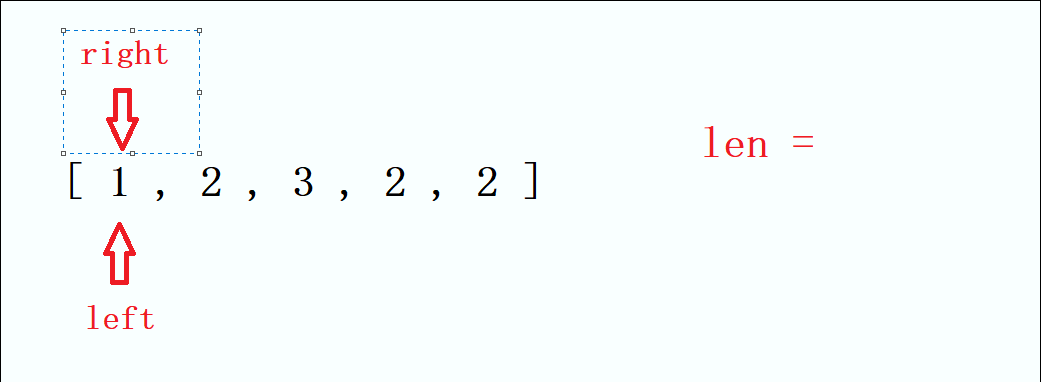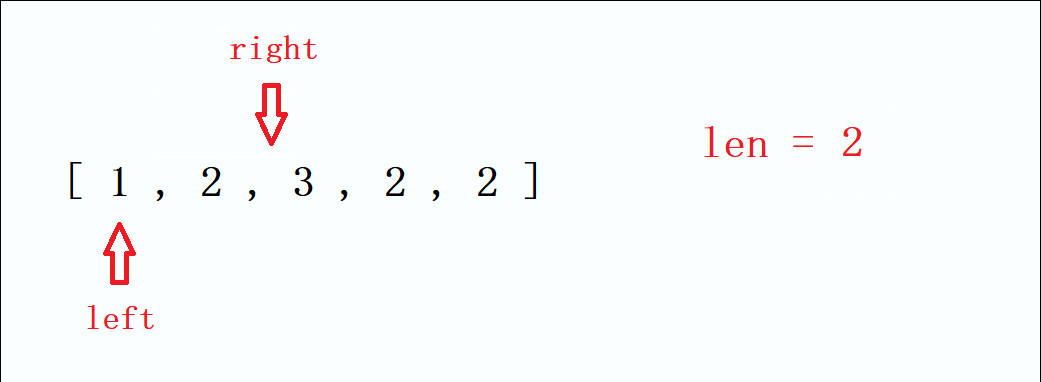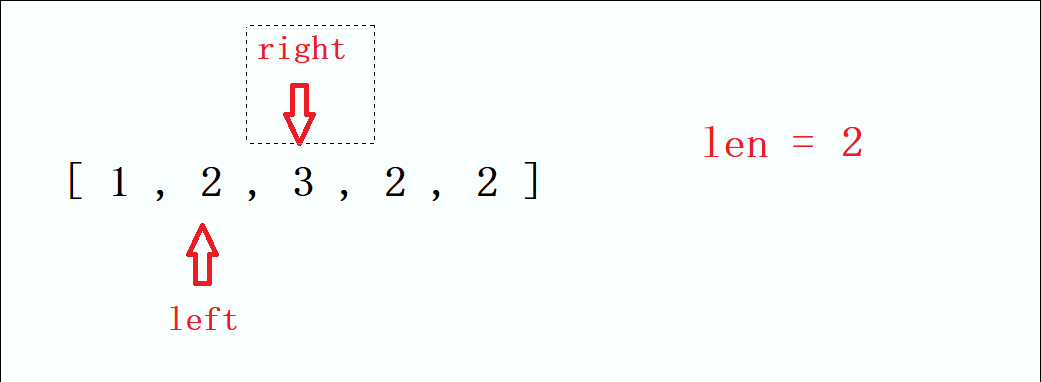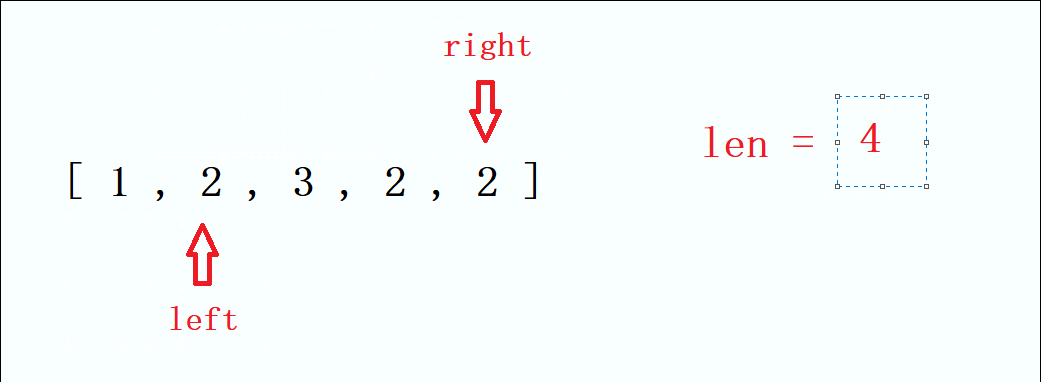第五章开始啦~~~~~~~~~~~~~
防抖和节流之前自己有学过一次,包括几种方式怎么实现,代码如何写花了两天有写过,这次算是更系统的一个复习加填补
十七、防抖与节流
为什么需要防抖和节流:
在一些高频率事件触发的场景下我们不希望对应的事件处理函数多次执行
场景:
滚动事件(滚轮)
输入的模糊匹配
轮播图切换
点击操作
…
为什么会出现这样的情况?
浏览器默认情况下都会有自己的监听事件间隔( 4~6ms),如果检测到多次事件的监听执行,那么就会造成不必要的资源浪费,所以这里需要一种机制,就是防抖和节流
前置的场景: 界面上有一个按钮,我们可以连续多次点击
防抖:对于这个高频的操作来说,我们只希望识别一次点击,可以人为是第一次或者是最后一次
节流:对于高频操作,我们可以自己来设置频率,让本来会执行很多次的事件触发,按着我们定义的频率减少触发的次数
1.防抖实现
/**
* handle 最终需要执行的事件监听
* wait 事件触发之后多久开始执行,不写形参是为了方法的形参等问题的处理较为麻烦
* immediate 控制执行第一次还是最后一次,false 执行最后一次
*/
function myDebounce(handle, wait, immediate) {
// 参数类型判断及默认值处理
if (typeof handle !== 'function') throw new Error('handle must be an function')
if (typeof wait === 'undefined') wait = 300
if (typeof wait === 'boolean') {
immediate = wait
wait = 300
}
if (typeof immediate !== 'boolean') immediate = false
// 所谓的防抖效果我们想要实现的就是有一个 ”人“ 可以管理 handle 的执行次数
// 如果我们想要执行最后一次,那就意味着无论我们当前点击了多少次,前面的N-1次都无用
// return function的时候直接初始化的返回了一个函数赋值给了按钮的点击事件,然后点击按钮的时候
