数据准备
员工表:emp
Oracle:
create table emp (
empno number(4) not null,
ename varchar2(10),
job varchar2(9),
mgr number(4),
hiredate date,
sal number(7, 2),
comm number(7, 2),
deptno number(2)
);
insert into emp values(100, ‘jack’, ‘副总’, null, ‘03-5月-02’, 90000, null, 1);
insert into emp values(200, ‘tony’, ‘总监’, 100, ‘02-2月-15’, 10000, 2000, 2);
insert into emp values(300, ‘hana’, ‘经理’, 200, ‘02-2月-17’, 8000, 1000, 2);
insert into emp values(400, ‘leo’, ‘员工’, 300, ‘02-2月-19’, 3000, 200.12, 2);
insert into emp values(500, ‘liu’, ‘员工’, 300, ‘02-3月-19’, 3500, 200.58, 2);
MySQL:
create table emp (
empno numeric(4) not null,
ename varchar(10),
job varchar(9),
mgr numeric(4),
hiredate date,
sal numeric(7, 2),
comm numeric(7, 2),
deptno numeric(2)
);
insert into emp values(100, ‘jack’, ‘副总’, null, ‘2002-05-03’, 90000, null, 1);
insert into emp values(200, ‘tony’, ‘总监’,100, ‘2015-02-02’, 10000, 2000, 2);
insert into emp values(300, ‘hana’, ‘经理’, 200, ‘2017-02-02’, 8000, 1000, 2);
insert into emp values(400, ‘leo’, ‘员工’, 300, ‘2019-02-22’, 3000, 200.12, 2);
insert into emp values(500, ‘liu’, ‘员工’, 300, ‘2019-03-19’, 3500, 200.58, 2);
部门表:dept
Oracle:
create table dept (
deptno number(2) not null,
dname varchar2(14),
loc varchar2(13)
);
insert into dept values(1, ‘accounting’, ‘一区’);
insert into dept values(2, ‘research’, ‘二区’);
insert into dept values(3, ‘operations’, ‘二区’);
MySQL:
create table dept(
deptno numeric(2) not null,
dname varchar(14),
loc varchar(13)
);
insert into dept values(1, ‘accounting’, ‘一区’);
insert into dept values(2, ‘research’, ‘二区’);
insert into dept values(3, ‘operations’, ‘二区’);
工资级别表:salarygrade
Oracle:
create table salarygrade(
grade number,
losal number,
hisal number
);
MySQL:
create table salarygrade(
grade numeric,
losal numeric,
hisal numeric
);
基础函数
lower、upper
变小写
select lower(dname) from dept;
upper
变大写
select upper(dname) from dept;
length
select dname, length(dname) from dept;
substr
截取,从1开始
select dname, substr(dname, 1, 3) from dept;
concat
拼字符串
select dname, concat(dname, ‘(’) from dept;
select dname, concat(dname, ‘(’, loc) from dept;
select dname, concat(dname, ‘(’, loc, ‘)’) from dept;
综合案例:首字母大写
select dname,
substr(dname, 1, 1), #截取首个字母。
upper(substr(dname, 1, 1)), #将首个字母变成大写。
substr(dname, 2, length(dname)), #截取出除了第一个字母以外的字符。
concat(upper(substr(dname, 1, 1)), substr(dname, 2, length(dname))) #首字母大写实现方式二。
from dept;
replace
select loc, replace(loc, ‘区’, ‘区域’) from dept;
round、ceil、floor
round四舍五入,ceil向上取整(大于目标数的最小整数),floor向下取整(小于目标数的最大整数)。
select ename, comm,
round(comm, 1), round(comm, 2), round(comm, 3),
ceil(comm),
floor(comm)
from emp;
uuid
select uuid();
select replace(uuid(), ‘-’, ‘’),
length(replace(uuid(), ‘-’, ‘’));
日期函数
now
select now();
select current_date();
select current_time();
select curdate();
select curtime();
select sysdate from dual #oracle当前时间,dual内置虚拟表
trunc和floor都可以
last_day
