文章目录
- read_csv读取出错。因为多余异常列数据
- 解决方法
- pd.to_datetime(df['time_key'])但time_key出现不能转换的序列
- 解决方法
- pandas 提取时间序列年、月、日
- 方法一:pandas.Series.dt.month() 方法提取月份
- 方法二:strftime() 方法提取年、月、日
- 方法三:pandas.DatetimeIndex.month提取月份
- pd.concat()多表合并
- 示例
- df.groupby()分组
read_csv读取出错。因为多余异常列数据
在读取数据集的时候出现报错。检查才发现是出现是

ParserError: Error tokenizing data. C error: Expected 16 fields in
line 14996, saw 29
解决方法
由于我这边数据集够多。选择直接这种数据就舍弃跳过
df = pd.read_csv(filePath, on_bad_lines='warn')
on_bad_lines 指定遇到错误行(字段太多的行)时要执行的操作。允许的值为:
- “error”,遇到错误行时引发异常。
- “warn”,遇到错误行时发出警告并跳过该行。
- “skip”,在遇到错误行时跳过错误行而不引发或警告。
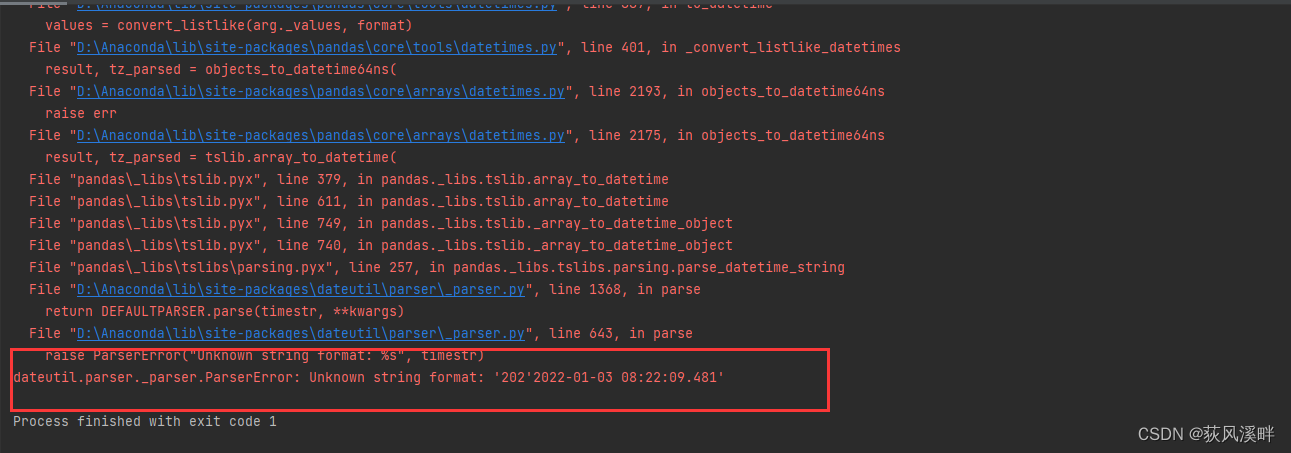
pd.to_datetime(df[‘time_key’])但time_key出现不能转换的序列
dateutil.parser._parser.ParserError: Unknown string format: ‘202’2022-01-03 08:22:09.481’
解决方法
把它挑出来剔除
df['time_key'] = pd.to_datetime(df['time_key'],errors='coerce') # 不加format也行,pandas自动推断日期格式,format='%Y-%m-%d %H:%M:%S'
df.dropna(inplace=True) #剔除
errors三种取值,‘ignore’, ‘raise’, ‘coerce’,默认为raise。
raise,则无效的解析将引发异常coerce,那么无效解析将被设置为NaT(not a time ,和NaN一样是空值)ignore,那么无效的解析将返回原值
to_datetime官网解释
pandas 提取时间序列年、月、日
方法一:pandas.Series.dt.month() 方法提取月份
应用于 Datetime 类型的pandas.Series.dt.month() 方法分别返回系列对象中Datetime条目的年和月的numpy数组。
注意:如果该列不是 Datetime 类型,则应首先使用 to_datetime() 方法将该列转换为 Datetime类型,pd.to_datetime()。
- 获取其他时间方法
dt.year、dt.month、dt.day:获取年、月、日;
dt.hour、dt.minute、dt.second、dt.microsecond:获取时、分、秒、微秒;
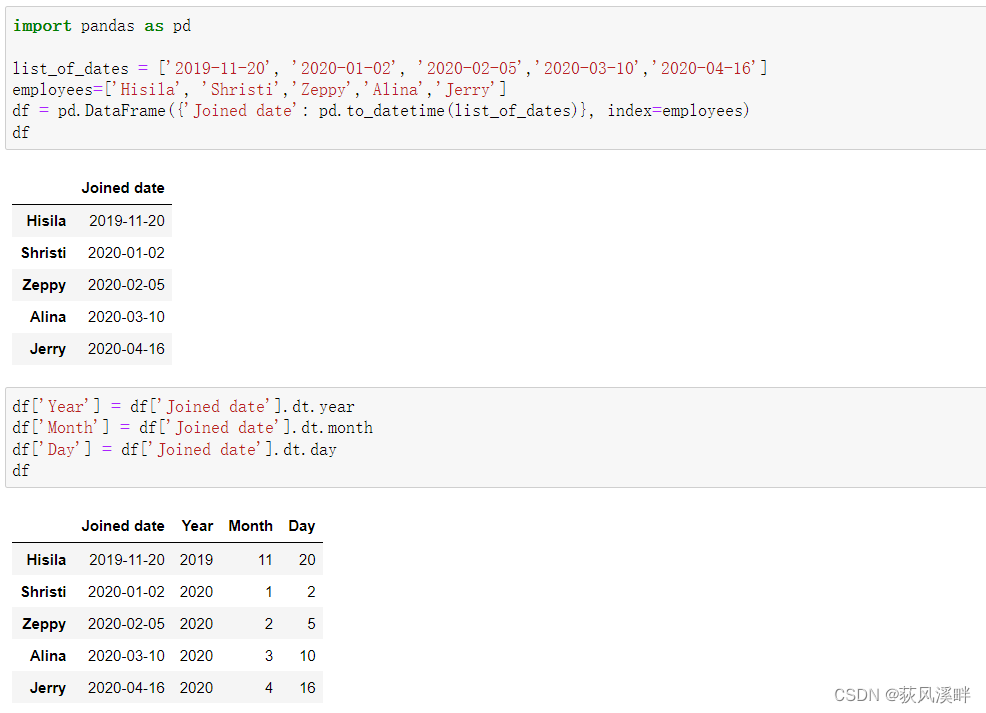
示例
import pandas as pd
list_of_dates = ['2019-11-20', '2020-01-02', '2020-02-05','2020-03-10','2020-04-16']
employees=['Hisila', 'Shristi','Zeppy','Alina','Jerry']
df = pd.DataFrame({'Joined date': pd.to_datetime(list_of_dates)}, index=employees)
df['Year'] = df['Joined date'].dt.year
df['Month'] = df['Joined date'].dt.month
print(df)
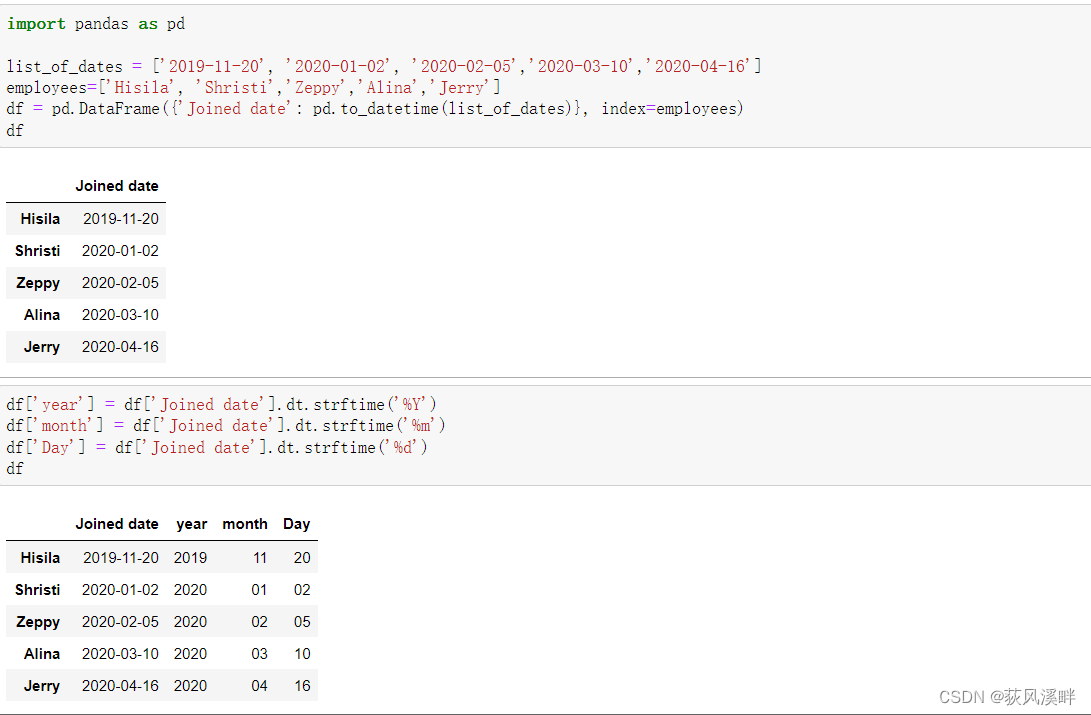
方法二:strftime() 方法提取年、月、日
strftime() 方法使用 Datetime,将格式代码作为输入,并返回表示输出中指定的特定格式的字符串。使用%Y 和%m 作为格式代码来提取年份和月份。
df['year'] = df['Joined date'].dt.strftime('%Y')
df['month'] = df['Joined date'].dt.strftime('%m')
df['Day'] = df['Joined date'].dt.strftime('%d')
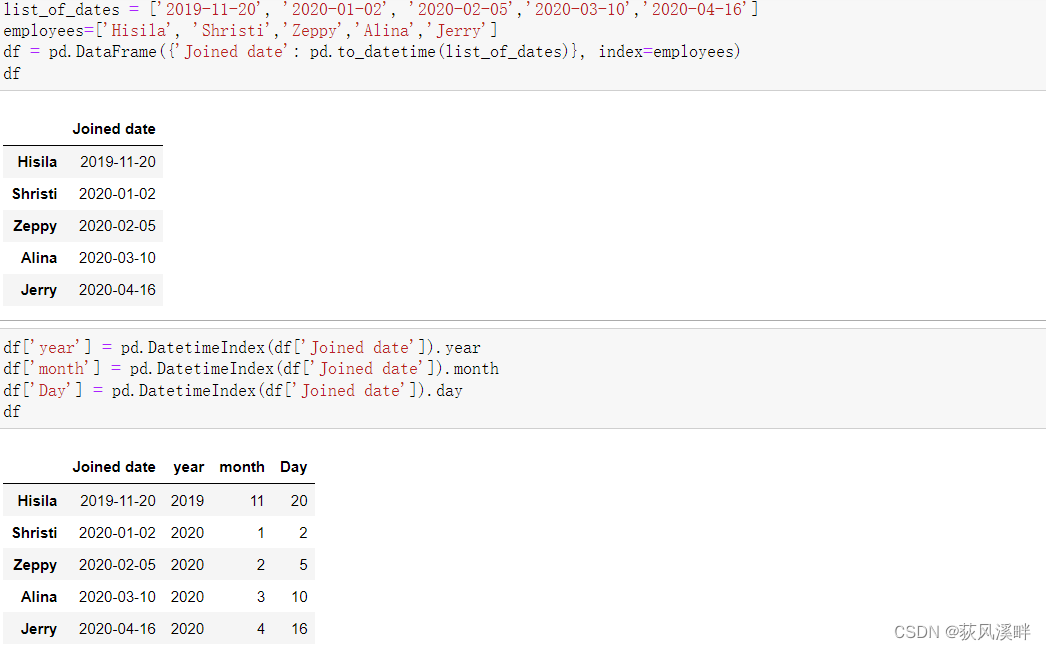
方法三:pandas.DatetimeIndex.month提取月份
通过检索 pandas.DatetimeIndex 对象的月份属性的值类,从 Datetime 列中提取月份。
此时,datatime是DataFrame的索引,时间类型的索引。比非时间索引类型的时间类型列,在抽取年月的时候,少个dt。
df['year'] = pd.DatetimeIndex(df['Joined date']).year
df['month'] = pd.DatetimeIndex(df['Joined date']).month
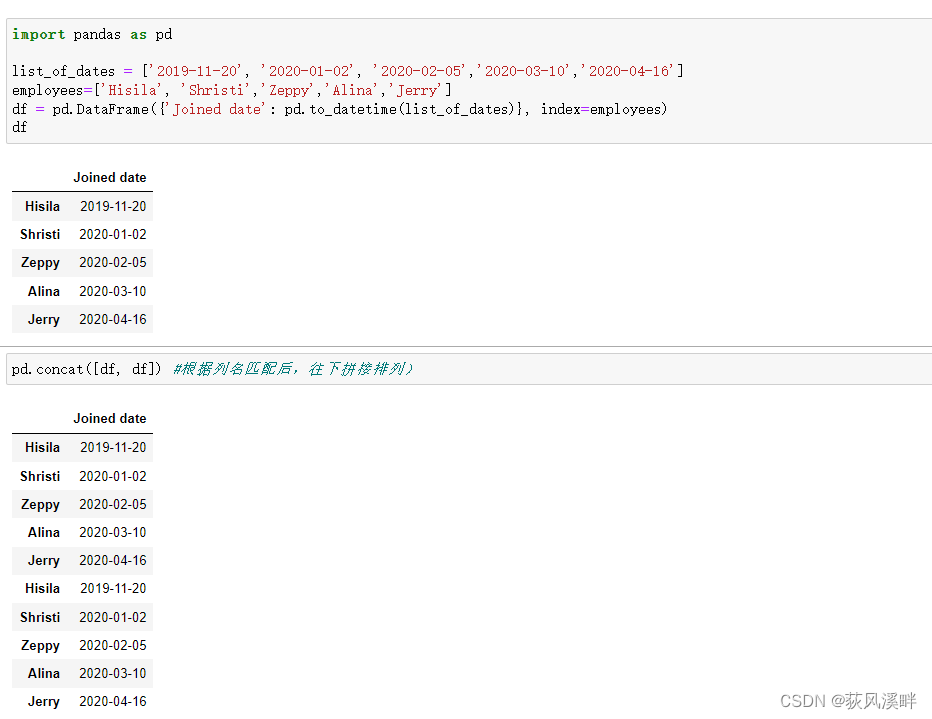
pd.concat()多表合并
参数:
concat(objs, *, axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
参数介绍:
- axis=0代表
index,匹配列名,往下拼接排列;axis=1代表columns,拼接生成新列,索引不变。( 默认axis=0) - objs:需要连接的对象集合,一般是列表或字典;
- join:参数为
outer(默认拼接方式,并集合并)或inner(交集合并); ignore_index=True:重建索引,默认是False
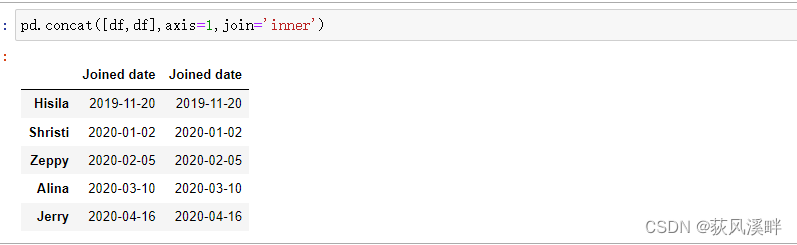
示例
import pandas as pd
list_of_dates = ['2019-11-20', '2020-01-02', '2020-02-05','2020-03-10','2020-04-16']
employees=['Hisila', 'Shristi','Zeppy','Alina','Jerry']
df = pd.DataFrame({'Joined date': pd.to_datetime(list_of_dates)}, index=employees)
pd.concat([df, df]) #根据列名匹配后,往下拼接排列)
pd.concat([df,df],axis=1,join='inner')
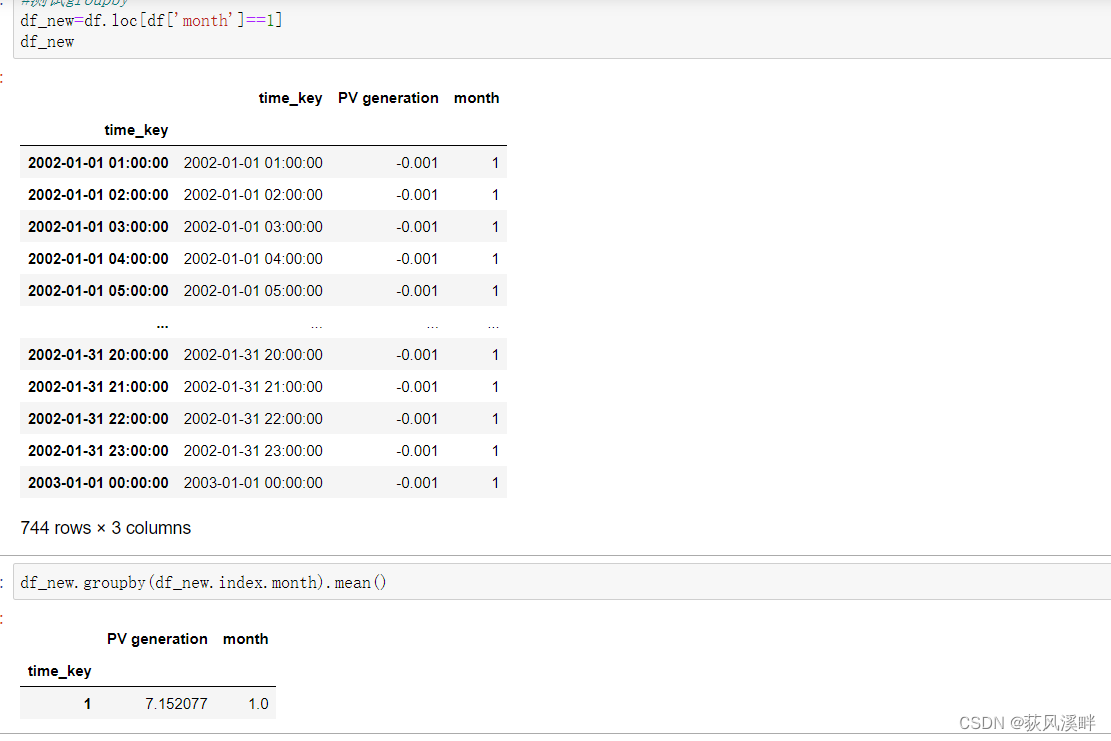
df.groupby()分组
df_new=df.loc[df['month']==1]
df_new.groupby(df_new.index.month).mean() #按时间序列中的月份求各列的均值.hour,day同理