//this和...args是这两个参数才会赋值给这个函数,所以不用箭头函数可以获取到this和args
let timer = null
return function proxy(...args) {
let self = this,init = immediate && !timer
clearTimeout(timer)
timer = setTimeout(() => {
timer = null
!immediate ? handle.call(self, ...args) : null
}, wait)
十七、十七、
// 如果当前传递进来的是 true 就表示我们需要立即执行
// 如果想要实现只在第一次执行,那么可以添加上 timer 为 null 做为判断
// 因为只要 timer 为 Null 就意味着没有第二次....点击
init ? handle.call(self, ...args) : null
}
}
// 定义事件执行函数
function btnClick(ev) {
console.log('点击了1111', this, ev)
}
// 当我们执行了按钮点击之后就会执行...返回的 proxy
let oBtn = document.getElementById('btn')
oBtn.onclick = myDebounce(btnClick, 200, false)
2.节流实现
节流:我们这里的节流指的就是在自定义的一段时间内让事件进行触发
核心的思想,就是给事件赋值函数的时候不直接赋值相应的直行函数,而是赋值一个代理函数
以滚动事件触发为例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>节流函数实现</title>
<style>
body {
height: 5000px;
}
</style>
</head>
<body>
<script>
// 节流:我们这里的节流指的就是在自定义的一段时间内让事件进行触发
function myThrottle(handle, wait) {
if (typeof handle !== 'function') throw new Error('handle must be an function')
if (typeof wait === 'undefined') wait = 400
let previous = 0 // 定义变量记录上一次执行时的时间
let timer = null // 用它来管理定时器
return function proxy(...args) {