每月最大日期
select ename, hiredate, last_day(hiredate) from emp;
date
select hiredate, year(hiredate), month(hiredate), day(hiredate) from emp;
date_format
日期转字符串,注意格式的大小写。
%Y 4位 %y 2位
%H 24小时 %h 12小时
select date_format(now(), ‘%Y-%m-%d’);
select date_format(now(), ‘%Y-%m-%d %H:%i:%s’);
select date_format(now(), ‘%Y年%m月%d日’);
select date_format(now(), ‘%Y年%m月%d日 %H时%i分%s秒’);
str_to_date
字符串转日期
select str_to_date(‘2020-05-08’, ‘%Y-%m-%d’) from emp;
select year(str_to_date(‘2020-05-08’, ‘%Y-%m-%d’)) from emp;
条件查询
distinct
使用distinct关键字,去除重复的记录行
select loc from dept;
select distinct loc from dept;
where
select * from emp where 1=1;
select * from emp where 1=0;
select * from emp where empno=100;
select * from emp where ename=‘tony’ and deptno=2;
#Oracle区分大小写,Mysql不区分大小写
select * from dept where dname=‘ACCOUNTING’;
select * from dept where dname=‘Accounting’;
select * from dept where dname=‘accounting’;
like
通配符%代表0到n个字符,通配符下划线_代表1个字符
select * from emp where ename like ‘t%’; #t字母开头,效率高
select * from emp where ename like ‘%n%’; #中间含有n
select * from emp where ename like ‘t___’; #3个下划线
select * from emp where ename like ‘__n%’; #2个下划线
and&or
and并且,or或者
select * from dept where dname=‘accounting’ and loc=‘一区’;
select * from dept where dname=‘accounting’ or loc=‘二区’;
null
select * from emp where mgr is null; #字段内容为null的
select * from emp where mgr is not null; #字段内容不为null的
nvl
字段值为null时替换;loc为null替换为‘无’
insert into dept (deptno, dname) values (4, ‘workspace’);
select deptno, dname, nvl(loc, ‘无’) as loc from dept;
between and
between x and y 在x和y之间的值
select * from emp
where sal between 5000 and 10000;
等价于
select * from emp
where sal >= 5000 and sal <= 10000;
union
把多个结果集合并,前提条件,两个结果集列对应,个数和类型一致
select * from emp where empno=100
union
select * from emp where empno=200;
报错:The used SELECT statements have a different number of columns
select * from emp
union
select * from dept;
没有实际意义
select empno, ename from emp
union
select deptno, dname from dept;
limit
分数最高的记录:按分数排序后,limit n,返回前n条。oracle做的很不好,实现繁琐,而mysql做的很好,语法简洁高效。
select * from emp limit 3 #返回前3条
select * from emp limit 0, 3 #返回前3条(offset, count)offset从0开始
select * from emp limit 1, 3 #返回第2到4条,共计3条
子查询
概念:子查询是指嵌入在其他select语句中的select语句,也叫嵌套查询。
单行子查询
返回结果为一个
列出tony所在部门的所有人员
select deptno from emp where ename=‘tony’;
select * from emp where deptno = (select deptno from emp where ename=‘tony’);
deptno = 使用等号,后面的查询结果只能为一个值
多行子查询
select * from emp where job in (‘经理’, ‘员工’);
select * from emp where job in (select distinct job from emp);
例子:查询
薪资统计
薪水大于等于10000的员工
select * from emp where sal>=10000;
薪水在5000到10000之间的员工
select * from emp where sal>=5000 and sal<=10000;
入职统计
2015年以前入职的老员工
select * from emp where date_format(hiredate, ‘%Y-%m-%d’)<=‘2015-01-01’;
2019年以后签约的员工,日期进行格式转换后方便比较
select * from emp where date_format(hiredate, ‘%Y-%m-%d’)>=‘2019-01-01’;
2015年到2019年入职的员工
select * from emp where
