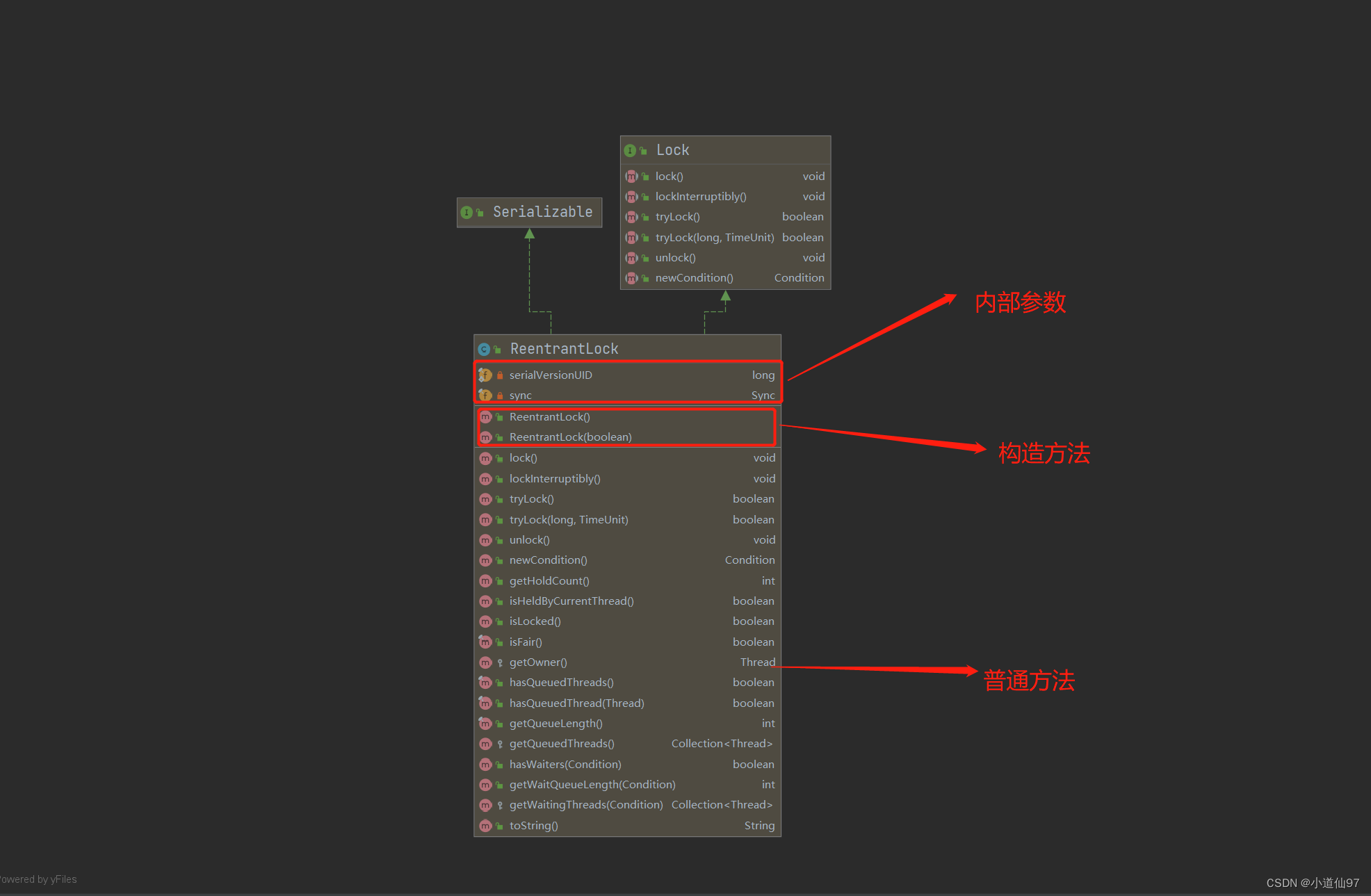
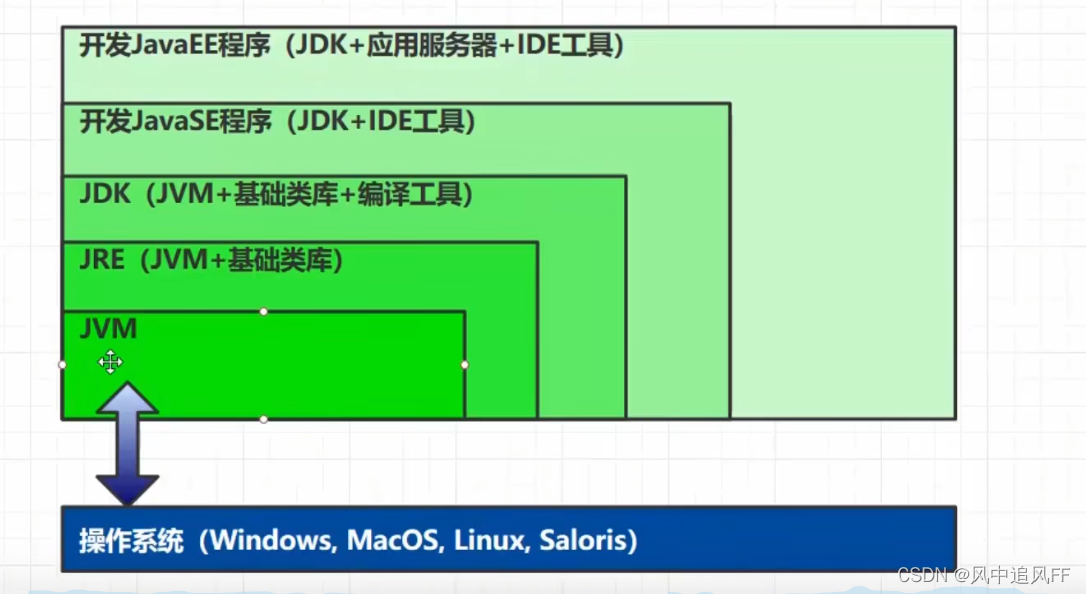
1.JVM介绍
越界检查肯定有用,防止覆盖别的地方的代码。

JVM来评价java在底层操作系统的差异。
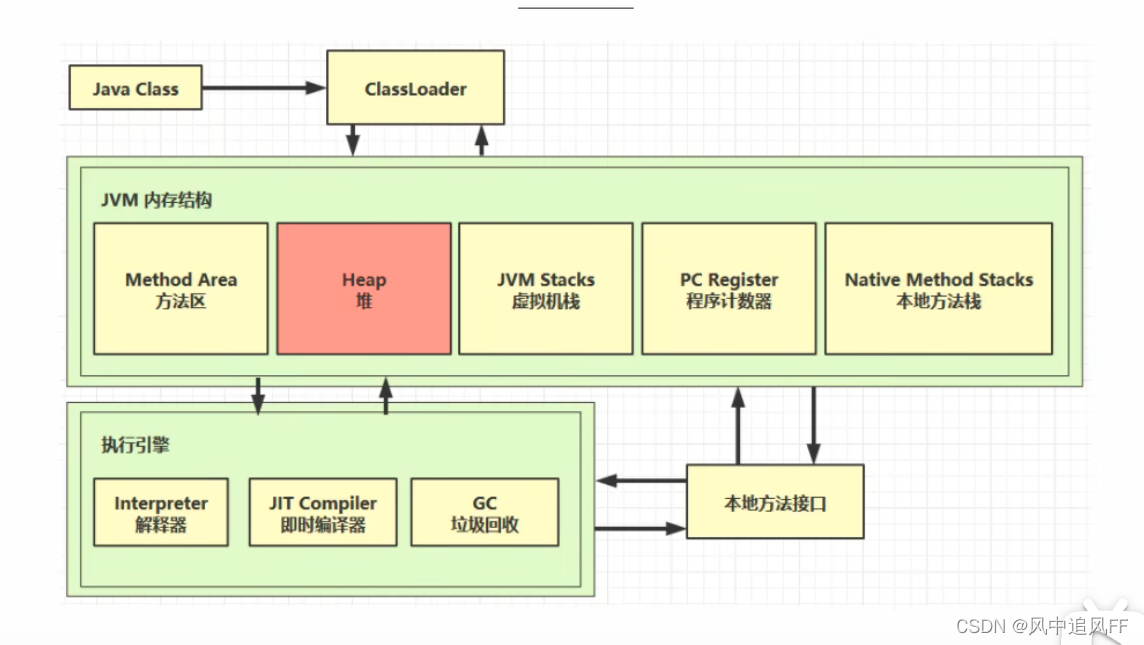
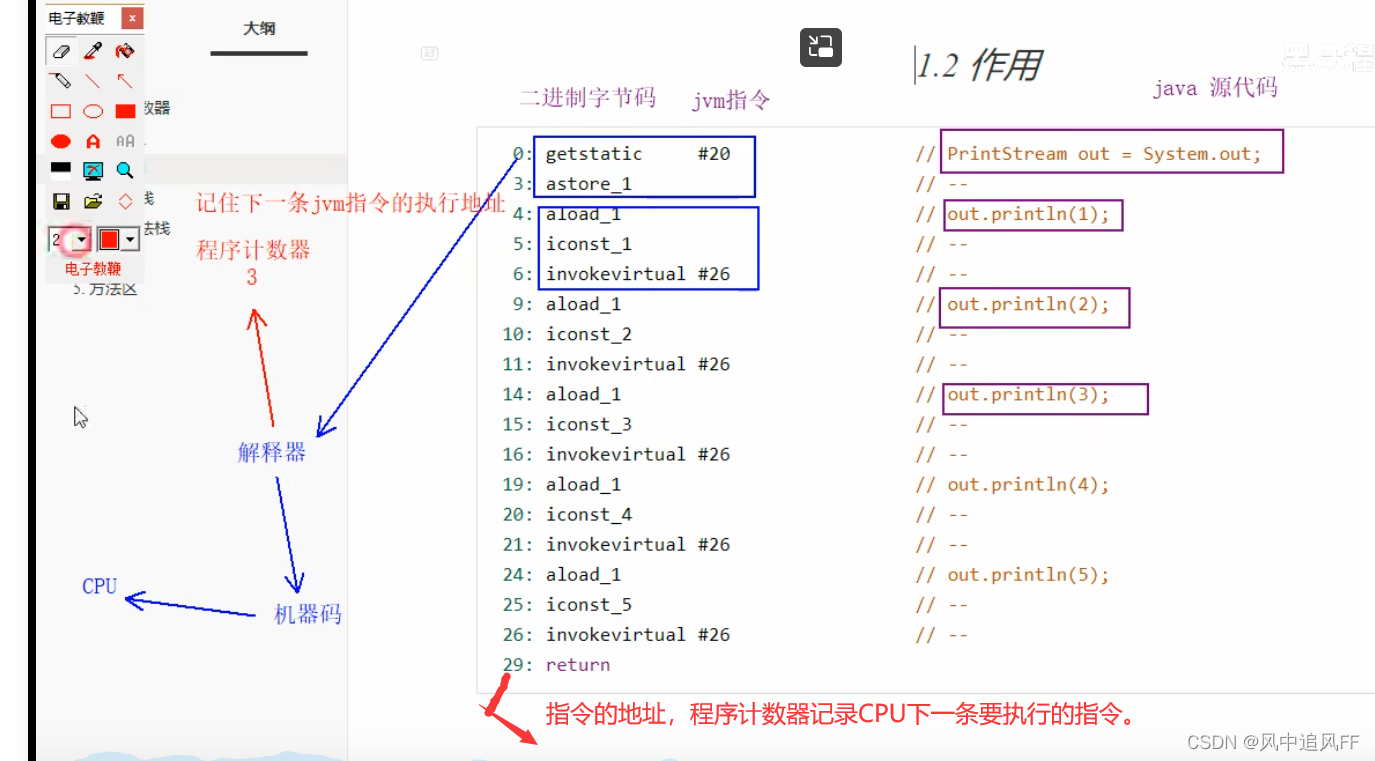
2.程序计数器
我们java源代码会变成一条一条jvm指令。
在物理上实现程序计数器,是用一个寄存器。这样速度更快。
程序计数器不会内存溢出
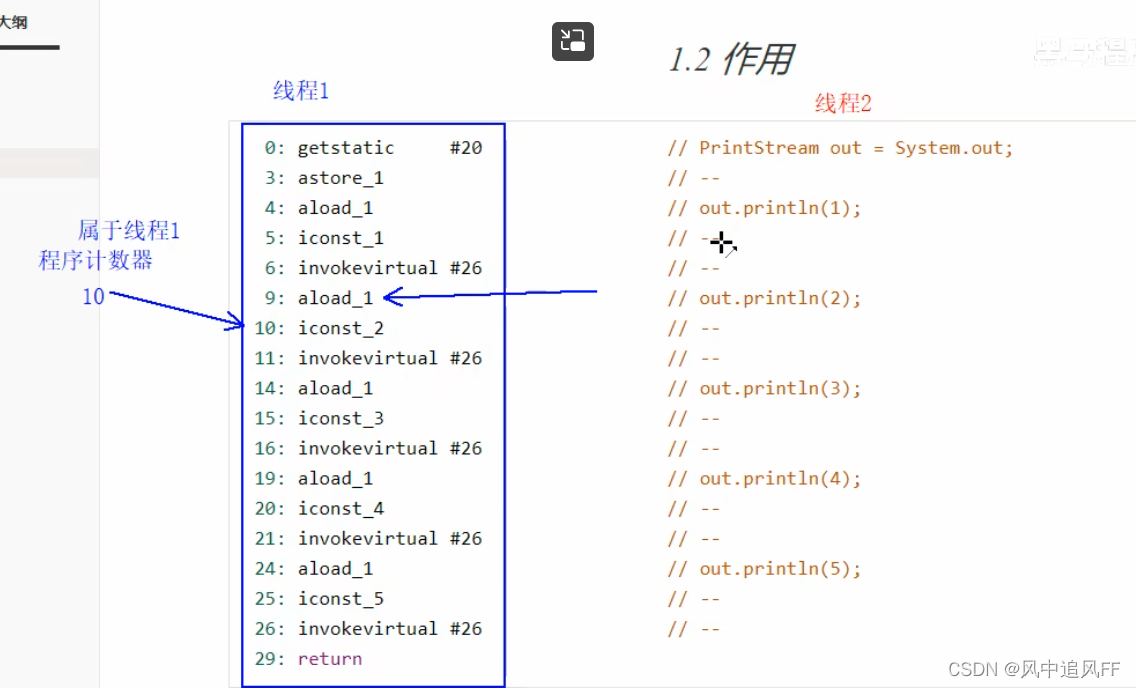
2.1 线程私有
比如我的线程1,在分配的时间片,只执行到了指令9,这个时候切换到线程2。
程序计数器是线程1私有的。记录线程1下一条要执行的是指令10
2.2 程序计数器不会内存溢出
3.虚拟机栈
一个线程运行需要一个虚拟机栈
一个栈帧就对应着一个方法的调用。
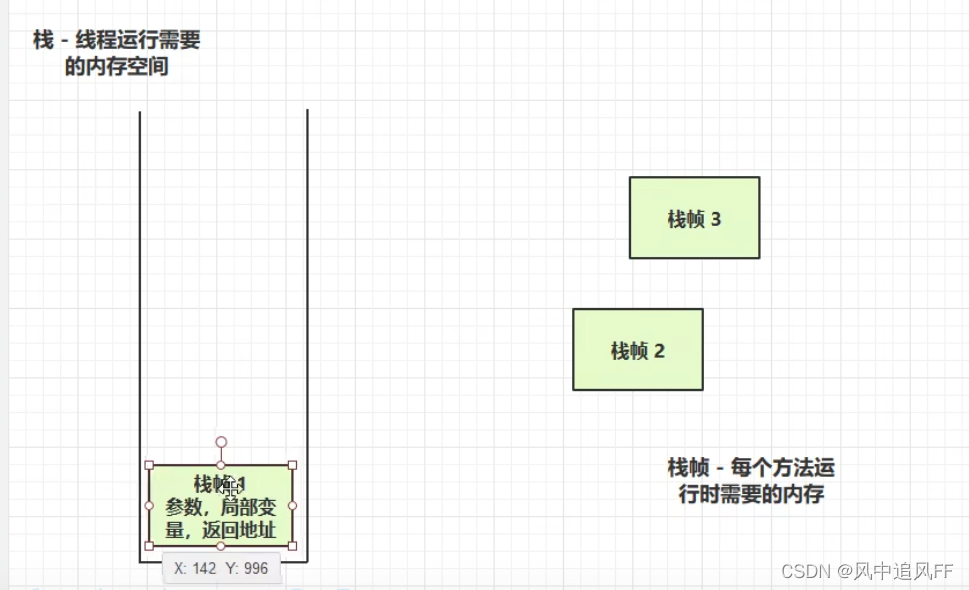
而如果方法1间接调用了方法2,就会把栈帧2放进栈。依次类推。
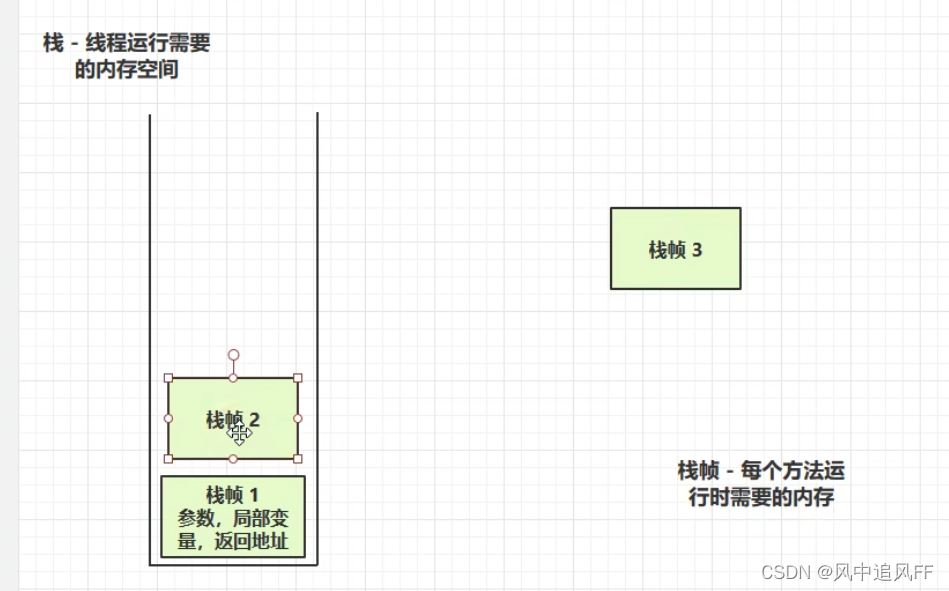
然后从栈顶挨个等待CPU的宠幸。
栈顶那个叫活动栈帧。
3.1 关于栈的几个问题

1.每次栈顶的方法执行完毕都会自动弹出栈,不需要垃圾回收管理栈。
2.栈的内存划大,反而会让线程数变少。划大了,只能方便方法的递归调用。
可以通过-Xss设置栈的内存大小。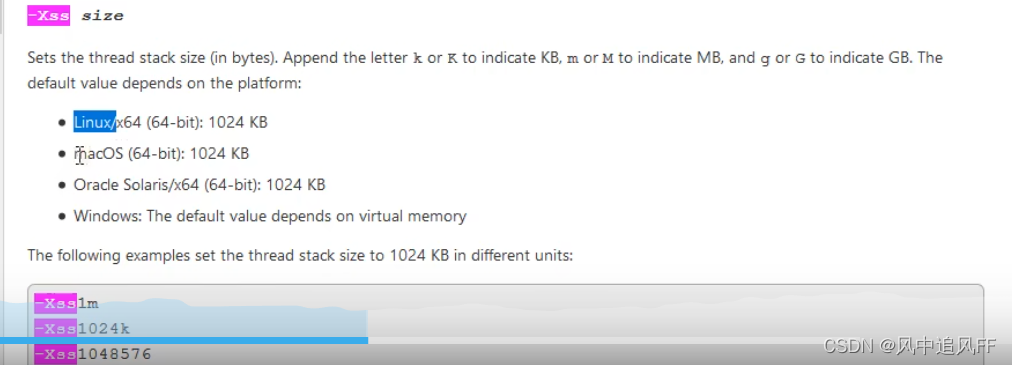
3.栈方法内的
多个线程执行一个方法,里面的变量每次都不一样,互不影响,肯定线程安全。

但如果这个变量是static 变量,会被共享。
如果不加线程保护就不安全。
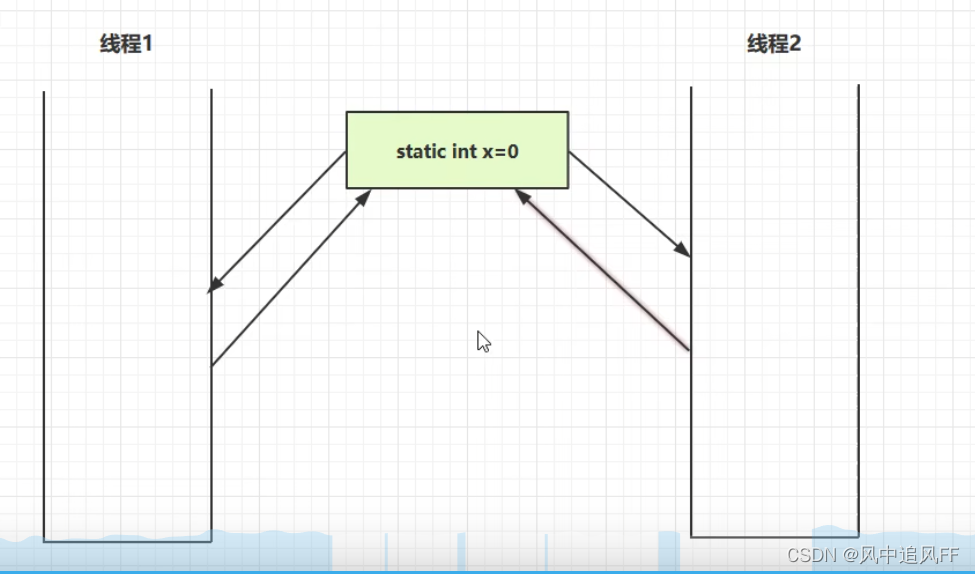
那如果是多个线程修改同一个对象,那就是线程共享的。
StringBuilder不是线程安全的。
那我们这个时候就得改成StringBuffer了。

3.2 栈内存溢出
1.栈帧太多。比如没有递归终止条件

就会报错,lang包下的StackOverflowError

2.栈帧过大
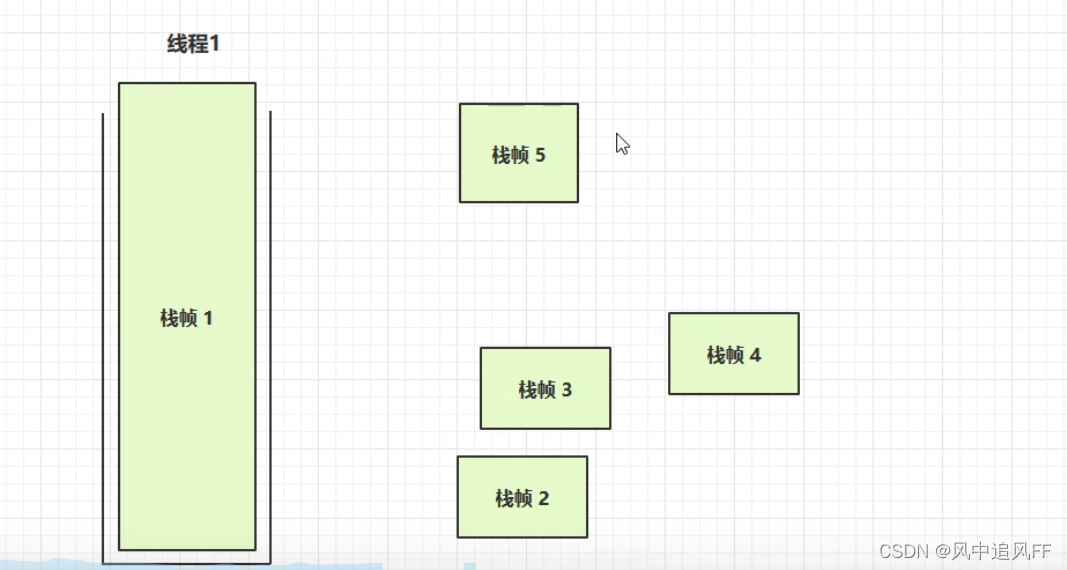
在这里可以用-Xss 256k来指定栈大小。修改虚拟机参数。
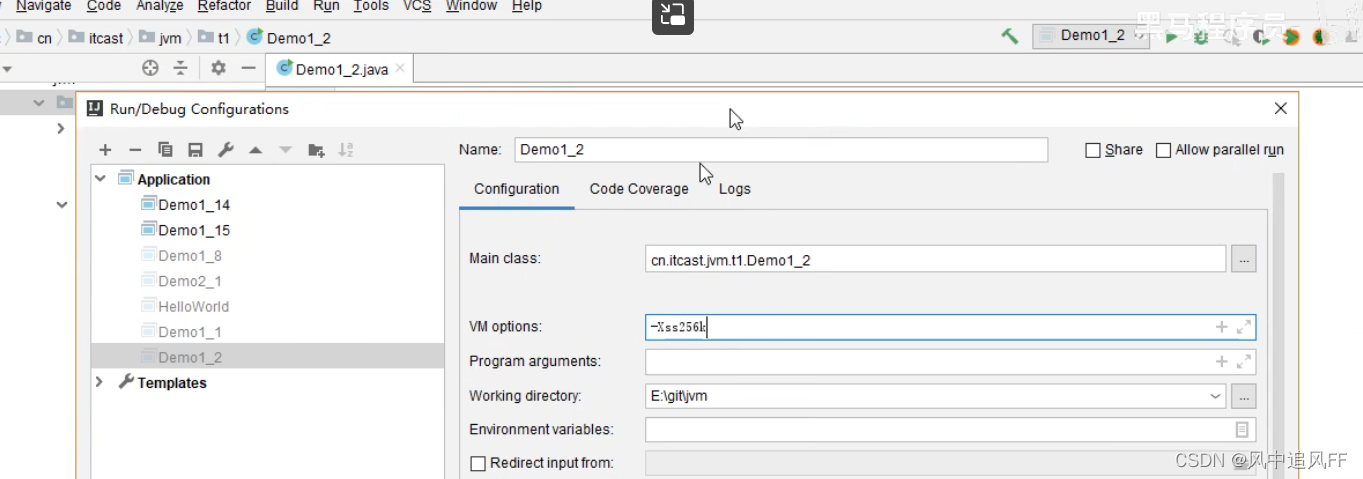
3.3 线程运行诊断
3.3.1 案例1,cpu占用太高
linux里使用top检测后天内存使用情况,但只能定位到哪个进程的占用高。


找到32665这个线程占用最高。

二进制的32665转成16进制7F99,jstack里面的线程编号是16进制的。
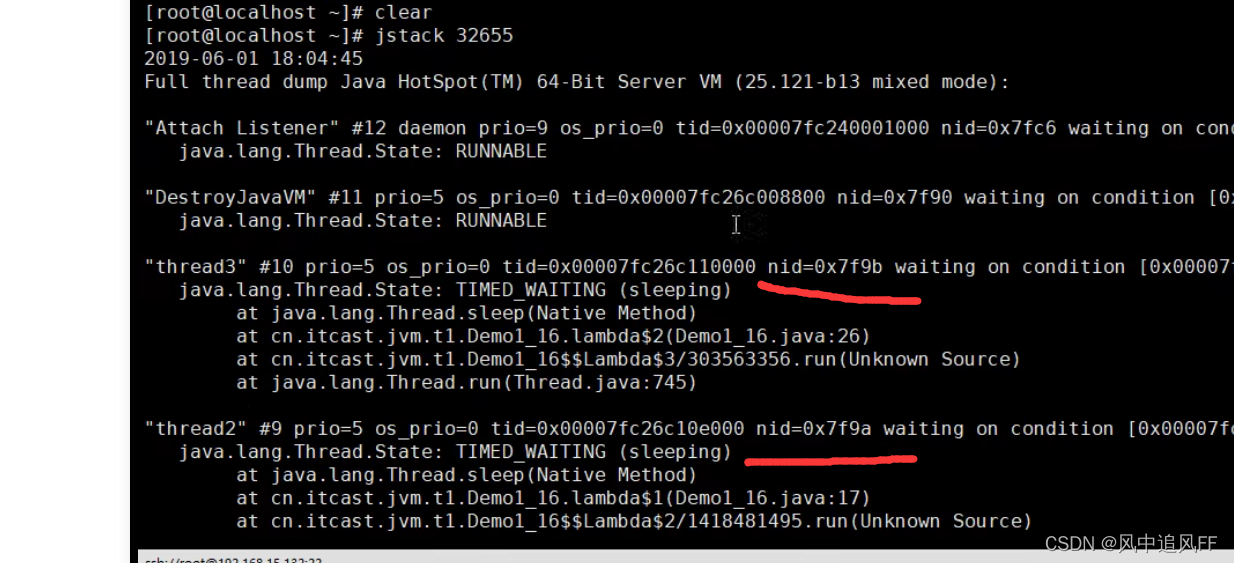
然后我们找到这个线程
可以看出来哪个类的那行代码出了问题。

3.3.2 案例2很久没出结果
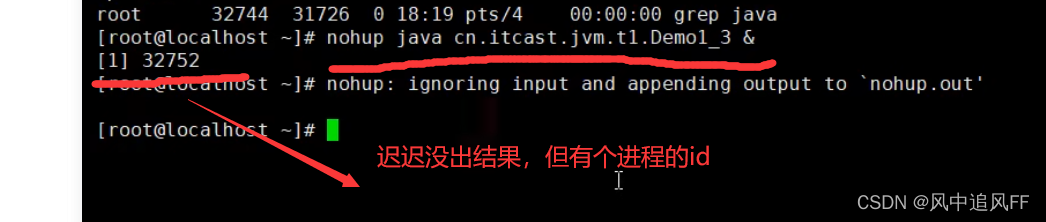
然后jstack 进程号 ,查看这个进程

往下翻,发现了一个死锁。说我的Tread 1和0 发生了死锁。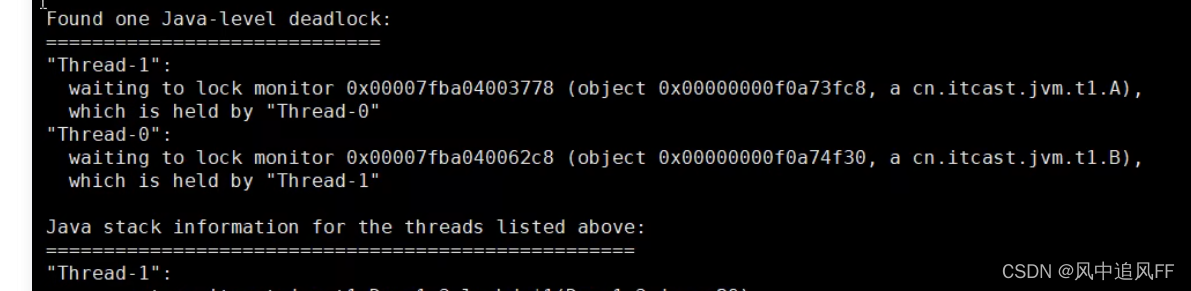
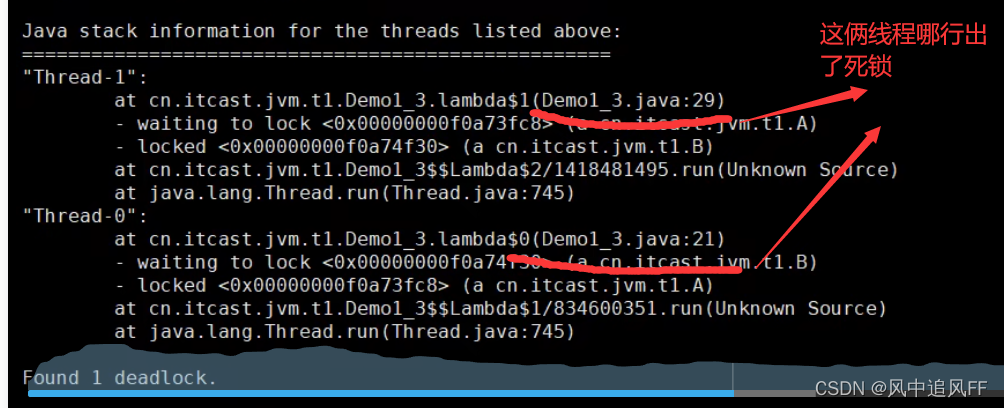
线程1锁了a,然后休眠,线程b想锁a,发现获得不了,就死锁了。

3.4 本地方法栈
调用操作系统底层的本地方法(C或C++),这些本地方法用,就在本地方法栈。
比如object类里的clone方法,这个方法是没有实现的,用C或C++实现。

4.堆

一个堆溢出的异常,OutOfMemoryError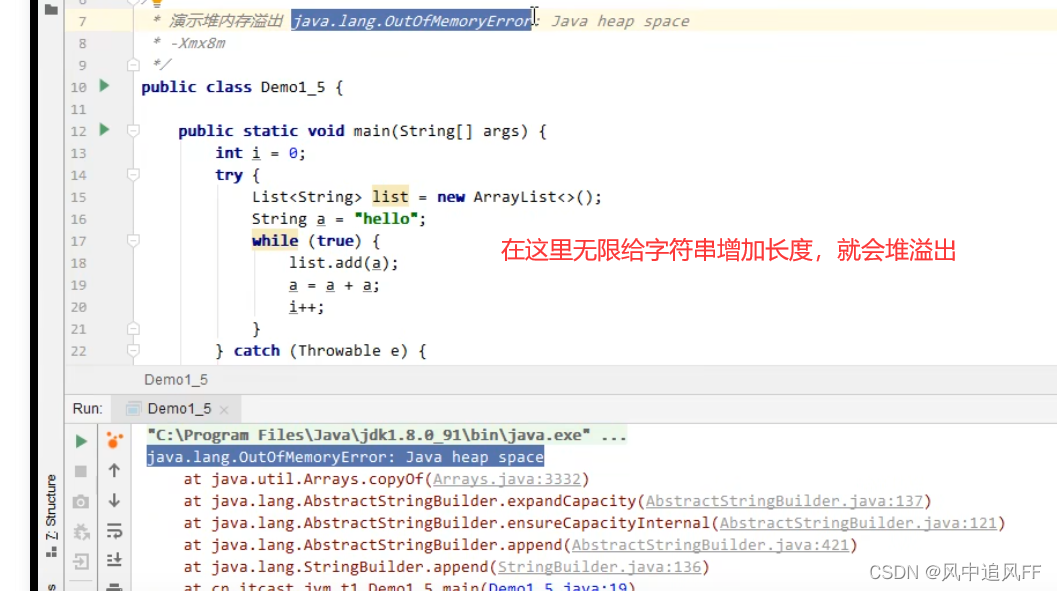
可以配置-Xmx大小,来指定堆空间的大小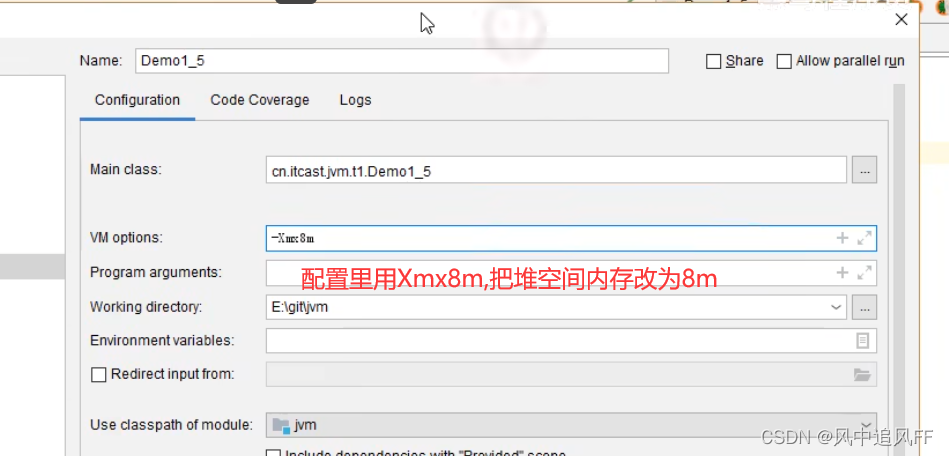
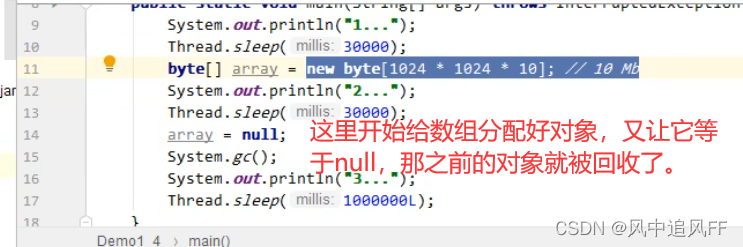
4.1 堆内存诊断

