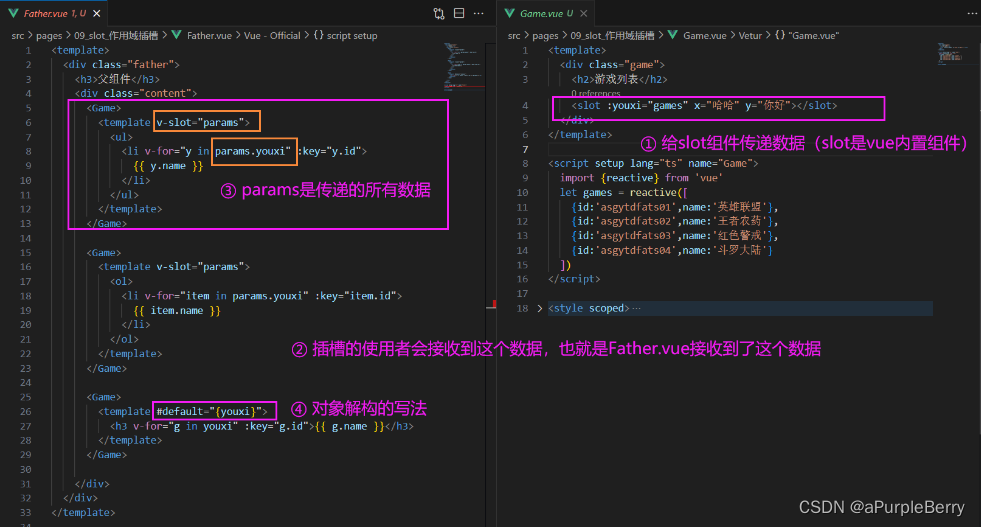
https://www.hello-algo.com/chapter_searching/binary_search/
二分查找法
给定一个长度为 n的数组 nums ,元素按从小到大的顺序排列,数组不包含重复元素。请查找并返回元素 target 在该数组中的索引。若数组不包含该元素,则返回 -1 。
# 首先初始化 i=0,j=n-1, 代表搜索区间是[0,n-1]
# 然后,循环执行以下2个步骤
# 1:m = (i+j)/2 ,向下取整,求出搜索区间的中间点
# 2:判断nums[m]和target的大小关系,有以下三种情况:
# a:nums[m] > target,说明目标在区间[i,m-1],所以让j = m - 1
# b: nums[m] < target,说明目标在区间[m+1,j],所以让i = m + 1
# c:说明已经找到目标值,因此返回索引m
代码如下:
def binary_search(nums: list[int], target: int):
i, j = 0, len(nums) - 1
while i <= j:
m = (i+j) // 2
if nums[m] > target:
j = m -1
elif nums[m] < target:
i = m + 1
else:
return m
return -1
优点:效率高,无需额外空间
缺点:仅适用于有序数据,仅使用数数组搜索,当数据量较小时,线性查找速度更快。
二分查找插入点
给定一个长度为 n的有序数组 nums 和一个元素 target ,数组不存在重复元素。现将 target 插入到数组 nums 中,并保持其有序性。若数组中已存在元素 target ,则插入到其左方。请返回插入后 target 在数组中的索引。
- 当target存在时,插入的索引就是taget的位置
- 当target不存在时:如果target > nums[m],让i = m +1 ,所以i在靠着大于等于目标的位置移动;反之j在靠着小于等于目标的位置移动,这导致的结果就是,最终i等于第一个比目标大的元素,j指向首个比目标小的元素。
可知,最终返回i即是插入的位置
def binary_search_insertion_simple(nums: list[int], target: int) -> int:
"""二分查找插入点(无重复元素)"""
i, j = 0, len(nums) - 1 # 初始化双闭区间 [0, n-1]
while i <= j:
m = (i + j) // 2 # 计算中点索引 m
if nums[m] < target:
i = m + 1 # target 在区间 [m+1, j] 中
elif nums[m] > target:
j = m - 1 # target 在区间 [i, m-1] 中
else:
return m # 找到 target ,返回插入点 m
# 未找到 target ,返回插入点 i
return i
重复值的情况
在上一题的基础上,规定数组可能包含重复元素,其余不变
def binary_search_insertion(nums: list[int], target: int) -> int:
"""二分查找插入点(存在重复元素)"""
i, j = 0, len(nums) - 1 # 初始化双闭区间 [0, n-1]
while i <= j:
m = (i + j) // 2 # 计算中点索引 m
if nums[m] < target:
i = m + 1 # target 在区间 [m+1, j] 中
elif nums[m] > target:
j = m - 1 # target 在区间 [i, m-1] 中
else:
j = m - 1 # 首个小于 target 的元素在区间 [i, m-1] 中
# 返回插入点 i
return i
查找左边界
def binary_search_left_edge(nums: list[int], target: int) -> int:
"""二分查找最左一个 target"""
# 等价于查找 target 的插入点
i = binary_search_insertion(nums, target)
