一、自动化测试理论:
- UI: User Interface (用户接口-用户界面),主要包括:app 和web
- UI自动化测试:使用工具或代码执行用例的过程
- 什么样的项目适合做自动化:
- 需要回归测试项目(甲方自营项目、金融、电商)
- 需求变动不频繁:稳定的模块
- 项目周期长的项目:(甲方自营项目、6个月以上的外包)
- 自动化测试的目的:提高测试效率
二、自动化测试工具及环境
1. 工具:
- QTP:商业、收费、支持UI
- robot framework: python扩展库,使用封装好的关键字驱动、半代码水平、支持UI
- selenium: 开源/免费/主流支持UI
2. 环境搭建:
所需环境: python解释器+ pycharm+selenium+ 浏览器+ 浏览器驱动
selenium: pip install selenium
浏览器驱动: CNPM Binaries Mirror![]() https://registry.npmmirror.com/binary.html?path=chromedriver/
https://registry.npmmirror.com/binary.html?path=chromedriver/
windows:
1、解压下载的驱动,获取到chromedriver.exe
2、将chromedriver.exe复制到python.exe所在⽬录即可(避免再次将chromedrver.exe
添加path变量)
mac:
1、解压下载的驱动,获取到chromedriver
2、将chromedriver复制到/usr/local/bin⽬录即可。
三、元素操作
1. 元素定位
通过代码调用方法查找元素
元素定位方法:
id/ name/ class/ tag_name/ link_text/ partial_link_text/ xpath/ css
步骤:
from selenium import webdriver
# 打开浏览器
driver = webdriver.Chrome("/usr/local/bin/chromedriver")
# 输入url
driver.get("https://www.baidu.com")
# 关闭浏览器
driver.quit()1)id定位
方法: driver.find_element_by_id("id值")
前提:标签必须有id属性
输入方法: 元素.send_keys(“内容”)
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("北京")
driver.find_element_by_id("su").click()2) name 定位
方法:driver.find_element_by_name("name属性值")
前提:标签有name属性
特点:由于name属性值可以重复,所以使用时需要查看是否为唯一
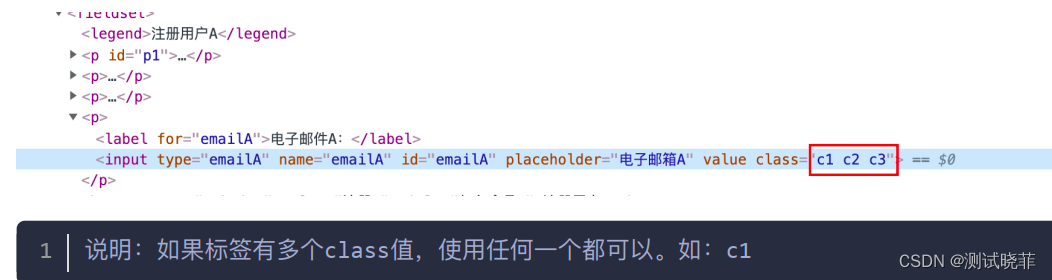
3)class 定位
方法:driver.find_element_by_class_name("class属性值")
前提:标签有class属性
特点:class属性值可以有多个值
4) tag_name 定位
说明:根据标签名进行定位
方法: driver.find_element_by_tag_name("标签名")
提示: 如果页面存在多个相同标签,默认返回第一个
5)link_text 定位
说明:根据链接文本(a标签)定位
方法: driver.find_element_by_link_text("链接文本")
特点:传入的链接文本, 必须全部匹配,不能模糊
6)partial_link_text 定位
说明:根据连接文本(a标签)定位
方法: driver.find_element_by_partial_link_text("连接文本")
特点:传入的链接文本, 支持模糊匹配(传入局部文字)
7)扩展-查找一组元素
说明:返回列表格式
方法:driver.find_elements_by_xxx()
提示:如果没有搜索到符合的标签,会返回空列表
2. 元素定位(xpath\css)
为什么要学习 xpath 和 css?
