词袋模型(BoW)是自然语言处理(NLP)和机器学习中一种简单而广泛使用的文本表示方法。它将文本文档转换为数值特征向量,使得可以对文本数据执行数学和统计操作。词袋模型将文本视为无序的单词集合(或“袋”),忽略语法和单词顺序但保留重数。
我们研究两种类型的词袋向量:
- 原始计数:实际计算文本中每个单词出现的次数
- TF-IDF:调整原始计数,以偏好那些在少数文档中大量出现的单词,而不是那些在所有文档中广泛出现的单词
定义
文档与语料库:
- 文档是您用例的最小文本单位
- 语料库是您的文档集合
- 用例:考虑您正在寻找答案的典型问题
- 查询:您将用来在语料库中搜索的文本
分词器
分词器是一个程序,它接收文本并将其拆分成更小的单元。一本书可以被拆分成章节、段落、句子、单词。这些都是分词过程的例子。
一旦文本被分词成句子,您就可以将句子分词成单词。
句子
在自然语言中,文本由多个句子组成,句子之间通过如.这样的标点符号分隔。然而,将文本拆分成句子仍然是一个挑战,因为一些.表示缩写,例如。
单词:
任何文本都是由单词组成的。有时它们通过空格或标点符号很好地分隔开来。如同句子一样,有些单词包含标点符号,比如U.S.A.或to court-martial。
词汇表:语料库中使用的独特单词列表。
下面我们用一些实例来演示如何讲一篇长文章进行分割并且将其中的单词向量化等。
import numpy as np
import math
import pandas as pd1. 下载语料库
我们将使用某些来自阿瑟·柯南·道尔爵士的《波希米亚的丑闻》这一福尔摩斯故事的短片段。
我们将从这本书的第一段开始。
语料库(Corpus):《波希米亚的丑闻》中的所有句子
文档(Document):书中的1个句子
import requests
r = requests.get('https://sherlock-holm.es/stories/plain-text/scan.txt')
assert r.status_code == 200
with open('scandal_in_bohemia.txt', 'w') as out:
out.write(r.content.decode('utf-8'))
lines = [txt for txt in open('scandal_in_bohemia.txt') if len(txt.strip()) > 0]
print(lines[:20])
# First Paragraph
par = ' '.join([x.strip() for x in lines[7:25]])
import textwrap
print(textwrap.fill(par, width=80))2. 引入NLK库
import nltk
nltk.download('punkt')3. 引入sentence tokenizer讲一篇文章分割成句子
from nltk.tokenize import sent_tokenize
nltk_sentences = sent_tokenize(par)
nltk_sentences3. 引入word tokenizer讲一个句子分割成单词
from nltk.tokenize import word_tokenize
nltk_tokens = word_tokenize(nltk_sentences[0])
nltk_tokens我们也可以利用SpaCy进行类似的转换,代码如下:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(par)
spacy_sentences = list(doc.sents)
spacy_sentences
spacy_tokens = [x for x in spacy_sentences[0]]
spacy_tokens4. 向量化
下面我们来定义一个function用来显示文章中的单词,方法的输入为向量器,可以是CountVectorizer :
#文字向量化
from sklearn.feature_extraction.text import CountVectorizer
def show_vocabulary(vectorizer):
words = vectorizer.get_feature_names_out()
print(f'Vocabulary size: {len(words)} words')
# we can print ~10 words per line
for l in np.array_split(words, math.ceil(len(words) / 10)):
print(''.join([f'{x:<15}' for x in l]))
count_small = CountVectorizer(lowercase=False) #没有将单词转化成小写
count_small.fit(nltk_sentences)
show_vocabulary(count_small)
输出结果:

words = vectorizer.get_feature_names_out(): 此行在向量器对象上调用方法get_feature_names_out()。此方法返回向量器从数据中学到的特征名称(单词或符号)的数组。这些名称代表转换后的特征矩阵中的列。- 循环