# 未找到 target ,返回 -1
if i == len(nums) or nums[i] != target:
return -1
# 找到 target ,返回索引 i
return i
查找右边界
替换在 nums[m] == target 情况下的指针收缩操作即可,接下来介绍一些取巧的办法
-
复用左边界法,使查找目标加一
def binary_search_right_edge(nums: list[int], target: int) -> int: """二分查找最右一个 target""" # 转化为查找最左一个 target + 1 i = binary_search_insertion(nums, target + 1) # j 指向最右一个 target ,i 指向首个大于 target 的元素 j = i - 1 # 未找到 target ,返回 -1 if j == -1 or nums[j] != target: return -1 # 找到 target ,返回索引 j return j -
转换为查找不存在的元素
当数组不包含目标元素时,最终i和j会分别指向首个大于、小于target的元素:
查找最左侧元素时,可以将目标设置为targe-0.5,最终返回i
查找最右侧元素时,可以将目标设置为target+0.5,最终返回j

哈希优化
在算法题中,通常通过将线性遍历替换为哈希搜索来提升时间复杂度。例如以下题目
给定一个整数数组
nums和一个目标元素target,请在数组中搜索“和”为target的两个元素,并返回它们的数组索引。返回任意一个解即可。
线性遍历
开启一个两层循环,每次判断是否和为目标值。简单粗暴
def two_sum_brute_force(nums: list[int], target: int) -> list[int]:
"""方法一:暴力枚举"""
# 两层循环,时间复杂度为 O(n^2)
n = len(nums)
for i in range(n):
for j in range(i+1, n):
if nums[i] + nums[i] == target:
return [i, j]
return []
哈希查找
def two_sum_hash_table(nums: list[int], target: int) -> list[int]:
"""方法二:辅助哈希表"""
# 辅助哈希表,空间复杂度为 O(n)
dic = {}
n = len(nums)
for i in range(n):
if target - nums[i] not in dic:
dic[nums[i]] = i
else:
return [dic[target - nums[i]], i]
return []
搜索算法总结
搜索算法根据实现方式可以分为以下两类:
- 通过遍历数据结构来定位元素,例如数组、图、树的遍历等
- 利用数据结构的特性,实现高效搜索,例如二分查找、哈希查找
暴力搜索
- 线性搜索,适用于数组、链表
- 广度优先和深度优先搜索,适用于图、树
优点是通用性好,容易理解,不需要对数据结构做预期处理;不需要额外空间。
缺点是此类算法的时间复杂度为O(n),因此在元素较多时效率较低
自适应搜索
自适应搜索利用数据结构的特性来优化搜索
- 二分查找,利用有序性来进行搜索,仅适用于数组
- 哈希查找,利用哈希表将搜索数据和目标数据建立键值对映射,从而实现查询操作
- 树查找
效率高,可达到o(logn)甚至o(1)
缺点:需要对数据进行预处理,需要额外空间
搜索方法选取

表 10-1 查找算法效率对比
| 线性搜索 | 二分查找 | 树查找 | 哈希查找 | |
|---|---|---|---|---|
| 查找元素 | O(n) | O(logn) | O(logn) | O(1) |
| 插入元素 | O(1) | O(n) | O(logn) | O(1) |
| 删除元素 | O(n) | O(n) | O(logn) | O(1) |
| 额外空间 | O(1) | O(1) | O(logn) | O(n) |
| 数据预处理 | / | 排序 O(nlogn) | 建树 O(nlogn) | 建哈希表 O(n) |
| 数据是否有序 | 无序 | 有序 | 有序 | 无序 |
搜索算法的选择还取决于数据体量、搜索性能要求、数据查询与更新频率等。