如果标签没有id/name/class 属性,也不是链接标签,只能用 tag_name定位,比较麻烦。
使用xpath 和 css 比较方便,支持任意属性和层级来查找元素
1)xpath
是 xml path 的简称,使用标签路径来定位

属性:
单属性://*[@属性名='属性值']
多属性://*[@属性名='属性值' and @属性名='属性值']
层级与属性:
说明:如果元素现有的属性不能唯一匹配,需要结合层级使用
语法:
//父标签/子标签 必须为直属子级
//父标签[@属性='值']//后代标签 父和后代之间可以跨越元素
扩展:
根据显示文本定位: //*[text()='文本值']
属性模糊匹配://*[contains(@属性名,'属性部分值')]
2)css选择器
css选择器是html查找元素的工具
id选择器/类选择器/标签选择器/属性选择器/层级选择器
id选择器:
语法:#id属性值
前提: 标签必须有id属性
类选择器:
语法:.class属性值
前提:标签必须有class属性
标签选择器:
语法:标签名
提示:注意标签是否在页面中唯一,否则返回单个或所有
属性选择器:
语法: [属性名='属性值']
层级选择器:
父子关系: 选择器>选择器 ,比如: #p1>input
后代关系:选择器 选择器 比如:#p1 input
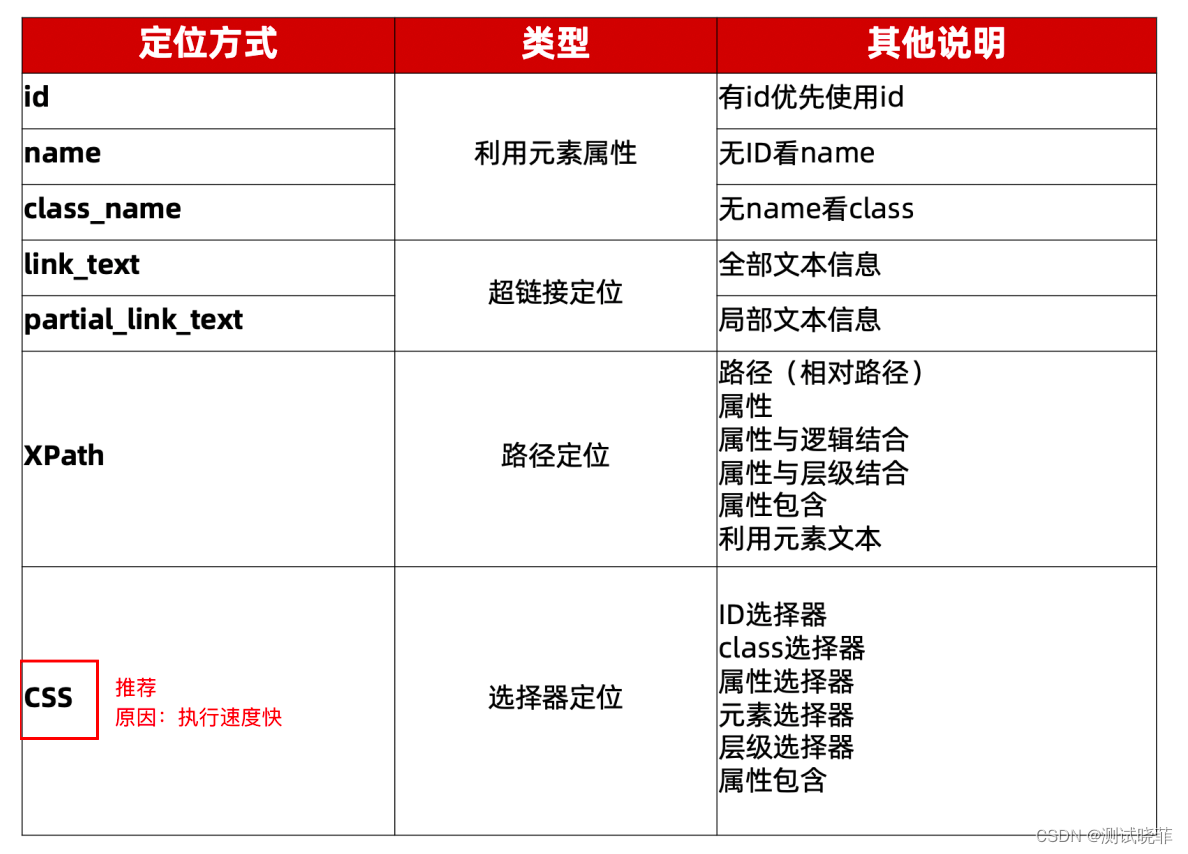
元素定位总结:
3. 元素的常用操作方法:
点击 元素.click()