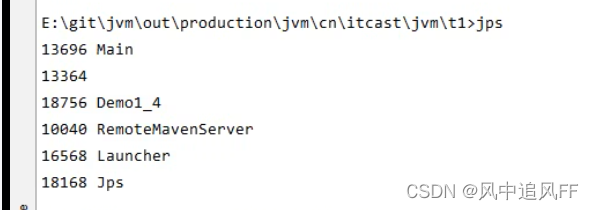
4.1.1 JPS工具
jps 可以查看运行的进程id。
4.1.2 Jmap工具
jmap工具用不了说明JDK版本是高于8的,
JDK8需要Jhsdb jmap -heap -pid 加进程号。
我们可以看到堆的一些配置,堆的最大size。
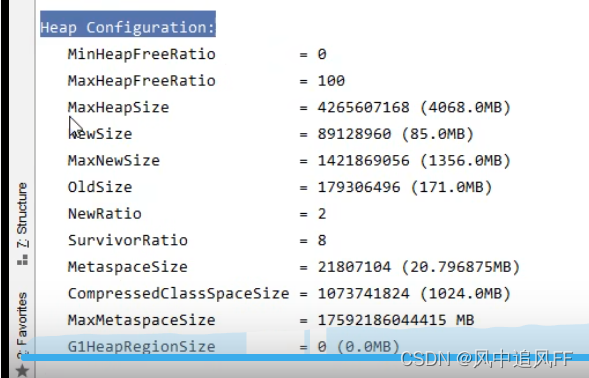
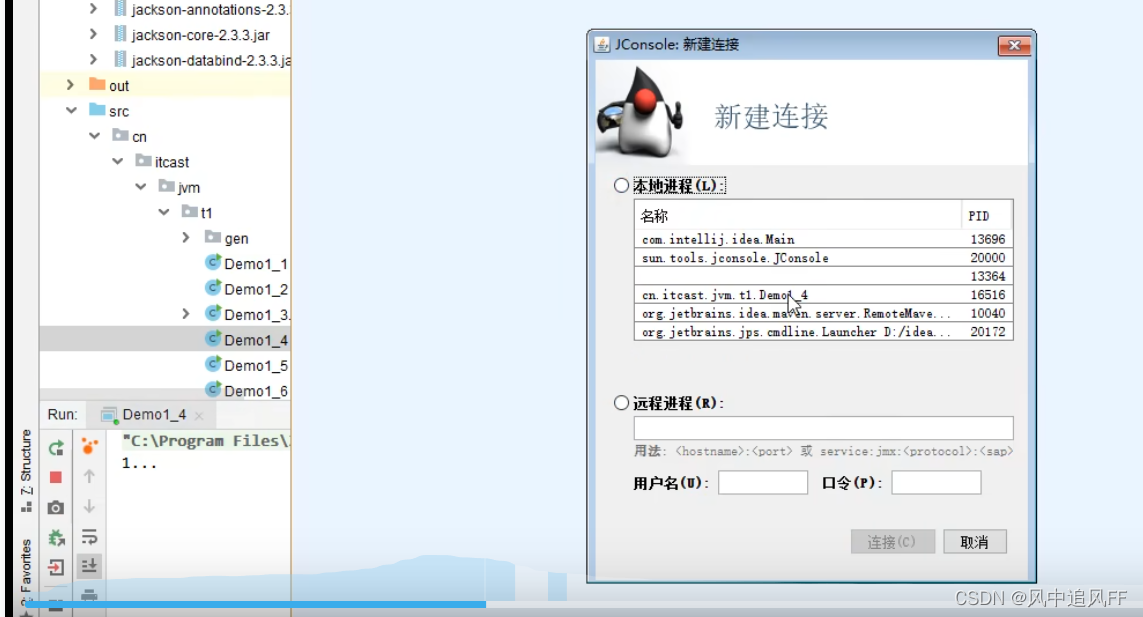
4.1.3 Jconsole
控制台上输入Jconsole,可以监控本地的进程
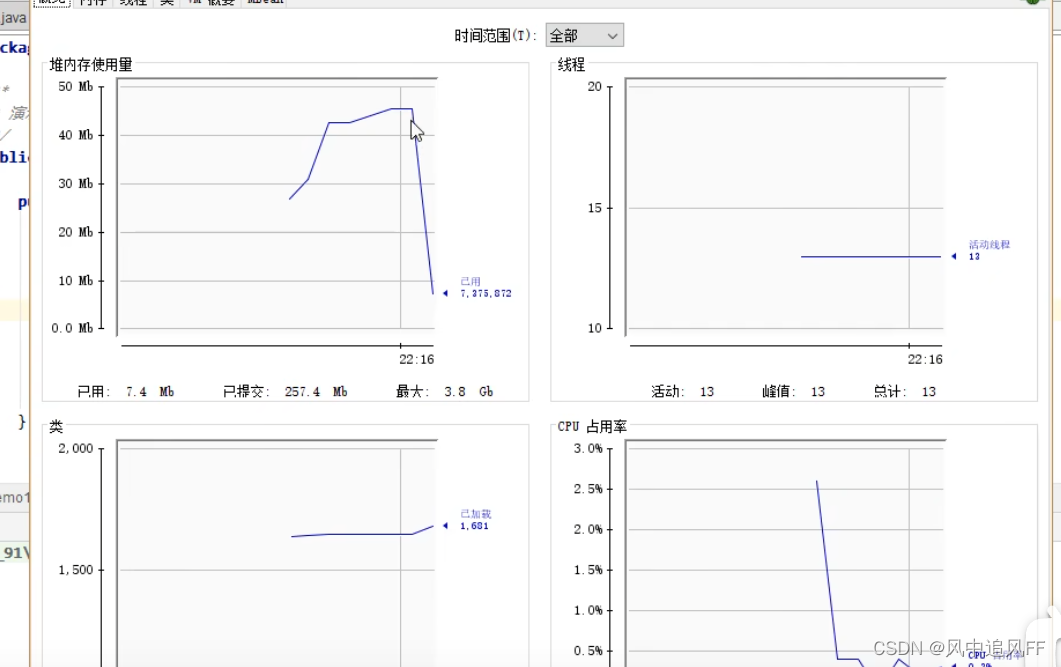
4.1.4 垃圾回收后,内存依然占用很大
用jvisualvm,这是个虚拟机的图形可视化工具

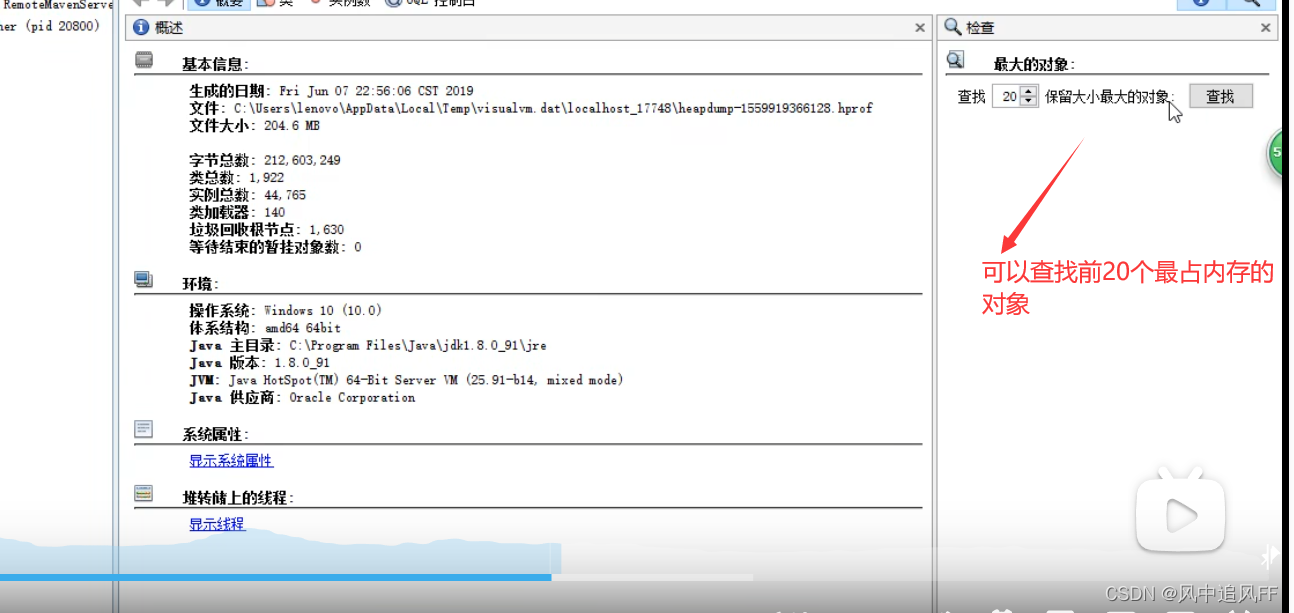
然后挨个检查对象里的内容,哪些内存占用高。
然后发现,这个占用大的对象,一直也没到生命周期的结尾。
根本没有走完一生,不可能被回收。
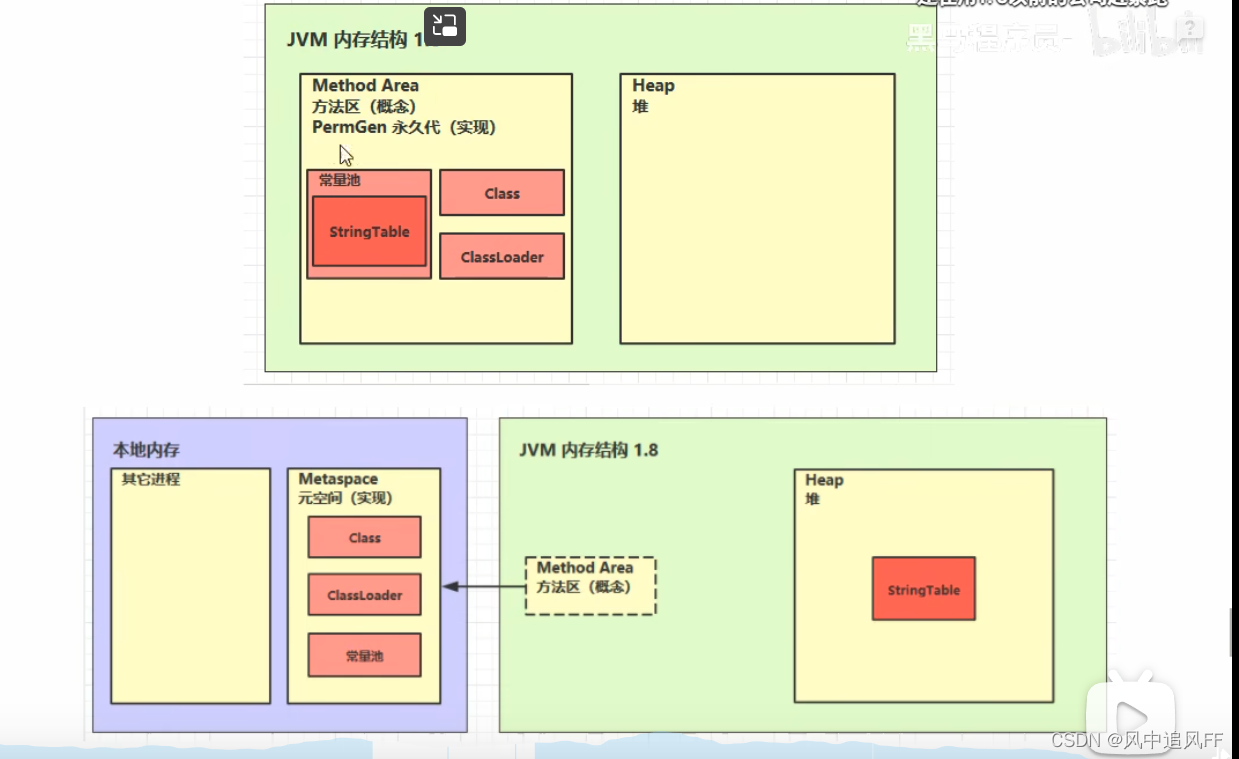
5. 方法区
1.8 之前,永久代用的堆空间的内存,用永久代实现的方法区。
1.8之后 用的是本地内存的metaSpace元空间实现的方法区。

5.1 方法区的内存溢出

5.1.1 1.8版本方法区的溢出
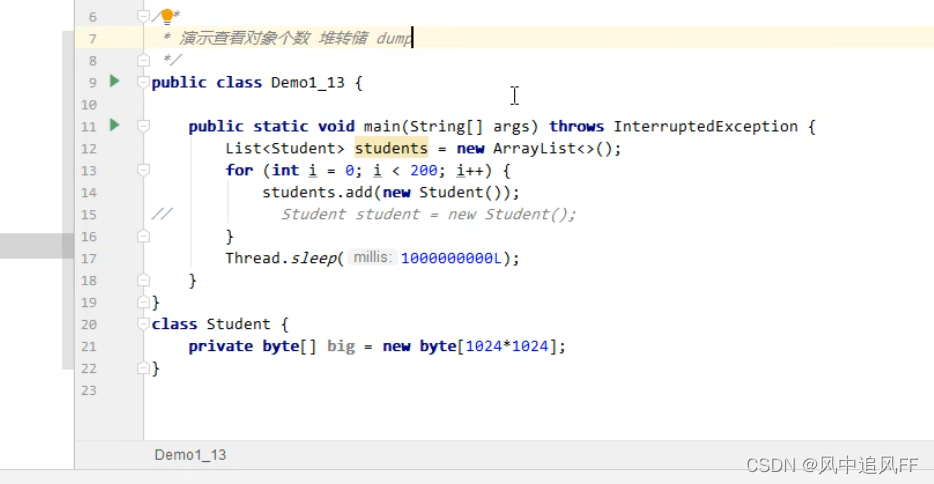
我们在这里建了1万个类,并加载。
我们可以把最大元空间大小设为8m,-XX:MaxMetaspaceSize=8m
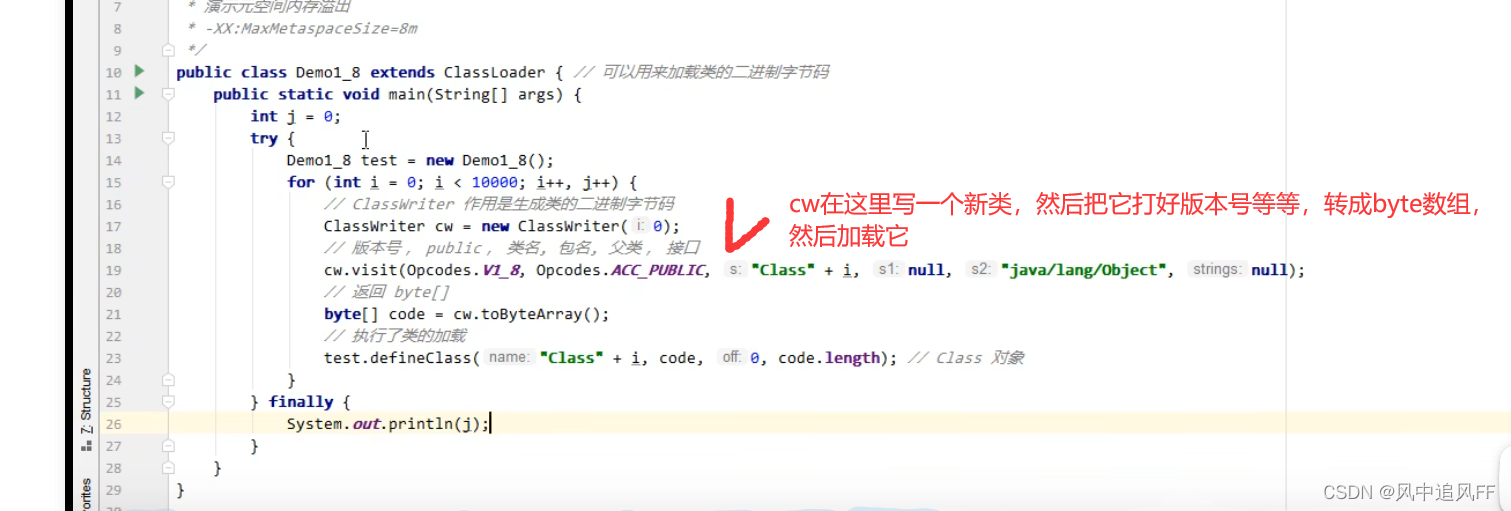
然后就可能会溢出了。

5.1.2 1.6版本方法区的溢出
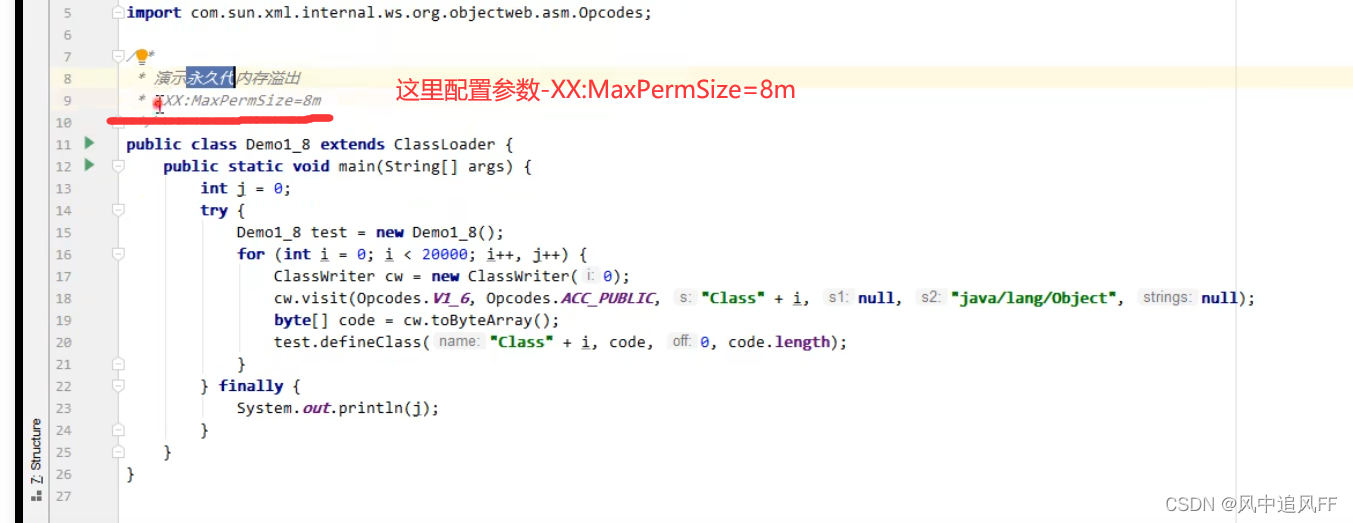
当溢出的时候报错信息为 PermGen,永久代空间内存溢出。
5.1.3 内存溢出的场景
spring 动态代理那,都在加载类。

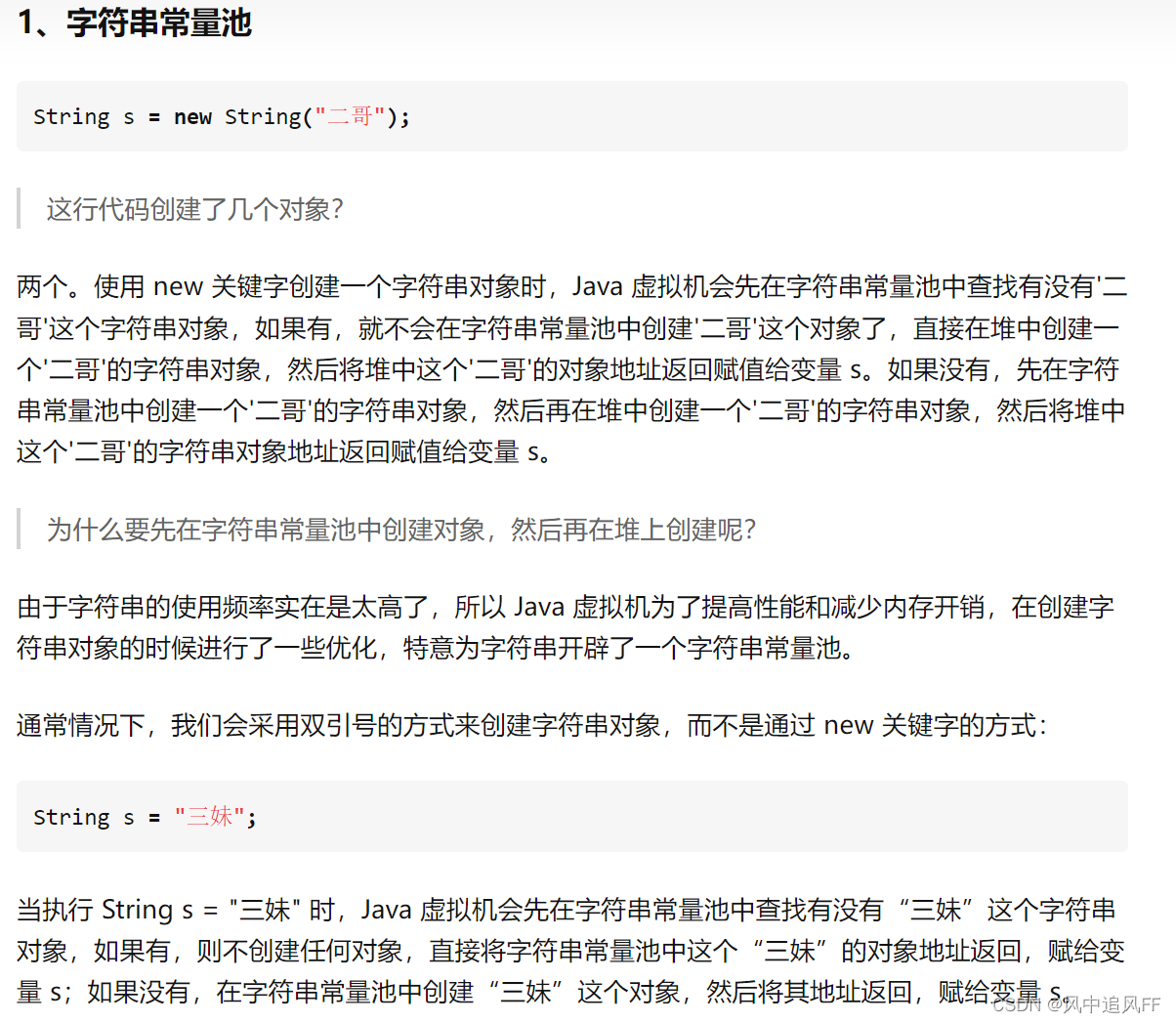
6.常量池
首先一个类编译成字节码的时候,有类基本信息,常量池,类方法定义(包含了虚拟机指令)。
我们找到这个class文件,反编译它。
javap -c xxx.class
得到的结果,前面的一部分是类的基本信息
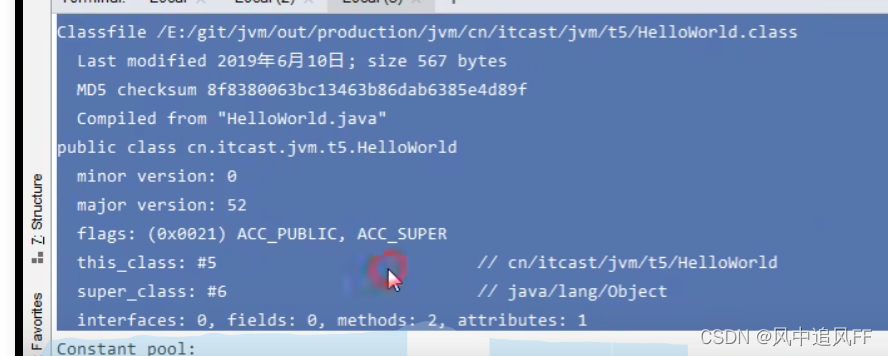
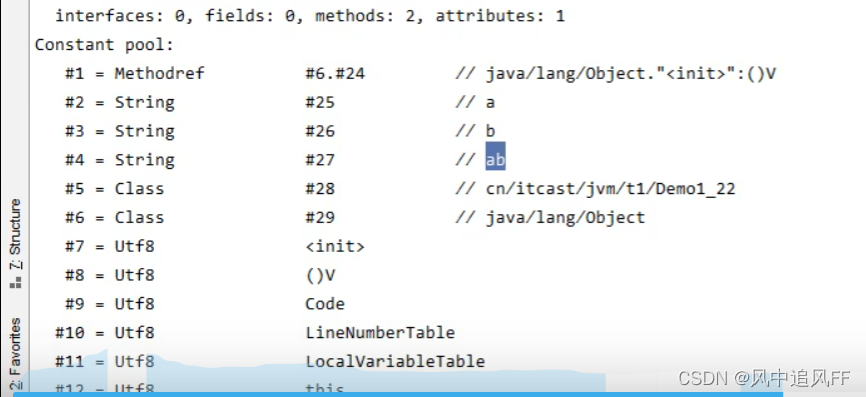
常量池,例如 #1 为常量的编号,#1同时引用了#6和#20。
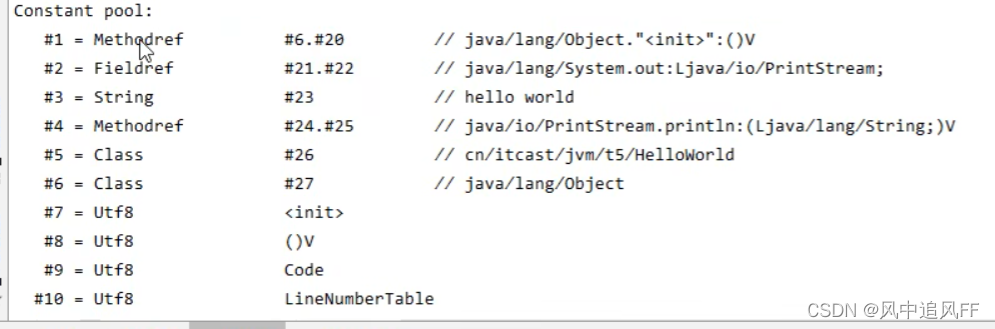
再往下看,会发现,编译器会给我们这个类一个默认构造方法。
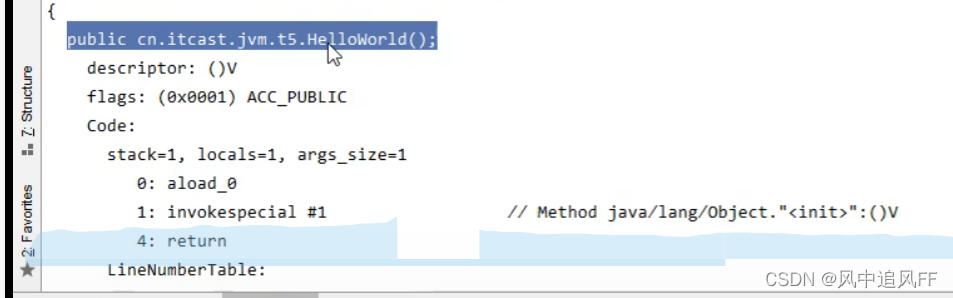
方法里都是指令加常量,类似汇编语言。
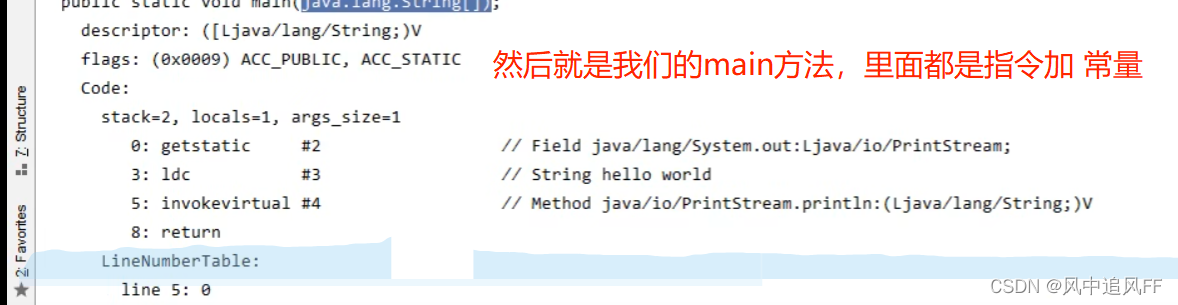
这里的main方法就成了四条指令。比如你想执行指令0,就要引用 #2这个静态成员变量。
6.1 运行时常量池

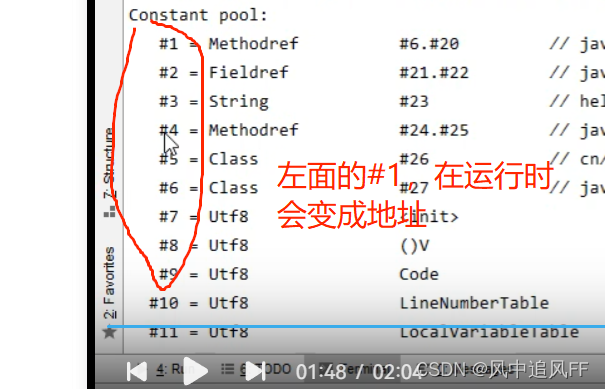
每个类都有自己的常量池,当这个类在运行时,就把它的常量池放在运行时常量池。
6.2 StringTable面试题(有串池)字符串的生成过程
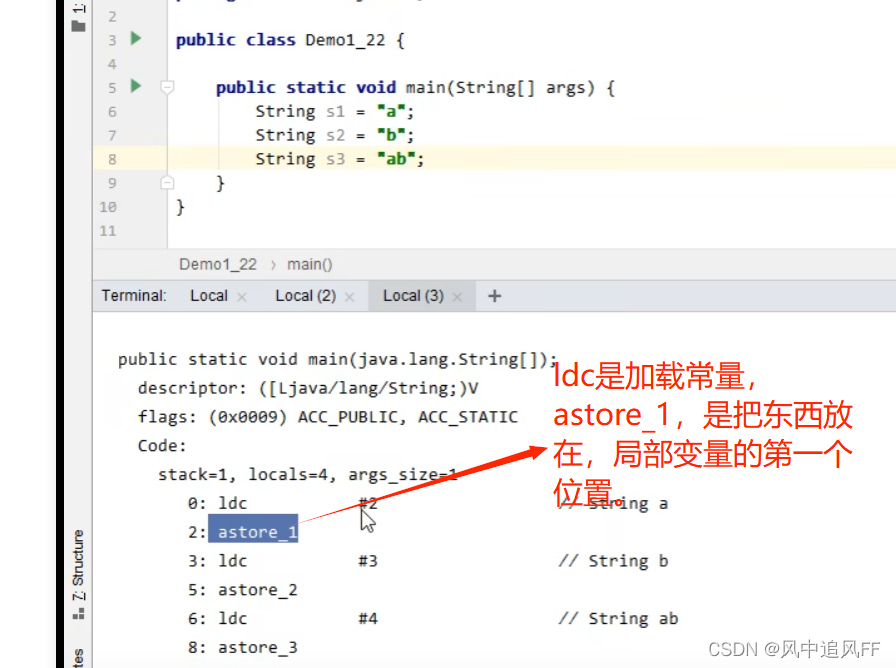
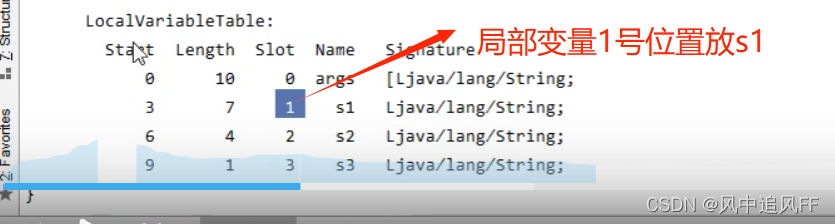
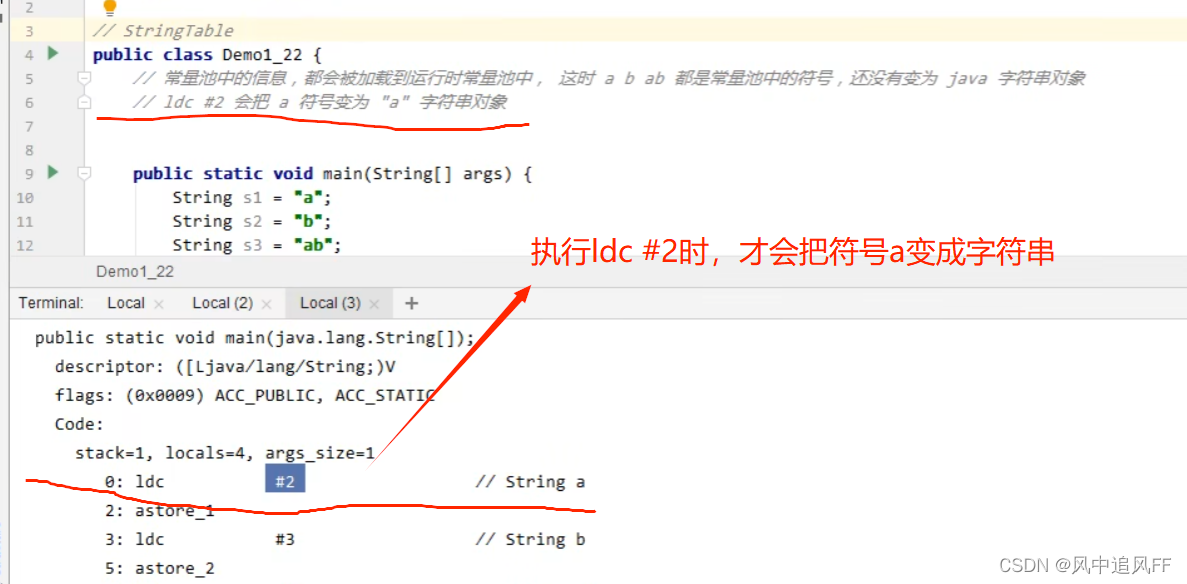
然后我们来看常量池,在刚运行时,a,b就是里面的符号,还没有变成String字符串对象。
执行指令才把符号变成字符串对象。
然后我们就会把刚生成的这个字符串放入串池StringTable,串池是哈希表。
如果串池里有这个对象,就直接拿来用。

6.3 字符串的拼接
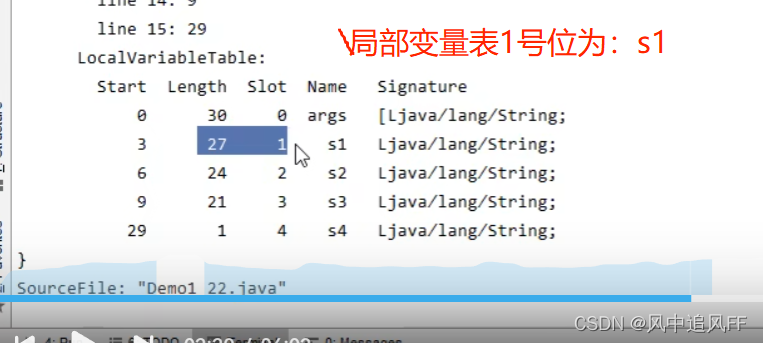
6.3.1 拼接两个变量
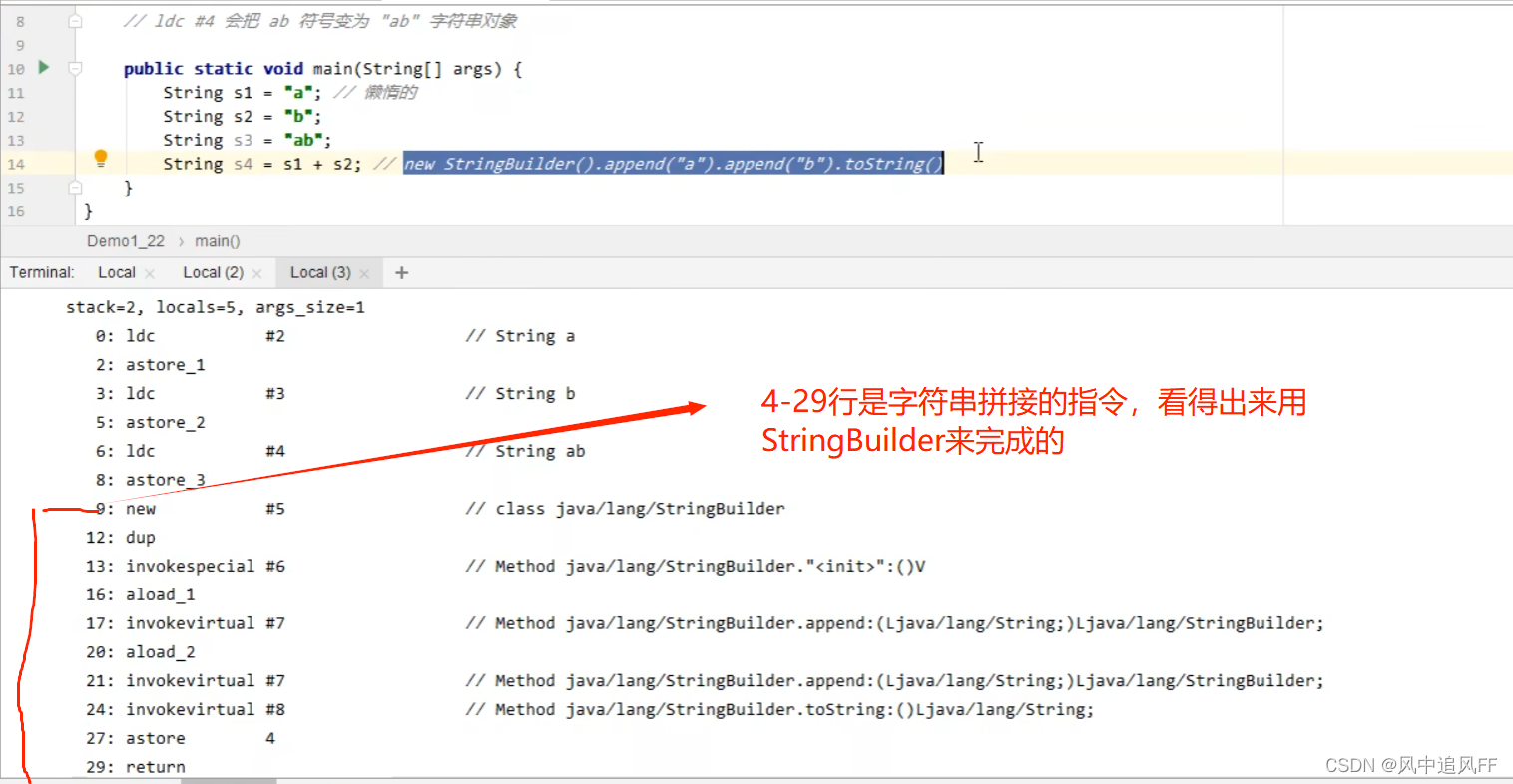
String Builder的to String 方法,就是 再new 一个String 对象。
字符串的拼接就是String -> StringBuilder ->String
这题我们就知道是啥了,S3是串池的对象,S4是新new出来的东西,肯定不相等。输出为false

6.3.2 拼接两个字符串常量

这样它就会去串池里直接找已经有的对象。

那为什么连接这么快呢?
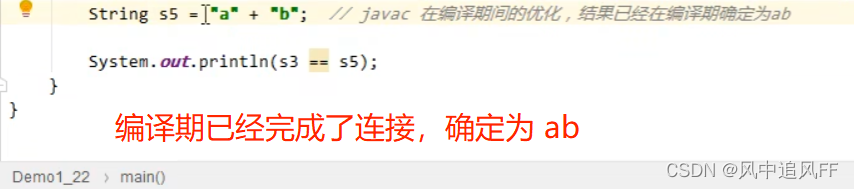
6.4 StringTable字符串常量池
这里会往串池里放新串,如果串池里有,那就不再创建。