let now = new Date() // 定义变量记录当前次执行的时刻时间点
let self = this
let interval = wait - (now - previous)
if (interval <= 0) {
// 此时就说明是一个非高频次操作,可以执行 handle
clearTimeout(timer)
timer = null
handle.call(self, ...args)
previous = new Date()
} else if (!timer) {
// 当我们发现当前系统中有一个定时器了,就意味着我们不需要再开启定时器
// 此时就说明这次的操作发生在了我们定义的频次时间范围内,那就不应该执行 handle
// 这个时候我们就可以自定义一个定时器,让 handle 在 interval 之后去执行
timer = setTimeout(() => {
clearTimeout(timer) // 这个操作只是将系统中的定时器清除了,但是 timer 中的值还在
timer = null
handle.call(self, ...args)
previous = new Date()
}, interval)
}
}
}
// 定义滚动事件监听
function scrollFn() {
console.log('滚动了')
}
// window.onscroll = scrollFn
window.onscroll = myThrottle(scrollFn, 600)
</script>
</body>
</html>
每一次触发都会开辟一个全新的上下文,因此这里会造成性能上的消耗,造成不必要的资源浪费,因为我们也没必要有这么多的高频触发。
谷歌浏览器会在每5到6ms的时候进行一次事件监听,但是我们不想触发太频繁,因此这里我们想要400ms的时候再去触发,就可以写节流.
这里有一些注意点:
- 写timeout的原因是,当我们处于高频出发时间段内的时候,我们是让他不执行,但是如果后续没有再触发,其实最后一次我们是需要相应的数据的,所以写timeout延迟触发最后一次
- 在设立定时器的时候需要将之前的定时器进行清除,不然会设立多个,只会延迟后面的操作,却不会不执行
- 谷歌浏览器的触发时间点正好跟咱们写的节流函数出发点时间重合的时候,interval <=0成立,但是tiemer确实不为空,定时函数就没有再重新设立,所以需要在上面的判断中,将timer重新清除,这样才可以形成一个新的定时器,为后续使用
- 这里的节流跟我之前看到的节流的实现可能不太一样,但是这一版本确实完善一些,主体思想都是一样的
十八、减少判断层级
在编写代码的过程中避免不了会用到if else判断,但是多层的if判断会影响代码性能,这时我们都可以提前去return掉无效条件,达到嵌套层级的优化效果。
实例原代码:
/**
* 编写一些章节会员判断
* @param part 当前章节
* @param chapter 当前章节数
*/
function doSomeThing(part,chapter){
const parts=['ES2016','工程化','Vue','React','Node'];
if (part){
if (parts.includes(part)){
console.log('当前属于可读模块')
if (chapter > 5){
console.log('该模块是付费内容,您需要提供一个vip身份')
}
}
}else{
console.log('请确认模块信息')
}
}
doSomeThing('ES2016',6)
简化:
function doSomeThing2(part, chapter) {
const parts = ['ES2016', '工程化', 'Vue', 'React', 'Node'];
if (!part) {
console.log('请确认模块信息')
return
}
if (!parts.includes(part)) return
console.log('当前属于可读模块')
if (chapter > 5) {
console.log('该模块是付费内容,您需要提供一个vip身份')
}
}
doSomeThing2('ES2016', 6)
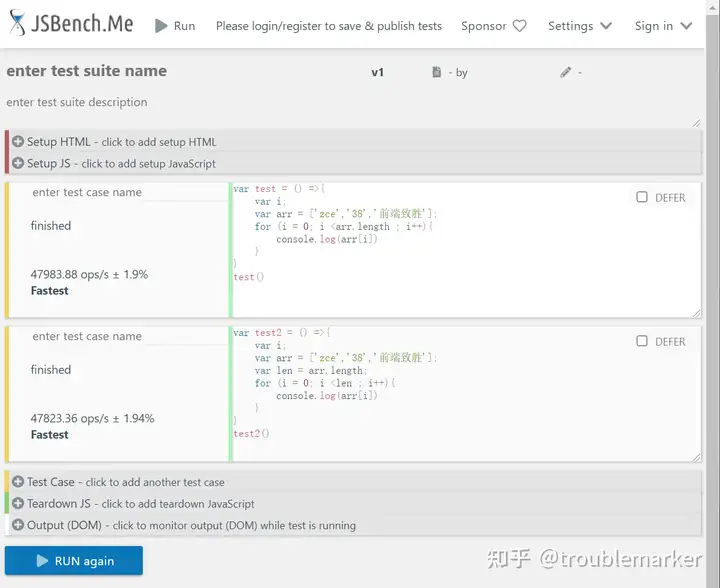
在JSBench中进行测试:

可以看到下面的ops会大一些。
十九、减少循环体活动
主要说功能,而不是哪种实现方式,循环次数固定的情况下,放在循环体里的内容越多,执行效率越慢。有几种优化思路:
1.每次循环都要用到的不变的值,都抽离到循环外面去完成,类似于数据缓存。
例子:
var test = () =>{
var i;
var arr = ['zce','38','前端致胜'];
for (i = 0; i <arr.length ; i++){
console.log(arr[i])
}
}
test()
优化:
var test2 = () =>{
var i;
var arr = ['zce','38','前端致胜'];