str_to_date(hiredate, ‘%Y-%m-%d’)>=‘2015-01-01’
and
str_to_date(hiredate, ‘%Y-%m-%d’)<=‘2019-12-31’;
年薪统计
公司13薪,年底双薪,统计员工的年薪=sal13+comm13
副总不按月奖金计算
select empno, ename, job, sal * 13+comm13 from emp;
select empno, ename, job, sal * 13+nvl(comm13, 0) from emp;
select empno, ename, job, sal * 13+nvl(comm13, 0) as 年收入 from emp;
select empno, ename, job, sal * 13+nvl(comm13, 0) as ‘年收入’ from emp;
select empno, ename, job, sal * 13+nvl(comm*13 ,0) as “年收入” from emp;
计算时字段为数值类型应该按0来计算,按null达不到我们预期效果。
备份和恢复
概念:
数据库是我们业务系统的核心,业务系统的数据都保存在数据库中,一旦数据丢失,将带来难以估量的损失。特别现在出现黑客劫持,黑客攻击数据库服务器后,将上面的数据全部加密,如果不交付赎金,就自动删除数据。这种现象已经屡有发生,我们应该养成备份的习惯。防止这种极端情况的发生。
备份
方式一:
C:>mysqldump -uroot -proot yhdb > d:/yhdb20190901-tony.sql
注意:
备份不是在mysql环境里,而是直接在操作系统环境中执行mysqldump命令
MySQL的dump为sql纯文本文件,oracle备份为二进制文件,命令有差异
方式二:
C:>mysqldump -uroot -proot --databases yhdb > d:\yh.sql
加—databases参数,导出的sql脚本中会含有创建数据和打开数据的步骤
起名规则:数据库名称-备份日期-备份人
恢复
方式一:
Mysql习惯创建sql的备份文件没有创建数据库的sql语句,需手动创建
MariaDB [yhdb]> create database yhdb charset utf8; #创建库,设置u8
MariaDB [yhdb]> use yhdb; #打开yhdb数据库
MariaDB [yhdb]> source d:/yhdb-20190901-tony.sql #恢复数据
MariaDB [yhdb]> show tables; #展示所有表
方式二:
使用—databases参数导出的sql含有数据库创建脚本,就可以无需创建数据库
C:>mysql -uroot -proot < d:/yh.sql
数据库优化
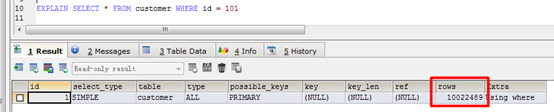
- where条件查询时要类型匹配,否则索引失效
customer表的id字段为varchar类型,按整数类型查询全表遍历,查的很快也是由于缓存而非使用索引。
- like原则
like ‘宋%’ 会使用索引
like ‘%宋%’ 索引失效 - 查询字段尽量不要使用*
select * from tb_item;
select id, title, sell_point, status, created, updated from tb_item;
- 量变引起质变,不同字段类型查询性能差异很大
select count(1) from customer_varchar ; 一千万数据,耗时2:14:364
select count(1) from customer_bigint; 一千万数据,耗时15:959
select count(1) from customer_int ; 一千万数据,耗时14:352
select count(1) from customer_char; 一千万数据,耗时1:55:409
- 分组
select age, count() from customer_age_char group by age ; 34:352
select age, count() from customer_age_int group by age; 18:798
小结
中文乱码
如果在dos命令下执行insert插入中文数据,数据又乱码,那现在sqlYog客户端执行下面命令:
set names utf8;
set names gbk;
设置客户端字符集和服务器端相同。如果不知道它到底用的什么编码?怎么办呢?很简单,两个都尝试下,哪个最后操作完成,查询数据库不乱码,就用哪个。
为何会造成乱码呢?
MySQL数据库默认字符集是lantin1,也就是以后网页中遇到的ISO8859-1,它是英文字符集,不支持存放中文。我们创建库时,可以指定字符集:
create database yhdb charset utf8;
但这样很容易造成服务器和客户端编码集不同,如服务器端utf8,客户端ISO8859-1。mysql和客户端工具都有习惯的默认编码设置,好几个地方,要都统一才可以保证不乱码。
我们只要保证创建数据库时用utf8,使用可视化工具一般就基本正确。
注释
/* 很多注释内容 */
“#” 一行注释内容
“–” 一行注释内容,这个使用较多
聚合(aggregation)
count
记录总数
select * from emp;
select count() from emp;
select count() from emp where ename like ‘t%’;
select count(1) from emp;
select count(empno) from emp;
习惯使用*的方式,推荐使用后两种方式
max
最大值
select max(sal) from emp;
min
最小值
select min(sal) from emp;
select min(sal), max(sal) from emp;
利用子查询得到最大薪资的人员信息,如果最大薪资相同可能多条结果
select ename, max(sal) from emp
子查询时后面的sql只能返回一个值
select ename from emp where sal = (select max(sal) from emp)
avg
平均值
select avg(sal) from emp;
select ename, avg(sal) from emp #注意sql不是想出来的,而是根据业务去实现的,这句话虽然能执行,但却是错误的,没有业务的实际意义。平均薪资跟某个人有什么关系呢?
