GPDB技术内幕 - SEMI JOIN浅析
SEMI JOIN顾名思义,半连接,相对于join字段来说,针对外表的一行记录,内表只要有一条满足,就输出外表记录。注意,这里是仅输出外表记录。GPDB中有几种实现方式,本文我们简单聊聊。
从代码中,我们看到SEMI JOIN的类型有3类:

1、JOIN_SEMI
这是普通实现方式。针对nestloop join、merge join、hash join的inner join来说,只要针对JOIN字段,内表有记录就输出外表记录。以nestloop join为例:
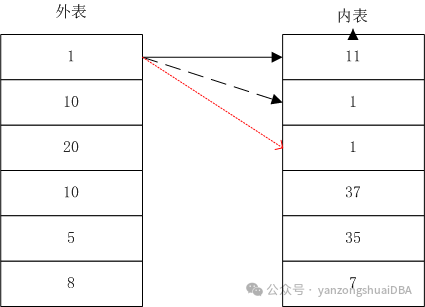
外表和内表记录是无序的,针对外表第一个记录1,遍历内表。内表第一记录为11,不匹配,继续下一条记录;下一条是1,join匹配,输出外表1的值;此时针对外表记录1,就不必继续内表扫描了,join结束,继续外表下一个记录10重新扫描内表进行join条件判断。
这种方式是通用实现方式。下面看第二种实现方式。
2、JOIN_UNIQUE_OUTER/JOIN_UNIQUE_INNER
从SEMI JOIN的语义中,可以看出join过成中,外表一个值仅能匹配内表一个值;这样我们就可以先将内表进行去重,然后再进行普通inner join,从而实现SEMI JOIN。
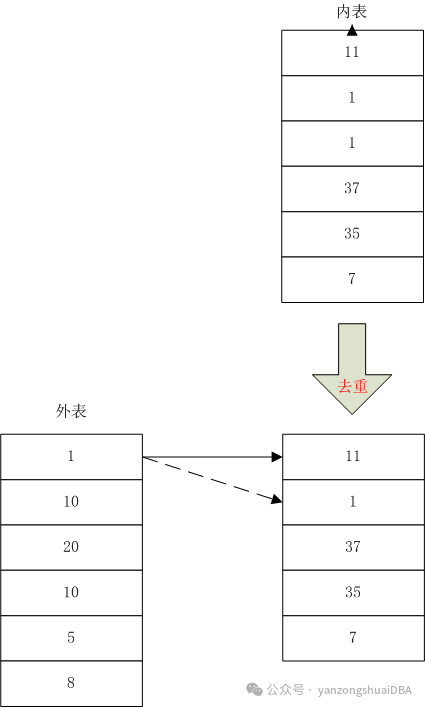
先将内表进行去重:可以通过group by进行聚合(hash agg或者sort agg)去重得到内表值;然后针对外表1,顺序扫描内表去重后的值11,不匹配,继续下一个值;下一个值是1,匹配,输出外表值1。针对Join的结果,内表因为去过重,所以满足join条件的必然只有一个值。
3、JOIN_DEDUP_SEMI/JOIN_DEDUP_SEMI_REVERSE
以上两种实现方式是沿用PgSQL,针对的是集中式实现方式。GPDB是分布式,当分布键不匹配时,就需要进行广播MOTION,即使每个segment上去过重,广播MOTION后仍旧可能存在重复值,这样就不能使用第2种实现方式。比如下面案例:第三种实现方式
postgres=# explain select * from s where exists (select 1 from r where s.a = r.b);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Gather Motion 3:1 (slice1; segments: 3) (cost=153.50..155.83 rows=100 width=8)
-> HashAggregate (cost=153.50..153.83 rows=34 width=8)
Group Key: (RowIdExpr)
-> Redistribute Motion 3:3 (slice2; segments: 3) (cost=11.75..153.00 rows=34 width=8)
Hash Key: (RowIdExpr)
-> Hash Join (cost=11.75..151.00 rows=34 width=8)
Hash Cond: (r.b = s.a)
-> Seq Scan on r (cost=0.00..112.00 rows=3334 width=4)
-> Hash (cost=8.00..8.00 rows=100 width=8)
-> Broadcast Motion 3:3 (slice3; segments: 3) (cost=0.00..8.00 rows=100 width=8)
-> Seq Scan on s (cost=0.00..4.00 rows=34 width=8)
Optimizer: Postgres query optimizer
(12 rows)分析:
1)上面案例s作为内表,r作为外表。s表远大于r表。s广播motion记录数量众多,代价非常大
2)Hash join构建hash表阶段进行去重
3)外表r不可以广播motion,否则会产生重复值
4)基于上述原因,只能选择广播大表进行JOIN_SEMI了
所以,GPDB实现了第3种方式,即先进行join,然后再去重。主要是为了能够广播小表,比如上述例子种的小表r(作为外表),即使产生重复值也可以在去重阶段去掉。
为了方便去重,GPDB引入了表达式RowIdExpr,即去重操作:DISTINCT ON (RowIdExpr)。该表达式为一条记录产生唯一标识值,附加到该记录中作为一个额外字段。广播后进行join,相对于JOIN_SEMI计划,多了一个重分布MOTION节点,当然MOTION的记录都非常少。上述例子中可以看到hash join后需要在RowIdExpr上进行重分布,然后再在RowIdExpr这个字段上通过Hash Agg进行去重。鉴于hash join前的广播分布和join后的重分布传输的记录数量都比较小,JOIN_DEDUP_SEMI实现方式就在三种实现方式中胜出了。