输入 元素.send_keys(内容)
清空 元素.clear()
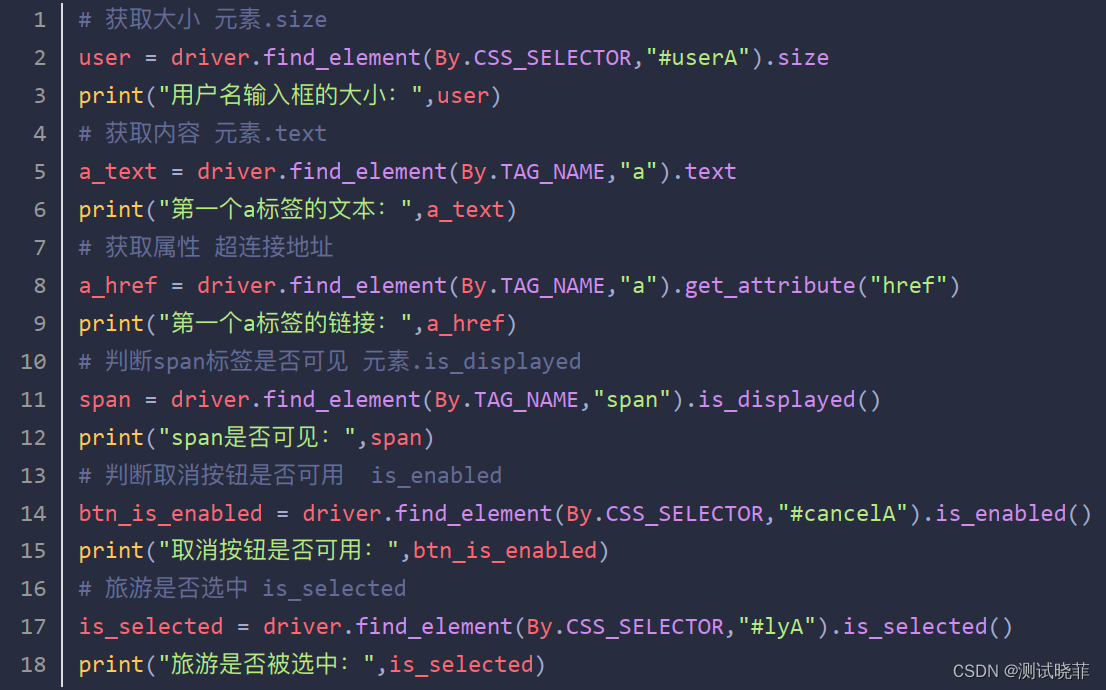
获取元素信息
- 获取大小: 元素.size
- 获取文本: 元素.text
- 获取属性:元素.get_attribute('属性名')
- 元素是否可见: 元素.is_displayed()
- 元素是否可用:元素.is_enabled()
- 元素是否选中: 元素.is_selected()
4. 浏览器的操作
浏览器常用的api:
窗口最大化: driver.maximize_window()
设置窗口大小: driver.set_window_size(width,height)
设置窗口位置:driver.set_window_position(x,y)
页面后退操作:driver.back()
页面前置操作:driver.forward()
页面刷新:driver.refresh()
浏览器常用获取信息api:
关闭当前窗口: driver.close()
关闭浏览器:driver.quit()
获取标题:driver.title
获取网页地址: driver.current_url








![[大模型]Yi-6B-chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/d43df42102a341b4a443cece5c7e214a.png#pic_center)