高于平均工资的员工有
select * from emp where sal >= (select avg(sal) from emp);
sum
合计
select sum(sal) from emp;
分组(group)
groupby
group by 用于对查询的结果进行分组统计
having 子句类似where限制返回结果,where用在主句中,having用在分组中
注意:使用分组限制会居多
错误,统计时非统计字段必须分组,能执行,但无业务意义
select deptno,max(sal) from emp;
每个部门最高的薪资和平均薪资
select deptno, max(sal),AVG(sal) from emp
group by deptno
order by max(sal);
每个部门每个岗位的最高薪资和平均薪资,结果中的非聚合列必须出现在分组中,否则业务意义不对
select deptno, job, max(sal), avg(sal) from emp
group by deptno,job
order by max(sal);
having
分组后数据的过滤,就是where语句,只是having专门配合groupby
平均工资小于8000的部门
select deptno, avg(sal) from emp
group by deptno
having abg(sal)<8000
学生姓名重名名单*
select name, count(name) from student
group by name
having count(name)>1;
学生成绩统计
创建表添加数据
drop table tb_cousre_score;
create table tb_cousre_score
(
id numeric,
name varchar(20),
course varchar(20),
score numeric
);
insert int tb_cousre_score (id, name, course, score) values (1, ‘张三’, ‘语文’, 88);
insert int tb_cousre_score (id, name, course, score) values (1, ‘张三’, ‘语文’, 67);
insert int tb_cousre_score (id, name, course, score) values (1, ‘张三’, ‘数学’, 76);
insert int tb_cousre_score (id, name, course, score) values (1, ‘张三’, ‘英语’, 43);
insert int tb_cousre_score (id, name, course, score) values (1, ‘张三’, ‘历史’, 56);
insert int tb_cousre_score (id, name, course, score) values (1, ‘张三’, ‘化学’, 11);
insert int tb_cousre_score (id, name, course, score) values (2, ‘李四’, ‘语文’, 54);
insert int tb_cousre_score (id, name, course, score) values (2, ‘李四’, ‘数学’, 81);
insert int tb_cousre_score (id, name, course, score) values (2, ‘李四’, ‘英语’, 64);
insert int tb_cousre_score (id, name, course, score) values (2, ‘李四’, ‘历史’, 93);
insert int tb_cousre_score (id, name, course, score) values (2, ‘李四’, ‘化学’, 27);
insert int tb_cousre_score (id, name, course, score) values (3, ‘王五’, ‘语文’, 24);
insert int tb_cousre_score (id, name, course, score) values (3, ‘王五’, ‘数学’, 25);
insert int tb_cousre_score (id, name, course, score) values (3, ‘王五’, ‘英语’, 8);
insert int tb_cousre_score (id, name, course, score) values (3, ‘王五’, ‘历史’, 45);
insert int tb_cousre_score (id, name, course, score) values (3, ‘王五’, ‘化学’, 1);
commit;
学生的成绩条数
select name, count(name) from tb_cousre_score
group by name;
行列转置
select id, name,
case when course=‘语文’ then score else 0 end 语文
from tb_cousre_score
注意:单纯这样没有什么业务意义,一般配合分组和聚合函数
每门最高成绩
分组groupby,排序orderby,聚合(最大值)max,
判断casewhen类似java中的if-else
多次考试取最高的成绩,张三有2次语文成绩67和88
select id, name,
max(case when course=‘语文’ then score else 0 end) 语文,
max(case when course=‘数学’ then score else 0 end) 数学,
max(case when course=‘英语’ then score else 0 end) 英语,
max(case when course=‘历史’ then score else 0 end) 历史,
max(case when course=‘化学’ then score else 0 end) 化学
from tb_cousre_score
group by id, name
order by id
每门成绩总和
select id,NAME,
sum(case where course=‘语文’ then score else 0 end) 语文,
sum(case where course=‘数学’ then score else 0 end) 数学,