for l in np.array_split(words, math.ceil(len(words) / 10)):将words数组分割成较小的块,目标是每块大约10个单词。np.array_split是一个来自NumPy的函数,用于将数组划分成多个子数组。 math.ceil(len(words) / 10)通过将单词总数除以10并向上取整来计算块的数量,以确保即使总数不是10的完美倍数也包括所有单词''.join([f'{x:<15}' for x in l]): 在循环内部,列表推导为块l中的每个单词生成一个格式化字符串。格式说明符{x:<15}为单词x添加填充,确保它至少占用15个字符,使输出整齐地排列成列。''.join(...)将列表中的所有格式化字符串连接成一个字符串,然后打印。这导致每个单词块被打印在新行上,每个单词之间间隔均匀。
如果我们将lowercase=Ture,讲所有大写转化成小写;输出结果为:
count_small = CountVectorizer(lowercase=True)
count_small.fit(nltk_sentences)
show_vocabulary(count_small)
下面定义另外一个function用来显示向量化的结果:
import os
os.environ["FORCE_COLOR"] = "1"
#termcolor 是一个用于给终端文本上色的Python模块。
#此导入对于下面定义的输出函数的视觉方面至关重要。
from termcolor import colored
def show_bow(vectorizer, bow):
words = vectorizer.get_feature_names_out()
# we can print ~8 words + coefs per line
for l in np.array_split(list(zip(words, bow)), math.ceil(len(words) / 8)):
print(' | '.join([colored(f'{w:<15}:{n:>2}', 'grey') if int(n) == 0 else colored(f'{w:<15}:{n:>2}', on_color='on_yellow', attrs=['bold']) for w, n in l ]))
def show_bow_float(vectorizer, bow):
words = vectorizer.get_feature_names_out()
# we can print ~6 words + coefs per line
for l in np.array_split(list(zip(words, bow)), math.ceil(len(words) / 6)):
print(' | '.join([colored(f'{w:<15}:{float(n):>0.2f}', 'grey') if float(n) == 0 else colored(f'{w:<15}:{float(n):>0.2f}', on_color='on_yellow', attrs=['bold']) for w, n in l ]))
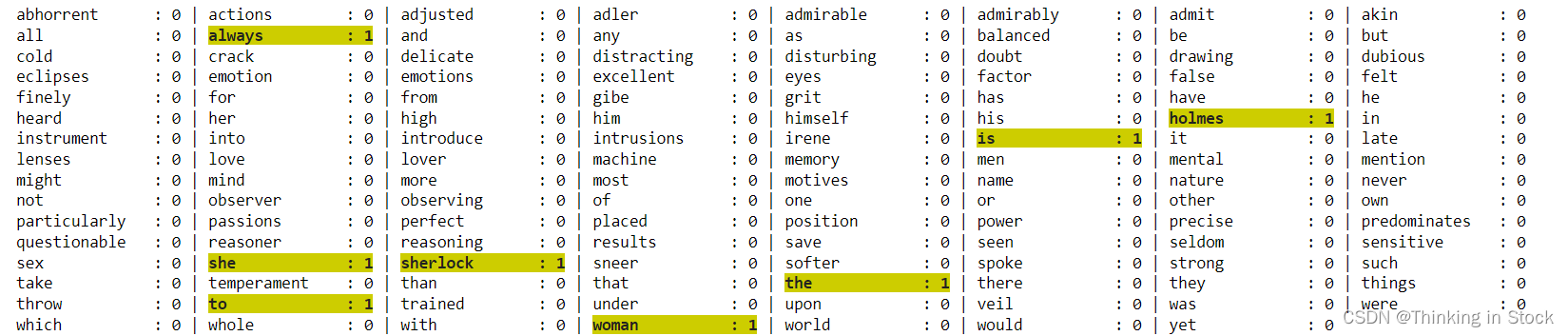
s = nltk_sentences[0]
print(f'Text: "{s}"')
bow = count_small.transform([s])
print(f'BoW Shape: {bow.shape}')
bow = bow.toarray() # From sparse matrix to dense matrix (Careful with MEMORY)
print(f'BoW Vector: {bow}')
show_bow(count_small, bow[0])函数 show_bow(vectorizer, bow):
- 目的:显示整数计数的词袋向量。
- 参数:
vectorizer:一个向量器对象,具有get_feature_names_out()等方法,通常来自诸如scikit-learn(例如,CountVectorizer)的库。bow:一个词袋向量(通常是一个稀疏数组或列表),包含由向量器确定的每个单词的频率计数。
- 过程:
- 从向量器中检索词汇,并将每个单词与其在
bow中对应的计数配对。 - 将单词和计数配对在一起,然后将它们分成每行大约8对。
- 打印每个单词及其计数,突出显示非零计数(用黄色加粗显示),以便它们在灰色显示的零计数中脱颖而出。
- 从向量器中检索词汇,并将每个单词与其在
函数 show_bow_float(vectorizer, bow):
- 目的:显示浮点系数的词袋向量(BoW),适用于如TF-IDF这样的情况,其中计数已标准化。
- 参数:
- 与
show_bow类似,但预期bow向量包含浮点数。
- 与
- 过程:
- 与
show_bow类似,但将数字格式化为浮点数,并调整显示以适应每行约6对的格式,因为浮点表示需要额外的空间。
- 与
运行结果: