01 背景
随着云计算、大数据技术的日趋成熟,复杂多元、规模庞大的数据所蕴含的经济价值和社会价值逐步凸显,数据安全也是企业面临的巨大挑战,B站一直致力于对用户隐私数据的保护。
02 Ranger概述
2.1 用户认证
提到安全,就不得不提及用户认证,Hadoop默认是没有安全认证的,用户可以伪装成任意用户访问集群,存在巨大安全隐患。Hadoop 1.x 版本以后就已经加入了Kerberos认证机制,只有经过认证的用户才可以访问集群,目前我们数据平台的客户端及早期开放给用户的一些开发客户端已经全部接入了Kerberos。
2.2 Ranger介绍
Kerberos只是控制集群的登录,相当于一把钥匙打开了进入集群操作的大门,并没有实现用户操作权限的管理,因此我们引入Ranger做权限管理。
Ranger提供一个集中式安全管理框架,它可以对Hadoop生态的组件如HDFS、Yarn、Hive、HBase等进行细粒度的数据访问控制,基本覆盖现有技术栈的组件。通过操作Ranger控制台和REST API,可以轻松的通过配置策略来控制用户访问权限。
我们使用的Ranger是基于1.2.0版本改造的,部署了2台写节点和2台读节点并接入公司的负载均衡系统来实现读写分离,用户在申请Hive表或者HDFS path,交接表或者交接任务时,会发送请求给Shielder(Shielder是工具侧的授权服务),授权时接入写节点的LB,shielder会通过LB调用Ranger Admin的REST API进行权限操作,Ranger Admin将相关policy持久化到DB,赋权完成后Shielder还会通过LB调用读节点的REST API进行权限预检,预检通过后用户申请权限的流程就结束了。
读节点的Ranger Admin会定时的从DB中全量load policy,plugins在poll policy时,Ranger Admin会将内存中的policy返回给嵌入在各个大数据组件的plugins。

03 HDFS Path鉴权
3.1 授权接口的改造
原生的Ranger授权接口需要传入RangerPolicy,对于工具层需要给HDFS表路径或者非表路径授权比较繁琐,因此我们改造了授权接口,只需要传入四个参数,如下:
-
service : ranger service name,用于识别service
-
type:path或者table,用于识别是为表赋权还是为路径赋权
-
resources:具体的HDFS路径或者Hive表
-
access:具体的权限类型,read或者write
如果type是table,会根据resources中的table,通过Hive Metastore(HMS) client获取table location,再根据路径查找相关policy是否存在来决定是更新还是创建。
3.2 Ranger Admin的改造
由于我们使用的Ranger版本需要全量load policy,原生的Ranger Admin load policy是从DB中串行的读取,数据读出来以后放在List中,通过ListIterator将各部分的数据拼接成Policy,拼接后如果检查到有的ListIterator还有next,说明在读数据是有policy发生了变化,需要重新读数据,这样load policy的时间就不可控了。为了降低Admin load policy的时间,我们将从DB中读数据的操作由串行改成并行,我们使用Map存放Policy数据,并取消了ListIterator对不齐时需要二次读数据的机制,这样虽然可能会导致在读数据的时候新增的access可能匹配不上item,但是在下一次读取的时候必然会匹配上,一次load policy的误差是在我们的接受范围内的。由于我们使用Map做policy拼接,读取item及access时的order by操作就可以取消了。
例如读access的query就由
select obj from XXPolicyItemAccess obj, XXPolicyItem itemwhere obj.policyItemId = item.idand item.policyId in (select policy.id from XXPolicy policy where policy.service = :serviceId)order by item.policyId, obj.policyItemId, obj.order
变成
select obj from XXPolicyItemAccess obj, XXPolicyItem itemwhere obj.policyItemId = item.idand item.policyId in (select policy.id from XXPolicy policy where policy.service = :serviceId)
目前我们HDFS有约18万的policy,70万的policy item,200万的policy item access,去掉order by后load access可以节约4s左右的时间,整体load policy的时间在25s左右。
3.3 灰度上线
为了鉴权可以优雅的上线,减少因权限问题导致的任务失败,我们在HDFS plugin端增加了鉴权模式,支持按group(一个部门对应一个group)灰度上线鉴权功能,鉴权模式分为ALWAYS_ALLOW,ALWAYS_DENY和BY_HADOOP_ACL,鉴权时在没有匹配到policy的情况下才会用上述鉴权模式进行检查,若模式为ALWAYS_ALLOW的情况下,会检查user的group是不是在strict group中,strict group可以通过配置文件配置,支持hadoop命令刷新,更新strict group配置后不用重启namenode就可以使其生效。在strict group中的user为严格鉴权,如果没有相关policy会拒绝访问HDFS,否则允许其访问,同时打印越权日志,可以根据越权日志决定为用户补权限。在所有的部门组灰度完成以后,鉴权模式切换到ALWAYS_DENY即可。

3.4 权限预检
由于权限生效会有一定的延迟,工具侧在调用Ranger api赋权以后,没办法感知权限是否生效,往往会发生工单流程已经走完,用户还是没有的权限的情况。再者我们在排查user是否有一个路径权限时,可能会因为父路径权限的影响,排查起来会繁琐一些,因此我们在Admin端开发了权限预检查的接口,支持传入user,库表及相应的权限类型,返回权限检查是否成功。
根据传入的HDFS Path,User和Accesses的类型构建RangerAccessRequest,通过RangerPolicyRepository的getLikelyMatchPolicyEvaluators方法获取evaluators,遍历evaluators计算得到result。同时会启动一个 线程定时的从RangerServicePoliciesCache中获取ServicePolicies,用于更新RangerPolicyRepository,频率与plugin poll policy的频率相同。

04 Hive Table鉴权
4.1 HDFS鉴权的痛点
HDFS鉴权在使用的过程中遇到了一些问题,比如table owner没有权限drop自己的表情况,对于管理表来说,drop表时会删除相应的表路径,对于HDFS来说删除路径需要父路径的write权限,但是该用户又没有库的写权限,导致drop表失败。还有比如view的HDFS路径与相应表的HDFS路径是同一个,如果只回收表的权限,相当于回收了HDFS路径的权限,用户即使还有view的权限,在访问HDFS的时候就会失败。而且HDFS鉴权也只能到path级别,无法进行更细粒度的鉴权和数据脱敏,因此我们引入了Hive Table鉴权。
4.2 Hive授权接口
Ranger各个service之前的policy是相互独立的,HDFS plugin在鉴权的时候只关心HDFS的policy,因此我们在Hive的授权的同时会将Hive的权限类型转换成HDFS的权限为HDFS赋权。
4.3 Hive Metastore远程鉴权及数据脱敏
Ranger所有的Plugin的load policy的机制都是相同的,需要请求Ranger Admin获取policy,将Policy缓存到内存并持久化到磁盘,这对于像HiveServer2,Spark Thrift Server和Kyuubi这样的长服务来说是可以接受的,但是对于像Hive Cli和Spark Sql这样的短任务,load policy会消耗大量的时间,内存和磁盘,也会增加Ranger Admin的负载。
因此,我们将鉴权和脱敏的功能放到Hive Metastore 中去做,实现了一个类似于Hive Plugin的Hive MetaStore Plugin,Hive Metastore新增了鉴权和脱敏两个接口。
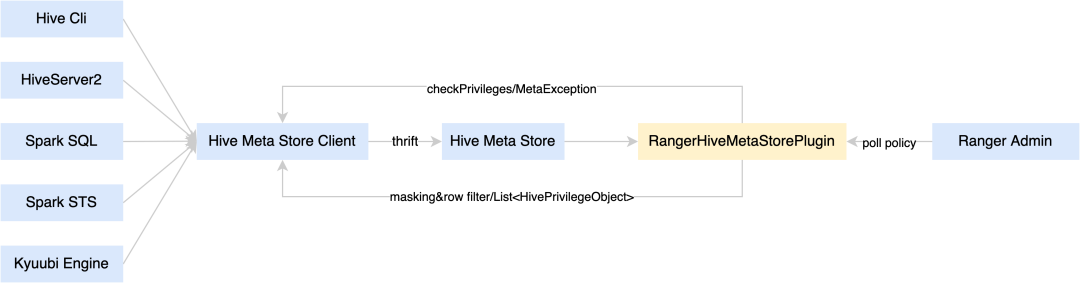
鉴权
将鉴权的请求参数封装到CheckPrivilegesBag中,无论是Hive还是Spark只要构建好CheckPrivilegesBag请求HMS即可。
struct CheckPrivilegesBag {1: HiveOperationObjectType hiveOperationObjectType, // 操作类型2: list<HiveObjectPrivileges> inputPrivileges, // 输入表信息3: list<HiveObjectPrivileges> outputPrivileges, // 输出表信息4: HiveAuthzContextObject hiveAuthzContext,5: string user,}
脱敏
row filter和column masking需要传入HiveAuthzContextObject,list<HiveObjectPrivileges>和user。
list<HiveObjectPrivileges> apply_row_filter_and_column_masking(1:HiveAuthzContextObject hiveAuthzContextObject,2: list<HiveObjectPrivileges> objectPrivileges, 3: string user) throws(1:MetaException o1)
4.4 Spark Ranger
Spark Ranger是通过inject Rule和Strategy解析plan来实现鉴权和脱敏的,改造成通过HMS鉴权,需要将SparkOperationType和SparkPrivilegeObject转换成对应的HiveOperationType和HivePrivilegeObject。
由于用来鉴权的RangerSparkAuthorizerExtension Rule可能会被执行多次,会做一些不必要的鉴权,带来额外的时间开销,查询表比较多的query在耗时上会更加明显。我们会将鉴权成功的输入表/字段和输出表/字段的相关信息缓存起来,下一次鉴权时首先剔除掉缓存中已通过鉴权的表/字段,如果剩余的不为空,再继续请求HMS鉴权
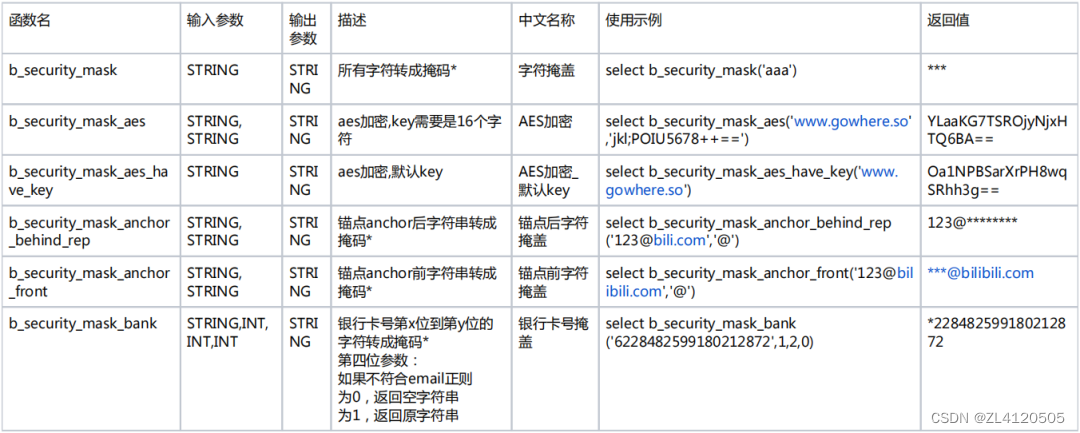
目前我们Spark和Hive已经全接入了HMS鉴权和数据脱敏,对于数据脱敏中的column masking,我们正在用的策略(部分)有:
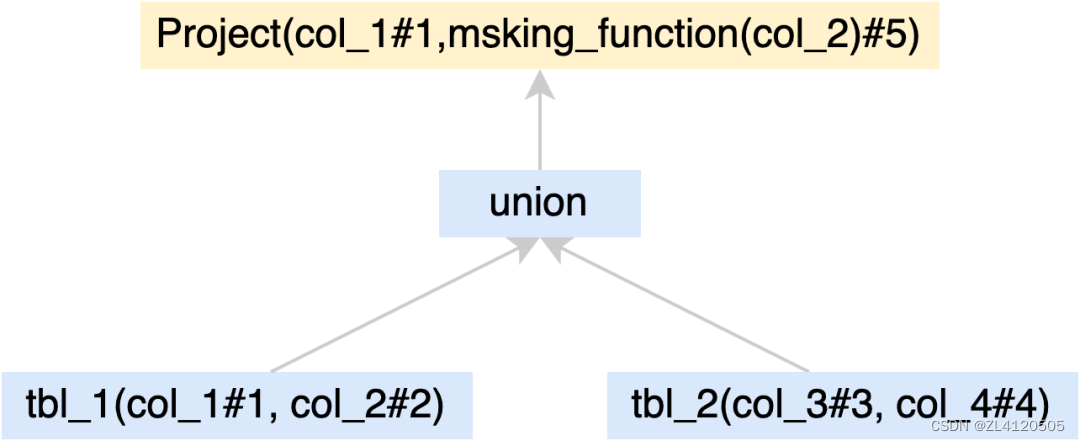
另外,我们在使用spark ranger做column masking的时候也遇到了一些问题,比如对于sql:
select col_1, col_2 from tbl_1 union select col_3, col_4 from tbl_2如果col_2和col_4的policy是不同的,终col_4的数据也会使用col_2的making policy,因为spark ranger的做法是在外层加一个Project,这样就会导致col_4的policy失效。
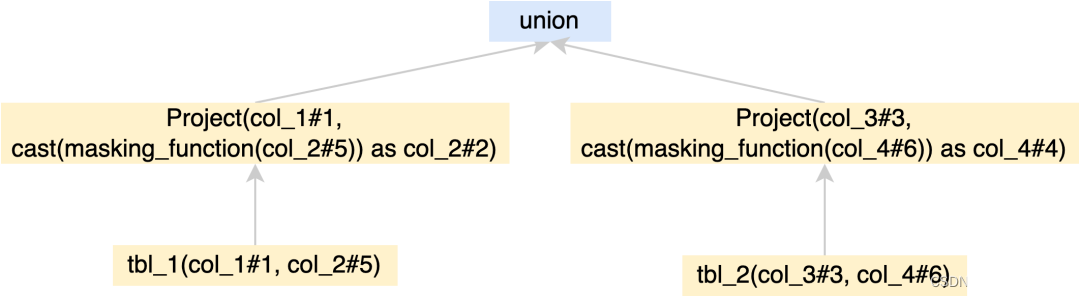