sum(case where course=‘英语’ then score else 0 end) 英语,
sum(case where course=‘历史’ then score else 0 end) 历史,
sum(case where course=‘化学’ then score else 0 end) 化学
from tb_cousre_score
group by id, name
order by id
集合
union 并集去重
select * from dept where loc=‘一区’
union
select * from dept where loc=‘二区’
实际开发中可以连接多个表的数据 a union b union c
select * from dept
union
select * from dept
union
select * from dept
union all 并集
会有重复数据,不进行合并
select * from dept
union all
select * from dept
intersect 交集
select * from dept where loc is not null
intersect
select * from dept
minus 差集
mysql不支持,可以使用left join变相实现,而oracle支持,很少用
select * from dept where loc is not null
minus
select * from dept
select * from dept
minus
select * from dept where loc is not null
注意:两者的差异,第一个结果为空,第二个有一条记录,为何?因为差集的意思是返回存在在第一个集合中,不存在在第二个集合中的数据。和数学上的差集有所不同。
多表联查
笛卡尔积
多表查询是指基于两个和两个以上的表的查询。在实际应用中,查询单个表可能不能满足你的需求,如显示员工表emp中不只显示deptno,还要显示部门名称,而部门名称dname在dept表中。
把两个表的数据都拼接起来
select * from emp, dept;
查询出员工编号、员工工资及所在部门的名称
select
d.dname,
e.empno, e.ename, e.sal
from emp e, dept d;
上面这种查询两个表的方式称为:笛卡尔积(Cartesian product),又称直积。一般笛卡尔积没有实际的业务意义,但作为概念必须了解,多表查询都是先生成笛卡尔积,再进行数据的筛选过滤。
这点很值得注意,实际开发中尽量少用多表联查,其根本原因就在这里,查询过程中,先在内存中构建一个大的结果集,然后在进行数据的过滤。那这个构建过程,和所使用的内存资源,包括过滤时的判断,都是既耗费资源,又浪费时间。
内连接 inner
#显示部门2的员工和工资
SELECT d.dname,e.ename,e.sal FROM emp e,dept d
WHERE e.deptno=d.deptno AND e.deptno=2
SELECT
d.dname,e.ename,e.job
FROM
(SELECT deptno,dname FROM dept) d
INNER JOIN
(SELECT deptno,ename,job FROM emp) e
ON d.deptno = e.deptno
WHERE d.deptno=2
左连接 left
也称为左外连接left outer join
SELECT
d.dname,e.ename,e.job
FROM
(SELECT deptno,dname FROM dept) d
LEFT JOIN
(SELECT deptno,ename,job FROM emp) e
ON d.deptno=e.deptno
下面是Oracle的独特语法,更加简洁,但不推荐,没有上面的语法更加清晰
select * from dept d,emp e where d.deptno=e.deptno(+)
select d.dname,e.ename,e.job from dept d,emp e
where d.deptno = e.deptno(+)
右连接 right
也称为右外连接right outer join
select
d.dname,e.ename,e.job
from
(select deptno,dname from dept) d
right join
(select deptno,ename,job from emp) e
on d.deptno = e.deptno
下面是Oracle的独特语法:
select * from dept d,emp e where d.deptno(+) = e.deptno
select d.dname,e.ename,e.job from dept d,emp e
where d.deptno(+) = e.deptno
自连接 self
一般只分为:内连接、左连接、右连接,自连接是指在同一张表的连接查询,下面代码本质还是内连接。
通过别名区分
SELECT worker.ename, boss.ename FROM emp worker, emp boss
WHERE worker.mgr = boss.empno AND worker.ename = ‘tony’;
简写
select w.ename, b.ename from emp w, emp b
where w.mgr = b.empno and w.ename = ‘tony’;
With
使用with子句可以让子查询重用相同的with查询块,通过select调用,很少用
WITH num AS (SELECT d.deptno FROM dept d WHERE d.deptno=1)
SELECT e.ename,e.job,e.sal FROM emp e WHERE e.deptno IN (SELECT * FROM num);
万能连接
多表联查有个技巧,其实所有的连接方式都可以转换为左连接!如果记录内容完整,如每个部门对应有员工,每个员工对应有部门,内连接就等价左连接,结果内容一样。右连接是按右侧表关联,那把它换到左边,那不就是左连接,所以换先位置它们就等价。所以记住左连接写法即可。
左连接写的过程,写它是有套路的,这个套路记住,就特别简单。
实现步骤:
- 第一步:左边查询括号写别名
- 第二步:右边查询括号写别名
- 第三步:left join恒中间,后面加on是条件
- 第四步:select挑字段,别名后面写字段
多表联查案例
班级学生(一对多)
SELECT
c.name,
s.*
FROM
