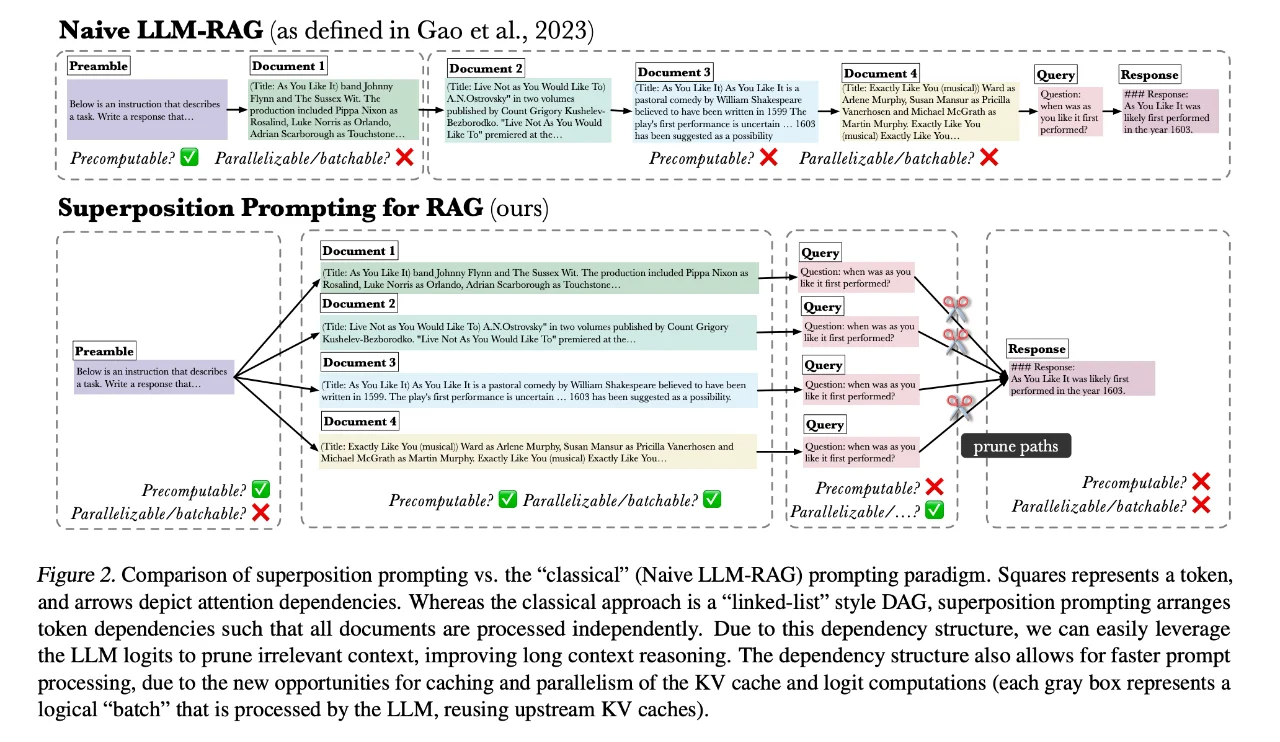
👉 话不多说,举一个叠加提示实际的例子
假设我们的任务是回答一个问题:“莎士比亚的《如你所愿》首次上演是什么时候?”我们有以下四个文档作为候选信息来源:
(Title: As You Like It) Band Johnny Flynn and The Sussex Wit …
(Title: Live Not as You Would Like To) A.N.Ostrovsky in two volumes published …
(Title: Exactly Like You (musical)) Ward as Arlene Murphy. Exactly Like You (musical) Exactly Like You …
在传统的检索增强生成方法中,我们可能需要逐个处理这些文档,并将它们全部融合到提示中,这可能会导致计算效率低下和分散现象。
而在“叠加提示”的过程中,我们可以并行处理这些文档的提示路径。具体来说:
1️⃣ 路径并行化:我们首先为每个文档创建一个独立的提示路径,这些路径可以同时被模型处理。
2️⃣ 路径剪枝:随着模型的处理,我们可以动态地评估每个路径的相关性。例如,第2个和第3个文档与问题关联度不高,因此它们的路径可以在早期阶段被剪枝,从而减少不必要的计算。
3️⃣ 结果合成:最终,我们只保留最相关的路径(在这个例子中可能是第4个文档的路径),并使用该路径生成的信息来回答问题。 通过这种方式,“叠加提示”能够有效地减少处理不相关文档的计算成本,同时提高检索结果的准确性。
今日 git 更新了多篇 arvix 上最新发表的论文,更详细的总结和更多的论文,
请移步 🔗github 搜索 llm-paper-daily 每日更新论文,觉得有帮助的,帮帮点个 🌟 哈。