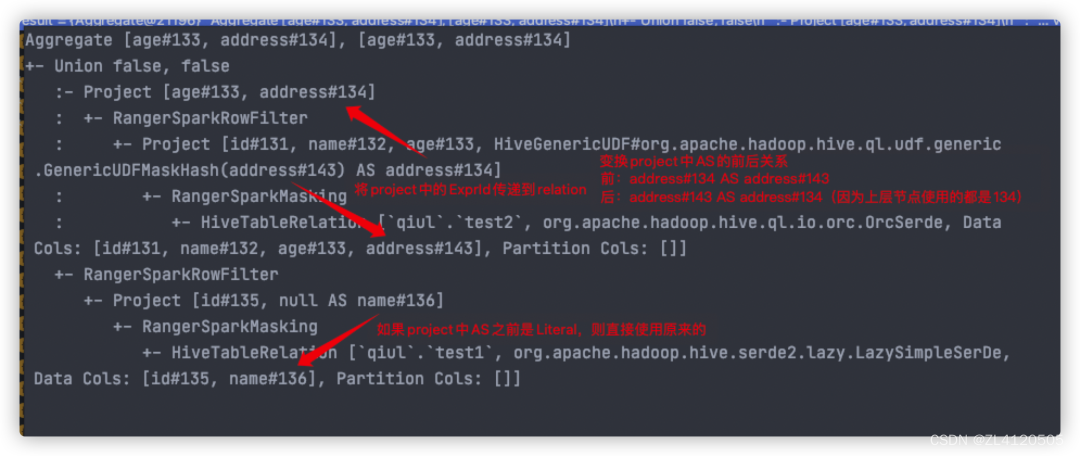
我们将Project推到Relation层,替换掉有making的column,在Project中将经过masking处理后的column cast成原始的column,执行计划就变成:
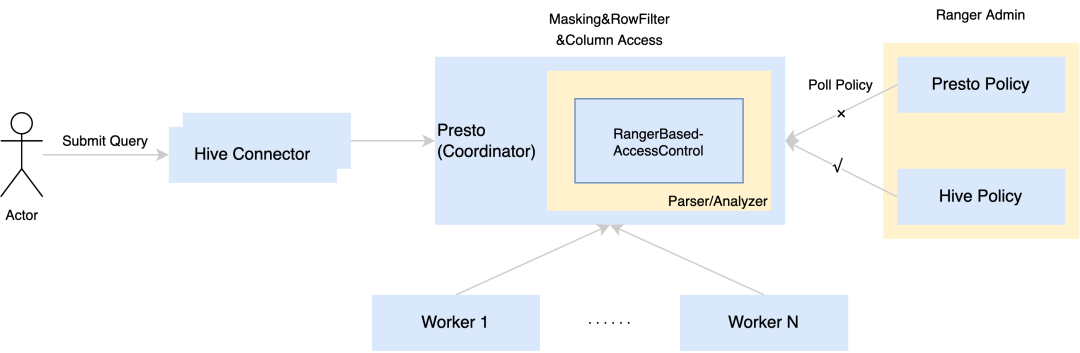
4.5 Presto Ranger
鉴于Presto Coordinator为常驻服务,从Ranger Admin获取并加载policy所带来的消耗是可接受的,因此我们在Presto Ranger Plugin上进行改造。社区鉴权逻辑为:首先定期请求Ranger Admin获取Presto相关的policy并将其拉取到本地,其次在Presto每次进行语义分析的时候,对当前表及字段的权限进行校验。对上述鉴权逻辑进行分析,我们不难发现社区的鉴权方式需要在Admin侧单独维护Presto相关的policy,而在我们的场景中大部分的权限需求还是在Hive中,为不同引擎各自维护一套policy无疑会增加运维成本,因此我们对其做了些改造,使其兼容Hive的policy。其实现方式并不复杂,一方面,将拉取Presto policy替换为拉取Hive policy;另一方面,将原先Presto plugin的3段式进行改造兼容Hive的格式。目前我们的Presto Ranger支持了表/字段、column masking和row filter的权限控制。
05 未来规划
5.1 增量Load Policy
即使我们优化了load policy的逻辑,plugin权限生效的时间也要在25s以上,而且随着policy的增加,这个时间还将进一步增加,Ranger-2.0.0版本已经支持了增量Load Policy功能,下半年我们也会参考社区做增量化改造,降低权限生效时间,预估能到1s内。
5.2 HDFS融合Hive Policy
Hive鉴权通过以后,任务访问HDFS还需要再经过HDFS的鉴权,这样就需要维护Hive和HDFS两份Policy,而且也不能解决前面提到的table owner无法删除自己的表的情况,下一步我们会将Hive Policy与HDFS Plugin融合起来,HDFS Plugin中维护一份table location数据,在检查路径权限时,首先检查路径对应的Hive Table是否有相应的权限,如果有就可以通过权限检查,如果没有匹配到table再检查HDFS Policy。
5.3 HDFS鉴权前置到NNProxy
目前我们HDFS有20+组的NS,每一组NS都要连接Ranger Admin获取policy,无疑增加了Ranger Admin的压力,后面我们考虑将HDFS鉴权的操作前置到NNProxy中去做,同时也能降低NameNode的处理时间。



![[大模型]Langchain-Chatchat安装和使用](https://img-blog.csdnimg.cn/img_convert/85e9661b26c5b5bd6b425c6d4f3df1db.jpeg)