(SELECT classid,NAME FROM class) c
LEFT JOIN
(SELECT classid,id,NAME,sex,birthday,salary FROM student) s
ON c.classid=s.classid
部门员工(一对多)
SELECT
d.deptno,d.dname,d.loc,
e.empno,e.ename,e.job,e.mgr,e.hiredate,e.sal,e.comm
FROM
(SELECT deptno,dname,loc FROM dept) d
LEFT JOIN
(SELECT deptno,empno,ename,job,mgr,hiredate,sal,comm FROM emp) e
ON d.deptno=e.deptno
员工和上级(自关联,一对一)
通过对表的两个查询SQL拼接而成
SELECT
e.deptno,e.empno,e.ename,
e.mgr,m.ename manager,
e.job,e.hiredate,e.sal,e.comm
FROM
(SELECT deptno,empno,ename,job,mgr,hiredate,sal,comm FROM emp) e
LEFT JOIN
(SELECT empno,ename FROM emp) m
ON e.mgr=m.empno
部门、员工和上级(三级关联)
两次leftjoin,把第一次的结果在()成一个表
SELECT
e.deptno,e.dname,e.loc,
e.empno,e.ename,e.job,
e.mgr,m.ename manager,
e.hiredate,e.sal,e.comm
FROM
(
SELECT
d.deptno,d.dname,d.loc,
e.empno,e.ename,e.job,e.mgr,e.hiredate,e.sal,e.comm
FROM
(SELECT deptno,dname,loc FROM dept) d
LEFT JOIN
(SELECT deptno,empno,ename,job,mgr,hiredate,sal,comm FROM emp) e
ON d.deptno=e.deptno
) e
LEFT JOIN
(SELECT empno,ename FROM emp) m
ON e.mgr=m.empno
商品分类和商品(一对多)
SELECT
c.name,i.title,i.price
FROM
(SELECT cid,title,price FROM tb_item) i
LEFT JOIN
(SELECT id,NAME FROM tb_item_cat) c
ON i.cid=c.id
商品和商品描述(一对一)
SELECT
i.title,i.price,d.item_desc
FROM
(SELECT id,title,price FROM tb_item) i
LEFT JOIN
(SELECT item_id,item_desc FROM tb_item_desc) d
ON i.id=d.item_id
用户、角色、中间表(多对多)
#某个用户所拥有的角色
SELECT role_id,NAME FROM role_p
WHERE role_id IN
(
SELECT role_id FROM role_user_p
WHERE user_id=(SELECT user_id FROM user_p WHERE user_id=100)
)
查询综合练习
drop table if exists courses;
drop table if exists scores;
drop table if exists students;
drop table if exists teachers;
create table courses
(
cno varchar(5) not null, --课程编号
cname varchar(10) not null, --课程名称
tno varchar(10) not null, --讲师编号 fk
primary key (cno)
);
create table scores
(
sno varchar(3) not null, --学生编号
cno varchar(5) not null, --课程编号
degree numeric(10,1) not null, --分数
primary key (sno, cno)
);
create table students
(
sno varchar(3) not null, --学生编号
sname varchar(4) not null, --学生姓名
ssex varchar(2) not null, --学生性别
sbirthday datetime, --学生生日
class varchar(5), --学生班级编号
primary key (sno)
);
create table teachers
(
tno varchar(3) not null, --老师编号
tname varchar(4) not null, --老师姓名
tsex varchar(2) not null, --老师性别
tbirthday datetime not null, --老师生日
prof varchar(6), --老师职称
depart varchar(10), --老师所教系
primary key (tno)
);
alter table courses add constraint FK_Reference_3 foreign key (tno)
references teachers (tno) on delete restrict on update restrict;
alter table scores add constraint FK_Reference_1 foreign key (sno)
references students (sno) on delete restrict on update restrict;
alter table scores add constraint FK_Reference_2 foreign key (cno)
references courses (cno) on delete restrict on update restrict;
insert into students (sno, sname, ssex, sbirthday, class) values (108, ‘曾华’, ‘男’, ‘1977-09-01’, 95033);