。

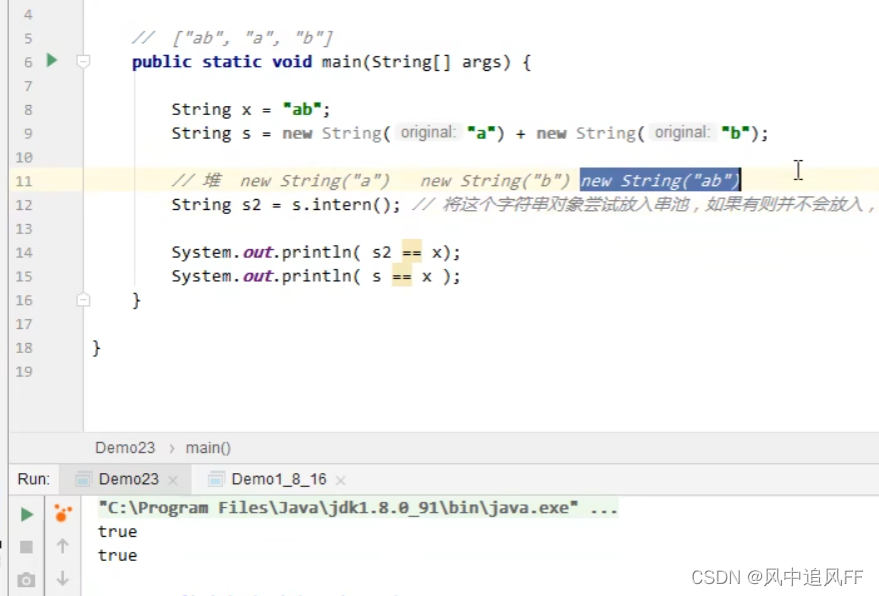
‘’a‘’就是字符串对象常量,当用双引号引起来的时候就在串池了。
这里产生的 ab是在堆里的字符串对象。
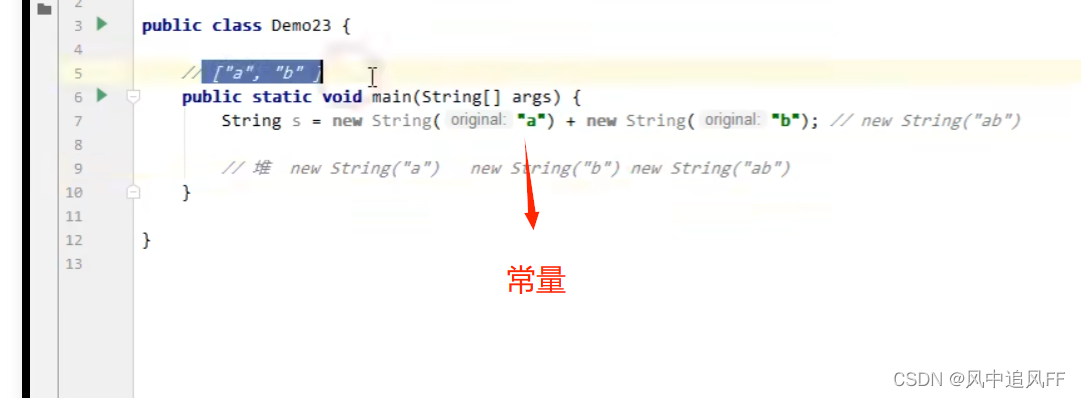
这里使用了s.intern(),但由于常量池已经有“ab”,所以这个时候s2应该是常量池里的''ab''。

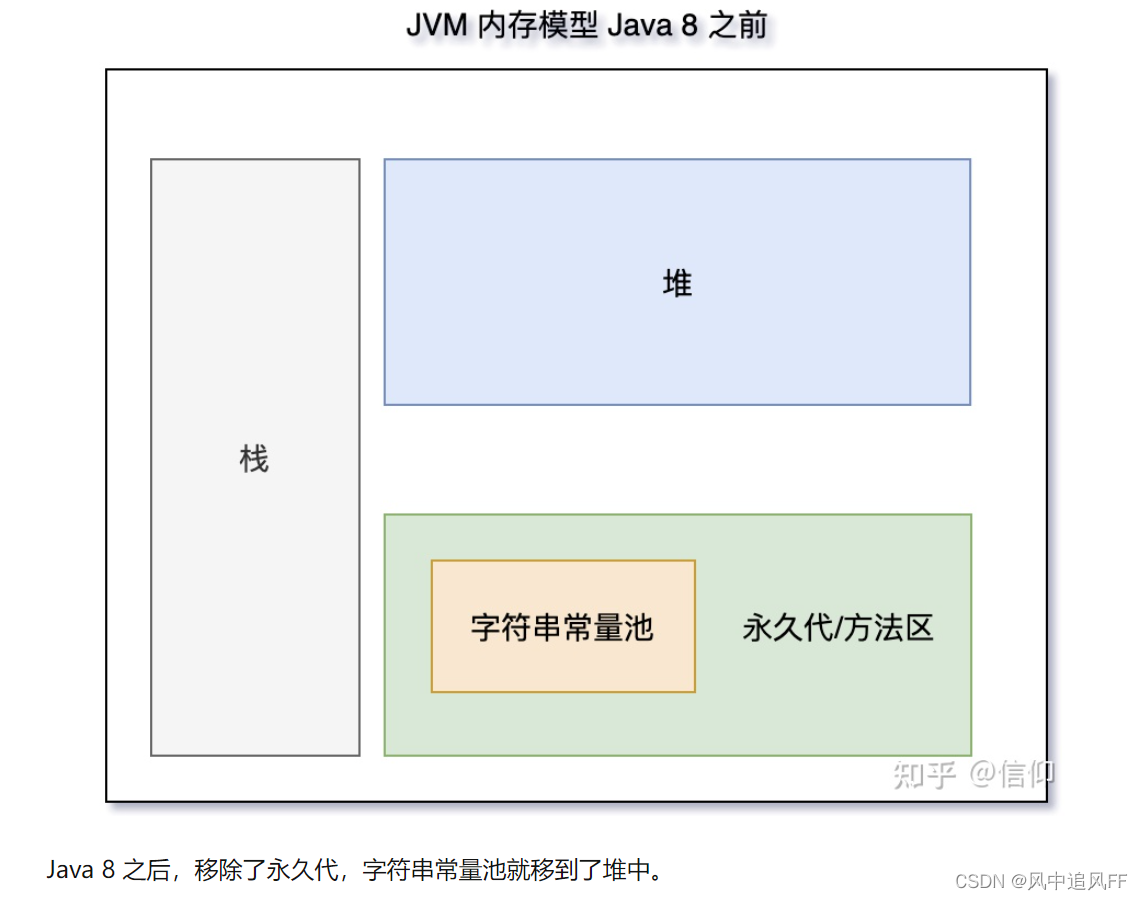
因为永久代被字符串常量池占用内存。
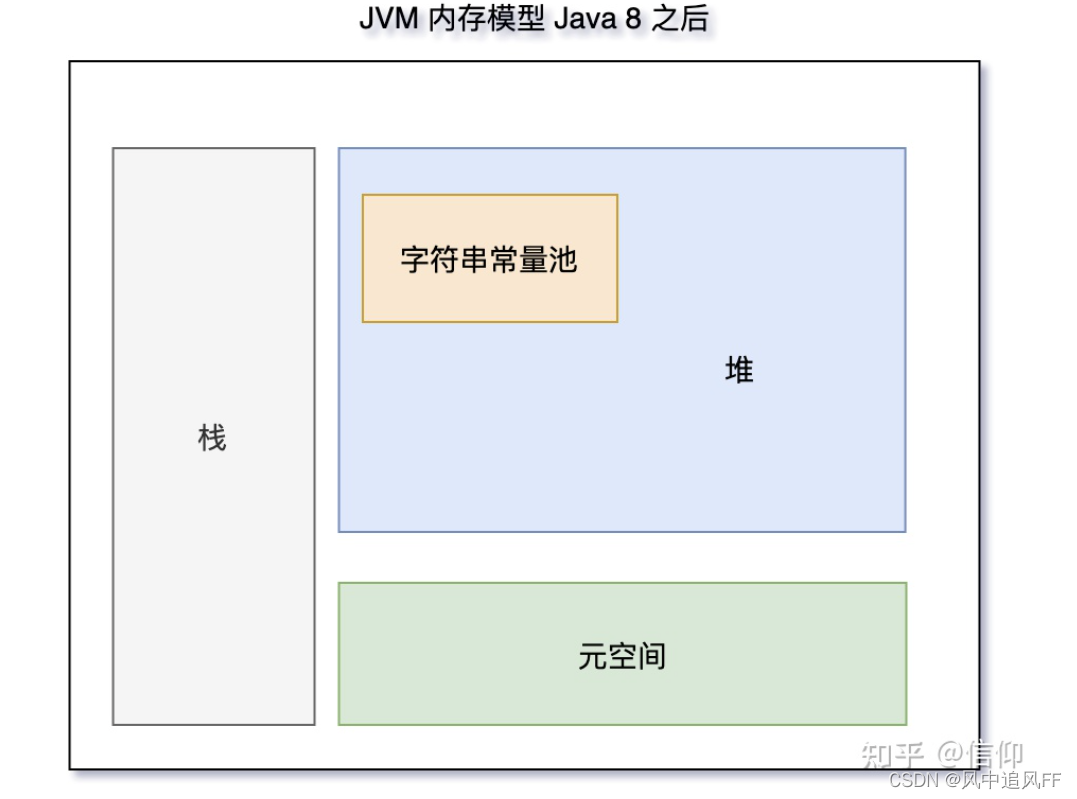

在JDK1.8下跑几道题。
public class Main {
public static void main(String[] args) {
String s1="a";
String s2="b";
String s3= "a"+"b";//在连接后,字符串常量里就有新的 "ab"
String s4= s1+s2;//堆里自己的对象,两变量的连接用的StringBuilder,然后toSting。
String s5= "ab";//s5用的s3时创建的字符串常量。
String s6= s4.intern();//发现常量池已经有,那s6就用常量池的。
System.out.println(s3==s4);//false
System.out.println(s4==s5);//false
System.out.println(s4==s6);//false
System.out.println(System.identityHashCode(s4));// 地址为460141958
System.out.println(System.identityHashCode(s6));//地址为1163157884
System.out.println(System.identityHashCode(s3));// 地址1163157884
System.out.println(s3==s5);//true
// write your code here
} //输出为false
String x2=new String("c")+new String("d");
String x1="cd";
x1.intern();
System.out.println(x1==x2);
//输出为false
String x1="cd";
String x2=new String("c")+new String("d");
x1.intern();
System.out.println(x1==x2);可以发现,new出来的就是不一样。拼接的才可能一样。
6.5 String table的垃圾回收
它在底层就是一个hash表,数组加链表的形式(被称作桶)。因为要解决冲突。
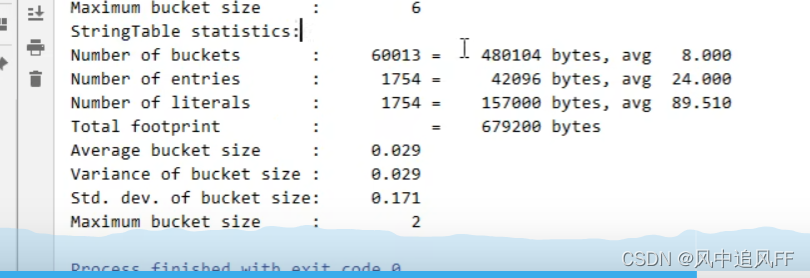
在这里疯狂的像StringTable里加数据
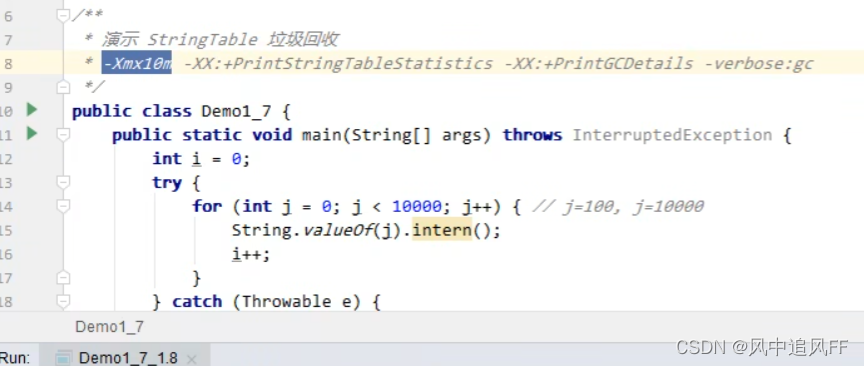
当内存不够的时候,就会触发垃圾回收机制。
6.6 String table的性能调优

6.6.1调整桶数
桶数多,哈希重装小,比较分散,查找速度就快。
调整 -XX:StringTableSize=桶个数
StringTable的底层是哈希表。
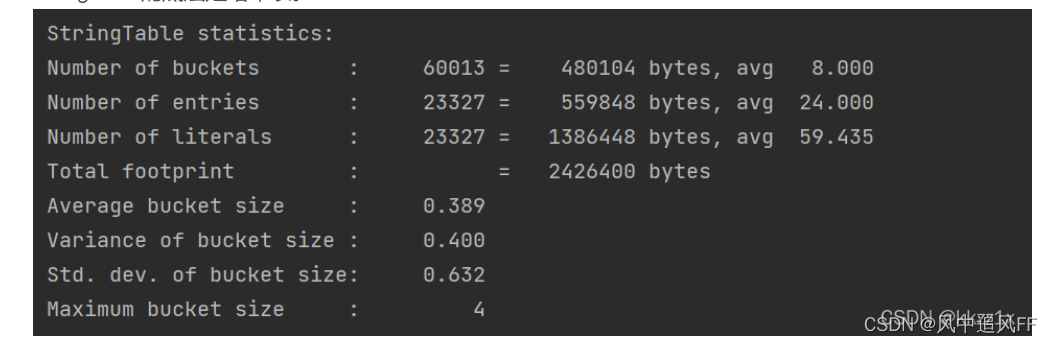
可以通过添加选项来调整bucket的大小,也就是哈希表的桶的个数。这个参数调的好,哈希冲突就少,少了的话那运行时间就会快。
-Xms500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000
如果字符串常量的个数非常多,那么把桶的大小调高一些。
对于要用到的字符串对象有大量重复的情况,考虑将字符串对象入池 节省堆内存的使用(放入串池就共享字符串啦><)
6.6.2 通过串池
如果要往一个list里疯狂插字符串。
可以先添加进串池,再加进list。

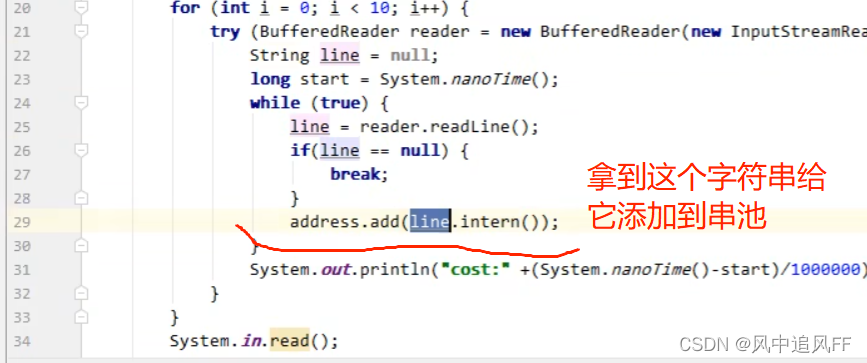
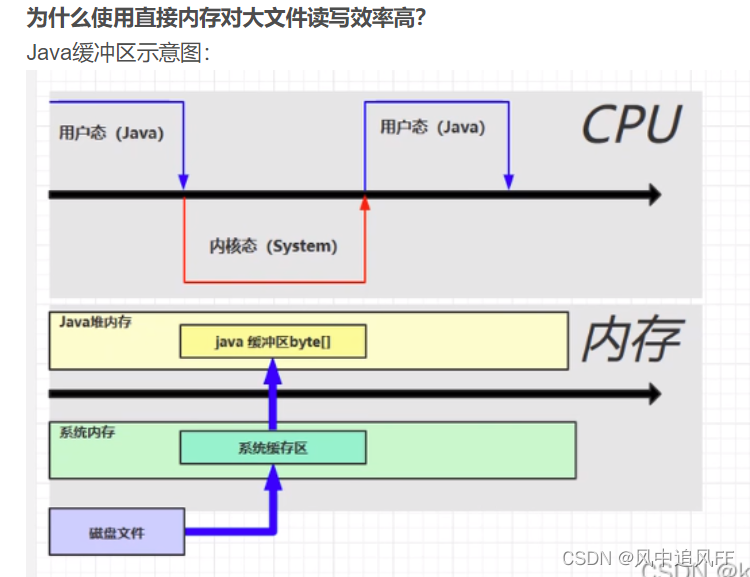
7.直接内存
属于是操作系统的内存。

这里java要用系统的命令,cpu就到了内核态。
7.1 传统阻塞IO
整了两个缓冲区。
7.2 DirectBuffer
整了一块和操作系统共享的内存区,能不快吗?
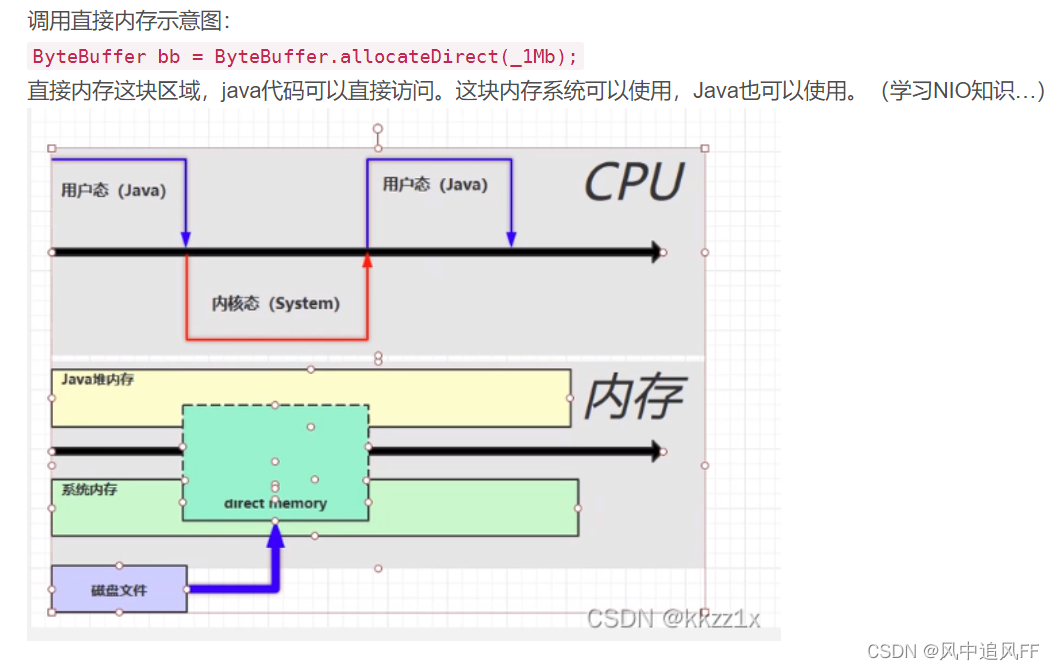
7.3 直接内存溢出(没有垃圾回收)
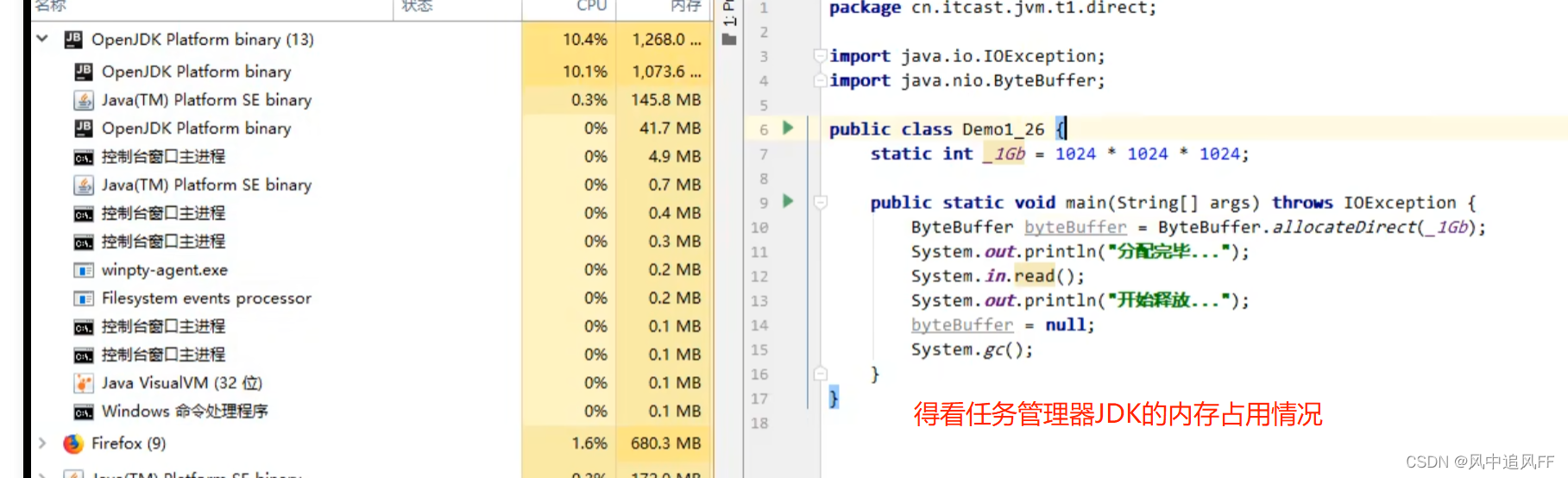
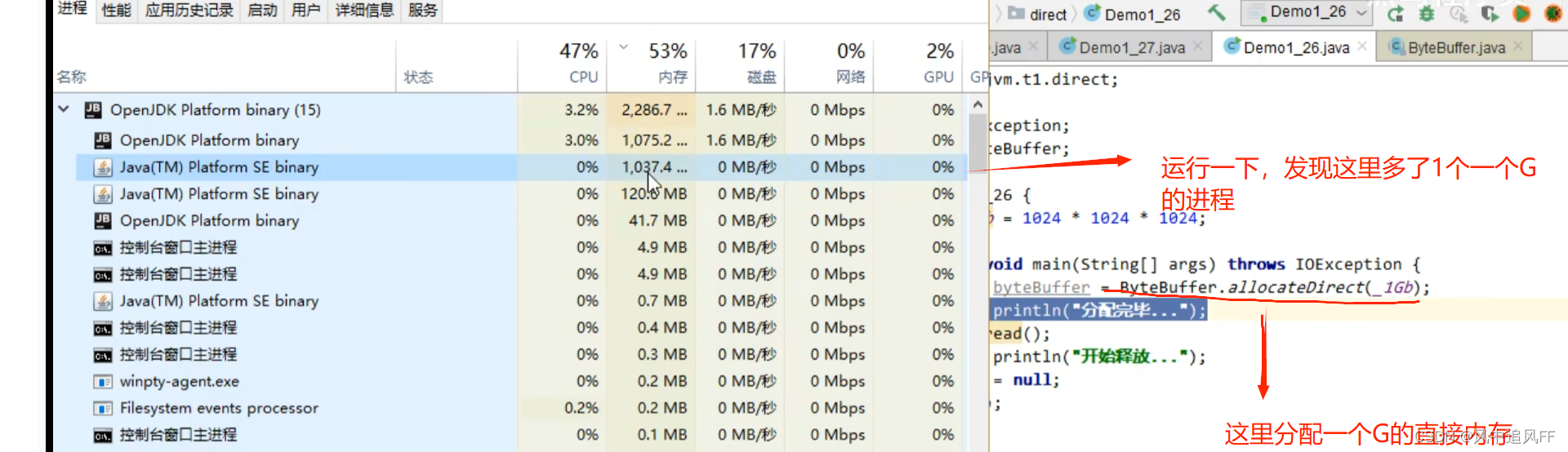
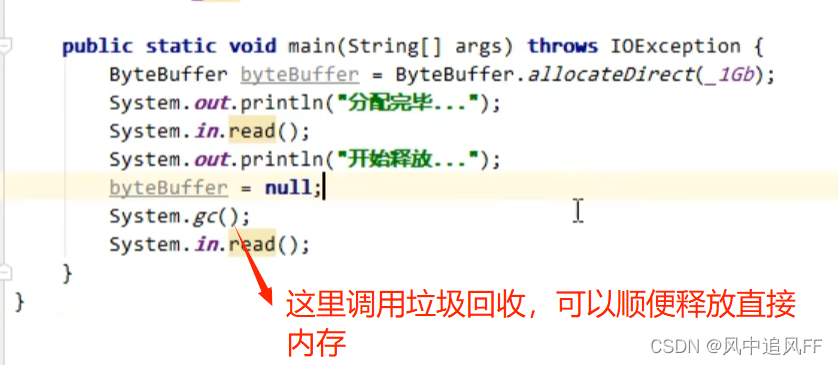
因为ByteBuffer 对象在被回收时,会调用unsafe对象里的直接内存回收方法。
7.3.1 直接内存释放的原理
直接内存的分配与释放,是通过一个unsafe对象完成的。
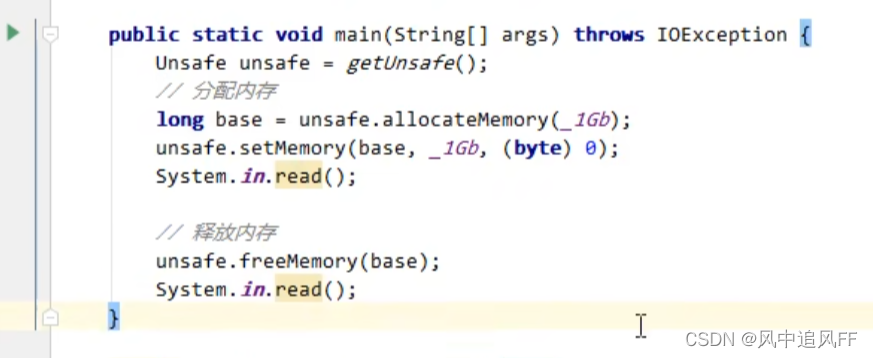
调用unsafe的freeMemory方法来释放直接内存。

7.4 禁用显式的垃圾回收对直接内存的影响
为了防止程序员,不用System.gc();
就在虚拟机参数那里设置这个操作的无效。
禁用了System.gc();会影响直接内存的释放

这里我们只能用unsafe对象,调用freeMerory的方法来直接释放。
8.堆的垃圾回收
8.1 如何判断一个对象可以回收
8.1.1 引用计数法
看一个对象被需要被引用的数量。
但这个东西有一个缺点。
在这种循环引用中,各自的计数都为1,就不会被释放。造成内存的泄露。
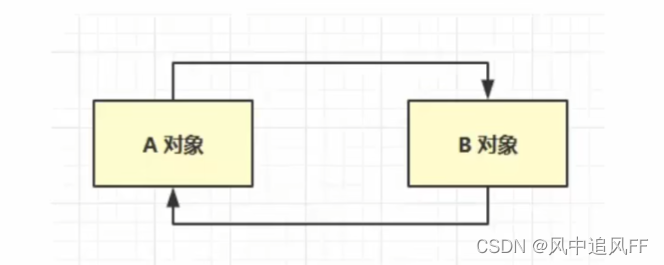
8.1.2 可达性分析算法(jVM正在用地)
1.首先得确定一些根对象,(根对象:那些一定不会被垃圾回收的对象)。
2.在垃圾回收之前,会对堆内存中所有的对象扫描。看看每个对象是否被根对象直接或间接地引用,如果没有就作为垃圾被回收。

但哪些对象可以作为根对象呢?


8.2 JVM的四种引用


8.2.1 强引用
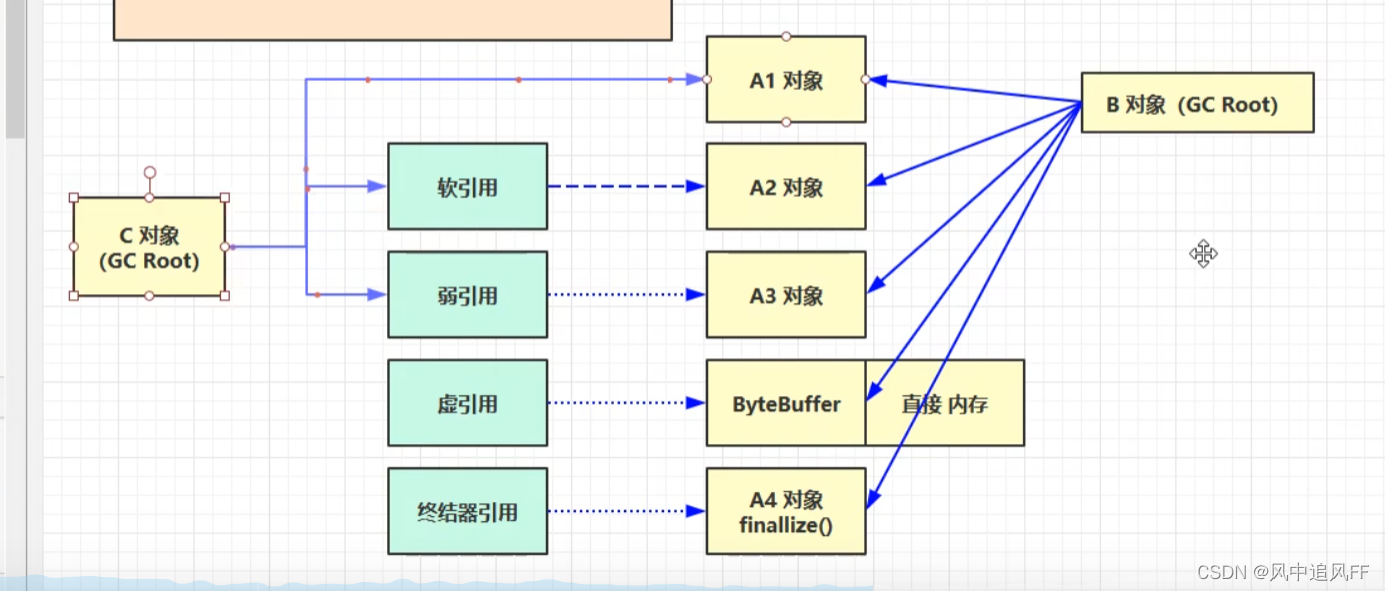
A1对象被两个GC Root 对象直接强引用,不可能回收它。
当引用消失的时候,就会被回收。
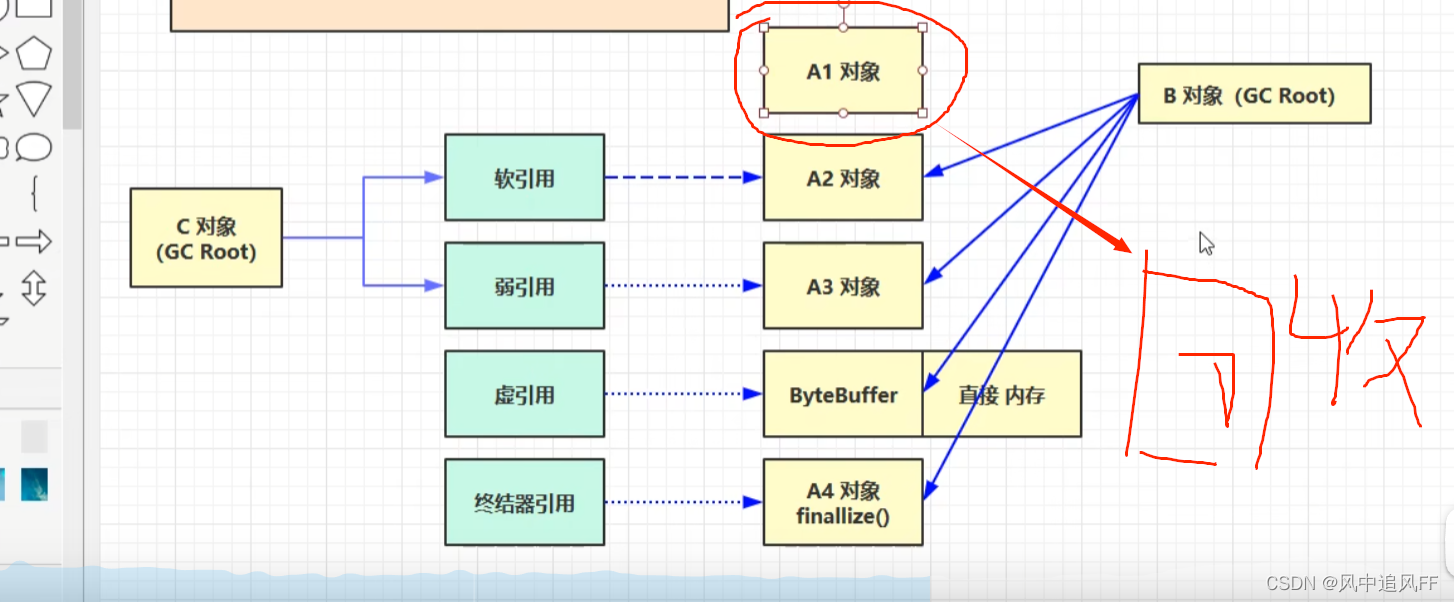
8.2.2 软引用
A2对象有强引用的时候不可能被回收,除非它的强引用消失,这个时候只剩下一个弱引用。
在垃圾回收时,如果回收完毕后,内存还是不够,那就回收对象2。
当我们软引用的对象消失后,软引用本身也是一个对象。

