前言
本博客是博主用于复习数据结构以及算法的博客,如果疏忽出现错误,还望各位指正。
堆排序(Heap Sort)概念
堆排序是一种基于堆数据结构的排序算法,其核心思想是将待排序的序列构建成一个最大堆(或最小堆),然后将堆顶元素与最后一个元素交换,再将剩余元素重新调整为最大堆(或最小堆),重复以上步骤直到所有元素都有序。
堆是一棵完全二叉树,因此一般可以当作数组处理。
对于最大堆,任何一个父节点的值都大于(或等于)其左右子节点的值;
对于最小堆,则是任何一个父节点的值都小于(或等于)其左右子节点的值。
建堆
上滤(插入新元素到堆中)
时间复杂度为O(N logN)
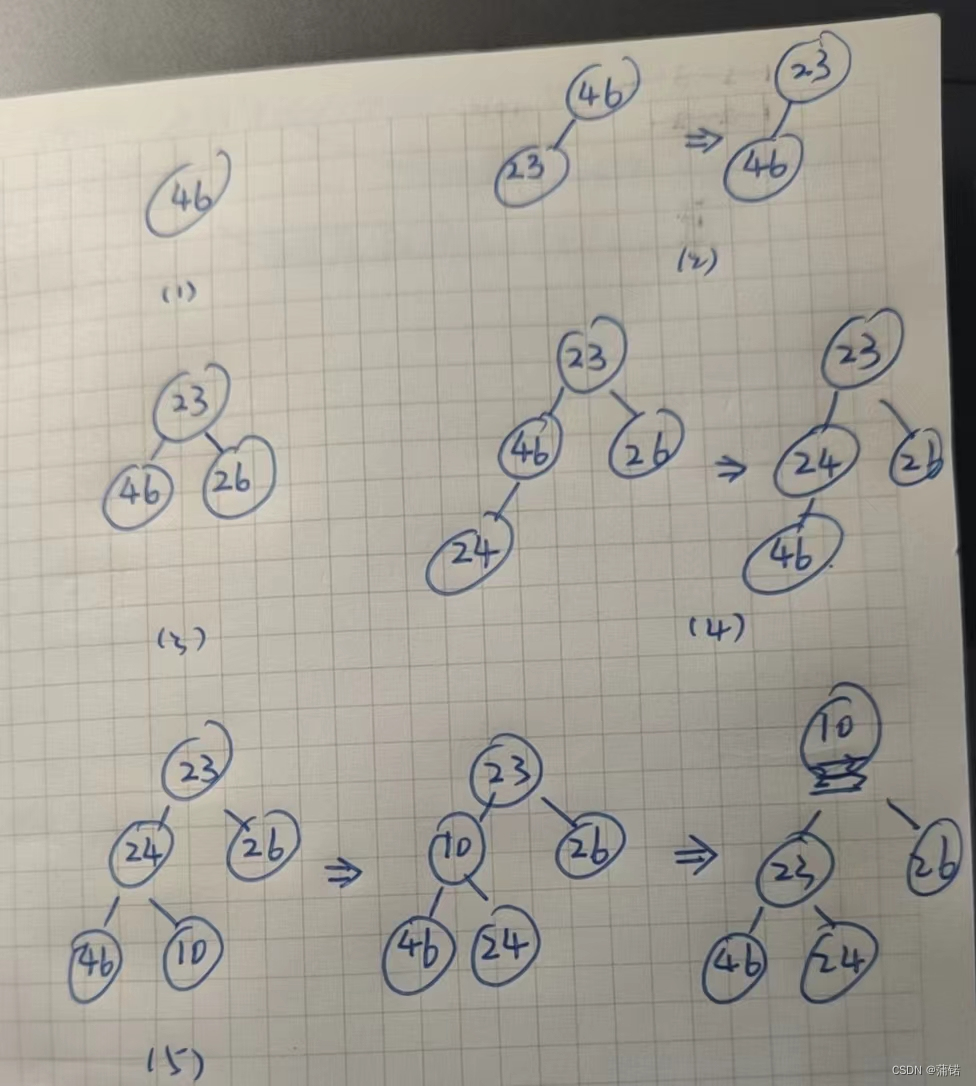
也就是一个一个插入,比如拿[46 23 26 24 10]来说,建堆过程就如下:
List<Integer> list = new ArrayList<>();
String[] num = in.nextLine().split(" ");
for(int i = 0;i<N;i++){
//小顶堆的形成,自上而下建堆,一个一个插入
if(list.size()==0){
list.add(Integer.parseInt(num[i]));
}else{
//如果长度不是0,就插入后进行比较
list.add(Integer.parseInt(num[i]));
int count = i;
while(count!=0){
int parent = 0;
if((count-1)%2==0){
parent = (count-1)/2;
}else if((count-2)%2==0){
parent =(count-2)/2;
}
if(list.get(count)<list.get(parent)){
int temp = list.get(count);
list.set(count,list.get(parent));
list.set(parent,temp);
count = parent;
}else{
break;
}
}
}
}下滤
一般用的是下滤,因为时间复杂度为O(N)
就是先整体插入,然后从倒数第一个非叶子结点进行堆调整:
1、找到倒数第一个非叶子结点23,判断其与子节点关系,发现比10大,于是互换
2、之后继续寻找非叶子结点,找到46,46与10交换后,继续与23交换

注意事项
建堆结束,两种方法建立的堆可能不一样,所以注意题目要求透露出的是哪一种。
比如要求上滤的:L2-012 关于堆的判断 - 团体程序设计天梯赛-练习集 (pintia.cn)
实现代码:
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
String[] mn = in.nextLine().split(" ");
int N = Integer.parseInt(mn[0]);
int M = Integer.parseInt(mn[1]);
List<Integer> list = new ArrayList<>();
String[] num = in.nextLine().split(" ");
for(int i = 0;i<N;i++){
//小顶堆的形成
if(list.size()==0){
list.add(Integer.parseInt(num[i]));
}else{
//如果长度不是0,就进行比较
list.add(Integer.parseInt(num[i]));
int count = i;
while(count!=0){
int parent = 0;
if((count-1)%2==0){
parent = (count-1)/2;
}else if((count-2)%2==0){
parent =(count-2)/2;
}
if(list.get(count)<list.get(parent)){
int temp = list.get(count);
list.set(count,list.get(parent));
list.set(parent,temp);
count = parent;
}else{
break;
}
}
}
}
//System.out.println(list.toString());
//判断
while(M-->0){
String[] judge = in.nextLine().split(" ");
//变成在数组中的下标
int x = list.indexOf(Integer.parseInt(judge[0]));
if(judge[3].equals("root")){
if(x==0){