insert into students (sno, sname, ssex, sbirthday, class) values (105, ‘匡明’, ‘男’, ‘1975-10-02’, 95031);
insert into students (sno, sname, ssex, sbirthday, class) values (107, ‘王丽’, ‘女’, ‘1976-01-23’, 95033);
insert into students (sno, sname, ssex, sbirthday, class) values (101, ‘李军’, ‘男’, ‘1976-02-20’, 95033);
insert into students (sno, sname, ssex, sbirthday, class) values (109, ‘王芳’, ‘女’, ‘1975-02-10’, 95031);
insert into students (sno, sname, ssex, sbirthday, class) values (103, ‘陆君’, ‘男’, ‘1974-06-03’, 95031);
insert into teachers (tno, tname, tsex, tbirthday, prof, depart) values (804, ‘易天’, ‘男’, ‘1958-12-02’, ‘副教授’, ‘计算机系’);
insert into teachers (tno, tname, tsex, tbirthday, prof, depart) values (856, ‘王旭’, ‘男’, ‘1969-03-12’, ‘讲师’, ‘电子工程系’);
insert into teachers (tno, tname, tsex, tbirthday, prof, depart) values (825, ‘李萍’, ‘女’, ‘1972-05-05’, ‘助教’, ‘计算机系’);
insert into teachers (tno, tname, tsex, tbirthday, prof, depart) values (831, ‘陈冰’, ‘女’, ‘1977-08-14’, ‘助教’, ‘电子工程系’);
insert into courses (cno, cname, tno) values (‘3-105’, ‘计算机导论’, 825);
insert into courses (cno, cname, tno) values (‘3-245’, ‘操作系统’, 804);
insert into courses (cno, cname, tno) values (‘6-166’, ‘模拟电路’, 856);
insert into courses (cno, cname, tno) values (‘6-106’, ‘概率论’, 831);
insert into courses (cno, cname, tno) values (‘9-888’, ‘高等数学’, 831);
insert into scores (sno, cno, degree) values (103, ‘3-245’, 86);
insert into scores (sno, cno, degree) values (105, ‘3-245’, 75);
insert into scores (sno, cno, degree) values (109, ‘3-245’, 68);
insert into scores (sno, cno, degree) values (103, ‘3-105’, 92);
insert into scores (sno, cno, degree) values (105, ‘3-105’, 88);
insert into scores (sno, cno, degree) values (109, ‘3-105’, 76);
insert into scores (sno, cno, degree) values (101, ‘3-105’, 64);
insert into scores (sno, cno, degree) values (107, ‘3-105’, 91);
insert into scores (sno, cno, degree) values (108, ‘3-105’, 78);
insert into scores (sno, cno, degree) values (101, ‘6-166’, 85);
insert into scores (sno, cno, degree) values (107, ‘6-106’, 79);
insert into scores (sno, cno, degree) values (108, ‘6-166’, 81);
desc courses;
desc scores;
desc students;
desc teachers;
select * from courses;
select * from scores;
select * from students;
select * from teachers;
- 左连接
select c.cno, c.cname, t.tno, t.tname
from
(select tno, tname from teachers) t
left join
(select tno, cno, cname from courses) c
on t.tno=c.tno;
- 内连接
select c.cno, c.cname, t.tno, t.tname
from
(select tno, tname from teachers) t
inner join
(select tno, cno, cname from courses) c
on t.tno=c.tno;
- 右连接
select c.cno, c.cname, t.tno, t.tname
from
(select tno, tname from teachers) t
right join
(select tno, cno, cname from courses) c
on t.tno=c.tno;
#查询students表的所有记录
select * from students;
#查询students表中的所有记录的sname、ssex和class列
select sname, ssex, class from students;
#查询teachers表所有的单位即不重复的depart列
select distinct depart from teachers;
#查询scores表中成绩在60到80之间的所有记录