如果在创建引用时,分配了一个引用队列, 这个软引用就会被放进 软引用队列
8.2.3 弱引用
与软引用差不多
区别就是:只要发生了垃圾回收,这个对象只有弱引用,就回收它。
弱引用的对象被回收,这个弱引用也会被放到队列。
8.2.4 释放引用队列可以释放内存
引用也占内存,可以通过队列来释放引用,来释放内存。
软引用,弱引用,强引用,可以创建队列,也可以不创建队列。
8.2.5 虚引用(释放绑定直接内存的对象)
必须关联一个引用队列。
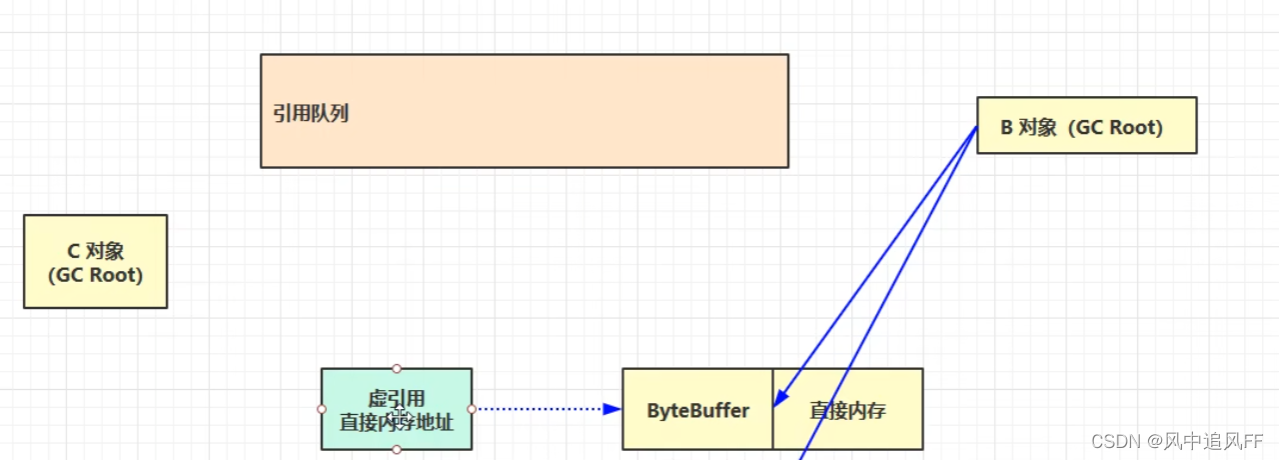
比如前面学的ByteBuffer,整的是直接内存,当ByteBuffer的强引用消失,它会被垃圾回收,但它指向的那块直接内存却不会被回收。
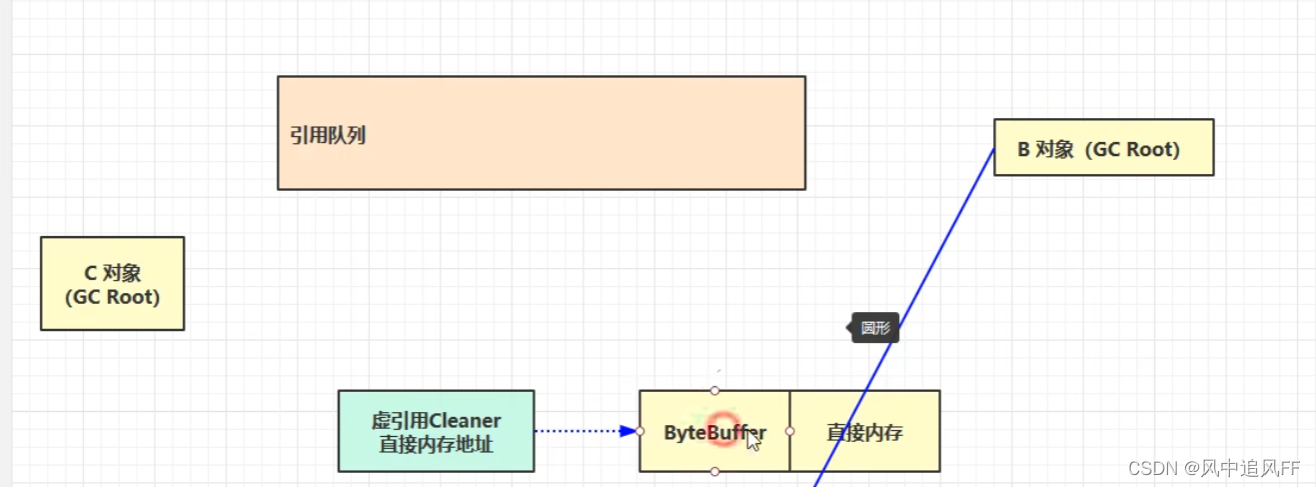
当ByteBuffer对象被回收时,让虚引用对象进入队列。
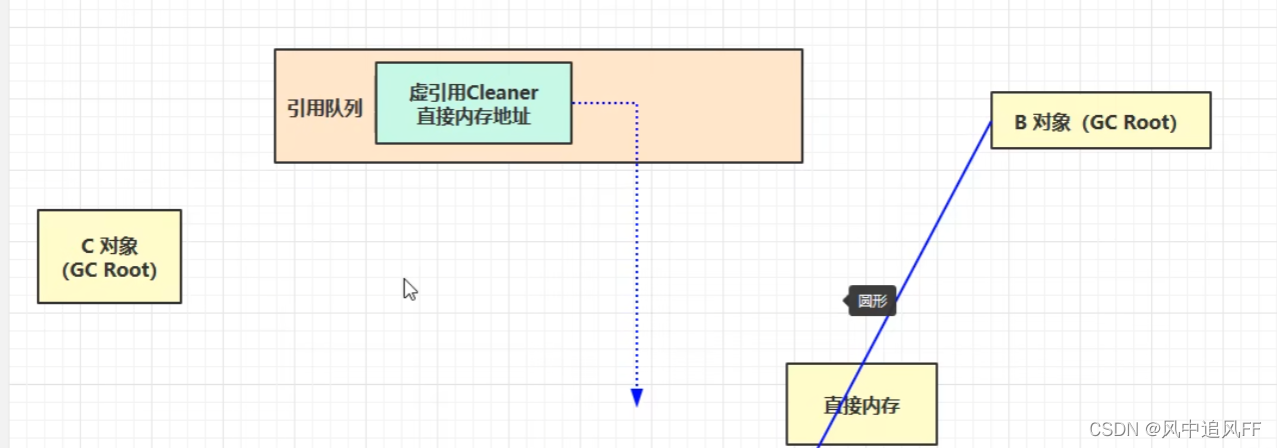
被一个refrencehandler线程来定时的检查,检查有没有cleaner,如果有,调用unsafe.freeMemory方法,释放这块的直接内存。
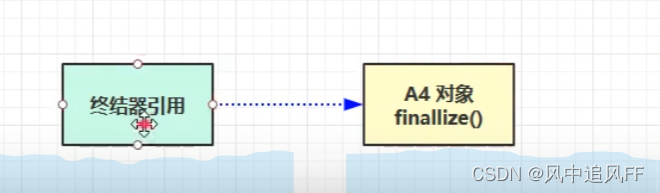
8.2.6 终结器引用(对象被回收的真正机制)
必须建立引用队列。
所有的java对象都继承object 父类,里面都有一个finallize()方法。
当这个对象实现了finallize方法,才会有终结器引用。
当没有强引用存在时,这个对象就会被创建一个终结器引用。
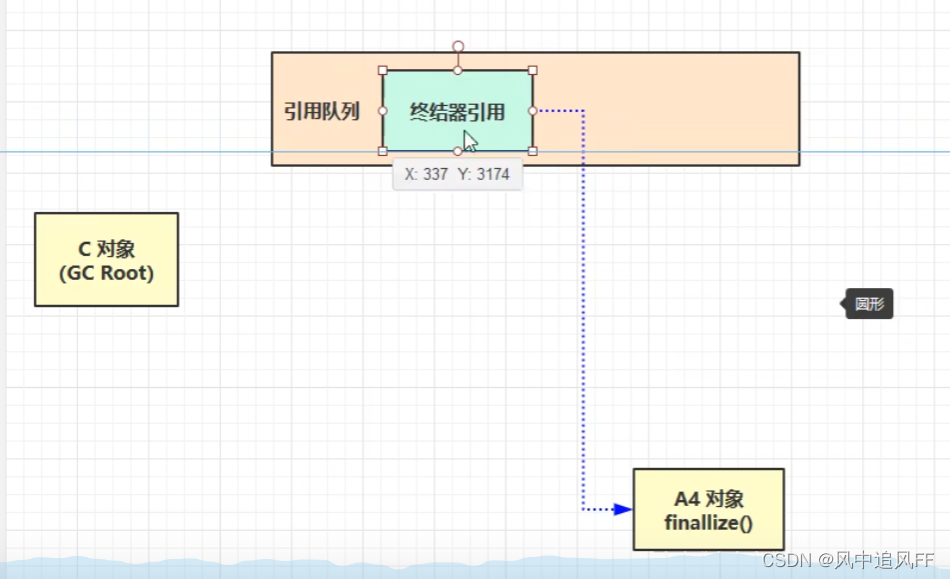
当这个对象被垃圾回收时,终结器引用就会被加入到引用队列。由一个finallizeHandler线程来调用对象里的finalize()方法,完成对象的终结。
8.2.7 不推荐用终结器引用
处理终结器引用的线程的优先级很低,对象可能会迟迟得不到终结,内存迟迟得不到释放。
8.3 垃圾回收算法
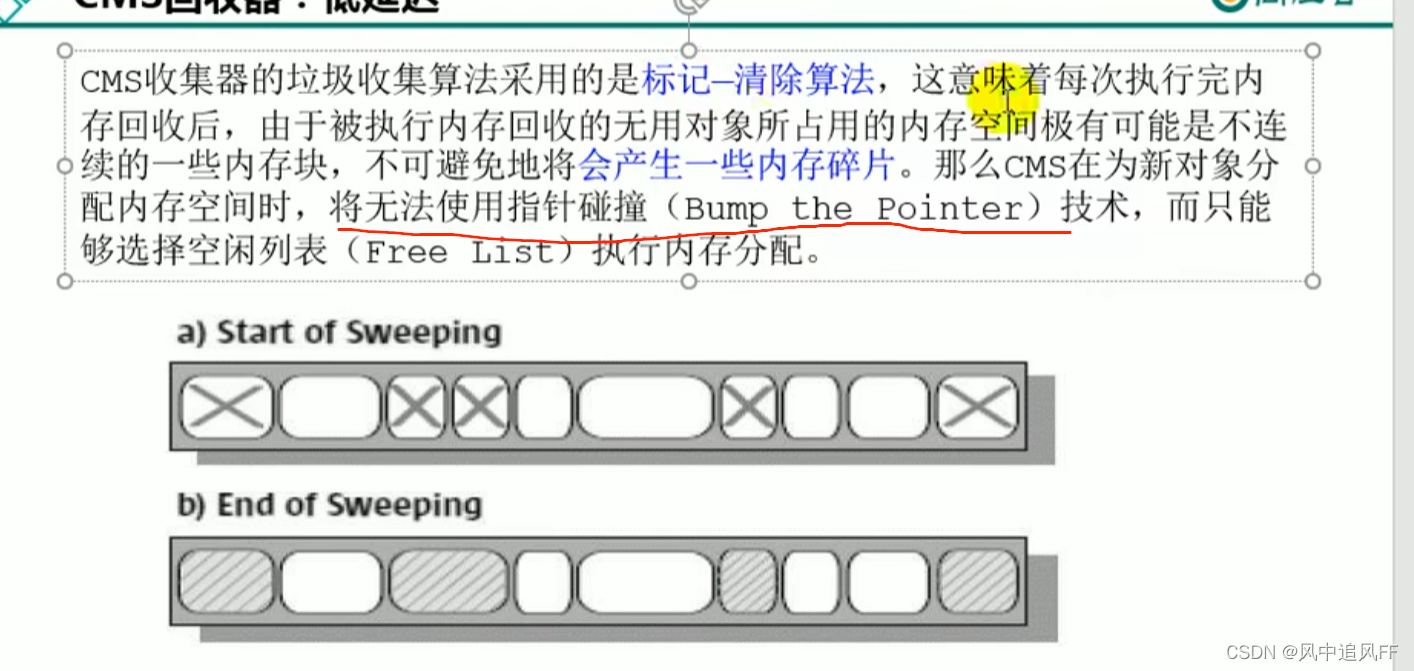
8.3.1 标记清除算法
就是顺着GC Root往下查可达性,标记那些不可达的对象。
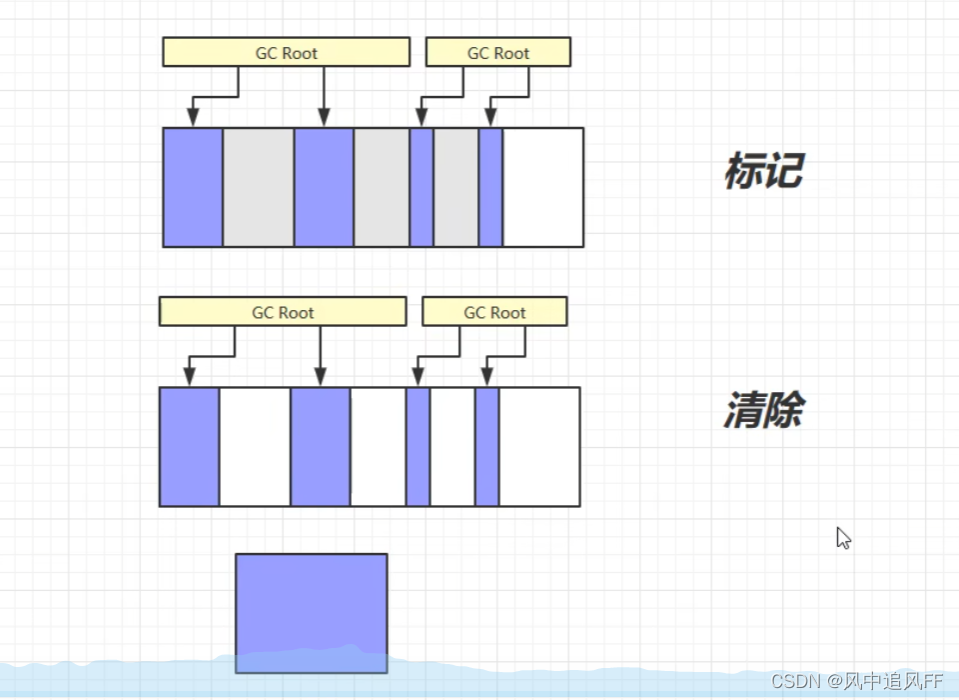
然后清理这些对象的内存,如何清?
记录这些对象的起始和终结地址,放在空闲的地址列表里,下次给新对象分配内存时,看看这个地址列表里有没有一块空间能容纳我们的新对象。就是覆盖,用新对象覆盖。
优点:快速
缺点:内存碎片太多
8.3.2 标记整理算法
就是顺着GC Root往下查可达性,标记那些不可达的对象。
然后整理一下我们的内存空间,重新根据分配空闲内存地址。
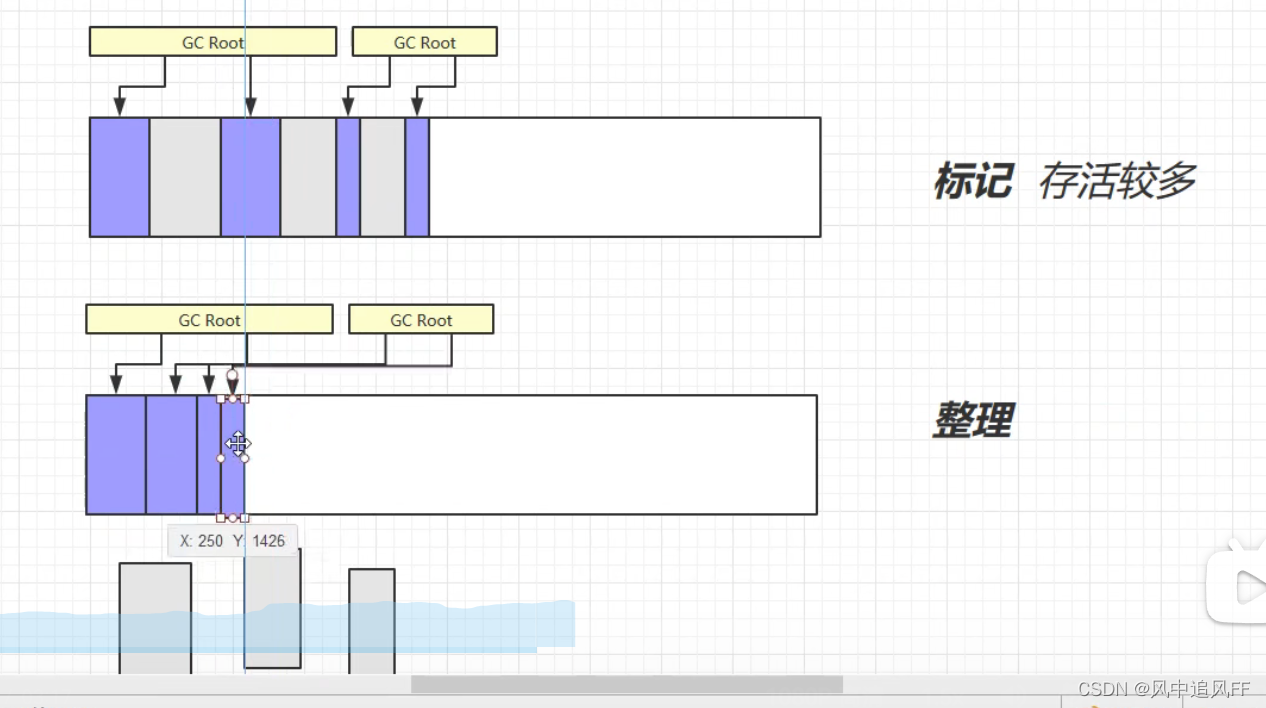
这就是通过外部技术来解决内存碎片。
整理牵扯到对象在内存上的移动,效率就低。
8.3.2 复制算法
就是顺着GC Root往下查可达性,标记那些不可达的对象。

整了两块,把存存活的复制到另一块。
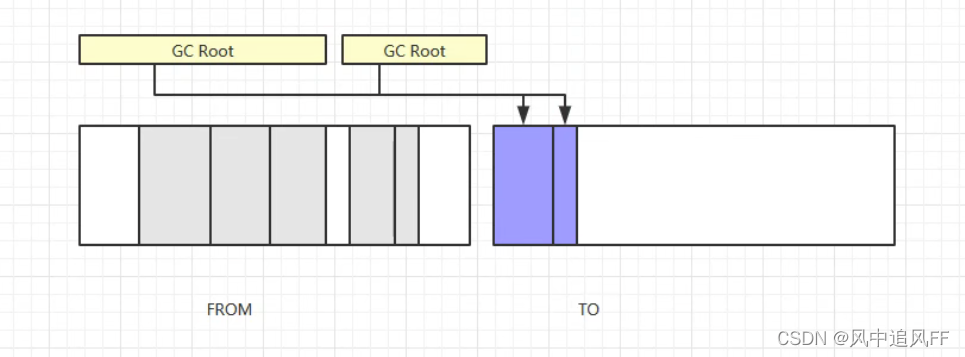
然后清理原来的,原来的又变成空白,作为备胎。
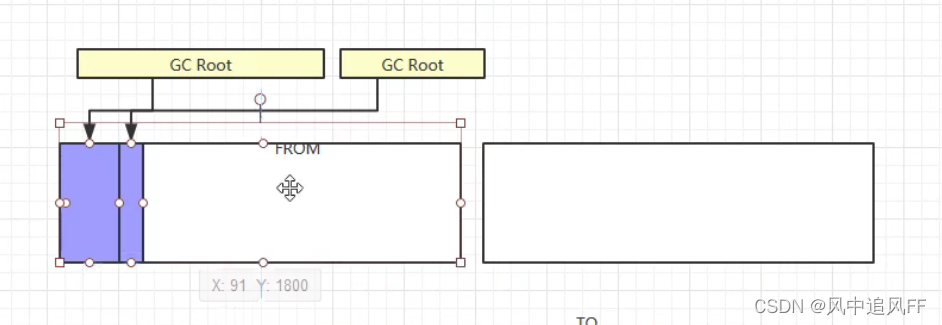
优点:没随碎片。
缺点:占用双倍内存。
8.4 分代垃圾回收机制
虚拟机不可能只用一种算法回收,都是多种结合。
老年代:很久才发生一次垃圾回收
新生代:频繁发生垃圾回收。
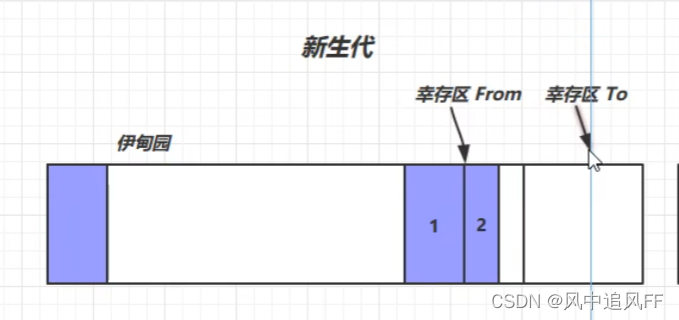
8.4.1 新生代第一次内存满(Minor GC)
新生代中的回收被称作Minor GC
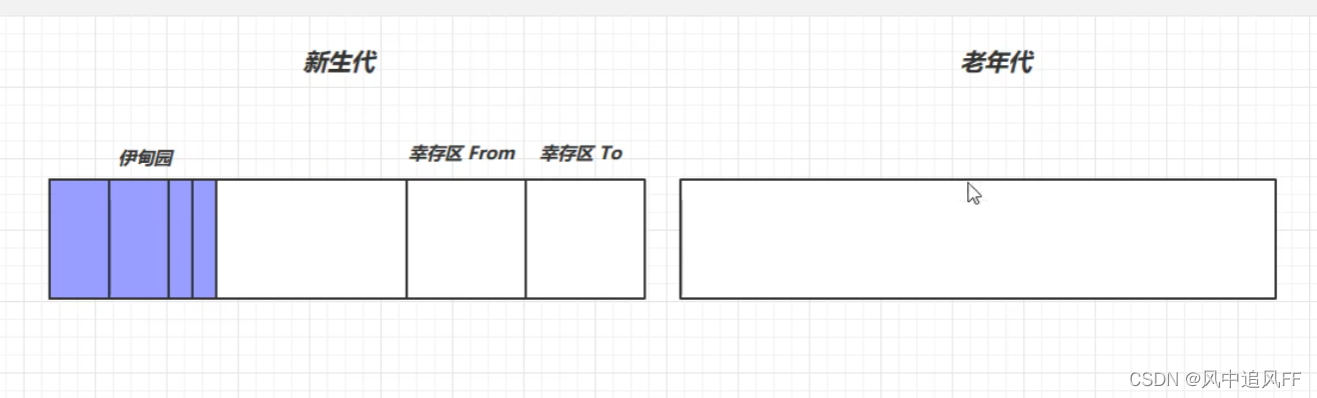
我们刚new的对象,放在伊甸园中,当我们创建很多对象,这里的空间就不够了。就会触发一次垃圾回收。就会触发一次复制回收,把GCRoot可达性查询后标记的对象,放进幸存区To中。
复制过去了,会让这些幸存对象的寿命加一。
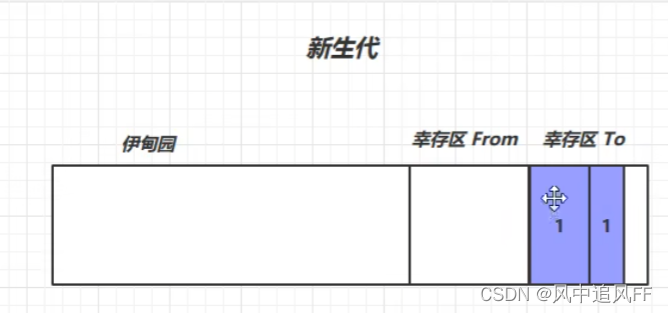
然后交换幸存区位置。
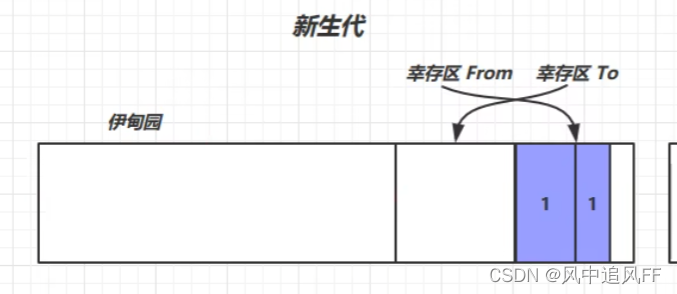
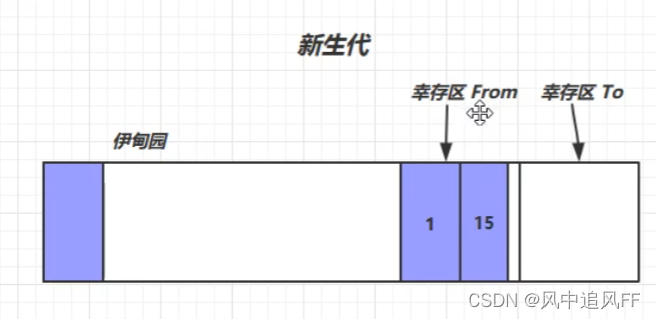
8.4.2 新生代第二次内存满 (Minor GC)
新生代中的回收被称作Minor GC
又满了,又触发了垃圾回收机制。
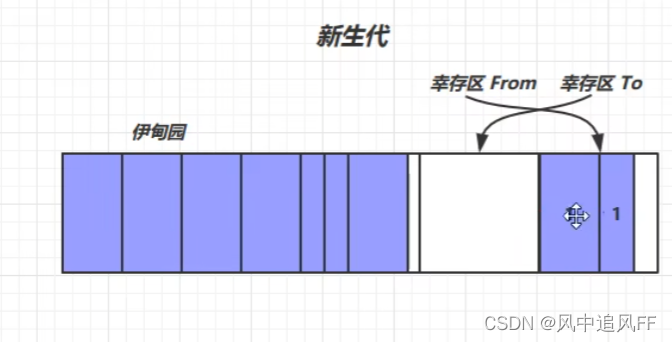
这次可能幸存区中,也有对象过期。
1是这次处理后,伊甸园留下来的对象。
2是这次处理后,幸存区留下来的对象。
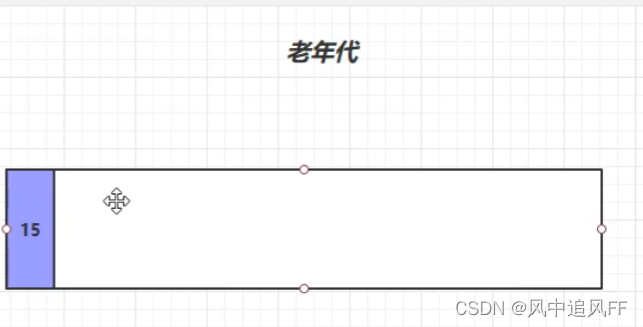
8.4.3 第N次内存满,弄进老年代。(Minor GC)
当我们发现一个对象存活了很多代,就试图给它弄进老年代。
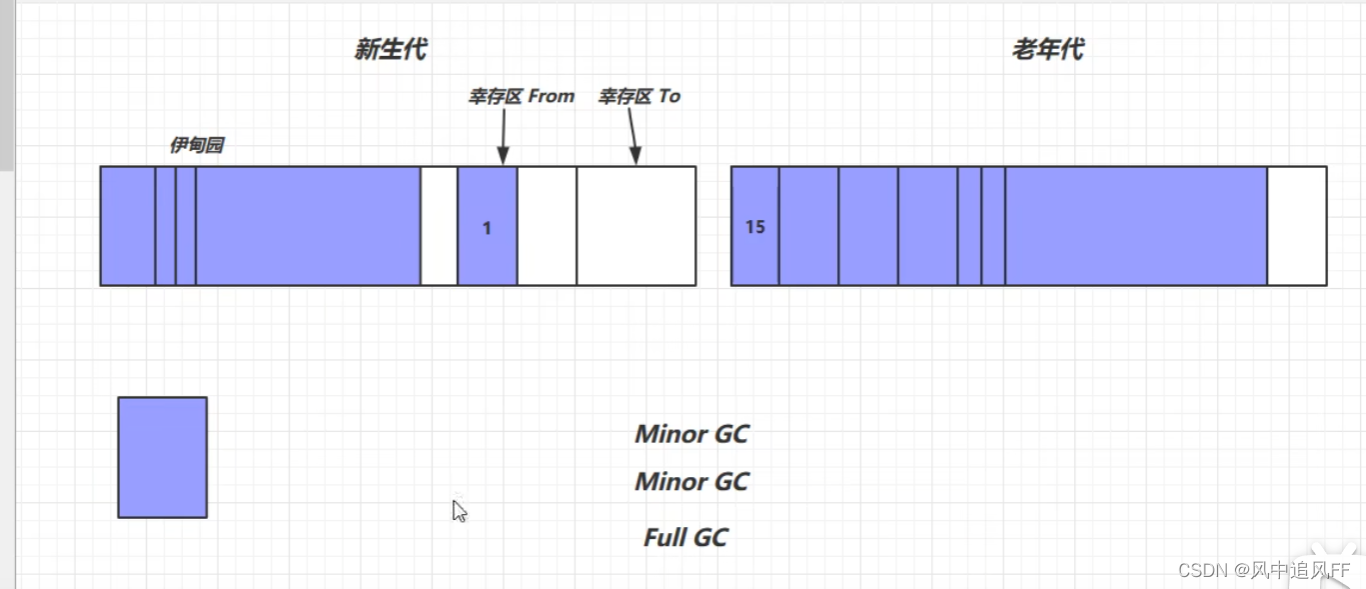
8.4.4 当新生代和老年代里面都放不下新对象(Full GC)
此时就会触发俩个代理,整个的垃圾回收。
8.4.5 总结
老年代的对象回收,时间更长(STW),老年代采用的算法可能是标记清除或标记整理。
因为它里面的对象不是那么容易被回收。
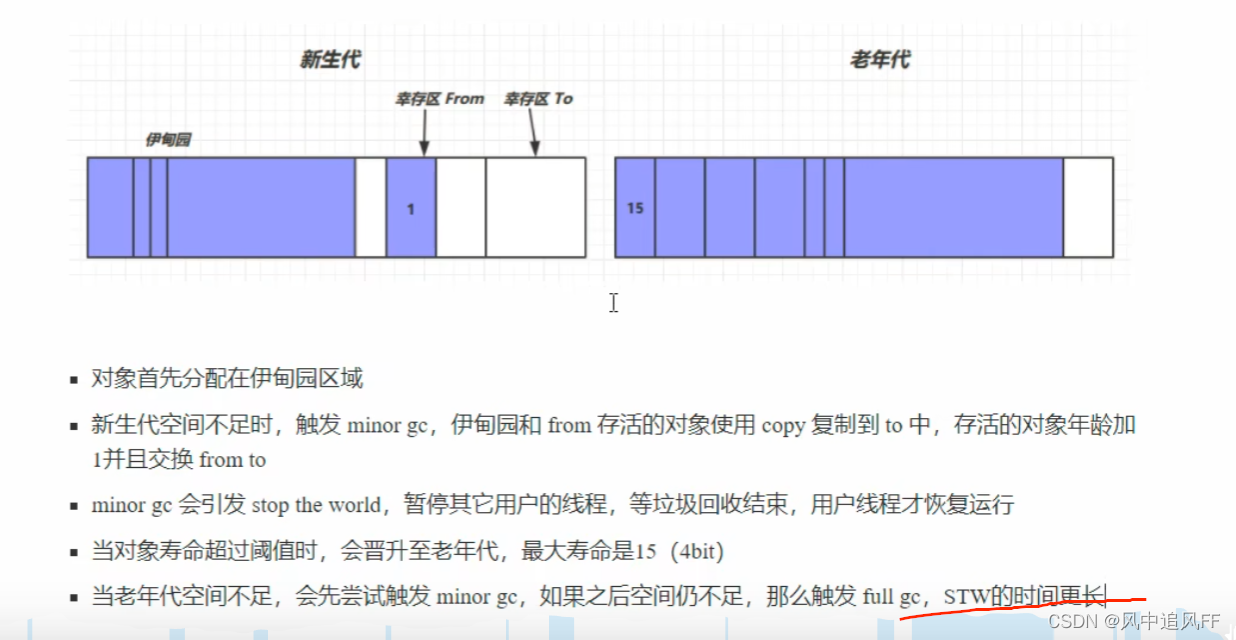
8.4.6 相关VM参数

8.5 垃圾回收器
STW就是等待时间。
吞吐量优先就是让总STW最短。
响应时间优先:每次让STW最小。

8.5.1 串行垃圾回收器
打开它的参数
新生代用serial串行完成垃圾回收。
老年代用SerialOld完成垃圾回收。
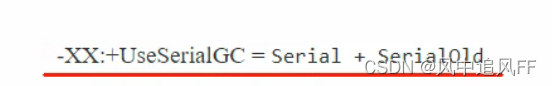
其他线程需要在安全点阻塞,因为里面的对象地址可能会变化。
这个时候只有垃圾回收线程在工作。
8.5.2 并行吞吐量优先
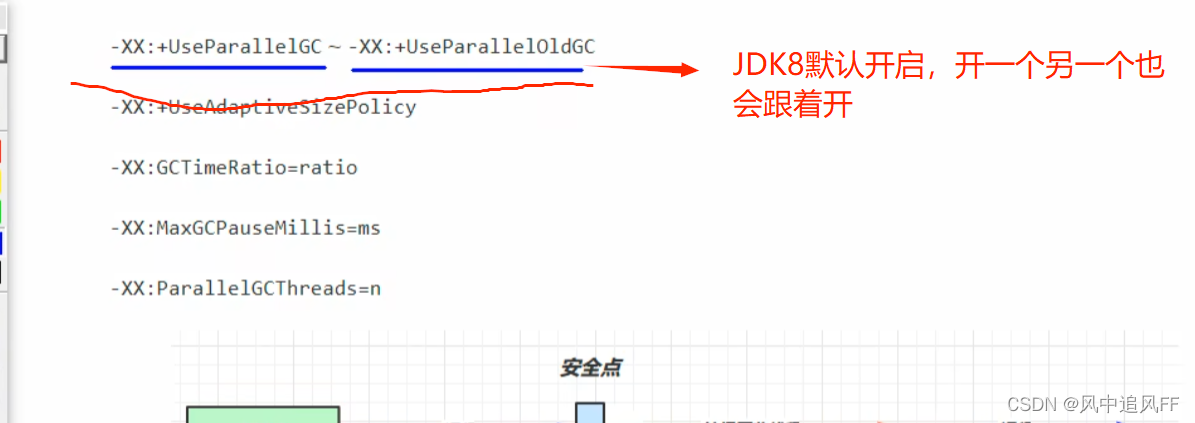
垃圾回收发生时,CPU是这样占用的。
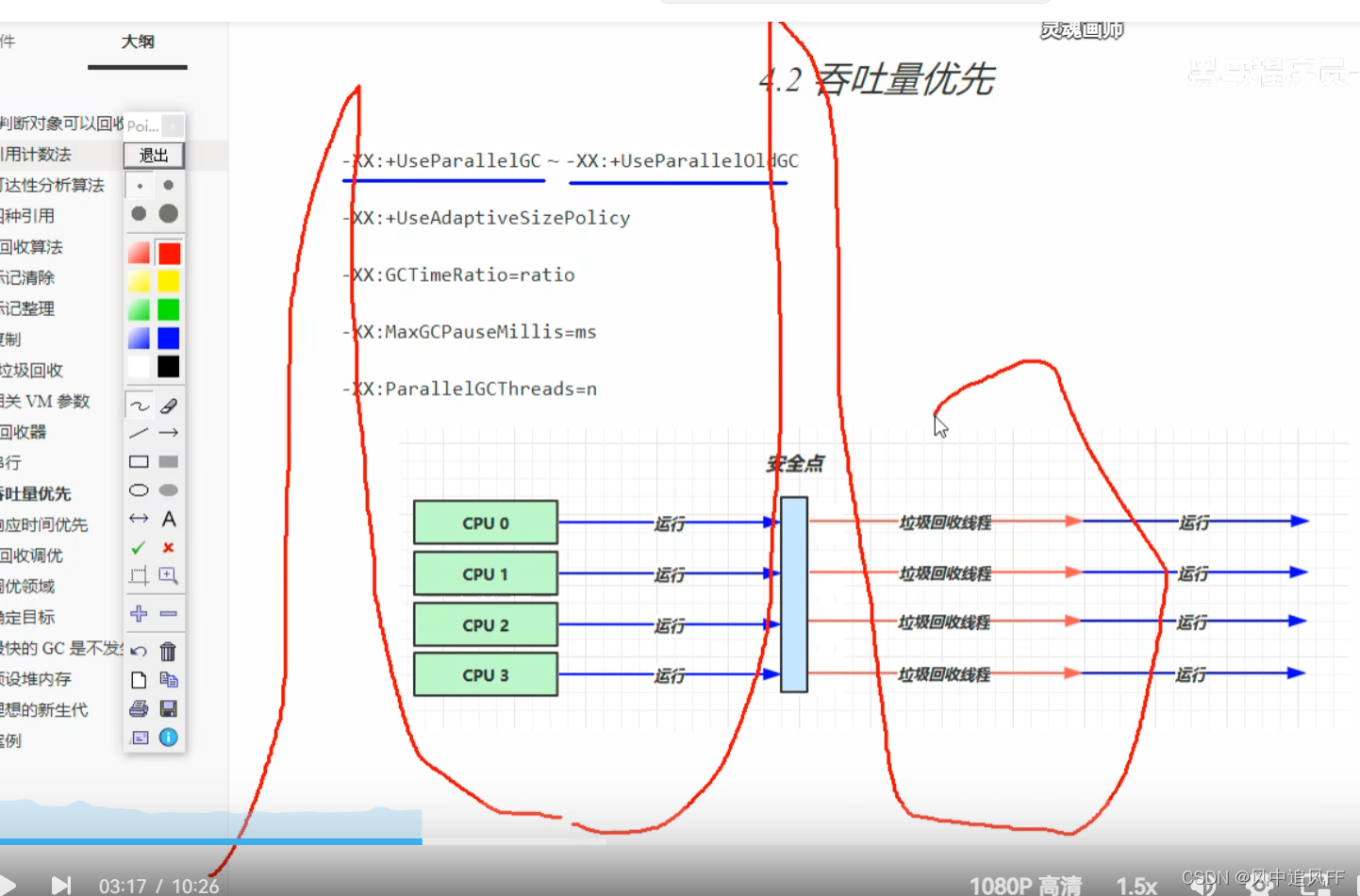
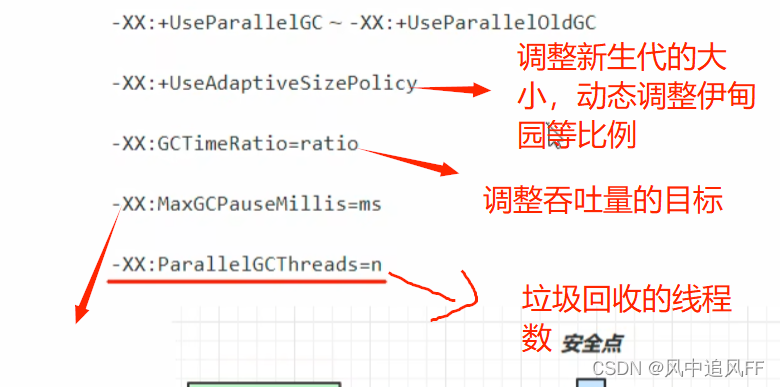
MAXGcPauseMillis=ms,最大暂停毫秒数,默认为200。
GCTimeRatio默认是99,一般设为19,使用不超过 1/(1+ratio)的时间用来垃圾回收。比如总时间为100s,不能超过20s来垃圾回收,如果达不到这个要求,paralleGC就会调整堆的大小,一般增大堆,然后垃圾回收的不频繁,垃圾回收的总时间下降,得到吞吐量的提高。但是即使垃圾回收次数变少,总的垃圾回收时间变短,但每次的垃圾回收时间会变长MAXGcPauseMillis就会变大。
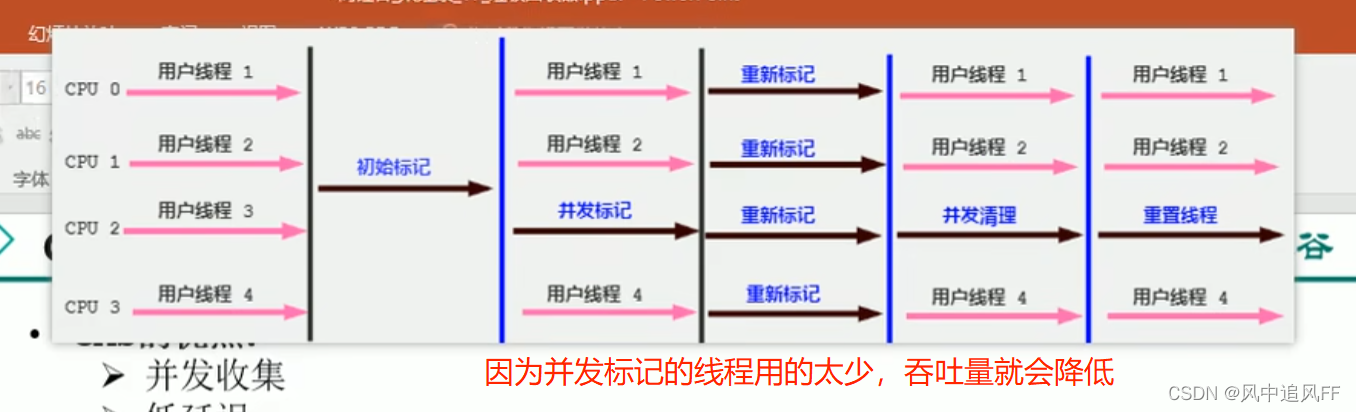
8.5.3 响应时间优先(CMS收集器的过程)
concurrent 是并发的。用户线程和垃圾回收线程是并发的。
为啥响应时间短?因为有部分标记的时间是和用户线程一起并发的,之前的标记或清理都是STW(stop to world暂停)。
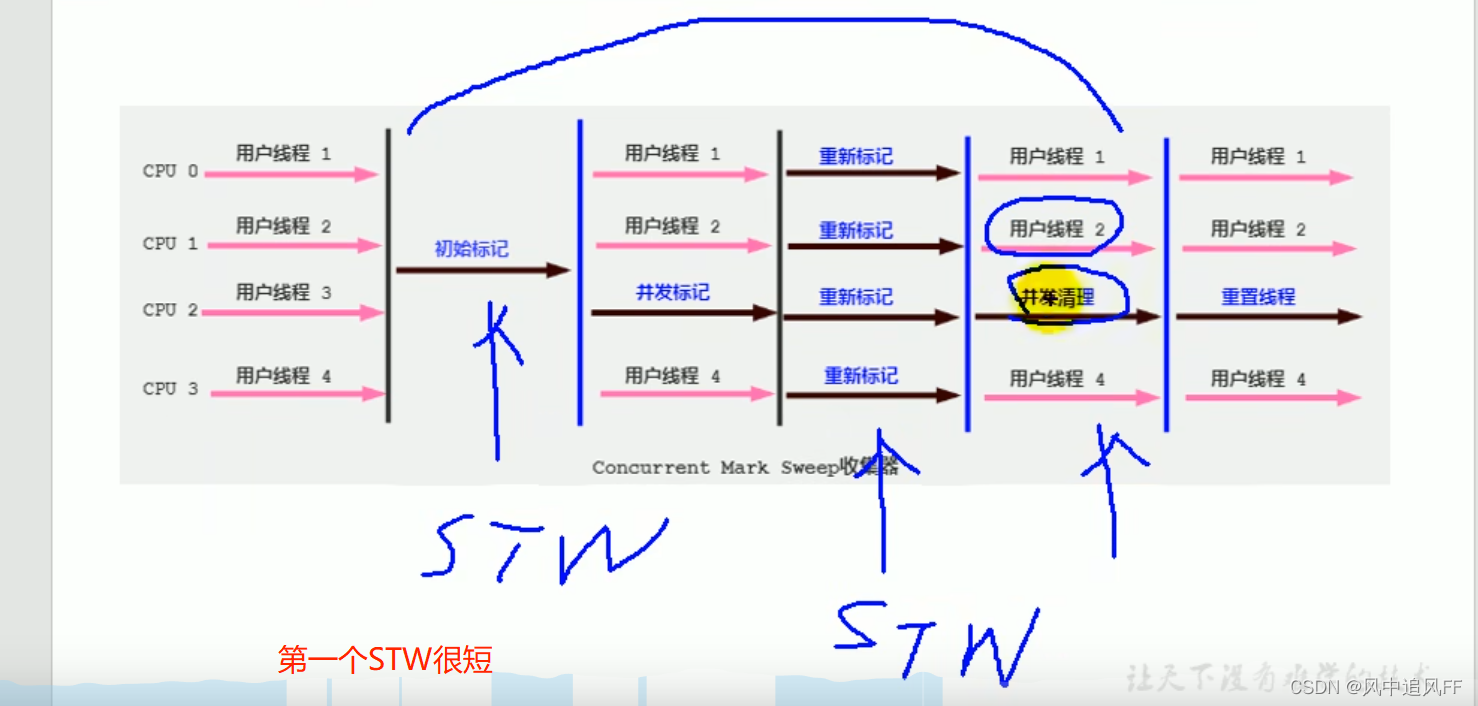
有四个阶段。
然后清除的时候就可以并发清除。
要解答这个问题,我们就要弄清楚:为啥 CMS 垃圾回收器为啥要分成「初始标记」、「并发标记」、「重新标记」、「并发清除」这四个步骤!我直接一步走到底不行吗?为啥要那么麻烦分成四个步骤呢?
答案只有一个:为了降低 Stop the World 的时间!
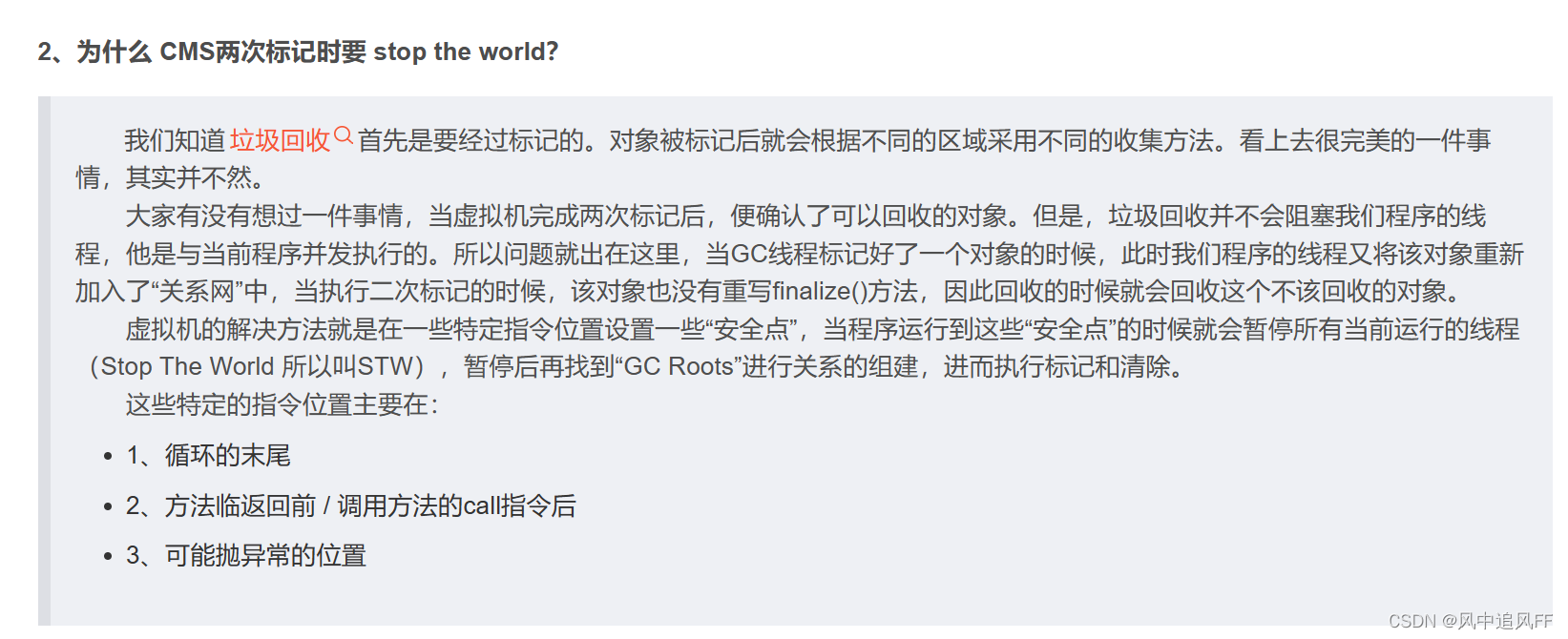
8.5.4 CMS的分析
1.需要在堆内存使用率那里设置阈值。

2. 为什么在初始标记和重新标记阶段需要STW。
3.CMS拥有标记清除算法内存碎片的弊端
4.那为什么我们不用标记压缩算法?
因为你在压缩的过程,用户线程也得搬家。适合大STW场景。

5.CMS的CPU敏感问题

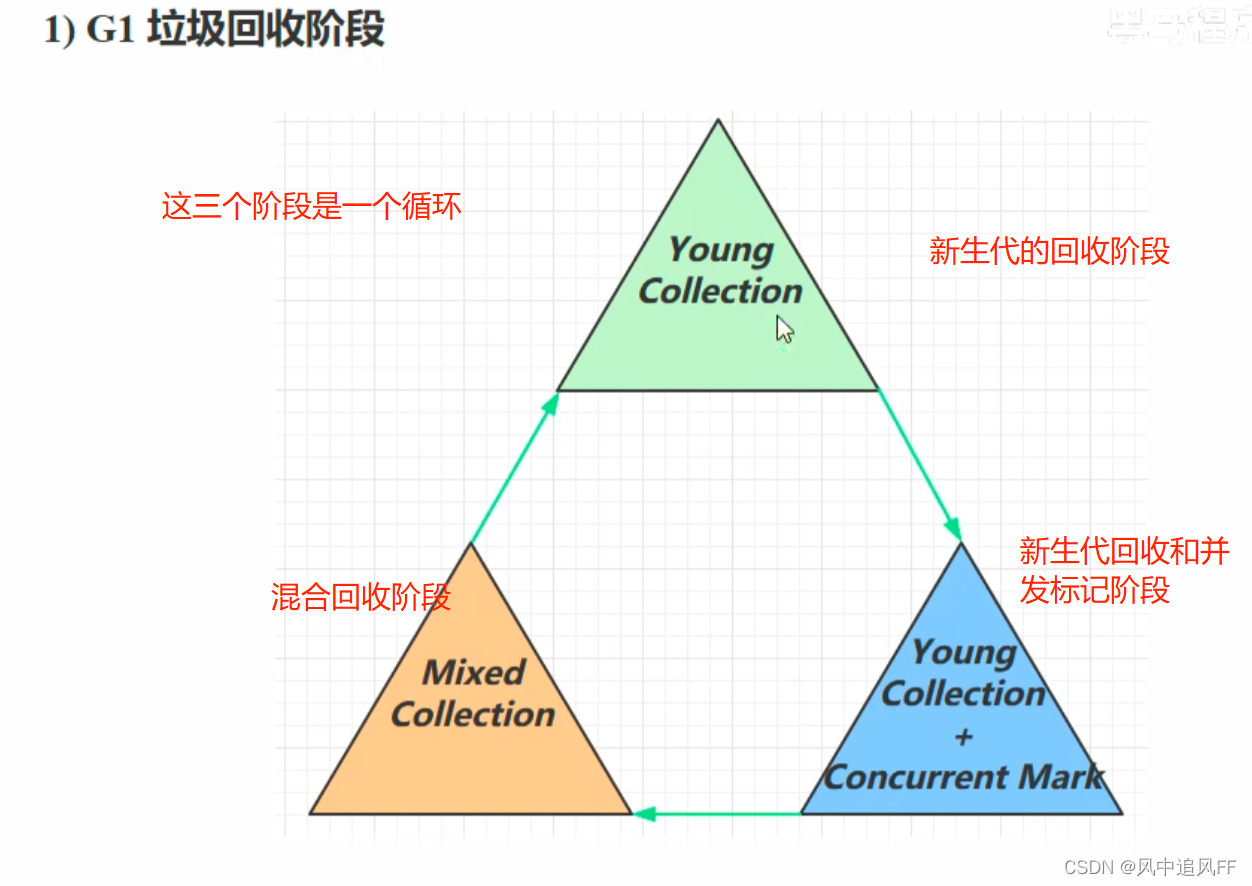
8.5.5 G1垃圾回收器
优先回收垃圾较多的区

如果堆内存花费都小的时候下,它和CMS花费的时间都不相上下。

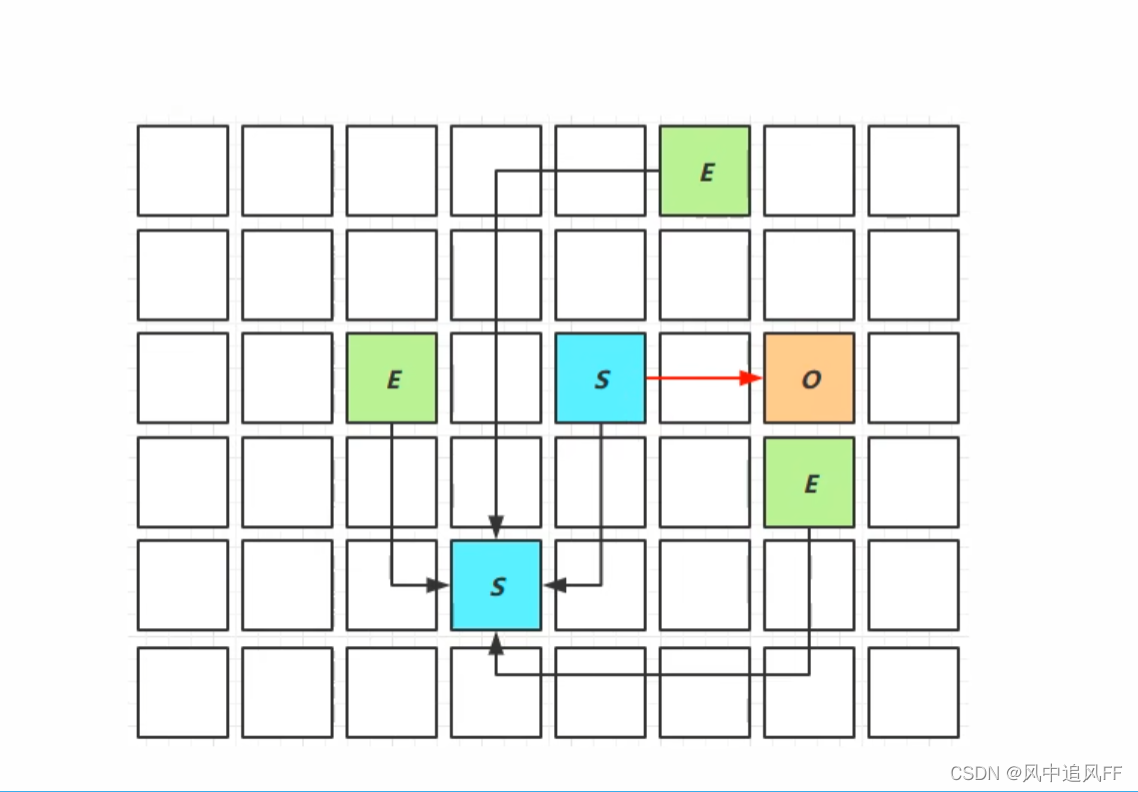
8.5.6 G1的youngCollection阶段(第一阶段)
堆里有很多区,E为新生代区,当新生代区满了之后就开始垃圾回收,剩余的放进幸存区S,幸存区的满了之后,触发垃圾回收,没被回收的会放进老年区O。
这个阶段进行GCRoot的初始标记。
8.5.7 G1的young Collection和 Concurrent Mark阶段(第二阶段)
这个阶段就是新生代和CM一起发生的阶段。
当老年区的占用堆空间的比例到达阈值,就会触发并发标记。
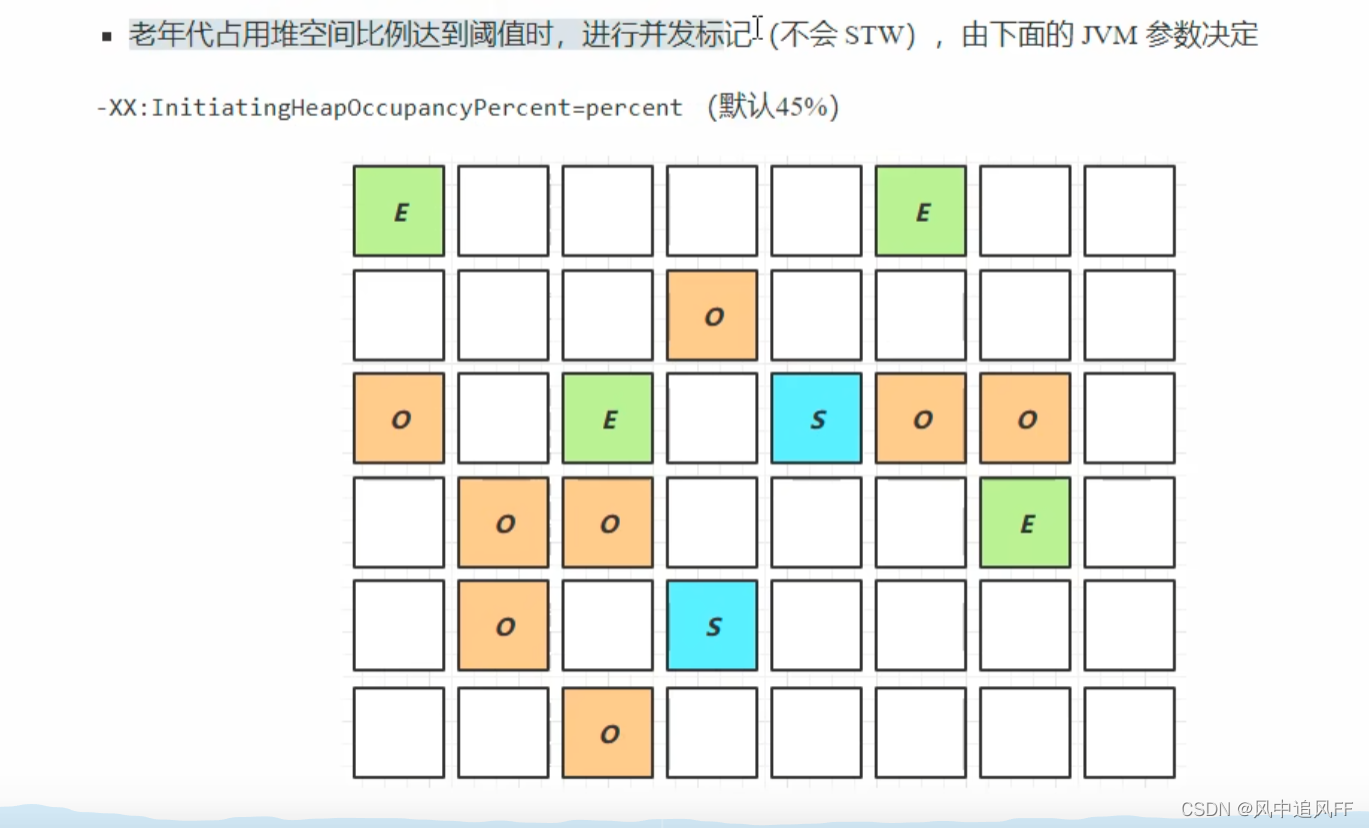
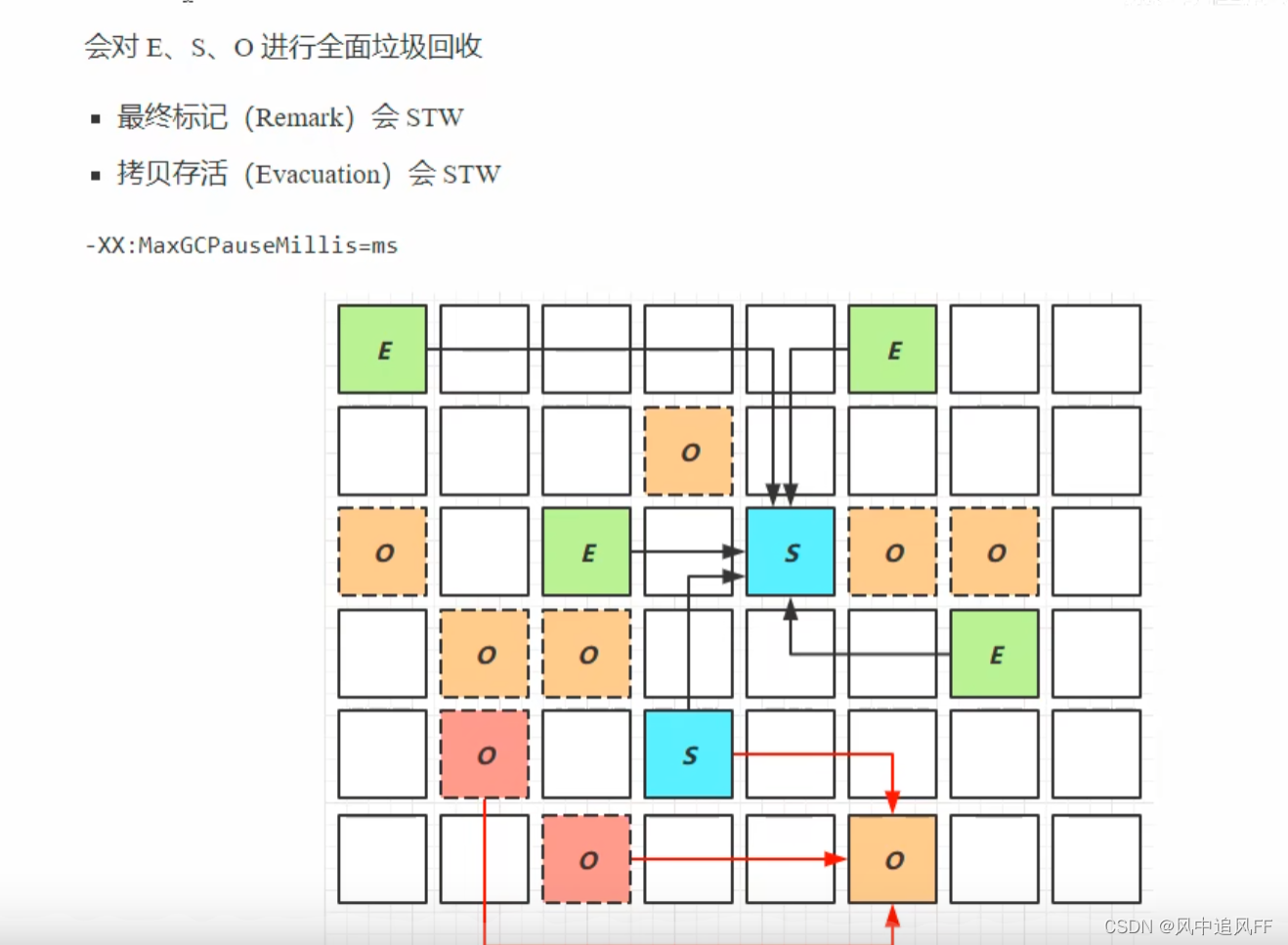
8.5.8 G1的Mixed Collection阶段(第三阶段)
优先回收垃圾较多的区。
在这个阶段就要开始回收幸存S区和老年O区里的垃圾,但是不是回收每一个老年O区,而是有选择地回收老年O区,老年区O里的存活对象一般较多。
参数MaxGcPauseMills最大暂停时间,此时挑垃圾最多的老年区回收,这样复制的时间更少。
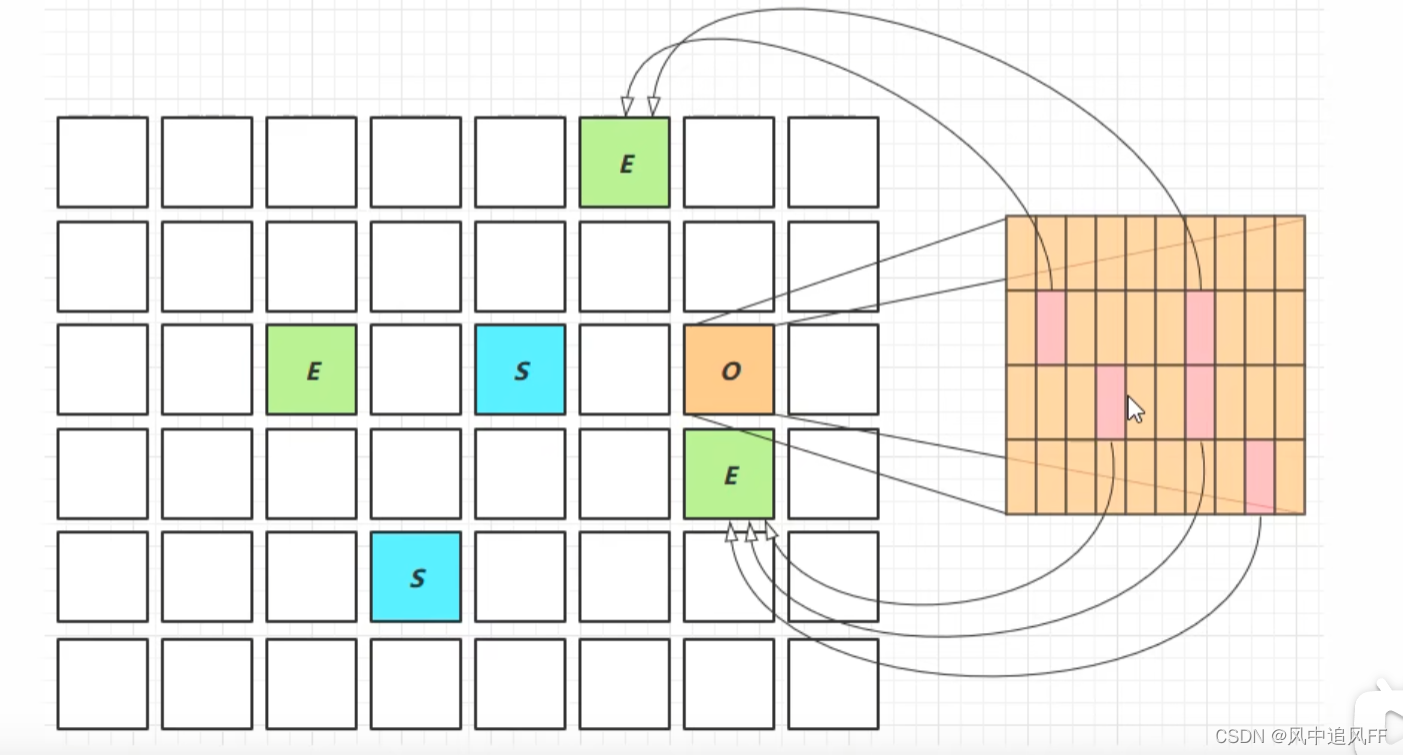
8.5.9 G1的young Collection 中可能发生的跨代引用问题
老年区会再分为card 小区,card里会记录老年代对象引用了哪个新生代对象。在GCRoot查找阶段,有这个映射关系,就会减少时间。
card小区里,如果这个小card区记录了新生代的引用,就称之为脏卡。
将来在新生代里进行垃圾回收时,可以通过Remembered Set ,直接去老年区里的脏卡里回收,减少GCroot时间。
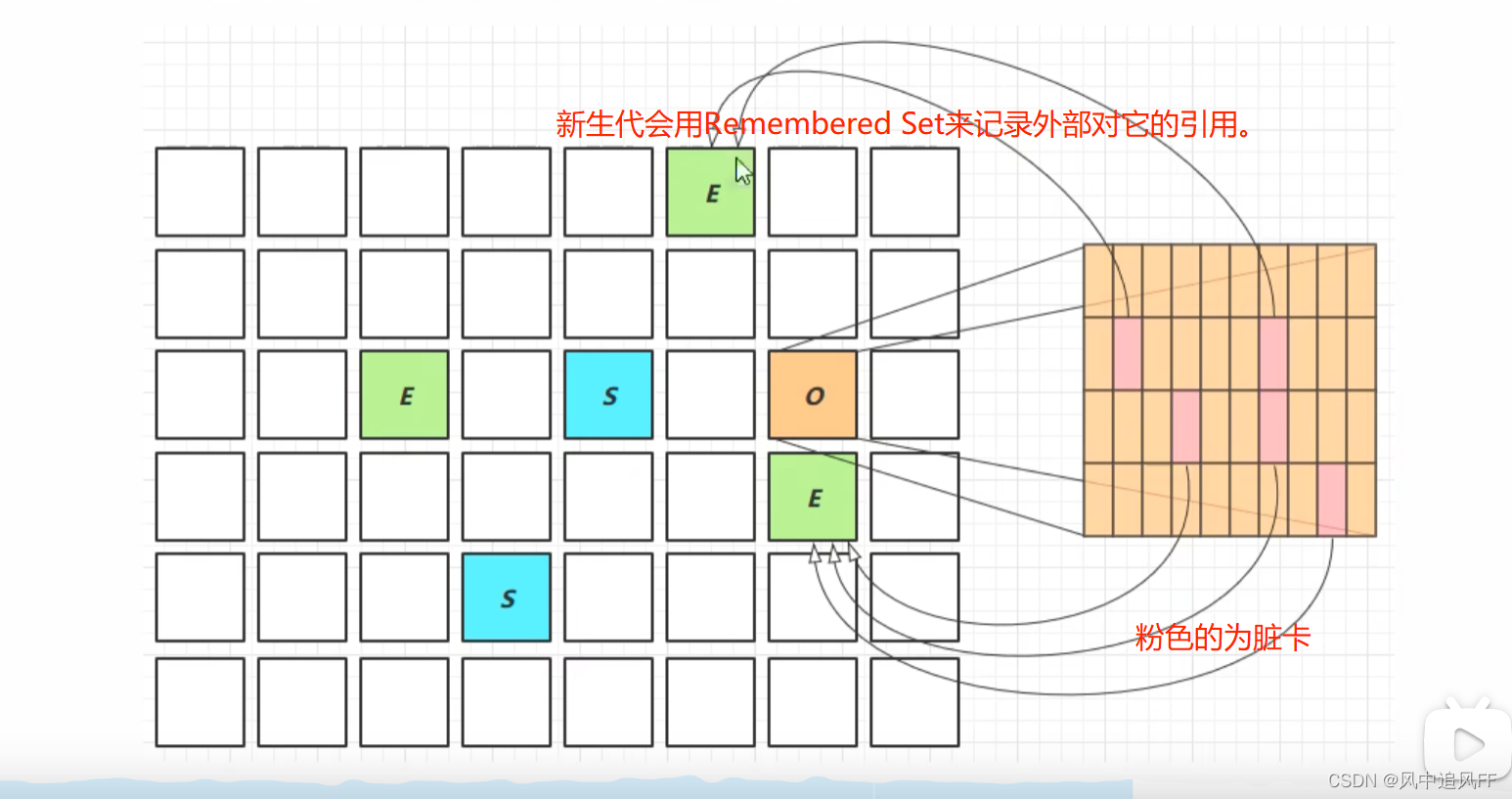
当引用发生变更时,会完成脏卡的更新用过P[ost-Write Barrier,就是自己写的一小段代码,来更新卡区。

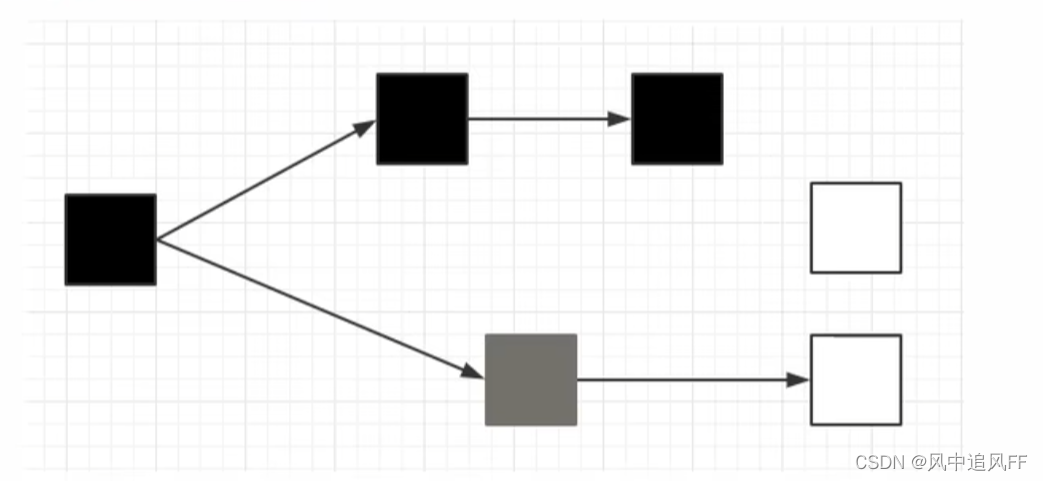
8.5.10 重新标记Remark阶段(G1和CMS)
使用三色标记,已经确定存活的标记成黑色,正在处理中(可能被回收或存活)的标记成灰色,已经处理完的标记成白色。
8.5.11 G1在 JDK 8u20里实现的 字符串去重
intern是看常量池里有没有值一样的字符串,关注的是String对象。
我们这里是看有没有值一样的字符数组,关注的是字符数组。
使用一个参数打开这个字符串去重的开关:-XX:+UserStringDeduplication

8.5.12 G1 在JDK 8u40并发标记类卸载

8.5.13 G1回收巨型对象
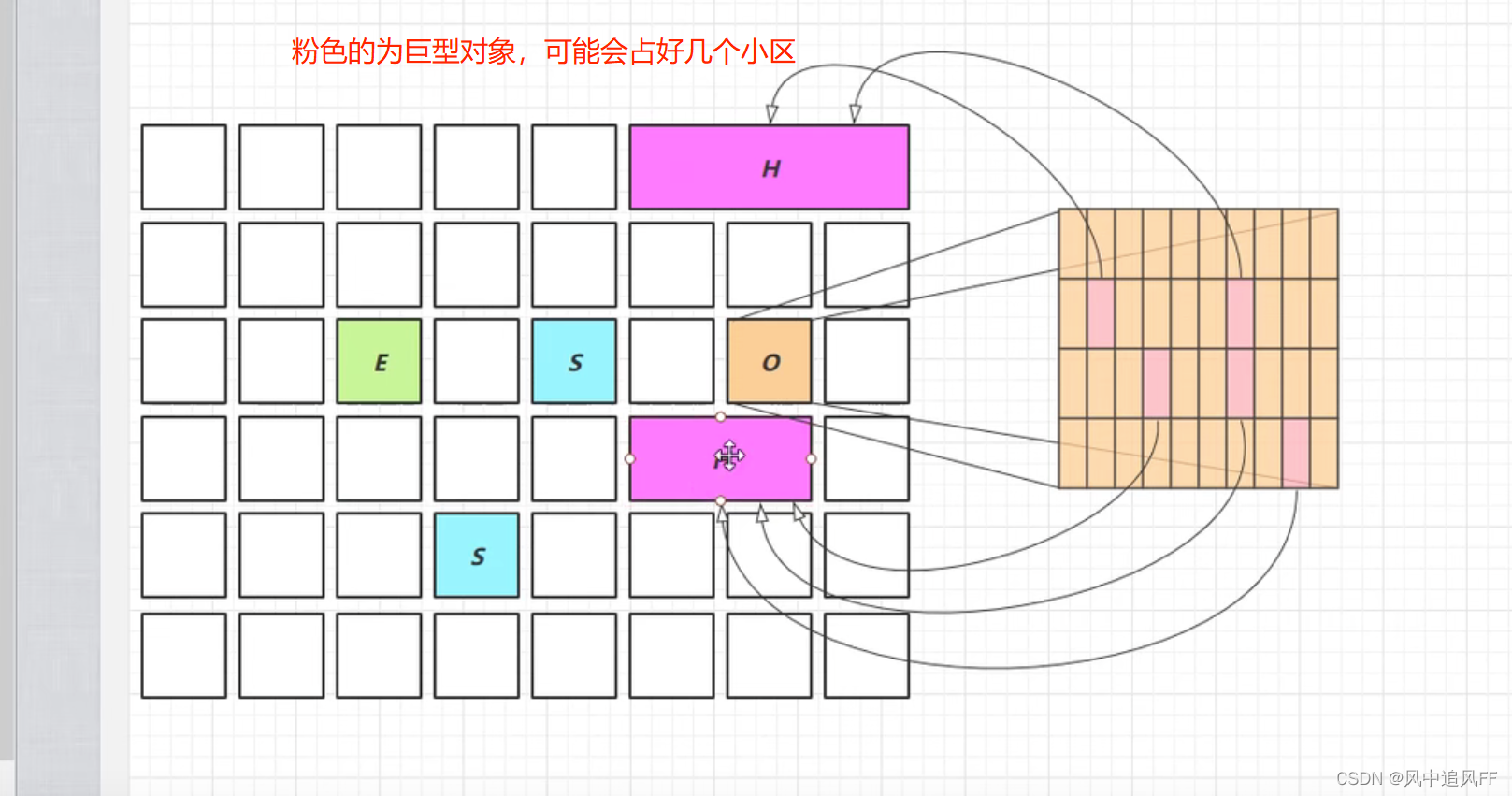
通过卡表查看老年代的incoming引用巨型对象情况。

8.5.14 G1 在JDK 9 中调整并发标记的起始时间
之前:并发标记的发生是有一个内存阈值:老年代占堆内存的比例,默认为45%。

现在JDK9:这个阈值不固定,我们设置的阈值,仅作为一个初始阈值。后面还会动态的调整。

8.5.15 G1在JDK9中的更高效垃圾回收
去看文档
8.6 垃圾回收调优
查看当时,虚拟机的参数设置
"F:\JAVA\JDK8.0\bin\java" -XX:+PrintFlagsFinal -version | findstr "GC"

可以看到这些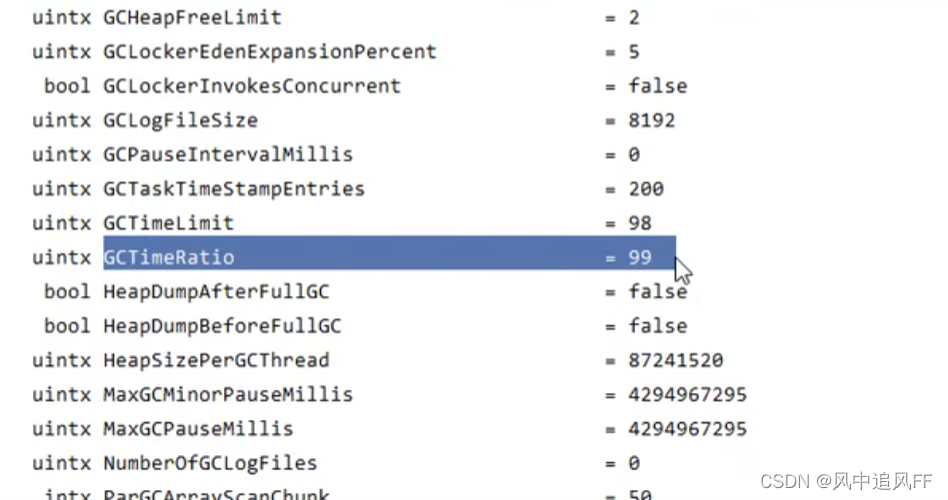
通过需求来决定合适的回收器
CMS,G1,ZGC 适用于高响应,低延迟。
ParallerGC适用于高吞吐量。
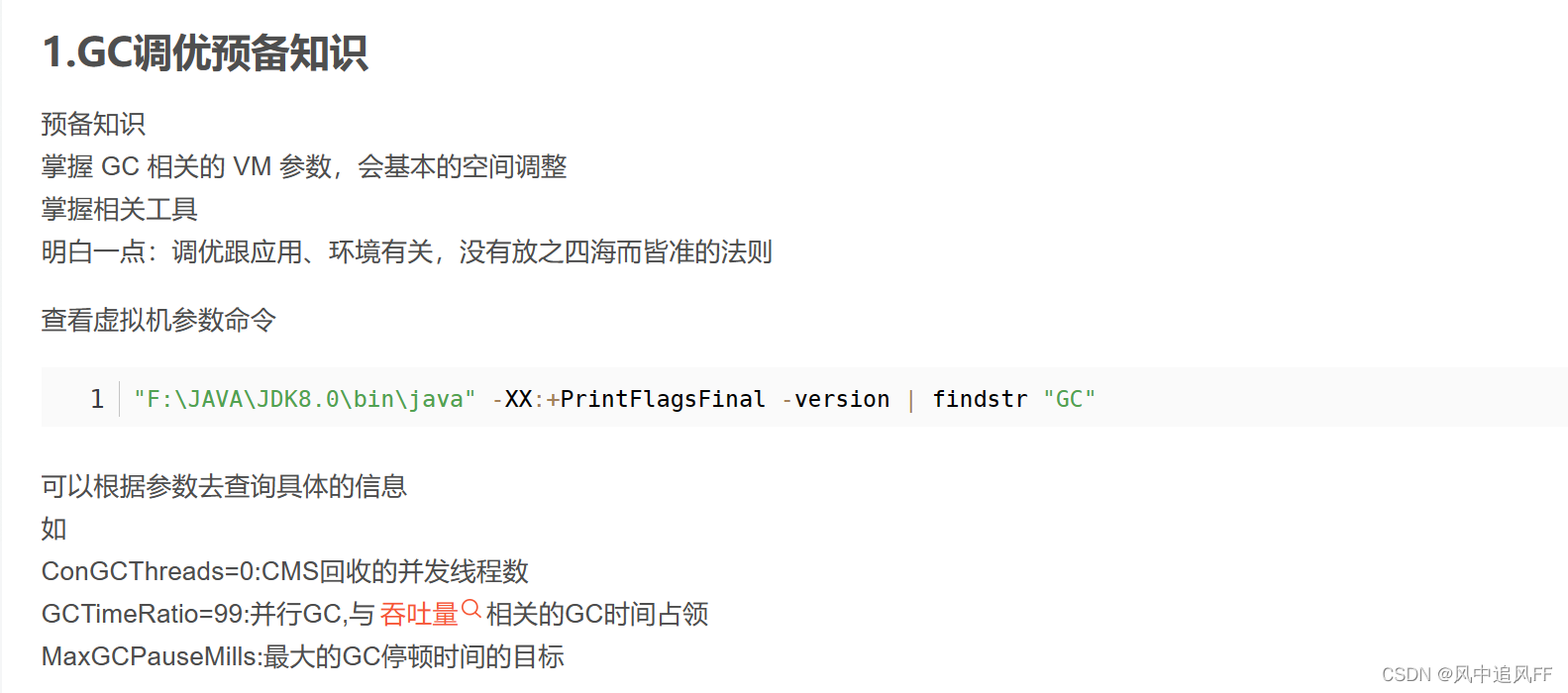



建议新生代占整个堆的 1/4以上和1/2一下。



-XX:MaxTenuringThreshold=threshold
调整最大晋升阈值
-XX:+PrintTenuringDistribution
打印晋升的详细信息,以便判断晋升阈值是否更合适。
Desired survivor size 48286924 bytes, new threshold 10 (max 10)
- age 1: 28992024 bytes, 28992024 total
- - age 2: 1366864 bytes, 30358888 total
- - age 3: 1425912 bytes, 31784800 total ...

9.类加载和字节码技术
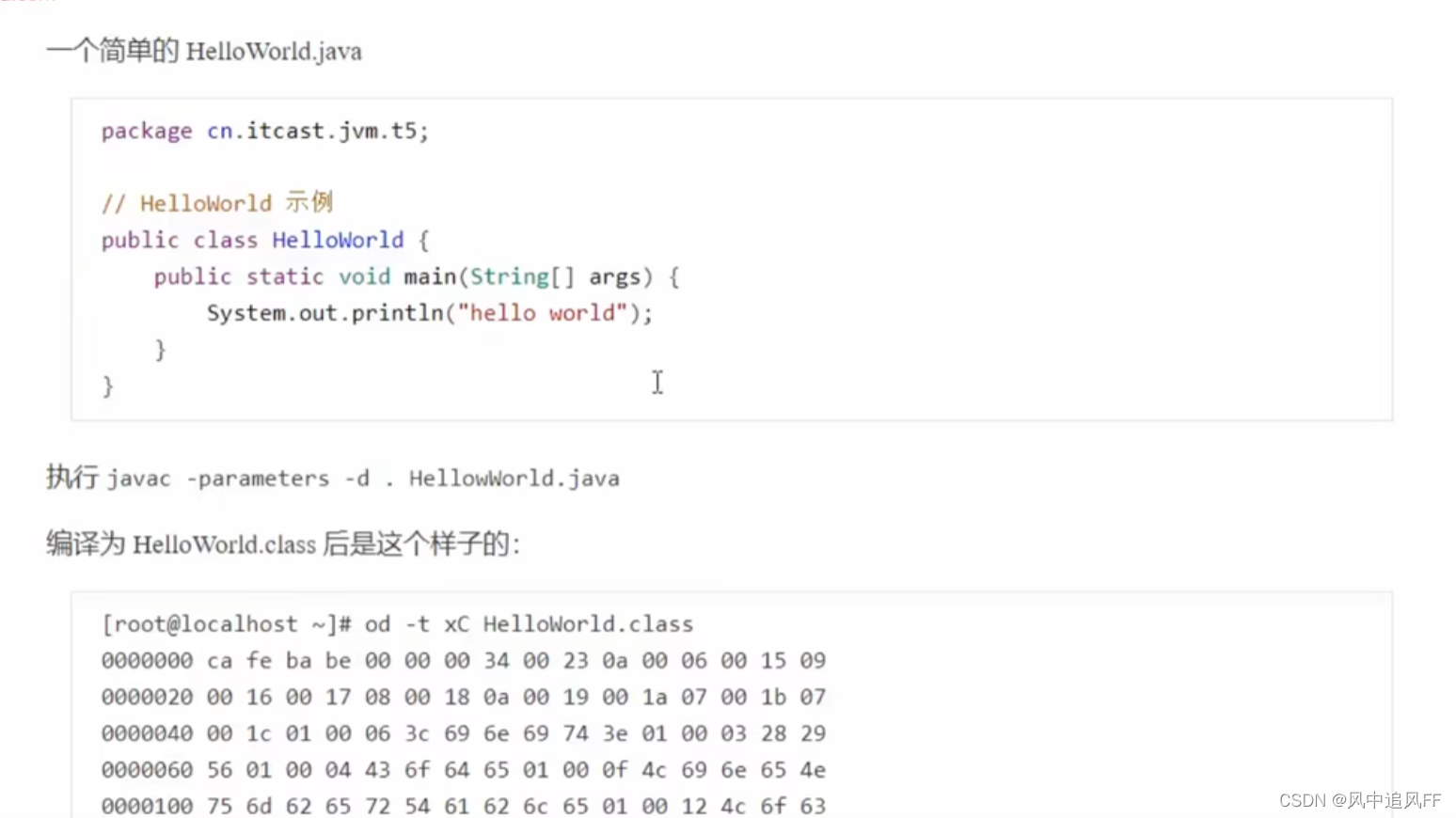
javac 指令编译后的文件如下。
常量池里value的含义。



0a翻译成10进制是10。表明了这是个方法引用。


太繁琐了,感觉面试不会问。
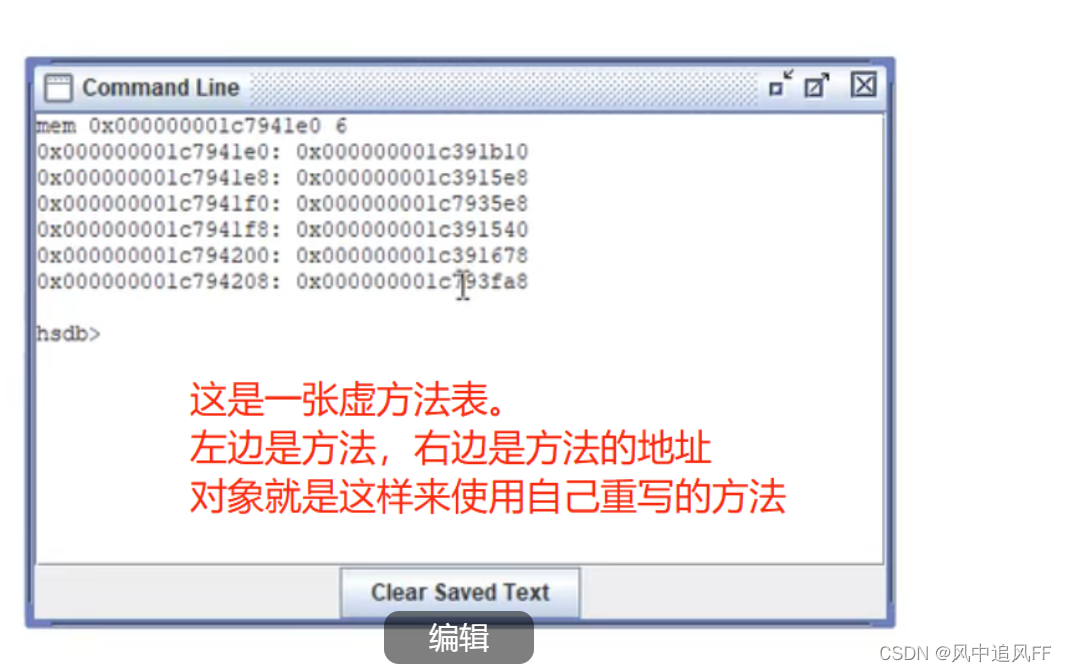
9.1 多态的原理
每个方法都有它的地址,所以不同的多态对象,调用同名的一个方法,调用的是自己的方法(如果自己重写)或父类的。虚方法表的右侧可能记录的还有父类这个方法的地址。

9.2 finally面试题
1.finally里的return会吞异常。本来要抛出异常给上层的,突然返回了。
2.如果在finally里的return之前执行了其它return , 那么最终的返回值是finally中的return

9.3 编译过程(语法糖)
编译之后肯定变成了字节码,写成下面代码的形式是方便理解。
9.3.1 加一个默认构造器

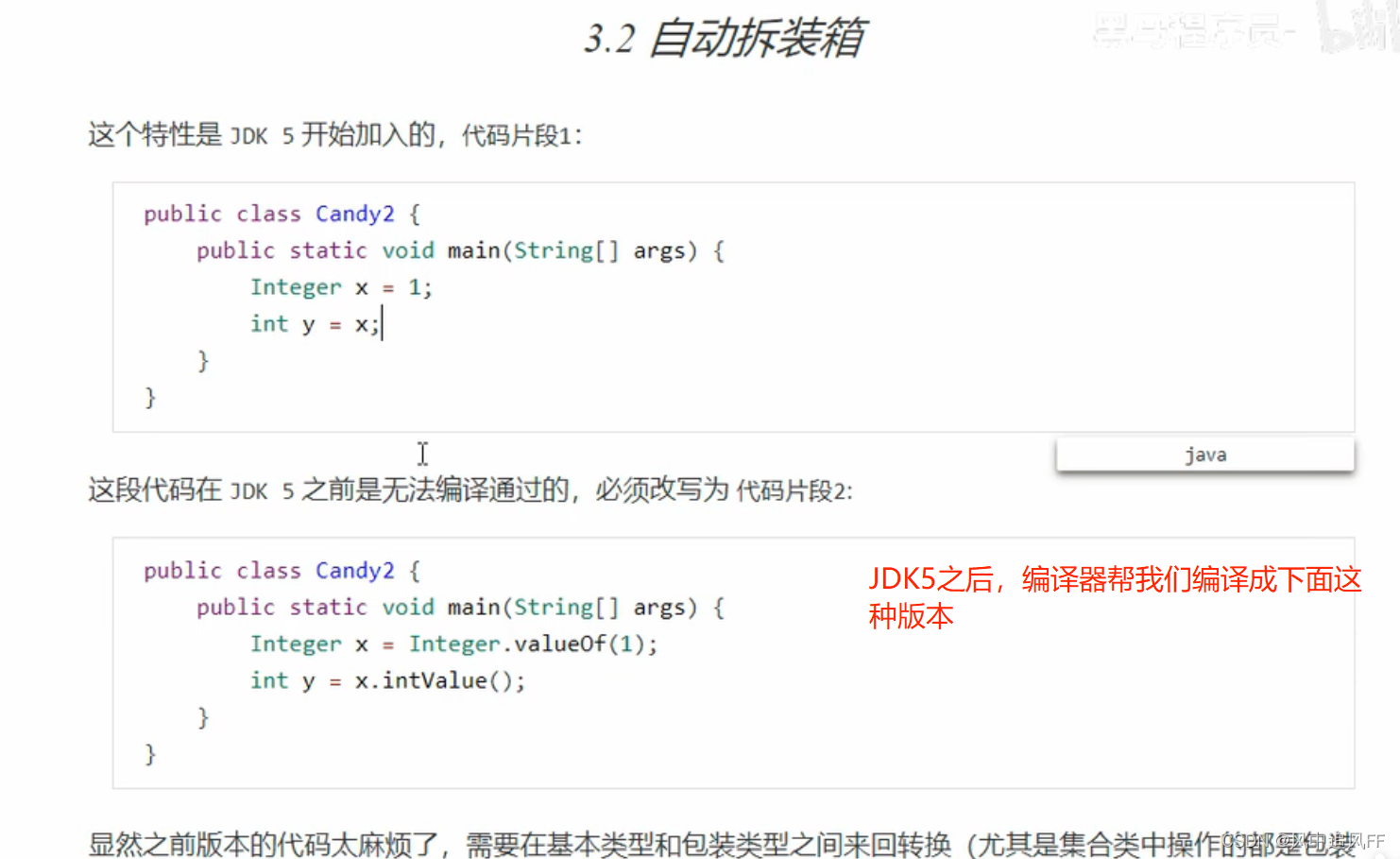
9.3.2 自动拆装箱
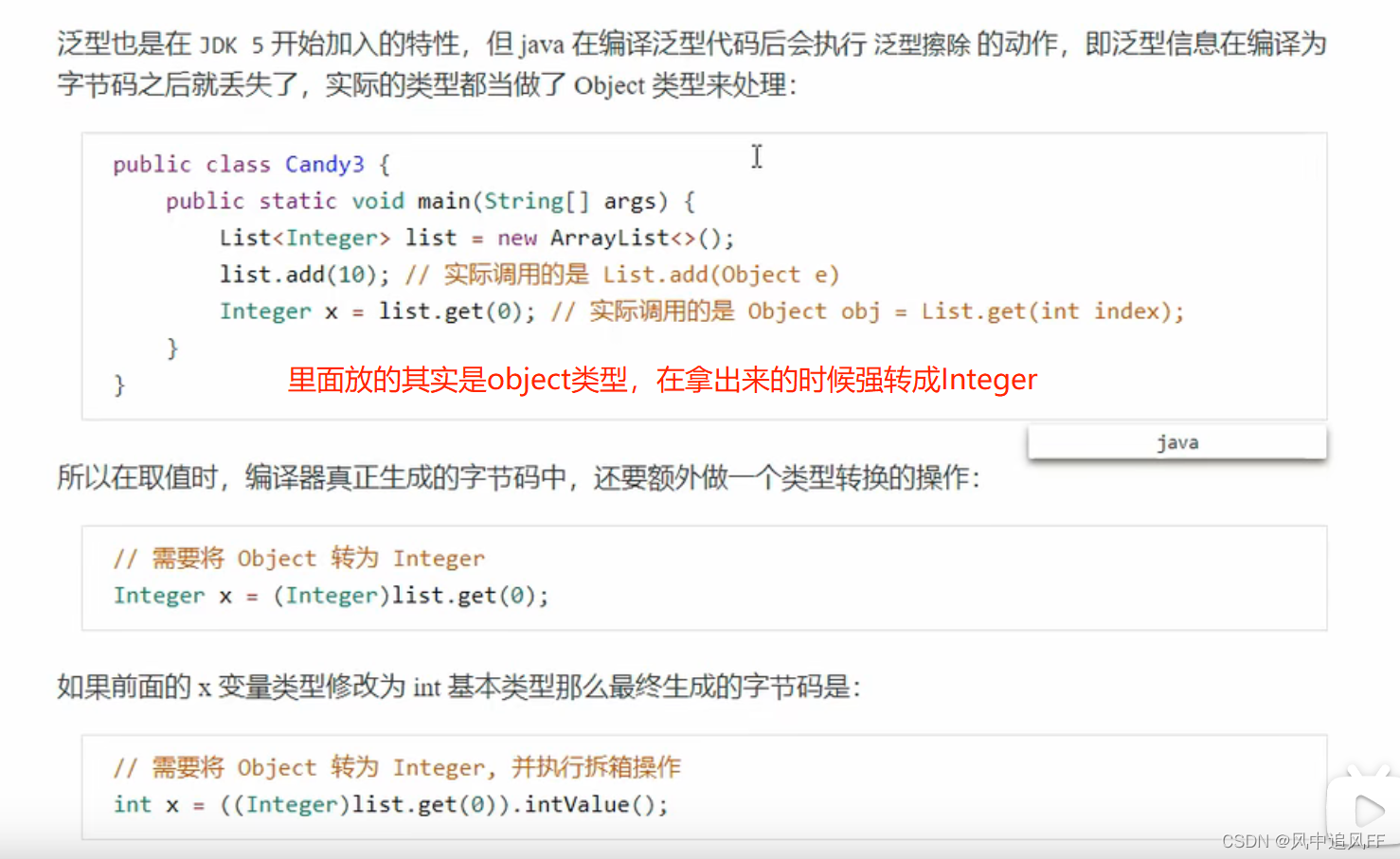
9.3.3 泛型集合取值
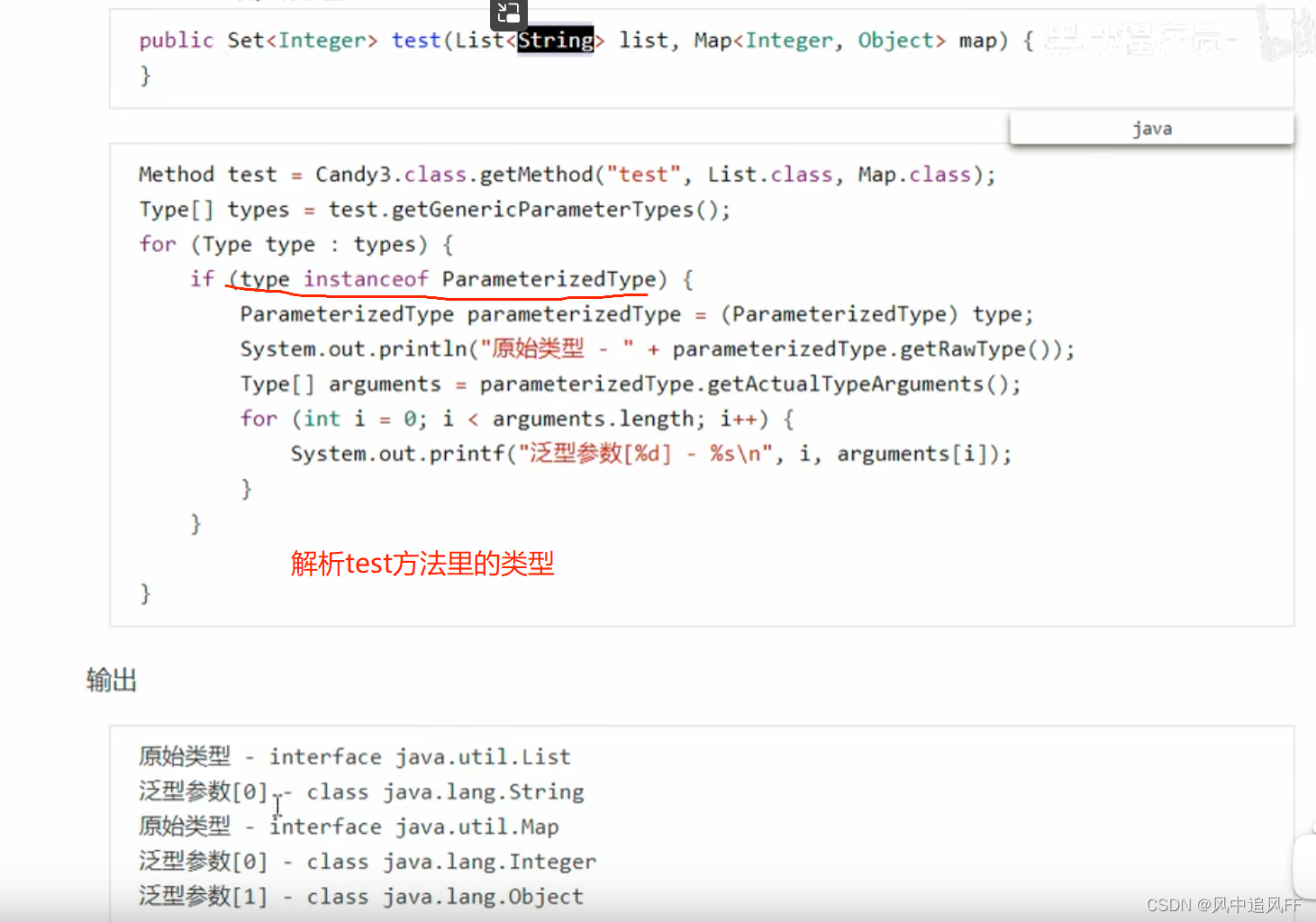
9.3.4 泛型反射
虽然List里放的是object类型,但在一张局部变量类型表中,记录了它承载的泛型是Integer。

可以直接反射解析方法里的类型。
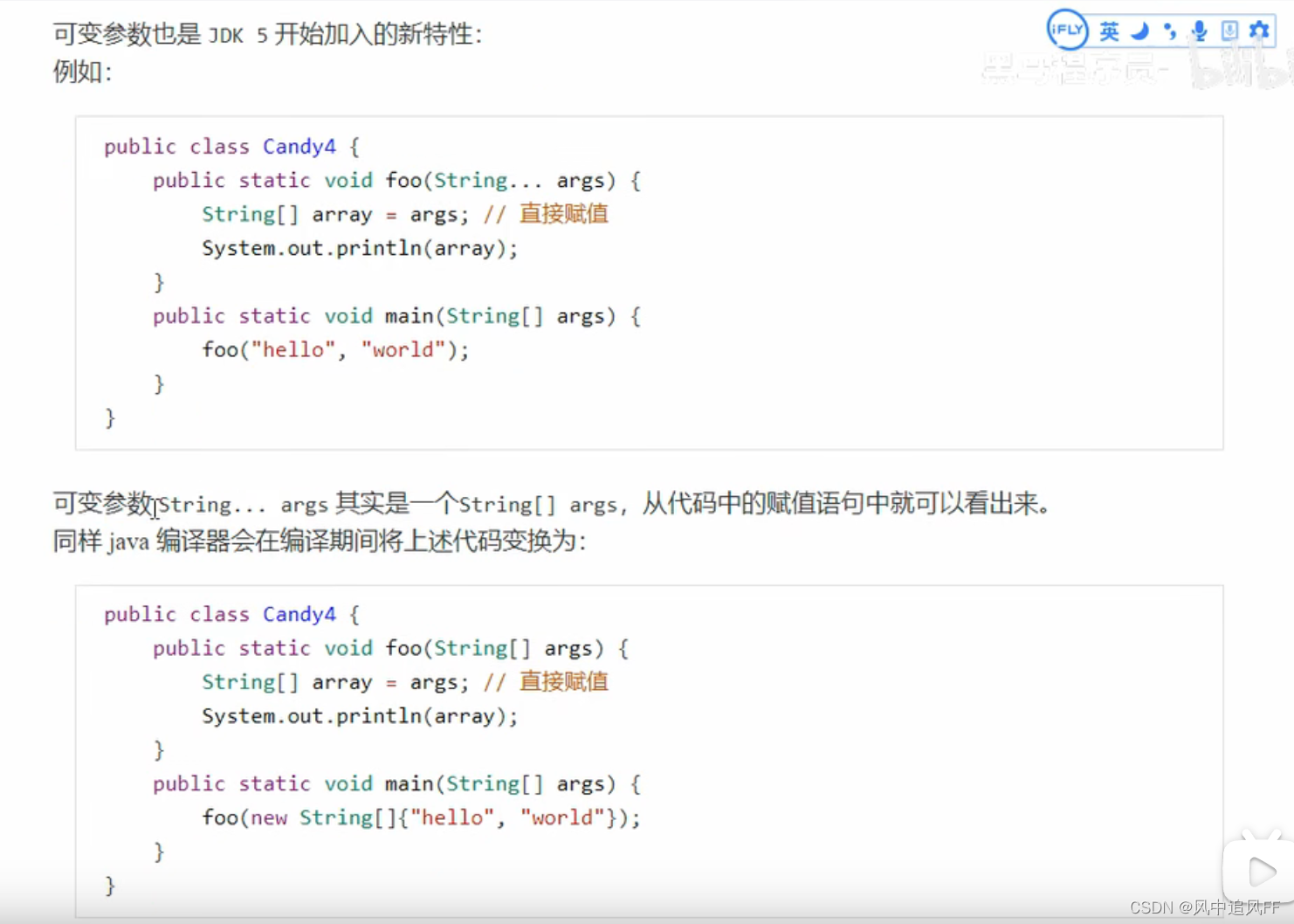
9.3.5 可变参数
9.3.6 forEach循环
数组就是变成了简单的for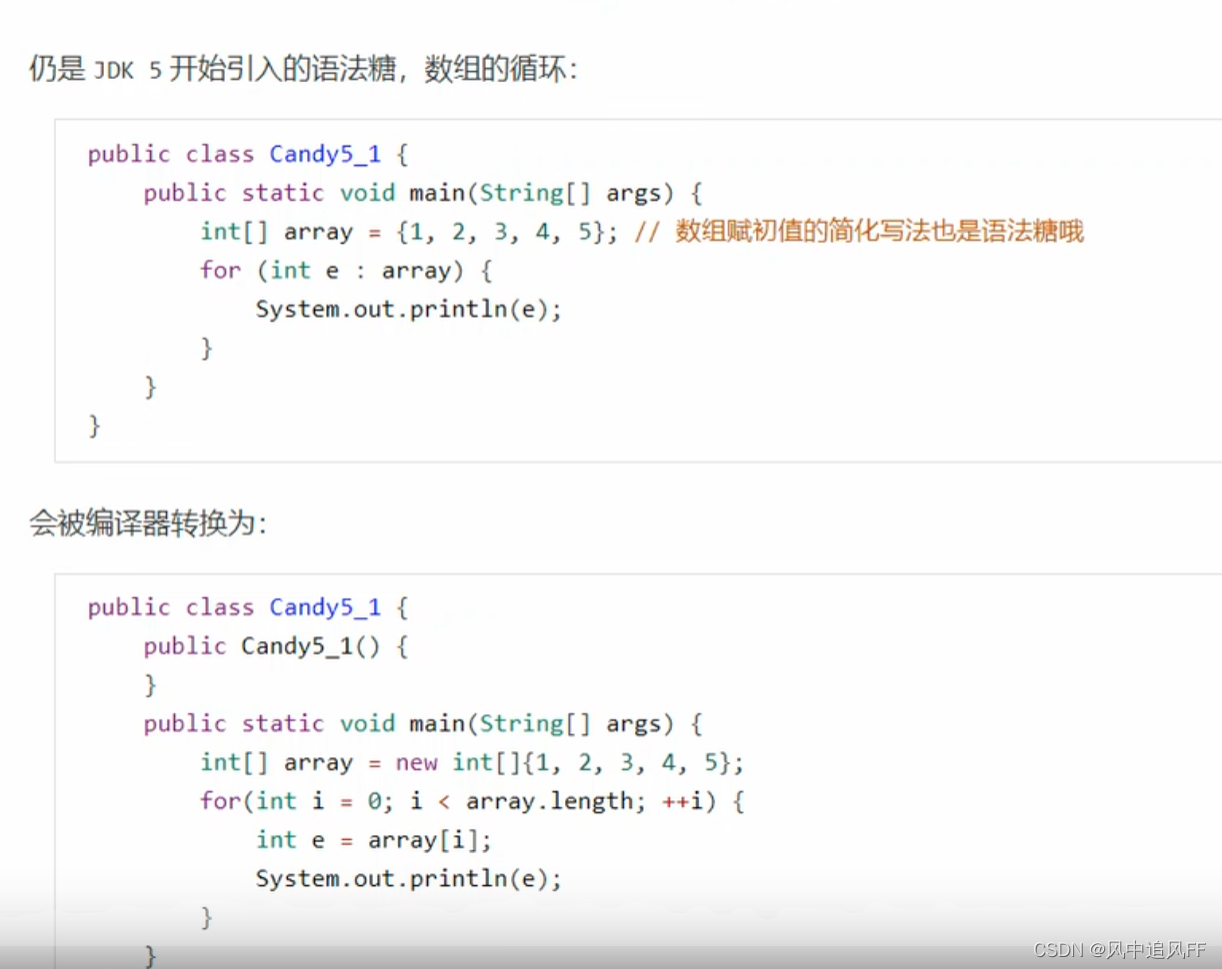
集合则是通过迭代器。
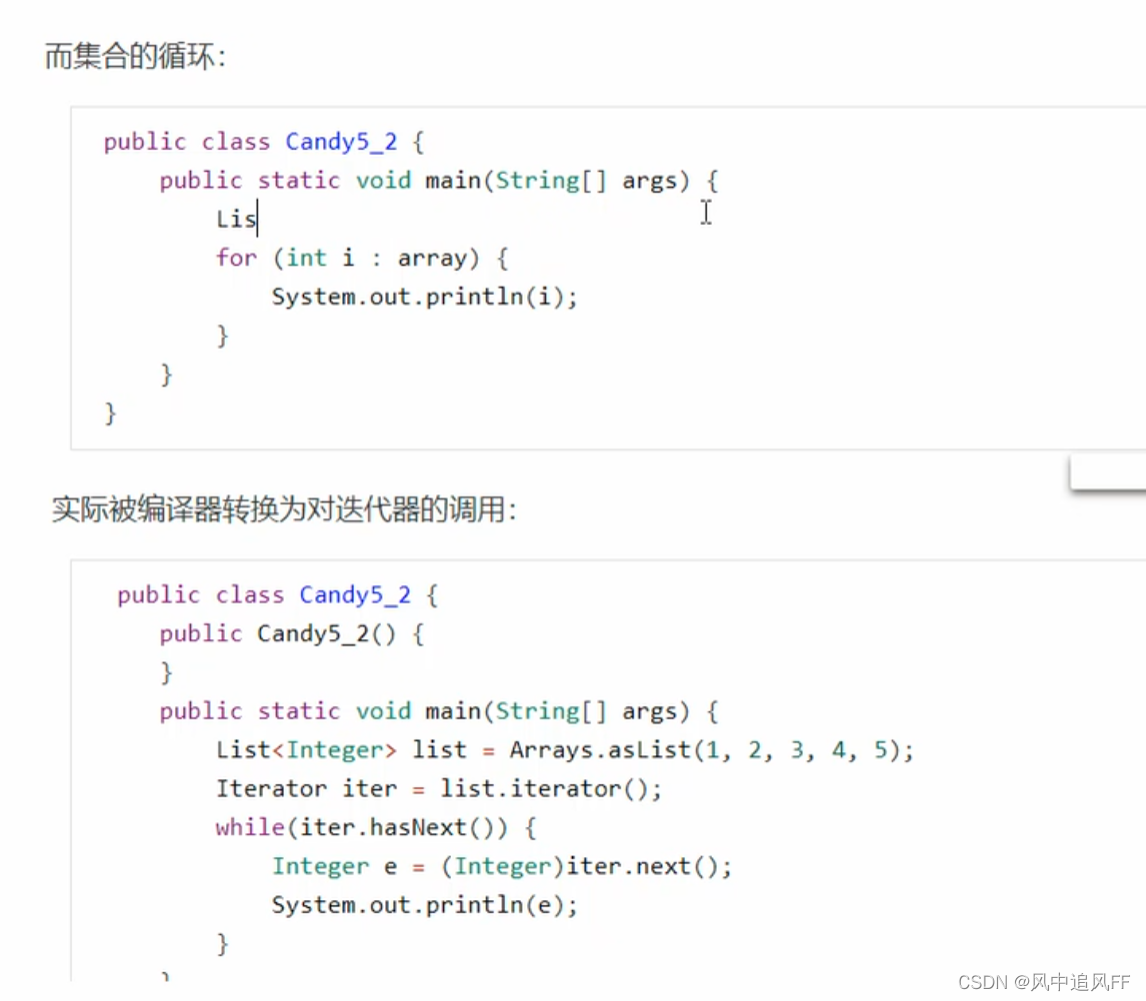
9.3.7 Switch和字符串
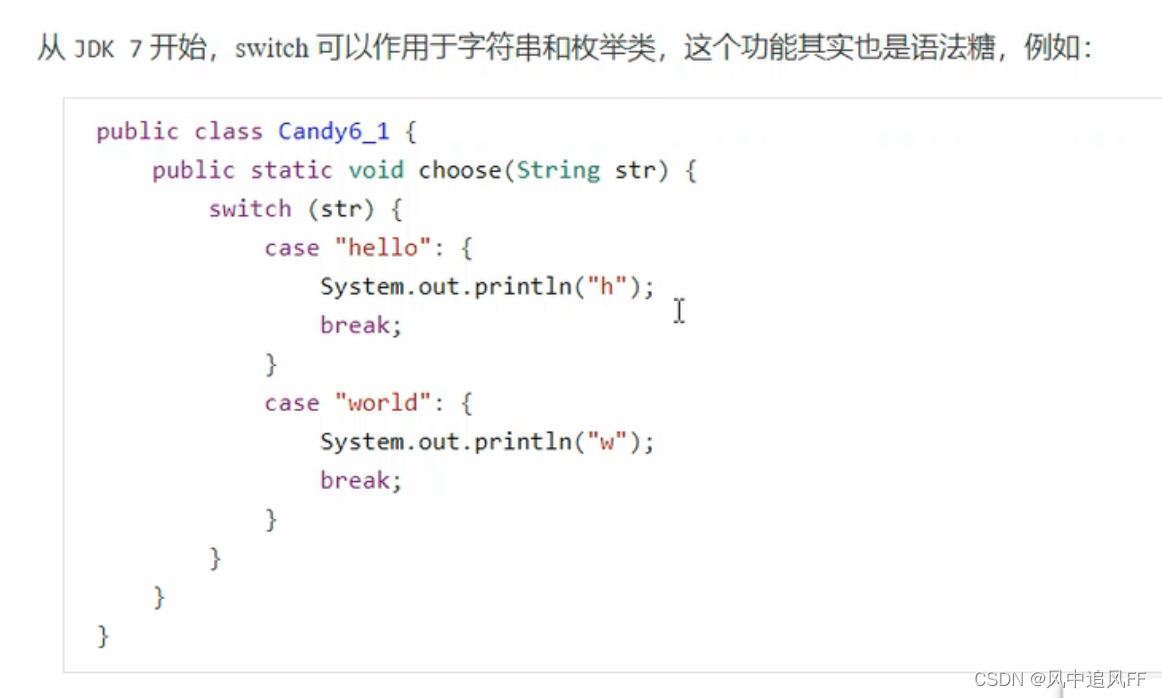
会被编译成如下:就是把字符串中转了一下。让case里永远都是一个字符或一个数字
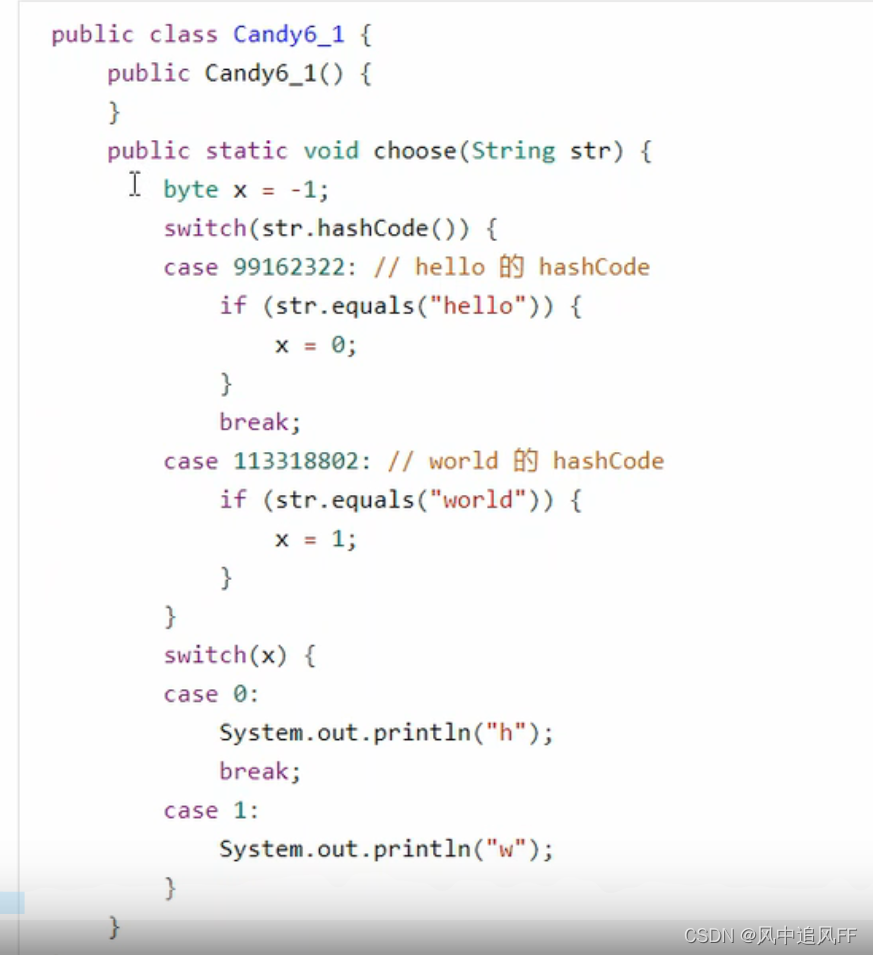
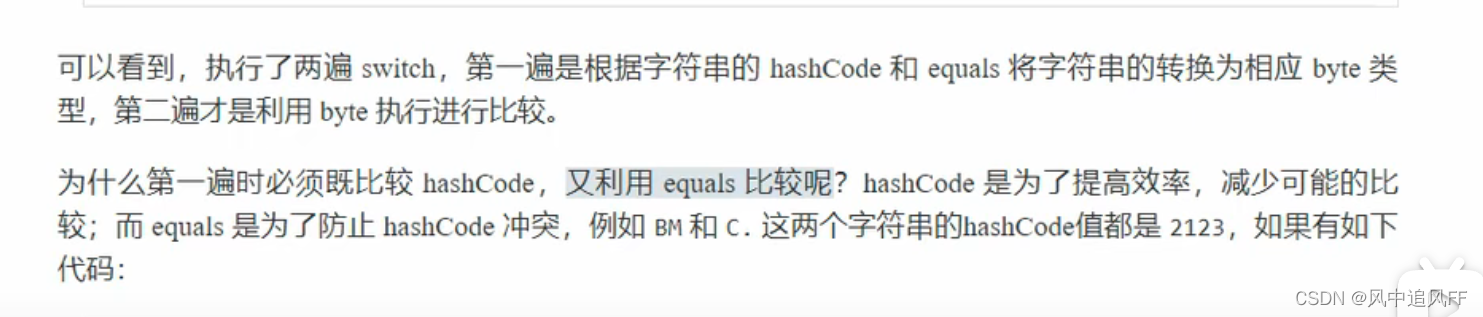
9.3.8 Switch和枚举类

编译器其实就是把MALE,FEMALE属性变成了数字。

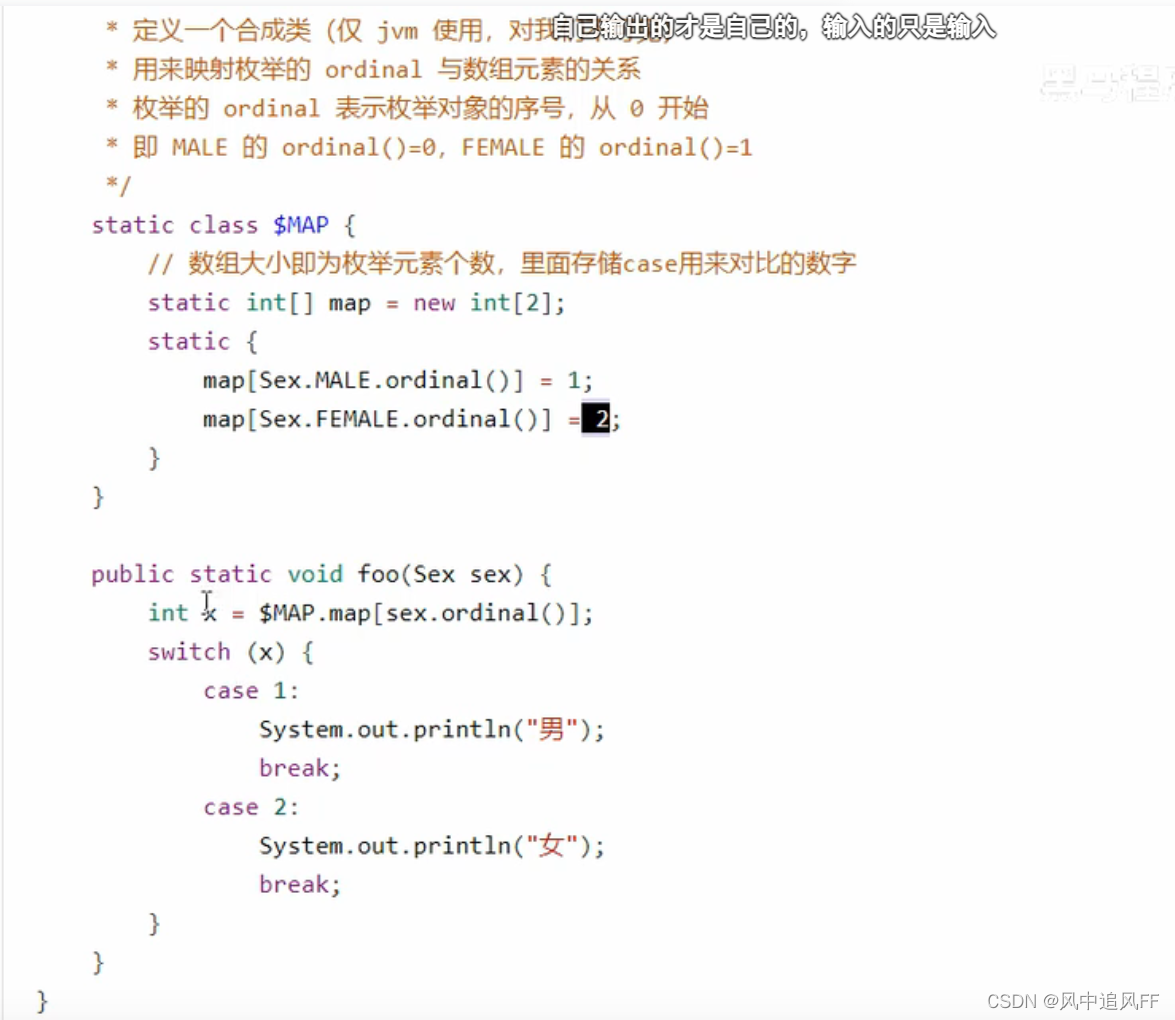
9.3.9 枚举类

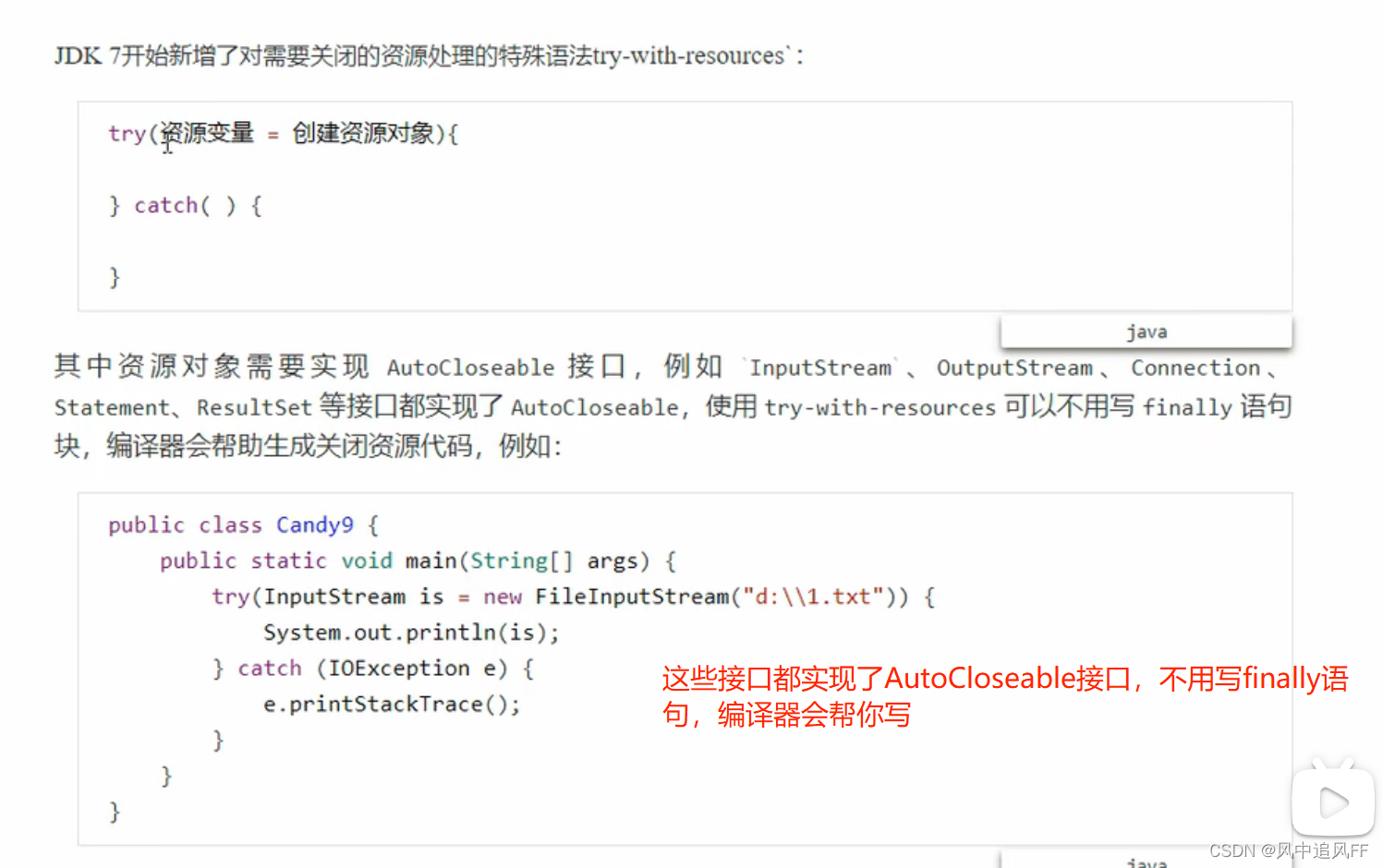
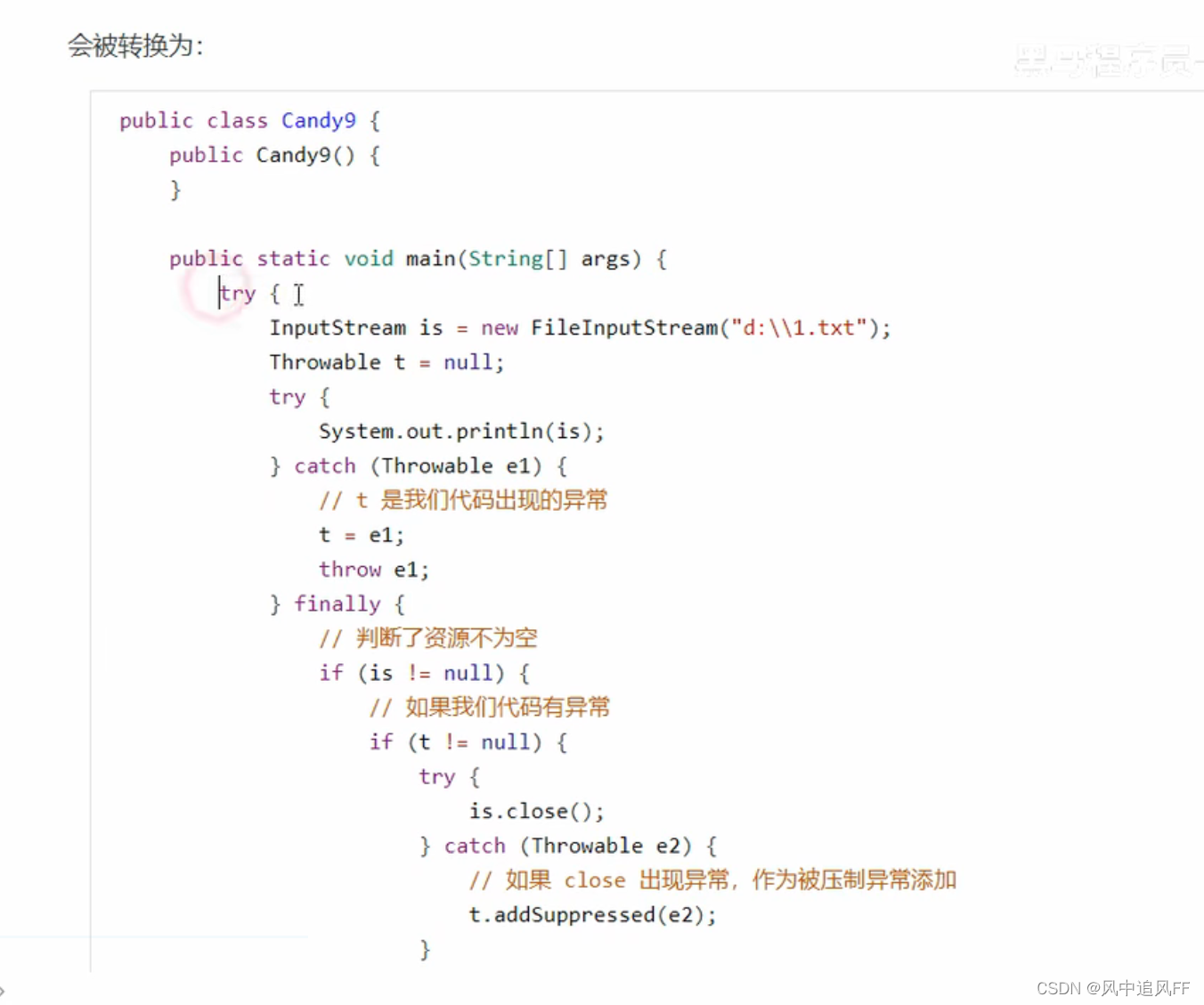
9.3.10 try-with-resource资源对象关闭
编译器帮我们写的finally如下:
9.3.11 方法重写时的桥接
子类重写方法的返回值的类型,可以是父类方法返回值的子类型。
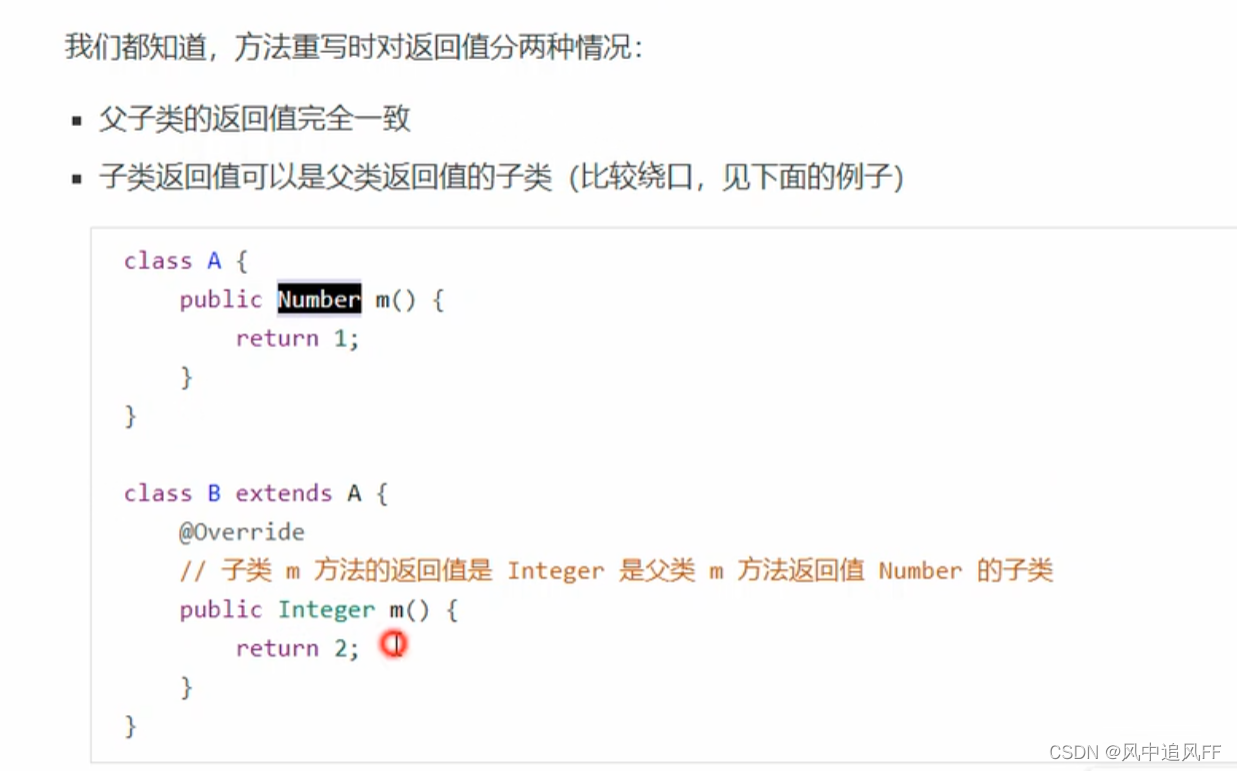
实际上编译器对子类里多写了一个方法。该方法仅对JVM可见,作为桥接手段

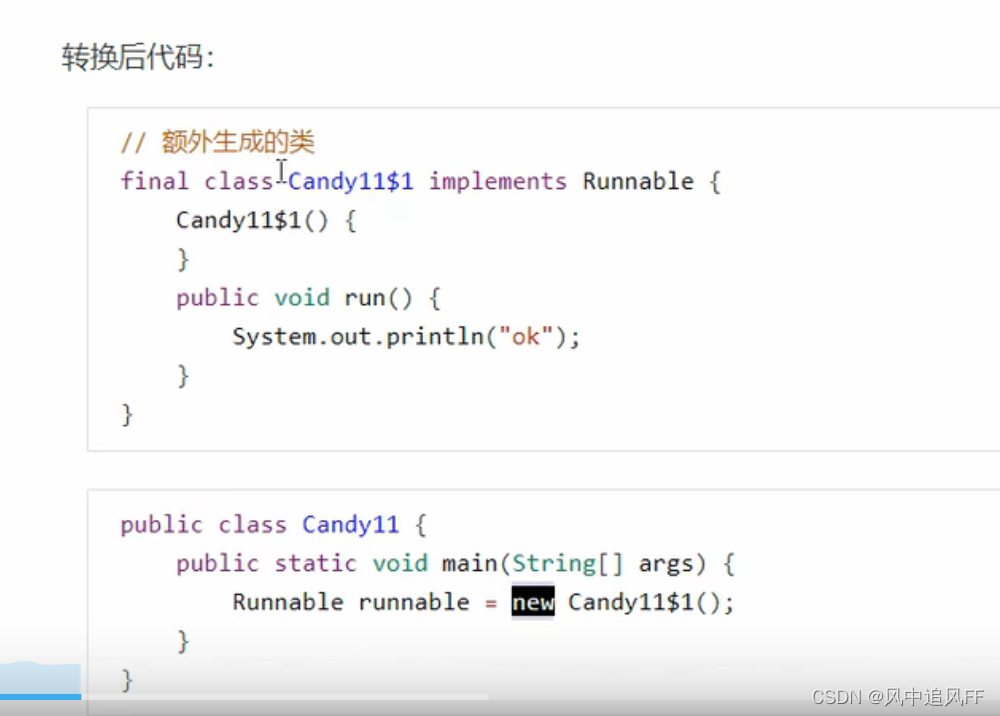
9.3.12 匿名内部类一

这个写法,实际上是编译器,根据里面的内容重建了一个类。
9.3.13 匿名内部类二

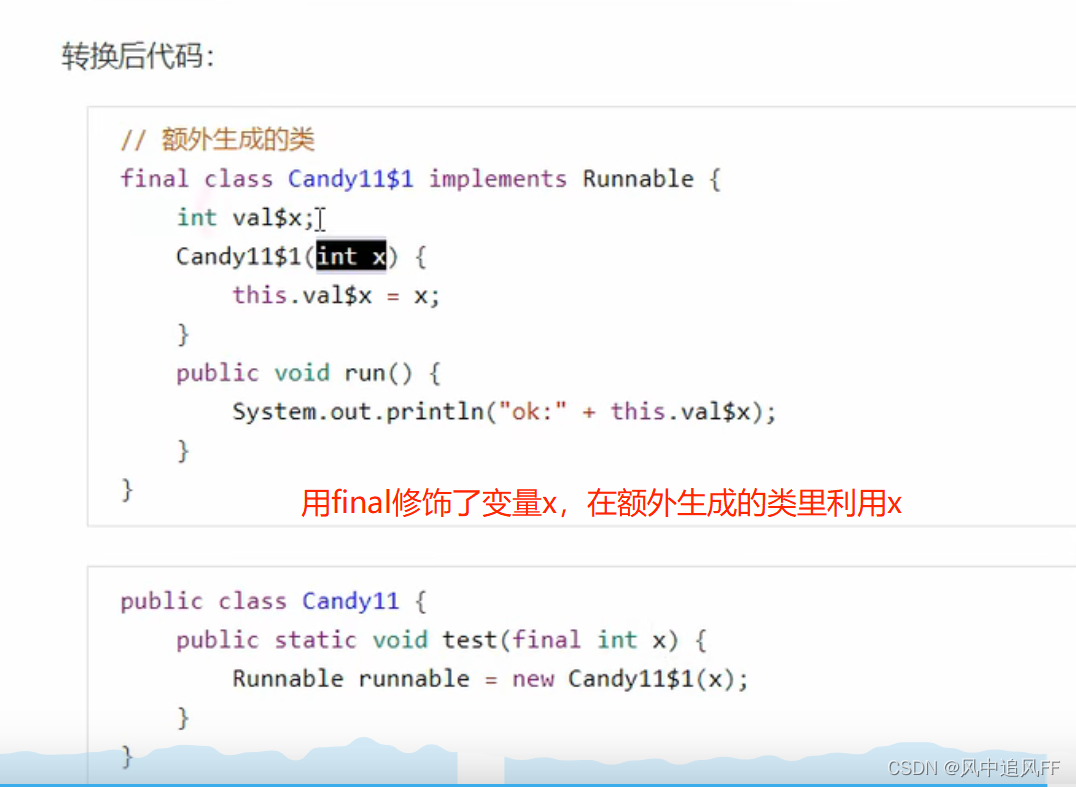
目的就是不让x再变,因为x再变,内部类里不会跟着变。

9.4 类加载

9.4.1 instanceKlass
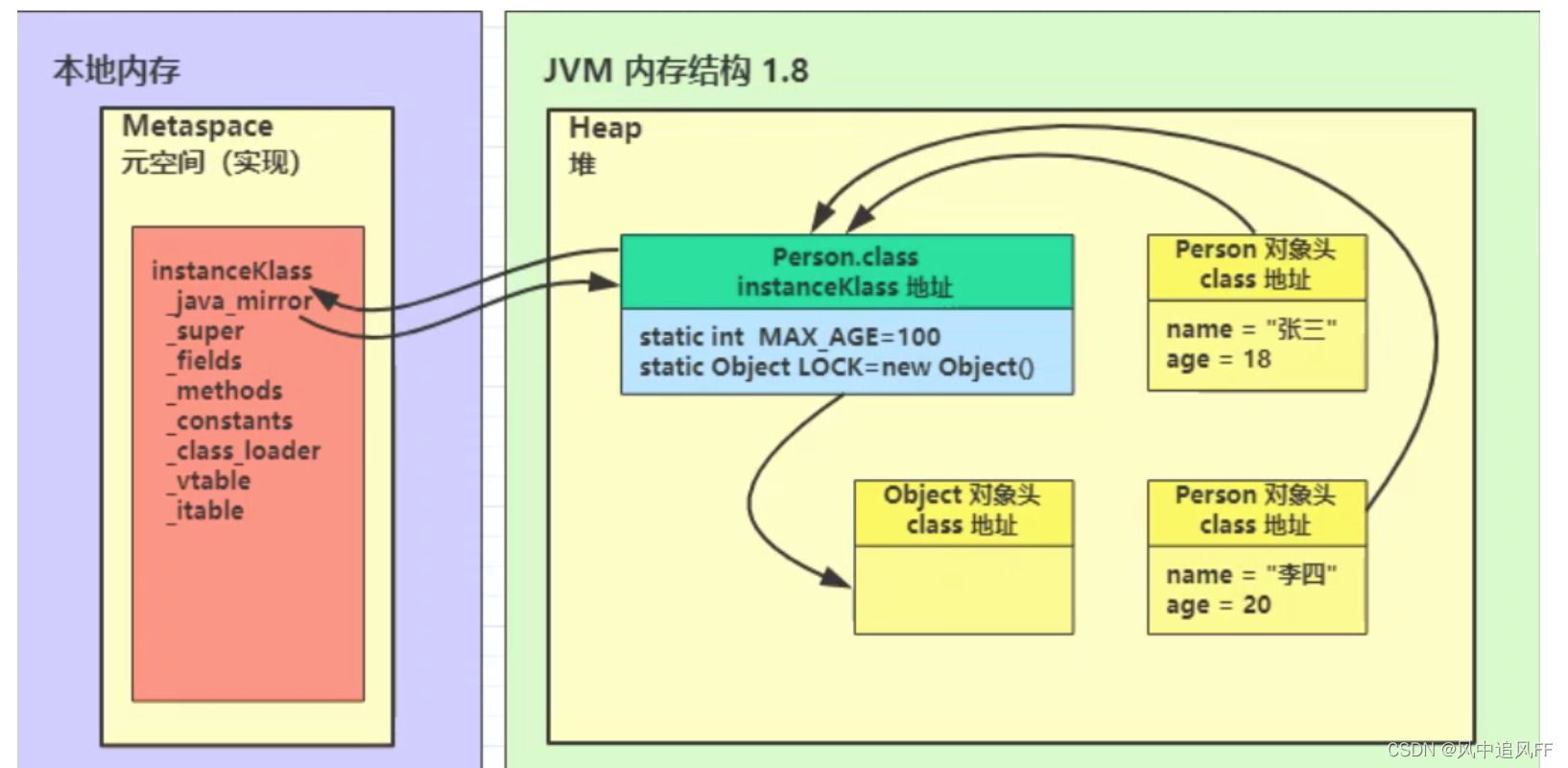
instanceKlass:就是类的字节码在本地内存中的C++描述。
将类的字节码载入方法区(1.8后为元空间,在本地内存中)中,内部采用 C++ 的 instanceKlass 描述 java 类,它的重要 field 有:
- _java_mirror 即 java 的类镜像,例如对 String 来说,它的镜像类就是 String.class,作用是把 klass 暴露给 java 使用
- _super 即父类
- _fields 即成员变量
- _methods 即方法
- _constants 即常量池
- _class_loader 即类加载器
- _vtable 虚方法表
- _itable 接口方法
如果这个类还有父类没有加载,先加载父类,并且加载和链接可能是交替运行的
这个过程,比如Person.class就是堆中的一个类对象,即Person.class就是一个对象。
- Person.class里记录着它对应的instanceKlass的地址,
- 它对应的instanceKlass里的属性_java_mirror记录着Person.class的地址
- 当声明一个Person实例的时候,这个实例有Person.class的地址,找到Person.class,然后找到instanceKlass,来拿自己要用的属性和方法等等......

9.4.2 什么是class对象?
(165条消息) Class.forName()用法详解_mocas_wang的博客-CSDN博客_class.forname
看看这个人的笔记
9.5 类的链接
9.5.1 验证
验证类的书写是否符合JVM规范
9.5.2 准备

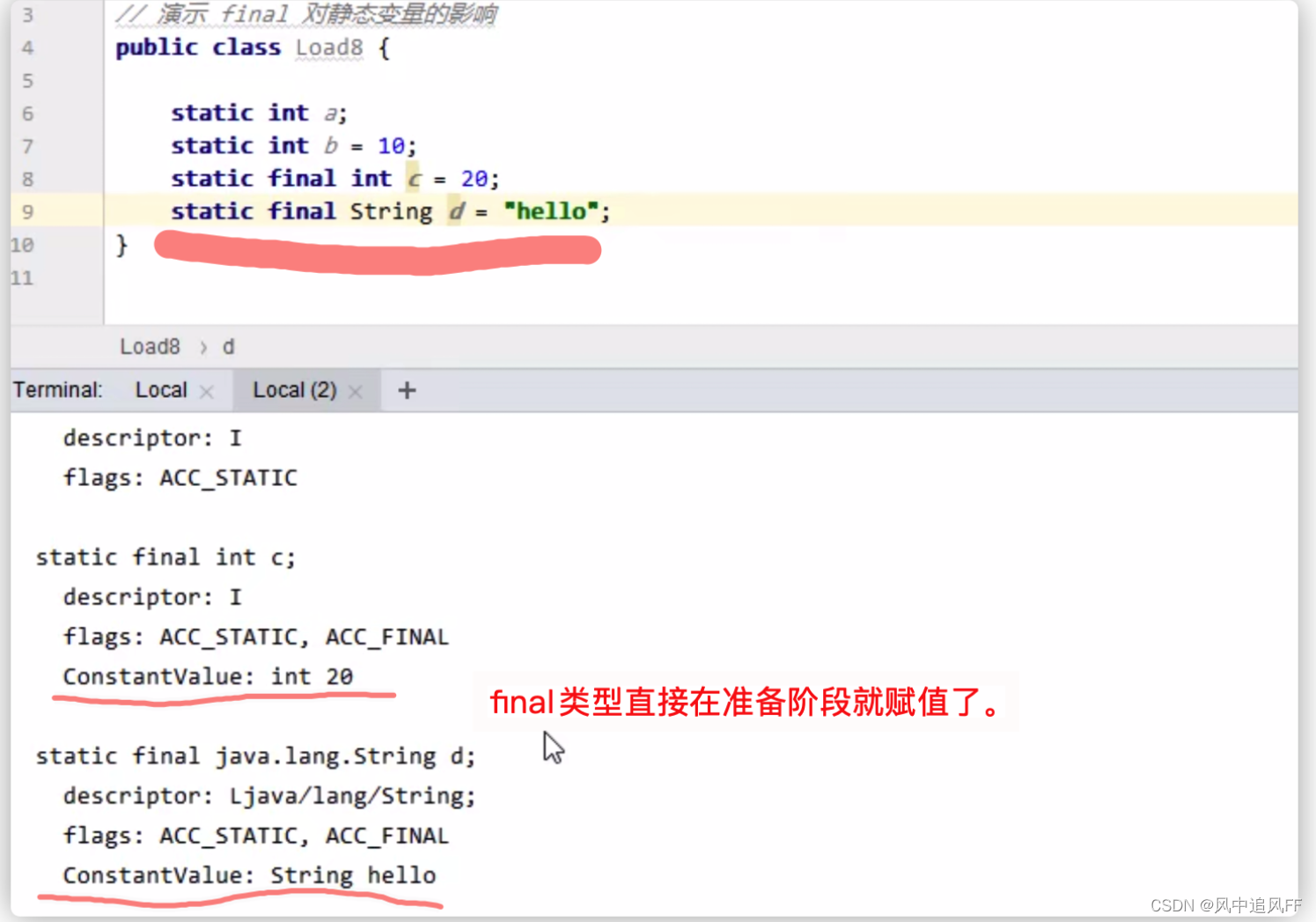
9.5.3 解析
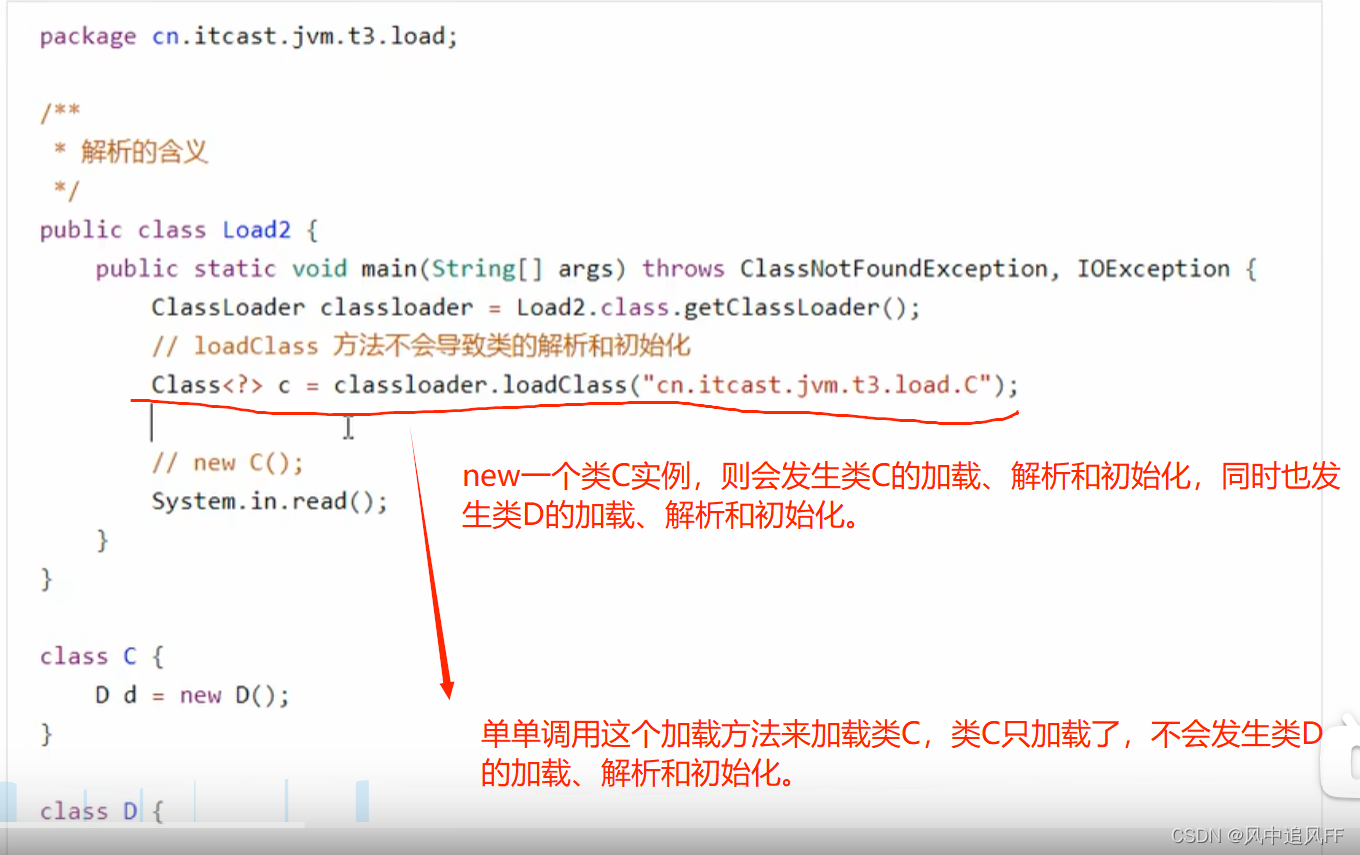
然后我们来看看解析是什么意思。
解析:将常量池里的符号引用解析为直接引用(即实际地址),就知道了那些类或方法或属性的地址。
未解析时:常量池中的看到的对象仅是符号,未真正的存在于内存中。
9.6 初始化



9.6.1 练习
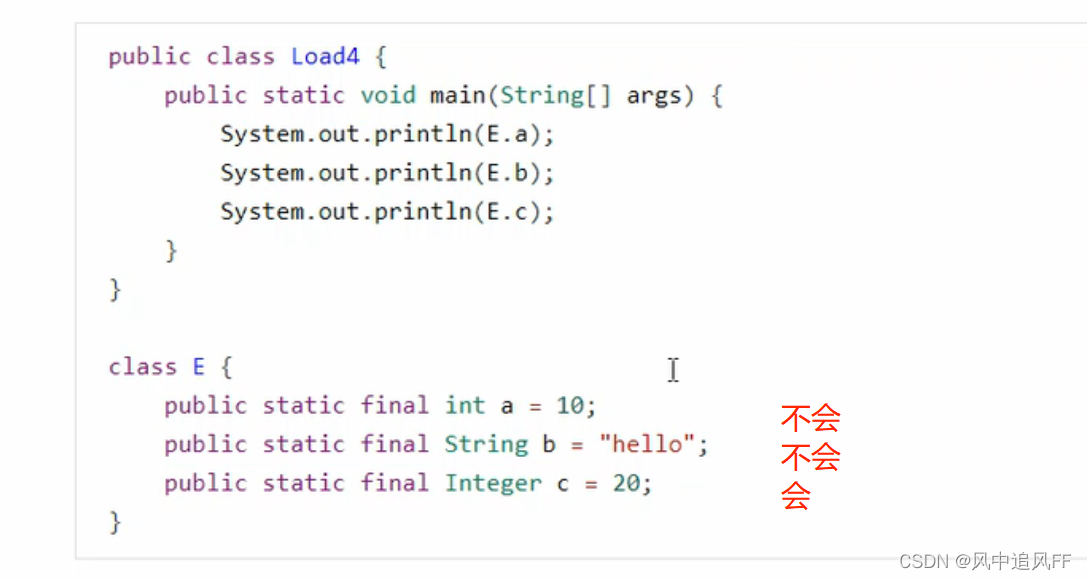
这里的初始化不会有线程安全问题。
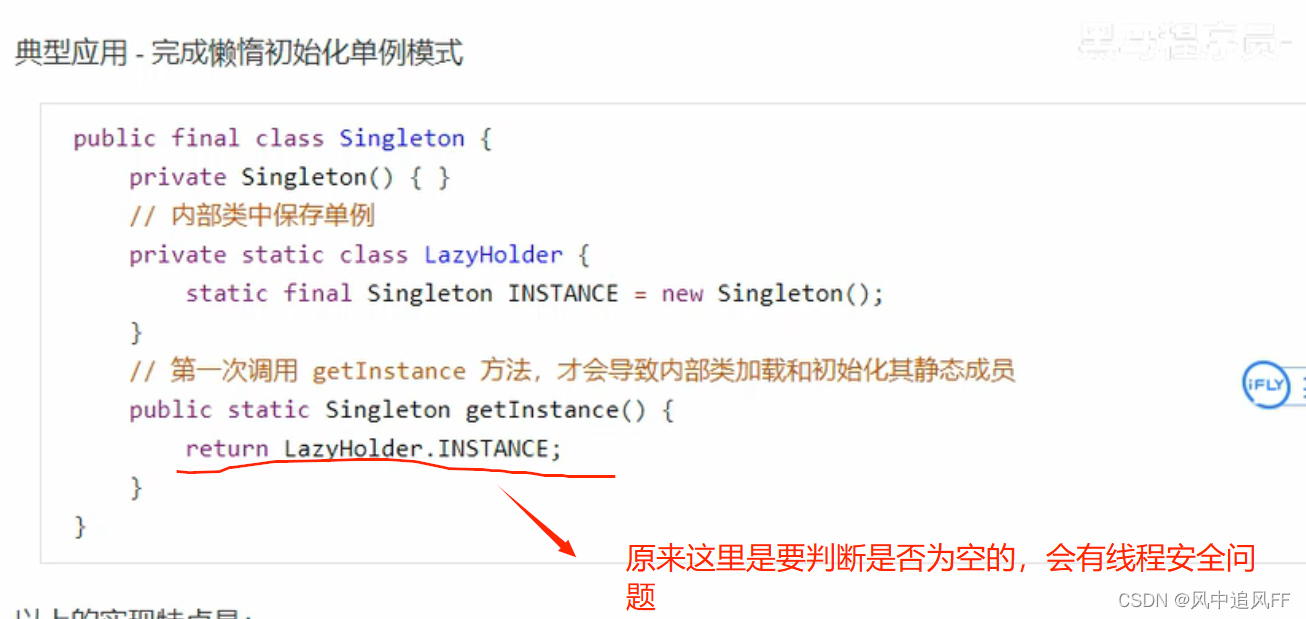
9.7 类加载器
比如定义一个student类,首先问问Extension加载器有没有加载过这个类,如果加载过,那就不加载了;如果没有加载过,接着问它的上一层Booststrap加载器,看看它有没有加载过,如果Booststrap加载器也没加载,那就由Application 加载器来加载。如果Booststrap加载器加载器加载了,那就加载了。自底向上访问是否加载。
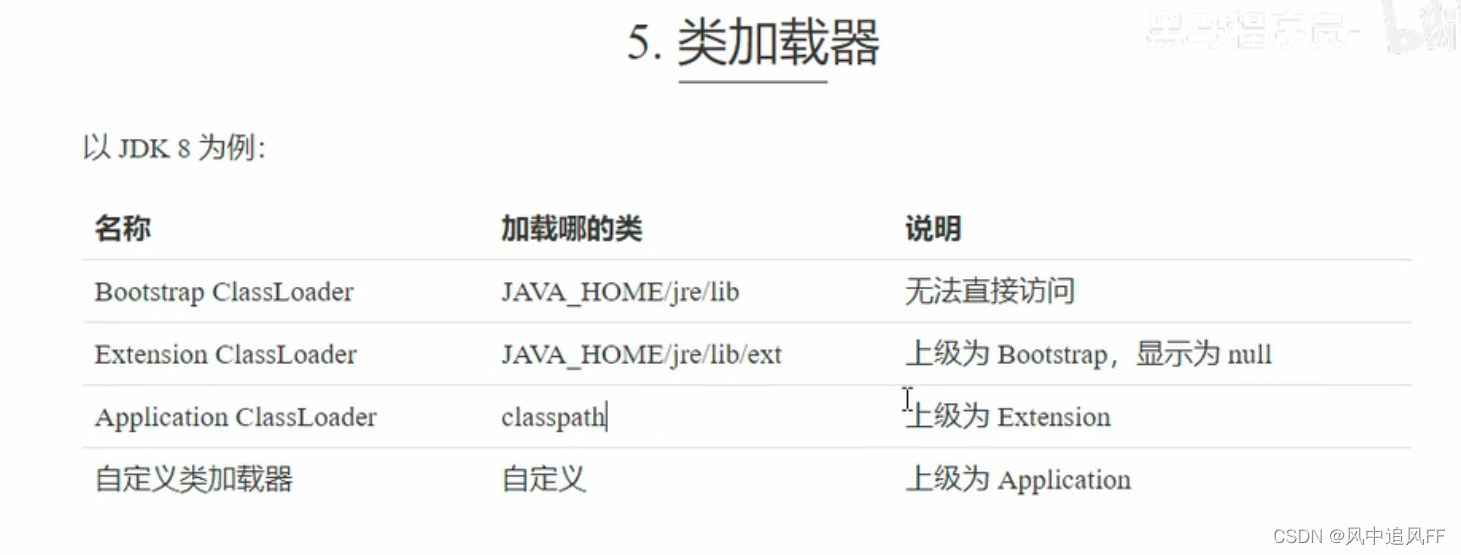
Bootstrap加载器来getParent,无法直接访问,因为它是由C++代码写的。
- 类加载器的作用:通过一个类的全限定名来获取描述此类的二进制字节流,并将此类相关信息加载到JVM的方法区,并创建一个 java.lang.Class 对象作为此类的访问接口, class 对象的引用也保存在方法区内。
- 每一个类加载器都有独立的类名称空间。比较两个类是否相等的前提是两个类是由同一个类加载器加载的,否则两个类比不相等。从JVM角度来讲,只有两种类加载器:启动类加载器、其他的类加载器。因为前者是JVM虚拟机的一部分,后者是独立于JVM实现的。
9.7.1 类加载的过程
-
根据JVM内存配置要求,为JVM申请特定大小的内存空间;
JVM启动时按照其配置要求,申请一块内存,并根据JVM规范和实现将内存划分为几个区域。class二进制文件信息被放入“方法区”,对象实例被放入“java堆”等
-
创建一个引导类加载器实例,初步加载系统类到内存方法区区域中;
JVM申请好内存空间后,JVM会创建一个引导类加载器(Bootstrap Classloader)实例,引导类加载器是使用C++语言实现的,负责加载JVM虚拟机运行时所需的基本系统级别的类,如java.lang.String, java.lang.Object等等。
引导类加载器(Bootstrap Classloader)会读取{JRE_HOME}/lib下的jar包和配置,然后将这些系统类加载到方法区内。 -
创建JVM 启动器实例
Launcher,并取得类加载器ClassLoader;此时,JVM虚拟机调用已经加载在方法区的类
sun.misc.Launcher的静态方法getLauncher(), 获取sun.misc.Launcher实例 -
使用上述获取的 ClassLoader 实例加载我们定义的类;
通过 launcher.getClassLoader() 方法返回 AppClassLoader 实例,接着就是 AppClassLoader 加载 我们自定义类.
加载自己写的类之前先要加载我们写的类中用到的其他类。在 org.luanlouis.jvm.load.Main 类被编译成的class文件中有一个叫常量池(Constant Pool)的结构体,通过这个常量池中的 CONSTANT_CLASS_INFO 常量判断该class用到了哪些类,并通过类加载器去加载这些类。
-
加载完成时候JVM会执行Main类的main方法入口,执行Main类的main方法;
-
结束,java程序运行结束,JVM销毁
9.7.2 启动类加载器(引导类加载器 BootStrap ClassLoader)
启动类加载器是使用C++语言实现的(HotSpot),负责加载JVM虚拟机运行时所需的基本系统级别的类,如java.lang.String, java.lang.Object等等。
启动类加载器(Bootstrap Classloader)会读取 {JRE_HOME}/lib 下的jar包(如 rt.jar)和配置,然后将这些系统类加载到方法区内。
由于类加载器是使用平台相关的底层C/C++语言实现的, 所以该加载器不能被Java代码访问到。但是,我们可以查询某个类是否被引导类加载器加载过
Class.forName既可以完成类的加载,也可以顺便完成类的链接和初始化操作。
那我们要怎么样才能知道这个类是由哪个类加载器加载的呢?
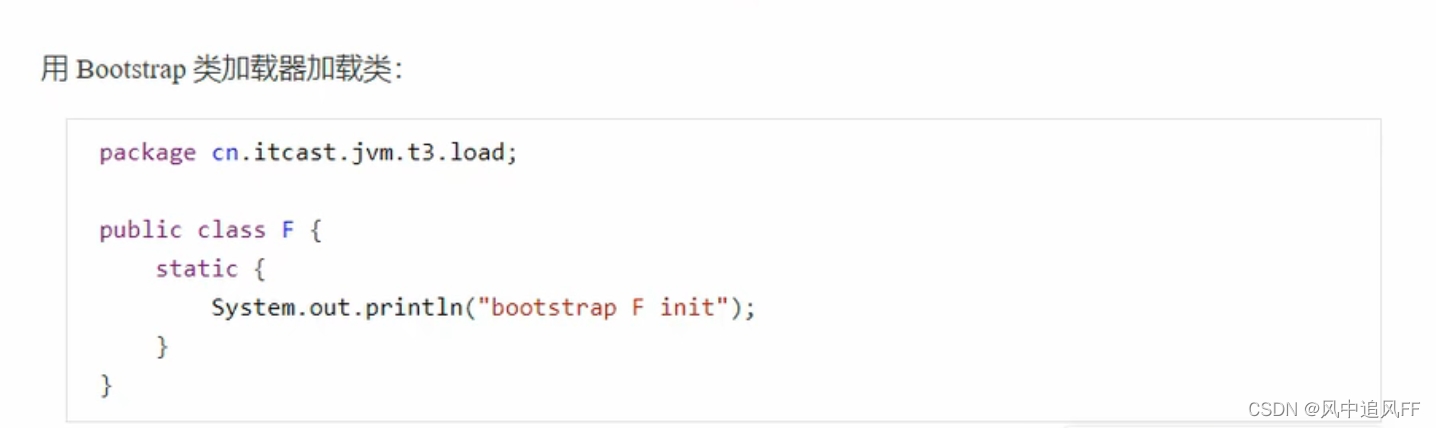
我们通过Class.forName来加载我们写好的F类
所有的类对象都可以通过getClassLoader()这个方法的得到它的加载器。
这里如果打印出的是null,则说明是启动类加载器加载的这个类。
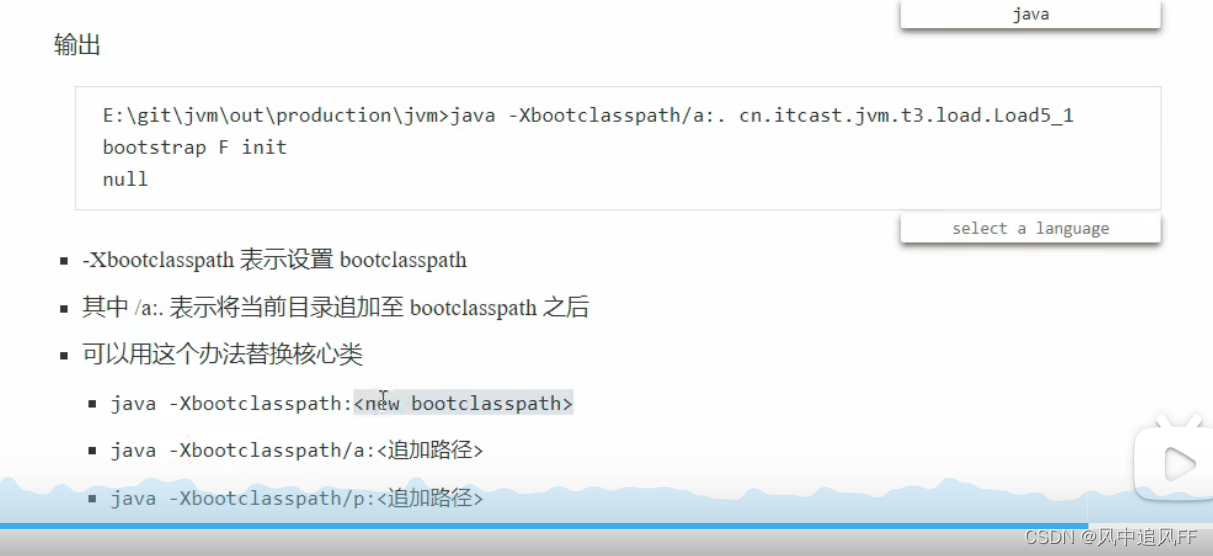
- java -Xbootclasspath:<new bootclaspath> ,是用新路径替换原有路径(jre下的lib)。
- Xbootclasspath/a:<追加路径> 被指定的文件追加到默认的bootstrap路径中。
9.7.3 扩展类加载器(Extension ClassLoader)
JDK9中,被平台类加载器(platform ClassLoader)取代
- 此加载器由 sun.misc.Launcher$ExtClassLoader 实现,它负责加载 {JAVA_HOME}\lib\ext 目录下的类库, 开发者可以直接获取此加载器。
- 拓展类加载器是是整个JVM加载器的Java代码可以访问到的类加载器的最顶端,即是超级父加载器,拓展类加载器是没有父类加载器的。
- 该加载器加载的类需要打成jar包。
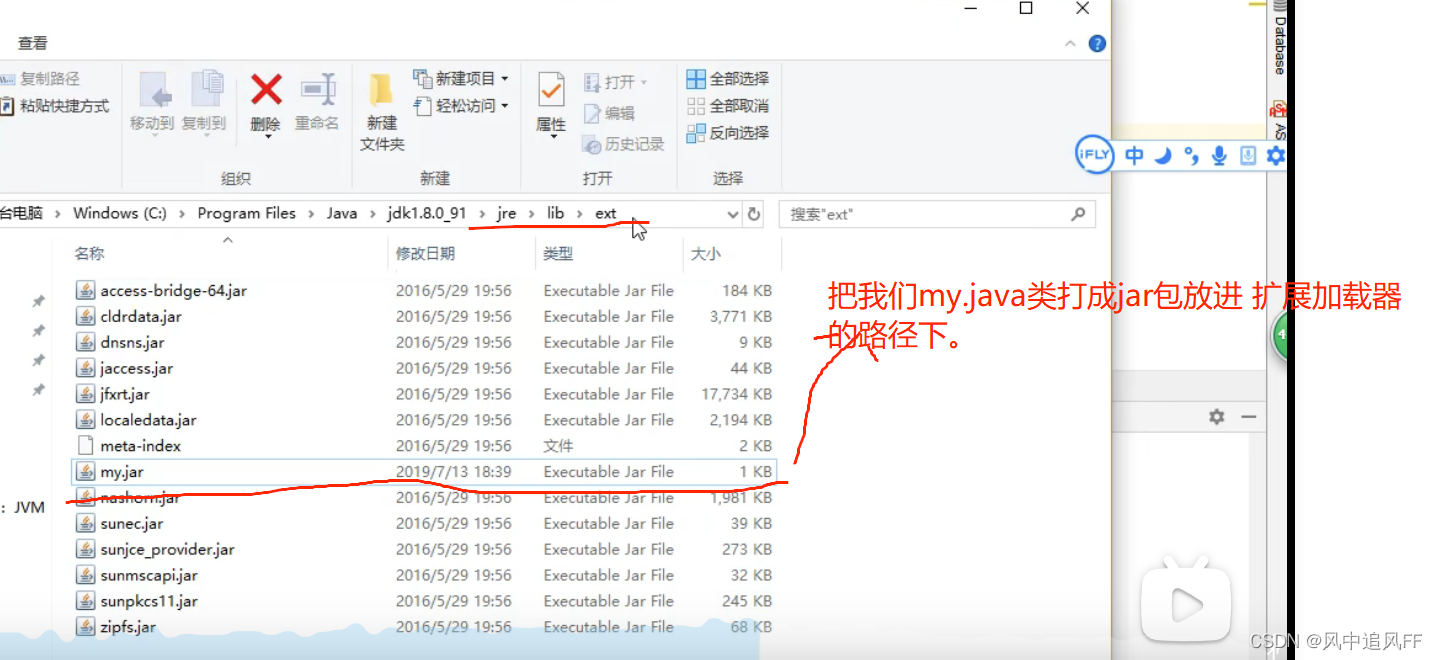
再打印它的类加载器,就成了扩展类加载器。
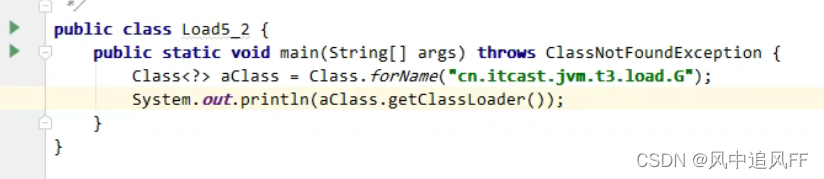
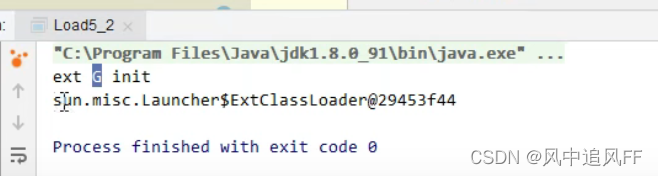
本来应该由应用程序加载器加载的,怎么被截胡了呢?
原理解释:Application ClassLoader先问Extension ClassLoader 是否加载过这个类,在Extension ClassLoader 的路径(也即是lib下的ext文件夹)中发现了我们的jar包,所有Application ClassLoader 就不加载 我们的jar包。
9.7.4 应用程序加载器 (Application ClassLoader)
此加载器负责加载用户类路径上指定的类库,若没有指定自定义加载器,则此加载器一般是程序中默认的加载器。
应用类加载器将拓展类加载器当成自己的父类加载器。
9.7.5 用户自定义类加载器(Customized Class Loader)
用户可以自己定义类加载器来加载类。所有的类加载器都要继承 java.lang.ClassLoader 类并重写 findClass(String name) 方法。用户自定义类加载器默认父加载器是 应用程序加载器
9.7.6 双亲委派模式
工作过程:一个类加载器收到类加载的请求,它首先会把这个请求委派给父类加载器去完成,层层上升,只有当父类加载器无法完成此加载请求时,子加载器才会尝试自己去加载。
父加载器和子加载器的关系是组合关系而不是继承关系。子加载器中有一个私有属性 parent 指向父加载器。
- 当应用程序加载器尝试加载类的时候,首先尝试让其父加载器–拓展类加载器加载;
- 如果拓展类加载器加载成功,则直接返回加载结果
Class<T> instance, 加载失败,则会询问是否引导类加载器已经加载了该类; - 当没有加载器加载时,应用加载器才会自己加载。
从源码看双亲委派模型:
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查是否已经被当前的类加载器加载,如果已经被加载,直接返回对应的Class<T>实例
Class<?> c = findLoadedClass(name);
//初次加载
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//如果有父类加载器,则先让父类加载器加载
c = parent.loadClass(name, false);
} else {
// 没有父加载器,则查看是否已经被启动类加载器加载,有则直接返回
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
// 父加载器加载失败,并且没有被引导类加载器加载,则尝试自己加载
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
// 自己尝试加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
//是否解析类
if (resolve) {
resolveClass(c);
}
return c;
}
} 9.7.7 SPI机制,JDBC打破双亲委派和线程上下文类加载器
可以看下面这篇
SPI 机制以及 jdbc 打破双亲委派

在获得数据库连接池时,我们只用了一个DriverManager类,但显然我们也需要加载mysql-connector-java.jar包里的类,DriverManager类是JDK核心库里的类,由bootstrap类加载器加载。
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/xxx?serverTimezone=GMT", "root", "123456");
如果我们不手动写
Class.forName("com.mysql.jdbc.Driver");也可以在DriverManager类里完成 对com.mysql.jdbc.driver类的加载。
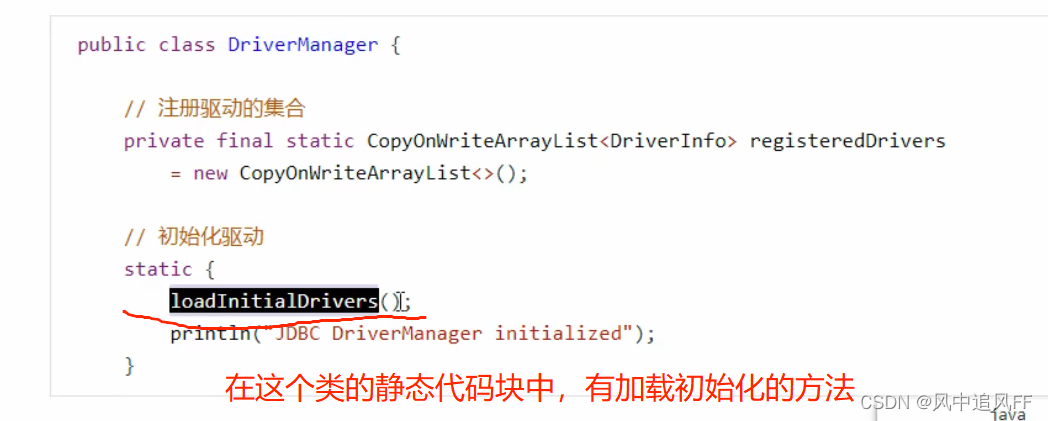
如何打破的双亲委派模式?
- 首先,肯定DriverManager类不能是直接调用Class.forName方法加载的(可以调用指定加载器的Class.forName方法),因为Class.forName 默认会采用调用者自己的类加载器去加载DriverManager 的类加载器启动类加载器,加载不到第三方驱动类com.mysql.jdbc.driver,所以DriveManager 必须要使用次一级的类加载器去加载。
SPI 和 线程上下文类加载器
先介绍一个SPI(Service Provider Interface )机制(或者说JDK指定的规范)
- 遵守JDK的约定:在jar包的META-INF/service包下,用接口全限定名(所谓全限定名 = 包名 + 类名)建立一个文件,文件的内容是 实现的类(第三方,要被加载的类)的名称。
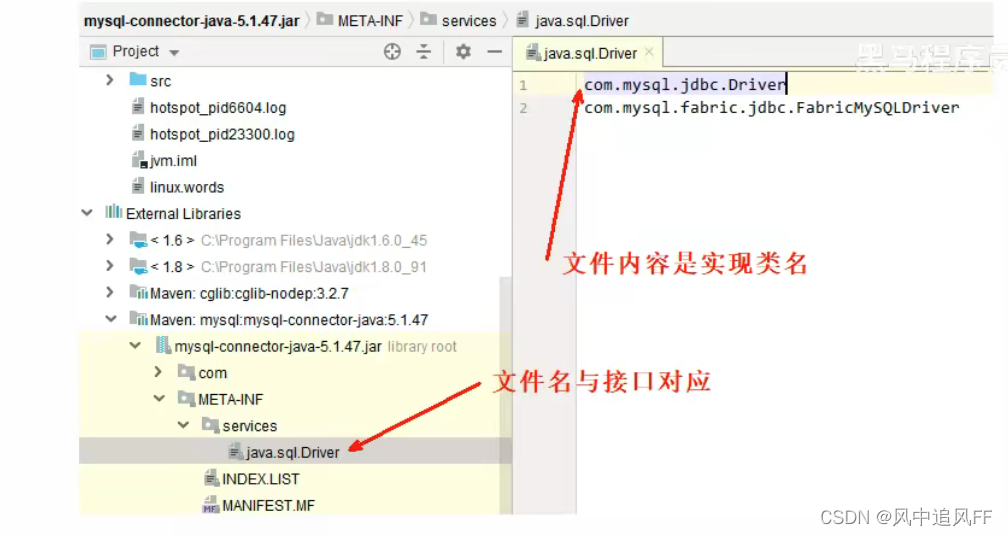
- 用ServiceLoader的load方法,把这个文件里的所有类都加载了,返回类对象集合。
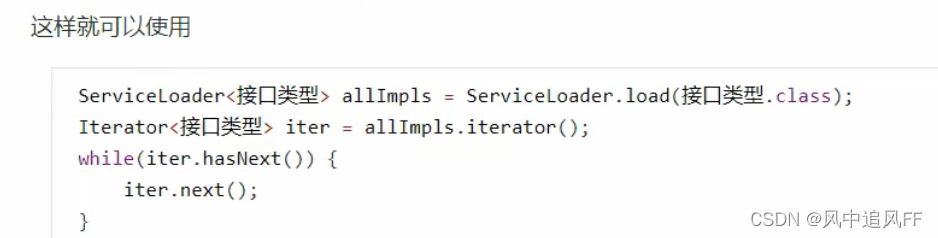
- load方法的内部使用了线程上下文类加载器

- 我们的jvm默认把应用程序加载器赋给 当前线程,所以getContextClassLoader拿到的是Application ClassLoader。
然后再看看里面的loadInitialDrivers()如何加载com.mysql.jdbc.driver类。
- 使用SPI (Service Provider Interface ),也就是线程上下文类加载器(默认为应用程序加载器。

- 直接使用指定加载器的的Class.forName加载com.mysql.jdbc.driver类

9.7.8 自定义类加载器
1.想加载任意路径下的类文件
2.一个接口可能有不同的实现,用不同的类加载器
3.比如一个类可能有多种版本(字节码编译版本),让新旧版本同时工作。tomcat容器

步骤:
- 只有重写findClass方法,才会委托上级的类加载器优先进行类的加载,只有上级类加载器没有找到Class的时候,才会掉用 findClass() 在本身的类加载器上查找,用本身的类加载器。
- 接下来在findClass里读取那个类文件的字节码(即byte数组),然后调用父类的defineClass方法来完成类的加载
- 然后我们的使用者,就可以调用我们自定义类加载器的loadClass方法来加载类。
10.运行期优化
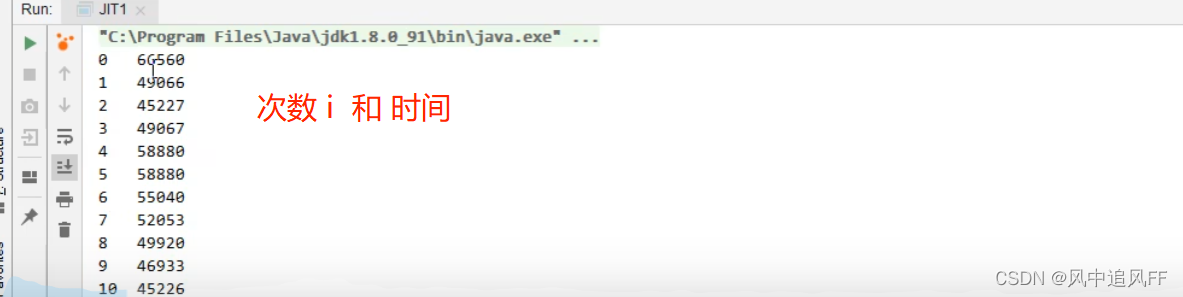
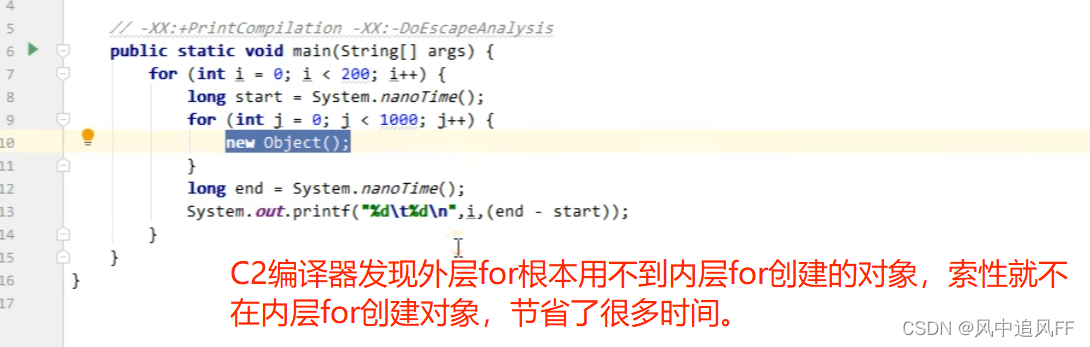
看一个小例子,内存for 循环1000次创建对象,外层循环记录每次创建对象花费的时间。
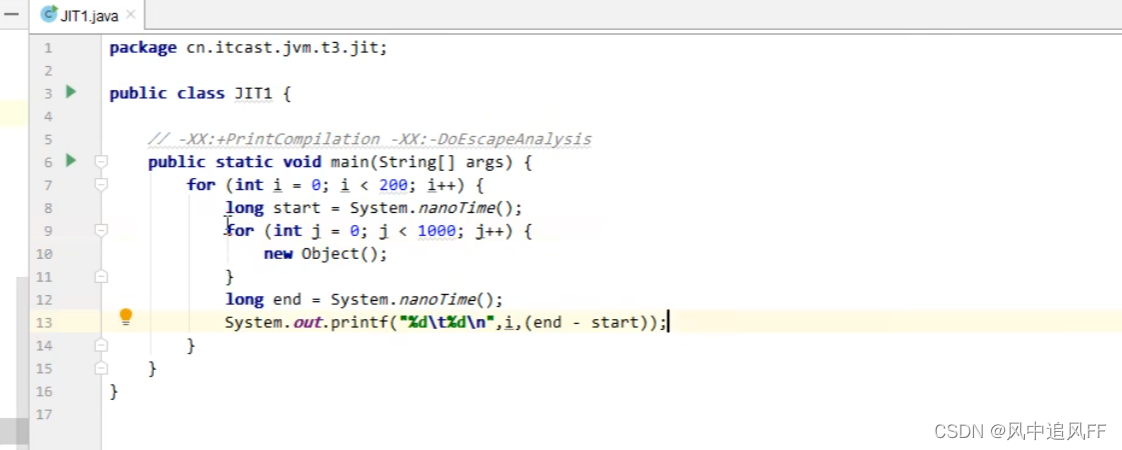
可以发现创建对象的时间越来越快。这说明JVM在运行期间对我们的代码优化
10.1 即时编译
10.1.1 分层编译 和 逃逸分析
即时编译器:将反复执行的代码的机器码存在Code Cache上

- 第0层就是普通的把字节码编译成机器码。
- C2是C1的优化版本的即时编译器,如果profiling发现某个方法被太频繁的调用,就会让C2来编译这个方法

逃逸分析:C2即时编译器可能通过分析发现某些孤立的代码,然后过滤掉这些代码(更改原来的字节码)。可以通过一个开关来关闭逃逸分析。-XX:-DoEscapeAnalysis

10.1.2 方法内联
方法内联就是把调用方函数代码"复制"到调用方函数中,减少因函数调用开销的技术
内联例子如下:
private int add2(int x1 , int x2 , int x3 , int x4) {
return add1(x1 , x2) + add1(x3,x4);
}
private int add1(int x1 , int x2) {
return x1 + x2;
}运行一段时间后,代码被内联翻译成:
private int add2(int x1 , int x2 , int x3 , int x4) {
//return add1(x1 , x2) + add1(x3,x4);
return x1 + x2 + x3 + x4;
}那为什么要方法内联呢?
函数调用过程
- 首先会有个执行栈,存储它们的局部变量、方法名、动态连接
- 当一个方法被调用,一个新的栈帧会被加到栈顶,分配的本地变量和参数会存储在这个栈帧
- 跳转到目标方法代码执行
- 方法返回的时候,本地方法和参数被销毁,栈顶被移除
- 返回原来的地址执行
有压栈和出栈的过程,因此,函数调用需要有一定的时间开销和空间开销。
当一个方法体不大,但又频繁被调用时,时间和空间开销变得很大,不划算
方法内联的条件
JVM会自动的识别热点方法,并对它们使用方法内联优化。那么一段代码需要执行多少次才会触发JIT优化呢?通常这个值由-XX:CompileThreshold参数进行设置:
- 使用client编译器时,默认为1500(即C1即时编译器)
- 使用server编译器时,默认为10000(即C2即时编译器)
方法题如果太大,即时标记为热点,JVM仍然不一定会对它做方法内联优化
- 如果方法是经常执行的,默认情况下,方法大小小于325字节的都会进行内联(可以通过** -XX:MaxFreqInlineSize=N**来设置这个大小)
- 如果方法不是经常执行的,默认情况下,方法大小小于35字节才会进行内联(可以通过** -XX:MaxInlineSize=N**来设置这个大小)
我们可以通过增加这个大小,以便更多的方法可以进行内联;但是除非能够显著提升性能,否则不推荐修改这个参数。因为更大的方法体会导致代码内存占用更多,更少的热点方法会被缓存,最终的效果不一定好。
同时我们也可以取消某个方法的内联,使用命令
内联的隐藏条件
虽然JIT号称可以针对代码全局的运行情况而优化,但是JIT对一个方法内联之后,还是可能因为方法被继承,导致需要类型检查(比如说多态)而没有达到性能的效果。想要对热点的方法使用上内联的优化方法,最好尽量使用final、private、static这些修饰符修饰方法,避免方法因为继承,导致需要额外的类型检查,而出现效果不好情况
10.1.3 字段优化
对象字段读取优化的
- 缓存读取
static int bar(Foo o, int x) { int y = o.a + x; // 将o.a存入缓存 return o.a + y; } //实例字段Foo.a被读取两次,即时编译器会将第一次读取的值缓存起来,并且 替换 第二次的字段读取操作,以 节省 一次内存访问 //优化后为 static int bar(Foo o, int x) { int t = o.a; int y = t + x; return t + y; } - 去掉不可达分支
static int bar(Foo o, int x) { o.a = 1; if (o.a >= 0) // 缓存中o.a为1,该行判断可以默认为true(IR图中自动消除该行) return x; else // 冗余无效代码,(IR图中自动消除该else分支) return -x; } // 优化后程序 static int bar(Foo o, int x) { o.a = 1; return x; } - 去除重复赋值语句:如果两次赋值语句之间,变量没有被间接存储到其他字段或没有被方法调用,JVM会消除第一处的冗余赋值指令
class Foo { int a = 0; // 冗余重复代码,被优化(IR图中被去除) void bar() { a = 1; // 冗余重复代码,被优化(IR图中被去除) a = 2; // 最终执行的赋值语句 } } // 优化后程序 class Foo { void bar() { a = 2; // 最终执行的赋值语句 } }// 重复代码消除 int bar(int x, int y) { int t = x*y; // 重复冗余代码,去除(x*y) t = x+y; return t; }
可能出现异常时,无法进行字段优化
// 除零异常
int bar(int x, int y) {
int t = x/y; // 由于可能出现y=0的算术操作异常,所以该行不能被优化去除
t = x+y;
return t;
}
如果所存储的字段被标记为 volatile ,那么即时编译器也 不能消除冗余存储
此时如果对变量i加上volatile关键字修饰的话,它可以保证当A线程对变量i值做了变动之后,会立即刷回到主内存中,而其它线程读取到该变量的值也作废,强迫重新从主内存中读取该变量的值,这样在任何时刻,AB线程总是会看到变量i的同一个值。
也就是说volatile修饰的变量,每次的变动必须得跟内存互动一下,会影响即时编译器的字段优化
同理,加解锁操作同样也会阻止即时编译器的字段读取优化。(比如volatile修饰的变量为T,你第一次为T赋值完,立马给它加了锁,然后再第二次对它进行赋值。第一次的值,很明显被锁上了,所以不能优化第一次的赋值。)
10.1.4 方法的反射优化 和反射调用慢的原因
首先我们得知道什么是java的反射机制
- JAVA反射机制是在 运行状态中,对于任意一个 类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
- 在执行方法时,局部变量会压栈,如果在方法中new一个类的实例(即类对象),那么会去方法区先找到这个类的信息,如果找不到就先加载这个类,在java堆上会保存一个类的实例,用这个实例的newInstance方法就可以创造出这个类的对象
java.lang.Class Class 类对象名称 = java.lang.Class.forName(要实例化的类全称); 类名 对象名 = (类名)Class类对象名称.newInstance();
这里invoke就是调用 Reflect1这个类里的静态方法foo,因为是静态方法,不需要借助
为什么从第16次之后,速度就变快了呢? foo为Method对象
先来看看JDK里Method.invoke()是怎么实现的。
它调用一个方法访问器MethodAccessor里的invoce方法,这里的MethodAccessor是一个接口
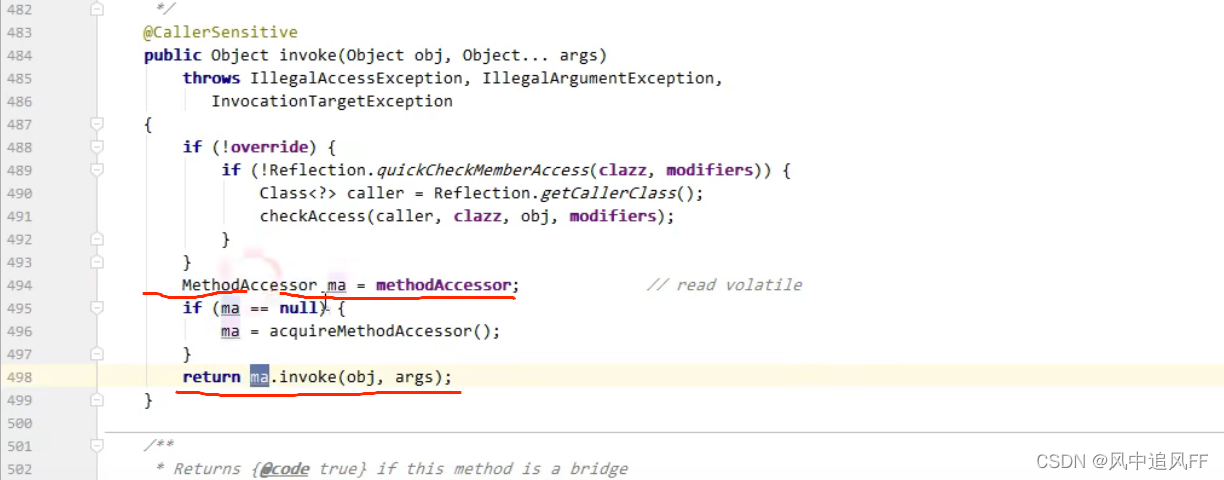
MethodAccessor这个接口有三个实现:DelegatingMethodAccessorImpl,MethodAccessorImpl和NativeMethodAccessorImpl

DelegatingMethodAccessorImpl里啥也没实现,在前16次它默认调用NativeMethodAccessorImpl(本地方法访问器)
我们先看NativeMethodAccessorImpl(本地方法访问器)的源码
在前16次它不满足if里的条件,会调用方法invoke0(C++实现,性能较低),
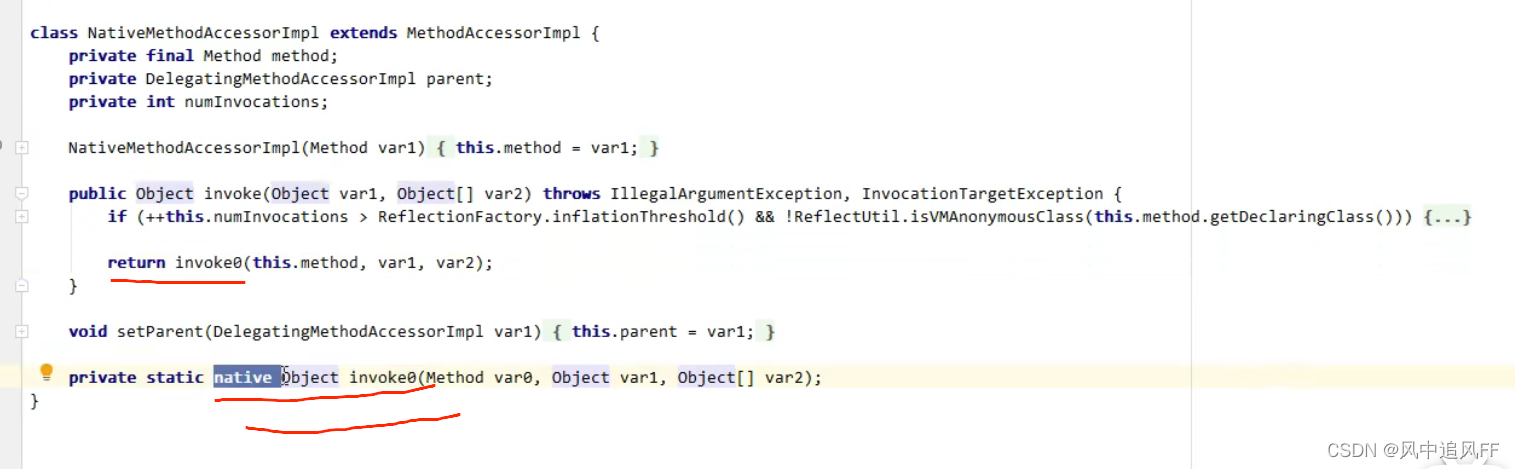
invoke0被调用的次数会被记录下来,当调用次数大于inflationThreshould(膨胀阈值默认16,这个阈值可以设置),NativeMethodAccessorImpl就会被替换成一个新的运行期间动态生成的方法访问器类(这个类没有源代码,在运行期间动态生成的)GeneratedMethodAccessor1。
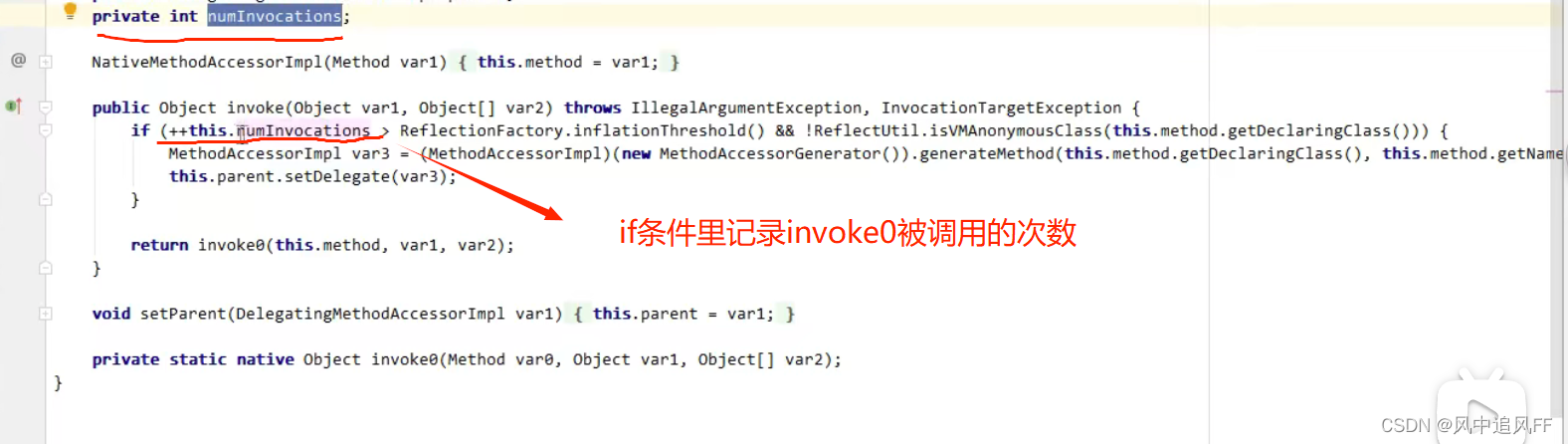
第17次调用时,使用这个新生成的方法访问器类GeneratedMethodAccessor1,这个类继承了MethodAccessorImpl父类,当然因此也间接实现了MethodAccessor接口,在我们的以往理解中invoke是方法反射调用,但实际在他生成的invoke代码里面,已经变成了Relect1.foo(),因为foo是静态方法,所以他是通过类名.静态方法名调用的,那这还是不是反射调用呢,很明显,已经不是了。
所以我们从第17次开始,java虚拟机已经把我们的反射方法调用转换成了正常的方法调用,性能和直接调用foo方法差距很小。
需要注意的是,膨胀阈值是可以进行设置的,即他是取了环境变量System.getProperty("sun.reflect.inflationThreshold");的值,所以可以自己去指定。
另外还可以通过另一个变量System.getProperty("sun.reflect.noInflation");即noInflation是不要膨胀,如果给他设置为ture,就相当于他会一上来就直接使用这个生成后的MethodAccessor,就不会使用那个本地MethodAccessor了。
当然我们也可以不用设,因为你虽然可以用noInflation来禁用膨胀,但是首次生成GeneratedMethodAccessor1是比较耗时的,如果你这个方法(比如 foo)只是反射调用一次,那感觉就会有些不太划算。
为什么java反射调用方法效率慢?
原因:
- 接口的通用性,java的invoke方法是传object和object[]数组的,基本数据类型的参数需要装箱和拆箱,产生大量额外的对象和内存开销,频繁触发GC。
- 编译器难以对动态调用的代码提前优化,比如不能方法内联。
- 反射查找时,按名检索类和方法,有一定的时间开销。
11.JMM( java Memory Model)java内存模型
11.1 原子性
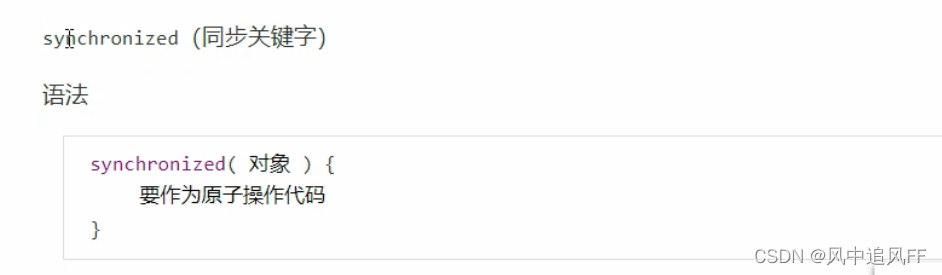
通过synchronized 关键字来保证操作的原子性。

先停一下,学JUC去