var len = arr.length;//减少对象的访问层级
for (i = 0; i <len ; i++){
console.log(arr[i])
}
}
test2()
运行比较:
2.若是我们对于输出顺序没有要求的话,也可以换成while循环,反向进行遍历。
var test3 = () =>{
var arr = ['zce','38','前端致胜'];
var len = arr.length;//减少对象的访问层级
while(len--){
console.log(arr[len])
}
}
test3()
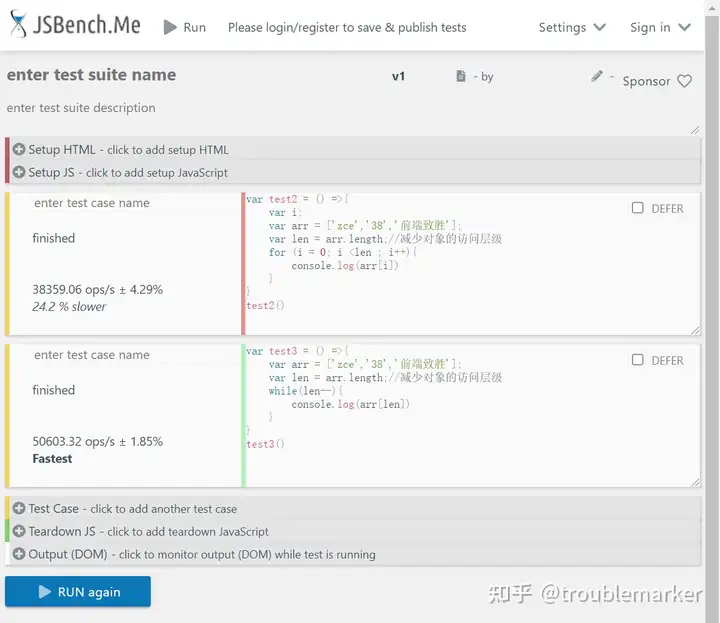
- 代码量变少了
- 从后往前,可以少做很多条件判断
- 效率上如图也提高了
二十、减少循环体活动
不同的数据声明方式在性能上面的关系和表现。
引用类型为例:
构造函数的方式:
let test = () =>{
let obj = new Object();//构造函数的方式
obj.name = 'zce'
obj.age = 38
obj.slogan = '前端致胜'
return obj
}
console.log(test())
字面量方式:
let test2 = () =>{
//字面量方式
let obj = {
name : 'zce',
age : 38,
slogan : '前端致胜'
};
return obj
}
console.log(test2())
对比:
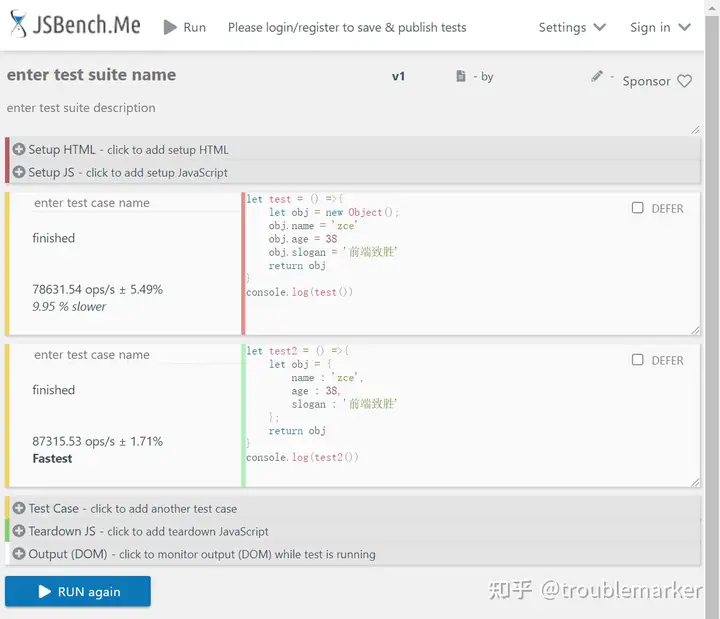
还是能够看出来字面量的方式效率上更快,有一个较大的差异,原因:
- 构造函数声明的方式其实是调用一个函数,而下面字面量的方式是开辟一个空间
- 且代码多
基础数据类型:
var str1 = 'zce说前端致胜'
var str2 = new String('zce说前端致胜')
console.log(str1)
console.log(str2)
//zce说前端致胜
//[String: 'zce说前端致胜']
对比:
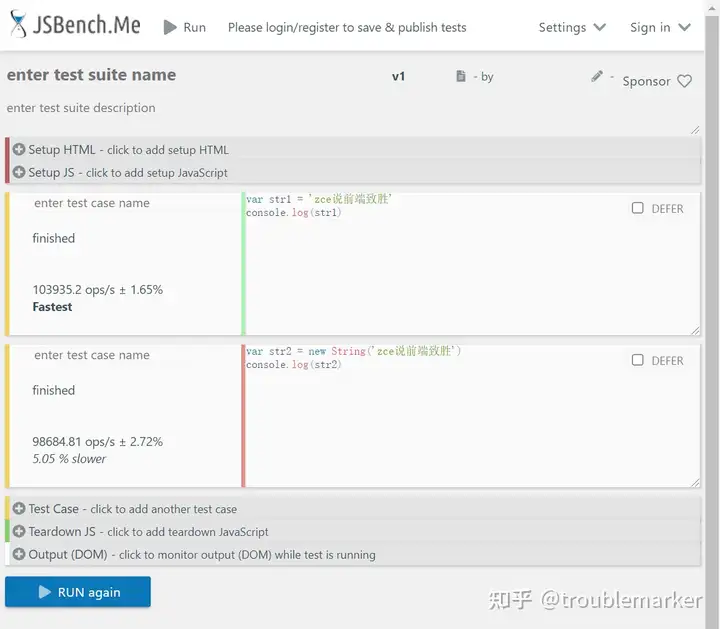
差距在5%以上,相较于引用类型数据,差距会更大,因为此时代码量是一致的,而上面是基础数据声明,下面是对象声明。
此时有一个细节,若是我们对这个字符串进行一些方法的调用的时候,上面会默认先转化为对象,然后再调用,而下面是直接调用,还是提倡用上面的方式,因为下面的方式创建的时候必然会有一些用不到的空间被占用和消耗。
总结:尽量采取字面量进行声明