select * from scores where degree between 60 and 80;
select * from scores where degree>=60 and degree<=80;
#查询scores表中成绩为85,86或88的记录
select * from scores where degree in (85, 86, 88);
select * from scores where degree=85 or degree=86 or degree=88;
#查询students表中“95031”班或性别为“女”的同学记录
select * from students where class=‘95031’ or ssex=‘女’;
#以班级class降序查询students表的所有记录
select * from students order by class desc;
#以cno升序、degree降序查询scores表的所有记录
select * from scores order by cno asc, degree desc;
#查询“95031”班的学生人数
select count(1) from students where class=‘95031’;
#查询每个班的学生人数
select class, count(class) from students group by class;
#查询scores表中的最高分的学生学号和课程号
select sno, cno, degree from scores where degree=(select max(degree) from scores);
select sno, cno, degree from scores order by degree desc limit 1;
#查询‘3-105’号课程的平均分
select avg(degree), round(avg(degree), 2) from scores where cno=‘3-105’;
#查询最高分
select max(degree) from scores;
#查询最低分
select min(degree) from scores;
#查询最低分大于70,最高分小于90的sno列
select sno from scores
group by sno
having min(degree)>70 and max(degree)<90;
#查询95033班和95031班全体学生的记录
select * from students;
select * from students where class in (‘95033’, ‘95031’);
select * from students where class=‘95033’ or class=‘95031’;
select * from students where class in (‘95033’,‘95031’) order by class desc;
#查询存在有85分以上成绩的课程cno
select * from scores;
select distinct cno from scores where degree>85;
#查询所有教师和同学的name、sex和birthday
select sname, ssex, sbirthday from students
union
select tname, tsex, tbirthday from teachers;
#查询所有“女”教师和“女”同学的name、sex和birthday
select sname, ssex, sbirthday from students where ssex=‘女’
union
select tname, tsex, tbirthday from teachers where tsex=‘女’;
#查询所有任课教师的tname和depart
select tname, depart from teachers
where tno in (
select tno from courses
);
#查询所有未讲课的教师的tname和depart
select tname, depart from teachers
where tno not in (
select tno from courses
);
#查询至少有2名男生的班号
#查询students表中姓“王”的同学记录
#查询students表中不姓“王”的同学记录
#查询students表同名的同学记录
#查询students表中每个学生的姓名和年龄
#查询students表中最大和最小的sbirthday日期值
#以班号和年龄从大到小的顺序查询student表中的全部记录
#查询“男”教师及其所上的课程
#查询最高分同学的sno、cno和degree列
#查询课程对应的老师姓名、职称、所属系
#查询scores表中至少有5名学生选修的并以3开头的课程的平均分数
#查询所有学生的sname、cno和degree列
#查询所有学生的sno、cname和degree列
#查询所有学生的sname、cname和degree列
#创建等级grade表,现查询所有同学的sno、cno和rank级别列
#查询选修“3-105”课程的成绩高于“109”号同学成绩的所有同学的记录
#查询scores中选学一门以上课程的同学中分数为非最高分成绩的记录
#查询成绩高于学号为“109”、课程号为“3-105”的成绩的所有记录
#查询和学号为108的同学同年出生的所有学生的sno、sname和sbirthday列
#查询“95033”班所选课程的平均分*
#查询“张旭“教师任课的学生成绩*
#查询选修某课程的同学人数多于5人的教师姓名
#查询出“计算机系“教师所教课程的成绩表
#查询“计算机系”与“电子工程系“不同职称的教师的tname和prof
#查询选修编号为“3-105“课程且成绩至少高于任意选修编号为“3-245”的同学的成绩的cno、sno和degree,并按degree从高到低次序排序
#查询选修编号为“3-105”且成绩高于所有选修编号为“3-245”课程的同学的cno、sno和degree
#查询成绩比该课程平均成绩低的同学的成绩表*
#查询和“李军”同性别的所有同学的sname
#查询和“李军”同性别并同班的同学sname
#查询所有选修“计算机导论”课程的“男”同学的成绩表












![[大模型]Yi-6B-chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/d43df42102a341b4a443cece5c7e214a.png#pic_center)