System.out.println("T");
}else{
System.out.println("F");
}
}else if(judge[3].equals("are")){
int y = list.indexOf(Integer.parseInt(judge[2]));
if((y-1)%2==0){
if(y+1==x){
System.out.println("T");
}else{
System.out.println("F");
}
}else if((y-2)%2==0){
if(y-1==x){
System.out.println("T");
}else{
System.out.println("F");
}
}
}else if(judge[3].equals("parent")){
int y = list.indexOf(Integer.parseInt(judge[5]));
if((y-1)%2==0){
if((y-1)/2==x){
System.out.println("T");
}else{
System.out.println("F");
}
}else if((y-2)%2==0){
if((y-2)/2==x){
System.out.println("T");
}else{
System.out.println("F");
}
}
}else if(judge[3].equals("child")){
int y = list.indexOf(Integer.parseInt(judge[5]));
if((2*y+1) == x || (2*y+2)== x){
System.out.println("T");
}else{
System.out.println("F");
}
}
}
}
}
当然,更简单的,可以直接使用Java提供的类,直接使用优先队列toArray解决:
【PTA-训练day1】L2-012 关于堆的判断 + L1-002打印沙漏_pta打印沙漏测试点-CSDN博客
Java优先队列
关于Java优先队列的一篇博主的博客详细介绍
【Java】PriorityQueue--优先级队列_java priorityqueue-CSDN博客
队列是一种先进先出(FIFO)的数据结构 ,但有些情况下, 操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列 ,该中场景下,使用队列显然不合适,比如:在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话.
在这种情况下, 数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。 这种数据结构就是 优先级队列(Priority Queue)。
JDK1.8 中的 PriorityQueue底层使用了堆这种数据结构 ,而堆实际就是在完全二叉树的基础上进行了一些调整。
默认情况下是小根堆,如果需要大根堆,则需要构建比较器。
其他方法与队列无异。
PriorityQueue<Integer> q=new PriorityQueue<>(); //默认小顶堆
PriorityQueue<Integer> q=new PriorityQueue<>((a,b)->(b-a)); //大顶堆
q.contains(val);
Integer[] t=q.toArray(new Integer[n]); //将队列转化为数组堆排序
上述三种建堆的方法,每次之后将最顶点进行一下处理(移除或者加入数组末尾等操作),然后重新建堆再操作即可实现堆排序。
应用场景
堆排序使用场景堆排序的使用场景与其他排序算法类似,适用于需要对大量数据进行排序的场景。比如取出第k大(小)的数,这时候可以用堆排序。
优/缺点
优点主要包括:
时间复杂度较低:堆排序的时间复杂度为 O(NlogN),相对于其他排序算法,其排序速度较快。
不占用额外空间:堆排序是一种原地排序算法,不需要额外的空间来存储排序结果。
适用于大数据量的排序:堆排序的时间复杂度不随数据量的增加而变化,因此适用于大数据量的排序。
缺点主要包括:
不稳定性:由于堆排序是通过交换元素来实现排序的,因此在排序过程中可能会破坏原有的相对顺序,导致排序结果不稳定。
实现复杂:相对于其他排序算法,堆排序的实现稍微复杂一些(不过借助Java提供的优先队列可以简单实现),需要理解堆数据结构的基本原理和实现过程。




![[大模型]Atom-7B-chat网页例子](https://img-blog.csdnimg.cn/direct/0b09c939f2364c8d921bb8dd51b182dc.png#pic_center)